实现prometheus+grafana的监控部署
直接贴部署用的文件信息了
kubectl label node xxx monitoring=true
创建命名空间
kubectl create ns monitoring部署operator
kubectl apply -f operator-rbac.yml
kubectl apply -f operator-dp.yml
kubectl apply -f operator-crd.yml
# 定义node-export
kubectl apply -f ./node-exporter/node-exporter-sa.yml
kubectl apply -f ./node-exporter/node-exporter-rbac.yml
kubectl apply -f ./node-exporter/node-exporter-svc.yml
kubectl apply -f ./node-exporter/node-exporter-ds.yml# 自定义配置文件,定义显示方式
kubectl apply -f ./grafana/pv-pvc-hostpath.yml
kubectl apply -f ./grafana/grafana-sa.yml
kubectl apply -f ./grafana/grafana-source.yml
kubectl apply -f ./grafana/grafana-datasources.yml
kubectl apply -f ./grafana/grafana-admin-secret.yml
kubectl apply -f ./grafana/grafana-svc.yml
# 创建配置conifgmap
kubectl create configmap grafana-config --from-file=./grafana/grafana.ini --namespace=monitoring
kubectl create configmap all-grafana-dashboards --from-file=./grafana/dashboard --namespace=monitoringkubectl apply -f ./grafana/grafana-dp.yml
kubectl apply -f ./service-discovery/kube-controller-manager-svc.yml
kubectl apply -f ./service-discovery/kube-scheduler-svc.yml # 自定义配置文件,定义收集和报警规则
kubectl apply -f ./prometheus/prometheus-secret.yml
kubectl apply -f ./prometheus/prometheus-rules.yml
kubectl apply -f ./prometheus/prometheus-rbac.yml
kubectl apply -f ./prometheus/prometheus-svc.yml# prometheus-operator 部署成功后才能创建成功
kubectl apply -f ./prometheus/pv-pvc-hostpath.yaml
kubectl apply -f ./prometheus/prometheus-main.yml# 监控目标,lable必须是k8s-app 因为prometheus是按这个查找的。不然prometheus采集不了该
kubectl apply -f ./servicemonitor/alertmanager-sm.yml
kubectl apply -f ./servicemonitor/coredns-sm.yml
kubectl apply -f ./servicemonitor/kube-apiserver-sm.yml
kubectl apply -f ./servicemonitor/kube-controller-manager-sm.yml
kubectl apply -f ./servicemonitor/kube-scheduler-sm.yml
kubectl apply -f ./servicemonitor/kubelet-sm.yml
kubectl apply -f ./servicemonitor/kubestate-metrics-sm.yml
kubectl apply -f ./servicemonitor/node-exporter-sm.yml
kubectl apply -f ./servicemonitor/prometheus-operator-sm.yml
kubectl apply -f ./servicemonitor/prometheus-sm.yml
kubectl apply -f ./servicemonitor/pushgateway-sm.yml# prometheus-adapter 部署
kubectl apply -f ./prometheus_adapter/metric_rule.yaml
kubectl apply -f ./prometheus_adapter/prometheus_adapter.yaml受限于篇幅就不张贴部署脚本内容,详情请参见
GitHub - chenrui2200/prometheus_k8s_install
创建出进监控pod

node_exporter 和 prometheus_k8s 是在 Kubernetes 环境中监控和收集指标的两个重要组件。它们之间有着密切的关系,以下是它们的详细讲解及相互关系。
Node Exporter
-
定义:
node_exporter是 Prometheus 官方提供的一个工具,用于收集和暴露操作系统及硬件的性能指标。这些指标包括 CPU、内存、磁盘、网络等系统级别的性能数据。 -
功能:
- 它运行在每个节点上,监控该节点的系统资源使用情况。
- 提供的指标格式符合 Prometheus 的要求,因此可以直接被 Prometheus 抓取。
-
使用场景:
- 适用于监控物理机、虚拟机或 Kubernetes 节点的基础设施健康状态。
Prometheus K8s
-
定义:
prometheus_k8s是一个 Prometheus 实例,专门用于在 Kubernetes 集群中监控 Kubernetes 资源及其运行的应用。 -
功能:
- 通过 Kubernetes 的 API,自动发现集群中的服务和容器,并抓取它们暴露的指标。
- 可以监控 Kubernetes 组件(如 kube-apiserver、kube-scheduler、kube-controller-manager)及各个应用程序的性能。
-
使用场景:
- 适用于监控整个 Kubernetes 集群的健康状况和性能。
二者的关系
-
数据来源:
node_exporter收集每个节点的系统性能指标,然后 Prometheus 可以抓取这些指标。prometheus_k8s则从 Kubernetes 中的其他组件和应用程序收集指标。
-
监控层次:
node_exporter主要关注底层硬件和操作系统级别的监控。prometheus_k8s关注 Kubernetes 资源和应用的监控,包括 Pods、服务和其它 Kubernetes 对象。
-
集成:
- 在 Kubernetes 环境中,通常会在每个节点上运行
node_exporter,并配置prometheus_k8s来定期抓取node_exporter的指标,这样就能实现对节点性能的全面监控。
- 在 Kubernetes 环境中,通常会在每个节点上运行
node_exporter 和 prometheus_k8s 是相辅相成的。node_exporter 提供了基础设施级别的监控,而 prometheus_k8s 则补充了 Kubernetes 资源和应用的监控。结合使用这两个组件,能够实现对整个系统的全面监控,帮助运维人员及时发现和解决问题。
查看前端展示

python实现prometheus客户端
import json, datetime, time
import requests
import pysnooperclass Prometheus():def __init__(self, host=''):# '/api/v1/query_range' 查看范围数据# '/api/v1/query' 瞬时数据查询self.host = hostself.query_path = 'http://%s/api/v1/query' % self.hostself.query_range_path = 'http://%s/api/v1/query_range' % self.host# @pysnooper.snoop()def get_istio_service_metric(self, namespace):service_metric = {"qps": {},"gpu": {},"memory": {},"cpu": {}}# qps请求mem_expr = 'sum by (destination_workload,response_code) (irate(istio_requests_total{destination_service_namespace="%s"}[1m]))' % (namespace,)# print(mem_expr)params = {'query': mem_expr,'start': int(time.time())-300,'end': int(time.time()),'step': "1m", # 运行小于1分钟的,将不会被采集到# 'timeout':"30s"}print(params)try:res = requests.get(url=self.query_range_path, params=params)metrics = json.loads(res.content.decode('utf8', 'ignore'))if metrics['status'] == 'success':metrics = metrics['data']['result']if metrics:for service in metrics:service_name = service['metric']['destination_workload']if service_name not in service_metric['qps']:service_metric['qps'][service_name] = {}service_metric["qps"][service_name] = service['values']except Exception as e:print(e)# 内存mem_expr = 'sum by (pod) (container_memory_working_set_bytes{job="kubelet", image!="",container_name!="POD",namespace="%s"})' % (namespace,)# print(mem_expr)params = {'query': mem_expr,'start': int(time.time()) - 300,'end': int(time.time()),'step': "1m", # 运行小于1分钟的,将不会被采集到# 'timeout':"30s"}print(params)try:res = requests.get(url=self.query_range_path, params=params)metrics = json.loads(res.content.decode('utf8', 'ignore'))if metrics['status'] == 'success':metrics = metrics['data']['result']if metrics:for pod in metrics:pod_name = pod['metric']['pod']if pod_name not in service_metric['memory']:service_metric[pod_name] = {}service_metric['memory'][pod_name] = pod['values']except Exception as e:print(e)# cpu获取cpu_expr = "sum by (pod) (rate(container_cpu_usage_seconds_total{namespace='%s',container!='POD'}[1m]))" % (namespace)params = {'query': cpu_expr,'start': int(time.time()) - 300,'end': int(time.time()),'step': "1m", # 运行小于1分钟的,将不会被采集到# 'timeout':"30s"}print(params)try:res = requests.get(url=self.query_range_path, params=params)metrics = json.loads(res.content.decode('utf8', 'ignore'))if metrics['status'] == 'success':metrics = metrics['data']['result']if metrics:for pod in metrics:pod_name = pod['metric']['pod']if pod_name not in service_metric['cpu']:service_metric[pod_name] = {}service_metric['cpu'][pod_name] = pod['values']except Exception as e:print(e)gpu_expr = "avg by (pod) (DCGM_FI_DEV_GPU_UTIL{namespace='%s'})" % (namespace)params = {'query': gpu_expr,'start': (datetime.datetime.now() - datetime.timedelta(days=1) - datetime.timedelta(hours=8)).strftime('%Y-%m-%dT%H:%M:%S.000Z'),'end': datetime.datetime.now().strftime('%Y-%m-%dT%H:%M:%S.000Z'),'step': "1m", # 运行小于1分钟的,将不会被采集到# 'timeout':"30s"}print(params)try:res = requests.get(url=self.query_range_path, params=params)metrics = json.loads(res.content.decode('utf8', 'ignore'))if metrics['status'] == 'success':metrics = metrics['data']['result']if metrics:# print(metrics)for pod in metrics:pod_name = pod['metric']['pod']if pod_name not in service_metric['gpu']:service_metric['gpu'][pod_name] = {}service_metric['gpu'][pod_name] = pod['values']except Exception as e:print(e)return service_metric# 获取当前pod利用率# @pysnooper.snoop()def get_resource_metric(self):max_cpu = 0max_mem = 0ave_gpu = 0pod_metric = {}# 这个pod 30分钟内的最大值mem_expr = "sum by (pod) (container_memory_working_set_bytes{container!='POD', container!=''})"# print(mem_expr)params = {'query': mem_expr,'start': int(time.time()) - 300,'end': int(time.time()),'step': "1m", # 运行小于1分钟的,将不会被采集到# 'timeout':"30s"}print(params)try:res = requests.get(url=self.query_range_path, params=params)metrics = json.loads(res.content.decode('utf8', 'ignore'))if metrics['status'] == 'success':metrics = metrics['data']['result']if metrics:for pod in metrics:if pod['metric']:pod_name = pod['metric']['pod']values = max([float(x[1]) for x in pod['values']])if pod_name not in pod_metric:pod_metric[pod_name] = {}pod_metric[pod_name]['memory'] = round(values / 1024 / 1024 / 1024, 2)except Exception as e:print(e)cpu_expr = "sum by (pod) (rate(container_cpu_usage_seconds_total{container!='POD'}[1m]))"params = {'query': cpu_expr,'start': int(time.time()) - 300,'end': int(time.time()),'step': "1m", # 运行小于1分钟的,将不会被采集到# 'timeout':"30s"}print(params)try:res = requests.get(url=self.query_range_path, params=params)metrics = json.loads(res.content.decode('utf8', 'ignore'))if metrics['status'] == 'success':metrics = metrics['data']['result']if metrics:for pod in metrics:if pod['metric']:pod_name = pod['metric']['pod']values = [float(x[1]) for x in pod['values']]# values = round(sum(values) / len(values), 2)values = round(max(values), 2)if pod_name not in pod_metric:pod_metric[pod_name] = {}pod_metric[pod_name]['cpu'] = valuesexcept Exception as e:print(e)gpu_expr = "avg by (pod) (DCGM_FI_DEV_GPU_UTIL)"params = {'query': gpu_expr,'start': int(time.time()) - 300,'end': int(time.time()),'step': "1m", # 运行小于1分钟的,将不会被采集到# 'timeout':"30s"}print(params)try:res = requests.get(url=self.query_range_path, params=params)metrics = json.loads(res.content.decode('utf8', 'ignore'))if metrics['status'] == 'success':metrics = metrics['data']['result']if metrics:# print(metrics)for pod in metrics:if pod['metric']:pod_name = pod['metric']['pod']values = [float(x[1]) for x in pod['values']]# values = round(sum(values)/len(values),2)values = round(max(values), 2)if pod_name not in pod_metric:pod_metric[pod_name] = {}pod_metric[pod_name]['gpu'] = values / 100except Exception as e:print(e)return pod_metric# @pysnooper.snoop()def get_namespace_resource_metric(self, namespace):max_cpu = 0max_mem = 0ave_gpu = 0pod_metric = {}# 这个pod 30分钟内的最大值mem_expr = "sum by (pod) (container_memory_working_set_bytes{namespace='%s',container!='POD', container!=''})" % (namespace,)# print(mem_expr)params = {'query': mem_expr,'start': int(time.time()) - 60*60*24,'end': int(time.time()),'step': "1m", # 运行小于1分钟的,将不会被采集到# 'timeout':"30s"}print(params)try:res = requests.get(url=self.query_range_path, params=params)metrics = json.loads(res.content.decode('utf8', 'ignore'))if metrics['status'] == 'success':metrics = metrics['data']['result']if metrics:for pod in metrics:pod_name = pod['metric']['pod']values = max([float(x[1]) for x in pod['values']])if pod_name not in pod_metric:pod_metric[pod_name] = {}pod_metric[pod_name]['memory'] = round(values / 1024 / 1024 / 1024, 2)except Exception as e:print(e)cpu_expr = "sum by (pod) (rate(container_cpu_usage_seconds_total{namespace='%s',container!='POD'}[1m]))" % (namespace)params = {'query': cpu_expr,'start': int(time.time()) - 60*60*24,'end': int(time.time()),'step': "1m", # 运行小于1分钟的,将不会被采集到# 'timeout':"30s"}print(params)try:res = requests.get(url=self.query_range_path, params=params)metrics = json.loads(res.content.decode('utf8', 'ignore'))if metrics['status'] == 'success':metrics = metrics['data']['result']if metrics:for pod in metrics:pod_name = pod['metric']['pod']values = [float(x[1]) for x in pod['values']]# values = round(sum(values) / len(values), 2)values = round(max(values), 2)if pod_name not in pod_metric:pod_metric[pod_name] = {}pod_metric[pod_name]['cpu'] = valuesexcept Exception as e:print(e)gpu_expr = "avg by (pod) (DCGM_FI_DEV_GPU_UTIL{namespace='%s'})" % (namespace)params = {'query': gpu_expr,'start': int(time.time()) - 60*60*24,'end': int(time.time()),'step': "1m", # 运行小于1分钟的,将不会被采集到# 'timeout':"30s"}print(params)try:res = requests.get(url=self.query_range_path, params=params)metrics = json.loads(res.content.decode('utf8', 'ignore'))if metrics['status'] == 'success':metrics = metrics['data']['result']if metrics:# print(metrics)for pod in metrics:pod_name = pod['metric']['pod']values = [float(x[1]) for x in pod['values']]# values = round(sum(values)/len(values),2)values = round(max(values), 2)if pod_name not in pod_metric:pod_metric[pod_name] = {}pod_metric[pod_name]['gpu'] = values / 100except Exception as e:print(e)return pod_metric# @pysnooper.snoop()def get_pod_resource_metric(self, pod_name, namespace):max_cpu = 0max_mem = 0ave_gpu = 0# 这个pod 30分钟内的最大值mem_expr = "sum by (pod) (container_memory_working_set_bytes{namespace='%s', pod=~'%s.*',container!='POD', container!=''})"%(namespace,pod_name)# print(mem_expr)params = {'query': mem_expr,'start': int(time.time()) - 60*60*24,'end': int(time.time()),'step': "1m", # 运行小于1分钟的,将不会被采集到# 'timeout':"30s"}print(params)try:res = requests.get(url=self.query_range_path, params=params)metrics = json.loads(res.content.decode('utf8', 'ignore'))if metrics['status'] == 'success':metrics = metrics['data']['result']if metrics:metrics = metrics[0]['values']for metric in metrics:if int(metric[1]) > max_mem:max_mem = int(metric[1]) / 1024 / 1024 / 1024except Exception as e:print(e)cpu_expr = "sum by (pod) (rate(container_cpu_usage_seconds_total{namespace='%s',pod=~'%s.*',container!='POD'}[1m]))" % (namespace, pod_name)params = {'query': cpu_expr,'start': int(time.time()) - 60*60*24,'end': int(time.time()),'step': "1m", # 运行小于1分钟的,将不会被采集到# 'timeout':"30s"}print(params)try:res = requests.get(url=self.query_range_path, params=params)metrics = json.loads(res.content.decode('utf8', 'ignore'))if metrics['status'] == 'success':metrics = metrics['data']['result']if metrics:metrics = metrics[0]['values']for metric in metrics:if float(metric[1]) > max_cpu:max_cpu = float(metric[1])except Exception as e:print(e)gpu_expr = "avg by (pod) (DCGM_FI_DEV_GPU_UTIL{namespace='%s',pod=~'%s.*'})" % (namespace, pod_name)params = {'query': gpu_expr,'start': int(time.time()) - 60*60*24,'end': int(time.time()),'step': "1m", # 运行小于1分钟的,将不会被采集到# 'timeout':"30s"}print(params)try:res = requests.get(url=self.query_range_path, params=params)metrics = json.loads(res.content.decode('utf8', 'ignore'))if metrics['status'] == 'success':metrics = metrics['data']['result']if metrics:metrics = metrics[0]['values']all_util = [float(metric[1]) for metric in metrics]ave_gpu = sum(all_util) / len(all_util) / 100except Exception as e:print(e)return {"cpu": round(max_cpu, 2), "memory": round(max_mem, 2), 'gpu': round(ave_gpu, 2)}# todo 获取机器的负载补充完整# @pysnooper.snoop()def get_machine_metric(self):# 这个pod 30分钟内的最大值metrics = {"pod_num": "sum(kubelet_running_pod_count)by (node)","request_memory": "","request_cpu": "","request_gpu": "","used_memory": "","used_cpu": "","used_gpu": "",}back = {}for metric_name in metrics:# print(mem_expr)params = {'query': metrics[metric_name],'timeout': "30s"}print(params)back[metric_name] = {}try:res = requests.get(url=self.query_path, params=params)metrics = json.loads(res.content.decode('utf8', 'ignore'))if metrics['status'] == 'success':metrics = metrics['data']['result']if metrics:for metric in metrics:node = metric['metric']['node']if ':' in node:node = node[:node.index(':')]value = metric['value'][1]back[metric_name][node] = int(value)except Exception as e:print(e)return backPrometheus 查询语法使用一种类似于函数式编程的表达方式,允许用户从时间序列数据库中提取和聚合数据。你提供的查询语句 cpu_expr 是一个典型的 Prometheus 查询,下面是对其各个部分的详细讲解:
-
函数
sum:是一个聚合函数,用于对一组时间序列进行求和。它可以用于计算所有匹配指标的总和。 -
by (pod)这是一个分组操作,表示将结果按pod标签进行分组。这样,查询结果将显示每个 pod 的 CPU 使用量总和。 -
rate(container_cpu_usage_seconds_total{...}[1m]):rate是一个用于计算时间序列速率的函数。在这里,它计算container_cpu_usage_seconds_total指标在过去 1 分钟内的变化率。container_cpu_usage_seconds_total是一个计数器类型的指标,表示容器 CPU 使用时间的总和。{namespace='%s',container!='POD'}是一个标签选择器,用于过滤指标。它选择特定命名空间下的所有容器,但排除了名为POD的容器。
- 整体而言,这个查询的目的是计算指定命名空间下,所有非
POD容器的 CPU 使用率,并按每个 pod 进行分组。通过使用rate函数,它可以提供 CPU 使用的实时速率,而不是总使用时间,这样更能反映容器的当前状态。
def echart(self, filters=None):prometheus = Prometheus(conf.get('PROMETHEUS', 'prometheus-k8s.monitoring:9090'))# 获取 prometheus-k8s 地址pod_resource_metric = prometheus.get_resource_metric()print('pod_resource_metric', pod_resource_metric)all_resource = {"mem_all": sum([int(global_cluster_load[cluster_name]['mem_all']) for cluster_name in global_cluster_load]),"cpu_all": sum([int(global_cluster_load[cluster_name]['cpu_all']) for cluster_name in global_cluster_load]),"gpu_all": sum([int(global_cluster_load[cluster_name]['gpu_all']) for cluster_name in global_cluster_load]),}all_resource_req = {"mem_req": sum([int(global_cluster_load[cluster_name]['mem_req']) for cluster_name in global_cluster_load]),"cpu_req": sum([int(global_cluster_load[cluster_name]['cpu_req']) for cluster_name in global_cluster_load]),"gpu_req": sum([int(global_cluster_load[cluster_name]['gpu_req']) for cluster_name in global_cluster_load]),}all_resource_used = {"mem_used": sum([pod_resource_metric[x].get('memory', 0) for x in pod_resource_metric]),"cpu_used": sum([pod_resource_metric[x].get('cpu', 0) for x in pod_resource_metric]),"gpu_used": sum([pod_resource_metric[x].get('gpu', 0) for x in pod_resource_metric]),}option = {"title": [{"subtext": __('集群信息'),"MEM_NAME": __('内存请求占有率'),"MEM_VALUE": int(100 * all_resource_req['mem_req'] / (0.001 + all_resource['mem_all'])),"CPU_NAME": __('CPU占用率'),"CPU_VALUE": int(all_resource['cpu_all']),'GPU_NAME': __('GPU总量(卡)'),'GPU_VALUE': int(all_resource['gpu_all']),'MEM_MAX': int(all_resource['mem_all'] * 2),'CPU_MAX': int(all_resource['cpu_all'] * 2),'GPU_MAX': int(all_resource['gpu_all'] * 2)},{"subtext": __('资源占用率'),"MEM_NAME": __('内存占用率'),"MEM_VALUE": int(100 * all_resource_req['mem_req'] / (0.001 + all_resource['mem_all'])),"CPU_NAME": __('CPU占用率'),"CPU_VALUE": int(100 * all_resource_req['cpu_req'] / (0.001 + all_resource['cpu_all'])),"GPU_NAME": __('GPU占用率'),"GPU_VALUE": int(100 * all_resource_req['gpu_req'] / (0.001 + all_resource['gpu_all']))},{"subtext": __('资源利用率'),'MEM_NAME': __('内存利用率'),'MEM_VALUE': str(min(100,int(100 *all_resource_used['mem_used'] / (0.001 +all_resource['mem_all'])))),'CPU_NAME': __('CPU利用率'),'CPU_VALUE': str(min(100, int(100 *all_resource_used['cpu_used'] / (0.001 +all_resource['cpu_all'])))),'GPU_NAME': __('GPU利用率'),'GPU_VALUE': str(min(100, int(100 *all_resource_used['gpu_used'] / (0.001 +all_resource['gpu_all']))))}]}return option附一个用上面代码实现的运维表盘界面

相关文章:
实现prometheus+grafana的监控部署
直接贴部署用的文件信息了 kubectl label node xxx monitoringtrue 创建命名空间 kubectl create ns monitoring 部署operator kubectl apply -f operator-rbac.yml kubectl apply -f operator-dp.yml kubectl apply -f operator-crd.yml # 定义node-export kubectl app…...

确保Spring Boot定时任务只执行一次方案
在Spring Boot项目中,确保定时任务只执行一次是一个常见的需求。这种需求可以通过多种方式来实现,以下是一些常见的方法,它们各具特点,可以根据项目的实际需求来选择最合适的方法。 1. 使用Scheduled注解并设置极大延迟 一种简单…...

【Python数据可视化】利用Matplotlib绘制美丽图表!
【Python数据可视化】利用Matplotlib绘制美丽图表! 数据可视化是数据分析过程中的重要步骤,它能直观地展示数据的趋势、分布和相关性,帮助我们做出明智的决策。在 Python 中,Matplotlib 是最常用的可视化库之一,它功能…...

【最新通知】2024年Cisco思科认证CCNA详解
CCNA现在涵盖安全性、自动化和可编程性。该计划拥有一项涵盖IT职业基础知识的认证,包括一门考试和一门培训课程,助您做好准备。 CCNA培训课程和考试最近面向最新技术和工作岗位进行了重新调整,为您提供了向任何方向发展事业所需的基础。CCNA认…...

监控内容、监控指标、监控工具大科普
在现代信息技术领域,监控技术扮演着至关重要的角色。它帮助我们实时了解系统、网络、应用以及环境的状态,确保它们的安全、稳定和高效运行。以下是对监控内容、监控指标和监控工具的详细科普。 一、监控内容 监控内容是指监控系统所关注和记录的具体信…...

生成文件夹 - python 实现
生成文件夹保存图片和文本等信息。 代码具体实现如下: #-*-coding:utf-8-*- # date:2021-04-13 # Author: DataBall - XIAN # Function: 生成文件夹import os if __name__ "__main__":path "./dataset"if not os.path.exists(path): # 如果…...
快速了解学会python基础语言及IDLE 提供的常用快捷键
😀前言 本篇博文是关于python的基础语言介绍及IDLE 提供的常用快捷键,希望你能够喜欢 🏠个人主页:晨犀主页 🧑个人简介:大家好,我是晨犀,希望我的文章可以帮助到大家,您的…...

【python】OpenCV—Sort the Point Set from Top Left to Bottom Right
文章目录 1、功能描述2、代码实现3、效果展示4、更多例子5、参考 1、功能描述 给出一张图片,里面含有各种图形,取各种图形的中心点,从左到右从上到下排序 例如 2、代码实现 import cv2 import numpy as npdef process_img(img):img_gray c…...

LeetCode 1493.删掉一个元素以后全为1的最长子数组
题目: 给你一个二进制数组 nums ,你需要从中删掉一个元素。 请你在删掉元素的结果数组中,返回最长的且只包含 1 的非空子数组的长度。 如果不存在这样的子数组,请返回 0 。 思路:不定长滑动窗口,将问题…...

php常用设计模式之工厂模式
引言 在日常开发中,我们一些业务场景需要用到发送短信通知。然而实际情况考虑到不同厂商之间的价格、实效性、可能会出现的情况等 我们的业务场景往往会接入多个短信厂商来保证我们业务的正常运行,而不同的短信厂商(如阿里云短信、腾讯云短信…...

通用软件版本标识
软件版本标识:了解不同的版本类型 在软件开发和发布过程中,版本号和标识扮演着重要的角色。它们不仅帮助开发者追踪软件的演变,还让用户了解软件的稳定性和功能。以下是一些常见的软件版本标识,以及它们的含义和用途。 Alpha&am…...
基于SpringBoot的就业平台开题报告)
(计算机毕设)基于SpringBoot的就业平台开题报告
一、立题依据(国内外研究进展或选题背景、研究意义等) 国内外研究进展或选题背景 在全球化的大背景下,就业问题一直是各国政府和社会各界关注的焦点。随着互联网技术的普及和发展,网络招聘已成为求职者和企业招聘的主要渠道。据相关数据显示࿰…...
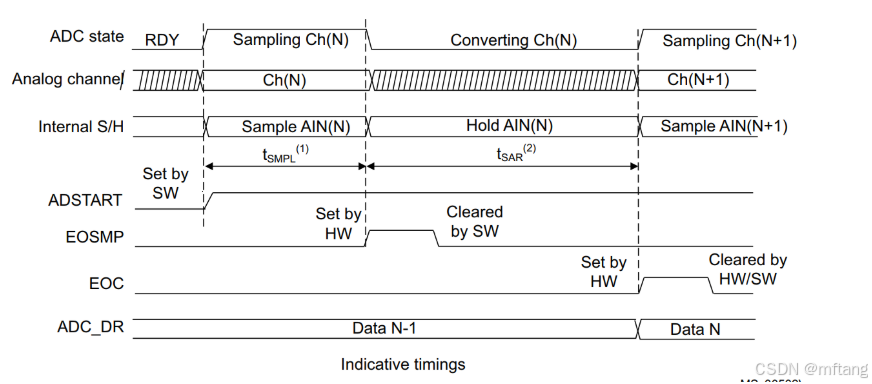
STM32G4系列MCU的ADC模块标定方法和采样时间
目录 概述 1 ADC模块标定 1.1 功能介绍 1.2 软件程序校准ADC 1.2.1 标定步骤 1.2.2 标定时序框图 1.3 软件程序重新注入校准因子到ADC 1.3.1 标定步骤 1.3.2 更新ADC校准因子 1.4 用单个ADC转换单端和差分模拟输入 1.4.1 标定流程 1.4.2 混合单端和差分通道 2 通道…...

NVIDIA Jetson支持的神经网络加速的量化平台
NVIDIA Jetson支持的神经网络加速的量化工具、技术 NVIDIA Jetson 是专为边缘计算和嵌入式系统设计的高性能计算平台,它支持多种深度学习模型的部署和推理。对于神经网络加速的量化平台,Jetson 支持以下技术和工具: TensorRT:Ten…...

MySQL 免密登录的几种配置方式
文章目录 MySQL 免密登录的几种配置方式使用操作系统用户实现免密登录具体步骤:Step 1: 修改 MySQL 配置文件Step 2: 重启 MySQL 服务Step 3: 使用系统用户登录 MySQL优点:缺点: 使用 mysql_config_editor 配置免密文件具体步骤:S…...

html全局属性、框架标签
常用的全局属性: 属性名含义id 给标签指定唯一标识,注意:id是不能重复的。 作用:可以让label标签与表单控件相关联;也可以与css、JavaScript配合使用。 注意:不能再以下HTML元素中使用:<hea…...

ARL 灯塔 | CentOS7 — ARL 灯塔搭建流程(Docker)
关注这个工具的其它相关内容:自动化信息收集工具 —— ARL 灯塔使用手册 - CSDN 博客 灯塔,全称:ARL 资产侦察灯塔系统,有着域名资产发现和整理、IP/IP 段资产整理、端口扫描和服务识别、WEB 站点指纹识别、资产分组管理和搜索等等…...
抖音列表页采集-前言
准备工作: 1.关于selenium介绍: python自动化入门的话,selenium绝对是最方便的选择,基本逻辑即为:程序模拟人的行为操作浏览器,这样的操作需要借用浏览器驱动,我选用的是chrome浏览器ÿ…...

Linux 端口占用 kill被占用的端口 杀掉端口
1、yum install lsof 2、输入netstat -tln,查看系统当前所有被占用端口 3、根据端口查询进程,输入lsof -i :9555,切记不要忘了添加冒号 4、 既然知道进程号了,那杀死当前进程就简单多了,直接 kill -9 PID 回车...

爬虫之数据解析
数据解析 数据解析这篇内容, 很多知识涉及到的都是以前学习过的内容了, 那这篇文章我们主要以实操为主, 来展开来讲解关于数据解析的内容。 360搜索图片 请求的url大家不需要再找了, 相信大家都会找请求了, 寻找请求从我的第一篇爬虫的博客开始到现在一直都在写,这边的话, 我已…...

重塑Word排版效率——多级列表与自动编号的进阶应用
1. 为什么你的Word文档总是排版混乱? 每次打开同事发来的Word文档,最让我头疼的就是那些乱七八糟的编号格式。明明应该是"1.1"的子标题,突然变成了"5.3";精心调整的缩进距离,传到别人电脑上就完全…...

高性能WebGL地图引擎OME:海量地理空间数据可视化实战指南
1. 项目概述与核心价值 如果你在开源社区里混迹过一段时间,尤其是对数据可视化、地理信息系统或者大规模图数据渲染感兴趣,那么“sgl-project/ome”这个项目标题很可能已经引起了你的注意。OME,全称可能是“Open Map Engine”或类似的概念&am…...

树莓派5 vs 树莓派4:从硬件架构到应用场景的全面对比与实战指南
1. 项目概述:为什么我们需要重新审视树莓派5?如果你和我一样,从树莓派2、3、4一路用过来,每次新版本发布都像是一次“挤牙膏”式的升级,那么树莓派5的到来,绝对会打破你的固有印象。它不再仅仅是“更快一点…...

惠普OMEN游戏本终极性能优化:OmenSuperHub开源工具完全指南
惠普OMEN游戏本终极性能优化:OmenSuperHub开源工具完全指南 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 还在为惠普OMEN游戏本官方软件的臃…...

书成紫微动律定凤凰驯:抛开网络臆想歪论正视海棠山铁哥的大道凰标之道
——褪去网络流言,正视正统文脉网络世间众说纷纭,流言四起,诸多无根揣测、片面臆想肆意流传。 不少人未曾静心品读深意,仅凭只言片语便妄加评判,或是跟风曲解本意,或是刻意附会杂论,更有甚者凭空…...

Netscape 浏览器:互联网时代的先驱者
Netscape 浏览器:互联网时代的先驱者 引言 自互联网诞生以来,浏览器作为连接用户与网络世界的重要工具,见证了互联网的飞速发展。在众多浏览器中,Netscape 浏览器以其创新和引领潮流的特性,成为了互联网时代的先驱者。本文将回顾 Netscape 浏览器的发展历程、技术特点及…...

51单片机驱动SG90舵机:从PWM原理到按键控制实战
1. SG90舵机与51单片机的基础认知 第一次接触SG90舵机时,我盯着那三根彩色导线发愣——这玩意儿怎么就能精准控制角度呢?后来发现它其实是微型伺服系统的典型代表,红色接5V电源,褐色接地线,黄色信号线接任意IO口&#…...

如何在5分钟内掌握Illustrator智能填充神器Fillinger
如何在5分钟内掌握Illustrator智能填充神器Fillinger 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 还在为复杂的图案填充耗费数小时吗?今天我要为你介绍一款能彻底改变…...

LabVIEW与单片机协同开发:构建可交互硬件原型的通信与事件驱动架构
1. 项目概述与核心思路上次我们聊了用LabVIEW制作一个“iPhone”的初步构想和界面设计,很多朋友反馈说对如何将虚拟界面与实际硬件联动起来特别感兴趣。这第二集,我们就来深入聊聊这块硬骨头——如何让LabVIEW这个强大的图形化编程工具,真正驱…...

ZYNQ PS-PL协同实战:如何设计一个带触发与延时的多通道数据采集卡?
ZYNQ PS-PL协同实战:工业级多通道数据采集卡架构设计精要 在工业自动化与测试测量领域,数据采集系统的性能直接决定了整个系统的可靠性与精度。Xilinx ZYNQ系列SoC凭借其独特的ARM处理器(PS)与可编程逻辑(PL)协同架构,成为构建高性能数据采集…...