金字塔流(Pyramid Flow): 用于生成人工智能长视频的新文本-视频开源模型

在 "生成式人工智能 "中的文本生成模型和图像生成模型大行其道之后,现在该是文本-视频模型大显身手的时候了,这个列表中的新模型就是 pyramid-flow-sd3,它是一个开源模型,用于从文本或图像生成长达 10 秒的视频,而且是 24fps 的视频!
该模型非常重要的点,
可以免费使用,并且开源,因此本地用户也可以使用代码使用该模型
生成较长的人工智能视频(最长 10 秒),是其他模型(5 秒)的两倍。
它既能生成文本视频,也能生成图像视频。
它是在开源数据集上训练的。
该模型可在 HuggingFace 上下载,并可使用 python
了解金字塔流
随着 pyramid-flow-sd3 的发布,该模型所基于的团队也引入了一个新概念,即金字塔流(Pyramid Flow)。 从官方 Github 代码库中摘录如下
Pyramid Flow, a training-efficient Autoregressive Video Generation method based on Flow Matching.
让我们来解释一下这些行话
自回归视频生成技术
自回归视频生成技术是一种按顺序生成视频每一帧画面的技术,每一帧新画面都会根据之前生成的画面进行预测。
这种方法可确保视频中的时间关系得以保留,从而使最终输出更加逼真。 该模型可学习理解运动和变化是如何随时间发生的,这对于创建流畅、可信的视频序列至关重要。
流匹配
流匹配是一种用于将生成数据的分布与真实数据的分布相一致的方法。 它涉及对数据点(在本例中为视频帧)如何随时间从一种状态过渡到另一种状态进行建模。
通俗地说 : 流匹配是一种帮助计算机学习如何使生成的视频看起来真实的技术。 它的重点是理解视频的一帧应该如何变化到下一帧。 通过了解这些变化,该模型可以制作出看起来自然可信的视频,就像现实生活中的运动一样。
Pyramid Flow(金字塔流)
Pyramid Flow(金字塔流)指的是视频生成中的一种分层方法,可在多个分辨率下运行,类似于金字塔结构。
这种方法允许模型从较低分辨率的表征开始,逐步细化为较高分辨率的表征。 通过这种方式处理数据,Pyramid Flow 提高了计算效率,并保持了帧间的连续性,这对于生成逼真的视频至关重要。
Pyramid Flow 与流量匹配有什么关系?
Pyramid Flow 使用流量匹配来改进视频生成。
当模型创建视频时,它会使用 "流匹配 "来确保金字塔的每一步(或层)都能顺利过渡到下一步。 这意味着,从模糊版本到清晰版本,它都能保持一切看起来真实流畅。
Pyramid Flow is like building a video step by step, while Flow Matching makes sure that every step looks good and flows well into the next one.
rain1011/pyramid-flow-sd3
这是 Pyramid Flow 的官方资源库,Pyramid Flow 是一种基于流匹配(Flow Matching)的训练效率高的自回归视频生成方法。 通过仅在开源数据集上进行训练,它能以 768p 分辨率和 24 FPS 的速度生成高质量的 10 秒视频,并自然支持图像到视频的生成。
安装
我们建议使用 conda 设置环境。 代码库目前使用 Python 3.8.10 和 PyTorch 2.1.2,我们正在积极努力支持更广泛的版本。
git clone https://github.com/jy0205/Pyramid-Flow
cd Pyramid-Flow# create env using conda
conda create -n pyramid python==3.8.10
conda activate pyramid
pip install -r requirements.txt然后,您可以直接从 Huggingface 下载模型。 我们提供 768p 和 384p 两种视频生成的模型检查点。 384p 检查点支持以 24FPS 的速度生成 5 秒钟的视频,而 768p 检查点支持以 24FPS 的速度生成长达 10 秒钟的视频。
from huggingface_hub import snapshot_downloadmodel_path = 'PATH' # The local directory to save downloaded checkpoint
snapshot_download("rain1011/pyramid-flow-sd3", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')使用
要使用我们的模型,请按照此链接中的 video_generation_demo.ipynb 中的推理代码进行操作。 我们将其进一步简化为以下两个步骤。 首先,加载下载的模型:
import torch
from PIL import Image
from pyramid_dit import PyramidDiTForVideoGeneration
from diffusers.utils import load_image, export_to_videotorch.cuda.set_device(0)
model_dtype, torch_dtype = 'bf16', torch.bfloat16 # Use bf16 (not support fp16 yet)model = PyramidDiTForVideoGeneration('PATH', # The downloaded checkpoint dirmodel_dtype,model_variant='diffusion_transformer_768p', # 'diffusion_transformer_384p'
)model.vae.to("cuda")
model.dit.to("cuda")
model.text_encoder.to("cuda")
model.vae.enable_tiling()然后,您可以尝试根据自己的提示将文字转换成视频:
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch_dtype):frames = model.generate(prompt=prompt,num_inference_steps=[20, 20, 20],video_num_inference_steps=[10, 10, 10],height=768, width=1280,temp=16, # temp=16: 5s, temp=31: 10sguidance_scale=9.0, # The guidance for the first frame, set it to 7 for 384p variantvideo_guidance_scale=5.0, # The guidance for the other video latentoutput_type="pil",save_memory=True, # If you have enough GPU memory, set it to `False` to improve vae decoding speed)export_to_video(frames, "./text_to_video_sample.mp4", fps=24)作为一个自回归模型,我们的模型还支持(以文本为条件的)图像到视频的生成:
image = Image.open('assets/the_great_wall.jpg').convert("RGB").resize((1280, 768))
prompt = "FPV flying over the Great Wall"with torch.no_grad(), torch.cuda.amp.autocast(enabled=True, dtype=torch_dtype):frames = model.generate_i2v(prompt=prompt,input_image=image,num_inference_steps=[10, 10, 10],temp=16,video_guidance_scale=4.0,output_type="pil",save_memory=True, # If you have enough GPU memory, set it to `False` to improve vae decoding speed)export_to_video(frames, "./image_to_video_sample.mp4", fps=24)通过添加 cpu_offloading=True 参数,我们还支持 CPU 卸载,以便在 GPU 内存不足 12GB 的情况下进行推理。 该功能由 @Ednaordinary 提供,详情请参见 #23。
使用技巧
- guidance_scale 参数控制视觉质量。 我们建议在文本到视频生成过程中,对 768p 检查点使用 [7, 9] 以内的指导,对 384p 检查点使用 7 以内的指导。
- 视频引导尺度(video_guidance_scale)参数用于控制运动。 数值越大,动态程度越高,自回归生成的劣化程度也就越低,而数值越小,视频就越稳定。
- 对于 10 秒钟的视频生成,我们建议使用 7 级指导等级和 5 级视频指导等级。
最后
自今年上半年图生视频的svd开源以后,越来越多的研究者都在尝试复现Sora模型,其中企业闭源的模型有不少,如MiniMax和Luma Dream Machine等,但终于开源社区也迎来了属于自己的文生图模型——CogVideoX。我觉得 Pyramid Flow 的出现也让我们更相信研究的方向是正确的,同时需要更多的实验和实践。吾生也有涯,而学也无涯,以有涯随无涯。
相关文章:
金字塔流(Pyramid Flow): 用于生成人工智能长视频的新文本-视频开源模型
在 "生成式人工智能 "中的文本生成模型和图像生成模型大行其道之后,现在该是文本-视频模型大显身手的时候了,这个列表中的新模型就是 pyramid-flow-sd3,它是一个开源模型,用于从文本或图像生成长达 10 秒的视频…...

施磊C++ | 进阶学习笔记 | 5.设计模式
五、设计模式 文章目录 五、设计模式1.设计模式三大类型概述一、创建型设计模式二、结构型设计模式三、行为型设计模式 2.设计模式三大原则3.单例模式1.饿汉单例模式2.懒汉单例模式 4.线程安全的懒汉单例模式1.锁双重判断2.简洁的线程安全懒汉单例模式 5.简单工厂(Simple Facto…...

智绘城市地图:使用百度地图 API 实现智能定位
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua小谢,在这里我会分享我的知识和经验。&am…...

【稳定性】稳定性建设之变更管理
作者:京东物流 冯志文 背景 在软件开发和运维领域,变更管理是一个至关重要的环节。无论是对现有系统的改进、功能的增加还是修复漏洞,变更都是不可避免的。这些变更可能涉及到软件代码的修改、配置的调整、服务器的扩容、三方jar包的变更等等…...
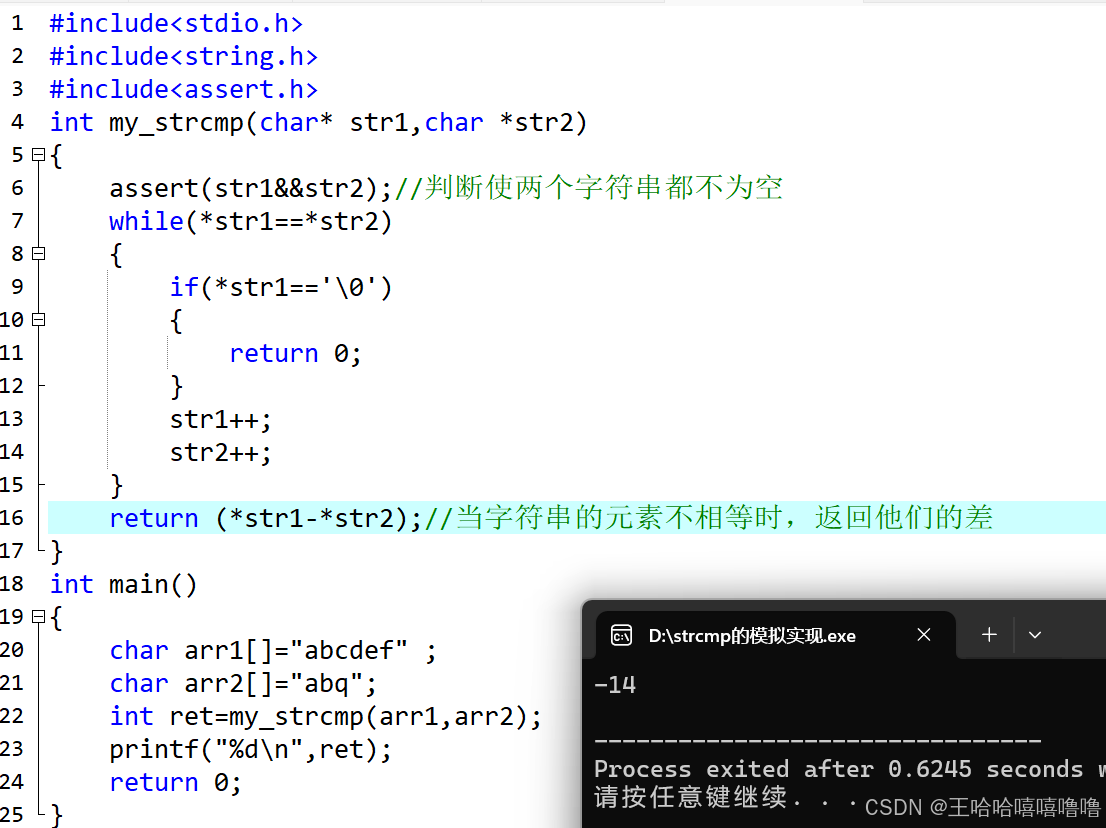
c语言中字符串函数strlen,strcmp,strcpy,srtcat,strncpy,strncmp,strncat
1.strlen的使用和模拟实现 strlen 用来求字符串的长度,统计\0之前字符的个数。 模拟实现1:计数参数法 模拟实验2:指针方法 模拟实验3:递归方法 2,strcpy 的使用和模拟实现(拷贝字符串) char*…...

高级SQL技巧
高级SQL技巧涵盖了许多方面,包括但不限于窗口函数、递归查询、公共表表达式(CTEs)、子查询、集合操作、临时函数、日期时间操作、索引优化等。以下是对这些技巧的详细讲解和示例。 窗口函数 窗口函数是一种特殊的SQL函数,能够在…...

新大话西游图文架设教程
开始架设 1. 架设条件 新大话西游架设需要准备: linux 系统服务器,建议 CentOs 7.6或以上版本游戏源码,。 2. 安装宝塔面板 宝塔是一个服务器运维管理软件,安装命令: yum install -y wget && wget -O in…...

Maven 快速入门
Maven 快速入门 一、简介1、概述2、特点3、工作原理4、常用命令5、生命周期6、优缺点🎈 面试题 二、安装和配置1、安装2、环境配置3、命令测试是否安装成功4、功能配置5、idea配置本地 maven6、maven 工程依赖包查询网站 三、基于IDEA创建Maven工程1、maven 工程中的…...

OpenCV-人脸检测
文章目录 一、人脸检测流程二、关键方法三、代码示例四、注意事项 OpenCV是一个开源的计算机视觉和机器学习软件库,它提供了多种人脸检测方法,以下是对OpenCV人脸检测的详细介绍: 一、人脸检测流程 人脸检测是识别图像中人脸位置的过程&…...

【重磅升级】基于大数据的股票量化分析与预测系统
温馨提示:文末有 CSDN 平台官方提供的学长 QQ 名片 :) 1. 项目简介 伴随全球经济一体化和我国经济的快速发展,中国股票市场对世界经济的影响力不断攀升,中国股市已成为全球第二大股票交易市场。在当今的金融市场中,股票价格的波动…...

python全栈学习记录(二十四)元类、异常处理
元类、异常处理 文章目录 元类、异常处理一、元类1.元类控制类的实例化2.属性/方法的查找顺序3.单例 二、异常处理 一、元类 1.元类控制类的实例化 类的__call__方法会在产生的对象被调用时自动触发,args和kwargs就是调用实例时传入的参数,返回值是调用…...

Golang Slice扩容机制及注意事项
Golang Slice扩容机制及注意事项: 在 Go语言中,Slice(切片)是一种非常灵活且强大的数据结构,它是对数组的抽象,提供了动态数组的功能。Slice 的扩容机制是自动的,但了解其背后的原理对于编写高…...

华为OD机试 - 猜数字 - 暴力枚举(Python/JS/C/C++ 2024 E卷 100分)
华为OD机试 2024E卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试真题(Python/JS/C/C)》。 刷的越多,抽中的概率越大,私信哪吒,备注华为OD,加入华为OD刷题交流群,…...

Flink触发器Trigger
前言 在 Flink 窗口计算模型中,数据先经过 WindowAssigner 分配窗口,然后再经过触发器 Trigger,Trigger 决定了一个窗口何时被 ProcessFunction 处理。每个 WindowAssigner 都有一个默认的 Trigger,如果默认的不满足需求…...

【操作系统的使用】Linux 系统环境变量与服务管理:设置与控制的艺术
文章目录 系统环境变量与服务管理:设置与控制的艺术一、系统环境变量的设置1.1 临时设置环境变量1.2 永久设置环境变量 二、服务启动类型的设置2.1 查看服务状态2.2 启动和停止服务2.3 设置服务的启动类型2.3.1 设置服务在启动时运行2.3.2 禁用服务在启动时运行2.3.…...

速盾:高防cdn配置中性能优化是什么?
高防CDN配置中的性能优化是指通过调整CDN配置以提升网站的加载速度、响应时间和用户体验。在进行性能优化时,需要考虑多个因素,包括CDN节点的选择和布置、缓存策略、缓存过期时间、预取和预加载、并发连接数和网络延迟等。 首先,CDN节点的选…...

Qt_软件添加版本信息
文章内容: 给生成的软件添加软件的版权等信息 #include <windows.h> //中文的话增加下面这一行 #pragma code_page(65001)VS_VERSION_INFO VERSIONINFO...

mallocfree和newdelete的区别
malloc\free和new\delete的区别 malloc/free new/delete 身份: 函数 运算符\关键字 返回值: void* 带类型的指针 参数: 字节个数(手动计算) 类型 自动计算字节数 处理数组: 手动计算数组总字节数 new 类型[数量] 扩容࿱…...
无锁队列实现(Michael Scott),伪代码与c++实现
一、Michael & Scoot 原版伪代码实现 structure pointer_t {ptr: pointer to node_t, count: unsigned integer}structure node_t {value: data type, next: pointer_t}structure queue_t {Head: pointer_t, Tail: pointer_t}initialize(Q: pointer to queue_t)node new_…...

猜数字小游戏
前言 猜数字游戏是一款经典且简单的互动游戏,常常用于提高逻辑思维能力和锻炼数学技巧。本文将深入探讨一段用 JavaScript 编写的猜数字游戏代码,帮助读者理解游戏的基本逻辑和实现方法。这段代码不仅适合初学者练习编程技巧,也是了解用户交…...

软阴影:那个让虚拟世界“温柔起来“的光影小秘密
一、从一只小猫的影子说起 前几天我在朋友家做客,他家养了一只胖乎乎的橘猫,正趴在阳台的窗边晒太阳。我无意间瞥了一眼那只猫脚边的影子,突然被一个细节震撼了—— 那只猫的影子——并不是一片均匀的黑。 仔细看——猫肚子紧贴地板的地方——…...

CUDA并行计算与FSR框架优化实践
1. CUDA并行计算与FSR框架概述在GPU加速计算领域,CUDA(Compute Unified Device Architecture)作为NVIDIA推出的并行计算平台和编程模型,已经成为高性能计算的事实标准。其核心设计理念是将计算任务分解为网格(Grid&…...

告别DLL缺失烦恼!Visual C++运行库合集一键搞定Windows应用依赖问题
告别DLL缺失烦恼!Visual C运行库合集一键搞定Windows应用依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经在打开某个软件或游戏时…...

告别鼠标点击,微博图片批量下载的轻松方案
告别鼠标点击,微博图片批量下载的轻松方案 【免费下载链接】weiboPicDownloader Download weibo images without logging-in 项目地址: https://gitcode.com/gh_mirrors/we/weiboPicDownloader 还记得那个周末的下午吗?你喜欢的博主发布了九宫格美…...

Python-for-Android 完整指南:5分钟将Python应用打包为Android APK
Python-for-Android 完整指南:5分钟将Python应用打包为Android APK 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android࿰…...

概率论:常见分布的期望与方差、中心极限定理、切比雪夫不等式
目录 一、0、1分布 二、二项分布 三、泊松分布 四、均匀分布 五、指数分布 六、正态分布 七、中心极限定理及其应用 (1)中心极限定理的定义 (2)使用示例 八、切比雪夫不等式 (1)切比雪夫不…...

基于ATmega328P与TFT屏的园艺环境监控系统:硬件选型与软件架构详解
1. 项目概述:打造你的家庭园艺数据监控中心如果你和我一样,是个喜欢在阳台或后院捣鼓花草的园艺爱好者,同时又对电子DIY有点兴趣,那么这个项目绝对会让你兴奋。我们不是在简单地种花,而是在用数据“聆听”植物的需求。…...

ComfyUI扩展生态系统的智能管家:ComfyUI-Manager全面解析
ComfyUI扩展生态系统的智能管家:ComfyUI-Manager全面解析 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various cu…...

Windows流媒体服务器终极指南:5分钟部署SRS高性能视频传输平台
Windows流媒体服务器终极指南:5分钟部署SRS高性能视频传输平台 【免费下载链接】srs-windows 项目地址: https://gitcode.com/gh_mirrors/sr/srs-windows 在Windows平台上快速搭建专业级流媒体服务器,SRS(Simple Realtime Server&…...

强化学习赋能匹配滤波器:可解释心电R波检测新范式
1. 项目概述:当经典匹配滤波器遇上强化学习在生物医学信号处理,尤其是心电分析这个行当里,R波的精准检测是几乎所有后续分析的基石。无论是计算心率、分析心率变异性,还是筛查心律失常,第一步都是把那些尖尖的R波从嘈杂…...