语义分割:YOLOv11的分割模型训练自己的数据集(从代码下载到实例测试)
文章目录
- 前言
- 一、环境搭建
- 二、构建数据集
- 三、修改配置文件
- ①数据集文件配置
- ②模型文件配置
- 四、模型训练和测试
- 模型训练
- 模型验证
- 模型推理
- 总结
前言
专栏目录:YOLOv11改进目录一览 | 涉及卷积层、轻量化、注意力、损失函数、Backbone、SPPF、Neck、检测头等全方位改进
专栏地址:YOLOv11改进专栏——以发表论文的角度,快速准确的找到有效涨点的创新点!
提示:本文是YOLOv11的分割模型训练自己数据集的记录教程,需要大家在本地已配置好CUDA,cuDNN等环境,没配置的小伙伴可以查看我的往期博客:在Windows10上配置CUDA环境教程
2024年9月30日,YOLOv11是Ultralytics最新发布的计算机视觉模型。支持多种任务,包括目标检测、实例分割、图像分类、姿态估计、有向目标检测以及物体跟踪等,本文主要讲述其分割任务的模型搭建训练流程。


代码地址:https://github.com/ultralytics/ultralytics

一、环境搭建
在配置好CUDA环境,并且获取到YOLOv11源码后,建议新建一个虚拟环境专门用于YOLOv11模型的训练。将YOLOv11加载到环境后,安装剩余的包,连接镜像,安装更快一些。
pip install ...
二、构建数据集
YOLOv11模型的训练需要原图像及对应的YOLO格式标签,还未制作标签的可以参考我这篇文章:Labelme安装与使用教程。注意labelme的标签是json格式的,这在训练前需要将json转成yolo的txt格式,链接里提供了相关的转换代码。
将原本数据集按照8:1:1的比例划分成训练集、验证集和测试集三类,划分代码如下,注意改成自己的文件路径。我的原始数据存放在/root/ultralytics-main/data,images里面包含全部图像,newLabel中包含打好的标签。




0 0.5655737704918032 0.460093896713615 0.5655737704918032 0.49765258215962443 0.5737704918032787 0.5352112676056338 0.5819672131147541 0.5915492957746479 0.5922131147540983 0.5821596244131455 0.5840163934426229 0.5305164319248826 0.5778688524590164 0.48826291079812206
# 将图片和标注数据按比例切分为 训练集和测试集
import shutil
import random
import os# 原始路径
image_original_path = "data/images/"
label_original_path = "data/newLabel/"cur_path = os.getcwd()
#cur_path = 'D:/image_denoising_test/denoise/'
# 训练集路径
train_image_path = os.path.join(cur_path, "datasets/images/train/")
train_label_path = os.path.join(cur_path, "datasets/labels/train/")# 验证集路径
val_image_path = os.path.join(cur_path, "datasets/images/val/")
val_label_path = os.path.join(cur_path, "datasets/labels/val/")# 测试集路径
test_image_path = os.path.join(cur_path, "datasets/images/test/")
test_label_path = os.path.join(cur_path, "datasets/labels/test/")# 训练集目录
list_train = os.path.join(cur_path, "datasets/train.txt")
list_val = os.path.join(cur_path, "datasets/val.txt")
list_test = os.path.join(cur_path, "datasets/test.txt")train_percent = 0.8
val_percent = 0.1
test_percent = 0.1def del_file(path):for i in os.listdir(path):file_data = path + "\\" + ios.remove(file_data)def mkdir():if not os.path.exists(train_image_path):os.makedirs(train_image_path)else:del_file(train_image_path)if not os.path.exists(train_label_path):os.makedirs(train_label_path)else:del_file(train_label_path)if not os.path.exists(val_image_path):os.makedirs(val_image_path)else:del_file(val_image_path)if not os.path.exists(val_label_path):os.makedirs(val_label_path)else:del_file(val_label_path)if not os.path.exists(test_image_path):os.makedirs(test_image_path)else:del_file(test_image_path)if not os.path.exists(test_label_path):os.makedirs(test_label_path)else:del_file(test_label_path)def clearfile():if os.path.exists(list_train):os.remove(list_train)if os.path.exists(list_val):os.remove(list_val)if os.path.exists(list_test):os.remove(list_test)def main():mkdir()clearfile()file_train = open(list_train, 'w')file_val = open(list_val, 'w')file_test = open(list_test, 'w')total_txt = os.listdir(label_original_path)num_txt = len(total_txt)list_all_txt = range(num_txt)num_train = int(num_txt * train_percent)num_val = int(num_txt * val_percent)num_test = num_txt - num_train - num_valtrain = random.sample(list_all_txt, num_train)# train从list_all_txt取出num_train个元素# 所以list_all_txt列表只剩下了这些元素val_test = [i for i in list_all_txt if not i in train]# 再从val_test取出num_val个元素,val_test剩下的元素就是testval = random.sample(val_test, num_val)print("训练集数目:{}, 验证集数目:{}, 测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))for i in list_all_txt:name = total_txt[i][:-4]srcImage = image_original_path + name + '.jpg'srcLabel = label_original_path + name + ".txt"if i in train:dst_train_Image = train_image_path + name + '.jpg'dst_train_Label = train_label_path + name + '.txt'shutil.copyfile(srcImage, dst_train_Image)shutil.copyfile(srcLabel, dst_train_Label)file_train.write(dst_train_Image + '\n')elif i in val:dst_val_Image = val_image_path + name + '.jpg'dst_val_Label = val_label_path + name + '.txt'shutil.copyfile(srcImage, dst_val_Image)shutil.copyfile(srcLabel, dst_val_Label)file_val.write(dst_val_Image + '\n')else:dst_test_Image = test_image_path + name + '.jpg'dst_test_Label = test_label_path + name + '.txt'shutil.copyfile(srcImage, dst_test_Image)shutil.copyfile(srcLabel, dst_test_Label)file_test.write(dst_test_Image + '\n')file_train.close()file_val.close()file_test.close()if __name__ == "__main__":main()
划分完成后将会在datasets文件夹下生成划分好的文件,其中images为划分后的图像文件,里面包含用于train、val、test的图像,已经划分完成;
labels文件夹中包含划分后的标签文件,已经划分完成,里面包含用于train、val、test的标签;train.txt、val.txt、test.txt中记录了各自的图像路径。


在训练过程中,也是主要使用这三个txt文件进行数据的索引。
三、修改配置文件
①数据集文件配置
数据集划分完成后,在根目录下新建data.yaml文件,即data.yaml,用于指明数据集路径和类别,我这边只有一个类别,只留了一个,多类别的在name内加上类别名即可。data.yaml中的内容为:
path: ../datasets/images # 数据集所在路径
train: train # 数据集路径下的train.txt
val: val # 数据集路径下的val.txt
test: test # 数据集路径下的test.txt# Classes
names:0: bubbeplume
②模型文件配置
在ultralytics/cfg/models/11文件夹下存放的是YOLOv11分割模型的各个版本的模型配置文件,检测的类别是coco数据的80类。在训练自己数据集的时候,只需要将其中的类别数修改成自己的大小。此处以yolo11-seg.yaml文件中的模型为例,将 nc: 1 # number of classes 修改类别数 修改成自己的类别数,如下:

# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11-seg instance segmentation model. For Usage examples see https://docs.ultralytics.com/tasks/segment# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n-seg.yaml' will call yolo11-seg.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 355 layers, 2876848 parameters, 2876832 gradients, 10.5 GFLOPss: [0.50, 0.50, 1024] # summary: 355 layers, 10113248 parameters, 10113232 gradients, 35.8 GFLOPsm: [0.50, 1.00, 512] # summary: 445 layers, 22420896 parameters, 22420880 gradients, 123.9 GFLOPsl: [1.00, 1.00, 512] # summary: 667 layers, 27678368 parameters, 27678352 gradients, 143.0 GFLOPsx: [1.00, 1.50, 512] # summary: 667 layers, 62142656 parameters, 62142640 gradients, 320.2 GFLOPs# YOLO11n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 2, C3k2, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 2, C3k2, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 2, C3k2, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 2, C2PSA, [1024]] # 10# YOLO11n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, C3k2, [512, False]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)- [[16, 19, 22], 1, Segment, [nc, 32, 256]] # Detect(P3, P4, P5)修改完成后,模型文件就配置好啦。
四、模型训练和测试
YOLOv11训练可使用命令或者代码进行运行,在训练过程中使用的具体的参数信息可在ultralytics/cfg/default.yaml路径下找到。
首先需要将default.yaml中的task设置成segment
模型训练
命令训练
打开终端,输入命令
yolo task=segment mode=train model=ultralytics/cfg/models/11/yolo11-seg.yaml data=data.yaml batch=32 epochs=300 imgsz=640 workers=10 device=0
- task:表示任务为目标分割,可选detect, segment,classify
- mode:表示模式,可选train,val,predict,export
- model:表示使用的模型,这里我就是使用的刚刚新建的yolov8-mask.yaml
- data:表示训练的图像文件,
- device:表示是否使用GPU进行训练,可选0,1,2…或者cpu
- epoch:表示训练的轮次
- batch:表示每次送人训练的图像数量,当报错OOM时,需调小batch大小,但大小需要设置为2的幂次,最小为1
- imgsz:表示图像大小,会统一缩放成指定大小
- workers:指数据装载时cpu所使用的线程数,过高时会报错:[WinError 1455] 页面文件太小,无法完成操作,此时就只能将default调成0了。
代码训练
from ultralytics import YOLOif __name__ == '__main__':model = YOLO(r'ultralytics/cfg/models/11/yolo11-seg.yaml') model.train(data=r'data.yaml',imgsz=640,epochs=100,single_cls=True, batch=16,workers=10,device='0',)训练情况:


模型验证
命令验证
yolo task=segment mode=val model=runs/segment/train/best.pt data=data.yaml device=0
在验证阶段,mode模式为验证,mode=val,模型使用训练完成的权重文件,第一次训练完存放在:runs/segment/train/best.pt,best.pt就是训练完成后的最佳权重。
当然也需要指定数据集data=data.yaml和所用的设备device=0,和训练时一致。也可以添加batch、imgsz,含义和训练时一致。
代码验证
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':model = YOLO('runs/segment/train/best.pt')model.val(data='data.yaml',imgsz=640,batch=16,split='test',workers=10,device='0',)模型推理
命令推理
yolo task=segment mode=predict model=runs/segment/train/best.pt source=inference device=0
在推理阶段,mode模式为预测,mode= predict,模型使用训练完成的权重文件:runs/segment/train/best.pt,source表示需要预测的图像文件路径,inference中存放了准备预测的图像。
代码推理
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':model = YOLO('runs/segment/train/best.pt')model.predict(source='inference',imgsz=640,device='0',)总结
以上就是YOLOv11训练自己数据集的全部过程啦,欢迎大家在评论区交流~
相关文章:
语义分割:YOLOv11的分割模型训练自己的数据集(从代码下载到实例测试)
文章目录 前言一、环境搭建二、构建数据集三、修改配置文件①数据集文件配置②模型文件配置 四、模型训练和测试模型训练模型验证模型推理 总结 前言 专栏目录:YOLOv11改进目录一览 | 涉及卷积层、轻量化、注意力、损失函数、Backbone、SPPF、Neck、检测头等全方位改…...

Python爬虫:从入门到精通
Python爬虫:从入门到精通 在数字时代,信息就如同水源,源源不绝。然而,当你想要从海量的信息中汲取有价值的“水”,你会发现这并不是一件容易的事。这就是为什么网络爬虫出现了。它们帮助我们在网络的海洋中航行&#…...

Web组态软件
Web组态软件是近年来前端开发领域的一股新兴力量,它以其独特的魅力吸引着越来越多的开发者们。那么,Web组态软件到底是什么?它有哪些特点?我们又该如何选择和使用它呢?下面,就让我们一起探讨这些问题。 一…...

Java中为什么要私有化构造方法
为什么要私有化构造方法 要私有化的方法不是来描述一类事物的,创建没有任何意义 解决方案: 提示:这里填写该问题的具体解决方案: 为什么要将构造方法私有化? 问:如果要限制一个类对象产生,即&…...

【大数据学习 | kafka】kafuka的基础架构
1. kafka是什么 Kafka是由LinkedIn开发的一个分布式的消息队列。它是一款开源的、轻量级的、分布式、可分区和具有复制备份的(Replicated)、基于ZooKeeper的协调管理的分布式流平台的功能强大的消息系统。与传统的消息系统相比,KafKa能够很好…...
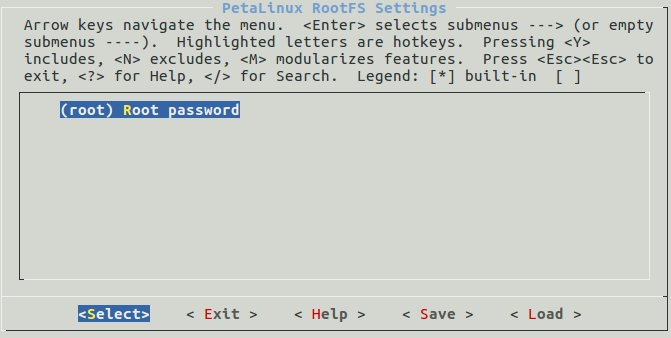
2-petalinux2018.3摸索记录-petalinux rootfs
1Filesystem Packages文件系统软件包2Petalinux Package GroupsPetalinux软件包组3Image Features镜像特性4apps应用程序5user packages用户软件包6Petalinux RootFS SettingsPetalinux根文件系统设置 Filesystem Packages(文件系统软件包) 这个选项主要…...

RHCE作业二
1.要求: 配置nginx服务通过ip访问多网站 2. 1关闭防火墙 2创建ip 3配置 4创建文件 5测试...
使用手册)
GPS/北斗时空安全隔离装置(卫星时空防护装置)使用手册
GPS/北斗时空安全隔离装置(卫星时空防护装置)使用手册 GPS/北斗时空安全隔离装置(卫星时空防护装置)使用手册 时空安全隔离装置采用先进的防欺骗抗干扰技术,能够有效检测识别欺骗干扰信号,并快速对异常信号进行关断、切换,消除欺骗干扰影响。…...

【C++篇】深度解析类与对象(下)
引言 在上一篇博客中,我们学习了C的基础类与对象概念,包括类的定义、对象的使用和构造函数的作用。在这一篇,我们将深入探讨C类的一些重要特性,如构造函数的高级用法、类型转换、static成员、友元、内部类、匿名对象,…...

【gRPC】什么是RPC——介绍一下RPC
说起RPC,博主使用CPP手搓了一个RPC项目,RPC简单来说,就是远程过程调用:我们一般在本地传入数据进行执行函数,然后返回一个结果;当我们使用RPC之后,我们可以将函数的执行过程放到另外一个服务器上…...

谈谈你对AQS的理解
AQS 是多线程同步器,它是 JUC 包中多个组件的底层实现,如 Lock、CountDownLatch、Semaphore等都用到了AQS。 从本质上来说,AQS 提供了两种锁机制,分别是排它锁,和共享锁。 排它锁,就是存在多线程竞争同一…...

Bitcoin全节点搭建
1. wget https://bitcoincore.org/bin/bitcoin-core-0.20.1/bitcoin-0.20.1-x86_64-linux-gnu.tar.gz 2.tar -xzvf bitcoin-0.20.1-x86_64-linux-gnu.tar.gz mv bitcoin-0.20.1 bitcoin 3.创建配置文件(bitcoin.conf) mkdir -p /btc_data mkdir ~/.b…...

【mysql进阶】4-6. InnoDB 磁盘文件
InnoDB 磁盘⽂件 1 InnoDB存储引擎包含哪些磁盘⽂件? 🔍 分析过程 ✅ 解答问题 InnoDB的磁盘⽂件主要是表空间⽂件和其他⽂件,表空间包括:系统表空间、独⽴表空间、通⽤表空间、临时表空间和撤销表空间;其他⽂件有重做…...
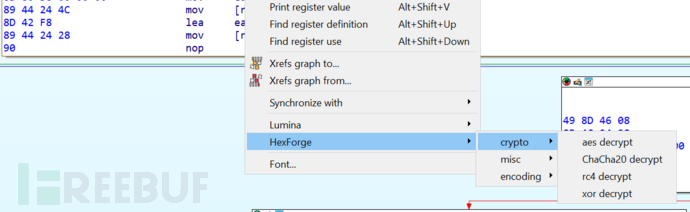
HexForge:一款用于扩展安全汇编和十六进制视图的IDA插件
关于HexForge HexForge是一款用于扩展安全汇编和十六进制视图的IDA插件,在该工具的帮助下,广大研究人员可以方便地直接从 IDA Pro 界面数据解码、解密或执行安全数据审计任务。 功能介绍 1、从 IDA 的反汇编或十六进制视图复制原始十六进制;…...
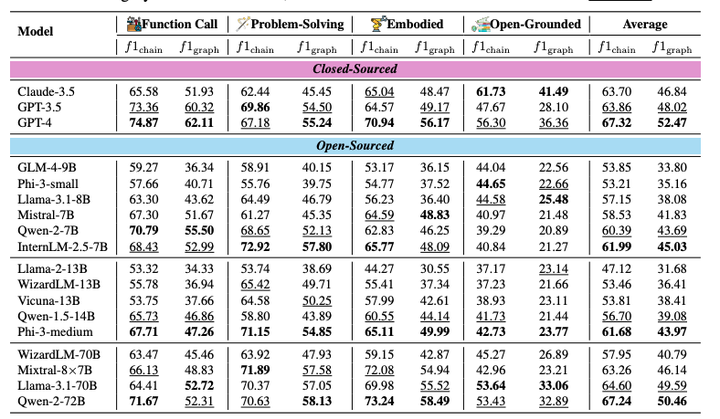
WORFBENCH:一个创新的评估基准,目的是全面测试大型语言模型在生成复杂工作流 方面的性能。
2024-10-10,由浙江大学和阿里巴巴集团联合创建的WORFBENCH,一个用于评估大型语言模型(LLMs)生成工作流能力的基准测试。它包含了一系列的测试和评估协议,用于量化和分析LLMs在处理复杂任务时分解问题和规划执行步骤的能力。WORFBE…...

SpringBoot 集成 Activiti 7 工作流引擎
一. 版本信息 IntelliJ IDEA 2023.3.6JDK 17Activiti 7 二. IDEA依赖插件安装 安装BPM流程图插件,如果IDEA的版本超过2020,则不支持actiBPM插件。我的IDEA是2023版本我装的是 Activiti BPMN visualizer 插件。 在Plugins 搜索 Activiti BPMN visualizer 安装创建…...

UVM初学篇 -(22)UVM field_automation 域的自动化机制
field_automation机制是域的自动化的机制,这个机制的最大的优点是可以对一些变量进行批量的处理,比如对象拷贝、克隆、打印之类的变量。 一、 成员变量的注册 使用field_automation机制首先要用uvm_field 系列宏完成变量的注册,类中的成员变…...

STL二分查找
本课主要介绍容器部分里面的二分查找函数。涉及的函数有 3 个,这 3 个函数的强两个输入参数都和迭代器有关,或者说参数是可以迭代的,而第三个参数则是你要查找的值。 1. binary_search binary_search 的返回结果是 bool 值,如果找…...

啤酒游戏—企业经营决策沙盘
感谢黄浦区文华学院的邀请,今年是为南房集团开展系统思考培训的第二年。我们现在为客户设计的一整年系统思考训练中,会将系统环路结构图与真实议题研讨作为前置内容,让大家在理解整体框架后,再体验麻省理工学院系统动力学著名的“…...
尚硅谷-react教程-求和案例-@redux-devtools/extension 开发者工具使用-笔记
## 7.求和案例_react-redux开发者工具的使用(1).npm install redux-devtools/extension(2).store中进行配置import { composeWithDevTools } from redux-devtools/extension;export default createStore(allReducer,composeWithDevTools(applyMiddleware(thunk))) src/redux/s…...

大模型风口已至:月薪30K+的AI Agent开发岗,你准备好了吗?
文章介绍了如何借助不同版本的Agents实现智能自动化,并详细描述了AI应用工程师和大模型算法工程师的岗位职责和任职要求。文章还强调了AI学习的重要性,指出最先掌握AI的人将具有竞争优势,并提供了大模型AI学习和面试资料,帮助读者…...

microeco:微生物组学分析工具的终极指南,让数据分析变得简单快速
microeco:微生物组学分析工具的终极指南,让数据分析变得简单快速 【免费下载链接】microeco An R package for downstream data analysis of microbiome omics data 项目地址: https://gitcode.com/gh_mirrors/mi/microeco 面对海量的微生物组学数…...

摄像头驱动调试避坑指南:用示波器快速定位I2C不通、MIPI无信号问题
摄像头驱动调试避坑指南:用示波器快速定位I2C不通、MIPI无信号问题 当摄像头模组在硬件调试阶段出现异常时,软件工程师往往会陷入"配置检查-重新烧录-再检查"的死循环。实际上,80%的摄像头初始化失败问题源于硬件信号层面的异常。本…...

5分钟掌握FanControl:Windows风扇控制的终极免费解决方案
5分钟掌握FanControl:Windows风扇控制的终极免费解决方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending…...
)
别再只调分辨率了!手把手教你用VESA时序搞定1080P显示器驱动(附Verilog代码)
从VESA标准到FPGA实战:构建1080P显示驱动的完整逻辑链 在数字显示技术领域,驱动一块19201080分辨率的屏幕远不止是配置几个参数那么简单。当我第一次尝试用FPGA驱动高清显示器时,发现大多数教程都停留在"设置分辨率"的层面…...

Claude Code与Cursor CLI集成:AI辅助编程工作流优化实践
1. 项目概述:Claude Code与Cursor CLI的桥梁如果你和我一样,日常开发中同时使用Claude Code和Cursor,并且对Composer 2的执行速度印象深刻,那么你很可能也面临过这样的困境:Claude Code在规划、分析和代码审查方面表现…...

通过API Key管理与审计日志功能加强企业级应用安全
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过API Key管理与审计日志功能加强企业级应用安全 将大模型能力集成到企业级应用,不仅关乎功能实现,更是一…...

为什么设计师集体弃用Sora 2改投Veo?——从渲染延迟、长时序连贯性到版权水印支持的6维生产力对比
更多请点击: https://intelliparadigm.com 第一章:Veo vs Sora 2视频质量对比测试全景概览 为客观评估当前主流生成式视频模型的视觉保真度与时空一致性,我们构建了统一测试基准,涵盖运动连贯性、纹理细节还原、文本-视频对齐精度…...

Perplexity接入Google Scholar的5大避坑指南:实测失效率下降87%的权威配置方案
更多请点击: https://intelliparadigm.com 第一章:Perplexity接入Google Scholar的整合背景与价值定位 学术信息检索正经历从“关键词匹配”向“语义理解可信溯源”的范式跃迁。Perplexity 作为基于大语言模型的实时问答引擎,其核心优势在于…...

Wireshark解密不止于IPSec:一份TLS/SSL、HTTPS、SSH等常见加密协议的解密指南
Wireshark解密不止于IPSec:一份TLS/SSL、HTTPS、SSH等常见加密协议的解密指南 当你面对一个加密的网络流量时,是否曾感到无从下手?无论是调试HTTPS API调用、分析SSH连接问题,还是研究QUIC协议的行为,加密流量总是像一…...