[自然语言处理]RNN
1 传统RNN模型与LSTM

import torch
import torch.nn as nntorch.manual_seed(6)# todo:基础RNN模型
def dem01():'''参数1:input_size 每个词的词向量维度(输入层神经元的个数)参数2:hidden_size 隐藏层神经元的个数参数3:hidden_layer 隐藏层的层数'''rnn = nn.RNN(5, 6, 1)'''参数1:sequence_length 每个样本的句子长度参数2:batch_size 每个批次的样本数量参数3:input_size 每个词的词向量维度(输入层神经元的个数)'''input = torch.randn(1, 3, 5)'''参数1:hidden_layer 隐藏层的层数参数2:batch_size 每个批次的样本数量参数3:hidden_size 隐藏层神经元的个数'''h0 = torch.randn(1, 3, 6)output, hn = rnn(input, h0)print(f'output {output}')print(f'hn {hn}')print(f'RNN模型 {rnn}')# todo:增加输入的sequence_length
def dem02():'''参数1:input_size 每个词的词向量维度(输入层神经元的个数)参数2:hidden_size 隐藏层神经元的个数参数3:hidden_layer 隐藏层的层数'''rnn = nn.RNN(5, 6, 1)'''参数1:sequence_length 每个样本的句子长度参数2:batch_size 每个批次的样本数量参数3:input_size 每个词的词向量维度(输入层神经元的个数)'''input = torch.randn(4, 3, 5)'''参数1:hidden_layer 隐藏层的层数参数2:batch_size 每个批次的样本数量参数3:hidden_size 隐藏层神经元的个数'''h0 = torch.randn(1, 3, 6)output, hn = rnn(input, h0)print(f'output {output}')print(f'hn {hn}')print(f'RNN模型 {rnn}')# todo:增加隐藏层的个数
def dem03():'''参数1:input_size 每个词的词向量维度(输入层神经元的个数)参数2:hidden_size 隐藏层神经元的个数参数3:hidden_layer 隐藏层的层数'''rnn = nn.RNN(5, 6, 2)'''参数1:sequence_length 每个样本的句子长度参数2:batch_size 每个批次的样本数量参数3:input_size 每个词的词向量维度(输入层神经元的个数)'''input = torch.randn(4, 3, 5)'''参数1:hidden_layer 隐藏层的层数参数2:batch_size 每个批次的样本数量参数3:hidden_size 隐藏层神经元的个数'''h0 = torch.randn(2, 3, 6)output, hn = rnn(input, h0)print(f'output {output}')print(f'hn {hn}')print(f'RNN模型 {rnn}')# todo:一个一个地向模型输入单词-全零初始化
def dem04_1():'''参数1:input_size 每个词的词向量维度(输入层神经元的个数)参数2:hidden_size 隐藏层神经元的个数参数3:hidden_layer 隐藏层的层数'''rnn = nn.RNN(5, 6, 1)'''参数1:sequence_length 每个样本的句子长度参数2:batch_size 每个批次的样本数量参数3:input_size 每个词的词向量维度(输入层神经元的个数)'''input = torch.randn(4, 1, 5)print(f'input {input}')'''参数1:hidden_layer 隐藏层的层数参数2:batch_size 每个批次的样本数量参数3:hidden_size 隐藏层神经元的个数'''# 每个样本一次性输入神经网络hn = torch.zeros(1, 1, 6)print(f'hn1 {hn}')output, hn = rnn(input, hn)print(f'output1 {output}')print(f'hn1 {hn}')print(f'RNN模型1 {rnn}')print('*' * 80)# 每个样本逐词送入神经网络hn = torch.zeros(1, 1, 6)print(f'hn2 {hn}')for i in range(4):tmp = input[i][0]print(f'tmp.shape {tmp.shape}')output, hn = rnn(tmp.unsqueeze(0).unsqueeze(0), hn)print(f'{i}-output {output}')print(f'{i}-hn {hn}')# todo:一个一个地向模型输入单词-全一初始化
def dem04_2():'''参数1:input_size 每个词的词向量维度(输入层神经元的个数)参数2:hidden_size 隐藏层神经元的个数参数3:hidden_layer 隐藏层的层数'''rnn = nn.RNN(5, 6, 1)'''参数1:sequence_length 每个样本的句子长度参数2:batch_size 每个批次的样本数量参数3:input_size 每个词的词向量维度(输入层神经元的个数)'''input = torch.randn(4, 1, 5)print(f'input {input}')'''参数1:hidden_layer 隐藏层的层数参数2:batch_size 每个批次的样本数量参数3:hidden_size 隐藏层神经元的个数'''# 每个样本一次性输入神经网络hn = torch.ones(1, 1, 6)print(f'hn1 {hn}')output, hn = rnn(input, hn)print(f'output1 {output}')print(f'hn1 {hn}')print(f'RNN模型1 {rnn}')print('*' * 80)# 每个样本逐词送入神经网络hn = torch.ones(1, 1, 6)print(f'hn2 {hn}')for i in range(4):tmp = input[i][0]print(f'tmp.shape {tmp.shape}')output, hn = rnn(tmp.unsqueeze(0).unsqueeze(0), hn)print(f'{i}-output {output}')print(f'{i}-hn {hn}')# todo:一个一个地向模型输入单词-随机初始化
def dem04_3():'''参数1:input_size 每个词的词向量维度(输入层神经元的个数)参数2:hidden_size 隐藏层神经元的个数参数3:hidden_layer 隐藏层的层数'''rnn = nn.RNN(5, 6, 1)'''参数1:sequence_length 每个样本的句子长度参数2:batch_size 每个批次的样本数量参数3:input_size 每个词的词向量维度(输入层神经元的个数)'''input = torch.randn(4, 1, 5)print(f'input {input}')'''参数1:hidden_layer 隐藏层的层数参数2:batch_size 每个批次的样本数量参数3:hidden_size 隐藏层神经元的个数'''# 每个样本一次性输入神经网络hn = torch.randn(1, 1, 6)print(f'hn1 {hn}')output, hn = rnn(input, hn)print(f'output1 {output}')print(f'hn1 {hn}')print(f'RNN模型1 {rnn}')print('*' * 80)# 每个样本逐词送入神经网络hn = torch.randn(1, 1, 6)print(f'hn2 {hn}')for i in range(4):tmp = input[i][0]print(f'tmp.shape {tmp.shape}')output, hn = rnn(tmp.unsqueeze(0).unsqueeze(0), hn)print(f'{i}-output {output}')print(f'{i}-hn {hn}')# todo:设置batch_first=True
def dem05():'''参数1:input_size 每个词的词向量维度(输入层神经元的个数)参数2:hidden_size 隐藏层神经元的个数参数3:hidden_layer 隐藏层的层数'''rnn = nn.RNN(5, 6, 1, batch_first=True)'''参数1:batch_size 每个批次的样本数量参数2:sequence_length 每个样本的句子长度参数3:input_size 每个词的词向量维度(输入层神经元的个数)'''input = torch.randn(3, 4, 5)'''参数1:hidden_layer 隐藏层的层数参数2:batch_size 每个批次的样本数量参数3:hidden_size 隐藏层神经元的个数'''h0 = torch.randn(1, 3, 6)output, hn = rnn(input, h0)print(f'output {output}')print(f'hn {hn}')print(f'RNN模型 {rnn}')# todo:基础LSTM模型
def dem06_1():'''参数1:input_size 每个词的词向量维度(输入层神经元的个数)参数2:hidden_size 隐藏层神经元的个数参数3:hidden_layer 隐藏层的层数'''rnn = nn.LSTM(5, 6, 2)'''参数1:batch_size 每个批次的样本数量参数2:sequence_length 每个样本的句子长度参数3:input_size 每个词的词向量维度(输入层神经元的个数)'''input = torch.randn(1, 3, 5)'''参数1:hidden_layer 隐藏层的层数参数2:batch_size 每个批次的样本数量参数3:hidden_size 隐藏层神经元的个数'''h0 = torch.randn(2, 3, 6)'''参数1:hidden_layer 隐藏层的层数参数2:batch_size 每个批次的样本数量参数3:hidden_size 隐藏层神经元的个数'''c0 = torch.randn(2, 3, 6)output, (hn, cn) = rnn(input, (h0, c0))print(f'output {output}')print(f'hn {hn}')print(f'cn {cn}')# todo:双向LSTM模型
def dem06_2():'''参数1:input_size 每个词的词向量维度(输入层神经元的个数)参数2:hidden_size 隐藏层神经元的个数参数3:hidden_layer 隐藏层的层数'''rnn = nn.LSTM(5, 6, 2,bidirectional=True)'''参数1:batch_size 每个批次的样本数量参数2:sequence_length 每个样本的句子长度参数3:input_size 每个词的词向量维度(输入层神经元的个数)'''input = torch.randn(1, 3, 5)'''参数1:hidden_layer 隐藏层的层数参数2:batch_size 每个批次的样本数量参数3:hidden_size 隐藏层神经元的个数'''h0 = torch.randn(4, 3, 6)'''参数1:hidden_layer 隐藏层的层数参数2:batch_size 每个批次的样本数量参数3:hidden_size 隐藏层神经元的个数'''c0 = torch.randn(4, 3, 6)output, (hn, cn) = rnn(input, (h0, c0))print(f'output {output}')print(f'hn {hn}')print(f'cn {cn}')if __name__ == '__main__':# dem01()# dem02()# dem03()# dem04_1()# dem04_2()# dem04_3()# dem05()# dem06_1()dem06_2()D:\nlplearning\nlpbase\python.exe D:\nlpcoding\rnncode.py
output tensor([[[ 0.0207, -0.1121, -0.0706, 0.1167, -0.3322, -0.0686],[ 0.1256, 0.1328, 0.2361, 0.2237, -0.0203, -0.2709],[-0.2668, -0.2721, -0.2168, 0.4734, 0.2420, 0.0349]]],grad_fn=<MkldnnRnnLayerBackward0>)
hn tensor([[[ 0.1501, -0.2106, 0.0213, 0.1309, 0.3074, -0.2038],[ 0.3639, -0.0394, -0.1912, 0.1282, 0.0369, -0.1094],[ 0.1217, -0.0517, 0.1884, -0.1100, -0.5018, -0.4512]],[[ 0.0207, -0.1121, -0.0706, 0.1167, -0.3322, -0.0686],[ 0.1256, 0.1328, 0.2361, 0.2237, -0.0203, -0.2709],[-0.2668, -0.2721, -0.2168, 0.4734, 0.2420, 0.0349]]],grad_fn=<StackBackward0>)
cn tensor([[[ 0.2791, -0.7362, 0.0501, 0.2612, 0.4655, -0.2338],[ 0.7902, -0.0920, -0.4955, 0.3865, 0.0868, -0.1612],[ 0.2312, -0.3736, 0.4033, -0.1386, -1.0151, -0.5971]],[[ 0.0441, -0.2279, -0.1483, 0.3397, -0.5597, -0.4339],[ 0.2154, 0.4119, 0.4723, 0.4731, -0.0284, -1.1095],[-0.5016, -0.5146, -0.4286, 1.5299, 0.5992, 0.1224]]],grad_fn=<StackBackward0>)Process finished with exit code 0
2 GRU
import torch
import torch.nn as nn# todo:基础GRU
def dem01():gru = nn.GRU(5, 6, 1)input = torch.randn(4, 3, 5)h0 = torch.randn(1, 3, 6)output, hn = gru(input, h0)print(f'output {output}')print(f'hn {hn}')if __name__ == '__main__':dem01()
相关文章:
[自然语言处理]RNN
1 传统RNN模型与LSTM import torch import torch.nn as nntorch.manual_seed(6)# todo:基础RNN模型 def dem01():参数1:input_size 每个词的词向量维度(输入层神经元的个数)参数2:hidden_size 隐藏层神经元的个数参数3:…...
MySQL(B站CodeWithMosh)——2024.10.11(14)
ZZZZZZ目的ZZZZZZ代码ZZZZZZ重点ZZZZZZ操作(非代码,需要自己手动) 8- CASE运算符The CASE Operator_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1UE41147KC?p62&vd_sourceeaeec77dfceb13d96cce76cc299fdd08 在sql_store中&am…...
Transformer的预训练模型
Transformer的预训练模型有很多,其中一些在自然语言处理(NLP)和计算机视觉等领域取得了巨大成功。以下是一些主要的Transformer预训练模型: 1. BERT (Bidirectional Encoder Representations from Transformers) 简介: BERT 是谷歌推出的双向Transformer模型,专注于编码器…...

手撕单例模式
在Go语言中实现单例模式,通常需要确保一个类只有一个实例,并且提供一个全局访问点。Go语言本身没有类的概念,但可以通过结构体和函数来模拟这种行为。下面是一个简单的手撕单例模式的实现示例: 懒汉式(延迟初始化&…...

UE4 材质学习笔记06(布料着色器/体积冰着色器)
一.布料着色器 要编写一个着色器首先是看一些参考图片,我们需要找出一些布料特有的特征,下面是一个棉织物,可以看到布料边缘的纤维可以捕捉光线使得边缘看起来更亮 下面是缎子和丝绸的图片,与棉织物有几乎相反的效果,…...

人工智能学习框架
人工智能学习框架是指用于开发和训练机器学习和深度学习模型的软件库和工具集。这些框架帮助开发者更高效地构建、训练和部署模型,加速人工智能应用的开发进程。 常见的人工智能学习框架 TensorFlow 由Google开发,是一个开源的深度学习框架,…...
)
GEE 教程:Landsat TOA数据计算地表温度(LST)
目录 简介 函数 expression(expression, map) Arguments: Returns: Image reduceRegion(reducer, geometry, scale, crs, crsTransform, bestEffort, maxPixels, tileScale) Arguments: Returns: Dictionary 代码 结果 简介 地表温度(Land Surface Temperature,LS…...

Web编程---配置Tomcat
文章目录 一、目的二、原理三、过程1. 解压“apache-tomcat-10.0.27-windows-x64.zip”文件到指定文件夹。2. 配置环境变量3.修改编码方式,防止 Tomcat 控制台出现乱码。4.启动 Tmocat5.打开浏览器,地址栏输入 http://localhost:8080 ,如果看…...
)
物联网5G模块WIFI模块调式记录(Pico)
调试环境 MCU:Pico1(无wifi版)5G模块:EC800K(iot专用4g卡)WIFI模块:ESP01s(Esp8266芯片)、DX-WF24开发环境:MacBook Pro Sonoma 14.5开发工具:Th…...

中国平安蝉联2024“金融业先锋30”第一名 获金融业ESG最高五星评级
2024年10月15日,中央广播电视总台正式对外发布《金融业ESG行动报告(2024)》(以下简称"《报告》"),并公布了"中国ESG上市公司金融业先锋30"榜单。中国平安凭借在绿色金融、普惠金融、养…...
[图解]题目解析:财务人员最有可能成为业务执行者的是
1 00:00:00,420 --> 00:00:04,760 接下来,是第3章自测题第1部分的第8题 2 00:00:05,090 --> 00:00:08,120 单选,针对以下研究对象 3 00:00:08,900 --> 00:00:11,530 财务人员最有可能成为业务执行者的是 4 00:00:12,800 --> 00:00:15,280…...

零基础学大模型——大模型技术学习过程梳理
“学习是一个从围观到宏观,从宏观到微观的一个过程” 学习大模型技术也有几个月的时间了,之前的学习一直是东一榔头,西一棒槌,这学一点那学一点,虽然弄的乱七八糟,但对大模型技术也算有了一个初步的认识。…...

匹配全国地址的正则表达式工具类
正则表达式,匹配全国五级地址工具类,可以直接放在项目中使用~ 1级:国 (可忽略不填) 2级:**省、**自治区、**直辖市、**特别行政区、(四个直辖市可忽略不填) 3级:**市、**…...

Notepad++ 使用技巧
notepad 高级“查找模式” 1)两个换行换一行 选中为 “扩展(\n, \r, \t, \0, \x…)” ,查找目标里面可以写上\r\n\r\n,替换为\r\n 2)移除空行 查找目标:\r\n\r\n,替换为…...

《语音识别芯片选型全攻略》
《语音识别芯片选型全攻略》 一、语音识别芯片性能评估(一)主控芯片性能评估(二)接口需求分析(三)可靠性评估(四)生产工艺考量(五)湿敏等级判断 二、语音识别…...

【MySQL】VARCHAR和CHAR的区别?
目录 区别存储方式最大长度存取效率 使用场景参考 在MySQL中,VARCHAR和CHAR是两种常用的字符串数据类型,它们各自有不同的特点和适用场景。下面我将和大家一起了解这两种数据类型的区别及使用场景。 区别 存储方式 CHAR(N):定长存储&#…...

SQL Server日期查询常用语句
一、以下是SQL 日期截取 & SQL Server日期比较日期查询常用语句 select CONVERT(varchar, getdate(), 120 ) 2004-09-12 11:06:08 select replace(replace(replace(CONVERT(varchar, getdate(), 120 ),-,), ,),:,) 20040912110608 select COUNVRT(varchar(12) , getdate…...
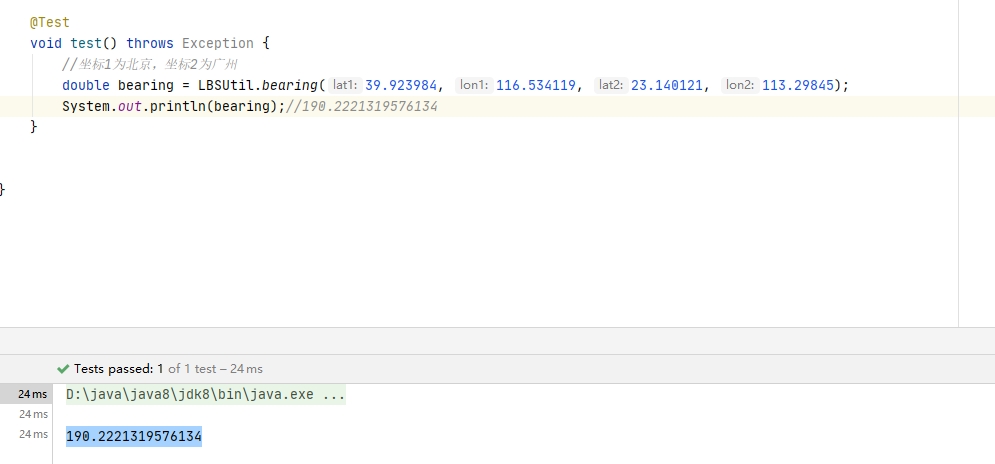
java地理方位角度计算
计算方位角度 从一个坐标到另一个坐标的方位角度. GIS地理 方位角,正北作为0度基线,顺时针旋转。 /*** GIS方位角度,正北为0度,顺时针旋转** param lat1 坐标1纬度* param lon1 坐标1经度* param lat2 坐标2纬度* param lon2 坐…...

RabbitMQ service is already present - only updating service parameters
Windows下卸载RabbitMQ之后,然后重新注册RabbitMQ服务的时候,报错以下信息: D:\software\rabbitmq-server-4.0.2\rabbitmq_server-4.0.2\sbin>D:\software\rabbitmq-server-4.0.2\rabbitmq_server-4.0.2\sbin\rabbitmq-service.bat install RabbitMQ service is already …...

贵州网站建设提升可见性的策略
贵州网站建设提升可见性的策略 在数字化时代,网站的可见性对企业的成功至关重要。在贵州,随着互联网的发展,越来越多的企业意识到网站建设的重要性。那么,如何有效提升网站的可见性呢?以下是几个关键策略。 **1. 优化…...
)
别再手动点菜单了!用这招让Cadence Virtuoso Schematic效率翻倍(附Net高亮快捷键配置)
电路设计效率革命:Cadence Virtuoso Schematic高阶快捷键配置指南 在集成电路设计的浩瀚宇宙中,Cadence Virtuoso如同设计师手中的光刻机,每一次精准操作都直接影响最终芯片的性能与可靠性。然而,当面对数百个晶体管组成的复杂模…...

从游戏引擎到仿真平台:手把手教你用AirSim+UE4搭建你的第一个无人机/自动驾驶仿真环境
从游戏引擎到仿真平台:构建AirSimUE4无人机与自动驾驶仿真环境实战指南当游戏引擎遇上机器人算法测试,会碰撞出怎样的火花?微软开源的AirSim项目将虚幻引擎(Unreal Engine)从游戏开发领域引入到自动驾驶和无人机研究的…...

2026数据治理平台选型:五款产品如何赋能数据中台建设?
一、引言:数据中台的成败,关键在治理在数字化浪潮的席卷下,“数据中台”已成为当代企业信息化架构中的核心战略组件。然而,一个悖论正困扰着大量企业:数据中台的基础设施搭建日趋完善,但真正将数据转化为业…...

JS中forEach与普通for
for就不用说了,最普通的循环函数forEach1. 只写 1 个参数只接收当前遍历元素let arr [10,20,30] arr.forEach(item > {console.log(item) // 依次 10、20、30 })2. 写 2 个参数依次接收元素值、下标索引let arr [10,20,30] arr.forEach((item, index) > {co…...

避坑指南:Unity动态加载模型时,TriLib插件材质丢失、缩放异常的5个常见问题解决
Unity动态加载模型避坑指南:TriLib插件材质丢失与缩放异常的深度解决方案当你在Unity项目中尝试使用TriLib插件动态加载外部模型时,是否遇到过这些令人抓狂的情况:模型加载后材质全部变成刺眼的粉红色,贴图神秘消失,或…...

基于ESP8266与RGBDigit的Wi-Fi网络时钟:硬件设计、物联网集成与DIY实践
1. 项目概述:一个能感知环境的网络时钟如果你和我一样,对复古又带点科技感的显示设备没有抵抗力,同时又是个喜欢动手折腾的极客,那么这个项目绝对能让你在工作室或家里多一个既实用又炫酷的玩意儿。我说的就是这款基于RGBDigit数码…...

深入解析NxDumpTool:Switch游戏文件系统提取的终极指南 [特殊字符]
深入解析NxDumpTool:Switch游戏文件系统提取的终极指南 🎮 【免费下载链接】nxdumptool Generates XCI/NSP/HFS0/ExeFS/RomFS/Certificate/Ticket dumps from Nintendo Switch gamecards and installed SD/eMMC titles. 项目地址: https://gitcode.com…...

NBT数据可视化编辑解决方案:NBTExplorer技术解析与应用指南
NBT数据可视化编辑解决方案:NBTExplorer技术解析与应用指南 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer NBTExplorer是一款面向Minecraft数据管理的…...
)
H3C VSR路由器实战:用QoS策略给不同VLAN用户打DSCP标签(附配置命令详解)
H3C VSR路由器QoS实战:基于VLAN的DSCP标记与流量调度指南 在企业网络环境中,不同业务对网络质量的需求差异显著。普通办公流量可以容忍轻微延迟,但视频会议需要稳定的低延迟保障,而访客上网则可能消耗大量带宽却无需优先保障。本文…...

ThingLinks-IoT:一站式物联网平台解决方案
ThingLinks-IoT 物联网平台 | 多协议接入物模型告警联动视频接入AI 助手 一体化方案 一个面向项目交付与企业生产场景的国产物联网中台——把"设备接入 → 数据处理 → 告警联动 → 业务集成"这条链路上的通用能力一次性做完做稳,让你只关心自己的业务。 …...