Spark 基础操作
Spark 操作
创建操作(Creation Operation)
用于RDD创建工作。RDD创建只有两种方法,一种是来自于内存集合和外部存储系统,另一种是通过转换操作生成的RDD
转换操作(Transformation Operation)
将RDD通过一定的操作变成新的RDD,比如HadoopRDD可以使用map操作变换为MappedRDD
RDD的转换操作是惰性操作,它只是定义了一个新的RDDs,并没有立即执行
控制操作(Control Operation)
进行RDD持久化,可以让RDD按不同的存储策略保存在磁盘或内存中,比如cache接口默认将RDD缓存在内存中
行动操作(Action Operation)
能够触发Spark运行的操作,例如,对RDD进行collect就是行动操作
Spark中行动操作分为两类,一类的操作结果变成Scala集合或者变量,另一类将RDD保存到外部文件系统或者数据库中
创建操作
parallelize[T](seq:Seq[T], numSlices:Int)
parallelize 在一个已经存在的Scala集合上创建(一个Seq对象)。集合的对象将会被复制,创建出一个可以被并行操作的分布式数据集
makeRDD[T](seq:Seq[(T, Seq[String])]):RDD[T]
并行化集合创建操作
基础转换操作
map[U](f:(T) => U):RDD[U]
map操作是对RDD中的每个元素都执行一个指定的函数来产生一个新的RDD,任何原RDD中的元素在新RDD中都有且只有一个元素与之对应
distinct():RDD[(T)]/distinct(nPartitions):RDD[(T)]
distinct操作是去除RDD重复的元素,返回所有元素不重复RDD
flatMap[U](f:(T) => TraversableOnce[U]):RDD[U]
flatMap操作与map类似,区别是原RDD中的每个元素经过map处理后只能生成一个元素,而在flatMap操作中原RDD中的每个元素可生成一个或多个元素来构建RDD
coalesce(numPartitions:Int,shuffle:Boolean = false):RDD[T]
coalesce操作使用HashPartitioner进行重分区,第一个参数为重分区的数目,第二个是否进行shuffle,默认情况为false
repartition(numPartitions:Int):RDD[T]
repartition操作是coalesce函数第二个参数为true的实现
randomSplit(weights:Array[Double], send:Long):Array[RDD[T]]
randomSplit操作是根据weights权重将一个RDD分隔为多个RDD
glom():RDD[Array[T]]
glom操作则是RDD中每一个分区所有类型为T的数据转变成元素为T的数组[Array[T]]
union(other:RDD[T]):RDD[T]
union操作是将两个RDD合并,返回两个RDD的并集,返回元素不去重
intersection(other:RDD[T]):RDD[T]
intersection操作类似SQL中的inner join操作,返回两个RDD交集,返回元素去重
subtract(other:RDD[T]):RDD[T]
subtract 返回在RDD中出现,且不在otherRDD中出现的元素
mapPartitions[U](f:(Iter), preserversPartitons:Boolean)
mapPartitions操作和map操作类似,只不过映射的参数由RDD中的每一个元素变成了RDD中每一个分区的迭代器
其中preserversPartitons表示是否保留父RDD的partitioner分区信息
如果在映射的过程中需要频繁创建额外的对象,使用mapPartitions操作要比map操作高效得多
比如,将RDD中的所有数据通过JDBC连接写入数据库,如果使用map函数,可能要为每一个元素都创建一个connection,这样开销很大
如果使用mapPartitions,那么只需要针对每一个分区建立一个connection
mapPartitionsWithIndex[U](f:(Iter), preserversPartitons:Boolean):RDD[U]
mapPartitionsWithIndex 操作作用类似于mapPartitions,只是输入参数多一个了分区索引
zip[U](other:RDD[U]):RDD[(T,U)]
zip操作用于将两个RDD组合成Key/Value形式的RDD,这里默认两个RDD的partition数量以及元素数量相同,否则会抛出异常
zipPartitions[B,V](rdd2:RDD[B])
zipPartitions 操作将多个RDD按照partition组合成新的RDD,该操作需要组合的RDD具有相同的分区数,但对于每个分区内的元素数量没有要求
zipWithIndex():RDD[(T,Long)]
zipWithIndex操作将RDD中的元素和这个元素在RDD中的ID(索引号)组合成键/值对
zipWithUniqueId():RDD[(T,Long)]
zipWithUniqueId 操作将RDD中的元素和一个唯一ID组合成键/值对,该唯一ID生成算法如下:
- 每个分区中第一个元素的唯一ID值为: 该分区索引号
- 每个分区中第N个元素的唯一ID值为:(前一个元素的唯一ID值) + (该RDD总的分区数)
键值转换操作
partitionBy(partitioner: Partitioner):RDD[(K, V)]
partitionBy 操作根据partitioner函数生成新的ShuffleRDD
mapValues[U](f:(V) => U):RDD[(K, U)]
mapValues类似于map,只不过mapValues是针对[K,V]中的V值进行map操作
flatMapValues[U](f:(V) => TraverableOnce[U]):RDD[(K,U)]
flatMapValues 相对flatMap, flatMapValues是针对[K,V]中的V值进行flatMap操作
combineByKey[C](createCombiner:(V), mergeValue:(C, V), mergeCombiners)
combineByKey 操作用于将RDD[K,V]转换成RDD[K,C].这里V类型和C类型可以相同也可以不同
combineByKey 参数含义
- createCombiner: 组合器函数,用于将V类型转换成C类型,输入参数为RDD[K,V]中的V,输出为C
- mergeValue: 合并值函数,将一个C类型和一个V类型值合并成一个C类型,输入参数为(C,V),输出为C
- mergeCombiners: 合并组合器函数,用于将两个C类型值合并成一个C类型,输入参数为(C,C),输出为C
- numPartitons: 结果RDD分区数,默认保持原有的分区数
- partitioner: 分区函数,默认为HashPartitioner
- mapSideCombine: 是否需要在Map端进行combine操作,类似于MapReduce中的combine,默认为true
foldByKey(zeroValue:V)(func:(V, V)=>V):RDD[(K,V)]
foldByKey 操作用于RDD[K, V]转换K将V做折叠、合并处理。其中参数zeroValue表示先根据映射函数将zeroValue应用于V
进行初始化V,再将映射函数应用于初始化后的V
reduceByKey(func:(V, V) => V):RDD[(K,V)]
reduceByKey操作用于将RDD[K,V]中每个K对应的V值根据映射函数来运算,其中参数numPartitions用于指定分区数,参数partitioner用于指定分区函数
reduceByLocally(func:(V, V) => V):Map[K,V]
reduceByLocally 和 reduceByKey 功能类似,不同的是,reduceByLocally运算结果映射到一个Map[K,V]中,而不是RDD[K,V]
groupByKey():RDD[(K, Iterable[V])]
groupByKey 操作用于将RDD[K,V]中每个K对应的V值合并到一个集合Iterable[V]中
cogroup[W](other:RDD[(K,V)]):RDD[(K,(Iterable[V], Iterable[W]))]
cogroup 相当于SQL中的全外关联,返回左右RDD中的记录,关联不上的为空
可传入的参数有1~3个RDD,参数numPartitons用于指定分区数,参数partitioner用于指定分区函数
join、fullOuterJoin、leftOuterJoin、rightOuterJoin
join、fullOuterJoin、leftOuterJoin、rightOuterJoin 都是针对RDD[K,V]中K值相等的连接操作
分别对应内连接、全连接、左连接和右连接。这些操作都调用cogroup进行实现,subtractByKey和基本操作subtract,只是subtractByKey针对的是键值操作
其中参数numPartions用于指定分区数,参数partitioner用于指定分区函数
控制操作
cache():RDD[T]
缓存
persist():RDD[]
persit(level:StorageLevel):RDD[T]
行动操作
集合标量行动操作
first(): T 表示返回RDD中的第一个元素,不排序
count(): Long 表示返回RDD中的元素个数
reduce(f:(T, T) => T):T
根据映射函数f,对RDD中的元素进行二元计算
collect(): Array[T]
表示将RDD转换成数组
take(num: Int): Array[T]
表示获取RDD中从0到num-1下标的元素,不排序
top(num: Int): Array[T]
表示从RDD中,按照默认(降序)或者指定的排序规则,返回前num个元素
takeOrdered(num: Int): Array[T]
和top类似,只不过以和top相反的顺序返回元素
aggregate[U](zeroValue: U)(seqOp: (U, T) => U, combOp: (U,U) => U)
用户聚合RDD中的元素,先使用seqOp将RDD中每个分区中的T类型聚合成U类型
再使用combOp将之前每个分区聚合后的U类型聚合成U类型,特别注意seqOp和combOp都会使用zeroValue的值,zeroValue的类型的为U
fold(zeroValue: T)(op: (T, T)=>T): Taggregate
fold是aggregate的简化,将aggregate中的seqOp和combOp使用同一个函数op
lookup(key: K): Seq[V]
lookup用于(K,V)类型的RDD,指定K值,返回RDD中该K对应的所有V值
countByKey(): Map[K, Long]
countByKey 统计RDD[K, V]中每个K的数量
foreach(f:(T) => Unit): Unit
foreach 遍历RDD,将函数f应用于每一个元素
要注意如果对RDD执行foreach,只会在Executor端有效,而并不是Driver端
foreachPartition(f:(Iterator[T]) => Unit): Unit
foreachPartition 和 foreach类似,只不过是对每一个分区使用f
sortBy[K](f:(T), ascending:Boolean, numPartitions):RDD[T]
sortBy根据给定的排序k函数将RDD中的元素进行排序
存储行动操作
saveAsTextFile(path: String): Util
saveAsTextFile 用于将RDD以文本文件的格式存储到文件系统中,codec参数可以指定压缩的类名
saveAsTextFile 用于将RDD以SequenceFile的文件格式保存到HDFS上
saveAsObjectFile(path: String): Util
saveAsObjectFile 用于将RDD中的元素序列化对象,存储到文件中,对于HDFS,默认采用SequenceFile保存
saveAsHadoop
saveAsHadoopFile 是将RDD存储在HDFS上的文件中
saveAsHadoopDataset(conf: JobConf): Unit
用于将RDD保存到除了HDFS的其他存储中,比如HBase
在JobConf中,通常需要关注或者设置5个参数: 文件的保存路径、key值的class类型、value值的class类型、RDD的输出格式以及压缩相关参数
相关文章:

Spark 基础操作
Spark 操作 创建操作(Creation Operation) 用于RDD创建工作。RDD创建只有两种方法,一种是来自于内存集合和外部存储系统,另一种是通过转换操作生成的RDD 转换操作(Transformation Operation) 将RDD通过一定的操作变成新的RDD,比如HadoopR…...

VoLTE 微案例:VoLTE 注册失败,I-CSCF 返回 403,HSS(UAR) 返回 5001
目录 1. 问题描述 2. 故障注册流程与正常流程对照 3. 结论 博主wx:yuanlai45_csdn 博主qq:2777137742 想要 深入学习 5GC IMS 等通信知识(加入 51学通信),或者想要 cpp 方向修改简历,模拟面试,学习指导都可以添加博主低价指导哈。 1. 问题描述...

智能财务 | 数据与融合,激发企业财务数智化转型思考
数据与融合,激发企业财务数智化转型思考 用友持续深耕企业财务领域,见证中国企业走过了财务电算化、信息化时代,当下共同经历数智化时代。2023 年度,通过走访标杆企业,与高校教授、权威机构学者共同探讨等形式…...

docker 下载netcore 镜像
dotnet-docker/README.runtime.md at main dotnet/dotnet-docker GitHub docker pull mcr.microsoft.com/dotnet/runtime:8.0 docker pull mcr.microsoft.com/dotnet/runtime:3.1...

Ajax:请求 响应
Ajax:请求 & 响应 AjaxjQuery的Ajax接口$.get$.post$.ajax PostMan 接口测试getpost Ajax 浏览器中看到的数据,并不是保存在浏览器本地的,而是实时向服务器进行请求的。当服务器接收到请求,就会发回一个响应,此时浏…...

WebForms DataList 控件深入解析
WebForms DataList 控件深入解析 概述 在 ASP.NET WebForms 的众多服务器控件中,DataList 控件是一个功能强大的数据绑定控件,它允许开发者以表格形式展示和操作数据。DataList 控件类似于 Repeater 控件,但提供了更多的内置布局和样式选项…...

【有啥问啥】DINO:一种改进的去噪锚框的端到端目标检测器
DINO:一种改进的去噪锚框的端到端目标检测器 在目标检测领域,DINO(DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection)是一种创新的端到端目标检测模型,旨在解决传统目标检测算法中的一些关…...

自由学习记录(15)
Java注解 else if的省略问题(可能看花) else if也是取最近的if连通,看上去加了{}就可以正常执行了,缩进要命,不提示真容易看错, 组合数公式和数组参数 在 C 中,数组作为函数参数时,…...
Docker 部署 JDK11 图文并茂简单易懂
部署 JDK11 ( Docker ) [Step 1] : 下载JDK11 - JDK 11 | Oracle 甲骨文官网 [Step 2] : jdk11上传服务器/root/jdk11 可自行创建文件夹 进入目录 /root/jdk11 解压文件 tar -zxvf jdk-11.0.22_linux-x64_bin.tar.gz解压后 进入 /root/jdk11/jdk-11.0.22 创建 jre 文件 ./bi…...

Cisco ASAv虚拟防火墙
EVE-NG模拟器使用Cisco防火墙版本ASAv-9.20.3-PLR-Licensed。配置如下,主要是三个方面,配置管理口地址模式DHCP,配置安全级别;第二,开启http服务器,配置允许访问主机的网段和接口;最后配置用户名…...

w~自动驾驶合集6
我自己的原文哦~ https://blog.51cto.com/whaosoft/12286744 #自动驾驶的技术发展路线 端到端自动驾驶 Recent Advancements in End-to-End Autonomous Driving using Deep Learning: A SurveyEnd-to-end Autonomous Driving: Challenges and Frontiers 在线高精地图 HDMa…...

C/C++ H264文件解析
C实现H264文件以及一段H264码流解析,源码如下: h264Parse.h: #ifndef _H264PARSE_H_ #define _H264PARSE_H_#include <fstream>class H264Parse { public:int open_file(const std::string &filename);/*** brief 从文件中读取一个nalu&…...

【Windows】电脑端口明明没有进程占用但显示端口被占用(动态端口)
TOC 一、问题 重启电脑后,启用某个服务显示1089端口被占用。 查看是哪个进程占用了: netstat -aon | findstr "1089"没有输出,但是换其他端口,是可以看到相关进程的: 现在最简单的方式是给我的服务指定另…...

Redis 持久化 问题
前言 相关系列 《Redis & 目录》(持续更新)《Redis & 持久化 & 源码》(学习过程/多有漏误/仅作参考/不再更新)《Redis & 持久化 & 总结》(学习总结/最新最准/持续更新)《Redis & …...

vivado 配置
配置 配置指的是将特定应用数据加载到 FPGA 器件的内部存储器的进程。 赛灵思 FPGA 配置数据储存在 CMOS 配置锁存 (CCL) 中,因此配置数据很不稳定,且在每次 FPGA 器件上电后都必须重 新加载。 赛灵思 FPGA 器件可通过配置引脚,自行…...

Java如何实现PDF转高质量图片
大家好,我是 V 哥。在Java中,将PDF文件转换为高质量的图片可以使用不同的库,其中最常用的库之一是 Apache PDFBox。通过该库,你可以读取PDF文件,并将每一页转换为图像文件。为了提高图像的质量,你可以指定分…...

itemStyle.normal.label is deprecated, use label instead.
itemStyle.normal.label is deprecated, use label instead. normal’hierarchy in label has been removed since 4.0. All style properties are configured in label directly now. 错误写法: itemStyle: {normal: {// color: #00E0FF, // 设置折线点颜色 labe…...

如何在 Linux VPS 上保护 MySQL 和 MariaDB 数据库
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 有许多在 Linux 和类 Unix 系统上可用的 SQL 数据库语言实现。MySQL 和 MariaDB 是在服务器环境中部署关系型数据库的两个流行选项…...

CSS 样式 box-sizing: border-box; 用于控制元素的盒模型如何计算宽度和高度
文章目录 box-sizing: border-box; 的含义默认盒模型 (content-box)border-box 盒模型 在微信小程序中的应用示例 在微信小程序中,CSS 样式 box-sizing: border-box; 用于控制元素的盒模型如何计算宽度和高度。具体来说, box-sizing: border-box; 会改…...
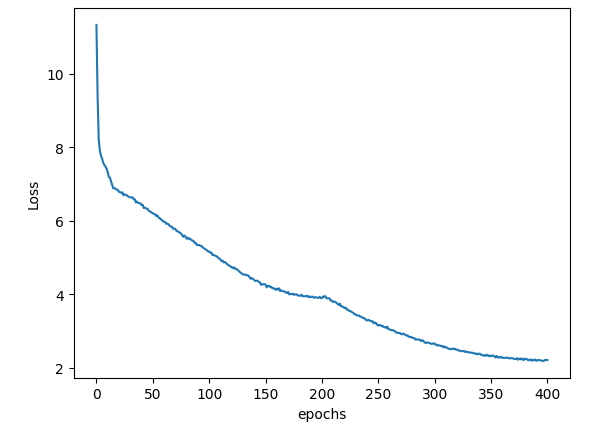
预训练 BERT 使用 Hugging Face 和 PyTorch 在 AMD GPU 上
Pre-training BERT using Hugging Face & PyTorch on an AMD GPU — ROCm Blogs 2024年1月26日,作者:Vara Lakshmi Bayanagari. 这篇博客解释了如何从头开始使用 Hugging Face 库和 PyTorch 后端在 AMD GPU 上为英文语料(WikiText-103-raw-v1)预训练…...

JSON数据同步利器:深度解析ogre-software/json-synchronizer的核心原理与应用
1. 项目概述:一个被低估的JSON数据同步利器如果你经常和JSON数据打交道,尤其是在前后端分离、微服务架构或者多数据源集成的场景下,你肯定遇到过这样的烦恼:手头有两份甚至多份JSON数据,它们结构相似,但内容…...

ReAct不是格式游戏!揭秘让LLM从“文本生成器”变身“决策引擎”的底层逻辑
文章指出,ReAct常被误解为高级Prompt工程,但核心是闭环执行架构。真正的ReAct强调“决策-执行-反馈”循环,而非固定的Thought/Action/Observation格式。工程代码定义流程,模型生成内容,实现真实工具调用与反馈闭环。文…...

一键解决!VisualCppRedist AIO彻底告别Windows DLL错误困扰
一键解决!VisualCppRedist AIO彻底告别Windows DLL错误困扰 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 还记得那个令人抓狂的时刻吗?…...

MCA Selector技术架构深度解析:Minecraft区块管理系统的实现原理
MCA Selector技术架构深度解析:Minecraft区块管理系统的实现原理 【免费下载链接】mcaselector A tool to select chunks from Minecraft worlds for deletion or export. 项目地址: https://gitcode.com/gh_mirrors/mc/mcaselector MCA Selector是一款专为M…...

不可错过的AI教材写作攻略,借助工具轻松达成低查重目标
教材编写中的挑战与AI工具的解决方案 在教材编写的过程中,确保原创性与合规性之间的平衡是一项关键任务。创作者在借鉴优秀教材的同时,又担心查重率可能会超标;而在尝试自主创作时,又容易面临逻辑不够严密或内容不准确的问题。更…...

从一张‘正常’图片到服务器沦陷:文件包含漏洞如何让图片马‘活’过来?
从一张“正常”图片到服务器沦陷:揭秘文件包含漏洞的致命组合攻击 当你深夜检查服务器日志时,发现有人上传了一张普通的风景图。文件头校验通过,MIME类型正确,甚至预览也显示正常。但三天后,这张“图片”却成为攻击者控…...

2026十大建议考的经济学专业证书有哪些
2026年十大经济学专业证书推荐经济学专业证书能够提升职业竞争力,尤其在数据分析、金融和经济预测领域。以下是2026年值得考取的十大经济学专业证书,包括CDA数据分析师证书等热门选择。1. CDA数据分析师证书CDA数据分析师证书是数据分析领域的权威认证&a…...

Base64编码实战:手把手教你用PHPStudy环境在本地调试图片/PDF内联显示
Base64编码实战:手把手教你用PHPStudy环境在本地调试图片/PDF内联显示 在Web开发中,Base64编码是一种常见的数据处理方式,它可以将二进制数据(如图片、PDF等)转换为可打印的ASCII字符串,从而方便地在HTML中…...

ComfyUI-Impact-Pack完全指南:如何彻底解决AI图像细节增强难题
ComfyUI-Impact-Pack完全指南:如何彻底解决AI图像细节增强难题 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地址: …...

Origin9.1绘图避坑指南:从数据导入到论文级.tif图保存的完整流程
Origin9.1科研绘图全流程避坑指南:从数据导入到论文级.tif输出 科研绘图是论文写作中不可或缺的一环,而Origin9.1作为经典的数据可视化工具,在学术界有着广泛的应用。然而,从原始数据到最终符合期刊要求的图表,这一过程…...