【Triton教程】向量相加
Triton 是一种用于并行编程的语言和编译器。它旨在提供一个基于 Python 的编程环境,以高效编写自定义 DNN 计算内核,并能够在现代 GPU 硬件上以最大吞吐量运行。
更多 Triton 中文文档可访问 →https://triton.hyper.ai/
在本教程中,你将使用 Triton 编写一个简单的向量相加 (vector addition) 程序。
你将了解:
- Triton 的基本编程模型
- 用于定义 Triton 内核的 triton.jit 装饰器 (decorator)
- 验证和基准测试自定义算子与原生参考实现的最佳实践
计算内核
import torch
import triton
import triton.language as tl@triton.jit
def add_kernel(x_ptr, # *Pointer* to first input vector. 指向第一个输入向量的指针。y_ptr, # *Pointer* to second input vector. 指向第二个输入向量的指针。output_ptr, # *Pointer* to output vector. 指向输出向量的指针。n_elements, # Size of the vector. 向量的大小。BLOCK_SIZE: tl.constexpr, # Number of elements each program should process. 每个程序应处理的元素数量。# NOTE: `constexpr` so it can be used as a shape value. 注意:`constexpr` 因此它可以用作形状值。):# There are multiple 'programs' processing different data. We identify which program# 有多个“程序”处理不同的数据。需要确定是哪一个程序:pid = tl.program_id(axis=0) # We use a 1D launch grid so axis is 0. 使用 1D 启动网格,因此轴为 0。# This program will process inputs that are offset from the initial data.# 该程序将处理相对初始数据偏移的输入。# For instance, if you had a vector of length 256 and block_size of 64, the programs would each access the elements [0:64, 64:128, 128:192, 192:256].# 例如,如果有一个长度为 256, 块大小为 64 的向量,程序将各自访问 [0:64, 64:128, 128:192, 192:256] 的元素。# Note that offsets is a list of pointers:# 注意 offsets 是指针列表:block_start = pid * BLOCK_SIZEoffsets = block_start + tl.arange(0, BLOCK_SIZE)# Create a mask to guard memory operations against out-of-bounds accesses.# 创建掩码以防止内存操作超出边界访问。mask = offsets < n_elements# Load x and y from DRAM, masking out any extra elements in case the input is not a multiple of the block size.# 从 DRAM 加载 x 和 y,如果输入不是块大小的整数倍,则屏蔽掉任何多余的元素。x = tl.load(x_ptr + offsets, mask=mask)y = tl.load(y_ptr + offsets, mask=mask)output = x + y# Write x + y back to DRAM.# 将 x + y 写回 DRAM。tl.store(output_ptr + offsets, output, mask=mask)
创建一个辅助函数从而: (1) 生成 z 张量,(2) 用适当的 grid/block sizes 将上述内核加入队列:
def add(x: torch.Tensor, y: torch.Tensor):# We need to preallocate the output.# 需要预分配输出。output = torch.empty_like(x)assert x.is_cuda and y.is_cuda and output.is_cudan_elements = output.numel()# The SPMD launch grid denotes the number of kernel instances that run in parallel.# SPMD 启动网格表示并行运行的内核实例的数量。# It is analogous to CUDA launch grids. It can be either Tuple[int], or Callable(metaparameters) -> Tuple[int].# 它类似于 CUDA 启动网格。它可以是 Tuple[int],也可以是 Callable(metaparameters) -> Tuple[int]。# In this case, we use a 1D grid where the size is the number of blocks:# 在这种情况下,使用 1D 网格,其中大小是块的数量:grid = lambda meta: (triton.cdiv(n_elements, meta['BLOCK_SIZE']), )# NOTE:# 注意:# - Each torch.tensor object is implicitly converted into a pointer to its first element.# - 每个 torch.tensor 对象都会隐式转换为其第一个元素的指针。# - `triton.jit`'ed functions can be indexed with a launch grid to obtain a callable GPU kernel.# - `triton.jit` 函数可以通过启动网格索引来获得可调用的 GPU 内核。# - Don't forget to pass meta-parameters as keywords arguments.# - 不要忘记以关键字参数传递元参数。add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)# We return a handle to z but, since `torch.cuda.synchronize()` hasn't been called, the kernel is still running asynchronously at this point.# 返回 z 的句柄,但由于 `torch.cuda.synchronize()` 尚未被调用,此时内核仍在异步运行。return output
使用上述函数计算两个 torch.tensor 对象的 element-wise sum,并测试其正确性:
torch.manual_seed(0)
size = 98432
x = torch.rand(size, device='cuda')
y = torch.rand(size, device='cuda')
output_torch = x + y
output_triton = add(x, y)
print(output_torch)
print(output_triton)
print(f'The maximum difference between torch and triton is 'f'{torch.max(torch.abs(output_torch - output_triton))}')
Out:
tensor([1.3713, 1.3076, 0.4940, ..., 0.6724, 1.2141, 0.9733], device='cuda:0')tensor([1.3713, 1.3076, 0.4940, ..., 0.6724, 1.2141, 0.9733], device='cuda:0')The maximum difference between torch and triton is 0.0
现在准备就绪。
基准测试
在 size 持续增长的向量上对自定义算子进行基准测试,从而比较其与 PyTorch 的性能差异。为了方便操作,Triton 提供了一系列内置工具,允许开发者简洁地绘制自定义算子在不同问题规模 (problem sizes) 下的的性能图。
@triton.testing.perf_report(triton.testing.Benchmark(x_names=['size'], # Argument names to use as an x-axis for the plot. 用作绘图 x 轴的参数名称。x_vals=[2**i for i in range(12, 28, 1)], # Different possible values for `x_name`. `x_name` 的不同可能值。x_log=True, # x axis is logarithmic. x 轴为对数。line_arg='provider', # Argument name whose value corresponds to a different line in the plot. 参数名称,其值对应于绘图中的不同线条。line_vals=['triton', 'torch'], # Possible values for `line_arg`. `line_arg` 的可能值。line_names=['Triton', 'Torch'], # Label name for the lines. 线条的标签名称。styles=[('blue', '-'), ('green', '-')], # Line styles. 线条样式。ylabel='GB/s', # Label name for the y-axis. y 轴标签名称。plot_name='vector-add-performance', # Name for the plot. Used also as a file name for saving the plot. 绘图名称。也用作保存绘图的文件名。args={}, # Values for function arguments not in `x_names` and `y_name`. 不在 `x_names` 和 `y_name` 中的函数参数值。))
def benchmark(size, provider):x = torch.rand(size, device='cuda', dtype=torch.float32)y = torch.rand(size, device='cuda', dtype=torch.float32)quantiles = [0.5, 0.2, 0.8]if provider == 'torch':ms, min_ms, max_ms = triton.testing.do_bench(lambda: x + y, quantiles=quantiles)if provider == 'triton':ms, min_ms, max_ms = triton.testing.do_bench(lambda: add(x, y), quantiles=quantiles)gbps = lambda ms: 3 * x.numel() * x.element_size() / ms * 1e-6return gbps(ms), gbps(max_ms), gbps(min_ms)
运行上述装饰函数 (decorated function)。输入查看性能数据,输入 show_plots=True 绘制结果, 以及/或者输入 save_path='/path/to/results/' 将其与原始 CSV 数据一起保存到磁盘:
benchmark.run(print_data=True, show_plots=True)

out:

Download Jupyter notebook: 01-vector-add.ipynb
Download Python source code: 01-vector-add.py
Download zipped: 01-vector-add.zip
相关文章:
【Triton教程】向量相加
Triton 是一种用于并行编程的语言和编译器。它旨在提供一个基于 Python 的编程环境,以高效编写自定义 DNN 计算内核,并能够在现代 GPU 硬件上以最大吞吐量运行。 更多 Triton 中文文档可访问 →https://triton.hyper.ai/ 在本教程中,你将使…...

关于CSS中毛玻璃和滤镜使用总结
【1】毛玻璃 毛玻璃效果(也称为磨砂玻璃效果)可以通过 CSS 的 backdrop-filter 属性来实现。这个属性允许你在背景上应用各种滤镜效果,从而创建出类似磨砂玻璃的效果。这种效果通常用于创建半透明背景下的模糊效果,使得背景图像或…...

陷入产出危机的我聊聊近况
文章目录 前言我的多重身份作为IT网管作为运维人员作为Web开发人员作为游戏开发人员 总结 前言 在总结文章时,我把自己当做一个内容产出者,当这样一个身份进入每天按部就班的平稳状态时会陷入一种焦虑,产生一种居然没有什么可写的感觉&#…...

HarmonyOS 开发知识总结
1. HarmonyOS 开发知识总结 1.1. resources->base->media中不可以新建文件夹? 项目图片路径resources->base->media中不可以新建文件夹,图片全平级放里面,查找图片不方便,有没有什么其他的办法解决这个难点ÿ…...

[WPF初学到大神] 1. 什么是WPF, MVVM框架, XAML?
什么是WPF? WPF(Windows Presentation Foundation) 包含XAML标记语言和后端代码来开发桌面应用程序的. 用VS新建项目有WPF(.Net Framework和.Net应用程序), 该怎么选? 首选 .NET 应用程序(.NET Core 或 .NET 5/6/7/8新版本)拥有更好的性能、跨平台Windows, Linux, Mac支…...

matlab怎样自动搜索文件夹中的所有txt文件,并将每个txt文件中的数据存放到一个cell数组中——MATLAB批量处理数据
在使用MATLAB批量处理数据时,有时候需要自动搜索文件夹中的所有txt文件,并将每个txt文件中的数据存放到一个以一定规律命名的变量中,以便于后续通过循环处理每个变量数据。 然而,MATLAB并不支持在变量名中直接使用i来动态生成变量…...
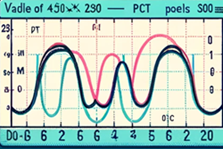
LabVIEW智能可变温循环PCT测试系统
随着全球能源危机的加剧和环境保护需求的提升,开发和利用清洁能源已成为全球必然趋势。氢能作为一种高效的替代能源,正逐步受到关注。然而,储氢技术的研究至关重要,尤其是储氢材料的PCT(Pressure-Composition-Temperat…...

SparkSQL整合Hive
spark-sql可以直接使用hive的元数据 1、环境搭建如下: ## 1、启动hive的元数据服务shell # 1、修改hive的配置文件 cd /usr/local/soft/hive-3.1.3/conf# 2、增加配置 vim hive-site.xml<property> <name>hive.metastore.uris</name> <value…...

Vue 3 和 Vue 2区别
Vue 3 是 Vue 2 的全新升级版本,引入了诸多新的特性,并在性能、开发体验、响应式系统等多个方面进行了改进。以下是 Vue 2 和 Vue 3 的详细对比: 1. 生命周期钩子差异 Vue 3 保留了大部分 Vue 2 的生命周期钩子,但部分名称有所调…...

React.memo和useMemo
React.memo和usememo React.memo React.memo是一个高阶组件,对组件进行性能优化,主要用于优化函数组件的性能,如果一个组件在相同的props下渲染出相同的结果,但是又不需要在组件更新的时候重新渲染,就可以使用react.…...

Android中实现网络请求的方式有哪些?
在Android开发中,实现网络请求是开发过程中不可避免的一部分。随着技术的不断发展,Android中出现了多种实现网络请求的方式,每种方式都有其独特的优缺点。 一、HttpURLConnection HttpURLConnection是Java提供的用于发送HTTP请求的标准类&a…...

安卓13usb触摸唤醒系统 android13触摸唤醒
总纲 android13 rom 开发总纲说明 文章目录 1.前言2.问题分析3.代码分析4.代码修改5.编译6.彩蛋1.前言 android13在待机后,需要能够使用触摸屏去唤醒我们的系统,这就需要我们修改系统的相关配置了。 2.问题分析 对于这个问题,我们需要知道安卓的事件分发,通过事件分发,…...

c++常用库函数
一.sort排序 快排的改进算法,评价复杂度为(nlogn). 1.用法 sort(起始地址,结束地址下一位,*比较函数) [起始地址,结束地址) (左开右闭) #include<bits/stdc.h> using namespace std; int main() {//sortvector<int&g…...

CSS 网格布局
网格布局是一个二维布局系统,允许开发者以行和列的形式创建灵活的网络,并将内容放置在网络的单元格中。有些元素可能只占据网络的一个单元,另一些元素则可能占据多行或多列。 网格的大小既可以精确定义,也可以根据自身内容自动计…...

python实现屏幕录制,录音录制工具
python实现屏幕录制,录音录制工具 一,介绍 Python 实现的屏幕录制和录音录制工具是一个便捷的应用程序,旨在帮助用户同时捕捉计算机屏幕上的活动以及与之相关的音频输出。这个工具尤其针对教育工作者、内容创作者、技术支持人员以及任何需要…...

elementui 的 table 组件回显已选数据时候使用toggleRowSelection 方法的坑点
elementui 的 table 组件回显问题 "vue": "^2.7.16", "element-ui": "^2.15.14", 问题描述: 场景:首先我们是通过接口获取到数据之后 然后将返回的数据回显到表格上面 问题:直接将后端返回的数据…...
)
MATLAB基础应用精讲-【数模应用】负二项回归(附R语言和python代码实现)
目录 前言 几个高频面试题目 负二项回归、Probit回归如何选择 负二项回归 Probit回归 知识储备 逻辑回归 算法原理 多阈值负二项回归模型 模型及估计方法 负二项回归模型 多阈值负二项回归模型 分割阶段 精确估计阈值阶段 负二项回归的操作步骤 负二项回归…...

20240803 芯动科技 笔试
文章目录 1、单选题1.11.21.31.42、填空题2.12.23、问答题3.13.23.34、编程题4.14.24.3岗位:嵌入式软件工程师(25届校招)(J12042) 题型:4 道单选题,2 道填空题, 3 道简答题,3 道编程题 1、单选题 1.1 已知 5 个元素的出栈序列是 1,2,3,4,5,6 则对应的入栈顺序可能是 …...

如何将 ECharts 图表插入 HTML Canvas
在 Web 开发中,数据可视化是一个常见且重要的需求。ECharts 是一个强大的图表库,而 HTML5 Canvas 则提供了灵活的绘图能力。今天,我们将探讨如何将这两者结合起来,实现将 ECharts 生成的图表插入到 HTML Canvas 中的特定位置。 为…...

突破干扰,无人机自动驾驶技术详解
突破干扰的无人机自动驾驶技术,是一个结合了多学科领域的复杂系统,旨在确保无人机在复杂电磁环境、人为干扰等条件下仍能自主、安全地完成飞行任务。以下是对该技术的详细解析: 一、技术概述 无人机自动驾驶技术通过集成传感器技术、人工智…...

新手也能懂的SSRF漏洞实战:用iwebsec靶场复现文件读取与内网探测
从零开始掌握SSRF漏洞:iwebsec靶场实战指南1. 认识SSRF漏洞的本质想象一下,你正在一家高档餐厅点餐,服务员承诺可以帮你从任何地方获取食材——包括隔壁竞争对手的厨房。SSRF(Server-Side Request Forgery)漏洞就像这个…...

古戏台构件声学特性的时域有限差分方法【附模型】
✨ 长期致力于时域有限差分法、窑洞、戏台、八字墙、共形技术研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)曲面共形网格快速生成算法: …...

金融合规审核为何人力堆积却仍漏洞百出?2026年RegTech演进与Agent全链路闭环解决方案
在2026年的金融监管环境下,合规审核已不再是简单的“查漏补缺”,而是演变为一场高强度的算力与逻辑博弈。尽管金融机构在合规成本上的投入逐年攀升,甚至不惜以“人海战术”填补流程断点,但监管罚单的数额与频率却并未显著下降。这…...

HarmonyOS ArkTS DateUtil 日期增减与日历计算完整指南
文章目录 背景一、引言二、日期增减方法详解使用示例 三、日历计算方法详解四、Demo 演示:日期增减结果展示五、Demo 演示:月历视图完整实现六、日历视图关键点解析为什么要填充前置空格?getLastDayOfMonth 的实现技巧 七、小结 背景 近期发现…...

Owl-Alpha 新手快速上手指南
在处理大规模数据或构建高性能应用时,我们常常会遇到一个棘手的问题:如何在不阻塞主线程的情况下,高效地执行耗时任务?无论是处理图像、解析大型文件,还是进行复杂的数学运算,传统的单线程模式往往会让界面…...

轻量化部署,异地机房快速接入,多机房管理不用再大动干戈
随着业务拓展,不少企业、单位陆续建起异地分部机房、多区域节点机房。传统资产管理系统部署复杂、对接困难,异地机房接入成本高、周期长,改造繁琐,让很多运维团队望而却步,只能继续沿用分散人工管理,资产混…...

如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗
如何快速集成 react-native-bottom-sheet-behavior:5 分钟搞定 Android 底部弹窗 【免费下载链接】react-native-bottom-sheet-behavior react-native wrapper for android BottomSheetBehavior 项目地址: https://gitcode.com/gh_mirrors/re/react-native-bottom…...

AWS DevOps Agent 完全指南
AWS DevOps Agent 是 AWS 推出的前沿 AI 运维代理,自主调查和解决事件、持续预防故障、提升系统可靠性。本文档覆盖从原理到实战的全生命周期管理。 一、定位与价值 一句话定义 AWS DevOps Agent = AI 驱动的 SRE 队友,724 自主调查告警、定位根因、生成修复方案、预防未来…...

Hermes Agent工具如何自定义接入Taotoken提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent工具如何自定义接入Taotoken提供商 Hermes Agent 是一款功能强大的AI智能体开发框架,它支持通过自定义提供…...

5步完美解决Windows 10 PL2303驱动兼容性问题:完整实施方案指南
5步完美解决Windows 10 PL2303驱动兼容性问题:完整实施方案指南 【免费下载链接】pl2303-win10 Windows 10 driver for end-of-life PL-2303 chipsets. 项目地址: https://gitcode.com/gh_mirrors/pl/pl2303-win10 在Windows 10系统中使用PL2303 USB转串口设…...