使用 PyTorch 构建 LSTM 股票价格预测模型
目录
- 引言
- 准备工作
- 1. 训练模型(`train.py`)
- 2. 模型定义(`model.py`)
- 3. 测试模型和可视化(`test.py`)
- 使用说明
- 模型调整
- 结论
引言
在金融领域,股票价格预测是一个重要且具有挑战性的任务。随着深度学习的发展,长短期记忆网络(LSTM)因其在处理时间序列数据方面的出色表现而受到关注。本篇博客将指导你如何使用PyTorch构建一个LSTM模型来预测股票价格,我们将逐步介绍数据预处理、模型训练和结果可视化的完整流程。
准备工作
-
安装依赖:
确保你已经安装了以下 Python 库:pip install pandas numpy torch matplotlib scikit-learn -
下载数据:
使用yfinance库下载你感兴趣的股票的历史数据,并保存为 CSV 文件。我们这里使用 Apple(AAPL)过去五年的数据,文件命名为AAPL_5y_data.csv。以下是一个下载数据的代码示例:import yfinance as yf# 下载Apple股票过去5年的数据 data = yf.download('AAPL', start='2019-01-01', end='2024-01-01') data.to_csv('AAPL_5y_data.csv')
1. 训练模型(train.py)
在这个脚本中,我们将读取 CSV 文件,归一化数据,并使用 LSTM 模型进行训练。
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
from sklearn.preprocessing import MinMaxScaler
from model import LSTM # 导入LSTM类# 设置随机种子
torch.manual_seed(42)# 读取CSV文件
file_path = 'AAPL_5y_data.csv' # 替换为你的CSV文件路径
data = pd.read_csv(file_path)# 确保日期列是 datetime 类型
data['Date'] = pd.to_datetime(data['Date'])
data.set_index('Date', inplace=True)# 选择多特征:'Close', 'Open', 'High', 'Low', 'Volume'
features = data[['Close', 'Open', 'High', 'Low', 'Volume']].values# 数据归一化
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(features)# 准备训练和测试数据
train_size = int(len(scaled_data) * 0.8)
train_data = scaled_data[:train_size]
test_data = scaled_data[train_size:]def create_dataset(data, time_step=1):X, y = [], []for i in range(len(data) - time_step - 1):a = data[i:(i + time_step)]X.append(a)y.append(data[i + time_step, 0]) # 预测收盘价return np.array(X), np.array(y)# 创建数据集
time_step = 50 # 时间步长
X_train, y_train = create_dataset(train_data, time_step)# 转换为PyTorch张量
X_train = torch.from_numpy(X_train).float()
y_train = torch.from_numpy(y_train).float().view(-1, 1)# 初始化模型、损失函数和优化器
model = LSTM()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)# 训练模型
num_epochs = 300
for epoch in range(num_epochs):model.train()optimizer.zero_grad()outputs = model(X_train)loss = criterion(outputs, y_train)loss.backward()optimizer.step()if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')# 保存模型
torch.save(model.state_dict(), 'lstm_model.pth')
print("模型已保存为 'lstm_model.pth'")
2. 模型定义(model.py)
在这个文件中定义 LSTM 模型结构。
import torch
import torch.nn as nnclass LSTM(nn.Module):def __init__(self):super(LSTM, self).__init__()self.lstm = nn.LSTM(input_size=5, hidden_size=100, num_layers=2, batch_first=True)self.fc = nn.Linear(100, 1)def forward(self, x):out, _ = self.lstm(x)out = self.fc(out[:, -1, :]) # 取最后时间步的输出return out
3. 测试模型和可视化(test.py)
在这个脚本中,我们将加载训练好的模型,并使用测试数据进行预测和可视化。
import pandas as pd
import numpy as np
import torch
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from model import LSTM # 导入LSTM类# 设置字体为SimHei,用于显示中文
plt.rcParams['font.family'] = 'SimHei'# 读取CSV文件
file_path = 'AAPL_5y_data.csv' # 替换为你的CSV文件路径
data = pd.read_csv(file_path)# 确保日期列是 datetime 类型
data['Date'] = pd.to_datetime(data['Date'])
data.set_index('Date', inplace=True)# 选择多特征:'Close', 'Open', 'High', 'Low', 'Volume'
features = data[['Close', 'Open', 'High', 'Low', 'Volume']].values# 数据归一化
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(features)# 准备训练和测试数据
train_size = int(len(scaled_data) * 0.8)
train_data = scaled_data[:train_size]
test_data = scaled_data[train_size:]def create_dataset(data, time_step=1):X, y = [], []for i in range(len(data) - time_step - 1):a = data[i:(i + time_step)]X.append(a)y.append(data[i + time_step, 0]) # 预测收盘价return np.array(X), np.array(y)# 创建测试数据集
time_step = 50 # 时间步长
X_test, y_test = create_dataset(test_data, time_step)# 转换为PyTorch张量
X_test = torch.from_numpy(X_test).float()
y_test = torch.from_numpy(y_test).float().view(-1, 1)# 加载模型
model = LSTM()
model.load_state_dict(torch.load('lstm_model.pth'))
model.eval()# 测试模型
with torch.no_grad():test_outputs = model(X_test)# test_outputs 是预测的收盘价,将其重新归一化为原始价格test_outputs = scaler.inverse_transform(np.concatenate((test_outputs.numpy(), np.zeros((test_outputs.shape[0], 4))), axis=1))[:, 0] # 反归一化收盘价y_test_inverse = scaler.inverse_transform(np.concatenate((y_test.numpy(), np.zeros((y_test.shape[0], 4))), axis=1))[:, 0]# 可视化结果
plt.figure(figsize=(14, 7))
plt.plot(data.index[-len(y_test):], y_test_inverse, label='真实价格', color='blue')
plt.plot(data.index[-len(test_outputs):], test_outputs, label='预测价格', color='red')
plt.title('股票价格预测')
plt.xlabel('日期')
plt.ylabel('价格')
plt.legend()
plt.show()
使用说明
-
保存脚本:
- 将训练脚本代码保存为
train.py。 - 将模型定义代码保存为
model.py。 - 将测试脚本代码保存为
test.py。
- 将训练脚本代码保存为
-
运行训练:
- 在命令行中运行训练脚本:
python train.py - 训练完成后,模型将保存为
lstm_model.pth。
- 在命令行中运行训练脚本:
-
运行测试和可视化:
-
在命令行中运行测试脚本:
python test.py -
这将加载已训练的模型,并可视化预测结果。

这只是一个演示,模型的预测效果还有待进一步优化。
-
模型调整
如果预测的价格和真实价格差距较大,可能是由于以下几个原因:
-
数据规模不足:
- 如果训练数据不足,模型可能无法学到市场的长期趋势。
- 改进:使用更多的历史数据,尽量包括多年的数据。可以尝试增加数据的时间跨度。
-
数据预处理问题:
- 数据没有正确归一化,或归一化范围过窄。
- 改进:检查
MinMaxScaler的应用。你可以尝试不同的归一化范围,例如(0, 1)或(-1, 1),也可以使用其他标准化方法(例如StandardScaler)。
-
模型复杂度不足:
- 模型的层数或隐藏单元数量可能不足以捕捉数据的复杂性。
- 改进:增加 LSTM 的隐藏层数量或隐藏单元数量。你还可以考虑添加其他类型的层,例如卷积层(CNN)或全连接层,以提高模型的表达能力。
-
超参数调整:
- 学习率、批大小和时间步长等超参数可能需要调整以优化模型性能。
- 改进:尝试不同的学习率(例如,0.001、0.0001 等)、不同的批大小(如 16、32、64)和时间步长(如 30、60)。
-
更改损失函数:
- 在某些情况下,使用不同的损失函数可能有助于模型的收敛。
- 改进:可以尝试使用其他损失函数,例如 Huber 损失函数(
nn.SmoothL1Loss)或自定义损失函数,以更好地适应数据。
结论
通过使用 PyTorch 构建 LSTM 模型,我们成功地实现了股票价格的预测。在这个过程中,我们学习了如何处理时间序列数据,构建和训练深度学习模型,以及如何评估和可视化预测结果。尽管模型的性能可能需要进一步的优化和调整,但这个示例为未来的工作奠定了基础。
希望这篇博客能够帮助你在股票价格预测方面取得更好的成果。欢迎分享你的成果和经验,或者提出你的问题!
相关文章:
使用 PyTorch 构建 LSTM 股票价格预测模型
目录 引言准备工作1. 训练模型(train.py)2. 模型定义(model.py)3. 测试模型和可视化(test.py)使用说明模型调整结论 引言 在金融领域,股票价格预测是一个重要且具有挑战性的任务。随着深度学习…...

【C++篇】C++类与对象深度解析(五):友元机制、内部类与匿名对象的讲解
文章目录 前言 💬 欢迎讨论:如果你在学习过程中有任何问题或想法,欢迎在评论区留言,我们一起交流学习。你的支持是我继续创作的动力! 👍 点赞、收藏与分享:觉得这篇文章对你有帮助!…...

模型训练进度条的代码
这个内容难在什么地方呢? 我想要跳转到另一个页面的时候 如何保存当前的训练状态,本来还想着加一个页面去管理进度的。然后想到了localstorage,将一些信息存储到浏览器中去。 进度条展示 <el-form-item label"训练进度" v-show…...

直观理解反向传播 | Chapter 3 | Deep Learning | 3Blue1Brown
目录 前言1. 简介2. 回顾3. 直观的演绎示例4. 随机梯度下降相关资料结语 前言 3Blue1Brown 视频笔记,仅供自己参考 这个章节主要来直观地理解反向传播算法到底在做什么 官网:https://www.3blue1brown.com 视频:https://www.bilibili.com/vide…...

052_python基于Python高校岗位招聘和分析平台
目录 系统展示 开发背景 代码实现 项目案例 获取源码 博主介绍:CodeMentor毕业设计领航者、全网关注者30W群落,InfoQ特邀专栏作家、技术博客领航者、InfoQ新星培育计划导师、Web开发领域杰出贡献者,博客领航之星、开发者头条/腾讯云/AW…...

基于物联网、大数据、人工智能等技术开发的Spring Cloud 智慧工地云平台源码,支持多端应用
系统概述: 智慧工地是指运用现代信息技术,如物联网(IoT)、大数据、人工智能(AI)、云计算、移动互联网等,对传统建筑工地进行智能化改造和管理的新型工地。它通过高度集成的系统和设备ÿ…...

常见的跨境电商平台对比【总结表】
常见的跨境电商平台对比【总结表】 平台目标市场费用结构物流服务支付方式推广工具适合卖家亚马逊全球销售佣金、月租费、FBAFBA支持全球配送多种支付方式广告工具、促销活动有一定资金实力的品牌和卖家eBay全球上市费、成交费第三方物流支持PayPal、信用卡广告工具、促销活动…...

perl批量改文件后缀
perl批量改文件后缀 如题,perl批量改文件后缀,将已有的统一格式的文件后缀,修改为新的统一的文件后缀。 #!/bin/perl use 5.010;print "Please input file suffix which U want to rename!\n"; chomp (my $suffix_old <>)…...

【Python中的字符串处理】正则表达式与常用字符串操作技巧!
Python中的字符串处理:正则表达式与常用字符串操作技巧 Python 在字符串处理方面提供了丰富的内置功能和模块,能够帮助开发者处理各种复杂的文本操作。无论是简单的字符串拼接、替换,还是借助正则表达式(re 模块)实现…...

又是一年一度的1024,那就记录一篇算法博客吧~ 【二进制加法探秘】
前言: 又是一年一度的1024,那就记录一篇算法博客吧~ 内容如下~ 1 题目介绍 给定两个二进制字符串 a 和 b,需要返回它们的和,结果以二进制字符串形式给出。 示例 1: 输入: a “11”, b “1” 输出: “100” 示例 2…...

LeetCode--买卖股票的最佳时机含冷冻期--动态规划
一、题目解析 二、算法原理 我们可以使用dp[i]来表示第i天买卖股票所获得的最大利润。由题可得我们只能持有一支股票,并且在卖出后有冷冻期的限制,因此我们会有三种不同的状态: 我们目前持有一支股票,对应的「累计最大收益」记为…...

装了Ubuntu和Windows双系统,如何设置默认启动Windows
可以将默认启动系统设置为Windows,以下是步骤: 1. 修改GRUB配置文件: • 启动到Ubuntu,打开终端。 • 编辑GRUB配置文件: sudo nano /etc/default/grub • 找到这一行: GRUB_DEFAULT0 将0改为对应Wi…...

WPF+MVVM案例实战-设备状态LED灯变化实现
文章目录 1、项目创建2、UI界面布局1. MainWindow.xaml2、颜色转换器实现2.MainViewModel.cs 代码实现 3、运行效果4.源代码下载 1、项目创建 打开 VS2022 ,新建项目 Wpf_Examples,创建各层级文件夹,安装 CommunityToolkit.Mvvm 和 Microsof…...

MySQL--基本介绍
一.数据库前言 1.数据库的相关介绍 关系数据库管理系统(Relational Database Management System:RDBMS)是指包括相互联系的逻辑组织和存取这些数据的一套程序 (数据库管理系统软件)。关系数据库管理系统就是管理关系数据库,并将数…...

PAT甲级1008 Elevator
题目地址:1008 Elevator - PAT (Advanced Level) Practice (pintia.cn) 介绍 The highest building in our city has only one elevator. A request list is made up with N positive numbers. The numbers denote at which floors the elevator will stop, in spe…...

数据导入导出
1.数据加载 - LOAD 语法 LOAD DATA [LOCAL] INPATH filepath [OVERWRITE] INTO TABLE tablename; 操作: 建表 CREATE TABLE myhive.test_load( dt string comment 时间(时分秒) , user_id string comment 用户 ID, word string comment 搜索词 , u…...

git的安装以及入门使用
文章目录 git的安装以及入门使用什么是git?git安装git官网 git初始化配置使用方式初始化配置: git的安装以及入门使用 什么是git? Git 是一个免费开源的分布式版本控制系统,使用特殊的仓库数据库记录文件变化。它记录每个文件的…...

【acwing】算法基础课-搜索与图论
目录 1、dfs(深度优先搜索) 1.1 排列数字 1.2 n皇后问题 搜索顺序1 搜索顺序2 2、bfs(广度优先搜索) 2.1 走迷宫 2.2 八数码 3、树与图的存储 4、树与图的遍历 4.1 树的重心 4.2 图中点的层次 5、拓扑排序 6、最短路问题 6.1 朴素Dijkstra算法 6.2 堆优化Dijks…...
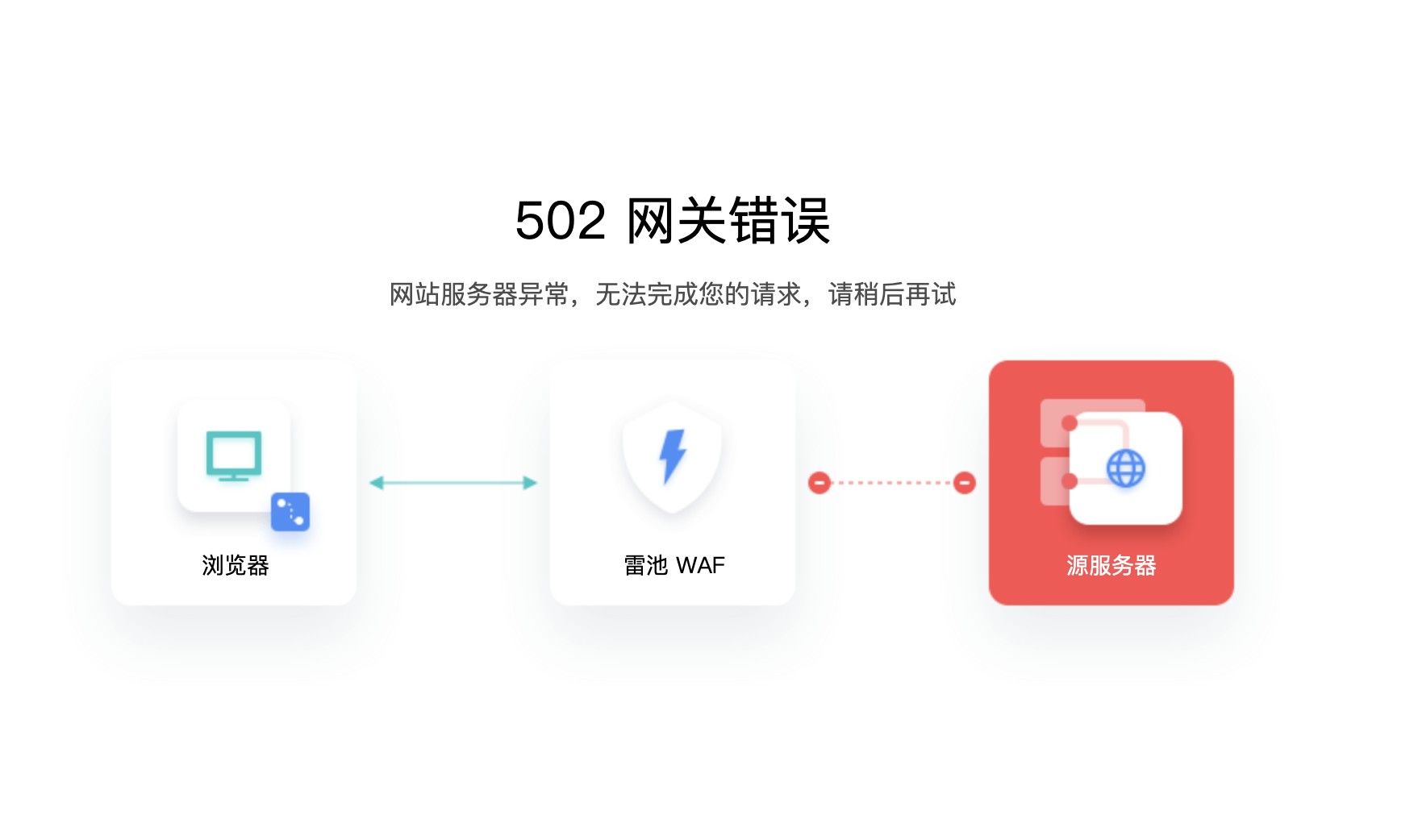
502 错误码通常出现在什么场景?
服务器过载场景 高流量访问:当网站遇到突发的高流量情况,如热门产品促销活动、新闻热点事件导致网站访问量激增时,服务器可能会因承受过多请求而无法及时响应。例如,电商平台在 “双十一” 等购物节期间,大量用户同时…...

面试经典算法题69-两数之和
面试经典算法题69-两数之和 公众号:阿Q技术站 LeetCode.1 问题描述 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。…...

Windows热键冲突终极解决方案:3分钟找出占用你快捷键的“小偷“
Windows热键冲突终极解决方案:3分钟找出占用你快捷键的"小偷" 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detect…...

Linux 系统运行速度慢有哪些排查方法?
Linux 系统变慢通常是资源供需失衡导致的,建议按 CPU、内存、磁盘 I/O、网络的顺序依次排查,优先使用 top、free、iostat 等基础命令定位瓶颈。 先说结论:系统卡顿本质是核心资源被过度占用,需先定位具体瓶颈资源,再针…...

ProxyClaw住宅代理实战:破解反爬虫,赋能AI智能体与数据工程
1. 项目概述:ProxyClaw,一个为AI与数据工程而生的住宅代理网络 如果你正在构建一个需要从互联网上大规模、稳定抓取数据的AI智能体、自动化机器人或者数据管道,那么“被目标网站封禁”这件事,大概率是你最头疼的日常。无论是电商平…...

ServerPackCreator终极指南:3分钟自动化创建Minecraft服务器包 [特殊字符]
ServerPackCreator终极指南:3分钟自动化创建Minecraft服务器包 🚀 【免费下载链接】ServerPackCreator Create a server pack from a Minecraft Forge, NeoForge, Fabric, LegacyFabric or Quilt modpack! 项目地址: https://gitcode.com/gh_mirrors/s…...

如何在Windows上免费获得流畅的B站观影体验:BiliBili-UWP第三方客户端终极指南
如何在Windows上免费获得流畅的B站观影体验:BiliBili-UWP第三方客户端终极指南 【免费下载链接】BiliBili-UWP BiliBili的UWP客户端,当然,是第三方的了 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBili-UWP 还在为网页版B站卡顿…...

基于python-telegram-bot的审批按钮系统设计与实现
1. 项目概述:一个为Telegram机器人设计的审批按钮系统如果你在团队协作、内容审核或者自动化流程中,经常需要通过Telegram机器人来处理“同意”或“拒绝”这类审批请求,那么你很可能遇到过这样的困扰:用户发来一条需要审核的消息&…...

UML 关系详解
依赖(Dependency)含义:一个类的变化会影响到另一个类,但反之不一定。这是一种“使用”关系,通常是临时的、较弱的。典型场景:一个类作为另一个类方法的局部变量、方法参数,或调用静态方法。UML表…...

AI时代就业真相:小白程序员如何抓住大模型机遇,收藏这份必看指南!
智联招聘数据显示,AI短期内替代部分岗位,但新增岗位同样显著。编辑、翻译等白领岗位需求缩减,而AI工程师、数据标注师等需求激增。初级职位衰减,中级与高级职位增长,企业招聘更看重软技能与AI应用能力。建议关注新质生…...

汽车软件化演进:从原生应用到手机集成的技术路径与实战解析
1. 从机械到智能:汽车软件化的十字路口十年前,当福特和通用汽车开始在硅谷和南加州大肆招聘软件工程师时,很多人可能还没意识到,这不仅仅是一次普通的“招兵买马”,而是一场深刻改变汽车工业基因的序曲。2014年那会儿&…...

如何在Windows电脑上直接安装Android应用:3个简单步骤告别模拟器
如何在Windows电脑上直接安装Android应用:3个简单步骤告别模拟器 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经希望在Windows电脑上直接运行An…...