Spark:DataFrame介绍及使用
1. DataFrame详解
DataFrame是基于RDD进行封装的结构化数据类型,增加了schema元数据,最终DataFrame类型在计算时,还是转为rdd计算。DataFrame的结构化数据有Row(行数据)和schema元数据构成。
- Row 类型 表示一行数据
- DataFrame就算是多行构成
# 导入行类Row
from pyspark.sql import Row# 创建行数据
r1 = Row(1, '张三', 20)# 行数取取值 按照下标取值
data = r1[0]
print(data)
data1 = r1[1]
print(data1)# 指定字段创建行数据
r2 = Row(id=2, name='李四', age=22)
# 按照字段取值
data3 = r2['id']
print(data3)
data4 = r2['name']
print(data4)
- schema表信息
- 定义DataFrame中的表的字段名和字段类型。
# 导入数据类型
from pyspark.sql.types import *# 定义schema信息
# 使用StructType类进行定义
# add()方法是指定字段信息
# 第一参数,字段名
# 第二个参数,字段信息
# 第三个参数是否允许为空值 默认是True,允许为空
schema_type = StructType().\add('id',IntegerType()).\add('name',StringType()).\add('age',IntegerType(),False)
2. DataFrame创建
创建datafram数据需要使用一个sparksession的类创建,SparkSession类是在SparkContext的基础上进行了封装,也就是SparkSession类中包含了SparkContext。
2.1 基本创建
#DataFrame 的基本创建
#Row就是行数据定义的类
from pyspark.sql import Row, SparkSession
from pyspark.sql.types import *#行数据创建
r1 = Row(1,"刘向阳",23,'男')
print(r1)#行数据下标取值
print(r1[0])
print(r1[1])#创建行数据时可以指定字段名
r2 = Row(id=2,name='李四',age=20,gender='女')
print(r2)
#使用字段名取值
print(r2['name'])# 定义元数据
schema = (StructType().add('id', IntegerType()).add('username', StringType()).add('age', IntegerType()).add('gender', StringType()))
print(schema)# 将元数据和行数据放在一起合成DataFrame
ss = SparkSession.builder.getOrCreate()# 调用创建df的方法
df = ss.createDataFrame([r1,r2],schema=schema)# 查看df中数据
df.show()#查看元数据信息
df.printSchema()
运行结果:

2.2 RDD和DF之间的转化
- rdd的二维数据转化为DataFrame
- rdd.toDF()

- rdd.toDF()
# rdd 和 dataframe的转化
from pyspark.sql import SparkSession#创建SparkSession对象
ss = SparkSession.builder.getOrCreate()#基于ss对象获取sparkContext
sc = ss.sparkContext#创建rdd , 要使用二维列表指定每行数据
rdd = sc.parallelize([[1,'张三',20,'男'],[2,'李四',20,'男']])#将rdd转为df
df = rdd.toDF(schema='id int,name string,age int,gender string')#df数据查看
df.show()
df.printSchema()#df可以转rdd
res = df.rdd.collect()
print(res)rdd2 = df.rdd.map(lambda x:x['name'])res2 = rdd2.collect()
print(res2)
运行结果:

2.3 pandas和spark之间转化
- spark的df转为pandas的df
toPandas
#pandas 和 spark的dataframe转化
from pyspark.sql import SparkSession
import pandas as pdss = SparkSession.builder.getOrCreate()#创建pandas的df
df_pd = pd.DataFrame({'id':[1,2,3,4],'name':['张三','李四','王五','赵六'],'age':[1,2,3,4],'gender':['男','女','女','女']}
)
#查看数据
print(df_pd)#取值
name = df_pd['name'][0]
print(name)
# 将pandas中的df转为spark的df
df_spark = ss.createDataFrame(df_pd)#查看
df_spark.show()#取值
row = df_spark.limit(1).first()
print(row['name'])#将spark的df重新转为pandas的df
df_pandas = df_spark.toPandas()
print(df_pandas)
运行结果:

2.4 读取文件数据转为df
通过read方法读取数据转为df
- ss.read
#读取文件转为df
from pyspark.sql import SparkSessionss = SparkSession.builder.getOrCreate()#读取不同文件数据转为df
# txt文件
df = ss.read.text('hdfs://node1:8020/data/students.txt')
df.show()# json 文件
df_json = ss.read.json('hdfs://node1:8020/data/baike_qa_valid.json')
df_json.show()#orc文件
df_orc = ss.read.orc('hdfs://node1:8020/data/users.orc')
df_orc.show()#去取csv文件
#header或csv文件中的第一行作为表头字段数据
df_csv = ss.read.csv('hdfs://node1:8020/data/students.csv')
df_csv.show()
3. DataFrame基本使用
3.1 SQL语句
使用sparksession提供的sql方法,编写sql语句执行
#使用sql操作dataframe结构化数据
from pyspark.sql import SparkSessionss = SparkSession.builder.getOrCreate()#读取文件数据转为df
df_csv = ss.read.csv('hdfs://node1:8020/data/students.csv', header=True,sep=',')#使用sql操作df数据
#将df指定一个临时表名
df_csv.createTempView('stu')#编写sql字符串语句,支持hivesql语法
sql_str ="""
select * from stu
"""#执行sql语句,执行结果返回一个新的df
df_res = ss.sql(sql_str)
df_csv.show()
df_res.show()
3.2 DSL方法
DSL方法是df提供的数据操作函数
使用方式:
- df.方法()
- 可以进行链式调用
- df.方法().方法().方法()
- 方法执行后返回一个新的df保存计算结果
- new_df = df.方法()
spark提供DSL方法和sql的关键词一样,使用方式和sql基本类似,在进行数据处理时,要按照sql的执行顺序去思考如何处理数据。
from join 知道数据在哪 df本身就是要处理的数据 df.join(df2) from 表
where 过滤需要处理的数据 df.join(df2).where()
group by 聚合 数据的计算 df.join(df2).where().groupby().sum()
having 计算后的数据进行过滤 df.join(df2).where().groupby().sum().where()
select 展示数据的字段 df.join(df2).where().groupby().sum().where().select()
order by 展示数据的排序 df.join(df2).where().groupby().sum().where().select().orderBy()
limit 展示数据的数量 df.join(df2).where().groupby().sum().where().select().orderBy().limit()
DSL方法执行完成后会得到一个处理后的新的df
#使用DSL方法操作dataframe
from pyspark.sql import SparkSessionss = SparkSession.builder.getOrCreate()#读取文件数据转为df
df_csv = ss.read.csv('hdfs://node1/data/students.csv', header=True,sep=',')#使用DSL方法对df数据进行操作
df2 = df_csv.select('id','name')#查看结果
df2.show()#第二种指定字段的方式
df3 = df_csv.select(df_csv.age,df_csv.gender)#给字段起别名
df4 = df_csv.select(df_csv.age.alias('new_age'),df_csv.gender)
df4.show()#修改字段类型
df_csv.printSchema()
df5 = df_csv.select(df_csv.age.cast('int'),df_csv.gender)
df5.printSchema()#where 的数据过滤
age = 20
df6 = df_csv.where(f'age > {age}')
df6.show()#过滤年龄大于20并且性别为女性的学生信息
df7 = df_csv.where(f'age > 20 and gender = "女" ')
df7.show()#使用第二种字段判断方式
df8 = df_csv.where(df_csv.age == age)
df8.show()#分组聚合计算
df9 = df_csv.select(df_csv.gender,df_csv.cls,df_csv.age.cast('int').alias('age')).groupby('gender','cls').sum('age')
df9.show()#分组后过滤where 聚合计算时只能一次计算一个聚合数据
df10 = df_csv.select(df_csv.gender,df_csv.cls,df_csv.age.cast('int').alias('age')).groupby('gender','cls').sum('age').where('sum(age) > 80')
df10.show()#排序
df11 = df_csv.orderBy('age') #默认排序
df11.show()df12 = df_csv.orderBy('age',ascending=False) #降序
df12.show()#分页
df13 = df_csv.limit(5)
df13.show()#转为rdd
res = df_csv.rdd.collect()[5:10]
print(res)
df_new = ss.createDataFrame(res)
df_new.show()
相关文章:
Spark:DataFrame介绍及使用
1. DataFrame详解 DataFrame是基于RDD进行封装的结构化数据类型,增加了schema元数据,最终DataFrame类型在计算时,还是转为rdd计算。DataFrame的结构化数据有Row(行数据)和schema元数据构成。 Row 类型 表示一行数据 …...

Linux系统:本机(物理主机)访问不了虚拟机中的apache服务问题的解决方案
学习目标: 提示:本文主要讲述-本机(物理主机)访问不了虚拟机中的apache服务情况下的解决方案 Linux系统:Ubuntu 23.04; 文中提到的“本机”:代表,宿主机,物理主机; 首先,…...

望繁信科技成功签约国显科技 流程挖掘助力制造业智造未来
近日,上海望繁信科技有限公司(简称“望繁信科技”)成功与深圳市国显科技有限公司(简称“国显科技”)达成合作。国显科技作为全球领先的TFT-LCD液晶显示及Mini/Micro LED显示产品供应商,致力于为笔记本、手机…...

枚举在Java体系中的作用
1. 枚举 枚举是在JDK1.5以后引入的。主要用途是:将一组常量组织起来,在这之前表示一组常量通常使用定义常量的方式: //用public static final修饰常量 public static final int RED 1; public static final int GREEN 2; public static f…...

『气泡水』Web官网 案例赏析
前言 Schweppes,作为一家享誉全球的气泡水品牌,致力于与年轻消费者建立更紧密的联系,并提升品牌影响力。为此,其打造了一个充满创意和高度互动性的官网,利用前端技术和动画效果,将产品特性与用户浏览体验完…...

【前端】制作一个简单的网页(2)
单标签组成的元素 这类标签不需要内容产生效果,通常表示对网页的某种行为,它们不用标记任何内容,开始即是结束。 比如,<hr>标签的作用是在网页中添加一条分割线,它仅包含开始标签,是一个单标签元素。…...

OpenAI Canvas:提升编程与写作效率的全新工作界面
随着人工智能技术的飞速发展,大语言模型(LLM)不仅限于生成文本,还能逐步扩展至编程、设计等任务的支持。近期,OpenAI 推出了一个名为 Canvas 的全新功能,专门用于协助用户进行编程和写作。这一功能与 Claud…...

将SpringBoot的Maven项目打成jar包和war包
先需要明确的是,该项目打包的形态是可执行的jar包,还是在tomcat下运行的war包。 springboot自带的maven打包 1.创建一个springboot web项目 1.api控制层HelloWorld.java RestController RequestMapping("/hello") public class HelloWorld …...

【Iceberg分析】Spark与Iceberg集成之常用存储过程
文章目录 Spark与Iceberg集成之常用存储过程调用语法调用样例表快照管理快照回滚根据snapshotid进行回滚根据timestamp进行回滚 设置表当前生效的快照 表元数据管理设置快照过期时间清除孤岛文件重写数据文件运用参数示例optionsGeneral OptionsOptions for sort strategyOptio…...

[旧日谈]关于Qt的刷新事件频率,以及我们在Qt的框架上做实时的绘制操作时我们该关心什么。
[旧日谈]关于Qt的刷新事件频率,以及我们在Qt的框架上做实时的绘制操作时我们该关心什么。 最近在开发的时候,发现一个依赖事件来刷新渲染的控件会导致程序很容易异常和崩溃。 当程序在运行的时候,其实软件本身的负载并不高,所以…...
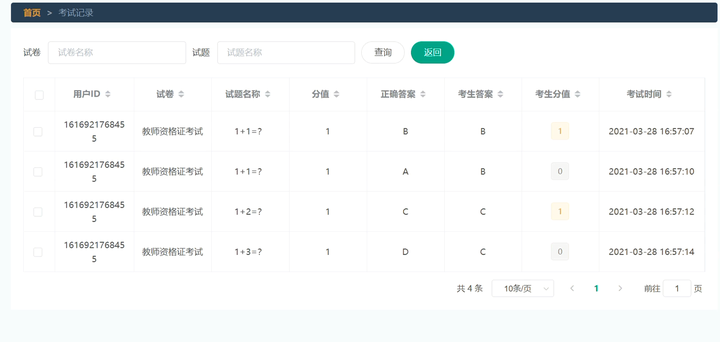
云上考场小程序+ssm论文源码调试讲解
2 关键技术简介 2.1 微信小程序 微信小程序,简称小程序,英文名Mini Program,是一种全新的连接用户与服务的方式,可以快速访问、快速传播,并具有良好的使用体验。 小程序的主要开发语言是JavaScript,它与…...

城域网——IP城域网、城域以太网、光城域网
一、城域网 1、城域网(Metropolitan Area Network,MAN):一个城市范围内所建立的计算机通信网。 2、分布式队列双总线(Distributed Queue Dual Bus,DQDB):即IEEE802.6,由…...

华为Eth-trunk链路聚合加入到E-trunk实现跨设备的链路聚合
一、适用场景(注:e-trunk与eth-trunk是2个不同的概念) 1、企业中有重要的server服务器业务不能中断的情况下,可将上行链路中的汇聚交换机,通过eth-trunk链路聚合技术,实现链路故障后,仍有可用的…...

【网络安全】JSONP劫持原理及攻击实战
未经许可,不得转载。 文章目录 JSONP简介JSONP工作原理JSONP劫持Callback可定义问题JSONP简介 JSONP(JavaScript Object Notation Padding)是一种用于绕过浏览器同源策略限制的技术,使得网页可以从不同域名的服务器请求数据。由于浏览器的同源策略限制,网页通常只能向与其…...
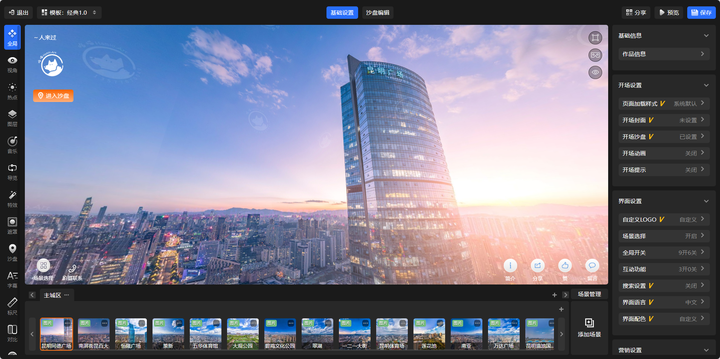
VR全景摄影的拍摄和编辑软件推荐
随着虚拟现实技术的不断进步,VR全景摄影逐渐成为商业、娱乐和教育等多个领域中的重要工具。通过专业的设备与软件,摄影师能够创作出沉浸式的360度全景作品,为观众提供身临其境的视觉体验。在这篇文章中,我们将介绍VR全景摄影的相关…...

linux:使用sar诊断问题
使用sar诊断问题 1. CPU 使用情况2. 内存与交换3. 磁盘 I/O 活动4. 网络 I/O 活动5. 进程与上下文切换6. 系统调用与文件活动7. 电源管理8. 延迟分析9. 系统全局统计10. 查看历史记录11. 特定时间段12. 自动定时采样其他参数:使用实例: sar(S…...
)
CUDA编程技巧(不断搜集更新)
1 使用位运算替换部分乘法或除法 位移操作主要适用于无符号整数,对于带符号数的位移,特别是负数,可能会导致问题,如果你需要对负数执行除法或者乘法,最好谨慎使用位移运算。 1.1 替换除法 当需要将一个数除以 2、4、…...

云计算(第二阶段):mysql后的shell
第一章:变量 前言 什么是shell Shell 是一种提供用户与操作系统内核交互的工具,它接受用户输入的命令,解释后交给操作系统去执行。它不仅可以作为命令解释器,还可以通过脚本完成一系列自动化任务。 shell的特点 跨平台:…...
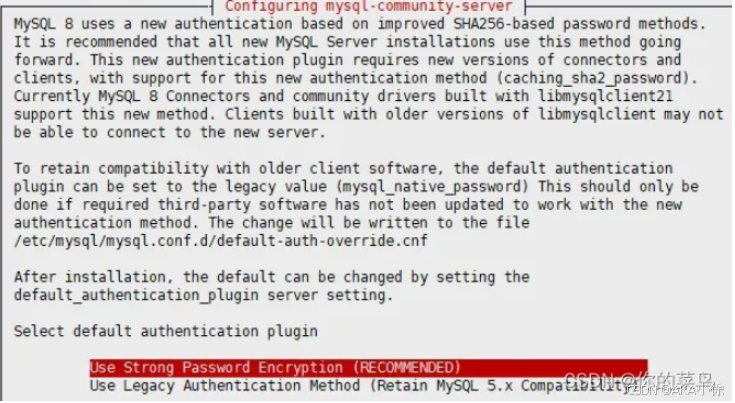
Debian12离线部署Mysql全网最详细教程
一、下载安装所需要的库 1、所需要的库 # 所需要的库有 libc6_2.36-9deb12u8_amd64.deb libgcc-s1_12.2.0-14_amd64.deb libstdc6_12.2.0-14_amd64.deb gcc-12-base_12.2.0-14_amd64.deb psmisc_23.6-1_amd64.deb libnuma1_2.0.18-1_amd64.deb libmecab2_0.996-14b14_amd64.d…...

文本生成视频技术:艺术与科学的交汇点
在人工智能技术的飞速发展下,文本生成视频(Text-to-Video)技术已经成为现实。这项技术能够根据文本描述生成相应的视频内容,极大地拓展了内容创作的边界。本文将从三个主要方面对文本生成视频技术进行深入探讨:技术能达…...

【STM32CubeMX实战】基于NRF24L01与HAL库构建稳定无线通信链路
1. NRF24L01无线模块基础认知 第一次接触NRF24L01这个火柴盒大小的模块时,我完全没想到它能在2.4GHz频段实现2Mbps的高速通信。这个由Nordic公司出品的射频芯片,特别适合嵌入式系统的无线通信需求。它的工作电压范围在1.9V到3.6V之间,实测在3…...

官宣!网络安全法正式实施,人才缺口 327 万,这 5 类人直接站上风口,年薪百万不是梦
【必看收藏】网络安全人才抢夺战打响!新法实施后5类专业薪资翻倍,附学习路线 新《网络安全法》实施引爆网络安全人才市场,全球缺口480万,中国缺口327万以上。网络空间安全、信息安全、保密技术、网络安全科学与技术、信息对抗技术…...

【NotebookLM海洋学研究辅助实战指南】:20年海洋数据科学家亲授AI笔记法,3步构建专属科研知识图谱
更多请点击: https://intelliparadigm.com 第一章:NotebookLM海洋学研究辅助 NotebookLM 是 Google 推出的基于用户上传文档进行深度语义理解与推理的 AI 工具,特别适用于海洋学这类多源异构、长周期、高专业性的科研场景。研究人员可将 PDF…...
系统安装)
从零到一:手把手教你用U盘搞定OpenEuler(欧拉)系统安装
1. 为什么选择OpenEuler? OpenEuler作为一款开源的企业级Linux发行版,凭借其高性能、高可靠性和安全性,已经成为众多开发者和企业的首选。我第一次接触OpenEuler是在一个服务器迁移项目中,当时需要寻找一个稳定且长期维护的Linux发…...

大模型爆发期!程序员现在转型,还能赶上风口吗?
文章目录前言一、2026年,大模型风口到底有多猛?二、90%的人不敢转型,都是被这3个误区坑了误区1:转大模型必须会高数、会从头训模型误区2:我只会写CRUD,没资格转大模型误区3:现在转已经晚了&…...

深度解析ArtPlayer.js:5个高级视频播放器实战技巧
深度解析ArtPlayer.js:5个高级视频播放器实战技巧 【免费下载链接】ArtPlayer :art: ArtPlayer.js is a modern and full featured HTML5 video player 项目地址: https://gitcode.com/gh_mirrors/ar/ArtPlayer ArtPlayer.js是一款功能全面且高度可定制的现代…...

Windows: 深入剖析pip install SSLError与SSL模块缺失的根源及系统级修复
1. Windows下pip install SSLError的典型表现 最近在Windows系统上用pip安装Python包时,不少朋友都遇到了这样的报错信息:"Cant connect to HTTPS URL because the SSL module is not available"。这个错误通常会出现在使用清华源、阿里云源等…...

手把手教你用YOLOv5训练VisDrone2019数据集:搞定无人机航拍小目标检测
无人机视角下的目标检测实战:YOLOv5与VisDrone2019数据集深度适配指南 无人机航拍图像的目标检测一直是计算机视觉领域的难点与热点。VisDrone2019作为当前最权威的无人机视角数据集之一,包含了丰富的场景变化和极具挑战性的小目标检测任务。本文将带您从…...
)
CentOS 7/8 服务器根目录爆满?别慌,用LVM无损调整home空间给root(保姆级避坑指南)
CentOS服务器根目录空间告急?LVM动态扩容实战指南 凌晨三点,服务器监控突然狂闪警报——根目录剩余空间不足5%!这种场景对于运维人员来说无异于一场噩梦。当关键业务系统因日志无法写入而濒临崩溃时,传统的重装系统或数据迁移方案…...

FanControl完全指南:Windows风扇智能调速的终极解决方案
FanControl完全指南:Windows风扇智能调速的终极解决方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/…...