逻辑回归与神经网络
从逻辑回归开始学习神经网络
神经网络直观上解释,就是由许多相互连接的圆圈组成的网络模型:

而逻辑回归可以看作是这个网络中的一个圆圈:

圆圈被称为神经元,整个网络被称为神经网络。
本节的任务是我们究竟如何理解具体的一个神经元,又如何将神经元组成一个大的神经网络。

为了后面的描述更加严谨,这里做一个提前声明,神经网络中所使用的激活函数 f(z) 全部都是 sigmoid 函数。
这样的声明是为了确保每一个神经元都对应一个逻辑回归模型,这个声明此时看不懂不要紧,后面会具体解释。
神经元和神经网络
直接学习神经网络不见得好懂,因此我们先看其中一个具体的圆圈(即神经元,也被称作感知机)是如何工作的:

对于上图这样的一个网络,用红色圆圈标记其中一个神经元,在其前面有三条连接线指向它,在它后面有两条连接线从该神经元发出:

这说明在这个神经元的前面一层中有3个神经元在向这个神经元发送数据,数据经过该神经元的计算,又发送给后面一层的两个神经元。
现在我们明白了这个神经元的前后连接关系,为了后续说明的简单,我们删掉前面的神经元,只保留这个神经元的3条输入线段,对于当前关注的这个红圈的神经元,会给后面的两个神经元发送数据,但只会计算一个结果,因此我们只保留一条连线表示数据从该神经元发送出去:

现在图像就很清楚明了了:

接下来就可以讨论该神经元是如何工作的了。
逻辑回归模型

一个神经元的工作方式就是逻辑回归模型的工作方式,这里不打算从头开始讲逻辑回归,如果只是单纯想看懂本节的内容,甚至不需要知道逻辑回归是干什么的,我们只需要知道逻辑回归是如何计算的就可以了。

前面说的3条连接线,对应了3条输入数据,也就是有3个输入特征,我们用 x1、x2、x3 来表示这3条数据,每一个逻辑回归都有一组参数w和b参数,这个参数就是大家常听到的大模型中的8B、70B的那种参数,只不过8B指的是w和b的总和是80亿,由于这里的逻辑回归只有x123,3个输入特征,因此该回归模型一共有3个w和1个b ,共4个参数。

神经元中的 b 被称为偏置参数,一般不画在模型中,但计算的时候要带上它,在表示神经元的圆圈中写出计算方法,也就是上图中的公式,在经过该公式的计算后得到 z,z 再经过激活函数 f() 后得到输出结果 a 。
这样就得到了逻辑回归模型的结构图。
在计算神经元的输出时,使用的是中学数学中直线方程的计算方法:

但是注意,这里的直线方程是空间中的直线方程,平面与空间中的直线方程差异如下:

对于空间中的直线方程我们可以使用 Σ 求和符号来表示:

因此我们举例的神经元可以计算如下:

最终将 z 输入到激活函数 f 中得到最后的输出 a 。
激活函数 f() :

这里的 f 选择的是 sigmoid 函数,函数图像如上图右侧,通过 sigmoid 函数我们可以将任意实数值映射到 0 和 1 之间:

之前声明说,将激活函数默认设置为是 sigmoid 函数,这样神经网络才是由逻辑回归组成的,这是因为如果抛开逻辑回归只考虑神经网络的神经元的话,那么激活函数可以有很多的选择:

当选择其它的函数作为激活函数时,网络中的神经元就不再是逻辑回归了,本节一直强调逻辑回归是为了让大家了解逻辑回归模型是学习神经网络的基础。
将逻辑回归组成神经网络
最后,我们将一个个的逻辑回归连接到一起就组成了神经网络:

神经网络具有层的概念,例如上图就是一个三层的神经网络,第一层是输入层、第二层是隐藏层、第三层是输出层:

但是对于输入层的神经元不能被看作是逻辑回归,因为它们只是用来接收外界输入的信号的,而隐藏层和输出层中的神经元都可以看作是一个个的逻辑回归模型。
因此上图一共使用了 7 个逻辑回归(隐藏层五个+输出层两个)组成了一个神经网络。
由于神经网络是从前往后计算的,也就是先计算前面层的逻辑回归然后再计算后面层的逻辑回归,因此神经网络的计算被称为是前向传播:

这种神经网络也被称为前馈神经网络。
逻辑回归详解
相信在上面小节中,对于什么是逻辑回归一定非常好奇,这一节就来详解一下逻辑回归。
逻辑回归是应用最为广泛的二分类模型,并且也是进一步学习神经网络等深度学习模型的基础。
本节我们从下面三个角度来详解逻辑回归:
1、什么是线性分类
2、逻辑回归的算法原理
3、PyTorch实现逻辑回归
什么是线性分类
来看下面这个例子:

在平面 x1-0-x2 中,分布着蓝色圆圈表示的正样本,红色叉叉表示的负样本,它们有两个特征 x1 和 x2 .
其中正样本的标签是 y = 1,负样本的标签是 y = 0,然后在平面上画出一条直线:x1 + x2 - 3 = 0
该直线交 x1 轴于点(3, 0) ,交 x2 轴于点(0, 3):

此时可以观察到正负两种样本刚好分布在直线的两侧。
对于任意的某个样本(x1, x2) ,如果将该样本向量带入表达式 x1 + x2 - 3,当计算结果大于等于 0 时那么该样本就是正例,否则就是负例:

这样我们就通过直线 x1 + x2 - 3 = 0,对样本进行了分类,这条直线就是这个分类问题的决策边界。
当使用一条直线来区分样本是正例还是负例,那么这就是线性分类问题。
而逻辑回归算法会训练出一个由直线表示的决策边界,因此逻辑回归是线性分类器。
逻辑回归的算法原理
逻辑回归的假设函数
任何机器学习模型都需要一个假设函数,我们通过假设函数来表示输入数据与输出结果之间的关系。
也就是将样本的特征向量 x ,输入到假设函数中 Hθ(x) 中,计算出模型的预测结果:

逻辑回归的假设函数如下所示:

下面我们就基于分类问题本身,来解释逻辑回归的假设函数 Hθ(x) 。
设平面上的样本正例的标记为 y=1,负例的标记 y=0,那么逻辑回归模型需要预测样本的标记值:预测未知的样本 x 是0还是1。
也就是将未知样本 x 输入到逻辑回归模型,然后模型预测该样本是0还是1。
实际上,我们希望模型的预测结果也就是 Hθ(x) 的输出是 0 到 1 中间的某个值,这样就可以将预测结果 h 看作是样本 x 属于某个类别的概率了。也就是当我们发现预测 h 接近 1 时,样本 x 就更可能是正例,h接近0时,样本 x 更可能是负例。

具体来说,在使用逻辑回归预测样本的类别时,会提前设置一个阈值 p 用来控制分类的界限:

比如阈值 p 设置为 0.5 的话,假设预测值Hθ(x) = 0.75,那么 0.75 >= 0.5 ,因此 x 为正例。
因此基于这样的考虑,为了使得 Hθ(x) 的输出是 0 到 1 区间中的某个值,我们引入 sigmoid 函数,设 sigmoid 函数为 g(z),那么其为下图右侧的公式:

观察 sigmoid 函数会发现,自变量 z 的范围是负无穷到正无穷,z 趋近于负无穷时函数值接近于0,z 趋近于正无穷时,函数值趋近于 1:

并且该函数在 z=0 的位置左右对称。
任意直线的表达式为:

我们将该表达式用 z 表示,并带入到 sigmoid 函数中:

此时就得到了自变量是 x1 到 xn,参数是 θ0 到 θn,值域是 0 到 1 的函数 Hθ(x) 。
该函数就是逻辑回归的假设函数,它由直线 z 和 sigmoid 函数两部分组成。
逻辑回归的代价函数
机器学习模型的代价函数衡量了模型在训练集上所犯的错误大小,因此需要准确的描述样本预测值与真实值之间的误差。
在逻辑回归中,使用交叉熵损失函数作为模型的代价函数:

我们要求出代价函数 J 取得最小值时,逻辑回归模型中的参数 θ0 到 θn 它们的具体值是多少。
下面我们具体来说明为什么逻辑回归的代价函数是交叉熵损失误差:
设下面的公式是某一个样本的代价:

J(θ) 为 m 个样本的平均代价:

在 cost 函数中,Hθ(x)表示样本属于某一个类别的预测概率,y表示样本的标签,cost函数描述了模型对于一个样本所犯错误的大小:

我们希望一个样本的代价 cost,有如下性质:



为了实现拥有这样性质的 cost 函数,我们引入 log 函数,我们将 -log(x) 和 -log(1-x) 两个函数画在坐标系中,这两个函数以 x = 0.5 左右对称,接着将自变量 x 的值限制在 0 到 1 之间:

观察函数图像可以发现,蓝色函数在 x 趋近于 0 时函数值趋近于正无穷,x=1时蓝色函数值为 0.
橙色函数则正好相反。
因此如果函数的自变量 x 就对应模型的预测值 h,那么蓝色函数就恰好可以代表样本为正例时代价 cost 随预测值 h 的变化。
橙色函数则可以表示样本为负例时,代价 cost 随预测值 h 的变化:

基于这样的考虑,就可以设计出如下的 cost 函数:

将上图中的两个函数合成一个,也就是用 Hθ(x)、y 和 log 函数同时表达一个样本的代价值 cost:

最后将 m 个样本的代价值相加到一起除以 m,就得到了逻辑回归的总代价函数 J(θ):

J(θ) 即为我们的交叉熵损失误差。
PyTorch实现逻辑回归
接下来我们使用深度学习框架来训练逻辑回归模型。
首先我们要清楚我们要构建的场景类似如下,也就是我们刚刚一直在说的例子:

因此我们可以写出如下代码:
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
import numpy
import torch# 实现逻辑回归的假设函数hθ(x) 的计算方法
# 计算逻辑回归模型的预测值hθ(x)
def hypothesis(theta0, theta1, theta2, x1, x2):z = theta0 + theta1 * x1 + theta2 * x2h = torch.sigmoid(z)return h.view(-1, 1)# 实现逻辑回归的代价函数J(θ)的计算方法
# 计算预测值h与真实值y的交叉熵损失函数
def J(h, y):return -torch.mean(y * torch.log(h) + (1 - y) * torch.log(1 - h))if __name__ == '__main__':# 使用mak_blobs函数,在平面上随机生成50个随机样本,包含两个类别x, y = make_blobs(n_samples=50, centers=2, random_state=0, cluster_std=0.5)# x1, x2分别保存样本的两个特征x1 = x[:, 0]x2 = x[:, 1]# 使用plt.scatter绘制正样本和负样本# 其中正样本使用蓝色圆圈表示,负样本使用红色叉叉表示plt.scatter(x1[y == 1], x2[y == 1], color='blue', marker='o')plt.scatter(x1[y == 0], x2[y == 0], color='red', marker='x')# 将两个特征x1、x2和标签y,转为张量形式x1 = torch.tensor(x1, dtype=torch.float32)x2 = torch.tensor(x2, dtype=torch.float32)y = torch.tensor(y, dtype=torch.float32).view(-1, 1)# 定义直线的3个参数,θ0、θ1、θ2θ0 = torch.tensor(0.0, requires_grad=True)θ1 = torch.tensor(0.0, requires_grad=True)θ2 = torch.tensor(0.0, requires_grad=True)# 定义Adam优化器optimizer,优化三个θ参数optimizer = torch.optim.Adam([θ0, θ1, θ2])for epoch in range(10000): # 进入逻辑回归模型的训练迭代# 计算模型的预测值h = hypothesis(θ0, θ1, θ2, x1, x2)# 调用函数J,计算预测值h与真实值y之间的损失lossloss = J(h, y)loss.backward() # 计算loss关于参数θ的梯度optimizer.step() # 更新模型参数optimizer.zero_grad() # 将梯度清零if epoch % 1000 == 0:# 每一千次迭代打印一次当前的损失,loss.item()是损失的标量值print(f'After {epoch} iterations, the loss is {loss.item():.3f}')# 完成训练后,再基于迭代出的参数,绘制出逻辑回归的蓝色决策边界w1 = θ1.item()w2 = θ2.item()b = θ0.item()x = numpy.linspace(-1, 6, 100)d = -(w1 * x + b) * 1.0 / w2plt.plot(x, d)plt.show()
代码运行输出如下:


可以看到分类效果是不错的。
相信经过上面这一连串的流程讲解,逻辑回归与神经网络应该已经很容易明白了。
补充:逻辑回归与线性回归的区别


相关文章:
逻辑回归与神经网络
从逻辑回归开始学习神经网络 神经网络直观上解释,就是由许多相互连接的圆圈组成的网络模型: 而逻辑回归可以看作是这个网络中的一个圆圈: 圆圈被称为神经元,整个网络被称为神经网络。 本节的任务是我们究竟如何理解具体的一个神…...

隨筆 20241024 Kafka 数据格式解析:批次头与数据体
Kafka作为分布式流处理平台,以其高吞吐量、可扩展性和强大的数据传输能力,成为了现代大数据和实时处理的核心组件之一。在Kafka中,数据的存储和传输遵循一种高效的结构化格式,主要由 批次头(Batch Header)和…...

【WiFi7】 支持wifi7的手机
数据来源 Smartphones with WiFi 7 - list of all latest phones 2024 Motorola Moto X50 Ultra 6.7" 1220x2712 Snapdragon 8s Gen 3 16GB RAM 1024 GB 4500 mAh a/b/g/n/ac/6e/7 Sony Xperia 1 VI 6.5" 1080x2340 Snapdragon 8 Gen 3 12GB RAM 512 G…...
LabVIEW偏振调制激光高精度测距系统
在航空航天、汽车制造、桥梁建筑等先进制造领域,许多大型零件的装配精度要求越来越高,传统的测距方法在面对大尺寸、高精度测量时,难以满足工业应用的要求。绝对测距技术在大尺度测量上往往会因受环境影响大、测距精度低而无法满足需求。基于…...

Python Pandas 数据分析的得力工具:简介
Python Pandas 数据分析的得力工具:简介 在如今的大数据与人工智能时代,数据的收集和处理能力变得至关重要。无论是在科学研究、商业分析还是人工智能领域,如何快速、高效地分析和处理数据都是不可忽视的课题。在众多的数据分析工具中&#…...

Llama 3.2-Vision 多模态大模型本地运行教程
Ollama 刚刚放出了对 Llama 3.2-Vision 的支持!这让人想起了新游戏发布带来的兴奋感——我期待着探索 Ollama 对 Llama 3.2-Vision 的支持。该模型不仅在自然语言理解方面表现出色,而且可以无缝处理图像,最好的部分是什么?它是免费…...

iOS 18.2 可让欧盟用户删除App Store、Safari、信息、相机和照片应用
升级到 iOS 18.2 之后,欧盟的 iPhone 用户可以完全删除一些核心应用程序,包括 App Store、Safari、信息、相机和 Photos 。苹果在 8 月份表示,计划对其在欧盟的数字市场法案合规性进行更多修改,其中一项更新包括欧盟用户删除系统应…...

照片怎么转换成pdf?盘点6种图片转pdf格式有效方法,直击要点!
照片怎么转换成pdf?在日常生活和工作中,我们难免会碰到需要将照片以pdf格式保存的情况,以便于更好的整理、分享或打印。虽然jpg格式的图片因其体积小而方便分享,但有时我们也希望将这些图片转换成pdf格式,以便于创建专…...

【Qt】Windows下Qt连接DM数据库
环境信息:W11 Qt5.12及以上 dm8 QODBC达梦 Windows环境创建ODBC数据源 使用 ODBC 方法访问 DM 数据库服务器之前,必须先配置 ODBC 数据源 在控制面板Windows工具中显示ODBC数据源管理器 ODBC数据源管理器标签 用户 DSN:添加、删除或配置本…...

2024 你还不会微前端吗 (上) — 从巨石应用到微应用
前言 微前端系列分为 上/下 两篇,本文为 上篇 主要还是了解微前端的由来、概念、作用等,以及基于已有的微前端框架进行实践,并了解微前端的核心功能所在,而在 下篇 中主要就是通过自定义实现一个微前端框架来加深理解。 微前端是…...
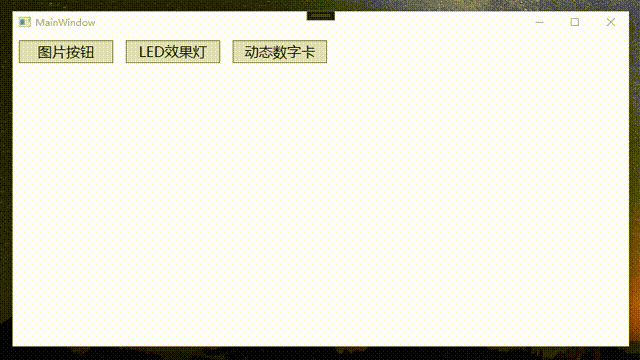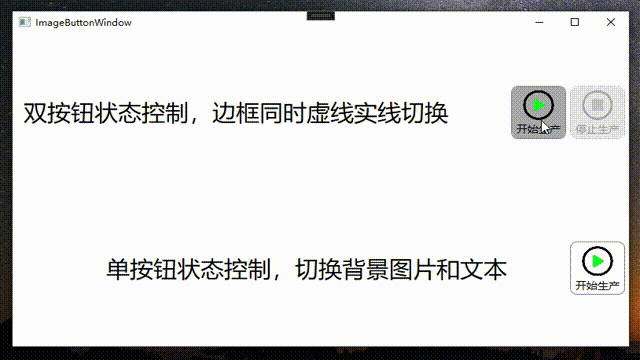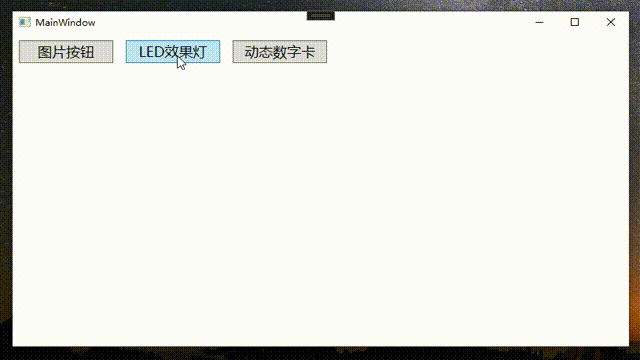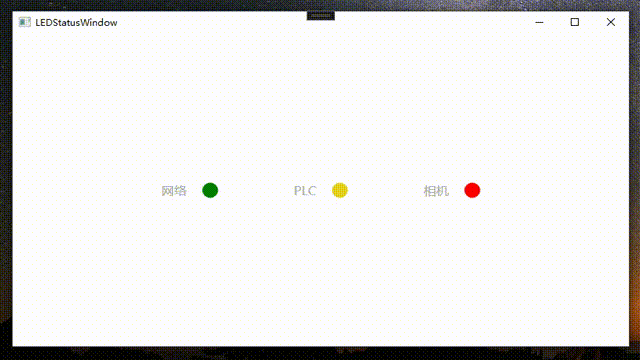
WPF+MVVM案例实战(三)- 动态数字卡片效果实现
1、创建项目 打开 VS2022 ,新建项目 Wpf_Examples,创建各层级文件夹,安装 CommunityToolkit.Mvvm 和 Microsoft.Extensions.DependencyInjectio NuGet包,完成MVVM框架搭建。搭建完成后项目层次如下图所示: 这里如何实现 MVVM 框…...

#网络安全#渗透测试# 渗透测试应用
网络安全渗透测试是一种重要的安全评估方法,用于发现和评估网络系统中的安全漏洞。在进行渗透测试时,需要注意以下几个关键点: 法律和道德考量 获得授权:在进行渗透测试之前,必须获得目标系统的正式授权。未经授权的测…...
MicroServer Gen8再玩 OCP万兆光口+IT直通之二
这个接上一篇,来个简单测试。 一、测试环境 PC端:Win10,网卡:万兆光纤(做都做了,都给接上),硬盘使用N年的三星SSD 840 交换机:磊科GS10,带两个万兆口 Gen…...

【JAVA面试题】Java和C++主要区别有哪些?各有哪些优缺点?
文章目录 强烈推荐前言区别:1. 语法和编程风格2.内存管理3.平台独立性4.性能5.指针和引用6.多线程7.使用场景 Java 的优缺点优点:缺点: C 的优缺点优点:缺点: 总结专栏集锦 强烈推荐 前些天发现了一个巨牛的人工智能学…...
保姆级教程!!教你通过【Pycharm远程】连接服务器运行项目代码
小罗碎碎念 这篇文章主要解决一个问题——我有服务器,但是不知道怎么拿来写代码,跑深度学习项目。确实,玩深度学习的成本比较高,无论是前期的学习成本,还是你需要具备的硬件成本,都是拦路虎。小罗没有办法…...

JMeter详细介绍和相关概念
JMeter是一款开源的、强大的、用于进行性能测试和功能测试的Java应用程序。 本篇承接上一篇 JMeter快速入门示例 , 对该篇中出现的相关概念进行详细介绍。 JMeter测试计划 测试计划名称和注释:整个测试脚本保存的名称,以及对该测试计划的注…...
如何使用Git
简介 一.git简介 Git是一个分布式版本控制工具,通常用来对软件开发过程中的源代码文件进行管理.通过Git仓库来存储和管理这些文件,Git仓库分两种: 本地仓库:开发人员自己电脑上的Git仓库远程仓库:远程服务器上的Git仓库 commit:提交,将本地文件和版本信息保存到本地仓库 p…...

Redis 哨兵 问题
前言 相关系列 《Redis & 目录》(持续更新)《Redis & 哨兵 & 源码》(学习过程/多有漏误/仅作参考/不再更新)《Redis & 哨兵 & 总结》(学习总结/最新最准/持续更新)《Redis & 哨兵…...

安卓基础001
前言 也是好久没有更新博客了,最近实习也是需要学习一些知识哈哈哈哈哈哈为了更好的发展嘛,咱们从客户端开始,过程可能有点像写前端,不喜勿喷,希望在学习的过程中也可以给大家带来一些简单得帮助吧....... tips:这里跳过安卓studio安装,大家可自行寻找教程 写的不详细,只是为了…...

shodan2:绕过shodan高级会员限制+metasploit批量验证漏洞
shodan2 shodanmetasploit批量验证漏洞 shodan的这个指令语法是特别多的,那么我不可能说一个个全部讲完,因为有的参数可能你一辈子都用不上,主要就是把一些红队最常用的参数给你讲完,今天我们看看怎么去查一个cve-2019-0708的一…...

丹青识画系统助力PS软件插件开发:智能图像分析功能扩展
丹青识画系统助力PS软件插件开发:智能图像分析功能扩展 作为一名和设计工具打了十几年交道的“老炮儿”,我见过太多设计师朋友在创意构思和细节调整时陷入纠结。一张图,色彩搭配是否和谐?构图有没有更好的可能?很多时…...

突破Windows远程桌面限制:RDP Wrapper多用户并发实战指南
突破Windows远程桌面限制:RDP Wrapper多用户并发实战指南 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 在远程办公与协作日益普及的今天,Windows远程桌面功能成为连接不同设备的重要桥梁。…...

Youtu-VL-4B-Instruct商业应用:法律合同截图OCR+关键条款摘要生成提效方案
Youtu-VL-4B-Instruct商业应用:法律合同截图OCR关键条款摘要生成提效方案 1. 引言:当法律遇上AI,合同审核的痛点与转机 想象一下这个场景:法务同事或律师助理的电脑桌面上,堆满了来自邮件、聊天记录、扫描件的各种合…...
)
普冉PY32F071内存紧张?FreeRTOS配置优化全攻略(含heap_4选择与任务栈设置)
普冉PY32F071内存紧张?FreeRTOS配置优化全攻略(含heap_4选择与任务栈设置) 当你在PY32F071这颗Cortex-M0芯片上运行FreeRTOS时,是否遇到过任务莫名崩溃、系统运行不稳定的情况?作为一款仅有20KB RAM的微控制器…...

低成本工业机器人:开源六轴机械臂从技术原理到生态落地全指南
低成本工业机器人:开源六轴机械臂从技术原理到生态落地全指南 【免费下载链接】Faze4-Robotic-arm All files for 6 axis robot arm with cycloidal gearboxes . 项目地址: https://gitcode.com/gh_mirrors/fa/Faze4-Robotic-arm 技术原理:打破工…...

新手别慌!手把手教你用嘉立创EDA专业版搞定蓝桥杯平衡车PCB布局布线
从零到精通:嘉立创EDA专业版实战蓝桥杯平衡车PCB设计全攻略 第一次接触蓝桥杯电子设计竞赛的平衡车项目时,面对密密麻麻的元器件和错综复杂的布线要求,很多同学都会感到无从下手。本文将带你一步步攻克这个看似复杂的PCB设计任务,…...

Phi-3 Forest Laboratory 入门到精通:GitHub开源项目协作全流程指南
Phi-3 Forest Laboratory 入门到精通:GitHub开源项目协作全流程指南 你是不是也遇到过这种情况:自己写的代码跑得好好的,一跟别人合作就乱套了。版本冲突、代码覆盖、提交信息写得像天书……明明是个简单的功能开发,最后花在沟通…...

Squeezer安全最佳实践:保护区块链dApp的10个关键点
Squeezer安全最佳实践:保护区块链dApp的10个关键点 【免费下载链接】squeezer Squeezer Framework - Build serverless dApps 项目地址: https://gitcode.com/gh_mirrors/sq/squeezer Squeezer Framework作为构建无服务器区块链去中心化应用(dApp…...

【无线通信】基于统计信道的低复杂度旋转和位置优化为6D可移动天线无线通信附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...

人工智能|大模型 —— 量化 —— 一文搞懂大模型量化技术:GGUF、GPTQ、AWQ
目前关于大模型量化技术的文章层出不穷,但对其理论部分的深入探讨却相对较少。本文将对大模型量化技术进行系统性的介绍,并重点聚焦于理论层面的深入解析。 一、大模型量化基础 大模型量化的核心在于将模型参数的精度从较高的位宽(bit-width…...