【p2p、分布式,区块链笔记 分布式容错算法】: 拜占庭将军问题+实用拜占庭容错算法PBFT
| paper | code |
|---|---|
| https://pmg.csail.mit.edu/papers/osdi99.pdf | https://github.com/luckydonald/pbft |
- 其他相关实现:
- This is an implementation of the Pracltical Byzantine Fault Tolerance protocol using Python
- An implementation of the PBFT consensus algorithm using rust-libp2p as the networking layer.
- Network simulation for PBFT (Practical Byzantine Fault Tolerance) consensus algorithm in Python
- go Sample implementation of PBFT consensus algorithm
- https://github.com/vonwenm/pbft/blob/master/bft-simple/Makefile
PBFT相关简述
1. 拜占庭将军问题
- 拜占庭将军问题描述了一组将军(或节点)需要协同完成任务,但其中一部分将军可能会背叛或发出错误信息。问题是如何确保即使有一些将军是不可靠的,剩下的将军仍然能够达成一致并完成任务。
2. 拜占庭容错的核心目标
-
拜占庭容错的核心目标是确保系统即使在部分节点故障或恶意行为的情况下,也能继续正确地运作。这包括:
-
一致性:所有正常节点对系统状态达成一致。
-
可用性:系统能够在节点故障的情况下继续运行。
-
容错性:系统能够容忍一定数量的故障或恶意节点,而不会影响整体功能。
拜占庭容错和非拜占庭容错
-
拜占庭容错(Byzantine Fault Tolerance, BFT)和非拜占庭容错(Non-Byzantine Fault Tolerance)是两种不同的容错机制,用于确保系统在存在错误或故障的情况下仍然能够正常运行。
-
拜占庭容错的核心思想是
应对系统中存在的不确定性和不诚实节点,尤其是面对可能的恶意攻击和节点故障。这个概念来源于拜占庭将军问题(Byzantine Generals Problem),这个问题描述了在一个系统中,如何确保即使存在部分节点故障或恶意节点,系统仍能达成一致意见并保持正常运行。BFT能够处理和容忍节点的恶意行为,包括虚假信息、拒绝服务等。常见的BFT算法如Practical Byzantine Fault Tolerance (PBFT)、Delegated Byzantine Fault Tolerance (DBFT)等,能够在存在恶意节点的情况下达成一致。 实现BFT机制的系统通常需要更多的通信开销和计算资源,因为算法要处理复杂的协议以确保一致性。 -
拜占庭容错关注的是在节点故障、网络问题等正常的故障情况下保证系统的正确性和一致性,但不处理恶意行为。
容忍的是普通的故障,如崩溃、掉线等,而不是恶意行为。(更偏向封闭系统内部)。常见的非拜占庭容错算法如Paxos、Raft,这些算法假设所有的节点都遵循协议,没有恶意行为。 相对于BFT,非拜占庭容错的算法通常更简单,性能开销较低,因为不需要考虑恶意节点的情况。
3. BFT算法的基本要求
- 拜占庭容错算法通常要求系统中正常节点的数量至少是故障节点数量的三倍加一。也就是说,如果系统中有
n个节点,最多可以容忍f个故障节点,且f满足f < (n - 1) / 3。例如,在一个总共有 7 个节点的系统中,最多可以容忍 2 个故障节点。
4. BFT算法的实现:Practical Byzantine Fault Tolerance (PBFT)
- PBFT 由 Castro 和 Liskov 于1999年提出,广泛用于分布式系统。PBFT将原始的。PBFT 算法通过三阶段的协议(预备阶段、准备阶段和提交阶段)来确保系统的一致性。
- 如图所示算法分为5个部分
- 某个节点收到了 2 3 \frac{2}{3} 32以上的相同消息码,就认为网络达成了共识,可以进行下一步了。所以定义 f 表示最多可能的恶意节点的个数
request
- client向“主节点”发起服务调用请求
pre-request
- “主节点”将请求广播给其他“副本节点”
prepare
- “副本节点”间互相广播
- 收集满2f*1个prepare签名包,广播Commit包确认
commit
- 收集满2f*1个Commit包,区块落盘,回复给客户端
reply
- 返回响应本次请求的结果
注意:
- 以上的过程中没有考虑,主节点为恶意节点的状况。
视图切换协议确保了当主节点出现问题时及时替换。发现主节点有问题的节点会广播给所有其他节点。所有节点在收到请求后,会验证其合法性并准备进入新的视图。在接收到足够多的视图切换请求后(通常是超过三分之二的节点同意),节点会开始正式切换到新视图。每个节点会更新其视图编号,并通知其他节点它已进入新视图。在新视图中,新的领导者会被选出(通常是根据视图编号来轮流选择领导者),然后系统继续在新的视图下进行正常操作。
代码实现
client.py
- client.py的作用是设置并初始化用于节点和客户端之间通信的基础设施,以及定义一个客户端类
- 客户端的通信是同步的:在最后一个请求得到答复之前,它无法发送请求。

main.py
from PBFT import *
from client import *import threading
import time# 1.Parameters to be defined by the userwaiting_time_before_resending_request = 200 # 客户端在重新发送请求前等待的时间。如果没有收到响应,它会广播请求到所有节点
timer_limit_before_view_change = 200 # 视图切换的时限,论文中没有提到这个值,所以设为200秒
checkpoint_frequency = 100 # 检查点创建频率,根据原始文章的建议设为100# 2.Define the nodes we want in our network + their starting time + their type
nodes={} # 这是我们在网络中想要的节点的字典。键是节点类型,值是一个包含启动时间和节点数量的元组列表
#nodes[starting time] = [(type of nodes , number of nodes)]
nodes[0]=[("faulty_primary",0),("slow_nodes",0),("honest_node",4),("non_responding_node",0),("faulty_node",0),("faulty_replies_node",0)] # Nodes starting from the beginning
#nodes[1]=[("faulty_primary",0),("honest_node",1),("non_responding_node",0),("slow_nodes",1),("faulty_node",1),("faulty_replies_node",0)] # Nodes starting after 2 seconds
#nodes[2]=[("faulty_primary",0),("honest_node",0),("non_responding_node",0),("slow_nodes",2),("faulty_node",1),("faulty_replies_node",0)]# Running PBFT protocol
run_APBFT(nodes=nodes,proportion=1,checkpoint_frequency0=checkpoint_frequency,clients_ports0=clients_ports,timer_limit_before_view_change0=timer_limit_before_view_change)time.sleep(1) # Waiting for the network to start...# Run clients:
requests_number = 1 # The user chooses the number of requests he wants to execute simultaneously (They are all sent to the PBFT network at the same time) - Here each request will be sent by a different client
clients_list = []
for i in range (requests_number):globals()["C%s" % str(i)]=Client(i,waiting_time_before_resending_request)clients_list.append(globals()["C%s" % str(i)])
for i in range (requests_number):threading.Thread(target=clients_list[i].send_to_primary,args=("I am the client "+str(i),get_primary_id(),get_nodes_ids_list(),get_f())).start()time.sleep(0) #Exécution plus rapide lorsqu'on attend un moment avant de lancer la requête suivante
PBFT.py
run_APBFT函数
def run_APBFT(nodes, proportion, checkpoint_frequency0, clients_ports0, timer_limit_before_view_change0): # 定义一个函数 run_APBFT,它接受以下参数:# - nodes: 所有节点的列表 详见main.py# - proportion: 节点的比例,本次运行值为1# - checkpoint_frequency0: 检查点的频率# - clients_ports0: 客户端端口列表 由clinet.py确定,本次运行值为[30000, 30001, 30002, 30003, 30004, 30005, 30006, 30007, 30008, 30009, 30010, 30011, 30012, 30013, 30014, 30015, 30016, 30017, 30018, 30019, 30020, 30021, 30022, 30023, 30024, 30025, 30026, 30027, 30028, 30029, 30030, 30031, 30032, 30033, 30034, 30035, 30036, 30037, 30038, 30039, 30040, 30041, 30042, 30043, 30044, 30045, 30046, 30047, 30048, 30049, 30050, 30051, 30052, 30053, 30054, 30055, 30056, 30057, 30058, ...]# - timer_limit_before_view_change0: 视图更改之前的定时器限制,本次运行值为200# 设置全局变量 p 为传入的比例值global pp = proportionglobal number_of_messagesnumber_of_messages = {} # 初始化一个空字典,用于存储每个请求从 preprepare 到 reply 之间的消息数量# 格式: number_of_messages={"request":number_of_exchanged_messages, ...}global replied_requestsreplied_requests = {} # 初始化一个空字典,用于记录请求是否已回复# 比如在reply_received函数中 request='I am the client 0',replied_requests[request] = 1global timer_limit_before_view_changetimer_limit_before_view_change = timer_limit_before_view_change0# 设置全局变量 timer_limit_before_view_change 为传入的值global clients_portsclients_ports = clients_ports0# 设置全局变量 clients_ports 为传入的客户端端口列表global accepted_repliesaccepted_replies = {} # 初始化一个空字典,用于存储每个请求的客户机接受的回复# 格式: accepted_replies={"request":reply}global nn = 0 # 初始化节点总数 n 为 0,每次实例化一个节点时都会递增global ff = (n - 1) // 3 # 计算允许的故障节点数量 f# f 应随着节点总数 n 的变化而更新global the_nodes_ids_listthe_nodes_ids_list = [i for i in range(n)]# 初始化节点 ID 列表 the_nodes_ids_list,范围从 0 到 n-1global j j = 0# 初始化下一个节点 ID j 为 0,每次实例化一个新节点时都会递增global requests requests = {} # 初始化一个空字典,用于存储每个客户端 ID 及其最后请求的时间戳# 格式: requests={"client_id":timestamp}global checkpoint_frequencycheckpoint_frequency = checkpoint_frequency0# 设置全局变量 checkpoint_frequency 为传入的检查点频率值global sequence_numbersequence_number = 1 # 初始化序列号 sequence_number 为 1,每当有新请求时递增# 选择 1 以便在开始时有一个稳定的检查点,必要时可以用于视图更改global nodes_listnodes_list = []# 初始化一个空列表,用于存储所有节点的列表global total_processed_messagestotal_processed_messages = 0 # 初始化已处理的消息总数 total_processed_messages 为 0# 这是在处理请求时通过网络发送的消息总数# 节点评估指标:global processed_messages processed_messages = [] # 初始化一个空列表,用于记录每个节点处理的消息数量global messages_processing_ratemessages_processing_rate = [] # 初始化一个空列表,用于记录所有节点的消息处理率# 计算为节点发送的消息与所有节点通过网络发送的消息的比例###################global consensus_nodes consensus_nodes = []# 初始化一个空列表,用于存储参与共识的节点 ID# 启动一个新的线程来运行节点threading.Thread(target=run_nodes, args=(nodes,)).start()# 创建并启动一个新线程,执行 run_nodes 函数,传入所有节点列表作为参数
run_nodes函数
def run_nodes(nodes):# 声明全局变量,以便在函数中修改它们global jglobal nglobal f# 初始化总节点数total_initial_nodes = 0# 计算初始节点总数for node_type in nodes[0]:total_initial_nodes += node_type[1]# 用于记录上一个等待时间的变量last_waiting_time = 0# 遍历节点的等待时间for waiting_time in nodes:# 遍历当前等待时间下的节点类型和数量for tuple in nodes[waiting_time]:# 根据数量循环创建节点for i in range(tuple[1]):# 等待指定的时间(根据当前和上一个等待时间的差值)time.sleep(waiting_time - last_waiting_time)last_waiting_time = waiting_time# 获取节点类型node_type = tuple[0]# 根据节点类型创建相应的节点对象if node_type == "honest_node":node = HonestNode(node_id=j)elif node_type == "non_responding_node":node = NonRespondingNode(node_id=j)elif node_type == "faulty_primary":node = FaultyPrimary(node_id=j)elif node_type == "slow_nodes":node = SlowNode(node_id=j)elif node_type == "faulty_node":node = FaultyNode(node_id=j)elif node_type == "faulty_replies_node":node = FaultyRepliesNode(node_id=j)# 启动一个新线程来处理节点的接收逻辑threading.Thread(target=node.receive, args=()).start()# 将节点添加到节点列表中nodes_list.append(node)the_nodes_ids_list.append(j)# 初始化处理消息的计数器和处理率processed_messages.append(0)messages_processing_rate.append(0) # 初始化为0# 将节点ID添加到共识节点列表中consensus_nodes.append(j)# 更新节点数量和容错数n += 1f = (n - 1) // 3# 更新节点ID计数器j += 1# print(consensus_nodes)
节点和相关衍生类型

CG
- https://fisco-bcos-documentation.readthedocs.io/zh-cn/latest/docs/design/consensus/pbft.html
- pBFT 的优缺点
- Tendermint算法、Algorand、DAG、PoW 、PoS和DPoS算法
- https://github.com/shawnxiaoxiong/pbft-zh_ch/blob/master/pbft_zh-cn.md
相关文章:
【p2p、分布式,区块链笔记 分布式容错算法】: 拜占庭将军问题+实用拜占庭容错算法PBFT
papercodehttps://pmg.csail.mit.edu/papers/osdi99.pdfhttps://github.com/luckydonald/pbft 其他相关实现:This is an implementation of the Pracltical Byzantine Fault Tolerance protocol using PythonAn implementation of the PBFT consensus algorithm us…...
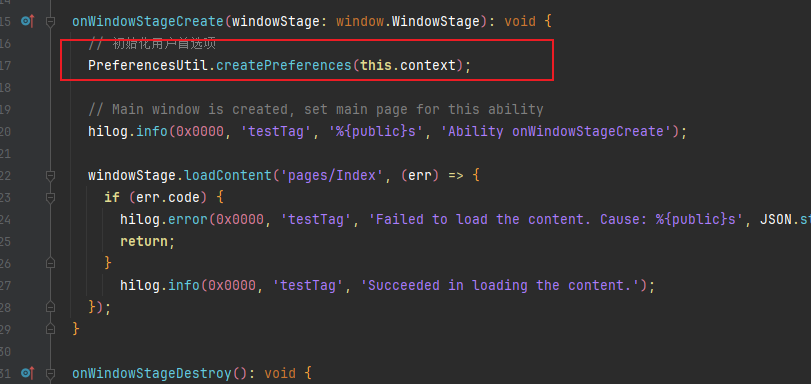
鸿蒙NEXT开发-应用数据持久化之用户首选项(基于最新api12稳定版)
注意:博主有个鸿蒙专栏,里面从上到下有关于鸿蒙next的教学文档,大家感兴趣可以学习下 如果大家觉得博主文章写的好的话,可以点下关注,博主会一直更新鸿蒙next相关知识 专栏地址: https://blog.csdn.net/qq_56760790/…...

人工智能_神经网络103_感知机_感知机工作原理_感知机具备学习能力_在学习过程中自我调整权重_优化效果_多元线性回归_逻辑回归---人工智能工作笔记0228
由于之前一直对神经网络不是特别清楚,尤其是对神经网络中的一些具体的概念,包括循环,神经网络卷积神经网络以及他们具体的作用,都是应用于什么方向不是特别清楚,所以现在我们来做教程来具体明确一下。 当然在机器学习之后还有深度学习,然后在深度学习中对各种神经网络的…...

WISE:重新思考大语言模型的终身模型编辑与知识记忆机制
论文地址:https://arxiv.org/abs/2405.14768https://arxiv.org/abs/2405.14768 1. 概述 随着世界知识的不断变化,大语言模型(LLMs)需要及时更新,纠正其生成的虚假信息或错误响应。这种持续的知识更新被称为终身模型编…...

网络安全证书介绍
网络安全领域有很多专业的证书,可以帮助你提升知识和技能,增强在这个行业中的竞争力。以下是一些常见的网络安全证书: 1. CompTIA Security 适合人群:初级安全专业人员证书内容:基础的网络安全概念和实践,…...

【已解决】【hadoop】【hive】启动不成功 报错 无法与MySQL服务器建立连接 Hive连接到MetaStore失败 无法进入交互式执行环境
启动hive显示什么才是成功 当你成功启动Hive时,通常会看到一系列的日志信息输出到控制台,这些信息包括了Hive服务初始化的过程以及它与Metastore服务连接的情况等。一旦Hive完成启动并准备就绪,你将看到提示符(如 hive> &#…...

基于架设一台NFS服务器实操作业
架设一台NFS服务器,并按照以下要求配置 首先需要关闭防火墙和SELinux 1、开放/nfs/shared目录,供所有用户查询资料 赋予所有用户只读的权限,sync将数据同步写到磁盘上 在客户端需要创建挂载点,把服务端共享的文件系统挂载到所创建…...

eachers中的树形图在点击其中某个子节点时关闭其他同级子节点
答案在代码末尾!!!!! tubiaoinit(params: any) {// 手动触发变化检测this.changeDetectorRef.detectChanges();if (this.myChart ! undefined) {this.myChart.dispose();}this.myChart echarts.init(this.pieChart?…...

Maven 介绍与核心概念解析
目录 1. pom文件解析 2. Maven坐标 3. Maven依赖范围 4. Maven 依赖传递与冲突解决 Maven,作为一个广泛应用于 Java 平台的自动化构建和依赖管理工具,其强大功能和易用性使得它在开发社区中备受青睐。本文将详细解析 Maven 的几个核心概念&a…...
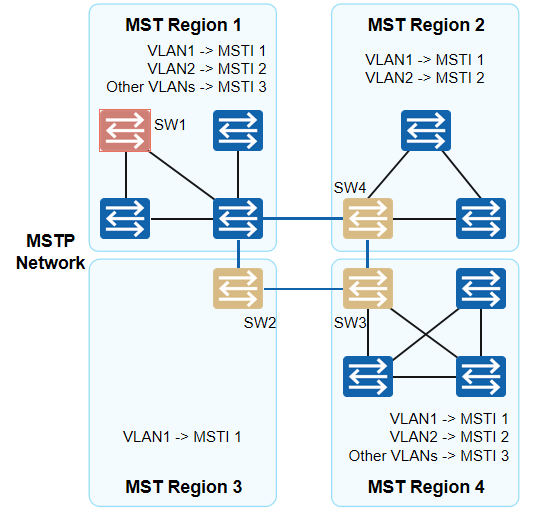
计算机网络-MSTP概述
一、RSTP/STP的缺陷与不足 前面我们学习了RSTP对于STP的一些优化与快速收敛机制。但在划分VLAN的网络中运行RSTP/STP,局域网内所有的VLAN共享一棵生成树,被阻塞后的链路将不承载任何流量,无法在VLAN间实现数据流量的负载均衡,导致…...

Redisson(三)应用场景及demo
一、基本的存储与查询 分布式环境下,为了方便多个进程之间的数据共享,可以使用RedissonClient的分布式集合类型,如List、Set、SortedSet等。 1、demo <parent><groupId>org.springframework.boot</groupId><artifact…...
1)
考研要求掌握的C语言程度(堆排序)1
含义 堆排序就是把数组的内容在心中建立为大根堆,然后每次循环把根顶和没交换过的根末进行调换,再次建立大根堆的过程 建树的几个公式 一个数组有n个元素 最后一个父亲节点是n/2-1; 假如父亲节点在数组的下标为a 那么左孩子节点在数组下标为2*a1,…...

chronyd配置了local的NTP server之后, NTP报文中出现public IP的问题
描述 客户在Rocky Linux 9.4的VM上配了一个local的NTP server(IP: 10.64.1.76)。 配置完成后, 时钟可以同步,但一段时间后客户的firewall收到告警, 拒绝了大量目标端口为123的请求, 且这些请求的目的IP并不是客户指定的NTP server的IP,客户要求解释原因…...

docker常用命令整理
文章目录 docker 常用操作命令一、镜像类操作1.构建镜像2.从容器创建镜像3.查看镜像列表4.删除镜像5. 从远程镜像仓库拉取镜像6. 将镜像推送到镜像仓库中7. 将镜像导出8. 导入镜像9. 登录镜像仓库 二、容器相关操作1. 运行容器2. 进入容器3. 查看容器的运行状态4. 查看容器的日…...

将CSDN博客转换为PDF的Python Web应用开发--Flask实战
文章目录 项目概述技术栈介绍 项目目录应用结构 功能实现单页博客转换示例: 专栏合集博客转换示例: PDF效果: 代码依赖文件requirements.txt:app.py:代码解释: /api/onepage.py:代码解释: /api/zhuanlan.py…...
AIGC学习笔记(3)——AI大模型开发工程师
文章目录 AI大模型开发工程师002 GPT大模型开发基础1 OpenAI账户注册2 OpenAI官网介绍3 OpenAI GPT费用计算4 OpenAI Key获取与配置5 OpenAI 大模型总览6 代码演示安装依赖导入依赖初始化客户端执行代码遇到的问题 AI大模型开发工程师 002 GPT大模型开发基础 1 OpenAI账户注册…...

Windows server 2003服务器的安装
Windows server 2003服务器的安装 安装前的准备: 1.镜像SN序列号 图1-1 Windows server 2003的安装包非常人性化 2.指定一个安装位置 图1-2 选择好安装位置 3.启动虚拟机打开安装向导 图1-3 打开VMware17安装向导 图1-4 给虚拟光驱插入光盘镜像 图1-5 输入SN并…...

HTML作业
作业 复现下面的图片 复现结果 代码 <!DOCTYPE html> <html><head><meta charset"utf-8"><title></title></head><body><form action"#"method"get"enctype"text/plain"><…...

MYSQL-SQL-04-DCL(Data Control Language,数据控制语言)
DCL(数据控制语言) DCL英文全称是Data Control Language(数据控制语言),用来管理数据库用户、控制数据库的访问权限。 一、管理用户 1、查询用户 在MySQL数据库管理系统中,mysql 是一个特殊的系统数据库名称,它并不…...

多线程进阶——线程池的实现
什么是池化技术 池化技术是一种资源管理策略,它通过重复利用已存在的资源来减少资源的消耗,从而提高系统的性能和效率。在计算机编程中,池化技术通常用于管理线程、连接、数据库连接等资源。 我们会将可能使用的资源预先创建好,…...

利用示波器直方图功能低成本测量信号抖动的方法与实践
1. 项目概述:用直方图低成本测量抖动在嵌入式系统、高速数字接口乃至电机控制的设计与调试中,信号抖动(Jitter)的测量和分析是一个绕不开的坎。无论是为了确保通信链路的误码率,还是为了验证时钟信号的纯净度ÿ…...

OpenClaw狂欢暗藏安全隐患,深圳机密计算科技端云一体方案筑牢AI Agent安全基座
AI Agent时代,安全信任的崩塌2026年初,OpenClaw横空出世,仅用60天打破React保持十年的GitHub Star纪录,成为当年热度最高的现象级开源项目。2026年3月,在英伟达GTC全球开发者大会上,黄仁勋直言称“OpenClaw…...

STM32+原理图+PCB程序直流充电桩主控方案源
💥💥💞💞欢迎来到本博客❤️❤️💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭:行百…...

量子计算采购策略与技术路线比较
1. 量子计算采购的现状与挑战 量子计算技术正在经历从实验室研究向实际应用过渡的关键阶段。根据2023年全球量子计算产业报告,量子处理器市场规模预计将从2023年的4.7亿美元增长到2030年的65亿美元,年复合增长率高达45%。然而,面对超导、离子…...

一分钟看懂大模型备案
大模型备案,全称 “生成式人工智能服务上线备案”,是国内面向公众提供大模型服务的法定合规流程,核心是审核模型安全、数据合规与内容可控,未备案违规上线最高罚一千万元,该处罚依据主要来自两大核心法规:1…...

3步精通UE4SS游戏Mod开发:从注入到实战完全指南
3步精通UE4SS游戏Mod开发:从注入到实战完全指南 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS UE…...

终极免费文档下载指南:如何用kill-doc脚本轻松获取百度文库、豆丁网等30+平台资源
终极免费文档下载指南:如何用kill-doc脚本轻松获取百度文库、豆丁网等30平台资源 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档&a…...
)
别再乱打包了!手把手教你用Kali Linux和Metasploit生成免杀后门(附实战演示)
Kali Linux高级免杀技术实战:从原理到绕过Windows Defender 在渗透测试和红队演练中,后门程序的免杀能力直接决定了行动的成败。许多初学者在使用Metasploit生成基础payload后,常常发现它们被主流杀毒软件轻易拦截。本文将深入探讨免杀技术的…...

VR大空间项目屡获行业大奖,AI数字人公司赋能文旅智慧升级
在经历了早期的概念普及和单点试验后,AI数字人、VR、MR等技术正在文旅行业完成从“尝鲜”到“刚需”的蜕变。不再仅仅是博物馆或景区里的一块互动屏幕,而是一套能够重塑服务流程、活化文化IP、创造全新消费场景的完整解决方案。从边疆秘境到城市地标&…...

千万级用户购物车系统的架构设计
我们当时搞的购物车服务,其实还是有点庞大的,看似是一个简单的CRUD,但是当你真正去实现一个购物车的时候,发现压根不是那回事。 当商品类型从单一SKU扩展到普通商品、套餐组合、活动商品,拼单等混合的时候,…...