利用Arcgis进行沟道形态分析
在做项目的时候需要学习到水文分析和沟道形态分析的学习,所以自己摸索着做了下面的工作和内容。如有不对请多指正!!
一、沟道形态分析概述
沟道形态分析是水文分析的一个重要方面,用于研究河流的形态和特征。沟道形态分析可以帮助我们了解河流的走向、宽度、深度、坡度等特征,从而对河流的水文过程进行模拟和预测。这对于研究区域的地貌演化、水土流失、泥石流风险评估等具有重要意义。
二、准备工作
1. 数据准备
- 数字高程模型(DEM):获取高分辨率的DEM数据,常用的数据源有SRTM、ASTER GDEM或LiDAR数据。我们的数据来源于无人机数据,经过密集点云的构建后,创建DEM并输出。
对于该部分我的操作见下方博文:
MetaShape+CloudCompare的一些基本操作(一)-CSDN博客文章浏览阅读811次,点赞29次,收藏30次。学习影像拼接和影像点云数据提取的小笔记(一)。有不对的地方多多指正,都是自己摸索出来的,可能会有很多不对的地方,请多指正_metashapehttps://blog.csdn.net/Johaden/article/details/142639796注意:在创建DEM的时候,我选的就是WGS84_UTM_Zone_49N,也就是投影坐标系,这样做可以省下后面在Arcgis中投影转换的步骤。
因为无人机的坐标系为WGS_84的地心坐标系,所以上面博客里面的CGCS2000投影坐标系其实并不好转换,需要填写一个转换参数。而又因为UTM投影在科研中比较常用,所以就采用了上述的投影坐标系。
2. 软件准备
- ArcGIS(版本建议10.2及以上)下方的操作版本为10.8.1
- Arc Hydro Tools(如果使用ArcGIS,可安装该工具箱进行水文分析)。
- Spatial Analyst扩展模块(ArcGIS自带)。
三、详细操作步骤
1. 导入DEM数据
- 打开ArcMap。
- 点击“文件(File)”->“添加数据(Add Data)”,选择您的DEM文件(.tif或.img格式),点击“添加”。(更推荐链接文件夹!!)
2. DEM预处理
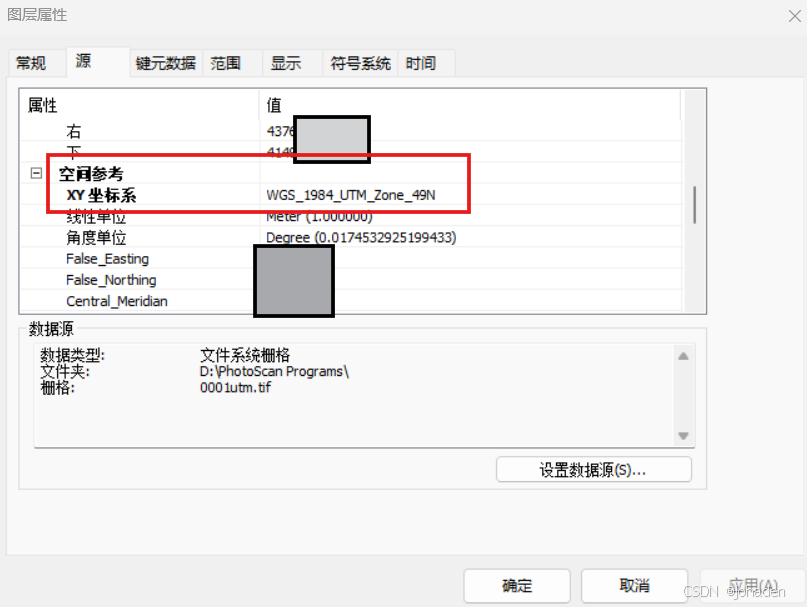
(1)投影设置
- 右键DEM图层,选择“属性(Properties)”,在“源(Source)”选项卡中确认坐标系。
- 如果坐标系不符合分析要求(如需要投影到UTM坐标系),使用“投影(Project Raster)”工具进行投影转换。
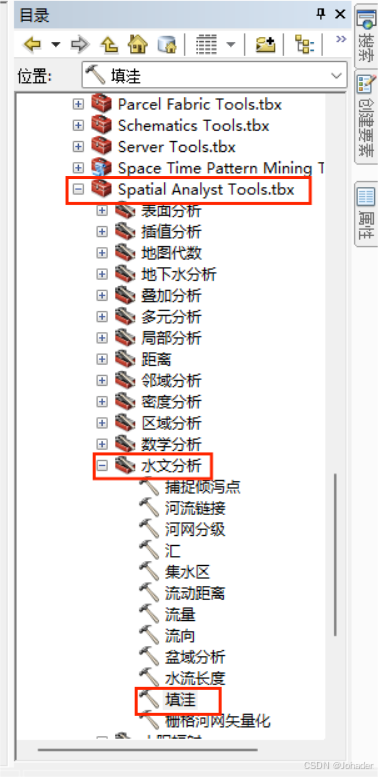
(2)填洼(Fill Sinks)
- 打开“ArcToolbox” -> “Spatial Analyst Tools” -> “Hydrology(水文分析)” -> “Fill”。
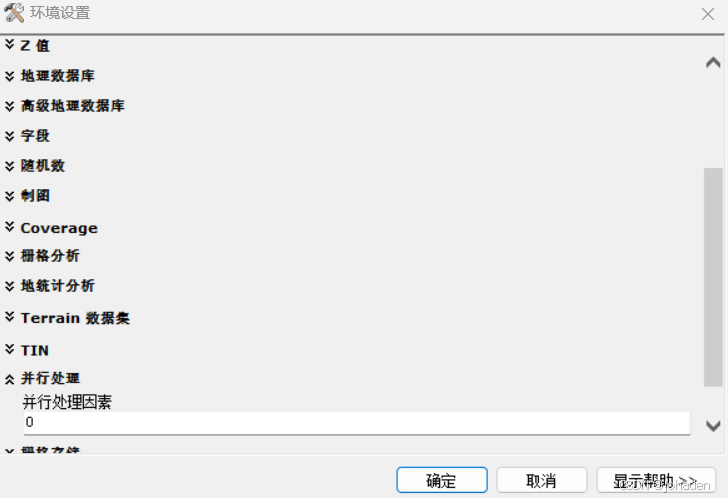
- 在“Fill”工具中:
- Input surface raster(输入表面栅格):选择您的DEM数据。
- Output surface raster(输出表面栅格):设置输出路径和文件名(如Filled_DEM)。
- 点击“环境”-并行处理设置为0。
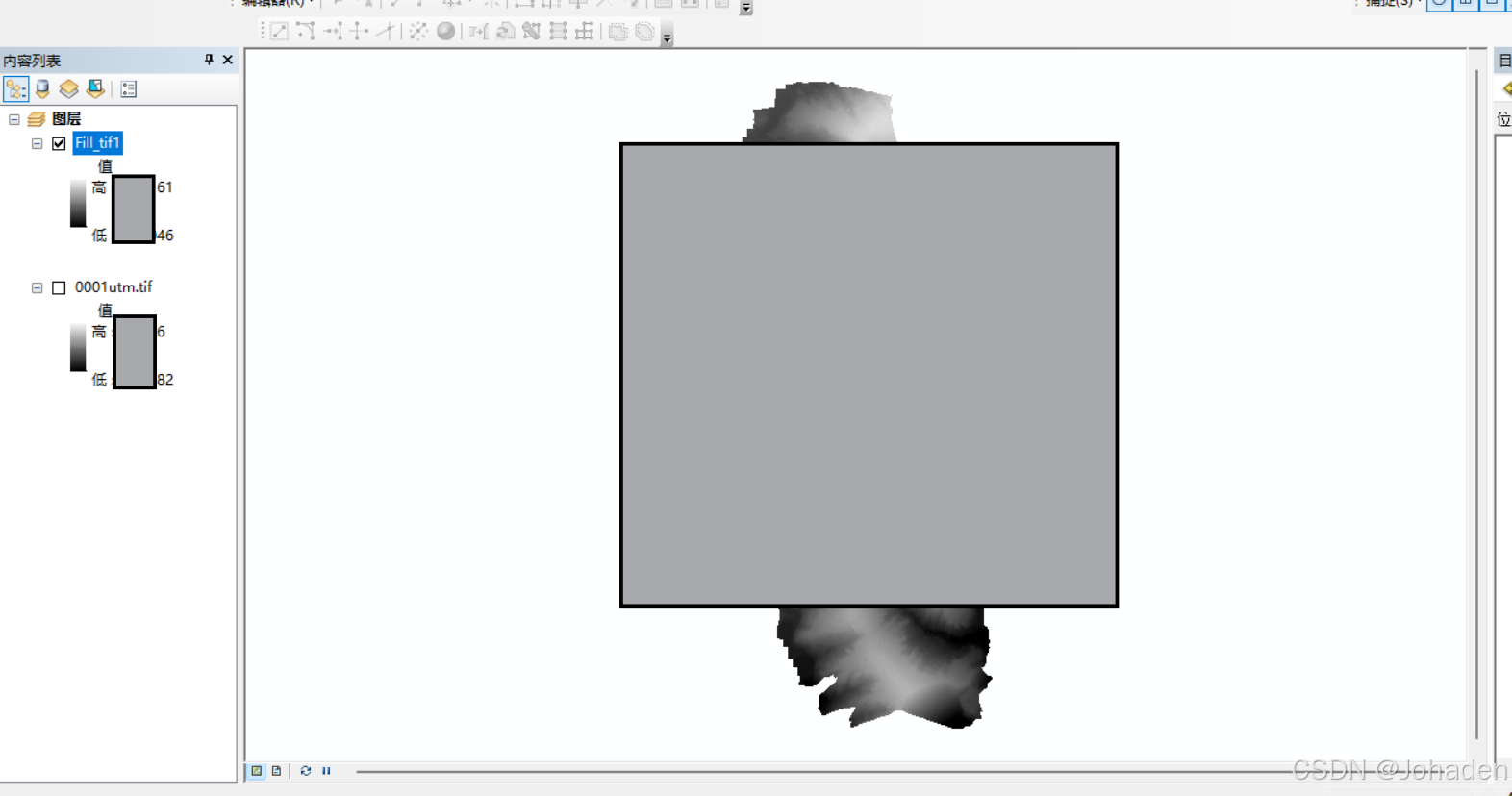
- 点击“OK”执行操作。该步骤用于填充DEM中的洼地,避免流水路径中断。
3. 生成流向和流量累积栅格
(1)计算流向(Flow Direction)
- 打开“Spatial Analyst Tools” -> “Hydrology” -> “Flow Direction”(流向)。
- 在“Flow Direction”工具中:
- Input surface raster:选择填洼后的DEM(Filled_tif1)。
- Output flow direction raster:设置输出路径和文件名(如Flow_Direction)。
同理,打开【环境设置】找到【并行处理】标签,将“并行处理因素”空白处填入“0”)→【确定】
- 点击“OK”执行操作。
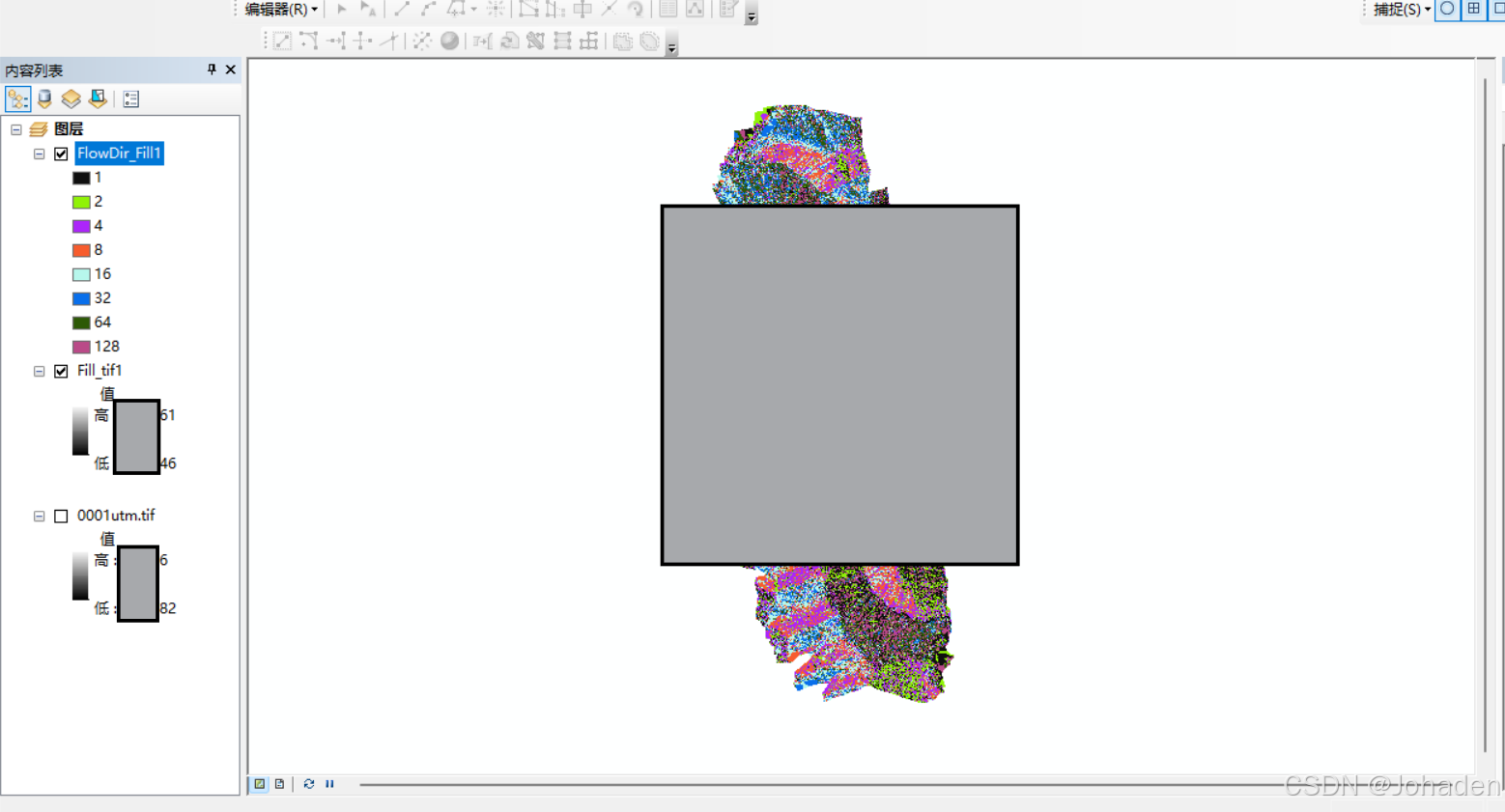
其中:
- 1:流向右方(东)
- 2:流向右下方(东南)
- 4:流向下方(南)
- 8:流向左下方(西南)
- 16:流向左方(西)
- 32:流向左上方(西北)
- 64:流向上方(北)
- 128:流向右上方(东北)
PS:强制所有像元向外流动是什么?什么时候勾选?
在进行流向分析时,有一个选项叫做“强制所有像元向外流动”(Force All Cells to Flow Out of the Domain)。这个选项的作用和适用场景如下:
当启用此选项时,ArcGIS 会确保所有位于研究区域边界上的像元的水流方向都指向研究区域的外部。这意味着即使这些边界像元的实际地形可能指示水流应该流入研究区域内部,它们也会被强制设置为流出研究区域。
这个选项主要用于避免水流在研究区域的边界上形成循环或停滞,确保所有的水流最终都能离开研究区域。
在这个示例中,矩形的边缘就是研究区域的边界。假设这个研究区域的数字高程模型(DEM)如下所示:
+-------------------+
| 10 10 10 10 10 10 10 10 10 10 |
| 10 10 10 10 10 10 10 10 10 10 |
| 10 10 10 10 10 10 10 10 10 10 |
| 10 10 10 10 10 10 10 10 10 10 |
| 10 10 10 10 8 8 8 10 10 10 |
| 10 10 10 10 8 5 8 10 10 10 |
| 10 10 10 10 8 8 8 10 10 10 |
| 10 10 10 10 10 10 10 10 10 10 |
| 10 10 10 10 10 10 10 10 10 10 |
| 10 10 10 10 10 10 10 10 10 10 |
+-------------------+在这个 DEM 中,数值表示高程,较低的数值表示洼地。假设你进行流向分析,不启用“强制所有像元向外流动”选项,流向结果可能如下所示:
+-------------------+
| ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ |
| ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ |
| ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ |
| ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ |
| ↓ ↓ ↓ ↓ ↘ ↘ ↘ ↓ ↓ ↓ |
| ↓ ↓ ↓ ↓ ↘ ↓ ↘ ↓ ↓ ↓ |
| ↓ ↓ ↓ ↓ ↘ ↘ ↘ ↓ ↓ ↓ |
| ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ |
| ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ |
| ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ |
+-------------------+可以看到,洼地内的水流方向是向内的,形成了一个闭环。
启用“强制所有像元向外流动”选项后,所有位于研究区域边界上的像元的水流方向都会被强制设置为指向研究区域外部。具体效果如下:
+-------------------+
| → → → → → → → → → → |
| ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ |
| ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ |
| ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ |
| ↓ ↓ ↓ ↓ ↘ ↘ ↘ ↓ ↓ ↓ |
| ↓ ↓ ↓ ↓ ↘ ↓ ↘ ↓ ↓ ↓ |
| ↓ ↓ ↓ ↓ ↘ ↘ ↘ ↓ ↓ ↓ |
| ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ |
| ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ |
| ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ |
+-------------------+可以看到,边界上的像元(最外层的像元)的水流方向被强制设置为指向外部,确保水流不会在边界处形成循环。
所以,在进行流向分析之前,先不勾选“强制所有像元向外流动”选项,查看初步结果。随后检查边界附近的水流方向,看是否存在明显的循环或停滞现象。
如果发现水流在边界处存在循环或停滞,尝试勾选“强制所有像元向外流动”选项,再次进行分析。对比两次分析的结果,看看区别大不大,我勾选后没发现什么大的区别。
(2)计算流量(Flow Accumulation)
- 打开“Spatial Analyst Tools” -> “Hydrology” -> “Flow Accumulation”(流量)。
- 在“Flow Accumulation”工具中:
- Input flow direction raster:选择上一步生成的流向栅格(Flow_Direction)。
- Output accumulation raster:设置输出路径和文件名(如Flow_Accumulation)。
同理,打开【环境设置】找到【并行处理】标签,将“并行处理因素”空白处填入“0”)→【确定】
- 点击“OK”执行操作。
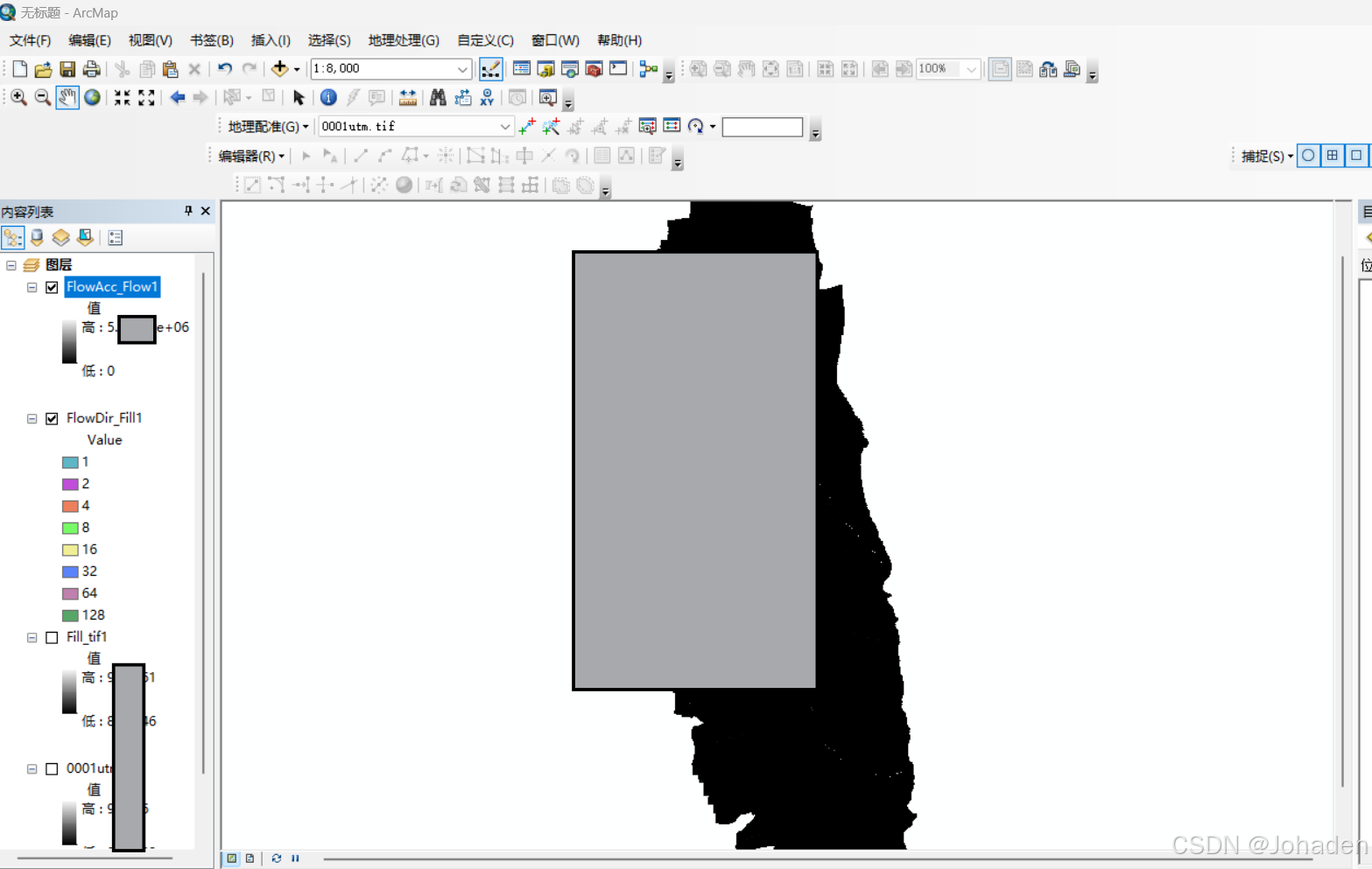
在流量累积图中,黑色背景表示累积流量较低或没有水流的区域,而白色线条表示累积流量较高的区域。具体来说:
- 黑色背景:这表示地表较为平坦或没有明显水流的区域。这些区域的累积流量值较低,通常接近于零。
- 白色线条:这些线条表示水流路径,通常是河流或溪流的位置。线条的粗细和亮度反映了累积流量的大小。线条越粗、越亮,表示累积流量越大。

通过流量累积分析,我们可以生成一个流量累积图,其中每个像元的值表示该像元及其上游所有像元的总累积流量。
4. 提取沟道网络
(1)设定阈值
- 根据研究区域的实际情况,确定一个阈值(如1000)。该阈值代表汇流累积值大于此值的区域将被视为沟道。
(2)使用栅格计算器
- 打开“Spatial Analyst Tools” -> “Map Algebra” -> “Raster Calculator(栅格计算器)”。
- 输入以下表达式:
Con("Flow_Accumulation" >= 1000, 1) (10-23补:阈值最终在输出坡度坡向图时选择了100)
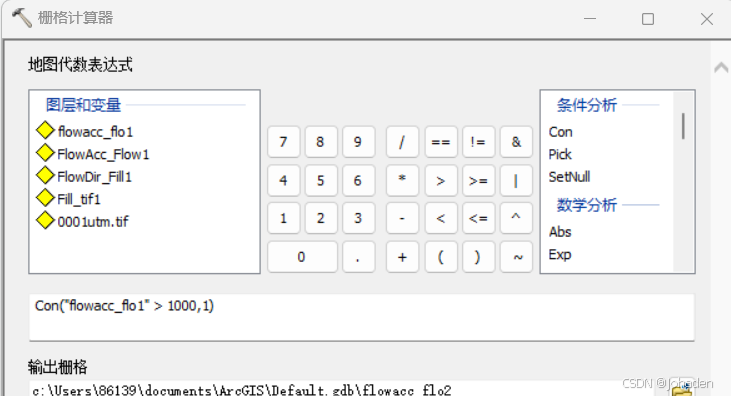
- 说明:“Flow_Accumulation”为之前生成的流量累积栅格,1000为设定的阈值,生成的“Stream”为二值栅格,值为1的像素代表沟道。
关于阈值,我们需要尝试使用不同的阈值(如 500、1000、5000 等),并将生成的水流路径与实际的河流网络对比。
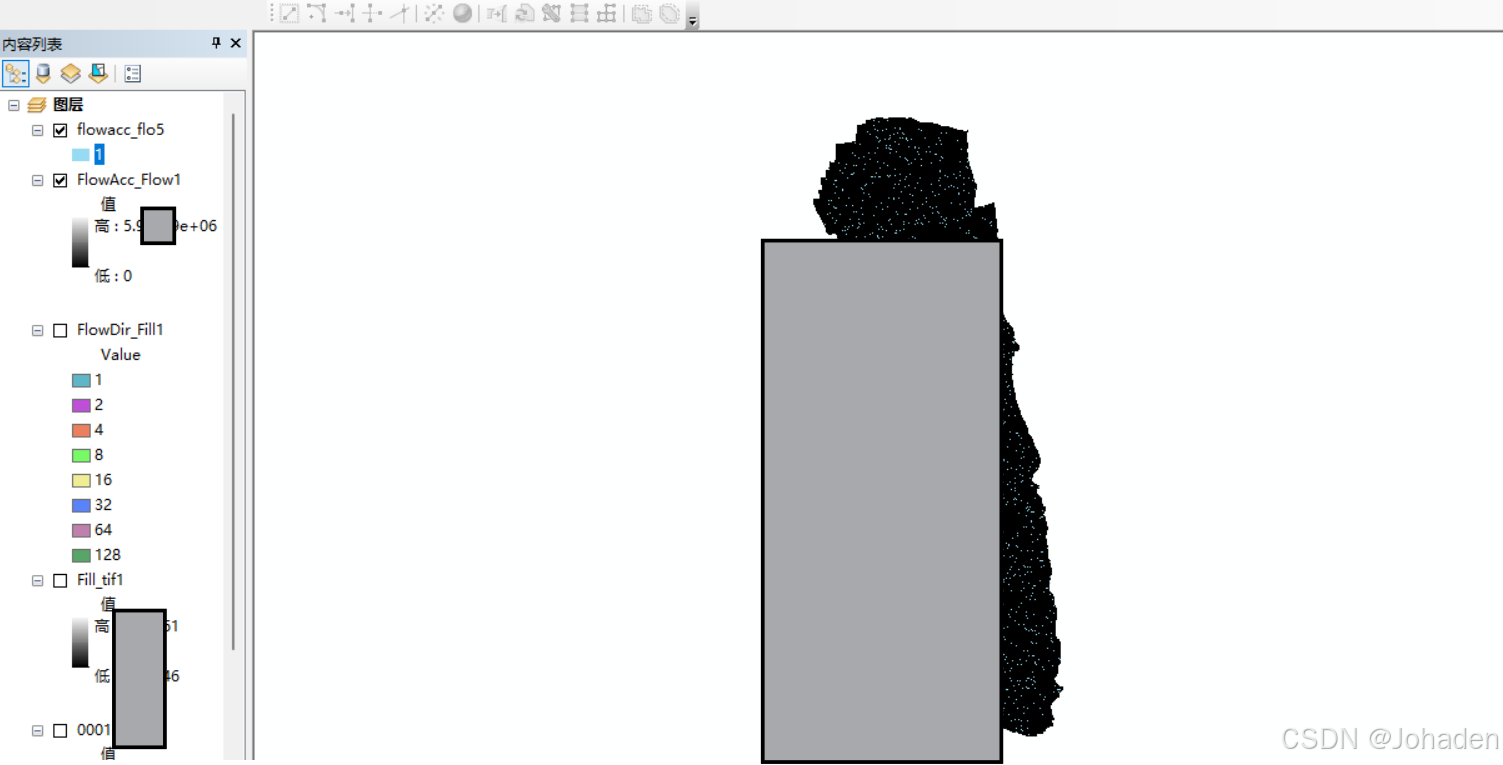
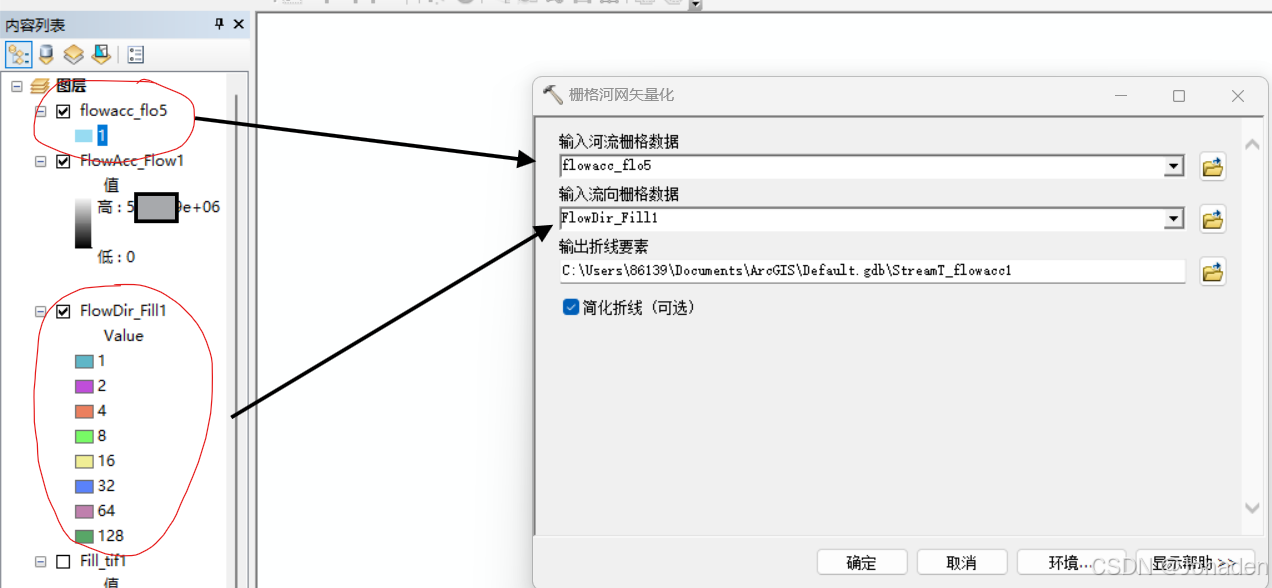
(3)将沟道栅格转换为矢量线
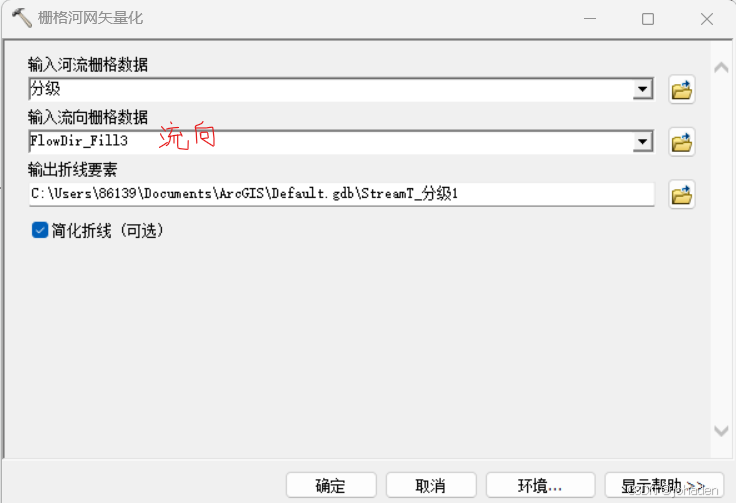
- 打开“Spatial Analyst Tools” -> “Hydrology” -> “Stream to Feature”(栅格河网矢量化)。
- 在“Stream to Feature”工具中:
- Input stream raster:选择“flowacc”栅格。(阈值处理的)
- Input flow direction raster:选择“Flow_Dir”栅格。(流向)
- Output polyline features:设置输出路径和文件名(如StreamT_flowacc1)。
- 点击“OK”执行操作。
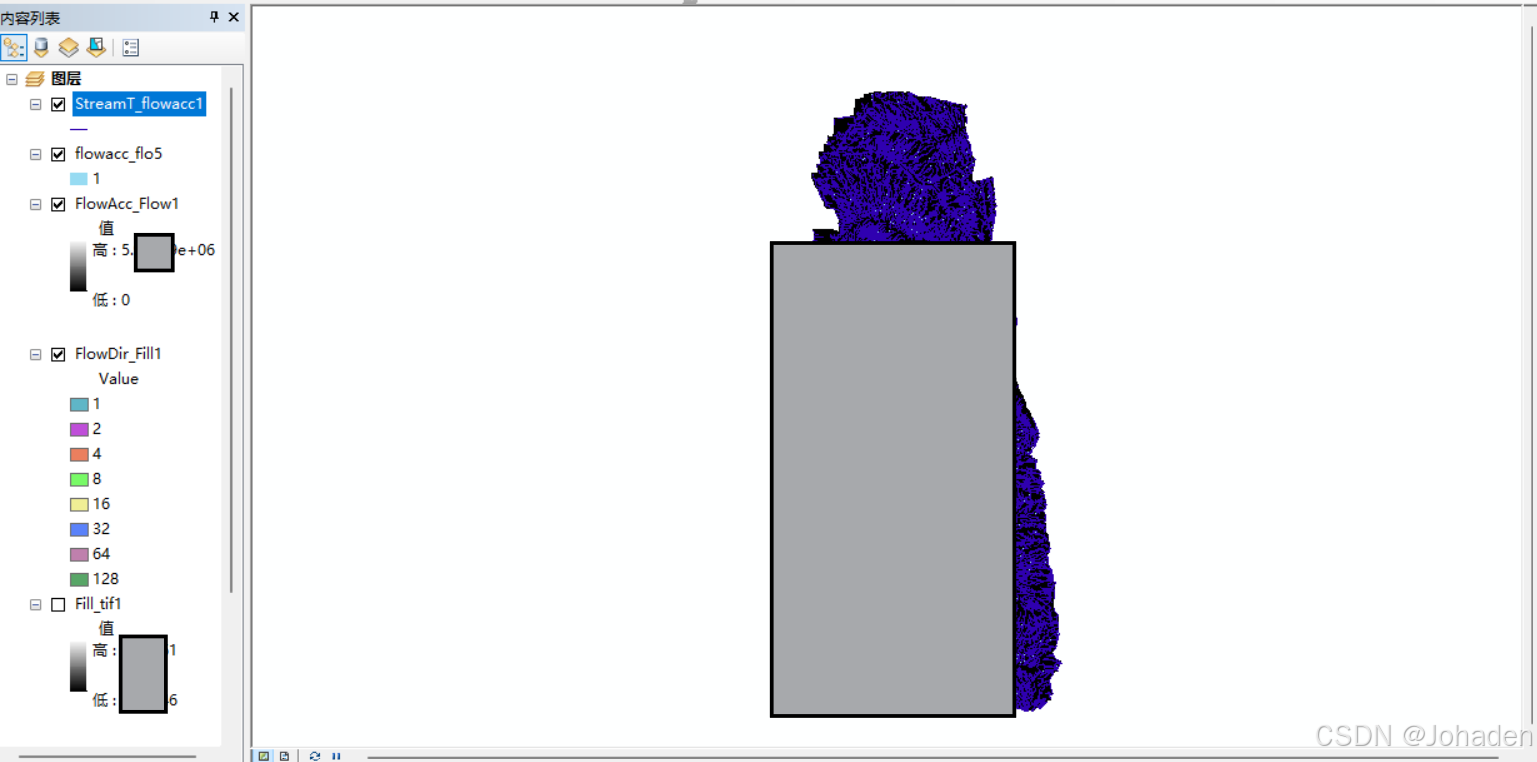
5. 计算沟道形态参数
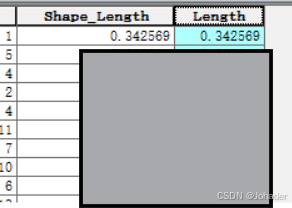
(1)计算沟道长度(一般情况下Arcgis会自动生成沟道长度,比如我的就是名为shape_length,如下所示,但是可能版本不同带来的效果不同,所以仍讲解一下若没有该长度怎么办?)
- 右键“StreamT_flowacc1”图层,选择“属性(Properties)”。
- 在“Symbology(符号系统)”选项卡,可以根据需要设置线的样式。
- 打开“属性表(Attribute Table)”,添加一个新字段:
- 点击“Table Options(表选项)” -> “Add Field(添加字段)”。
- 字段名称设为“Length”,类型选择“Double”。
- 计算长度:
- 右键“Length”字段,选择“Calculate Geometry(计算几何属性)”。
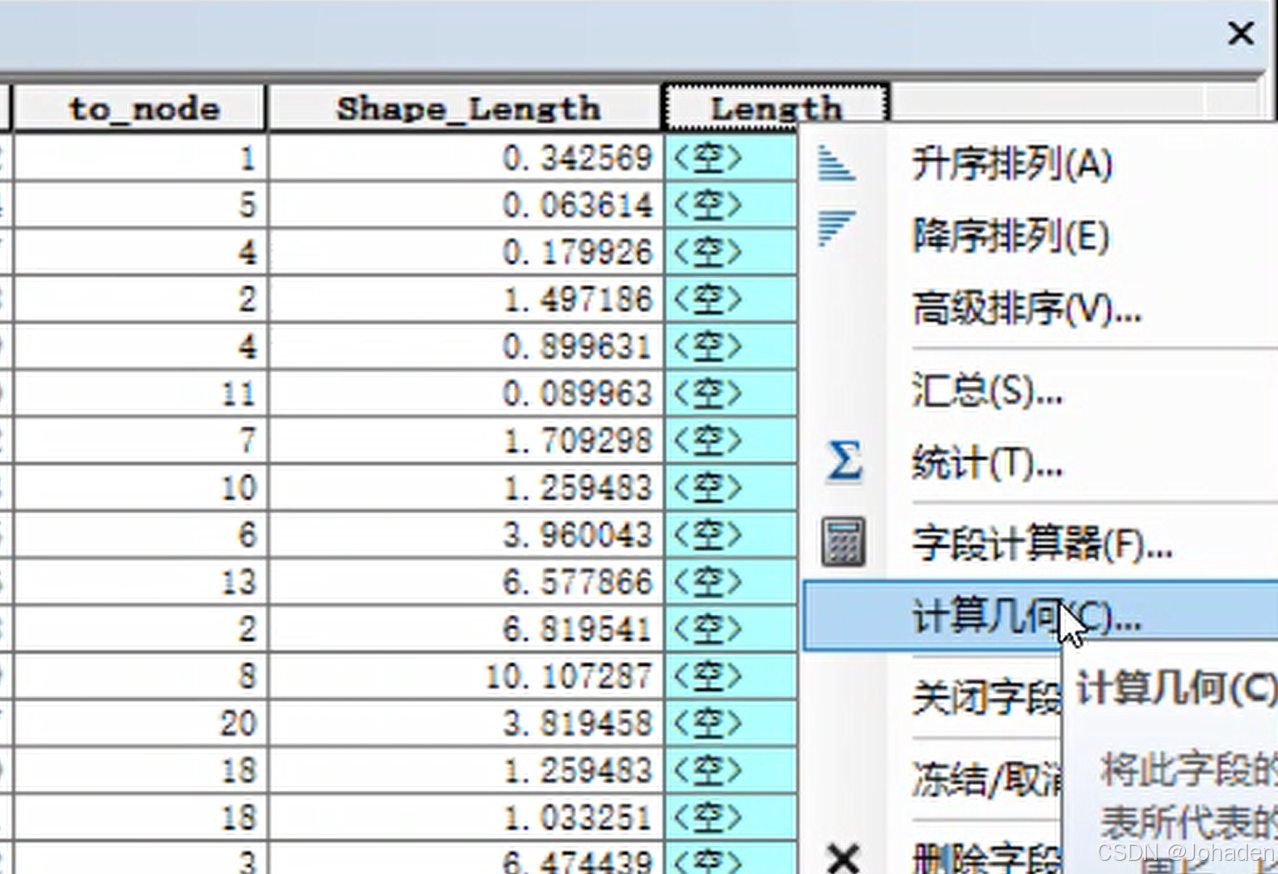
- 属性选为“长度(Length)”,单位根据需要选择(如米)。
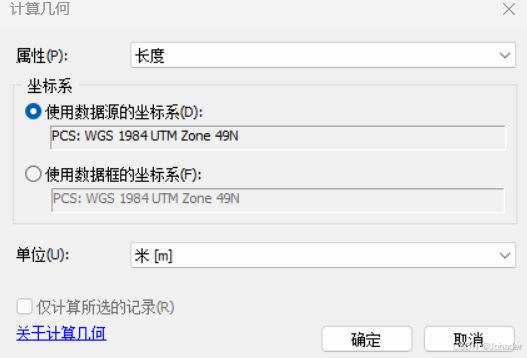
- 点击“OK”执行。(经对比发现两者相同,所以证明上述操作正确!)
(2)计算沟道坡度
- 生成坡度栅格:
- 打开“Spatial Analyst Tools” -> “Surface(表面分析)” -> “Slope(坡度)”。
- Input raster:选择填洼后的DEM(Filled_DEM)。
- Output raster:设置输出路径和文件名(如Slope)。
- 单位可以选择“度(下图)”或“百分比”。

- 将坡度值提取到沟道线上:
我之前想使用“提取值至点”,但是由于“提取值至点”(Extract Values to Points)工具只接受点要素作为输入(虽然可以转化为点,但是最后还是需要将点要素的属性加入回线要素,比较麻烦),而不能直接对线要素提取坡度值,所以我们可以使用“添加表面信息”(Add Surface Information)工具来实现将坡度值提取到沟道线上的目的。
- 确保已安装3D Analyst扩展模块:先在“自定义”->“扩展模块”中启用3D Analyst扩展模块。
- 打开“添加表面信息”工具:进入“ArcToolbox” -> “3D Analyst Tools” -> “Surface” -> “Add Surface Information”。
- 设置输入参数:
Input Feature Class(输入要素类):选择您的沟道线要素(如“StreamT_flowacc1”)。
Input Surface(输入表面):选择您的坡度栅格数据(如“Slope”)。
Surface Information(表面信息):勾选“Z_MEAN”,这样工具会计算每条线要素在坡度栅格上的平均坡度值。
- 点击“OK”或“运行”按钮,开始处理。
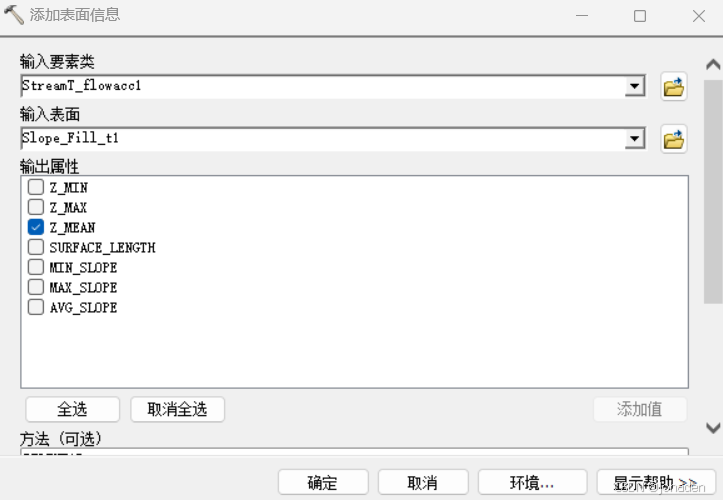
处理完成后,打开沟道线要素的属性表,就会发现多了一个字段(如“Z_MEAN”),其中包含了每条线对应的平均坡度值。
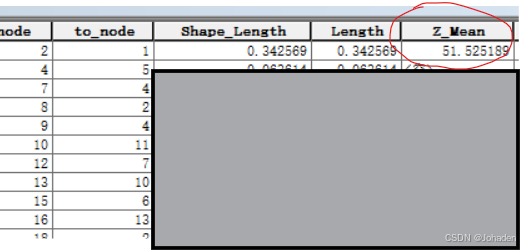
疑问:为什么输出属性要选择Z_mean而不是AVG_Slope?
1. 参数含义
(1)Z_MEAN
定义:计算输入要素在输入表面(栅格或TIN)上的Z值的平均值。(不单单指高程!!!)
适用情况:想要知道线要素在特定栅格表面(如坡度栅格、海拔栅格)上所覆盖区域的平均值时使用。
结果:对于坡度栅格,Z_MEAN会给出线要素在坡度栅格上的平均坡度值。
(2)AVG_SLOPE
定义:计算输入要素自身的平均坡度,基于要素的高程变化和水平距离。
适用情况:当有三维线要素(具有高程值的线,如3D多段线),并希望计算线要素自身的坡度时使用。
结果:AVG_SLOPE给出的是线要素自身的坡度,而不是其在栅格表面上的坡度。
不选择AVG_SLOPE的原因
限制造成的误解:AVG_SLOPE计算的是线要素自身的坡度,需要线要素具有高程(Z值)信息。如果线要素是二维的(没有Z值),那么计算的AVG_SLOPE可能为零或无效。
与栅格无关:AVG_SLOPE的计算不依赖于输入的栅格表面,即使指定了坡度栅格作为输入表面,工具也不会使用该栅格的数据来计算AVG_SLOPE。
结果不符合需求:由于AVG_SLOPE计算的是线要素自身的坡度,而不是线要素在坡度栅格上的坡度,因此无法满足提取坡度栅格值的需求。
(3)计算其他形态参数
- 密度分析:使用“Spatial Analyst Tools” -> “Density” -> “Line Density(线密度分析)”对沟道网络进行密度分析。
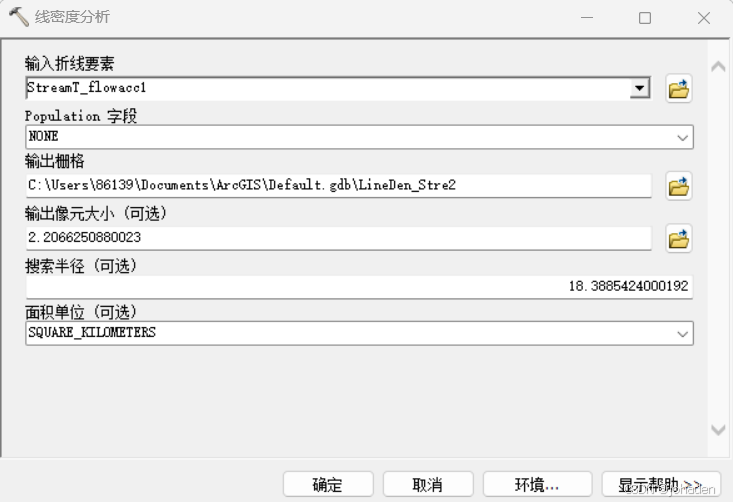

6.集水区分析
(1)河流链接
- spatial analyst->河流链接
- 在输入河流栅格中输入“河网栅格”,第二行输入“流向”,同理并行处理改为0。
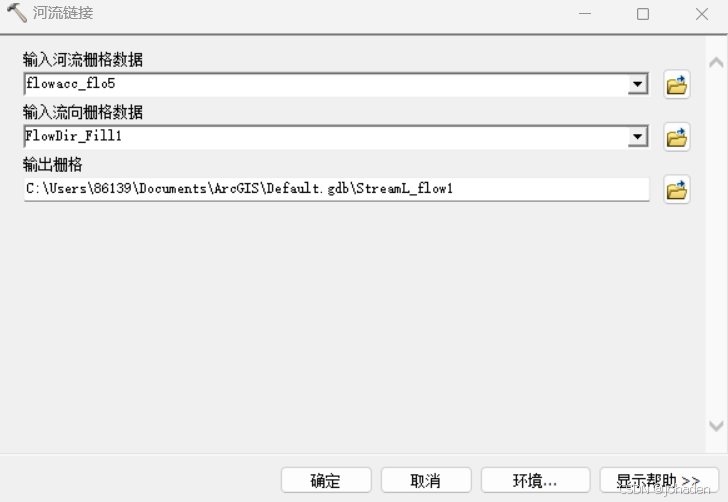
此处时间消耗较长,故将前面河网的Con("Flow_Accumulation" >= 1000, 1)中的1000改为4500。

(2)集水区分析
- Spatial Analyst->水文分析->集水区
第一行填流向栅格,第二行填上面的河流链接后的栅格。
同理,仍需要在环境中将“并行处理因素”空白处填入“0”。
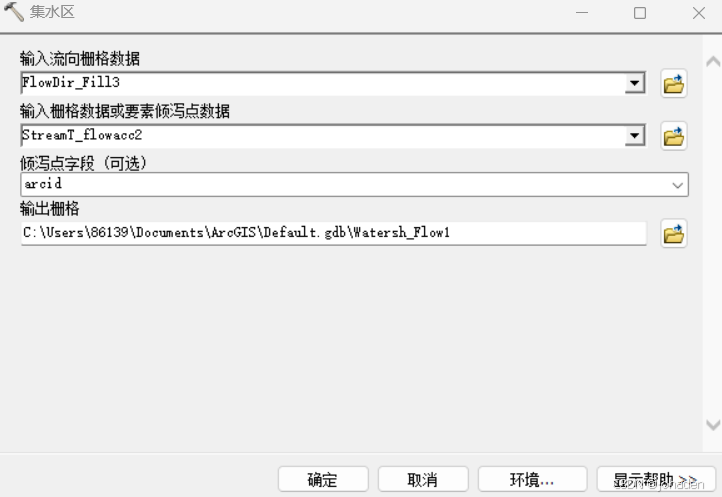
效果如下,有明显的分块迹象。

可以选择别的颜色

当然,上面的河网也可以分级。
补充:河网分级(紧接在3.4.之后)
- Spatial Analyst工具->水文分析->河网分级
第一行输入河网栅格,第二行输入流向。
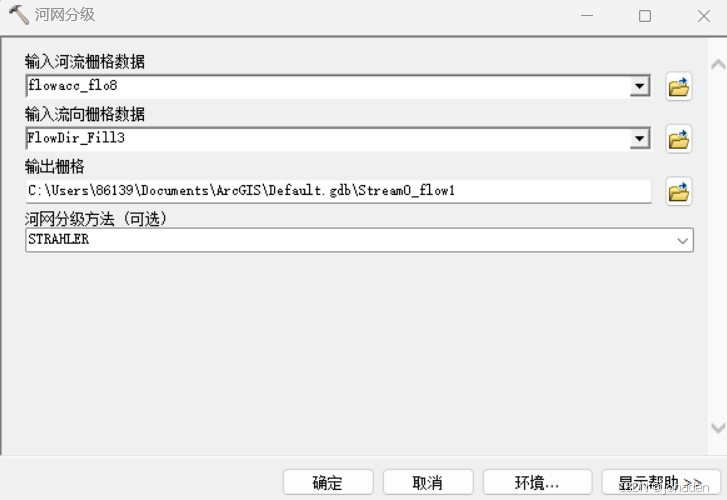
其中分级方法有斯特拉勒分级法(Strahler)和郭氏分级法(Shreve)。本次选择shreve。
何时使用哪种方法
-
斯特拉勒分级法:
- 适用场景:适用于需要明确区分主干河流和支流的研究,特别是关注河流网络的拓扑结构和层次关系。
- 优点:简单明了,易于理解和解释。
- 缺点:对河流长度和流量的考虑较少,可能不适合需要详细流量分析的场景。
-
郭氏分级法:
- 适用场景:适用于需要考虑河流长度和流量的研究,特别是在水文分析和流量模拟中。
- 优点:考虑了河流的长度和流量,提供了更详细的河流分级信息。
- 缺点:计算相对复杂,可能需要更多的数据和计算资源。

- 打开“Spatial Analyst Tools” -> “Hydrology” -> “Stream to Feature”(栅格河网矢量化)
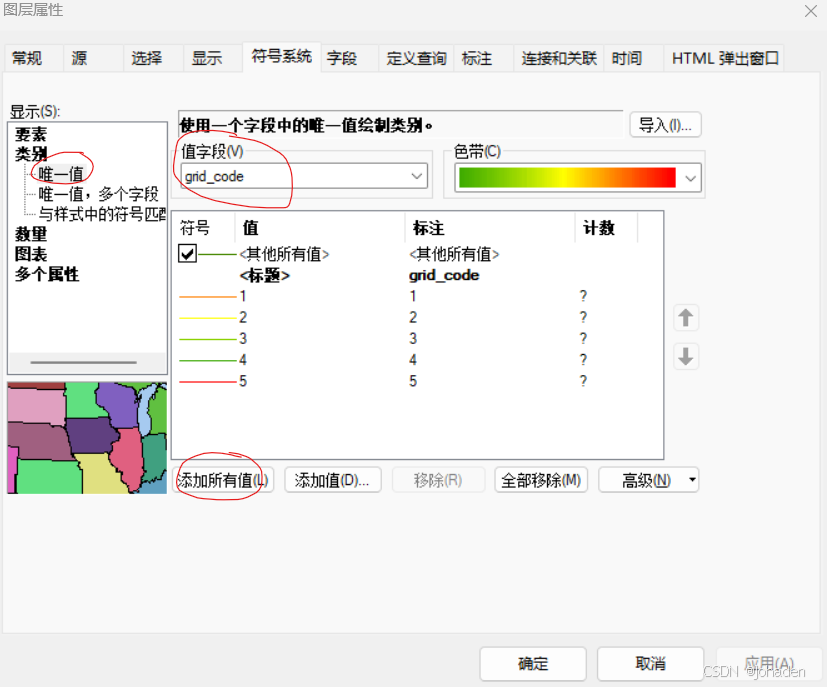
点击“符号系统”->“唯一值”->“改为grid code”->添加所有值
河网分级效果如下:

相关文章:
利用Arcgis进行沟道形态分析
在做项目的时候需要学习到水文分析和沟道形态分析的学习,所以自己摸索着做了下面的工作和内容。如有不对请多指正!! 一、沟道形态分析概述 沟道形态分析是水文分析的一个重要方面,用于研究河流的形态和特征。沟道形态分析可以帮助…...

Excel:vba实现筛选出有批注的单元格
实现的效果:代码: Sub test() Dim cell As RangeRange("F3:I10000").ClearlastRow Cells(Rows.Count, "f").End(xlUp).Row MsgBox lastrow For Each cell In Range("a1:a21")If Not cell.Comment Is Nothing ThenMsgBox…...

RabbitMQ 发布确认模式
RabbitMQ 发布确认模式 一、原理 RabbitMQ 的发布确认模式(Publisher Confirms)是一种机制,用于确保消息在被 RabbitMQ 服务器成功接收后,发布者能够获得确认。这一机制在高可用性和可靠性场景下尤为重要,能够有效防止…...

【面试题】什么是SpringBoot以及SpringBoot的优缺点
什么是SpringBoot以及SpringBoot的优缺点 什么是SpringBoot SpringBoot是基于Spring的一个微框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。 SpringBoot的优点 可以创建独立的Spring应用程序,并且基于其Maven或Gradle插件,可以创建可执…...

git区分大小写吗?如果不区分,那要如何设置?
git区分大小写吗?如果不区分,那要如何设置? "Git在文件名的大小写方面是区分大小写的,但在某些操作系统(如Windows和macOS)上,文件系统默认是不区分大小写的。这可能导致一些问题…...

Docker 安装使用
1. 下载 下载地址:Index of linux/static/stable/x86_64/ 下载好后,将文件docker-18.06.3-ce.tgz用WinSCP等工具,上传到不能外网的linux系统服务器 2. 安装 解压后的文件夹docker中文件如下所示: 将docker中的全部文件ÿ…...

Linux Docker配置镜像加速
Docker配置常用镜像加速地址包含阿里、腾讯、百度、网易 1. 编辑docke配置文件 vim /etc/docker/daemon.json写入以下内容 {"registry-mirrors": ["https://docker.mirrors.aliyuncs.com","https://registry.docker-cn.com","https://mi…...

了解CSS Typed OM
CSS Typed OM(CSS Typed Object Model)是一项前沿的技术,旨在改变我们编写和操作CSS的方式。以下是对CSS Typed OM的详细解析: 一、CSS Typed OM概述 CSS Typed OM是一个包含类型和方法的CSS对象模型,它暴露了作为Ja…...

[ 钓鱼实战系列-基础篇-6 ] 一篇文章让你了解邮件服务器机制(SMTP/POP/IMAP)-2
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...

在 Docker 中搭建 PostgreSQL16 主从同步环境
1. 环境搭建 本文介绍了如何在同一台机器上使用 Docker 容器搭建 PostgreSQL 的主从同步环境。通过创建互联网络和配置主库及从库,详细讲解了数据库初始化、角色创建、数据同步和验证步骤。主要步骤包括设置主库的连接信息、创建用于复制的角色、使用 pg_basebacku…...
SpringCloud无介绍快使用,sentinel服务熔断功能与持久化(二十四)
TOC 问题背景 从零开始学springcloud微服务项目 注意事项: 约定 > 配置 > 编码IDEA版本2021.1这个项目,我分了很多篇章,每篇文章一个操作步骤,目的是显得更简单明了controller调service,service调dao默认安装ngi…...
判断浏览器环境,前端打开微信浏览器
我们知道微信浏览器有自带针对微信的组件(比如:微信JSAPI支付使用的WeixinJSBridge),那么,有办法在普通浏览器中打开微信浏览器并跳转页面吗?(似乎微信已禁用外部浏览器调用的普通页面直接跳转,只能通过“weixin://前缀…...

【算法笔记】前缀和算法原理深度剖析(超全详细版)
【算法笔记】前缀和算法原理深度剖析(超全详细版) 🔥个人主页:大白的编程日记 🔥专栏:算法笔记 文章目录 【算法笔记】前缀和算法原理深度剖析(超全详细版)前言一.一维前缀和1.1题…...

linux之网络子系统- 地址解析协议arp 源码分析和邻居通用框架
一、arp 的作用 ARP(Address Resolution Protocol,地址解析协议)是将IP地址解析为以太网MAC地址(物理地址)的协议。在局域网中,当主机或其他网络设备有数据要发送给另一个主机或设备时,它必须知…...
 到 O(1) 的优化解析】)
经典动态规划问题:含手续费的股票买卖【从 O(n) 到 O(1) 的优化解析】
题目理解 我们要在给定的股票价格数组 prices 中进行买卖操作,并尽可能多次交易以获取最大利润。每次交易都需要支付一定的手续费 fee,因此我们必须考虑如何通过合适的交易策略最大化利润。 在本题中,每一天可以选择: 不进行任…...

Python画笔案例-088 绘制 滚动的汉字
1、绘制 滚动的汉字 通过 python 的turtle 库绘制 滚动的汉字,如下图: 2、实现代码 绘制 滚动的汉字,以下为实现代码: """滚动的汉字.py """ import time from turtle import * from write_patch import *width,height...

Redis 5.0 安装配置(Windows)
Redis 5.0之后支持Redis Stream等功能 下载地址:Releases tporadowski/redis GitHub 点击运行redis-server.exe 此外:Redis 6.0及以后版本目前都没有Windows版...

金融行业:办公安全防护专属攻略
在中国金融市场快速迈向数字化转型的进程中,数据安全与隐私保护成为了不容忽视的关键议题。面对不断升级的网络威胁和日益严格的监管要求,构建一个既能支持创新又能提供坚实防护的信息安全体系变得尤为重要。亿格云不断深耕办公安全领域,为金…...

python如何基于numpy pandas完成复杂的数据分析操作?
数据分析是现代数据科学的重要组成部分,Python作为一种强大的编程语言,提供了许多库来简化数据分析过程。 其中,NumPy和Pandas是两个最常用的库。NumPy主要用于数值计算,而Pandas则提供了强大的数据结构和数据分析工具。 本文将深入探讨如何利用这两个库进行复杂的数据分…...

Linux中定时任务调度工具——crontab
1.简介 crontab是Unix和类Unix操作系统(如Linux)中用于定时任务调度的工具。其名称来源于“cron”这个守护进程,它负责周期性地执行任务,并且“tab”表示这个工具的配置文件。用户可以通过配置crontab文件来设定定时任务…...

Agnix:为AI智能体打造安全可控的操作系统级执行环境
1. 项目概述:从“智能体”到“操作系统”的范式跃迁最近在开源社区里,一个名为agent-sh/agnix的项目引起了我的注意。乍一看这个名字,agent和agnix的组合,很容易让人联想到这是又一个基于大语言模型的智能体(Agent&…...

对比直接使用原厂API,Taotoken在计费透明度上的体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用原厂API,Taotoken在计费透明度上的体验 对于个人开发者而言,在项目开发中集成大模型能力时&am…...

3分钟快速上手:如何用res-downloader高效下载视频号资源
3分钟快速上手:如何用res-downloader高效下载视频号资源 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 在当今数…...

Python 爬虫反爬突破:CDN 防护节点穿透采集
前言 当下大型互联网站点、电商平台资讯门户、行业数据网站均全面接入 CDN 内容分发网络,借助全球节点缓存、流量调度、智能分流、节点 IP 隐身、区域访问限制等机制构建底层防护体系。传统爬虫直接请求源站 IP 的方式会被 CDN 节点拦截、跳转、限速、IP 封禁、节点…...
)
六、Ext系列文件系统(2)
...

语音真实度突破98.7%的关键在哪?ElevenLabs最新v3.2引擎深度测评,附权威MOS评分对比表
更多请点击: https://intelliparadigm.com 第一章:语音真实度突破98.7%的关键在哪?ElevenLabs最新v3.2引擎深度测评,附权威MOS评分对比表 ElevenLabs v3.2 引擎在2024年Q2发布的音频合成基准测试中,首次在自然度&…...

FlareLine Flutter:开源跨平台管理后台模板开发与部署指南
1. 项目概述:一个为现代应用而生的Flutter仪表盘模板如果你正在寻找一个能快速启动你的下一个Web、Android或iOS项目后台管理界面的方案,并且希望这个方案足够现代、功能齐全,同时又能让你完全掌控代码,那么FlareLine Flutter这个…...

基于GAN的端到端ISP:用AI学习从RAW到RGB的图像处理革命
1. 项目概述:从“拍”到“算”的ISP革命在计算机视觉和图像处理领域,图像信号处理器(ISP)一直扮演着“幕后英雄”的角色。它负责将相机传感器捕捉到的原始、未经处理的RAW Bayer数据,转换为我们手机相册里那些色彩鲜艳…...
)
别再想当然!用AD628/INA等差分放大器做单端采集,必须搞懂的共模电压计算(附Excel工具)
差分放大器单端采集实战指南:共模电压计算与设计避坑 在工业传感器接口和医疗设备信号链设计中,差分放大器常被用于单端信号采集的场景。许多工程师习惯性地认为,只要将差分放大器的负输入端接地,就能轻松实现单端转差分功能。但实…...

如何快速配置ComfyUI ControlNet预处理器:完整安装与使用指南
如何快速配置ComfyUI ControlNet预处理器:完整安装与使用指南 【免费下载链接】comfyui_controlnet_aux ComfyUIs ControlNet Auxiliary Preprocessors 项目地址: https://gitcode.com/gh_mirrors/co/comfyui_controlnet_aux ComfyUI ControlNet Aux预处理器…...