Go第三方框架--gorm框架(一)
前言
orm模型简介
orm模型全称是Object-Relational Mapping,即对象关系映射。其实就是在原生sql基础之上进行更高程度的封装。方便程序员采用面向对象的方式来操作数据库,将表映射成对象。
这种映射带来几个好处:
- 代码简洁:不用手动编写sql
- 安全性提高了:orm框架会自动处理参数化查询,可以有效减少sql注入的风险
- 可读性提高了:orm更接近自然语言。
- 可移植性提高,切换不同数据库时,不用重新编写sql,只需要更改连接字符串。
gorm模型简介
gorm顾名思义是采用go语言实现的orm框架,由jinzhu开发后开源,又融合了很多大神的思路。gorm主要是在go原生数据库包database/sql 的基础上引入orm思想来编写。所以其底层仍会调用database/sql的相关增删改查操作等dml操作和表结构修改等ddl操作。
以原生database/sql 查询为例:
要实现如下sql(gorm可以操作多种据库,我们本篇只以mysql为例来介绍)
SELECT * FROM userinfos WHERE name = "lisan” ORDER BY id ASC LIMIT 1;
则 database/sql 代码如下
dbsql, err := sql.Open("mysql", "root:root@tcp(127.0.0.1:3306)/world?charset=utf8mb4&parseTime=True&loc=Local")if err != nil {log.Fatal(err)}defer dbsql.Close()query := "SELECT * FROM userinfos WHERE name = ? ORDER BY id ASC LIMIT 1"// 执行查询_, err = dbsql.Query(query, "lisan")if err != nil {log.Fatal(err)}
debug可以看到其调用的是database/sql的QueryContext(…)函数。

如果用gorm来实现相同功能sql,则代码如下:
//gormdsn := "root:root@tcp(127.0.0.1:3306)/world?charset=utf8mb4&parseTime=True&loc=Local"db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{}) // db是初始化的db cloen=1 或 2 时,会将初始db复制一份,避免操作污染。if err != nil {panic(err)}var userinfo Userinfo// 查询单条db.Table(...) 中由于 db.clone=1 所以复制一份 新的db.clone=0 所以后续的链式调用 (各种. . .)的状态都会累加到 db.Table()生成的新db上,// 如此保证了 原始db的纯净 和 链式调用(拼装一条完整sql)的累加。(后续会有详细讲解)if err = db.Table("userinfos").Where("name = ?", "lisan").First(&userinfo).Error; err != nil {return}debug可以看到 其在First(…)函数内部也会调用 database/sql的QueryContext(…)函数

其调用链是
First(...)---->Execute(tx)----->f(db)----> Query(db *gorm.DB)---->db.Statement.ConnPool.QueryContext(....)---->QueryContext(....)
我们介绍gorm也是从具体的例子开始,到调用具体的database/sql函数为止。其实gorm可以看做将原生database/sql语句可配置化,自动对应表结构和sql语句进行封装。
至于database/sql调用的具体细节,后续会单独编写文章。好了明确了边界,现在我们来看下orm的几个重要结构体。
几种结构体
DB
db是gorm的核心结构体,所有操作都由它承载。
type DB struct {*Config // 存放一些初始化的配制信息,包括连接池和执行dml的回调函数等Error error // 执行操作的错误信息RowsAffected int64Statement *Statement // 执行增删改查的 状态信息 ,是sql语句累加的地方。clone int // db克隆次数 用来克隆db实例 避免多个查询时 互相影响 保证每个操作都会复制一份初始化的db // clone值 0:表示不复制实例 每个操作都会累计, 一般在相同sql语句中使用,例如 几个 where().where()链式调用需要进行sql状态累计。// 1:不同sql语句的增删改查等操作用,会复制一份新db,避免相互之间影响。一般只有连接池,配置等初始参数会复用,操作相关参数会初始化。相同语句链式调用会操作同一份Statement,不同的sql语句执行不同的Statement// 2: 开启事务时使用,配置直接复用,Statement会复制一份。 todo
}
Config结构体如下
Config
Config有初始化db需要的一些配置和初始化后的一些属性,比如连接池和回调函数等。
type Config struct {// GORM perform single create, update, delete operations in transactions by default to ensure database data // ... 省略一些本篇不用的属性// ClauseBuilders clause builderClauseBuilders map[string]clause.ClauseBuilder// ConnPool db conn pool // 连接池 对应database/sql 中的sql.DB 存放连接状态等信息 防止频繁创建连接ConnPool ConnPool// Dialector database dialectorDialector // mysql/sqlite等数据的操作接口// Plugins registered pluginsPlugins map[string]Plugincallbacks *callbacks // 增删改查等 gorm高度封装回调database/sql函数在这里注册cacheStore *sync.Map
}
其中 Dialector主要实现各种数据库的连接等操作,其结构如下:
type Dialector interface {Name() stringInitialize(*DB) error // 数据库连接池等的初始化 databae/sql.db的初始化 和 注册回调的原生database/sql dml 封装函数等Migrator(db *DB) Migrator // 装载操作 也就是承接 ddl的一些功能DataTypeOf(*schema.Field) stringDefaultValueOf(*schema.Field) clause.ExpressionBindVarTo(writer clause.Writer, stmt *Statement, v interface{})QuoteTo(clause.Writer, string)Explain(sql string, vars ...interface{}) string
}
其中 ConnPool 是Config中对接各数据库操作的地方,其函数内部直接调用了database/sql的相关函数,结构体如下:
type ConnPool interface {PrepareContext(ctx context.Context, query string) (*sql.Stmt, error) ExecContext(ctx context.Context, query string, args ...interface{}) (sql.Result, error) // 执行QueryContext(ctx context.Context, query string, args ...interface{}) (*sql.Rows, error) // 查询QueryRowContext(ctx context.Context, query string, args ...interface{}) *sql.Row
}目前 gorm集合了 mysql、sqlite等数据库的实现。
Config 中 callbacks属性 其结构体如下:
type callbacks struct {processors map[string]*processor
}type processor struct {db *DBClauses []stringfns []func(*DB) // 回调函数 query 等callbacks []*callback
}
Statement
Statement是状态,也就是拼接完整sql和执行sql时需要的信息。
type Statement struct {*DBTableExpr *clause.ExprTable string // 操作的表名Model interface{} // 结构体,跟表对应 用来承接结果Unscoped boolDest interface{} // 结构体,跟表对应ReflectValue reflect.ValueClauses map[string]clause.Clause // gorm执行语句 存储map 例如 Where("id=?",1) 则key:Where,value :包含 id和1,用来拼接最终sql; 累计各个dml的操作BuildClauses []string // 某dml操作可能需要的操作关键字, SELECT ,FROM,FOR等在sql中出现的先后顺序排列。 先出现的先用来组合SQL,这样保证sql语句的合法性Distinct boolSelects []string // selected columnsOmits []string // omit columnsJoins []joinPreloads map[string][]interface{}Settings sync.MapConnPool ConnPool // 连接池Schema *schema.Schema // 要执行操作的表对象的一些信息;比如:这张表属性列表、主键信息、表名;结构体和表名对应表。Context context.ContextRaiseErrorOnNotFound boolSkipHooks boolSQL strings.Builder // 拼接后的最终 sql语句 入参用占位符代替Vars []interface{} // SQL 属性的入参CurDestIndex intattrs []interface{}assigns []interface{}scopes []func(*DB) *DB
}现在只是大概梳理下其结构体,有疑惑很正常,接下来我们开始进入内部了解下其原理。共分为四大部分:
- 初始化:介绍gorm.db初始化的一些操作,包括初始化db.ConnPool(也就是database/sql db的初始化),注册回调的原生database/sql dml 封装函数等。
- 自动装载:自动装载主要介绍表的自动创建,属性的增加等ddl操作。
- 增删改查:这块主要讲解 gorm 如何将封装程序的可装配函数(例如where链式调用)转化为复杂的sql语句,然后通过回调函数实现原生 database/sql 的dml操作。
- 事务: todo
初始化
初始化主要是初始化一些必要的参数,我们重点关注初始化对应数据库的连接池和注册dml操作的回调函数。
初始化代码是示例的前几行,如下:
dsn := "root:root@tcp(127.0.0.1:3306)/world?charset=utf8mb4&parseTime=True&loc=Local"db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{}) // db是初始化的db cloen=1 时,会将初始db复制一份,避免操作污染。if err != nil {panic(err)}
其中mysql.Open(dsn)是按照mysql数据库的链接逻辑解析dsn,然后赋值给mysql的Dialector实现结构体,用来初始化mysql连接池用。
我们来看下gorm.Open(…)函数的实现:
func Open(dialector Dialector, opts ...Option) (db *DB, err error) {// ...// clone=1时 会复制一份 db的核心属性 包括 statement、config等db = &DB{Config: config, clone: 1}// 回调函数初始化 db.callbacks = initializeCallbacks(db)if config.ClauseBuilders == nil {config.ClauseBuilders = map[string]clause.ClauseBuilder{}}// 这块 调用database/sql 根据不同的Dialector初始化不同数据库的ConnPool(就是database/db 的sql.db参数)等参数;并将dml回调函数填入callbacksif config.Dialector != nil {err = config.Dialector.Initialize(db)if err != nil {if db, _ := db.DB(); db != nil {_ = db.Close()}}}// ...// 初始化Statement db.Statement = &Statement{DB: db,ConnPool: db.ConnPool,Context: context.Background(),Clauses: map[string]clause.Clause{},}// ...
}其中核心逻辑在config.Dialector.Initialize(db)中,我们来看下:
func (dialector Dialector) Initialize(db *gorm.DB) (err error) {// ...if dialector.Conn != nil {db.ConnPool = dialector.Conn} else {// 这边对接 database/sql 开始初始化连接池操作db.ConnPool, err = sql.Open(dialector.DriverName, dialector.DSN)if err != nil {return err}}// ...// register callbacks// 加载dml操作的关键字,用来定位sql关键字的先后顺序,以便生成合法的sql。callbackConfig := &callbacks.Config{CreateClauses: CreateClauses,QueryClauses: QueryClauses,UpdateClauses: UpdateClauses,DeleteClauses: DeleteClauses,}// ...// dml的callbacks函数在这里执行callbacks.RegisterDefaultCallbacks(db, callbackConfig)for k, v := range dialector.ClauseBuilders() {db.ClauseBuilders[k] = v}return
}我们看到这里主要完成了 mysql连接池的和dml回调函数的初始化。
其中 callbacks.RegisterDefaultCallbacks(…)函数如下:
func RegisterDefaultCallbacks(db *gorm.DB, config *Config) {// ...// 注册执行的回调函数会在 First()中 最后一行的Execute()执行函数的 fns列表调用 // Create() 返回create对应的 *processor指针 对此指针的修改会反映在 db.config.callbacks属性上createCallback := db.Callback().Create()// *processor.callbacks ([]*callback) 在这边初始化createCallback.Match(enableTransaction).Register("gorm:begin_transaction", BeginTransaction)createCallback.Register("gorm:before_create", BeforeCreate)createCallback.Register("gorm:save_before_associations", SaveBeforeAssociations(true))createCallback.Register("gorm:create", Create(config))createCallback.Register("gorm:save_after_associations", SaveAfterAssociations(true))createCallback.Register("gorm:after_create", AfterCreate)createCallback.Match(enableTransaction).Register("gorm:commit_or_rollback_transaction", CommitOrRollbackTransaction)createCallback.Clauses = config.CreateClauses// 查询回调函数注册 也就是后续DML章节讲解的 查询函数的注册queryCallback := db.Callback().Query()queryCallback.Register("gorm:query", Query)// ...// 删除deleteCallback := db.Callback().Delete()deleteCallback.Match(enableTransaction).Register("gorm:begin_transaction", BeginTransaction)// ...// 更新updateCallback := db.Callback().Update()updateCallback.Match(enableTransaction).Register("gorm:begin_transaction", BeginTransaction)updateCallback.Register("gorm:setup_reflect_value", SetupUpdateReflectValue)// ...// gorm可以对增删改查进行 封装操作,使得操作更简单。也支持原生sql的查询rowCallback := db.Callback().Row() rowCallback.Register("gorm:row", RowQuery)rowCallback.Clauses = config.QueryClauses// ...
}
我们来看下涉及的结构体之间的关系图:

到这里初始化我们需要关注的两个领域已将讲解完毕。
自动装载(ddl操作)
自动装载主要是用来实现ddl相关的此操作,比如表的创建,属性的增加,属性参数的修改,添加约束条件,添加索引等。其会动态感知结构体的字段变化,从而将其映射到表结构上。我们来看下其源码。先看下下面的例子:
type Userinfo struct {Id uintName stringGender stringHobby stringAddr stringAge uint8
}func TestGorm(t *testing.T) {//gormdsn := "root:root@tcp(127.0.0.1:3306)/world?charset=utf8mb4&parseTime=True&loc=Local"db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{})if err != nil {panic(err)}//自动迁移 ddl相关的操作 调用 excute函数执行操作,调用"row"或者"raw"对应的 processor 执行查询 执行原生操作err = db.AutoMigrate(&Userinfo{})if err != nil {return}
}
执行如上语句后会创建 表名为 userinfos的表

其代码比较简单,但内部有复杂的逻辑,我们来简单梳理下。
自动装载源码如下:
// AutoMigrate run auto migration for given models
func (db *DB) AutoMigrate(dst ...interface{}) error {return db.Migrator().AutoMigrate(dst...)
}其中 **Migrator()**方法返回值是Migrator 接口,其承载着自动装载需要的所有方法。todo
func (db *DB) Migrator() Migrator {tx := db.getInstance() // apply scopes to migratorfor len(tx.Statement.scopes) > 0 {tx = tx.executeScopes()}// 调用 Dialector 的 Migrator 方法,传入一个 Session 实例。Session 包含了当前的事务信息,用于执行迁移操作 return tx.Dialector.Migrator(tx.Session(&Session{}))
}
Migrator 接口如下:
// ddl相关操作 可以增删 表 表的属性 视图 限制条件 索引 等;可以查看数据库
type Migrator interface {// AutoMigrateAutoMigrate(dst ...interface{}) error // Database 数据库相关操作CurrentDatabase() stringFullDataTypeOf(*schema.Field) clause.ExprGetTypeAliases(databaseTypeName string) []string// Tables 表相关操作CreateTable(dst ...interface{}) errorDropTable(dst ...interface{}) error// ...// Columns 列相关操作AddColumn(dst interface{}, field string) errorDropColumn(dst interface{}, field string) error// ...// Views 视图相关操作CreateView(name string, option ViewOption) errorDropView(name string) error// Constraints 限制条件相关操作CreateConstraint(dst interface{}, name string) errorDropConstraint(dst interface{}, name string) errorHasConstraint(dst interface{}, name string) bool// Indexes 索引相关操作CreateIndex(dst interface{}, name string) errorDropIndex(dst interface{}, name string) error// ...
}
AutoMigrate(value …interface{})承载着,自动装载的核心逻辑,包括对表、属性、索引等的操作;源码如下:
// AutoMigrate auto migrate values
func (m Migrator) AutoMigrate(values ...interface{}) error {for _, value := range m.ReorderModels(values, true) {queryTx, execTx := m.GetQueryAndExecTx()// 没有找到对应表 需要创建表if !queryTx.Migrator().HasTable(value) {// 创建表if err := execTx.Migrator().CreateTable(value); err != nil {return err}} else {// 将结构体名映射成表名 然后执行回调函数if err := m.RunWithValue(value, func(stmt *gorm.Statement) error {columnTypes, err := queryTx.Migrator().ColumnTypes(value)if err != nil {return err}var (parseIndexes = stmt.Schema.ParseIndexes()parseCheckConstraints = stmt.Schema.ParseCheckConstraints())// DBNames 结构体 属性 按照 规则转换成 表属性 格式for _, dbName := range stmt.Schema.DBNames {var foundColumn gorm.ColumnType// columnTypes: 从数据库获得 表的 属性名信息 columnTypesfor _, columnType := range columnTypes {if columnType.Name() == dbName {foundColumn = columnTypebreak}}// 表中没有对应列if foundColumn == nil {// not found, add column 创建列if err = execTx.Migrator().AddColumn(value, dbName); err != nil {return err}} else {// found, smartly migrate 找到了结构体属性对应列名 对属性的参数(类型,注释等)进行 更新field := stmt.Schema.FieldsByDBName[dbName]if err = execTx.Migrator().MigrateColumn(value, field, foundColumn); err != nil {return err}}}// 对表约束条件进行更新if !m.DB.DisableForeignKeyConstraintWhenMigrating && !m.DB.IgnoreRelationshipsWhenMigrating {// ...}// 对表索引进行更新for _, idx := range parseIndexes {if !queryTx.Migrator().HasIndex(value, idx.Name) {if err := execTx.Migrator().CreateIndex(value, idx.Name); err != nil {return err}}}return nil}); err != nil {return err}}}return nil
}
AutoMigrate函数中需要的核心调用函数 都来自 Migrator 结构体 ,我们选择HasTable()函数来简单梳理下。
**HasTable(…)**用来判断是否存在特定表。其源码如下:
func (m Migrator) HasTable(value interface{}) bool {var count int64m.RunWithValue(value, func(stmt *gorm.Statement) error {currentDatabase := m.DB.Migrator().CurrentDatabase()// 原生sql执行(所谓执行原生sql,就是直接写原生sql,来调用database/sql方法,不使用gorm来组装sql),执行逻辑在Row()中,这边会调用已经注册的回调函数return m.DB.Raw("SELECT count(*) FROM information_schema.tables WHERE table_schema = ? AND table_name = ? AND table_type = ?", currentDatabase, stmt.Table, "BASE TABLE").Row().Scan(&count)})return count > 0
}
自动装载中所有对sql的调用的都是原生sql,因为查表、添加属性这种ddl sql语句比较固定,所以没必要采用组装的形式;而增删改查等 复杂的dml可以采用gorm来组装(比如:where(…).where(…)这种gorm最终会组合成sql语句。对database/sql的调用可以看做是接口调用,自动装载中的dml操作就简单的处理下得到了入参),再啰嗦一句,增删改等复杂的dml操作为用户提供了链式组合的方式来编写复杂的sql,它将组合的sql语句链,经过一些列的操作转换成调用原生sql的入参(原生sql和sql语句入参)。
自动装载函数AutoMigrate中还有好多值得深挖的点,由于篇幅原因不做介绍,感兴趣的大神可以深挖下。
相关文章:
Go第三方框架--gorm框架(一)
前言 orm模型简介 orm模型全称是Object-Relational Mapping,即对象关系映射。其实就是在原生sql基础之上进行更高程度的封装。方便程序员采用面向对象的方式来操作数据库,将表映射成对象。 这种映射带来几个好处: 代码简洁:不用…...
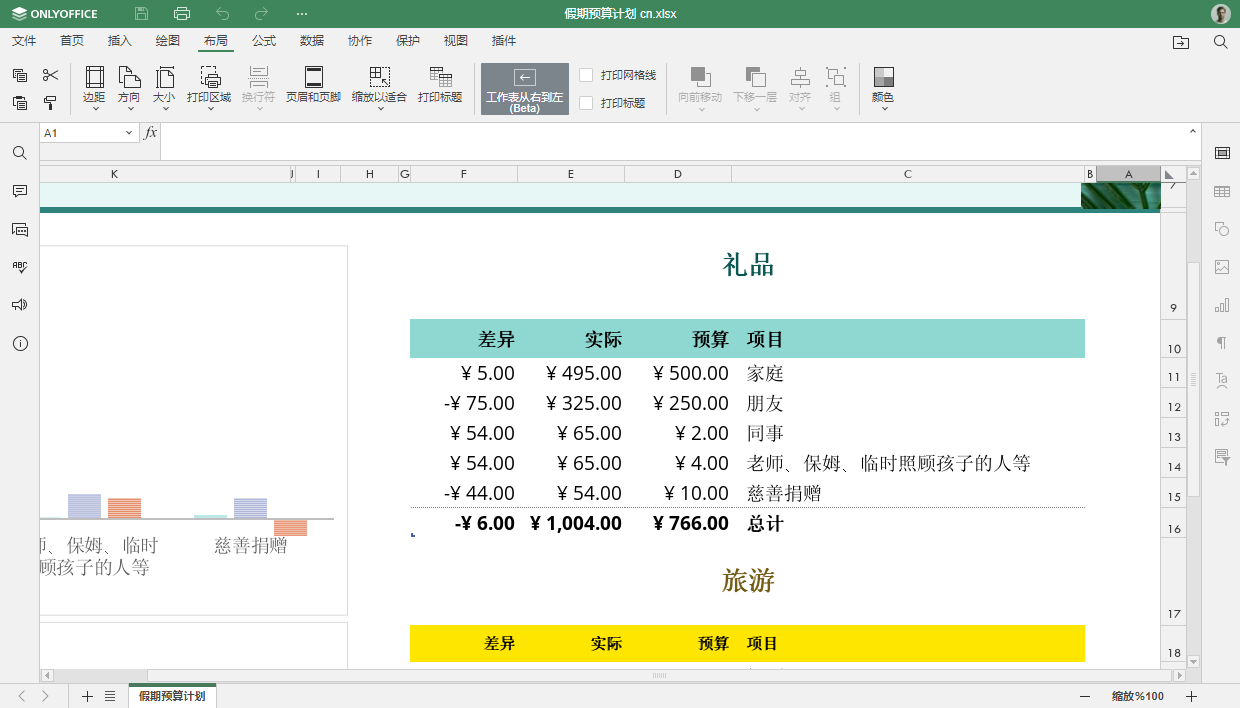
ONLYOFFICE文档8.2:开启无缝PDF协作
ONLYOFFICE 开源办公套件的最新版本新增约30个新功能,并修复了超过500处故障。 什么是 ONLYOFFICE 文档 ONLYOFFICE 文档是一套功能强大的文档编辑器,支持编辑处理文档、表格、幻灯片、可填写的表单和PDF。可多人在线协作,支持插件和 AI 集…...

内网python smtplib用ssh隧道通过跳板机发邮件
Python 自带 smtplib 包可以发邮件,示例见 [1,2],在邮箱设置启用 IMAP/POP3 就能用。有些邮箱需要设置授权码,如新浪、163 邮箱,然后以授权码作为 smtplib 登录服务器的密码。邮箱端配置参考 [3,4]。 现在情况是: 邮…...

基于C#开发游戏辅助工具的Windows底层相关方法详解
开发游戏辅助工具通常需要深入了解Windows操作系统的底层机制,以及如何与游戏进程进行有效交互。本文将基于C#语言,从Windows底层方法的角度来详细讲解开发游戏辅助工具的相关技术和概念。 一、游戏辅助工具的基本概述 游戏辅助工具,通常被称…...
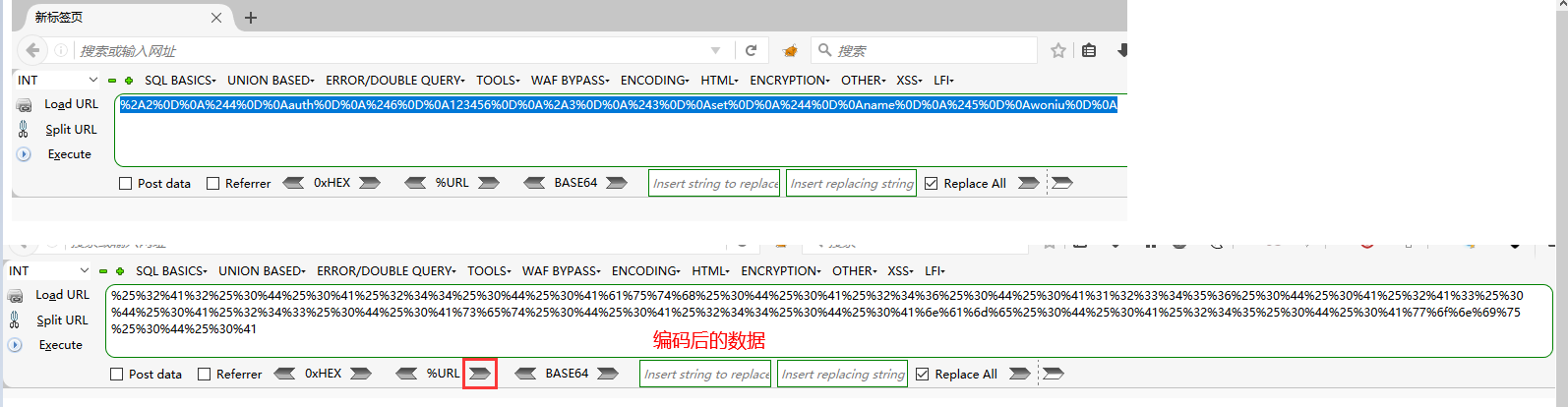
SSRF+Redis进行内网渗透
SSRFRedis进行内网渗透 一 环境搭建 准备一台服务器,开启了lampp以及redis,redis只允许内网访问 把上面这个注释放开后,redis就只能内网访问 启动redis 使用kali进行端口扫描,扫不到6379端口 kali连接不上redis ssrf漏洞代码 &…...

栈与队列-Java【力扣】【算法学习day.7】
前言 我做这类文档一个重要的目的还是给正在学习的大家提供方向(例如想要掌握基础用法,该刷哪些题?)我的解析也不会做的非常详细,只会提供思路和一些关键点,力扣上的大佬们的题解质量是非常非常高滴&#…...

最新版本!IntelliJ IDEA 2024.2.4 (Ultimate Edition) 的新特性
IntelliJ IDEA 2024.2版本(Ultimate Edition)的关键新特性包括: 改进的Spring Data JPA支持: 允许在IDE中直接运行Spring Data JPA方法,进行即时仓库查询验证。 无需运行应用程序或分析日志文件,即可查看…...

从头学PHP之运算符
关于运算符的图片均来自网络,主要是自己写太麻烦了,程序是个简化自己工作量的方式,能复制粘贴就不要手写了(建议初期还是多写写,加深下记忆)在这里我就偷个懒,图片涉及到侵权及时,请…...

使用 Git LFS(大文件存储)
Git LFS(Large File Storage)是一种扩展 Git 的工具,旨在更有效地管理大文件的版本控制。它通过将大文件的内容存储在 Git 之外来解决 Git 在处理大文件时的性能问题。 主要特点 替代存储:Git LFS 不直接将大文件存储在 Git 仓库…...

js 将一维数组转换成树形结构的方法
一维数组的数据结构,如下 const flatArray [ { id: 1, parent_id: null, name: ‘root1’ }, { id: 2, parent_id: null, name: ‘root2’ }, { id: 3, parent_id: 1, name: ‘child1’ }, { id: 4, parent_id: 2, name: ‘child2’ }, { id: 5, parent_id: 3, nam…...
刷新核心逻辑与空页面集成)
HarmonyOS NEXT开发实战:实现高效下拉刷新与上拉加载组件(二)刷新核心逻辑与空页面集成
前言: 在上一篇文章中,我们深入探讨了如何在HarmonyOS中实现一个功能完备的空页面组件。现在,我们将进入下拉刷新和上拉加载功能的核心逻辑实现。这不仅仅是技术实现,更是对用户体验的深刻理解。本文将详细介绍如何将空页面与下拉刷新、上拉加载逻辑相结合,打造一个既高效…...

Crawler4j在多线程网页抓取中的应用
网页爬虫作为获取网络数据的重要工具,其效率和性能直接影响到数据获取的速度和质量。Crawler4j作为一个强大的Java库,专门用于网页爬取,提供了丰富的功能来帮助开发者高效地抓取网页内容。本文将探讨如何利用Crawler4j进行多线程网页抓取&…...

【无标题】Django转化为exe,app
目录 1. 将 Django 项目转换为 .exe 文件(Windows)2. 将 Django 项目转换为 .app 应用程序(macOS)3. 发布到微信公众号将一个 Django 项目转换为 .exe 文件或 .app 应用程序,并发布到微信公众号,实际上涉及多个步骤和技术。下面我将分别介绍这些过程。 1. 将 Django 项目…...

HTML5_标签_各类表格的实现
目录 1. 表格标签 1.1 表格的主要作用 1.2 表格的基本语法 1.3 表头单元格标签 1.4 表格属性 案例分析 先制作表格的结构. 后书写表格属性. 代码示例: 1.5 表格结构标签 1.6 合并单元格 合并单元格方式: 目标单元格:(写合并代码) 合并单元…...
)
C语言数据结构之单向链表(SingleList)
C语言数据结构之单向链表(SingleList) 自定义结构体数据类型SListNode表示单向链表的节点,成员包括一个无类型的data用来存贮数据和一个SListNode本身类型的指针next,指向下一个节点。围绕SListNode写一系列函数以slist_开头实现…...

【银河麒麟高级服务器操作系统实例】金融行业TCP连接数猛增场景的系统优化
了解更多银河麒麟操作系统全新产品,请点击访问 麒麟软件产品专区:https://product.kylinos.cn 开发者专区:https://developer.kylinos.cn 文档中心:https://documentkylinos.cn 服务器环境以及配置 物理机/虚拟机/云/容器 物理…...

详解Java的类文件结构(.class文件的结构)
this_class 指向常量池中索引为 2 的 CONSTANT_Class_info。super_class 指向常量池中索引为 3 的 CONSTANT_Class_info。由于没有接口,所以 interfaces 的信息为空。 对应 class 文件中的位置如下图所示。 06、字段表 一个类中定义的字段会被存储在字段表&#x…...

爆肝整理14天!AI工具宝藏合集
随着AI技术的飞速发展,各类AI工具如雨后春笋般涌现。经过对上百款AI工具的深入探索与测试,我精心挑选出了一些功能强大的AI神器,这些工具将极大地降低自媒体创作的门槛。 🚀无论是撰写文案、剪辑视频、设计图文,还是处…...
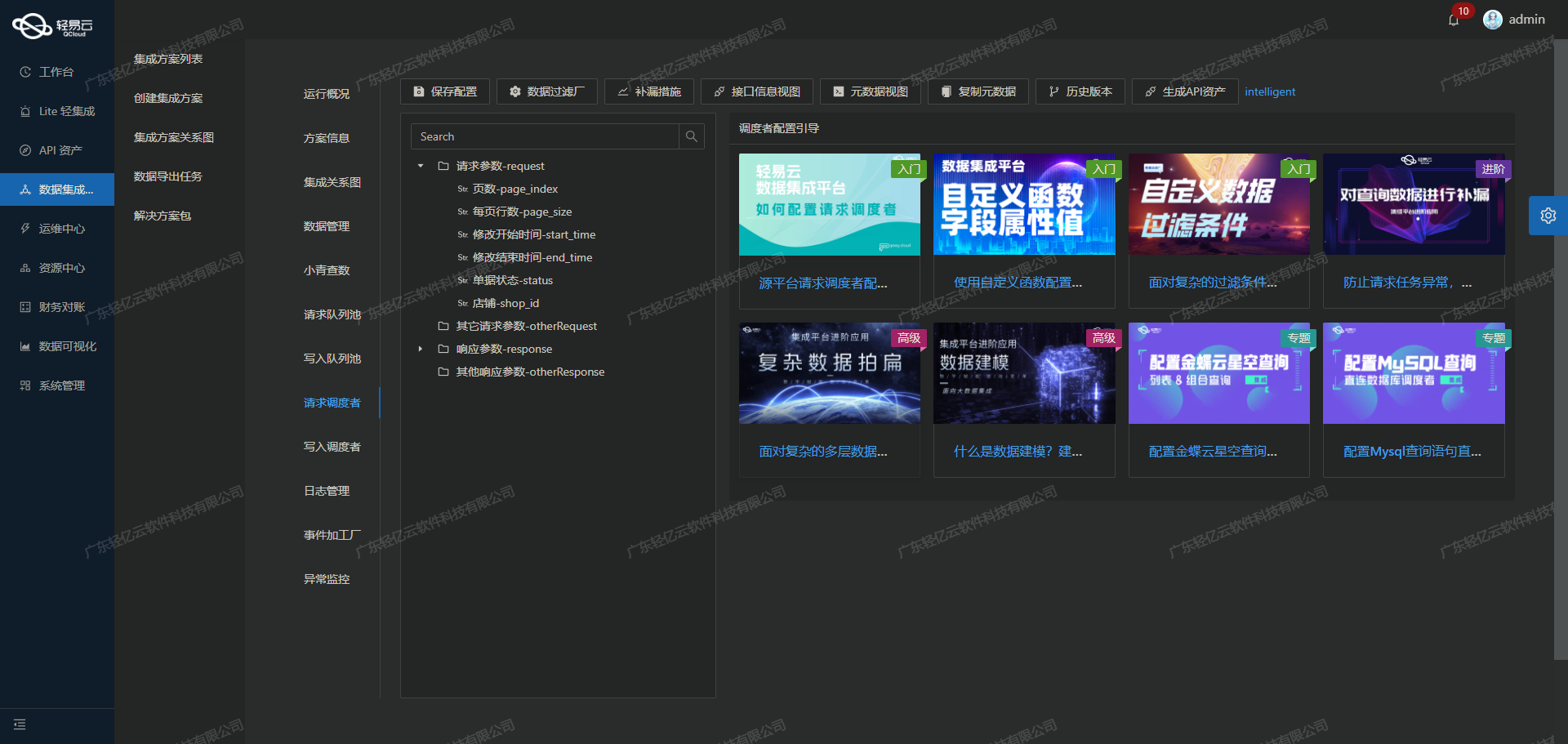
高效库存管理:金蝶云星空与管易云的盘亏单对接方案
高效库存管理:金蝶云星空与管易云的盘亏单对接方案 金蝶云星空与管易云的盘亏单对接方案 在企业日常运营中,库存管理是至关重要的一环。为了实现高效、准确的库存盘点和数据同步,我们采用了轻易云数据集成平台,将金蝶云星空的数据…...
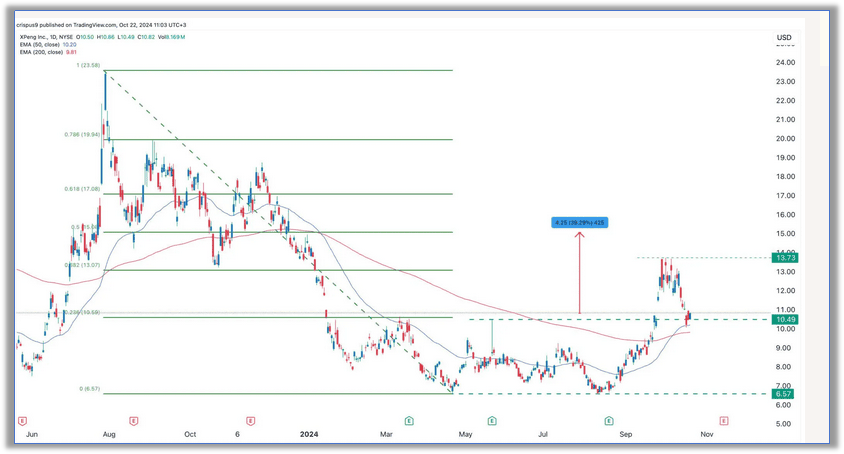
小鹏汽车股价分析:看涨信号已出现,技术指标显示还有40%的上涨空间
猛兽财经核心观点: (1)小鹏汽车的股价过去几天有所回落。 (2)随着需求的上升,该公司的业务发展的还算不错。 (3)猛兽财经对小鹏汽车股价的技术分析:多头已经将目标指向15…...

思源宋体完全指南:7种字体样式免费商用,打造专业中文排版
思源宋体完全指南:7种字体样式免费商用,打造专业中文排版 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为设计项目寻找既专业又免费的中文字体而烦恼吗&a…...

VLC技术重构:模块化架构深度解析与跨平台媒体处理突破
VLC技术重构:模块化架构深度解析与跨平台媒体处理突破 【免费下载链接】vlc VLC media player - All pull requests are ignored, please use MRs on https://code.videolan.org/videolan/vlc 项目地址: https://gitcode.com/gh_mirrors/vl/vlc 技术洞察&…...

2026年最值得投入的5款AI Agent工具:Gartner认证+生产环境压测数据全公开
更多请点击: https://intelliparadigm.com 第一章:2026年最佳AI Agent工具推荐 2026年,AI Agent 已从概念原型迈入企业级生产部署阶段。开发者不再满足于单任务自动化,而是追求具备长期记忆、跨平台协调与自主目标分解能力的智能…...

收藏必备!小白程序员轻松入门大模型:RAG架构详解与实践
本文详细介绍了检索增强生成(RAG)架构,旨在帮助初学者理解大模型如何结合外部知识库提升回答的准确性和时效性。文章涵盖了RAG的四种架构类型、黑盒与白盒增强策略、知识库构建、查询与检索增强方法,以及系统评估和优化增强过程。…...
:Agent 的记忆危机与 Mem0 的三阶段管道——为什么 RAG 不够用?)
【Mem0】 源码剖析(一):Agent 的记忆危机与 Mem0 的三阶段管道——为什么 RAG 不够用?
【Mem0】 源码剖析(一):Agent 的记忆危机与 Mem0 的三阶段管道——为什么 RAG 不够用? 写在前面:54K Star,论文被 arXiv 收录,LOCOMO 基准 SOTA——Mem0 是当前 Agent 记忆层的事实标准。它的核…...

Azure AI实战:从Demo到生产级智能应用架构全解析
1. 项目概述与核心价值最近在探索Azure AI服务时,我偶然发现了一个名为“Azure-AIGEN-demos”的GitHub仓库。这个项目由开发者retkowsky维护,乍一看名字,你可能会觉得它又是一个普通的Azure AI示例代码合集。但当我真正深入进去,花…...

AI增强自动化工作流:从规则驱动到意图驱动的智能决策实践
1. 项目概述:当AI遇见自动化工作流最近在GitHub上看到一个挺有意思的项目,叫“NitroRCr/AIaW”。光看名字,可能有点摸不着头脑,但点进去研究一下,你会发现它其实是一个将人工智能(AI)与自动化工…...

构建离线文档ETL管道:用Python实现PDF/Word智能转Markdown优化LLM输入
1. 项目概述:为什么我们需要一个离线的文档转换工具?如果你和我一样,经常需要把一堆PDF、Word文档甚至扫描件喂给本地的大语言模型(比如Ollama、LM Studio),那你肯定遇到过这个痛点:模型宝贵的上…...

WordPress AI内容创作栈:基于Claude API的自动化写作与运维实践
1. 项目概述:一个为WordPress量身定制的AI内容创作栈最近在折腾一个内容站,发现内容创作和日常运维的重复性工作实在太多了。从构思文章大纲、撰写初稿,到批量处理图片、优化SEO元数据,再到回复评论、生成周报,这些工作…...

Intel Quark SoC X1000:物联网边缘计算的核心技术解析
1. Intel Quark SoC X1000:物联网边缘计算的小型化革命在工业自动化现场,一台装备了温度传感器的风机正在持续监测轴承状态。传统方案需要将每秒数百个采样点全部上传云端,不仅占用带宽,延迟更是达到秒级。而采用Intel Quark SoC …...