Whisper 音视频转写
Whisper 音视频转写 API 接口文档
api.py
import os
import shutil
import socket
import torch
import whisper
from moviepy.editor import VideoFileClip
import opencc
from fastapi import FastAPI, File, UploadFile, Form, HTTPException, Request
from fastapi.responses import JSONResponse
from typing import Optional
from fastapi.staticfiles import StaticFilesapp = FastAPI(title="Whisper 音视频转写 API",description="基于 OpenAI Whisper 模型的音视频转写服务,支持上传文件或使用服务器上的文件生成字幕。",version="1.0.0"
)# 挂载静态目录,用于提供文件下载
app.mount("/static", StaticFiles(directory="/media/ubuntu/SOFT/whisper_test"), name="static")# 支持的文件扩展名
ALLOWED_EXTENSIONS = {'mp3', 'wav', 'mp4', 'avi', 'mov'}
UPLOAD_DIR = "/media/ubuntu/SOFT/whisper_test/uploads"# 检查文件扩展名是否允许
def allowed_file(filename: str):return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS# 格式化时间戳为 SRT 格式
def format_timestamp(seconds: float) -> str:milliseconds = int(seconds * 1000)hours = milliseconds // (1000 * 60 * 60)minutes = (milliseconds // (1000 * 60)) % 60seconds = (milliseconds // 1000) % 60milliseconds = milliseconds % 1000return f"{hours:02}:{minutes:02}:{seconds:02},{milliseconds:03}"# 生成 SRT 文件内容
def generate_srt(transcription_segments) -> str:srt_content = ""converter = opencc.OpenCC('t2s') # 繁体转简体for i, segment in enumerate(transcription_segments):start_time = format_timestamp(segment['start']) # 获取开始时间戳end_time = format_timestamp(segment['end']) # 获取结束时间戳text = converter.convert(segment['text'].strip()) # 繁体转简体srt_content += f"{i+1}\n{start_time} --> {end_time}\n{text}\n\n"return srt_content# 处理音频文件并生成 SRT 文件,返回转录文本
def transcribe_audio_to_srt(audio_path: str, srt_path: str, model_name="tiny"):device = "cuda" if torch.cuda.is_available() else "cpu" # 判断是否使用 GPUmodel = whisper.load_model(model_name).to(device) # 加载模型result = model.transcribe(audio_path, language="zh") # 转录音频print("当前模型:",model_name,"转录内容:",result["text"],"\n")srt_content = generate_srt(result['segments']) # 生成 SRT 文件内容with open(srt_path, "w", encoding="utf-8") as srt_file:srt_file.write(srt_content) # 将内容写入 SRT 文件return result["text"] # 返回转录的文本内容# 从视频中提取音频
def extract_audio_from_video(video_path: str, audio_path: str):video_clip = VideoFileClip(video_path) # 读取视频文件audio_clip = video_clip.audio # 获取音频audio_clip.write_audiofile(audio_path, codec='libmp3lame', bitrate="192k") # 保存为 MP3audio_clip.close() # 关闭音频文件video_clip.close() # 关闭视频文件# 处理单个音频或视频文件,生成 SRT 文件,并保留相对目录结构
def process_file_with_structure(file_path: str, input_dir: str, output_dir: str, model_name="tiny"):# 生成相对路径,保持输入和输出目录结构一致rel_path = os.path.relpath(file_path, input_dir)output_srt_dir = os.path.join(output_dir, os.path.dirname(rel_path))os.makedirs(output_srt_dir, exist_ok=True) # 创建对应的输出目录srt_output_path = os.path.join(output_srt_dir, os.path.splitext(os.path.basename(file_path))[0] + ".srt") # 生成 SRT 文件路径if file_path.lower().endswith((".mp3", ".wav")): # 如果是音频文件text_content = transcribe_audio_to_srt(file_path, srt_output_path, model_name) # 直接处理音频并返回转录文本elif file_path.lower().endswith((".mp4", ".avi", ".mov")): # 如果是视频文件audio_path = os.path.join(output_srt_dir, os.path.splitext(os.path.basename(file_path))[0] + "_audio.mp3")extract_audio_from_video(file_path, audio_path) # 提取音频text_content = transcribe_audio_to_srt(audio_path, srt_output_path, model_name) # 处理提取的音频并返回转录文本os.remove(audio_path) # 删除临时音频文件return srt_output_path, text_content # 返回 SRT 文件路径和转录文本# 遍历目录并处理所有音视频文件,保持目录结构
def process_directory_with_structure(input_dir: str, output_dir: str, model_name="tiny"):srt_files = []for root, _, files in os.walk(input_dir):for file in files:if allowed_file(file):file_path = os.path.join(root, file)srt_output_path, text_content = process_file_with_structure(file_path, input_dir, output_dir, model_name)srt_files.append((srt_output_path, text_content))return srt_files# 获取局域网 IP 地址
def get_local_ip():s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)s.connect(("8.8.8.8", 80)) # Google Public DNSip = s.getsockname()[0]s.close()return ip# 处理服务器上的文件和目录
@app.post("/transcribe_server/", summary="处理服务器上的目录或文件生成字幕文件", description="通过指定服务器的目录或文件路径,生成字幕文件。")
async def transcribe_server(request: Request,model: Optional[str] = Form("tiny"),input: str = Form(..., description="输入的服务器目录或文件路径"),output: Optional[str] = Form(None, description="输出目录路径。如果未指定,则默认在输入路径下创建'srt'文件夹。")
):"""处理服务器上的目录或文件,生成字幕文件。"""input_path = inputoutput_path = outputif not os.path.exists(input_path):raise HTTPException(status_code=400, detail="输入路径不存在")# 如果是目录if os.path.isdir(input_path):if not output_path:output_path = os.path.join(input_path, "srt") # 默认在输入路径下创建 srt 文件夹srt_files = process_directory_with_structure(input_path, output_path, model)# 创建下载链接local_ip = get_local_ip() # 获取局域网 IP 地址download_links = [f"http://{local_ip}:5001/static/{os.path.relpath(srt[0], '/media/ubuntu/SOFT/whisper_test')}" for srt in srt_files]return JSONResponse(content={"input": input_path,"output": output_path,"srt_files": [srt[0] for srt in srt_files],"transcripts": [srt[1] for srt in srt_files],"download_links": download_links})# 如果是文件elif os.path.isfile(input_path):if not output_path:output_path = os.path.join(os.path.dirname(input_path), "srt") # 默认在输入文件所在目录下创建 srt 文件夹srt_file, text_content = process_file_with_structure(input_path, os.path.dirname(input_path), output_path, model)# 创建下载链接local_ip = get_local_ip() # 获取局域网 IP 地址srt_download_link = f"http://{local_ip}:5001/static/{os.path.relpath(srt_file, '/media/ubuntu/SOFT/whisper_test')}"return JSONResponse(content={"input": input_path,"output": output_path,"srt_file": srt_file,"content": text_content,"download_link": srt_download_link})else:raise HTTPException(status_code=400, detail="输入路径无效:不是有效的文件或目录")# 处理客户端上传的文件,生成 SRT 文件并返回下载链接和文本内容
@app.post("/transcribe_client/", summary="处理客户端上传的文件生成字幕文件", description="上传客户端的文件,生成 SRT 文件,并返回下载链接和转录内容。")
async def transcribe_client(request: Request,model: Optional[str] = Form("tiny"),input_file: UploadFile = File(..., description="客户端上传的文件")
):"""处理客户端上传的文件,生成字幕文件,并返回生成的 SRT 文件路径和转录文本。"""if not os.path.exists(UPLOAD_DIR):os.makedirs(UPLOAD_DIR) # 确保临时目录存在# 将上传的文件保存到服务器的临时目录file_location = os.path.join(UPLOAD_DIR, input_file.filename)with open(file_location, "wb") as f:shutil.copyfileobj(input_file.file, f)input_path = file_location # 使用上传的文件路径作为输入路径if os.path.isfile(input_path):output_path = os.path.join(UPLOAD_DIR, "srt")srt_file, text_content = process_file_with_structure(input_path, UPLOAD_DIR, output_path, model)print("srt_file:",srt_file)# 返回下载链接和转录文本local_ip = get_local_ip() # 获取局域网 IP 地址srt_download_link = f"http://{local_ip}:5001/static/{os.path.relpath(srt_file, '/media/ubuntu/SOFT/whisper_test')}"print("srt_download_link",srt_download_link)print("",os.path.relpath(srt_file, '/media/ubuntu/SOFT/whisper_test/srt'))return JSONResponse(content={"input": input_path,"output": output_path,"srt_file": srt_file,"content": text_content, # 返回转录的文本内容"download_link": srt_download_link # 返回生成 SRT 文件的下载链接})raise HTTPException(status_code=400, detail="上传的文件无效,必须是音频或视频文件。")if __name__ == "__main__":import uvicornuvicorn.run(app, host="0.0.0.0", port=5001)项目简介
基于 OpenAI Whisper 模型的音视频转写服务,支持上传文件或使用服务器上的文件生成字幕。该 API 提供了处理音频和视频文件的能力,并将其转录为 SRT 字幕文件。
运行环境
- Python 3.x
- FastAPI
- torch
- whisper
- moviepy
- opencc
安装依赖
在运行该项目之前,请确保安装以下依赖:
pip install fastapi[all] torch moviepy opencc-python-reimplemented
启动服务器
在项目根目录下运行以下命令启动 FastAPI 服务器:
uvicorn main:app --host 0.0.0.0 --port 5001 --reload
接口列表
1. /transcribe_server/
描述:处理服务器上的目录或文件,生成字幕文件。
请求方法:POST
请求参数:
| 参数 | 类型 | 必填 | 描述 |
|---|---|---|---|
| model | string | 否 | 使用的 Whisper 模型,默认为 tiny |
| input | string | 是 | 输入的服务器目录或文件路径 |
| output | string | 否 | 输出目录路径,默认为输入路径下创建 srt 文件夹 |
返回示例:
{"input": "/path/to/server/directory","output": "/path/to/server/directory/srt","srt_files": ["/path/to/server/directory/srt/file1.srt"],"transcripts": ["转录内容"],"download_links": ["http://192.168.1.1:5001/static/file1.srt"]
}
2. /transcribe_client/
描述:处理客户端上传的文件,生成字幕文件。
请求方法:POST
请求参数:
| 参数 | 类型 | 必填 | 描述 |
|---|---|---|---|
| model | string | 否 | 使用的 Whisper 模型,默认为 tiny |
| input_file | UploadFile | 是 | 客户端上传的音频或视频文件 |
返回示例:
{"input": "/media/ubuntu/SOFT/whisper_test/uploads/example.wav","output": "/media/ubuntu/SOFT/whisper_test/uploads/srt","srt_file": "/media/ubuntu/SOFT/whisper_test/uploads/srt/example.srt","content": "转录后的文本内容","download_link": "http://192.168.1.1:5001/static/example.srt"
}
接口调用示例
使用 Python 调用接口
import requests# 调用 /transcribe_server 接口
response = requests.post("http://192.168.1.1:5001/transcribe_server/", data={"model": "tiny","input": "/path/to/server/directory"
})print(response.json())# 调用 /transcribe_client 接口
files = {'input_file': open('C:/path/to/your/example.wav', 'rb')}
response = requests.post("http://192.168.1.1:5001/transcribe_client/", files=files, data={"model": "tiny"})print(response.json())
使用 cURL 测试接口
调用 /transcribe_server/
curl -X POST "http://192.168.1.1:5001/transcribe_server/" \-H "Content-Type: application/x-www-form-urlencoded" \-d "model=tiny&input=/path/to/server/directory"
调用 /transcribe_client/
curl -X POST "http://192.168.1.1:5001/transcribe_client/" \-F "model=tiny" \-F "input_file=@C:/path/to/your/example.wav"
使用 Postman 测试接口
- 打开 Postman,创建一个新的请求。
- 设置请求方法为
POST。 - 输入请求 URL,例如
http://192.168.1.1:5001/transcribe_server/或http://192.168.1.1:5001/transcribe_client/。 - 在
Body选项中,选择form-data:- 对于
/transcribe_server/:- 添加字段
model(可选),值为tiny。 - 添加字段
input(必填),值为服务器上的目录路径。
- 添加字段
- 对于
/transcribe_client/:- 添加字段
model(可选),值为tiny。 - 添加字段
input_file(必填),值为上传的音频或视频文件。
- 添加字段
- 对于
- 点击
Send发送请求,查看返回结果。
注意事项
- 确保输入的目录或文件路径正确。
- 上传的文件类型必须为支持的音频或视频格式(mp3, wav, mp4, avi, mov)。
- 下载链接将在响应中返回,确保使用正确的局域网 IP 地址进行访问。
相关文章:

Whisper 音视频转写
Whisper 音视频转写 API 接口文档 api.py import os import shutil import socket import torch import whisper from moviepy.editor import VideoFileClip import opencc from fastapi import FastAPI, File, UploadFile, Form, HTTPException, Request from fastapi.respons…...

【详尽-实战篇】使用Springboot生成自带logo或者图片的二维码-扫描二维码可以跳转到指定的页面-Zing-core
先上效果图 项目源码:https://download.csdn.net/download/qq_43055855/89891285 源码地址 手机扫描二维码跳转到指定网页 概述 这个项目是一个基于 Java 的二维码生成与解析工具,主要由 QRCodeUtil 和 QRCodeController 两个类组成。它利用了 Google…...
详细教程)
vue跨标签页通信(或跨窗口)详细教程
在 Vue 应用中,跨标签页(或跨窗口)的通信通常涉及到两个或多个浏览器标签页之间的信息共享。由于每个标签页或窗口都是独立的 JavaScript 执行环境,它们不能直接通过 Vue 或其他 JavaScript 库来直接相互通信。但是,有一些方法可以实现这种跨标签页的通信,主要依靠浏览器…...

【VUE】Vue3通过数组下标更改数组视图为什么会更新?
在 Vue 3 中,使用 Proxy 来实现了对数组的响应式监听,相比于 Vue 2 使用的 Object.defineProperty(),Proxy 更加高效和灵活。 因此,在 Vue 3 中,通过数组下标直接更改数组中某一项的值,也能够被 Vue 正确监…...

前端转换double数据,保留两位小数
Number Number(1.00) 1 Number(1.10) 1.1 Number(1.101) 1.101 要想前端展示页面按 1.00展示1,1.10 展示1.1 需要套一个number() 1.1 保留两位小数,并三位一个分隔符 indexView.value[key] formatNumber(indexView.value[key].toFixed(2))//格式…...

【实战案例】JSR303统一校验与SpringBoot项目的整合
前后端分离项目中,当前前端请求后端接口的时候通常需要传输参数,对于参数的校验应该在哪一步进行校验?Controller中还是Service中?答案是都需要校验,只不过负责的板块不一样,Controller中通常校验请求参数的…...
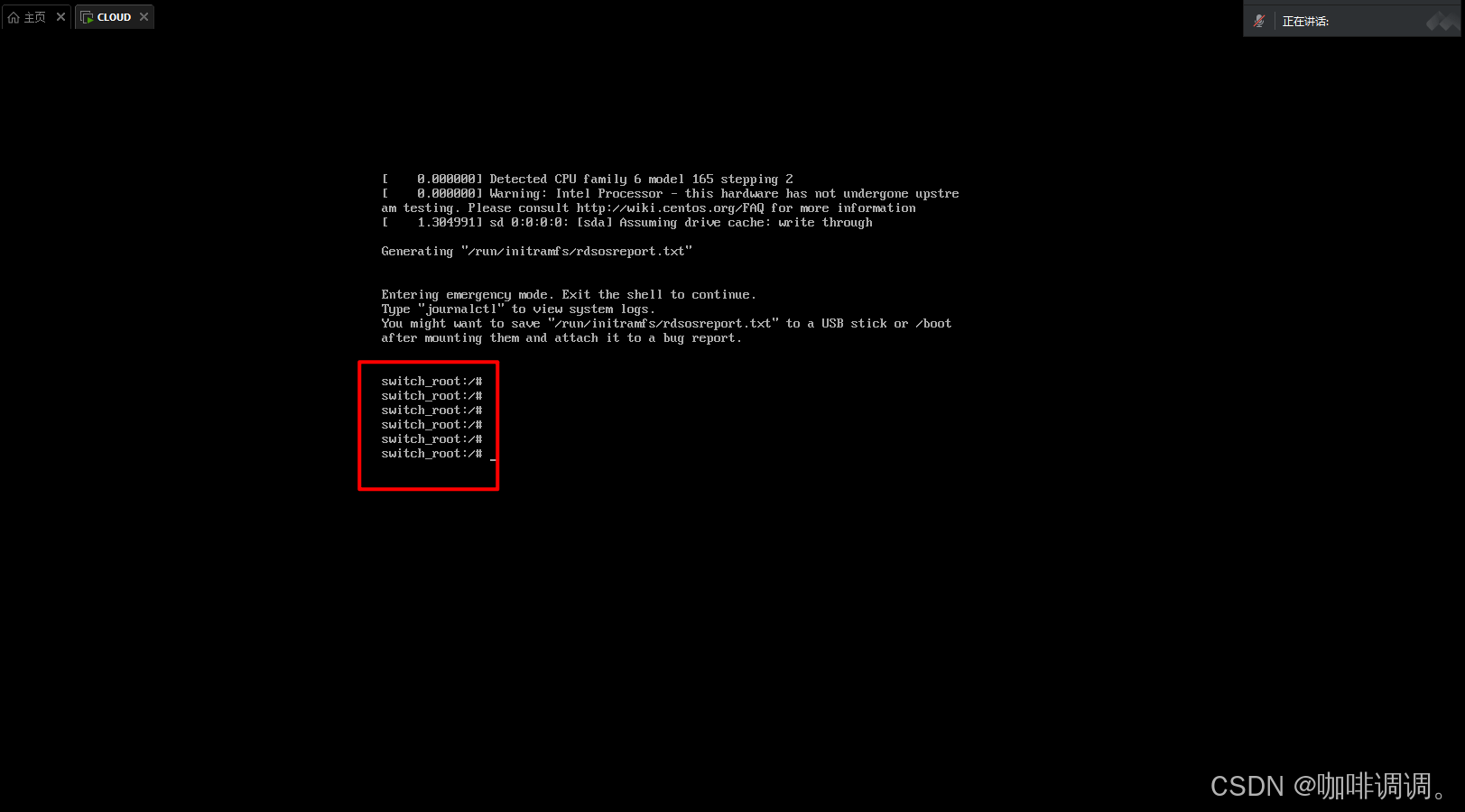
忘记了系统root密码,如何重置root密码?
重置root密码(CentOS7) 文章目录 重置root密码(CentOS7)[toc] 1.开启系统时,在引导界面按下字母e。 2.进入到内核界面,找到Linux开头字样一行,然后在最末尾输入参数rd.break,然后按住…...

7-基于国产化FT-M6678+JFM7K325T的6U CPCI信号处理卡
一、板卡概述 本板卡系我公司自主研发,基于6U CPCI的通用高性能信号处理平台。板卡采用一片国产8核DSP FT-C6678和一片国产FPGA JFM7K325T-2FFG900作为主处理器。为您提供了丰富的运算资源。如下图所示: 二、设计参考标准 ● PCIMG 2.0 R3.0 CompactP…...

计算机毕业设计 | SSM超市进销存管理系统(附源码)
1,绪论 1.1 开发背景 世界上第一个购物中心诞生于美国纽约,外国人迈克尔库伦开设了第一家合作商店,为了更好地吸引大量客流量,迈克尔库伦精心设计了低价策略,通过大量进货把商品价格压低,通过商店一次性集…...

手撕数据结构 —— 堆(C语言讲解)
目录 1.堆的认识 什么是堆 堆的性质 2.堆的存储 3.堆的实现 Heap.h中接口总览 具体实现 堆结构的定义 初始化堆 销毁堆 堆的插入 堆的向上调整算法 堆的插入的实现 堆的删除 堆的向下调整算法 堆的删除的实现 使用数组初始化堆 获取堆顶元素 获取堆中的数据…...

TS和JS中,string与String的区别
1. string string 是 TypeScript 的基本类型,用于表示简单的字符串值,同时它是一个原始类型,可直接表示文本数据。 2. String String 是 JavaScript 中的一个全局对象(类),用于创建字符串对象࿰…...

jna调用c++动态库linux测试
1、 编译代码和运行指令 javac -cp .:jna-5.7.0.jar:jna-platform-5.7.0.jar JnaTest.java VideoAiLibrary.java java -cp .:jna-5.7.0.jar:jna-platform-5.7.0.jar JnaTest javac -cp .:jna-5.7.0.jar:jna-platform-5.7.0.jar JnaTest.java VideoAiLibrary.java -cp 指定c…...
智诊小助手TF卡记录文件导出
若想将TF卡中记录的数据文件导出可按以下的流程进行配置: 点击主界面中的导出选项即可进入到下图中TF卡应用界面点击TF卡应用界面中“查看记录文件”的选项,进入导出文件界面。点击“选择”进入勾选文件的界面 点击“导出”后,点击“确定”即…...

Jetpack-ViewModel+LiveData+DataBinding
1.ViewModel 解决问题: 瞬态数据丢失异步调用内存泄漏类膨胀提高维护难度和测试难度 作用: 介于View视图和Model数据模型之间桥梁使视图和数据能够分离,也能保持通信 public class MainActivity extends AppCompatActivity {private Tex…...

Servlet[springmvc]的Servlet.init()引发异常
报错: 原因之一: web.xml配置文件中监听器导入依赖项错误...

总结:SQL查询变慢,常见原因分析!
文章目录 引言SQL查询慢原因索引失效特殊情况-执行计划中,key有值,还是很慢怎么办? 多表JOIN为什么互联网公司都不建议使用多表join? 索引基数太小不合理查询字段太多表中数据量太大数据库连接数不够为什么乐观锁还会导致大量的锁…...

基于webrtc实现音视频通信
与传统通信方式不同,p2p通信的实现过程不依赖于中间服务器的信息收发,直接通过信令等完成通信过程的建立; 通过websocket实现信令服务器的建立,而通过信令来确定通信双方; webrtc通过 sdp协议来完善通信双方间协议的…...

【多版本并发控制(MVCC)】
并发事务问题: MySQL隔离级别-未提交读,提交读,可重复读,序列化 隔离级别对于并发事务的解决情况 隔离级别脏读不可重复读幻读未提交读不可不可不可读已提交可不可不可可重复读 (默认)可可不可串行化&…...

常见漏洞及webshell工具的流量特征
常见攻击的流量特征 信息泄露 请求/路径中,包含 特殊文件 或 路径;响应包中,包含敏感信息(如,数据结构,用户信息,网络结构等) 弱口令爆破 非常规流量:短时间内大量数据…...

python学习-怎么在Pycharm写代码
打开Pycharm,点击文件-新建项目 2.选择pure python-点击箭头 展开 3.选择 Existing interpreter 如果 Existing interpreter 下没有相关环境 (1)点击**…** (2)选择python的安装路径 4.可修改文件名称-点击创建 …...

古戏台构件声学特性的时域有限差分方法【附模型】
✨ 长期致力于时域有限差分法、窑洞、戏台、八字墙、共形技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)曲面共形网格快速生成算法: …...

30岁裸辞后,我用两个月拿下AI应用认证,现在OFFER选择困难症犯了
30岁裸辞那天,我最怕的不是没收入,而是突然发现:过去积累的经验,正在被AI重新定价。以前会写方案、做表格、跟项目,算是职场硬通货;到了2026年,招聘JD里开始频繁出现AI工具应用、智能工作流、Pr…...

别再乱算相似度了!用Python实战二元变量聚类:从Jaccard系数到病人分组
医疗数据分析实战:用Python实现基于Jaccard系数的病人症状聚类在医疗数据分析领域,如何从海量病人症状数据中发现潜在规律一直是临床研究的难点。传统方法往往依赖医生经验或简单统计,而现代数据挖掘技术为我们提供了更科学的解决方案。本文将…...

如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南
如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI UAss…...

三十岁想从零转行现实吗?带你分辨真正有前景的好工作
我是29岁那年,完成从转行裸辞副业的职业转型。 如果你把职业生涯看成是从现在开始30岁,到你退休那年,中间这么漫长的30年,那么30岁转行完全来得及…...

3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行
3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or KernelSU (root so…...

Git Bash 中无法启动 Claude Code ?
最近需要在 git bash 中跑 Claude Code 。git bash 是随 git for windows 套件安装的,很久没更新了,结果启动 Claude Code 报错:Warning: no stdin data received in 3s, proceeding without it. If piping from a slow command, redirect st…...

对比按量计费与Token Plan套餐的实际成本差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按量计费与Token Plan套餐的实际成本差异 在构建和运营基于大模型的应用时,成本控制是一个核心的工程考量。Taotok…...

AICoverGen终极指南:快速创建AI翻唱歌曲的完整教程
AICoverGen终极指南:快速创建AI翻唱歌曲的完整教程 【免费下载链接】AICoverGen A WebUI to create song covers with any RVC v2 trained AI voice from YouTube videos or audio files. 项目地址: https://gitcode.com/gh_mirrors/ai/AICoverGen 想要让你的…...

Switch控制器PC适配难题的技术解决方案:BetterJoy架构解析与高级配置指南
Switch控制器PC适配难题的技术解决方案:BetterJoy架构解析与高级配置指南 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: ht…...