从可逆计算看低代码
2020年低代码(LowCode)这一buzzword频繁亮相于主流技术媒体,大背景下是微软/亚马逊/阿里/华为等巨头纷纷入场,推出自己的相应产品。一时之间,大大小小的技术山头,无论自己原先是搞OA/ERP/IOT/AI的,但凡认为自己有点技术的厂商,不说改旗易帜,至少也要加绣一条LowCode的花边,表示不落人后。
根据Gartner的2019年的LowCode报告,LowCode未来的钱景可谓是一片光明:
到2024年,四分之三的大型企业将使用至少四种低代码开发工具进行IT应用程序开发和公民开发(citizen development,可以认为是非IT背景的用户进行开发,例如:业务用户/产品经理/业务顾问等)。 到2024年,低代码应用程序开发将承担65%以上的应用程序开发活动。
向LowCode转型意味着软件将进入工业化生产阶段。但自从上世纪七十年代以来,这种转向尝试早已不是什么新鲜事情,这一轮的LowCode运动又有什么特殊之处?它凭什么能完成前辈未竟之事业?本文试图从可逆计算理论的角度针对LowCode中的一些技术问题谈谈自己的看法。
关于可逆计算理论的介绍,可以参见可逆计算:下一代软件构造理论
一. LowCode的本质是什么?
LowCode,顾名思义就是 Code Low,在软件产品的构建过程中大幅降低所谓代码编程活动所占的比例。显然,LowCode这一说法仅仅是一种愿望表达,即我们希望大幅降低代码编程量,这意味着更少的工作、更快的交付、更稳的系统,然后从老板的角度,它带来更低的成本、更高的利润和更广的市场等。作为一种朴素而美好的愿望,LowCode的本质与FastCode/CleanCode一样,那就是它没有什么本质,或者说它的本质就是对理想中的一种现象的描述。当所有其他指标都相同的情况下,FastCode肯定比SlowCode强,同样的,在提供同样功能特性的前提下,LowCode肯定比HighCode更让人青睐。
相比于Case工具、模型驱动、产生式编程等等看似高大上,但实际不知所云的专业概念,LowCode无疑是更具体的、更亲民的,特别是结合可视化拖拉拽取代程序员、全流程免运维等这些商业上鼓吹的具有立竿见影的经济效益的卖点,更容易打动圈外的人。
实际上LowCode更像是一面旗帜,所有能够减少Code的实践和理念都可以归于其麾下,而且我们几乎可以肯定的说,LowCode一定是走在正确的技术发展道路上。你能想象500年后人们还像今天一样人肉码代码吗?如果那时候人类还没有灭绝,大概也不会再需要现在这种程序员去写什么业务代码了吧。坚信Code不会被LowCode取代的人明显是缺乏未来视角。在走向智能社会的过程中,我们一定会经历一个智力工作逐步向机器转移,Code逐步减少的过程,那LowCode岂不就是通向未来之路吗?
LowCode具体的技术内涵与外延目前并没有确定下来,现有LowCode产品厂商的具体做法也很难被定性为最佳实践,甚至可以说按照现有的方案实际上是很难兑现其商业宣传中的各种神奇疗效的。如果LowCode真的能深刻的改变技术和商业领域,那还需要我们做出更多革命性的探索才行。
二. LowCode一定需要可视化设计吗?
LowCode减少编码工作无外乎有两种方式:
-
实质性的减少针对特定业务所需要编写的代码量
-
将传统上需要编码的工作转化为非编码的活动
可视化设计在LowCode中的作用就对应于第二种方式。相比于编程,它有两个优点:
-
可视化交互更加直观具体,所需编程知识更少
-
可视化交互约束性更强,更不容易出错
可视化设计无疑是目前LowCode平台厂商的核心卖点之一。但如果第一种抽象方式做得足够简单,我们并不一定需要可视化设计器。买不起豪华设计的穷人一样可以LowCode。很多时候我们只需要针对业务领域制定一个专用的领域语言就可以在很大程度上解决问题。例如目前所有创作类网站广泛使用的MarkDown语法,相比于复杂的文字排版软件其功能无疑弱到了极点,但关键是它在大多数日常场景下够用啊,而且具有内生的扩展机制,允许通过自定义扩展来适应各种特殊情况(比如嵌入公式、图表,甚至任意HTML等)。通过这种设计上的偏置,我们可以极大简化常见场景的复杂度,从而使得可视化设计成为次级的设计目标。
一个很有趣的问题是,可视化设计是否生产力更高?很多程序员估计是要举双手双脚反对的。实际上,按照目前可视化设计工具的现状,设计器的输出产物有可能复杂度会超过直接手写的代码。更不用说,设计器相比于代码还存在多种缺陷:
- 无法像代码文本那样采用多种工具、多种手段对目标进行自由编辑
- 无法像代码中的函数封装那样以简单的方式实现二次抽象,很多设计器甚至连简陋的组件组合和暂存机制都不提供。
- 无法像代码中的继承和接口注入机制那样,对设计工具和设计产物进行局部修正和调整。
可逆计算理论针对以上问题提出了自己的解决方案,它指出可视化设计是可逆性的一种自然推论:
DSL <=> 可视化界面
领域特定语言DSL具有多种表达形式(文本和图形化),这些展现形式之间可以可逆转换。DSL内置通用的二次封装和差量扩展机制。设计器本身不是固化的产品,而是由元设计器结合DSL的结构信息动态生成,从而实现设计器与应用描述之间的协同演化。
三. LowCode要怎么Low?
如果把软件产品生产看作是对信息的一种加工过程,那么上一节所提到的LowCode的变Low的策略实际就是:
-
减少信息表达
-
采用Code之外的形式表达
如果我们仔细观察一下市面上的LowCode产品,会发现一些有趣的现象。以ivx.cn为例,它面向的用户是非专业程序员,能够以完全免编程的方式来设计界面和后台逻辑。这种所谓NoCode的方式确实可以降低对使用者的技术要求,它所依赖的除了可视化设计器所提供的直观性之外,还在于它主动的限制了使用者所面对的设计空间,放弃了编程中的很多便利性和灵活性,通过降低设计空间中的信息密度来达到降低技术能力要求的目的。
比如说,在一般的编程实践中,我们需要了各种变量的作用域以及作用域之间的关系,在ivx中没有这些概念,都类似全局变量。编程时,我们可以写复杂的链式调用a.b(g(3)).f('abc'),在ivx中也不存在这种概念,设计器中的一行只能表达单一一个动作。对于完成工作这一基本要求来说,我们编程中所习惯的大量特性确实是没有必要的,限制“做一件事只有一种方式,执行一个动作只会产生一种后果”使得入门变得更加容易。
但是,这种Low化的方式也会限制平台自身的能力上限,导致难以参与到更加复杂和更加高价值的生产活动中。
如果要求LowCode能够辅助专业开发,那么它一定要能在某种程度上本质性的减少信息表达。为了做到这一点,我们已知的策略大概有如下几种:
- 系统化的组件重用
- 基于领域抽象的模型驱动
- 全端、全流程、全生命周期的一体化设计
3.1 组件重用
组件重用是降低系统复杂度的一种通用策略:将复杂的对象分解,然后识别出重复的组分。LowCode的不同之处在于,它鼓吹一种系统化的组件重用,比如提供完整的开箱即用的组件库,无需程序员到处收集,而且确保所有组件可以正确组合,并提供适当的文档和良好的设计器支持,同时组件的生产和消费过程也可以被纳入LowCode平台的管理范围,比如提供公开的物料库和组件市场等。目前LowCode领域所缺乏的是一种得到广泛支持的组件描述标准(可以类似Jetbrains公司的web-types标准 https://github.com/JetBrains/web-types),它使得不同来源的组件库可以在统一的层面得到管理。
组件重用属于哲学上还原论的一种应用。还原论最成功的范例无疑是原子论。纷繁芜杂的世界表象下竟然是区区百来种原子的支撑,这无疑是关于我们这个世界的最深刻的洞察。但是,认识了原子并不等于认识了世界,大量的信息存在于原子的组合过程中,我们还需要对这个世界的多层次的、整体性的认识。
当前组件技术所面临的挑战在于,我们对于组件的动态性、可组合性、环境适应性等要求越来越高,因此必须要引入超越单个组件视角的、更加系统化的解决方案。比如,我们可能希望一套组件能够适应桌面端、移动端、小程序等多种运行环境。LowCode平台所提供的标准的解决方案是转译技术:把同一套组件描述针对不同的运行环境翻译为不同的具体组件实现(而不是把针对多种运行环境的实现细节封装在组件内部)。当转译成为一种日常之后,我们也就开始走入了模型的世界。
3.2 模型驱动
根据量子力学,在我们的世界中信息是守恒的。如果向一个系统投入少量信息就能够产生大量有价值的结果,那只可能是两个原因:
-
看似多样化的结果背后存在一个简单的逻辑内核,系统的本质复杂性并不如表面上看起来那么高。
-
结合其他信息源和全局知识,系统自动推导出了大量的衍生结果。
为了构造这样一个**非线性(投入和产出不成正比)**的生产系统,我们首先需要建立领域抽象,然后基于领域抽象建立一个可以被少量信息驱动的产品工厂。
领域抽象是发现领域中的本质性要素和它们之间的作用关系,换句话说,其实就是削减不必要的需求。当我们在一个领域浸淫多年,有了充分的领域知识之后,我们会发现很多需求都是没必要的细节,我们完全可以选择只做性价比高的事情。如果将这种领域知识沉淀为某种领域特定的描述语言,则我们就可以极大的降低信息的表达量。举个例子,前端css框架bootstrap库本质上是对前端结构的重新认识,它将颜色限定为success/info/warning/danger等少数几种,将尺寸限制为sm/md/lg等,而将布局限制为一行仅有12个可选位置。用惯了bootstrap之后,我们会发现实际上多数时候我们并不需要那么丰富的颜色搭配,也不需要那么多种尺寸选择。通过主动限制自己的能力之后,我们通过自律反而获得了某种自由–减少了不必要的决策和要求,同时达到了风格上的统一。
模型对于复杂性的化简往往是乘性的。比如说,100种可能情况如果通过两个基本要素的交叉组合来描述,100 = 10*10, 则我们只需要定义20个基本要素和一个组合规则即可。不止于此,模型的更大的价值在于它提供了关于系统的全局性的知识。比如,在有限自动机模型中,a->b->c->a,一系列状态迁移后系统并不会发散,而必然会回归到某个已知状态。而在自相似的嵌套模型中,整体由部分组成,部分结构放大后又回归到已知的描述。
全局性的知识极大的便利了信息的传播和推导。例如,如果所有组件实例在运行时都有唯一的名称和稳定的定位路径,则我们可以利用它来实现数据自动绑定(与Store中的数据项自动对齐),客户点击追踪等。而在传统的编程活动中,我们所依赖的主要是通用的、领域无关的程序语言和组件库等,缺少全局性的统一的结构约束,很容易就会破坏全局性的结构假定,导致自动推理链条的中断,只能通过程序员的手工工作负责接续。现代软件设计范式中强调约定优于配置(convention over configuration),其要点也正在于利用和保留全局知识。
模型描述所提供的知识,其用途往往是多样化的,可以参与多种推导过程。例如,根据数据模型,我们可以自动生成数据库定义/数据迁移脚本/界面描述/数据存取代码/接口文档等。而在传统的编程方式中,一段代码它的用途往往是唯一的。
LowCode平台目前的主流做法首先是试图提供一个“更好”的编程模型,然后再内置或者集成大量的领域特定的服务或程序模板。这个所谓的更好当然是仁者见仁,智者见智。有一些相当于是弥补当前编程语言的不足,提供增强的语法特性。比如自动将符合某些条件的同步操作翻译为异步调用,自动实现远程调用代理等,甚至自动实现分布式调度等。有一些是整合最佳实践,降低开发难度,比如将底层的React/Redux封装为类Vue的响应式数据驱动模型。而另一些则是引入更强的假定,缩小了编程模型的适用范围但是增强了平台的控制力,比如简化前端模板语言,自动将模板与前后端模型对象绑定,提供模板到多端的渲染能力支持等。
LowCode平台一般都会内置表单模型、规则模型、流程模型、BI图表模型等通用开发领域常见的模型引擎,同时可能提供丰富的前端界面模板、大屏展示模板等物料资源。很多还会提供领域特定的服务支持,比如针对IOT数据的流式数据处理服务等。
3.3 一体化设计
根据热力学,对于我们所观察到的世界,信息总是耗散的。当信息经过系统的边界不断传递时,它可能会丢失,会扭曲,会冲突。在日常工作中,我们很大一部分工作量不是在做什么新的事情,而是重复实现数据的格式调整、完整性验证、接口适配等本质上属于对接转换的工作。
我们所处的技术环境本身一直处在变动不居的持续演化过程中,这也成为持久的混乱之源。把编译环境架设起来,保证持续集成能够稳定运行并不是一件很简单的事情。经常会发现新人下载源码之后,半天编译打包不成功。移动端、云环境、分布式等复杂的运行环境使得非功能性需求的重要性不断上升,相应所需的知识量也在不断的膨胀。
监控运维和运营数据分析目前已经成为在线软件不可或缺的组成部分,也倒逼着功能开发必须要为运维埋点和数据分析提供支持。
目前LowCode平台对这一系列挑战的回答一般是一个涵盖各种输入输出端点、开发部署测试发布全流程、软件生产运维退役全生命周期的大统一的解决方案。一体化的设计便于减少信息的损耗,避免信息的重复表达,维护模型语义的一致性,屏蔽底层工具遍地是坑的悲惨现实。但无疑,这也是一柄双刃剑。维持一个遗世独立的稳定的乌托邦,需要非常大的投入。可能巨型的公司可以利用LowCode形式来作为自身基础能力的输出,反正它们本身就需要再造很多工具,而且希望其他人绑定到自身所提供的技术生态上,而第三方本身对依赖巨头也存在着默认可接受的事实。
四. LowCode与模型驱动有区别吗?
从目前的实际技术路线来看,LowCode平台目前所采用的策略方针与传统模型驱动领域并无本质的区别。只不过是在新时代的技术场景下,新技术的诞生使得一些事情变得更加简单,而开源技术的广泛流行使得各人能够操纵的技术元素和技术方位变得更加广泛了而已。确认,如果能够把稳定性问题完全外包给云计算基础设施,小团队借助适当工具后的开发能力完全可以适应传统上的大型软件的研发工作。
新的时代也产生了新的需求,在整个产品的应用范围方面。LowCode与模型驱动有一些差别。
LowCode可以说是继组件技术之后,试图实现超越组件粒度的、粗粒度、系统级的软件复用的一种集大成的实践集合。
- 从编程思想上说,传统的模型驱动基本还是把整体研发逻辑适配到某种面向对象编程范式上,而目前随着函数式的兴起,多范式是一种必然的选择。
- 传统的复用虽然目标设想的很大,但实际的操作路线比较粗糙,只是简单的实现参数化。
从可逆计算理论角度考察,我认为LowCode与传统模型驱动的一个差别可以是基于差量模型驱动的、拥抱模型演化的设计。对于任何一个模型,我们可以问一个简单的问题:能否允许定制,如何定制?追加一个问题就是:模型如何分解,如何在模型基础上实现二次抽象?
对模型可以增加一个衡量标准:是否可逆。很多问题,当我们明确意识到可逆性的存在和必要性之后,就开始变得明晰起来。
从适用的技术手段上说,随着转译技术的发展,和编译器技术的普及,目前在语言级别动刀子也不再是一件难以想象的事情。实际上,很多库作者的实际做法就已经是进入传统编译技术的领域了。在我们的武器库中增加了这一手段之后,特别是在应用层开放使用这种能力之后,很多拓扑结构上难以处理的大范围的信息传导问题就很容易解决。形式稳定性问题在使用本征表示之后往往也得以解决。
抽象最基本的方法是参数化。比如
F(X1, X2, X3, ....)
如果从很粗糙的角度上说,一个模型的复杂度我们从所需参数的个数来衡量,参数少的就是复杂度低,参数多的就是复杂度高。比如,如果参数X1,X2,X3之间是相互独立的,则模型所对应的情况显然和 X1, X2, X3的交叉积的个数直接对应。但是,实际的世界往往更加复杂,但参数足够多之后,它们并不是互相独立的!
我们理解F(X1,X2,X3)的前提是,我们需要理解F,还需要理解X1,X2,X3在F内部传播并被使用的具体过程。如果它们是相互影响的,情况可能还要更加糟糕,那就是我们需要理解这种相互影响到底是如何以微妙的方式发生的。
但是,一个真正有趣的情况在于,如果我们为X1,X2,X3建立规范化的结构约束后会怎样?当参数足够复杂之后,它有可能自身构成一个有继变化的整体,我们可以用一个领域模型M来对它进行描述,从而使得我们可以在不依赖于F的情况下独立的理解M。
我们这个世界底层的逻辑是层展的。也就是说我们可以在不同的层面基于不同的结构建立对系统的理解。从一个层面进入到另一个层面时,我们对它们的理解可能是独立的(一个完备的参数系统升华为一个独立的概念空间)。当我们引入结构,并主动的管理概念结构时,我们所面对的复杂性情况就完全不同了。
参数化演变的终点是 f(DSL), 所有x构成一个有机变化的整体,从而实现整体领域逻辑的一种描述方式,而f成为领域的支撑能力。当然一个有效的DSL只能是描述某个业务切面,所以需要 f(DSL1) + g(DSL2)+ 。。。, 总结下来就是 Y = G(DSL) + delta。
抽象的一个常见问题是抽象泄露。如果我们抽象出的DSL与实际情况不符合怎么办?在可逆差量的视角下,这个问题可以这么解决:
Biz = App - G(DSL1)
把剥离领域描述DSL1之后剩下的部分Biz看作是一个独立的研究对象。这类似于物理上我们可以把高斯模型作为系统的零阶解, 然后把原始方程重新表述为修正量所对应的1阶方程。
从底层技术的基本逻辑来说,很多业务问题背后的技术结构是似曾相识的,但是目前主流的技术手段并不足以我们把相应的技术实现从一种技术场景迁移到其他技术场景。总是有很多技术实现和业务内容强绑定,需要程序员拷贝粘贴过来之后手工进行剪裁修正。通过DSL抽象和差量化处理,我们可以实现不同层面逻辑的一种新的拆分模式,例如在不打开引擎盖的情况下换发动机。
程序员是站在上帝视角看待软件系统的,他并不需要完全被动的接收系统中的事实。上帝说,要有光,于是就有了光。程序员可以自己设计规则(Rule/Law),并约束所有元素的行为。现在有些人认为LowCode只能做从0到1的原型开发,最终还是要通过DDD之类的传统技术重构,这大概是认为LowCode只能是把业务对齐到少数内置的模型上,而不能根据领域的实际情况提供最合适的逻辑分解。而可逆计算的视角不同,它强调DSL本身应该是可定制的,可以根据需求变化做自由扩展。同时类似JetBrains公司的MPS系统,可逆计算的支撑技术应该是一种领域语言工作台,它为领域语言的开发/运行提供完整的解决方案。
五. LowCode需要技术中立吗?
LowCode试图实现更高级的复用,那么技术生态的分裂所导致的这种偶然的依赖性必然是它要试图屏蔽的内容。同样的逻辑内容为什么使用java实现了之后在typescript不能被直接使用?
技术中立存在几种策略:
-
微服务。通过技术中立的通信协议实现分离,这是一种非常规范而成熟的方案。而且随着内核网络栈的优化,例如引入RDMA和DPDK技术,Sidecar模式下跨进程调用的性能极度优化后可以与进程内调用可比。
-
虚拟机。GraalVM提供了通过编译混杂不同的技术栈的作用,这也是非常有前途的一种方向,它的好处是可以跨越技术边界实现协同优化。而在微服务的方案中,Java调用JavaScript的代码不能进行统一优化。
-
领域语言。这是一种低成本的,控制权由普通程序员掌握的方案。如果编写解释器的复杂性能够进一步降低,比如类似于一个解释规则就是简单对应于一个函数调用,它可以成为我们解决日常业务问题的一种常规手段。
如果把每种具体的实现技术看作是一种不同的坐标系,那么采用不同的技术去实现就相当于是把一个确定的逻辑使用不同的坐标系统去表示。那么数学上是如何处理坐标无关量的?物理学的所有原理都是所谓参照系无关的,也就是坐标无关的,它们都采用所谓的张量(Tensor)来表示。张量的坐标无关本质上说的是,一个物理量在不同的坐标系里有不同的具体表示,这些具体的表示之间通过某种可逆的结构变换联系在一起。坐标中立并不意味着绑定到某种坐标系中,而是不同的坐标之间可以可逆转换。
所以依据可逆计算理论,我们并不一定要强求大一统设计,强求所有地方的信息表达都只有唯一的一种形式。而可以是多种表达,只要存在某种预定义的可逆机制可以从系统中反向抽取信息并自动进行转换即可。比如,现有的接口定义都存在接口描述,无论是采用protobuf描述,还是jsonrpc,抑或是grpc。因为它们都是描述式信息。原则上我们是可以根据其中一种描述,补充部分信息实现这些结构描述之间的自由转换的。如果我们的产品可以随时根据接口描述自动生成,它就可以不是一种固化的二进制代码。延迟生成,实际上就是一种多阶段编译技术,它可以是未来LowCode的发展方向。
可逆性是可以分而治之的。当一个庞大模型的每个局部都是可逆的时候,我们就有可能自动得到整体的可逆性。可逆性本身也是可以跨系统的。LowCode的未来不应该是单一的产品或者单一的SAAS应用,而是内与外、上下游可以实现信息的自由传递与转换,突破技术形式的绑定。
坐标中立的体系存在一个特例–零,它为系统带来了一种本质性的化简机制。一个坐标中立的零在所有的坐标系中都仍然保持为零。它的含义在于,有很多运算我们完全可以在坐标中立的表象中完成。大量的判断和结构转换/加工都可以在纯形式的层面完成,它们完全不涉及到复杂的运行时依赖。
可逆计算的一个核心观点是,坐标中立是形式层面的事情,可以完全脱离运行时来讨论。通过编译期的元编程技术,我们可以实现运行时结构与直接手写代码完全相同。LowCode在运行期可以不引入额外的间接处理层。
六. LowCode需要图灵完备吗?
说实话,图灵完备这个概念完全是计算机圈子内部的行话。说起模型,一个模型的重要性和有效性与图灵完备有半毛钱的关系吗?比如,化学分子式无疑是描述分子结构的一种非常有效的领域特定语言,化学反应方程是对具体化学反应过程的一种模型化的描述,它需要是图灵完备的吗?牛顿万有引力方程将天上的星星和地上的苹果联系在一起,是伟大的建模成就,它的计算可以指导四季耕作。微分方程模型的建立和求解需要图灵完备吗?
领域内最核心的知识并不需要图灵完备。我们需要图灵完备的地方是当我们需要做一些“通用”的计算和处理过程的时候,当我们需要机器代替我们去自动化处理某些平平无奇的动作的时候。当我们要以某种未预料的方式来处理某些事情时,我们需要保留图灵完备的处理能力。如果我们已经遇到过这种情况,往往我们能够进行算法封装,把复杂的逻辑运算封装到算法内部,外部使用者并不需要图灵完备。
LowCode为了完成足够广泛范围的工作,它肯定是要保留图灵完备的能力的。但是它所提供的核心的领域模型并不需要图灵完备。图灵完备反而可以只是某种边缘场景的应用。
图灵完备能力的获得可以是通过内嵌的DSL语言。当然这是一种非常廉价的方式,特别是可以充分利用IDE对语言本身的支持来免费获得实现对DSL的支持。但是这种做法的问题在于,嵌入式DSL往往只关注于正确表达的形式直观性,对于偏离DSL形式的情况缺乏约束。也就是说,如果使用者不按照约定的方式去编写DSL是完全可能的,虽然语义上是完全一致的,但从形式上就不符合原始DSL的要求。面向DSL的结构转换也就难以进行下去。
JSX这种方式是一种有趣的扩展形式。因为执行时我们可以获得虚拟DOM节点,相当于是拥有对结构的比较大的控制权限的。但是typescript的问题在于它没有明确的编译期。jsx的编译期处理非常复杂,运行期得到的是具体的VDOM节点。而在编译期我们需要分析代码结构,而因为停机问题的存在,普遍来说代码结构是难以分析的。所以vue template这种编译期可分析的结构是非常重要的。
图灵完备并不是信息完备。反向解析得到信息是目前所有主流技术都缺乏的。图灵完备实际上不利于信息逆向分析。习惯于手写代码的传统导致程序员对于程序结构的自动分析并不重视,因为这些工作此前都是编译器编写者的责任。而如果LowCode可以大规模在应用层使用这种技术,还需要更多的普及教育。现在所有语言的运行时能力很强,但是编译期的逆向能力都很差。很多人倾向于用json,本质上是想把逆向分析/转换的能力掌握到手里。
DSL也不一定意味着特殊的程序语法。我们对于可逆计算的具体实现是直接使用xml模板技术作为前后台统一的结构描述,相当于是直接编写AST抽象语法树。相比于LISP,好处在于结构形式更加丰富一些。显然html格式对于一般人员来说,比lisp还是要更加容易阅读。
可逆计算提供了将扩展能力累加到领域特定逻辑之上的方法。
七. 为了LowCode我们会失去什么?
一个有趣的问题是,LowCode带给我们的都是好处吗?使用LowCode我们会失去什么?
我的回答是,LowCode将使得程序员失去一家独大的控制权。传统的编程方式,所有软件结构的构造都源自于程序员的输入,因为程序员成为了应用和需求人员不可回避的中介。而LowCode技术所带来的一种变革在于,通过将逻辑分层分解,多种信息来源可能独立的参与系统构建。需求人员完全可能绕过程序员直接指示业务模型的构造,并在系统智能的支持下自主的完成业务设计-反馈的循环。当这些人员直接掌握控制权之后,可能他们也不想再回到此前那个需要被动等待的时代。
LowCode的技术策略虽然看来看去似乎并不新鲜,但是它确实在表述和立意上有所不同。它明确强调citizen programming,而此前的model driven本质上还是程序员内部的问题。
任何一场技术革命实质性的结果都是生产力和生产关系的变革。我们已经站在时代的边缘,使得多种信息掌控者:程序员、业务人员、人工智能等等可以通过分工协作、齐头并进的方式参与逻辑系统的构建,使得信息的流动有望突破形式的限制,绕过人类载体,跨越系统边界和时间演化进程。LowCode在传达这一核心概念的时候是不清晰的、存在误导性的。
基于可逆计算理论,我提出了一个新的概念: 下一代软件生产范式-NOP(非编程,NOP is Not Programming)。
NOP强调了这种生产范式转换所带来的本质性变化。从桌面互联网转向移动互联网技术之后,一个新的理念诞生,那就是所谓的移动优先。当我们设计一个系统时,首先考虑移动端的处理过程,然后再考虑桌面端。类似的,在LowCode的时代,我们在软件生产中需要考虑描述优先,通过领域模型将系统的逻辑结构以可以进行差量修正的形式明确表达处理,它作为一种后续的财富,使得我们的系统逻辑可以越来越多的摆脱某种当时当地的技术实现约束的限制,明确记录我们的业务意图。
描述的部分应该和常规代码的部分具有明确的边界。以Antlr4为例,此前的设计中,我们会在描述式的EBNF范式中增加action标注来控制语法解析器的行为,而在Antlr4中明确提出语法文件中只描述语法结构,一些特定的处理过程全部集中到Listener和Visitor处理器中。描述信息完全被隔离之后,antlr立刻摆脱了java的束缚,它可以根据同一份语法定义,生成java/go/typescript等不同语法实现的解析器,同时根据语法描述自动生成IDE语法解析插件,格式化处理器,IDE自动提示等,产生了多种用途。
在我看来,传统上的code使用的逻辑是机器运行的逻辑,把所有逻辑的表述形式都适配到适合图灵机或者lamba演算机运行的形式。但是领域逻辑具有自己特定的表述形式,它的组成元素有自己的作用方式,这些方式可以被直接理解,而不必非要划归为某个图灵机上执行的步骤去理解。一个语言就是一个世界,不同的世界有不同世界观。LowCode不是说code有多low, 而应是表述的方向不同。
LowCode并不等价于让不懂逻辑的人写代码(虽然很多产品试图给人这种错觉让人买单)。实际上很多数学家也不会写程序,但是他们非常懂逻辑。5-10年以后市场上会有不少40岁以上的曾经的程序员,但他们不一定再懂最新的开发技术,用一个更高层的逻辑描述不还是能开发业务逻辑并享用到最新的技术进展吗?
基于可逆计算理论设计的低代码平台NopPlatform已开源:
- gitee: canonical-entropy/nop-entropy
- github: entropy-cloud/nop-entropy
- 开发示例:docs/tutorial/tutorial.md
- 可逆计算原理和Nop平台介绍及答疑_哔哩哔哩_bilibili
相关文章:

从可逆计算看低代码
2020年低代码(LowCode)这一buzzword频繁亮相于主流技术媒体,大背景下是微软/亚马逊/阿里/华为等巨头纷纷入场,推出自己的相应产品。一时之间,大大小小的技术山头,无论自己原先是搞OA/ERP/IOT/AI的ÿ…...

设计模式最佳实践代码总结 - 结构型设计模式篇 - 侨接设计模式最佳实践
目录 侨接设计模式最佳实践 侨接设计模式最佳实践 桥接模式是一种结构型设计模式,它将抽象部分与它的实现部分分离,使它们可以独立地变化。桥接模式是一种结构型设计模式,它将抽象部分与它的实现部分分离,使它们可以独立地变化。…...

【软件测试】python——Unittest
UnitTest 框架 笔记来自于黑马程序员python自动化测试教程,python从基础到Uinttest框架管理测试用例。链接:[黑马程序员python自动化测试教程,python从基础到Uinttest框架管理测试用例](https://www.bilibili.com/video/BV1av411q7dT?spm_i…...

Maven:详解 clean 和 install 命令的使用
clean 的主要功能是清理项目构建过程中生成的所有临时文件和输出文件。具体来说,clean 阶段会删除 target 目录及其所有内容。 clean 阶段的具体功能 删除 target 目录: target 目录是 Maven 构建过程中默认的输出目录,存放所有构建生成的文件…...

HTTP与RPC
一、概念 HTTP(Hypertext Transfer Protocol,超文本传输协议)是一种应用层协议,主要用于在Web服务器之间传输html页面和其他Web资源。 RPC(Remote Procedure Call,远程过程调用) 是一种通用的远程调用通信协议&#…...

解决蓝牙键盘按键错乱的问题
最近发现我的蓝牙键盘按下的键盘与实际不符,于是就上网搜索答案,网上的方法都试了一遍 最后想着准备退货,没想到客服直接给我解决了 原因很简单,就是之前误触了键盘的某些按键导致的 每个键盘品牌的按键因该都不同的,可…...

MiL.k X Biggie 奇妙宇宙来袭!
MiL.k 和亚航奖励计划联手推出 MiL.k X BIGGIE 奇妙宇宙,为亚航会员和 MiL.k 用户提供神奇的 Web3 体验。这款沉浸式体验位于 The Sandbox 的 MiL.k Land,提供趣味游戏,解锁令人兴奋的新奖励。 亚航吉祥物 BIGGIE 和他友好的机舱服务员将引导…...
rm -rf <directory_name>)
云服务器中删除非空目录(包含文件和子目录)rm -rf <directory_name>
在云服务器中删除目录可以使用 rm 命令。如果您需要删除一个非空目录(包含文件和子目录),可以使用以下命令: rm -rf <directory_name>参数解释: -r:递归删除,即删除目录及其所有内容&am…...
1991-2024年经管类国自然、国社科立项名单(附68份国自然标书)-最新出炉 附下载链接
很全!1991-2024年经管类国自然、国社科立项名单(附68份国自然标书) 下载链接-点它👉👉👉:很全1991-2024年经管类国自然、国社科立项名单(附68份国自然标书).zip 资源介…...

Flutter问题记录 - 布局中莫名其妙的白线/缝隙
文章目录 前言开发环境问题描述问题分析解决方案最后 前言 最近客服反馈了一个奇怪的问题,有个用户反馈其他问题时给了应用截图,然后他发现这截图中有一条奇怪的白线。他在自己手机上没有发现这个问题,于是提工单反馈到我这。 开发环境 Fl…...
-----LoRA(中))
从零学习大模型(七)-----LoRA(中)
自注意力层中的 LoRA 应用 Transformer 的自注意力机制是模型理解输入序列之间复杂关系的核心部分。自注意力层通常包含多个线性变换,包括键(Key)、查询(Query) 和 值(Value) 三个权重矩阵的线…...
Java知识巩固(十二)
I/O JavaIO流了解吗? IO 即 Input/Output,输入和输出。数据输入到计算机内存的过程即输入,反之输出到外部存储(比如数据库,文件,远程主机)的过程即输出。数据传输过程类似于水流,因…...

一家光伏企业终止,恐不具行业代表性,市占率仅为2.35%
海达光能终止原因如下:报告期内海达光能销售金额较所在行业第二名亚玛顿相差两倍以上,公司毛利率更是远低于行业龙头福莱特,恐难以说明公司行业代表性。在企业竞争上,公司2021年度的市场占有率约为2.35%,公司未来光伏玻…...

企业计算机监控软件是什么?6款电脑监控软件分享!提升企业管理效率,吐血推荐!
嘿,各位企业管理者和IT小伙伴们! 您是否曾担忧员工在工作时间内效率低下?是否对公司的数据安全感到不安? 别担心,今天我们就来聊聊企业计算机监控软件,它就像是企业的"超级侦探",帮…...
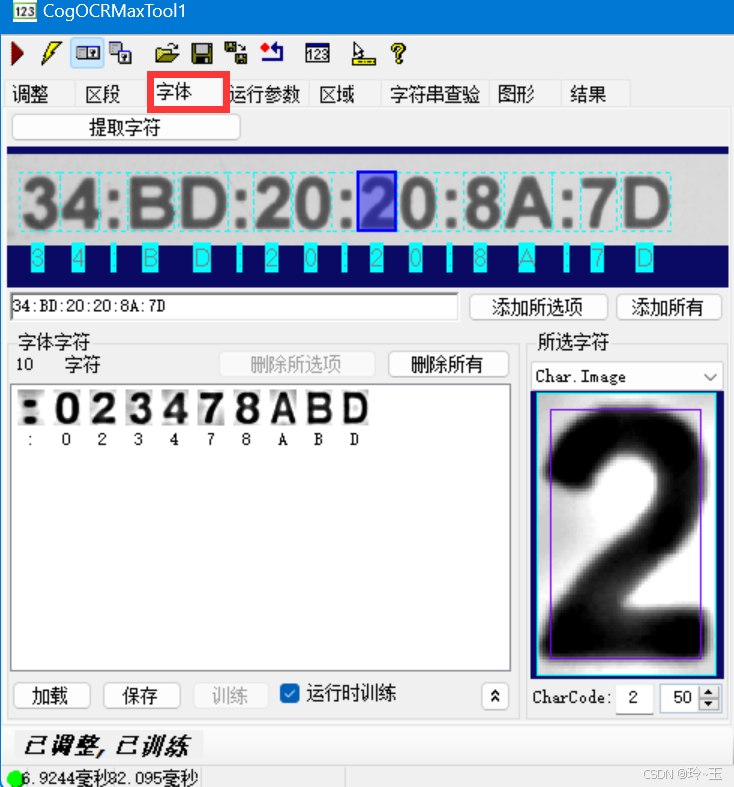
VisionPro —— CogOCRMaxTool工具详解
CogOCRMaxTool的作用: CogOCRMaxTool:是一个字符识别工具,主要用于字符识别,它能够根据已训练的字符样本读取灰度图像中的字符,并返回读取结果。 一:工具位置 二:添加图片 三:工具的初始页面 将识别框拖到需要识别处…...

网站安全问题都有哪些,分别详细说明
网站安全问题涉及多个方面,以下是一些常见的网站安全问题及其详细说明: 数据泄露 问题描述:数据泄露是指网站存储的用户敏感信息(如用户名、密码、信用卡信息等)被非法获取。黑客可能通过SQL注入、XSS攻击等手段窃取这…...

DiskGenius一键修复磁盘损坏
下午外接磁盘和U盘都出现扇区损坏,估计就是在开着电脑,可能是电脑运行的软件还在对磁盘进行读写,不小心按到笔记本关机键,重新开机读写磁盘分区变得异常卡顿,估摸就是这个原因导致扇区损坏。在进行读写时,整…...

Matlab实现鼠群优化算法优化回声状态网络模型 (ROS-ESN)(附源码)
目录 1.内容介绍 2.部分代码 3.实验结果 4.内容获取 1内容介绍 鼠群优化算法(Rat Swarm Optimization, ROS)是一种基于老鼠群体行为的群体智能优化算法。ROS通过模拟老鼠在寻找食物时的聚集、分散和跟随行为,来探索解空间并寻找最优解。该算…...

nfs作业
一、作业要求 1、开放/nfs/shared目录,供所有用户查询资料 2、开放/nfs/upload目录,为192.168.xxx.0/24网段主机可以上传目录, 并将所有用户及所属的组映射为nfs-upload,其UID和GID均为210 3、将/home/tom目录仅共享给192.168.xxx.xxx这台…...

Linux 基础io_理解文件系统_软硬链接_动静态库
一.磁盘 1.磁盘物理结构 盘片 磁盘可以有多个磁片,每个磁片有两个盘面,每个盘面都对应一个磁头,都可以存储数据。 磁道 扇区 磁道是指在盘面上,由磁头读写的数据环形轨道。每个磁道都是由一圈圈的圆形区域组成,数据…...

电力系统网络安全:从风险认知到威胁建模的实战指南
1. 从日常运维到风险认知:重新审视大容量电力系统的安全基线在能源行业干了十几年,我见过太多同行把大容量电力系统(Bulk Energy System, BES)的运维简化为“确保别停电”。日常的告警处理、设备巡检、工单流转构成了工作的全部叙…...

美政府AI主管:Anthropic 将在 18 个月内成为人类历史最有价值公司
Anthropic 已经成为人工智能革命中最成功的案例之一,但这或许还不是全部。风险投资家兼美国政府人工智能和加密货币沙皇大卫萨克斯在 All-In播客节目中提出了一个惊人的说法:Anthropic 不仅有望成为科技界最强大的公司,而且有望成为人类历史上…...

uni-app iOS后台运行 uni-app App如何实现后台定位或音乐播放
iOS上uni.startBackgroundTask基本无效,仅音频播放、定位更新、后台数据刷新三类能力合规;后台定位需manifest声明原生权限地理围栏事件;无声音频保活须onLaunch配置AudioSession并延迟播放。uni.startBackgroundTask 在 iOS 上基本无效&…...

ncmdump工具完全攻略:解锁网易云音乐NCM格式转换的终极指南
ncmdump工具完全攻略:解锁网易云音乐NCM格式转换的终极指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM加密格式无法在其他播放器播放而烦恼吗?你是否经历过精心收藏的音乐只能…...
)
2000-2025年《中国县域统计年鉴》pdf+excel版(附赠面板数据)
资源介绍《中国县域统计年鉴》2000-2025一、数据介绍《中国县域统计年鉴》是一部全面反映我国县域社会经济发展状况的资料性年鉴,从2014年开始分为《中国县域统计年鉴(县市卷)》和《中国县域统计年鉴(乡镇卷)》两卷。数…...
)
艾尔登法环黑夜君临修改器2026.5.11最新中文汉化版免费下载 转存后自动更新 (看到请立即转存 资源随时失效)
在《艾尔登法环》的庞大世界观下,一款名为《艾尔登法环:黑夜君临》(ELDEN RING NIGHTREIGN)的衍生作品于 2025 年正式登场。它并非单纯的续作或大型 DLC,而是一款基于原作设定、专注于多人协作生存与浓缩化 RPG 体验的…...

从SPICE到Q-SPICE:四阶累积量如何重塑阵列信号处理的超分辨能力
1. 从SPICE到Q-SPICE:为什么我们需要四阶累积量? 我第一次接触SPICE算法是在处理雷达信号的时候。当时团队遇到一个头疼的问题:在强噪声环境下,传统算法就像近视眼观察星空,明明知道那里有信号,却怎么也分辨…...

ArcGIS符号库“隐身”之谜:从DAO组件缺失到完整恢复的实战指南
1. 当符号选择器突然"罢工":一个GISer的崩溃瞬间 那天早上我正赶着完成客户的地图项目,准备给水系图层换个漂亮的蓝色符号。像往常一样双击图层打开属性窗口,点击Symbol Selector准备挑选样式时,整个人瞬间僵住了——本…...

MCA Selector技术架构深度解析:Minecraft区块管理系统的实现原理
MCA Selector技术架构深度解析:Minecraft区块管理系统的实现原理 【免费下载链接】mcaselector A tool to select chunks from Minecraft worlds for deletion or export. 项目地址: https://gitcode.com/gh_mirrors/mc/mcaselector MCA Selector是一款专为M…...

八大网盘直链获取开源工具全面指南:如何高效管理你的云端文件下载
八大网盘直链获取开源工具全面指南:如何高效管理你的云端文件下载 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动…...