vLLM 推理引擎性能分析基准测试
文章目录
- 分析步骤
- 案例
- 案例描述
- 测试数据集
- 原始数据
- 〇轮测试(enable-64)
- 一轮测试(enable-128)
- 二轮测试(enable-256)
- 三轮测试(enable-512)
- 四轮测试(enable-2048)
- 五轮测试(enable-4096)
- 六轮测试(enable-8192)
- 七轮测试(disable-256)
- 八轮测试(disable-512)
- 九轮测试(disable-2048)
- 十轮测试(disable-4096)
- 十一轮测试(disable-8192)
- 数据可视化
- 数据汇总说明
- 总览-耗时&吞吐量
- TTFT(Time To First Token)
- TPOT(Time per Output Token)
- ITL(Inter-token Latency)
- 结论
本篇为 vLLM 性能测试分析篇,vLLM 调研文档请看 vLLM 调研文档
分析步骤
-
通过设置环境变量 VLLM_TORCH_PROFILER_DIR 到你想要保存追踪文件的目录来启用追踪,例如:VLLM_TORCH_PROFILER_DIR=/mnt/traces/。OpenAI 服务也需要在设置了VLLM_TORCH_PROFILER_DIR环境变量的情况下启动
docker run --runtime nvidia --gpus all \-v /data1/data_vllm:/data \-p 8001:8000 \-e VLLM_TORCH_PROFILER_DIR=/data/mnt/traces/ \--name qwen_llm_3 \--ipc=host \swr.cn-east-3.myhuaweicloud.com/kubesre/docker.io/vllm/vllm-openai \--model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 \--max-model-len 102400 -
使用benchmarks/benchmark_serving.py脚本进行性能测试,输出测试数据集请求情况,以及内存跟踪日志:
/usr/bin/python3 vllm/benchmarks/benchmark_serving.py --backend vllm --model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 --dataset ShareGPT_V3_unfiltered_cleaned_split.json --profile--dataset ShareGPT_V3_unfiltered_cleaned_split.json:这个参数指定了用于测试的数据集 --profile:启用性能分析。意味着在运行测试时会收集性能相关的数据,如 GPU 和内存使用情况以及处理请求所需的时间。 -
上传跟踪日志到 https://ui.perfetto.dev/ 可以进行内存占用可视化分析
案例
案例描述
本案例将分析 --enable-chunked-prefill 的启用/禁用以及 --max-num-batched-tokens 参数的调整对性能的影响情况。
参数描述请参考官方文档:https://docs.vllm.ai/en/stable/models/performance.html#chunked-prefill
测试数据集
线上拉取:https://github.com/vllm-project/vllm/blob/main/benchmarks/README.md
原始数据
〇轮测试(enable-64)
- 启动参数
docker run --runtime nvidia --gpus all \-v /data1/data_vllm:/data \-p 8001:8000 \-e VLLM_TORCH_PROFILER_DIR=/data/mnt/traces/ \--name qwen_llm_3 \--ipc=host \swr.cn-east-3.myhuaweicloud.com/kubesre/docker.io/vllm/vllm-openai \--model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 \--max-model-len 102000 \--max-num-batched-tokens 64 \--max-num-seqs 64python3 vllm/benchmarks/benchmark_serving.py --backend vllm --model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 --dataset ShareGPT_V3_unfiltered_cleaned_split.json --profile
- 测试结果
Starting profiler...
Traffic request rate: inf
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [07:38<00:00, 1.63s/it]Stopping profiler...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [07:38<00:00, 2.18it/s]
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 458.11
Total input tokens: 217393
Total generated tokens: 198783
Request throughput (req/s): 2.18
Output token throughput (tok/s): 433.92
Total Token throughput (tok/s): 908.47
---------------Time to First Token----------------
Mean TTFT (ms): 220088.62
Median TTFT (ms): 221079.64
P99 TTFT (ms): 435865.23
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 67.91
Median TPOT (ms): 68.32
P99 TPOT (ms): 72.16
---------------Inter-token Latency----------------
Mean ITL (ms): 68.05
Median ITL (ms): 68.24
P99 ITL (ms): 72.45
==================================================
一轮测试(enable-128)
- 启动参数
docker run --runtime nvidia --gpus all \-v /data1/data_vllm:/data \-p 8001:8000 \-e VLLM_TORCH_PROFILER_DIR=/data/mnt/traces/ \--name qwen_llm_3 \--ipc=host \swr.cn-east-3.myhuaweicloud.com/kubesre/docker.io/vllm/vllm-openai \--model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 \--max-model-len 102000 \--max-num-batched-tokens 128 \--max-num-seqs 128python3 vllm/benchmarks/benchmark_serving.py --backend vllm --model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 --dataset ShareGPT_V3_unfiltered_cleaned_split.json --profile
- 测试结果
Starting profiler...
Traffic request rate: inf
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [06:47<00:00, 1.66it/s]Stopping profiler...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [06:47<00:00, 2.46it/s]
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 407.00
Total input tokens: 217393
Total generated tokens: 198440
Request throughput (req/s): 2.46
Output token throughput (tok/s): 487.56
Total Token throughput (tok/s): 1021.69
---------------Time to First Token----------------
Mean TTFT (ms): 189093.46
Median TTFT (ms): 186896.79
P99 TTFT (ms): 377978.23
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 119.23
Median TPOT (ms): 121.42
P99 TPOT (ms): 133.46
---------------Inter-token Latency----------------
Mean ITL (ms): 118.04
Median ITL (ms): 120.48
P99 ITL (ms): 127.46
==================================================
二轮测试(enable-256)
- 启动参数
docker run --runtime nvidia --gpus all \-v /data1/data_vllm:/data \-p 8001:8000 \-e VLLM_TORCH_PROFILER_DIR=/data/mnt/traces/ \--name qwen_llm_3 \--ipc=host \swr.cn-east-3.myhuaweicloud.com/kubesre/docker.io/vllm/vllm-openai \--model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 \--max-model-len 102000 \--max-num-batched-tokens 256python3 vllm/benchmarks/benchmark_serving.py --backend vllm --model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 --dataset ShareGPT_V3_unfiltered_cleaned_split.json --profile
- 测试结果
Starting profiler...
Traffic request rate: inf
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [06:30<00:00, 1.54it/s]Stopping profiler...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [06:30<00:00, 2.56it/s]
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 390.70
Total input tokens: 217393
Total generated tokens: 198786
Request throughput (req/s): 2.56
Output token throughput (tok/s): 508.80
Total Token throughput (tok/s): 1065.22
---------------Time to First Token----------------
Mean TTFT (ms): 165589.63
Median TTFT (ms): 163038.00
P99 TTFT (ms): 349869.23
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 222.05
Median TPOT (ms): 230.34
P99 TPOT (ms): 253.39
---------------Inter-token Latency----------------
Mean ITL (ms): 216.90
Median ITL (ms): 225.01
P99 ITL (ms): 454.54
==================================================
三轮测试(enable-512)
- 启动参数
docker run --runtime nvidia --gpus all \-v /data1/data_vllm:/data \-p 8001:8000 \-e VLLM_TORCH_PROFILER_DIR=/data/mnt/traces/ \--name qwen_llm_3 \--ipc=host \swr.cn-east-3.myhuaweicloud.com/kubesre/docker.io/vllm/vllm-openai \--model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 \--max-model-len 102000 \--max-num-batched-tokens 512python3 vllm/benchmarks/benchmark_serving.py --backend vllm --model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 --dataset ShareGPT_V3_unfiltered_cleaned_split.json --profile
- 测试结果
Starting profiler...
Traffic request rate: inf
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [06:33<00:00, 1.20it/s]Stopping profiler...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [06:33<00:00, 2.54it/s]
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 393.35
Total input tokens: 217393
Total generated tokens: 198794
Request throughput (req/s): 2.54
Output token throughput (tok/s): 505.39
Total Token throughput (tok/s): 1058.05
---------------Time to First Token----------------
Mean TTFT (ms): 145934.18
Median TTFT (ms): 130854.88
P99 TTFT (ms): 331526.83
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 413.37
Median TPOT (ms): 435.94
P99 TPOT (ms): 485.53
---------------Inter-token Latency----------------
Mean ITL (ms): 387.35
Median ITL (ms): 437.46
P99 ITL (ms): 712.21
==================================================
四轮测试(enable-2048)
- 启动参数
docker run --runtime nvidia --gpus all \-v /data1/data_vllm:/data \-p 8001:8000 \-e VLLM_TORCH_PROFILER_DIR=/data/mnt/traces/ \--name qwen_llm_3 \--ipc=host \swr.cn-east-3.myhuaweicloud.com/kubesre/docker.io/vllm/vllm-openai \--model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 \--max-model-len 102000 \--max-num-batched-tokens 2048python3 vllm/benchmarks/benchmark_serving.py --backend vllm --model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 --dataset ShareGPT_V3_unfiltered_cleaned_split.json --profile
- 测试结果
Starting profiler...
Traffic request rate: inf
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [06:44<00:00, 1.52it/s]Stopping profiler...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [06:44<00:00, 2.47it/s]
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 404.65
Total input tokens: 217393
Total generated tokens: 198641
Request throughput (req/s): 2.47
Output token throughput (tok/s): 490.90
Total Token throughput (tok/s): 1028.13
---------------Time to First Token----------------
Mean TTFT (ms): 145587.94
Median TTFT (ms): 136750.66
P99 TTFT (ms): 333788.49
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 546.50
Median TPOT (ms): 481.48
P99 TPOT (ms): 1553.99
---------------Inter-token Latency----------------
Mean ITL (ms): 440.14
Median ITL (ms): 293.70
P99 ITL (ms): 1557.57
==================================================
五轮测试(enable-4096)
- 启动参数
docker run --runtime nvidia --gpus all \-v /data1/data_vllm:/data \-p 8001:8000 \-e VLLM_TORCH_PROFILER_DIR=/data/mnt/traces/ \--name qwen_llm_3 \--ipc=host \swr.cn-east-3.myhuaweicloud.com/kubesre/docker.io/vllm/vllm-openai \--model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 \--max-model-len 100928 \--max-num-batched-tokens 4096python3 vllm/benchmarks/benchmark_serving.py --backend vllm --model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 --dataset ShareGPT_V3_unfiltered_cleaned_split.json --profile
- 测试结果
Starting profiler...
Traffic request rate: inf
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [06:43<00:00, 1.17it/s]Stopping profiler...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [06:43<00:00, 2.48it/s]
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 403.73
Total input tokens: 217393
Total generated tokens: 198567
Request throughput (req/s): 2.48
Output token throughput (tok/s): 491.83
Total Token throughput (tok/s): 1030.30
---------------Time to First Token----------------
Mean TTFT (ms): 145208.34
Median TTFT (ms): 135880.49
P99 TTFT (ms): 333073.43
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 576.98
Median TPOT (ms): 480.20
P99 TPOT (ms): 3010.28
---------------Inter-token Latency----------------
Mean ITL (ms): 440.17
Median ITL (ms): 291.82
P99 ITL (ms): 2020.04
==================================================
六轮测试(enable-8192)
- 启动参数
docker run --runtime nvidia --gpus all \-v /data1/data_vllm:/data \-p 8001:8000 \-e VLLM_TORCH_PROFILER_DIR=/data/mnt/traces/ \--name qwen_llm_3 \--ipc=host \swr.cn-east-3.myhuaweicloud.com/kubesre/docker.io/vllm/vllm-openai \--model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 \--max-model-len 98832 \--max-num-batched-tokens 8192python3 vllm/benchmarks/benchmark_serving.py --backend vllm --model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 --dataset ShareGPT_V3_unfiltered_cleaned_split.json --profile
- 测试结果
Starting profiler...
Traffic request rate: inf
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [06:43<00:00, 1.58it/s]Stopping profiler...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [06:43<00:00, 2.48it/s]
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 403.80
Total input tokens: 217393
Total generated tokens: 198695
Request throughput (req/s): 2.48
Output token throughput (tok/s): 492.07
Total Token throughput (tok/s): 1030.44
---------------Time to First Token----------------
Mean TTFT (ms): 145191.92
Median TTFT (ms): 137176.88
P99 TTFT (ms): 333630.23
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 590.15
Median TPOT (ms): 482.05
P99 TPOT (ms): 3091.14
---------------Inter-token Latency----------------
Mean ITL (ms): 439.71
Median ITL (ms): 290.74
P99 ITL (ms): 1798.01
==================================================
在启用 chunked-prefill 的情况下,max-num-batched-tokens 越小,TTFT 越长,ITL 越短;max-num-batched-tokens 越大,TTFT 越短,ITL 越长。
七轮测试(disable-256)
- 启动参数
docker run --runtime nvidia --gpus all \-v /data1/data_vllm:/data \-p 8001:8000 \-e VLLM_TORCH_PROFILER_DIR=/data/mnt/traces/ \--name qwen_llm_3 \--ipc=host \swr.cn-east-3.myhuaweicloud.com/kubesre/docker.io/vllm/vllm-openai \--model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 \--max-model-len 256 \--max-num-batched-tokens 256 \--enable-chunked-prefill falsepython3 vllm/benchmarks/benchmark_serving.py --backend vllm --model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 --dataset ShareGPT_V3_unfiltered_cleaned_split.json --profile
- 测试结果
Starting profiler...
Traffic request rate: inf
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▌| 998/1000 [00:48<00:00, 15.69it/s]Stopping profiler...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [00:48<00:00, 20.63it/s]
============ Serving Benchmark Result ============
Successful requests: 296
Benchmark duration (s): 48.48
Total input tokens: 14909
Total generated tokens: 29120
Request throughput (req/s): 6.11
Output token throughput (tok/s): 600.72
Total Token throughput (tok/s): 908.27
---------------Time to First Token----------------
Mean TTFT (ms): 8354.34
Median TTFT (ms): 7792.90
P99 TTFT (ms): 18643.59
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 409.28
Median TPOT (ms): 272.91
P99 TPOT (ms): 1815.86
---------------Inter-token Latency----------------
Mean ITL (ms): 246.95
Median ITL (ms): 175.46
P99 ITL (ms): 580.31
==================================================
八轮测试(disable-512)
- 启动参数
docker run --runtime nvidia --gpus all \-v /data1/data_vllm:/data \-p 8001:8000 \-e VLLM_TORCH_PROFILER_DIR=/data/mnt/traces/ \--name qwen_llm_3 \--ipc=host \swr.cn-east-3.myhuaweicloud.com/kubesre/docker.io/vllm/vllm-openai \--model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 \--max-model-len 512 \--max-num-batched-tokens 512 \--enable-chunked-prefill falsepython3 vllm/benchmarks/benchmark_serving.py --backend vllm --model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 --dataset ShareGPT_V3_unfiltered_cleaned_split.json --profile
- 测试结果
Starting profiler...
Traffic request rate: inf
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [03:14<00:00, 1.15it/s]Stopping profiler...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [03:14<00:00, 5.15it/s]
============ Serving Benchmark Result ============
Successful requests: 700
Benchmark duration (s): 194.36
Total input tokens: 82224
Total generated tokens: 108536
Request throughput (req/s): 3.60
Output token throughput (tok/s): 558.42
Total Token throughput (tok/s): 981.47
---------------Time to First Token----------------
Mean TTFT (ms): 59907.26
Median TTFT (ms): 43205.72
P99 TTFT (ms): 149116.64
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 527.19
Median TPOT (ms): 401.10
P99 TPOT (ms): 2689.25
---------------Inter-token Latency----------------
Mean ITL (ms): 372.15
Median ITL (ms): 290.96
P99 ITL (ms): 987.35
==================================================
九轮测试(disable-2048)
- 启动参数
docker run --runtime nvidia --gpus all \-v /data1/data_vllm:/data \-p 8001:8000 \-e VLLM_TORCH_PROFILER_DIR=/data/mnt/traces/ \--name qwen_llm_3 \--ipc=host \swr.cn-east-3.myhuaweicloud.com/kubesre/docker.io/vllm/vllm-openai \--model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 \--max-model-len 2048 \--max-num-batched-tokens 2048 \--enable-chunked-prefill falsepython3 vllm/benchmarks/benchmark_serving.py --backend vllm --model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 --dataset ShareGPT_V3_unfiltered_cleaned_split.json --profile
- 测试结果
Starting profiler...
Traffic request rate: inf
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [06:43<00:00, 2.38it/s]Stopping profiler...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [06:43<00:00, 2.48it/s]
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 403.04
Total input tokens: 217393
Total generated tokens: 198690
Request throughput (req/s): 2.48
Output token throughput (tok/s): 492.98
Total Token throughput (tok/s): 1032.36
---------------Time to First Token----------------
Mean TTFT (ms): 142571.62
Median TTFT (ms): 135323.01
P99 TTFT (ms): 333148.28
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 668.80
Median TPOT (ms): 472.08
P99 TPOT (ms): 5647.73
---------------Inter-token Latency----------------
Mean ITL (ms): 446.03
Median ITL (ms): 305.97
P99 ITL (ms): 1420.74
==================================================
十轮测试(disable-4096)
- 启动参数
docker run --runtime nvidia --gpus all \-v /data1/data_vllm:/data \-p 8001:8000 \-e VLLM_TORCH_PROFILER_DIR=/data/mnt/traces/ \--name qwen_llm_3 \--ipc=host \swr.cn-east-3.myhuaweicloud.com/kubesre/docker.io/vllm/vllm-openai \--model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 \--max-model-len 4096 \--max-num-batched-tokens 4096 \--enable-chunked-prefill falsepython3 vllm/benchmarks/benchmark_serving.py --backend vllm --model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 --dataset ShareGPT_V3_unfiltered_cleaned_split.json --profile
- 测试结果
Starting profiler...
Traffic request rate: inf
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [06:44<00:00, 1.62it/s]Stopping profiler...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [06:44<00:00, 2.47it/s]
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 404.60
Total input tokens: 217393
Total generated tokens: 198856
Request throughput (req/s): 2.47
Output token throughput (tok/s): 491.48
Total Token throughput (tok/s): 1028.78
---------------Time to First Token----------------
Mean TTFT (ms): 145568.89
Median TTFT (ms): 138366.82
P99 TTFT (ms): 333544.04
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 612.43
Median TPOT (ms): 478.76
P99 TPOT (ms): 3506.11
---------------Inter-token Latency----------------
Mean ITL (ms): 444.17
Median ITL (ms): 305.46
P99 ITL (ms): 1451.10
==================================================
十一轮测试(disable-8192)
- 启动参数
docker run --runtime nvidia --gpus all \-v /data1/data_vllm:/data \-p 8001:8000 \-e VLLM_TORCH_PROFILER_DIR=/data/mnt/traces/ \--name qwen_llm_3 \--ipc=host \swr.cn-east-3.myhuaweicloud.com/kubesre/docker.io/vllm/vllm-openai \--model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 \--max-model-len 8192 \--max-num-batched-tokens 8192 \--enable-chunked-prefill falsepython3 vllm/benchmarks/benchmark_serving.py --backend vllm --model /data/Qwen2.5-72B-Instruct-GPTQ-Int4 --dataset ShareGPT_V3_unfiltered_cleaned_split.json --profile
- 测试结果
Starting profiler...
Traffic request rate: inf
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [06:44<00:00, 1.20it/s]Stopping profiler...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [06:44<00:00, 2.47it/s]
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 404.37
Total input tokens: 217393
Total generated tokens: 198400
Request throughput (req/s): 2.47
Output token throughput (tok/s): 490.64
Total Token throughput (tok/s): 1028.26
---------------Time to First Token----------------
Mean TTFT (ms): 145157.15
Median TTFT (ms): 138322.92
P99 TTFT (ms): 331883.14
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 609.64
Median TPOT (ms): 477.62
P99 TPOT (ms): 3823.35
---------------Inter-token Latency----------------
Mean ITL (ms): 443.97
Median ITL (ms): 303.46
P99 ITL (ms): 1575.09
==================================================
在不启用 chunked-prefill 的情况下,七八轮显示部分失败了,失败原因是超过上下文限制
数据可视化
数据汇总说明
说明1:横轴命名规则为 [序号]-[–enable-chunked-prefill]-[–max-num-batched-tokens],其中序号便于排序,例如:0-enable-64 表示第 0 轮测试,启用 chunked-prefill,max-num-batched-tokens 设置为 64
说明2:以下数据分析均基于本次测试数据集,场景更多类似于日常对话,本次的调优分析并不适合直播数据分析场景
说明3:第七、八轮数据存在因上下文长度超出最大设置长度导致请求失败的情况,数据失真,不在以下仪表板呈现
总览-耗时&吞吐量

这里包含了整个测试集的总耗时,输出 token 吞吐量,总(输出+输入) token 吞吐量
除了开启 --enable-chunked-prefill 且 --max-num-batched-tokens 设置较小时会影响总耗时,其他情况几乎无差别,–max-num-batched-tokens 设置越小,触发 chunked-prefill 情况越多,prefill 耗时大于 decode 阶段带来的耗时收益,导致总耗时变长
TTFT(Time To First Token)

该指标表示的是第一个 token 生成时间,也即 prefill 阶段的总耗时
- 启用 --enable-chunked-prefill
- –max-num-batched-tokens < 512 时,值越大,prefill 耗时越长
- –max-num-batched-tokens >= 512 之后,prefill 耗时相差不大,应该和测试数据集有关系,长文本的请求较少,触发chunked-prefill 的序列就少
- 不启用 --enable-chunked-prefill
- 设置的 --max-num-batched-tokens <= 512 时,数值越小失败请求越多,失败原因是上下文长度超过设置的最大上下文长度(折线图未体现,看原始数据)
- 设置的 --max-num-batched-tokens >= 2048 时,prefill 耗时几乎一致
TPOT(Time per Output Token)

该指标反映的是 decode 阶段输出每个 token 的时间,它衡量的是模型生成 token 的整体速度,不考虑 token 生成的顺序
- 启用 --enable-chunked-prefill
- 可以看到这个指标基本上和 TTFT 相反,–max-num-batched-tokens 越短,就越快将序列送去 decode,耗时就越短
ITL(Inter-token Latency)

该指标反映的是 decode 阶段 token 连续输出的耗时,它专注于衡量模型生成 token 的流式特性,即一个 token 生成后,下一个 Token 生成前的等待时间。
- 都是 decode 阶段,它和 TPOT 走势是一致的
结论
- 首先声明,测试数据集对测试情况影响会比较大,该测试集为官方提供的 1000 例无长文本(上下文基本在 512内)的测试集,生产调优需要根据场景进行重新分析
- –enable-chunked-prefill 如果开启,–max-num-batched-tokens 的大小设置会影响总耗时和吞吐量
- 如果设置的过小,比如 --max-num-batched-tokens < 256 时,该值越小耗时越长
- 如果设置 --max-num-batched-tokens >= 256 时,耗时和吞吐量
几乎无影响
- 相比总耗时和吞吐量,–enable-chunked-prefill 如果开启,–max-num-batched-tokens 的大小设置
对 prefill 和 decode 两阶段耗时影响较大- –max-num-batched-tokens设置越大 prefill 阶段耗时越短,decode 阶段耗时越长;相反值越小,decode 阶段耗时越短,prefill 阶段耗时越长
- 但 --max-num-batched-tokens 超过一定值时(本测试集超过 2048 时),两者几乎无波动
- –enable-chunked-prefill 如果未开启,请求上下文长度会受限于 --max-num-batched-tokens 的设置,如果值设置的较小,则上下文大于该值的请求将会请求失败
- 测试过程中其他结论
- –max-num-batched-tokens 设置的值需要大于模型上下文长度–max-model-len
- –max-num-batched-tokens 需要大于 batched 的序列(请求)数量–max-num-seqs
- –max-num-batched-tokens 的设置还会受到机器可用显存(乘以 --gpu-memory-utilization)限制,因为 KV-Cache 大概需要占用的最大显存大小公式如下:
KV_cache_size = 2 * n_layers * n_heads * seq_length * d_head * precision * batch_size这个公式是用来估算 Transformer 模型中 KV 缓存大小的。下面是公式中每个参数的详细解释:2:这个系数是因为每个注意力头都有两个张量需要被缓存:键(Key)和值(Value)张量。所以,对于每个头,我们都需要存储两个张量的内存。 n_layers:模型中注意力层的总数。在 Transformer 模型中,每个编码器或解码器块通常包含一个自注意力层,所以这个数字通常等于模型的块数。 n_heads:每个注意力层中注意力头的数量。在多头自注意力(Multi-Head Attention)机制中,模型会将注意力机制分割成多个“头”,每个头学习序列的不同部分。 seq_length:序列的最大长度。这是模型在单次推理中可以处理的输入序列的最大长度,包括提示(prompt)和生成的补全部分(completion)。 d_head:每个注意力头的隐藏维度。这是每个头中键和值张量的维度大小。 precision:数据的精度,它决定了每个参数需要多少字节来存储。常见的精度包括: - FP32(单精度浮点数):4字节/参数 - FP16(半精度浮点数):2字节/参数 - INT8(8位整数):1字节/参数 batch_size:批处理大小,即模型一次推理中同时处理的序列数量。 - 以上涉及到各参数描述
- –max-model-len:默认无值,会取模型配置文件里的最大上下文配置
- –enable-chunked-prefill:默认不开启,当 --max-model-len > 30k 时,自动开启
- –max-num-batched-tokens:默认值 512
- –max-num-seqs:默认值 256
- –gpu-memory-utilization:默认 0.9;这个参数指定了模型在启动时应该预分配多少百分比的 GPU 内存。增加这个值可以提供更多的内存给模型的 KV 缓存(关键值缓存),有助于提高模型处理大型输入或批量请求的能力。
相关文章:
vLLM 推理引擎性能分析基准测试
文章目录 分析步骤案例案例描述测试数据集 原始数据〇轮测试(enable-64)一轮测试(enable-128)二轮测试(enable-256)三轮测试(enable-512)四轮测试(enable-2048࿰…...

图像增强论文精读笔记-Kindling the Darkness: A Practical Low-light Image Enhancer(KinD)
1. 论文基本信息 论文标题:Kindling the Darkness: A Practical Low-light Image Enhancer 作者:Yonghua Zhang等 发表时间和期刊:2019;ACM MM 论文链接:https://arxiv.org/abs/1905.04161 2. 研究背景和动机 现有…...

HALCON数据结构之字符串
1.1 String字符串的基本操作 *将数字转换为字符串或修改字符串 *tuple_string (T, Format, String) //HALCON语句 *String: T $ Format //赋值操作*Format string 由以下四个部分组成: *<flags><field width>.<precision><conversion 字符&g…...

string模拟优化和vector使用
1.简单介绍编码 utf_8变长编码,常用英文字母使用1个字节,对于其它语言可能2到14,大部分编码是utf_8,char_16是编码为utf_16, char_32是编码为utf_32, wchar_t是宽字符的, utf_16是大小为俩个字节&a…...

Go-知识依赖GOPATH
Go-知识依赖GOPATH 1. 介绍2. GOROOT 是什么3. GOPATH 是什么4. 依赖查找5. GOPATH 的缺点1. 介绍 早期Go语言单纯地使用GOPATH管理依赖,但是GOPATH不方便管理依赖的多个版本,后来增加了vendor,允许把项目依赖 连同项目源码一同管理。Go 1.11 引入了全新的依赖管理工具 Go …...

PyTorch 中 reshape 函数用法示例
PyTorch 中 reshape 函数用法示例 在 PyTorch 中,reshape 函数用于改变张量的形状,而不改变其中的数据。下面是一些关于 reshape 函数的常见用法示例。 基本语法 torch.reshape(input, shape) # input: 要重塑的张量。 # shape: 目标形状࿰…...

安全光幕的工作原理及应用场景
安全光幕是一种利用光电传感技术来检测和响应危险情况的先进设备。其工作原理基于红外线传感器,通过发射红外光束并接收反射或透射光束来形成一道无形的屏障。以下是对安全光幕工作原理和应用场景的介绍: 工作原理 发射器与接收器:安全光幕通…...

《深度学习》OpenCV LBPH算法人脸识别 原理及案例解析
目录 一、LBPH算法 1、概念 2、实现步骤 3、方法 1)步骤1 • 缩放 • 旋转和平移 2)步骤2 二、案例实现 1、完整代码 1)图像内容: 2)运行结果: 一、LBPH算法 1、概念 在OpenCV中,L…...

数据结构之顺序表——动态顺序表(C语言版)
静态顺序表我们已经实现完毕了,下来我们实现一下动态顺序表 静态链接:数据结构之顺序表——动态顺序表(C语言版) 首先来了解一下两个顺序表的差别 一、内存管理的灵活性 动态分配与释放:动态顺序表能够在运行时根据需要动态地分配和释放内存…...

Python 网络爬虫入门与实战
目录 1 引言 2 网络爬虫基础知识 2.1 什么是网络爬虫 2.2 爬虫的工作原理 2.3 爬虫的应用场景 3 Python 爬虫环境搭建 3.1 安装 Python 3.2 安装必要的库 4 使用 Requests 库进行基本爬虫 4.1 发送 GET 请求 4.2 发送 POST 请求 4.3 处理响应 5 使用 BeautifulSoup…...

成都睿明智科技有限公司电商服务可靠不?
在这个短视频风起云涌的时代,抖音不仅成为了人们娱乐消遣的首选平台,更是众多商家竞相追逐的电商新蓝海。成都睿明智科技有限公司,作为抖音电商服务领域的佼佼者,正以其独到的洞察力和专业的服务,助力无数品牌在这片沃…...

fmql之Linux Uart
正点原子第48章。 串口收发测试 正点原子教程 RS232和RS485的串口收发测试是一样的。 // 设置串口波特率为115200 stty -F /dev/ttyPS1 ispeed 115200 ospeed 115200 cs8// 发送字符串 echo "www.openedv.com" >/dev/ttyPS1// 接收数据 cat /dev/ttyPS1 fmql测…...

【火山引擎】调用火山大模型的方法 | SDK安装 | 配置 | 客户端初始化 | 设置
豆包 (Doubao) 是字节跳动研发的大规模预训练语言模型。 目录 1 安装 2 配置访问凭证 3 客户端初始化 4 设置地域和访问域名 5 设置超时/重试次数 1 安装 通过pip安装PYTHON SDK。 pip install volcengine-python-sdk[ark] 2 配置访问凭证 获取 API Key 访问凭证具体步…...
前端实现下载功能汇总(下载二进制流文件、数组下载成csv、将十六进制下载成pcap、将文件下载成zip)
前言:汇总一下做过的下载功能,持续补充中 一、将后端传过来的二进制流文件下载(需要提取headers里面的文件名) const { herders,data }res; // 创建下载链接元素 const link document.createElement("a");// 创建 Bl…...

iLogtail 开源两周年:UC 工程师分享日志查询服务建设实践案例
作者:UC 浏览器后端工程师,梁若羽 传统 ELK 方案 众所周知,ELK 中的 E 指的是 ElasticSearch,L 指的是 Logstash,K 指的是 Kibana。Logstash 是功能强大的数据处理管道,提供了复杂的数据转换、过滤和丰富…...

【MySQL】入门篇—基本数据类型:NULL值的概念
在关系数据库中,NULL值是一个特殊的标记,表示缺失或未知的值。 NULL并不等同于零(0)或空字符串(),它表示一个字段没有任何值。 这一概念在数据库设计和数据管理中至关重要,因为它影…...

Java设计模式10 - 观察者模式
观察者模式 观察者模式也叫作发布-订阅模式,也就是事件监听机制。观察者模式定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象,这个主题对象在状态上发生变化时,会通知所有观察者对象,使他们能够自…...
LabVIEW示波器通信及应用
基于LabVIEW平台开发的罗德与施瓦茨示波器通信与应用系统实现了示波器的远程控制及波形数据的实时分析,通过TCP/IP或USB接口与计算机通信,利用VISA技术进行指令传输,从而实现高效的数据采集与处理功能。 项目背景 随着现代电子测试需求的日益…...
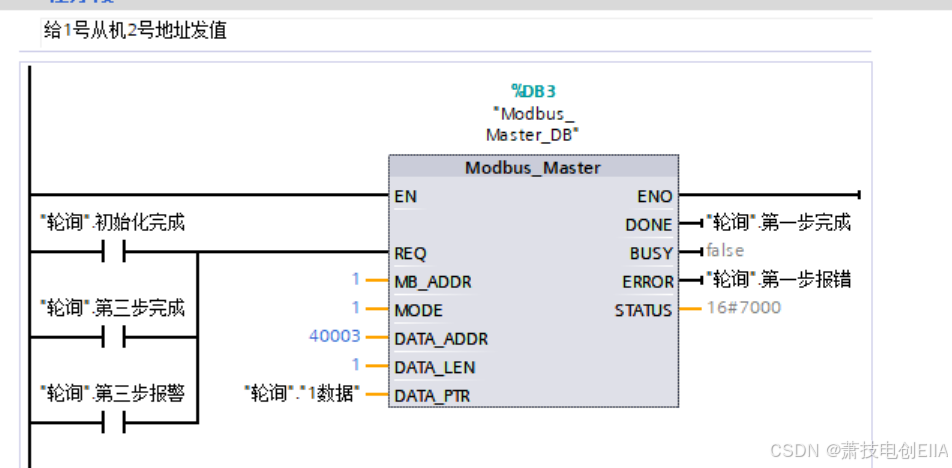
西门子PLC中Modbus通讯DATA_ADDR通讯起始地址设置以及RTU轮询程序设计。
1 DATA_ADDR通讯起始地址设置 因为西门子PLC保持型寄存器的是40001~49999和400001~465536, 那么什么时候用40001什么时候用400001呢? 当需要的地址超过49999的话就用400001。 比如从站的某个地址是#16 48D518645 4000118645超过了49999 这边因为前…...
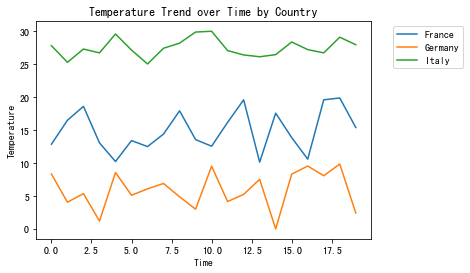
趋势(一)利用python绘制折线图
趋势(一)利用python绘制折线图 折线图( Line Chart)简介 折线图用于在连续间隔或时间跨度上显示定量数值,最常用来显示趋势和关系(与其他折线组合起来)。折线图既能直观地显示数量随时间的变化…...

App无辜躺枪?手把手教你搞定腾讯手机管家误报导致的应用商店下架
当合规应用遭遇误报下架:开发者系统性应对指南运动健康类应用被标记为金融诈骗软件?社交工具因"病毒风险"被各大商店紧急下架?这类看似荒谬的误报事件,正在成为中小开发团队的"无妄之灾"。某知名运动App开发团…...

古戏台构件声学特性的时域有限差分方法【附模型】
✨ 长期致力于时域有限差分法、窑洞、戏台、八字墙、共形技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)曲面共形网格快速生成算法: …...

极致精简,功能强大的PDF编辑工具
这是一款功能全面的PDF编辑工具 你只需要导入一份PDF格式文件 就可以快速的对它进行插入 批注编辑保护转换等各种操作 而且无需登录 也可以直接使用 在插入选项中可以进行插入文字图片 页面页眉页脚页码文档背景水印视频音频等 在批注选项中可以管理批注隐藏批注 高亮显示 文本…...

如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南
如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI UAss…...

警惕!AI正在悄悄重构全球攻防格局
警惕!AI 正在悄悄重构全球攻防格局 热点聚焦 AI重构网络安全:全球巨头加速布局 2026年5月,全球网络安全领域迎来重大变革,AI技术正在重塑攻防格局。OpenAI发布专为网络安全防御打造的集成化AI平台Daybreak,将安全防…...

关于psthon问题
我想问问各位 我python可以查到 但是我的bit文件查不到python怎么回事...

AI学习 - 大模型基础入门
AI学习 - 大模型基础入门 从零开始:Ollama 安装 → 本地模型运行 → Python 代码接入 → 理解核心概念 摘要 本文记录了在 Windows 上使用 Ollama 部署本地大模型、并通过 Python 代码接入调用的完整过程。内容涵盖:Ollama 安装与模型拉取、大模型基础概…...

打造XBEE封装BLE112蓝牙模块:硬件设计、射频布局与调试全攻略
1. 项目概述:为什么我们需要一个“XBEE格式”的蓝牙模块?在嵌入式开发和物联网项目中,无线通信模块的选择往往决定了项目的成败。对于很多工程师和创客来说,Silicon Labs(芯科科技)的BLE112/113模块是蓝牙4…...

【大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型?】
大模型聚合平台深度评测:阿里云百炼 vs 腾讯云 ADP,企业如何选型? 随着大模型技术的快速发展,越来越多的企业开始将 AI 能力融入到业务流程中。然而,面对市场上众多的大模型产品,企业往往面临着 “选择困难…...

Go开发者必备:circuitbreaker API全解析与最佳实践指南 [特殊字符]
Go开发者必备:circuitbreaker API全解析与最佳实践指南 🚀 【免费下载链接】circuitbreaker Circuit Breakers in Go 项目地址: https://gitcode.com/gh_mirrors/circ/circuitbreaker 作为一名Go开发者,你是否经常遇到远程服务调用失败…...