吴恩达深度学习笔记:卷积神经网络(Foundations of Convolutional Neural Networks)3.7-3.8
目录
- 第四门课 卷积神经网络(Convolutional Neural Networks)
- 第三周 目标检测(Object detection)
- 3.7 非极大值抑制(Non-max suppression)
- 3.8 Anchor Boxes
第四门课 卷积神经网络(Convolutional Neural Networks)
第三周 目标检测(Object detection)
3.7 非极大值抑制(Non-max suppression)
到目前为止你们学到的对象检测中的一个问题是,你的算法可能对同一个对象做出多次检测,所以算法不是对某个对象检测出一次,而是检测出多次。非极大值抑制这个方法可以确保你的算法对每个对象只检测一次,我们讲一个例子。

假设你需要在这张图片里检测行人和汽车,你可能会在上面放个 19×19 网格,理论上这辆车只有一个中点,所以它应该只被分配到一个格子里,左边的车子也只有一个中点,所以理论上应该只有一个格子做出有车的预测。

实践中当你运行对象分类和定位算法时,对于每个格子都运行一次,所以这个格子(编号 1)可能会认为这辆车中点应该在格子内部,这几个格子(编号 2、3)也会这么认为。对于左边的车子也一样,所以不仅仅是这个格子,如果这是你们以前见过的图像,不仅这个格(编号 4)子会认为它里面有车,也许这个格子(编号 5)和这个格子(编号 6)也会,也许其他格子也会这么认为,觉得它们格子内有车。
我们分步介绍一下非极大抑制是怎么起效的,因为你要在 361 个格子上都运行一次图像检测和定位算法,那么可能很多格子都会举手说我的𝑝𝑐,我这个格子里有车的概率很高,而不是 361 个格子中仅有两个格子会报告它们检测出一个对象。所以当你运行算法的时候,最后可能会对同一个对象做出多次检测,所以非极大值抑制做的就是清理这些检测结果。这样一辆车只检测一次,而不是每辆车都触发多次检测。

所以具体上,这个算法做的是,首先看看每次报告每个检测结果相关的概率𝑝𝑐,在本周的编程练习中有更多细节,实际上是𝑝𝑐乘以𝑐1、𝑐2或𝑐3。现在我们就说,这个𝑝𝑐检测概率,首先看概率最大的那个,这个例子(右边车辆)中是 0.9,然后就说这是最可靠的检测,所以我们就用高亮标记,就说我这里找到了一辆车。这么做之后,非极大值抑制就会逐一审视剩下的矩形,所有和这个最大的边框有很高交并比,高度重叠的其他边界框,那么这些输出就会被抑制。所以这两个矩形𝑝𝑐分别是 0.6 和 0.7,这两个矩形和淡蓝色矩形重叠程度很高,所以会被抑制,变暗,表示它们被抑制了。

接下来,逐一审视剩下的矩形,找出概率最高,𝑝𝑐最高的一个,在这种情况下是 0.8,我们就认为这里检测出一辆车(左边车辆),然后非极大值抑制算法就会去掉其他 loU 值很高的矩形。所以现在每个矩形都会被高亮显示或者变暗,如果你直接抛弃变暗的矩形,那就剩下高亮显示的那些,这就是最后得到的两个预测结果。
所以这就是非极大值抑制,非最大值意味着你只输出概率最大的分类结果,但抑制很接近,但不是最大的其他预测结果,所以这方法叫做非极大值抑制。
我们来看看算法的细节,首先这个 19×19 网格上执行一下算法,你会得到 19×19×8 的输出尺寸。不过对于这个例子来说,我们简化一下,就说你只做汽车检测,我们就去掉𝑐1、𝑐2和𝑐3,然后假设这条线对于 19×19 的每一个输出,对于 361 个格子的每个输出,你会得到这样的输出预测,就是格子中有对象的概率(𝑝𝑐),然后是边界框参数(𝑏𝑥、𝑏𝑦、𝑏ℎ和𝑏𝑤)。如果你只检测一种对象,那么就没有𝑐1、𝑐2和𝑐3这些预测分量。多个对象处于同一个格子中的情况,我会放到编程练习中,你们可以在本周末之前做做。

现在要实现非极大值抑制,你可以做的第一件事是,去掉所有边界框,我们就将所有的预测值,所有的边界框𝑝𝑐小于或等于某个阈值,比如𝑝𝑐 ≤ 0.6的边界框去掉。
我们就这样说,除非算法认为这里存在对象的概率至少有 0.6,否则就抛弃,所以这就抛弃了所有概率比较低的输出边界框。所以思路是对于这 361 个位置,你输出一个边界框,还有那个最好边界框所对应的概率,所以我们只是抛弃所有低概率的边界框。

接下来剩下的边界框,没有抛弃没有处理过的,你就一直选择概率𝑝𝑐最高的边界框,然后把它输出成预测结果,这个过程就是上一张幻灯片,取一个边界框,让它高亮显示,这样你就可以确定输出做出有一辆车的预测。

接下来去掉所有剩下的边界框,任何没有达到输出标准的边界框,之前没有抛弃的边界框,把这些和输出边界框有高重叠面积和上一步输出边界框有很高交并比的边界框全部抛弃。所以 while 循环的第二步是上一张幻灯片变暗的那些边界框,和高亮标记的边界重叠面积很高的那些边界框抛弃掉。在还有剩下边界框的时候,一直这么做,把没处理的都处理完,直到每个边界框都判断过了,它们有的作为输出结果,剩下的会被抛弃,它们和输出结果重叠面积太高,和输出结果交并比太高,和你刚刚输出这里存在对象结果的重叠程度过高。
在这张幻灯片中,我只介绍了算法检测单个对象的情况,如果你尝试同时检测三个对象,比如说行人、汽车、摩托,那么输出向量就会有三个额外的分量。事实证明,正确的做法是独立进行三次非极大值抑制,对每个输出类别都做一次,但这个细节就留给本周的编程练习吧,其中你可以自己尝试实现,我们可以自己试试在多个对象类别检测时做非极大值抑制。
这就是非极大值抑制,如果你能实现我们说过的对象检测算法,你其实可以得到相当不错的结果。但结束我们对 YOLO 算法的介绍之前,最后我还有一个细节想给大家分享,可以进一步改善算法效果,就是 anchor box 的思路,我们下一个视频再介绍
3.8 Anchor Boxes
到目前为止,对象检测中存在的一个问题是每个格子只能检测出一个对象,如果你想让一个格子检测出多个对象,你可以这么做,就是使用 anchor box 这个概念,我们从一个例子开始讲吧。

假设你有这样一张图片,对于这个例子,我们继续使用 3×3 网格,注意行人的中点和汽车的中点几乎在同一个地方,两者都落入到同一个格子中。所以对于那个格子,如果 𝑦 输出这个向量𝑦 = [ p c b x b y b h b w c 1 c 2 c 3 ] \begin{bmatrix} p_c\\ b_x \\ b_y \\ b_h \\ b_w \\ c_1 \\ c_2 \\ c_3 \end{bmatrix} pcbxbybhbwc1c2c3 ,你可以检测这三个类别,行人、汽车和摩托车,它将无法输出检测结果,所以我必须从两个检测结果中选一个。

而 anchor box 的思路是,这样子,预先定义两个不同形状的 anchor box,或者 anchor box 形状,你要做的是把预测结果和这两个 anchor box 关联起来。一般来说,你可能会用更多的 anchor box,可能要 5 个甚至更多,但对于这个视频,我们就用两个 anchor box,这样介绍起来简单一些。

你要做的是定义类别标签,用的向量不再是上面这个: [ p c b x b y b h b w c 1 c 2 c 3 ] T \begin{bmatrix}p_c&b_x&b_y&b_h&b_w&c_1&c_2&c_3 \end{bmatrix}^T [pcbxbybhbwc1c2c3]T
而是重复两次: [ p c b x b y b h b w c 1 c 2 c 3 p c b x b y b h b w c 1 c 2 c 3 ] T \begin{bmatrix}p_c&b_x&b_y&b_h&b_w&c_1&c_2&c_3&p_c&b_x&b_y&b_h&b_w&c_1&c_2&c_3\end{bmatrix}^T [pcbxbybhbwc1c2c3pcbxbybhbwc1c2c3]T
前面的𝑝𝑐, 𝑏𝑥, 𝑏𝑦, 𝑏ℎ, 𝑏𝑤, 𝑐1, 𝑐2, 𝑐3(绿色方框标记的参数)是和 anchor box 1 关联的 8 个参数,后面的 8 个参数(橙色方框标记的元素)是和 anchor box 2 相关联。因为行人的形状更类似于 anchor box 1 的形状,而不是 anchor box 2 的形状,所以你可以用这 8 个数值(前
8 个参数),这么编码𝑝𝑐 = 1,是的,代表有个行人,用𝑏𝑥, 𝑏𝑦, 𝑏ℎ和𝑏𝑤来编码包住行人的边界框,然后用𝑐1, 𝑐2, 𝑐3(𝑐1 = 1, 𝑐2 = 0, 𝑐3 = 0)来说明这个对象是个行人。然后是车子,因为车子的边界框比起 anchor box 1 更像 anchor box 2 的形状,你就可以这么编码,这里第二个对象是汽车,然后有这样的边界框等等,这里所有参数都和检测汽车相关(𝑝𝑐 = 1, 𝑏𝑥, 𝑏𝑦, 𝑏ℎ, 𝑏𝑤, 𝑐1 = 0, 𝑐2 = 1, 𝑐3 = 0)。

总结一下,用 anchor box 之前,你做的是这个,对于训练集图像中的每个对象,都根据那个对象中点位置分配到对应的格子中,所以输出𝑦就是 3×3×8,因为是 3×3 网格,对于每个网格位置,我们有输出向量,包含𝑝𝑐,然后边界框参数𝑏𝑥, 𝑏𝑦, 𝑏ℎ和𝑏𝑤,然后𝑐1, 𝑐2, 𝑐3。
现在用到 anchor box 这个概念,是这么做的。现在每个对象都和之前一样分配到同一个格子中,分配到对象中点所在的格子中,以及分配到和对象形状交并比最高的 anchor box中。所以这里有两个 anchor box,你就取这个对象,如果你的对象形状是这样的(编号 1,红色框),你就看看这两个 anchor box,anchor box 1 形状是这样(编号 2,紫色框),anchor box 2 形状是这样(编号 3,紫色框),然后你观察哪一个 anchor box 和实际边界框(编号1,红色框)的交并比更高,不管选的是哪一个,这个对象不只分配到一个格子,而是分配到一对,即(grid cell,anchor box)对,这就是对象在目标标签中的编码方式。所以现在输出 𝑦 就是 3×3×16,上一张幻灯片中你们看到 𝑦 现在是 16 维的,或者你也可以看成是3×3×2×8,因为现在这里有 2 个 anchor box,而 𝑦 是 8 维的。𝑦 维度是 8,因为我们有 3 个对象类别,如果你有更多对象,那么𝑦 的维度会更高。

所以我们来看一个具体的例子,对于这个格子(编号 2),我们定义一下𝑦,:
[ p c b x b y b h b w c 1 c 2 c 3 p c b x b y b h b w c 1 c 2 c 3 ] T \begin{bmatrix}p_c&b_x&b_y&b_h&b_w&c_1&c_2&c_3&p_c&b_x&b_y&b_h&b_w&c_1&c_2&c_3\end{bmatrix}^T [pcbxbybhbwc1c2c3pcbxbybhbwc1c2c3]T
所以行人更类似于 anchor box 1 的形状,所以对于行人来说,我们将她分配到向量的上半部分。是的,这里存在一个对象,即𝑝𝑐 = 1,有一个边界框包住行人,如果行人是类别 1,那么 𝑐1 = 1, 𝑐2 = 0, 𝑐3 = 0(编号 1 所示的橙色参数)。车子的形状更像 anchor box 2,所以这个向量剩下的部分是 𝑝𝑐 = 1,然后和车相关的边界框,然后𝑐1 = 0, 𝑐2 = 1, 𝑐3 = 0(编号 1所示的绿色参数)。所以这就是对应中下格子的标签 𝑦,这个箭头指向的格子(编号 2 所示)。
现在其中一个格子有车,没有行人,如果它里面只有一辆车,那么假设车子的边界框形状是这样,更像 anchor box 2,如果这里只有一辆车,行人走开了,那么 anchor box 2 分量还是一样的,要记住这是向量对应 anchor box 2 的分量和 anchor box 1 对应的向量分量,你要填的就是,里面没有任何对象,所以 𝑝𝑐 = 0,然后剩下的就是 don’t care-s(即?)(编号 3所示)。
现在还有一些额外的细节,如果你有两个 anchor box,但在同一个格子中有三个对象,这种情况算法处理不好,你希望这种情况不会发生,但如果真的发生了,这个算法并没有很好的处理办法,对于这种情况,我们就引入一些打破僵局的默认手段。还有这种情况,两个对象都分配到一个格子中,而且它们的 anchor box 形状也一样,这是算法处理不好的另一种情况,你需要引入一些打破僵局的默认手段,专门处理这种情况,希望你的数据集里不会出现这种情况,其实出现的情况不多,所以对性能的影响应该不会很大。
这就是 anchor box 的概念,我们建立 anchor box 这个概念,是为了处理两个对象出现在同一个格子的情况,实践中这种情况很少发生,特别是如果你用的是 19×19 网格而不是3×3 的网格,两个对象中点处于 361 个格子中同一个格子的概率很低,确实会出现,但出现频率不高。也许设立 anchor box 的好处在于 anchor box 能让你的学习算法能够更有征对性,特别是如果你的数据集有一些很高很瘦的对象,比如说行人,还有像汽车这样很宽的对象,这样你的算法就能更有针对性的处理,这样有一些输出单元可以针对检测很宽很胖的对象,比如说车子,然后输出一些单元,可以针对检测很高很瘦的对象,比如说行人。
最后,你应该怎么选择 anchor box 呢?人们一般手工指定 anchor box 形状,你可以选择 5 到 10 个 anchor box 形状,覆盖到多种不同的形状,可以涵盖你想要检测的对象的各种形状。还有一个更高级的版本,我就简单说一句,你们如果接触过一些机器学习,可能知道后期 YOLO 论文中有更好的做法,就是所谓的 k-平均算法,可以将两类对象形状聚类,如果我们用它来选择一组 anchor box,选择最具有代表性的一组 anchor box,可以代表你试图检测的十几个对象类别,但这其实是自动选择 anchor box 的高级方法。如果你就人工选择一些形状,合理的考虑到所有对象的形状,你预计会检测的很高很瘦或者很宽很胖的对象,这应该也不难做。
所以这就是 anchor box,在下一个视频中,我们把学到的所有东西一起融入到 YOLO 算法中。
相关文章:
吴恩达深度学习笔记:卷积神经网络(Foundations of Convolutional Neural Networks)3.7-3.8
目录 第四门课 卷积神经网络(Convolutional Neural Networks)第三周 目标检测(Object detection)3.7 非极大值抑制(Non-max suppression)3.8 Anchor Boxes 第四门课 卷积神经网络(Convolutional…...

【Linux】最基本的字符设备驱动
前面我们介绍到怎么编译出内核模块.ko文件,然后还加载了这个驱动模块。但是,那个驱动代码还不完善,驱动写好后怎么在应用层使用也没有介绍。 字符设备抽象 Linux内核中将字符设备抽象成一个具体的数据结构(struct cdevÿ…...
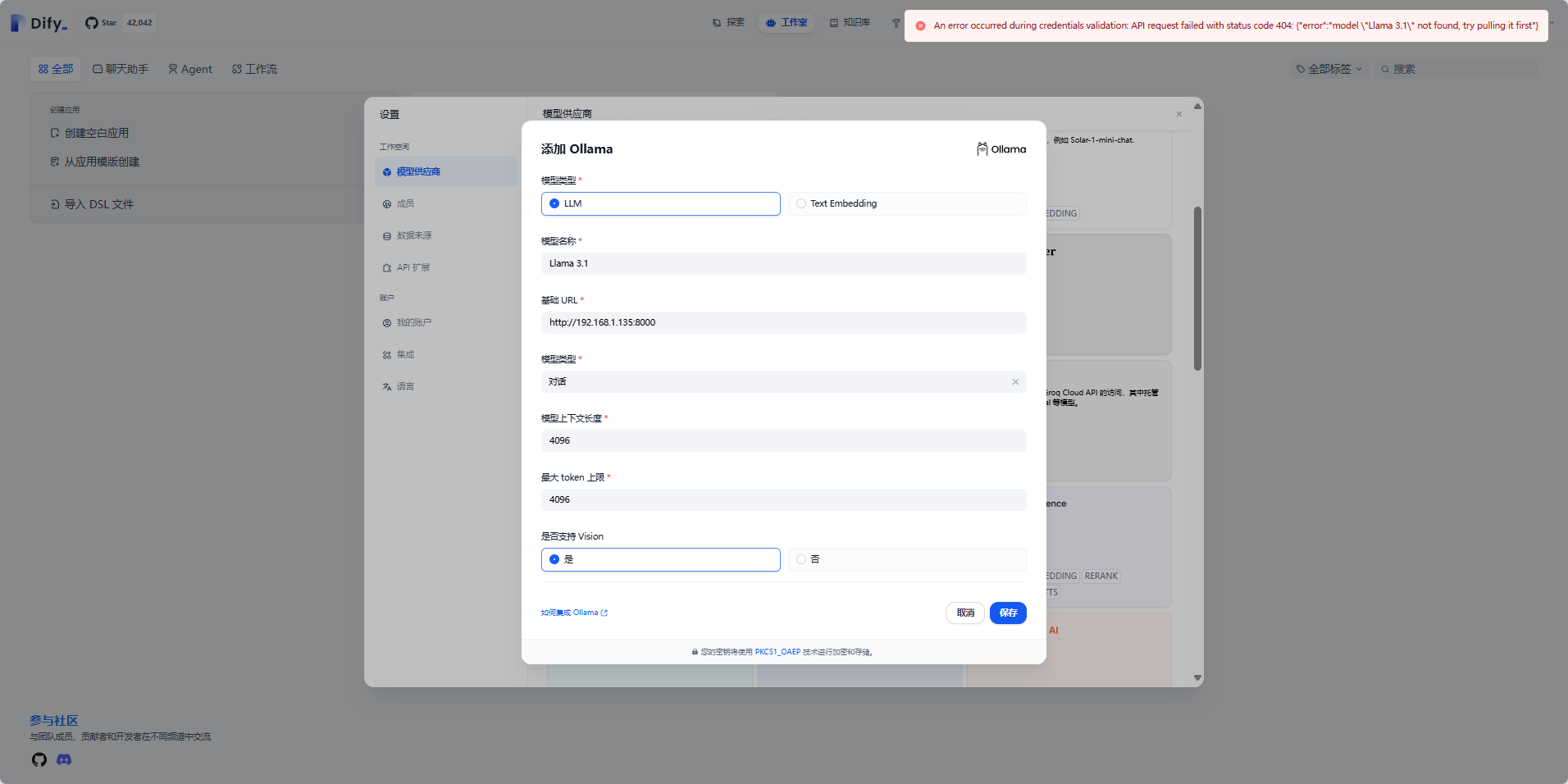
利用 Llama 3.1模型 + Dify开源LLM应用开发平台,在你的Windows环境中搭建一套AI工作流
文章目录 1. 什么是Ollama?2. 什么是Dify?3. 下载Ollama4. 安装Ollama5. Ollama Model library模型库6. 本地部署Llama 3.1模型7. 安装Docker Desktop8. 使用Docker-Compose部署Dify9. 注册Dify账号10. 集成本地部署的 Llama 3.1模型11. 集成智谱AI大模型…...

Docker常用命令分享二
docker的用户组管理过程: 1、sudo : 可以让普通用户临时获得root用户的权限,来新建docker用户组 2、普通用户并没有使用sudo的权限 3、先要让root用户把testing用户加入到sudoers的授权文件中 4、sudoers的文件居然是只读的,先解决这个问…...

【一步步开发AI运动小程序】二十、AI运动小程序如何适配相机全屏模式?
引言 受小程序camera组件预览和抽帧图像不一致的特性影响,一直未全功能支持全屏模式,详见本系列文件第四节小程序如何抽帧;随着插件在云上赛事、健身锻炼、AI体测、AR互动场景的深入应用,各开发者迫切的希望能在全屏模式下应用&am…...

[Java基础] 运算符
[Java基础] 基本数据类型 [Java基础] Java HashMap 的数据结构和底层原理 目录 算术运算符 比较运算符 逻辑运算符 位运算符 赋值运算符 其他运算符 常见面试题 Java语言支持哪些类型的运算符? 请解释逻辑运算符&&和&的区别? 请解释条件运…...

[001-02-018].第05节:数据类型及类型转换
我的后端学习大纲 我的Java学习大纲 1、数据类型介绍: 1.0.计算机存储单位: 1.1.基本数据类型介绍: a.整型:byte、short、int、long 1.整型包括:byte、short、int、long,可如下图方式类比记忆࿱…...

Netty基础
Netty基础 一级目录I/O请求基础知识Netty如何实现自己的I/O模型 网络框架的选型 Netty整体架构Netty逻辑处理架构网络通信层事件调度层服务编排层 组件关系梳理Netty源码结构 netty是目前最流行的一款高性能java网络编程框架,广泛使用于中间件、直播、社交、游戏等领…...

602,好友申请二:谁有最多的好友
好友申请二:谁有最多的好友 实现 with tmp as (selectrequester_id idfrom RequestAcceptedunion allselectaccepter_id idfrom RequestAccepted )selectid,count(*) num from tmp group by id order by num desc limit 1;...
)
【Matlab算法MATLAB实现的音频信号时频分析与可视化(附MATLAB完整代码)
MATLAB实现的音频信号时频分析与可视化 前言正文:时频分析实现原理代码实现代码运行结果图及说明结果图:结果说明:总结前言 音频信号的时频分析是信号处理领域中的一个重要研究方向。它允许我们同时观察信号在时间和频率域的特性,为音频处理、语音识别、音乐分析等应用提供…...

界面耻辱纪念堂--可视元素03
更多的迹象表明,关于在程序里使用新的动态界面元素,微软的态度是不确定的,其中一个是仅仅需要对比一下Office97 里的“Coolbars”和“标准工具条”。Coolbar 按钮直到用户指针通过的时候才成为按钮(否则是平的)。 工具…...

国产龙芯处理器选择迅为2K1000开发板有资料
硬件配置国产龙芯处理器,双核64位系统,板载2G DDR3内存,流畅运行Busybox、Buildroot、Loognix、QT5.12 系统!接口全板载4路USB HOST、2路千兆以太网、2路UART、2路CAN总线、Mini PCIE、SATA固态盘接口、4G接口、GPS接口WIF1、蓝牙、Mini HDMI…...
)
MySQL 命令(持续更新)
将 MySQL 命令结果输出到文件中 通过 k8s MySQL pod 里的客户端连接到 MySQL 服务器 kubectl exec mysql-pod -- mysql -hx.x.x.x -uroot -proot -e SELECT * FROM db.table; > result.txt通过 k8s MySQL pod 的客户端连接 MySQL 服务器,直接进入到 MySQL 客户端…...

Linux下Docker方式Jenkins安装和配置
一、下载&安装 Jenkins官方Docker仓库地址:https://hub.docker.com/r/jenkins/jenkins 从官网上可以看到,当前最新的稳定版本是 jenkins/jenkins:lts-jdk17。建议下在新的,后面依赖下不来 所以,我们这里,执行doc…...

低代码框架参考
企业管理信息系统作为一类重要的应用软件系统,具有自己的特点,主要有两个方面: 1. 系统规模大,目前市场上常见的ERP系统一般都有几千个页面。 2. 页面逻辑相似性强。经过比较可以发现,大部分页面具有类似的功能&…...
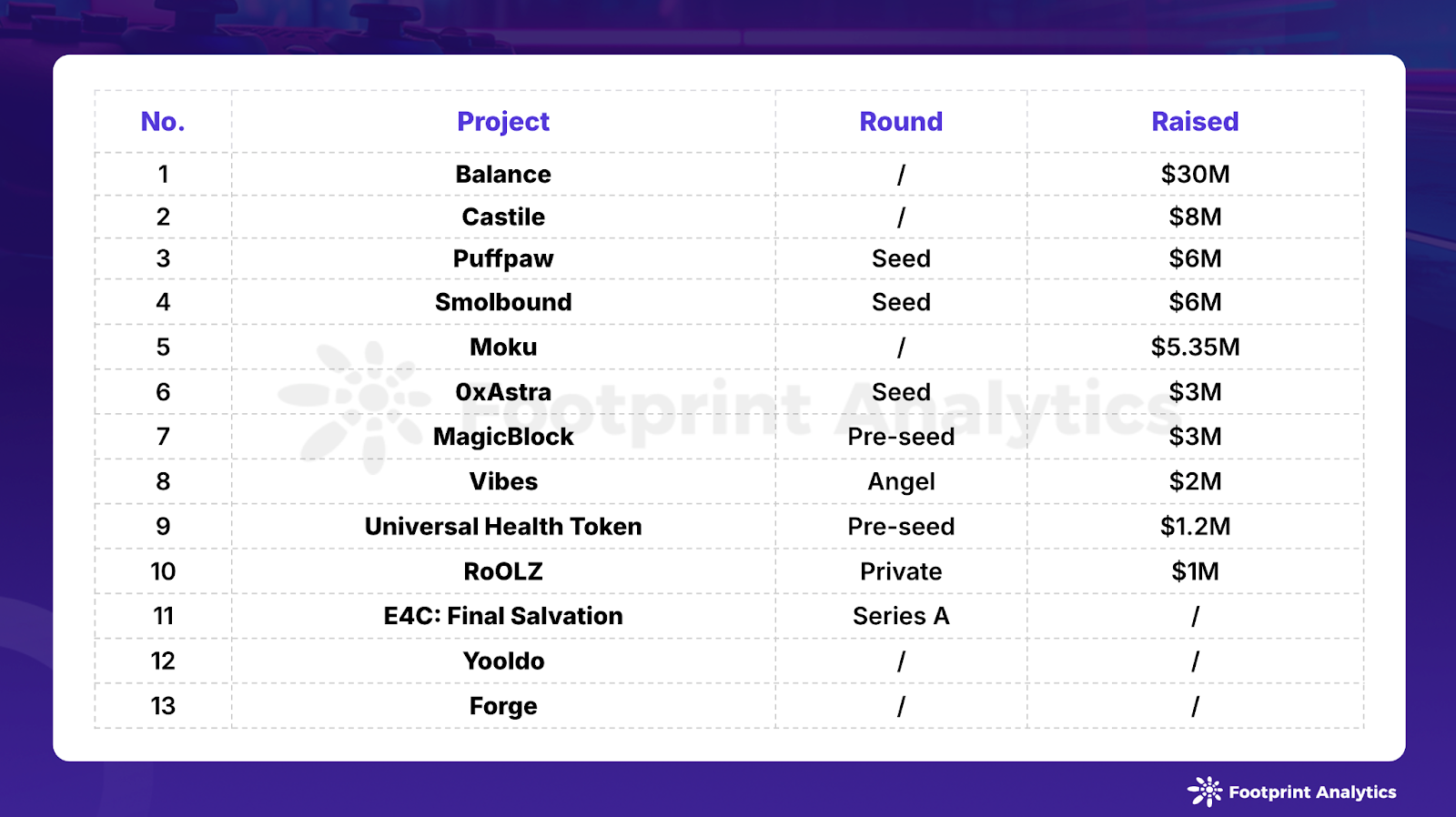
2024 年 9 月区块链游戏研报:行业回暖,Telegram 游戏引发热潮
作者:Stella L (stellafootprint.network) 数据来源:Footprint Analytics Games Research Page 9 月份,区块链游戏代币的市场总值增长了 29.2%,达到 232 亿美元,日活跃用户(DAU)数量上升了 1…...
)
python爬虫登录校验之滑块验证、图形验证码(OCR)
在爬虫过程中,验证码和滑块验证是常见的反爬措施。针对这些挑战,通常采用OCR识别图形验证码和模拟滑块拖动来处理滑块验证。以下是如何处理这两种类型验证的详细方法。 1. 图形验证码(OCR) a. 使用 tesserocr 和 Pillow 处理图形…...
Python程序结构)
(一)Python程序结构
1、Python写模块 使用缩进分层来写模块; 2、缩进规范 最好使用同一种缩进方式,统一使用tab或者空格键; 3、换行符:\n; print("窗前明月光\n疑似地上霜") 4、续行符号:\; 注意1…...

二叉树——相同的树
还是应用递归的思想,将这个问题拆分为三个部分,第一:当两棵树均为空树,或者访问到最后的子树时均为空树时,则返回true。第二:当两棵树中其中一棵树为空树,另一棵树不是空树,证明两棵…...

探秘 1688 商品详情接口:高并发批量采集的实战攻略
在进行 1688 商品详情接口批量采集并考虑高并发使用时,你可以从以下几个方面着手: 一、技术选型 选择合适的编程语言和框架:例如 Python 的 Scrapy 框架或者 Java 的 Spring Boot 结合相关爬虫库等,这些工具可以帮助你高效地实现…...

LLM API安全攻防实战:从提示词注入到自动化测试方案
1. 项目概述:被忽视的LLM API安全前线最近在帮几个团队做上线前的安全审计,发现一个挺有意思的现象:大家对于传统API的鉴权、限流、SQL注入这些常规检查已经形成了肌肉记忆,但一旦涉及到LLM(大语言模型)的A…...

除了ulimit -c unlimited:深入理解Linux core dump机制与高级配置指南
深入Linux核心转储:从基础配置到生产环境实战指南当服务器上的关键应用突然崩溃时,系统管理员最需要的就是一份完整的"事故现场记录"。Linux的core dump机制正是为此而生,它能保存程序崩溃时的内存状态、寄存器值和调用堆栈&#x…...

高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析
高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析 【免费下载链接】srs-windows 项目地址: https://gitcode.com/gh_mirrors/sr/srs-windows 在Windows平台上构建专业级流媒体服务系统,需要综合考虑协议兼容性、性能优化和部署架…...

【2026最新】应对Turnitin查重:实测5大英文查降AI宝藏工具,一站式搞定初稿
现在的英文初稿,无论是期刊文章、SCI 还是普通的 Course Essay,基本都需要评估内容的原创度,进行文章 AI 率检测。很多伙伴以为纯手敲就能过,结果一查数据依然不尽如人意。 针对英文内容,咱们必须使用专门的英文检测和…...

3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行
3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or KernelSU (root so…...

Java网络编程基础分享
在学习 Java 的过程中,网络编程是非常重要的一环。无论是后端开发、分布式系统、即时通讯、文件传输,还是游戏服务、物联网设备,都离不开网络通信一、计算机网络基础1.1 什么是计算机网络把不同地理位置、具有独立功能的计算机,通…...

泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅
泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you cha…...
)
Midjourney模糊效果深度拆解(从--stylize到--sref的光学模拟原理揭秘)
更多请点击: https://codechina.net 第一章:Midjourney模糊效果的本质与视觉认知基础 Midjourney 中的模糊效果并非图像后处理意义上的高斯模糊(Gaussian Blur),而是由扩散模型在潜空间中对高频细节进行概率性抑制所…...

城通网盘直链解析终极指南:3分钟告别广告等待
城通网盘直链解析终极指南:3分钟告别广告等待 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 还在为城通网盘下载而烦恼吗?每次下载都要面对烦人的广告等待,还要输入…...

Linux 软链接和硬链接详解:ln 命令背后的 inode 原理
Linux 软链接和硬链接详解:ln 命令背后的 inode 原理 1. 前言 Linux 中经常会看到链接文件,例如: /bin -> /usr/bin python -> python3 current -> /opt/app/releases/v2Linux 链接主要有两种: 软链接:symbol…...