文件路径模块os.path
文件路径模块os.path
文章目录
- 文件路径模块os.path
- 1.概述
- 2.解析路径
- 2.1.拆分路径和文件名split
- 2.2.获取文件名称basename
- 2.3.返回路径第一部分dirname
- 2.4.扩展名称解析路径splitext
- 2.5.返回公共前缀路径commonprefix
- 3.创建路径
- 3.1.拼接路径join
- 3.2.获取家目录
- 3.3.规范化路径normpath
- 3.4.相对路径转化为绝对路径abspath
- 4.获取文件属性
- 5.测试文件
1.概述
这篇文章介绍与文件操作相关的路径操作模块,包含解析路径、建立路径、规范化路径等相关操作。
2.解析路径
2.1.拆分路径和文件名split
split函数用来将文件路径查分为两部分,路径和文件名。它返回一个tuple,这个tuple第一个元素是路径,第二个元素是路径的最后一个部分,通常是文件名称。
import os.pathPATHS = ['/one/two/three','/one/two/three/','/','.','',
]for path in PATHS:print('{!r:>17} : {}'.format(path, os.path.split(path)))
运行上面的代码,split函数默认通过 / 拆分文件路径,以最后一个/ 为分界线,左边的是路径,右边的是文件名称。
# 最后一个/右边有three,返回的元组中第二个元素为three
'/one/two/three' : ('/one/two', 'three')
# 最后一个/右边没有内容,返回的元组中第二个元素为空
'/one/two/three/' : ('/one/two/three', '')'/' : ('/', '')'.' : ('', '.')'' : ('', '')
2.2.获取文件名称basename
basename函数接收一个代表文件系统路径的类路径对象,返回一个代表指定路径基本名称的字符串值。它返回的值等价于split函数返回值的第二部分,他会将整个路径剔除到最后一个元素,如果最后一个元素是文件名称,则获取的就是一个文件名称。
import os.pathPATHS = ['/one/two/three','/one/two/three/','/','.','',
]for path in PATHS:print('{!r:>17} : {!r}'.format(path, os.path.basename(path)))运行上面的代码,返回值是路径中最后一个元素,这个元素也称为路径的基本名称。
# 冒号左边是完整路径,右边是拆分路径获取的值
'/one/two/three' : 'three'
'/one/two/three/' : '''/' : '''.' : '.''' : ''
2.3.返回路径第一部分dirname
dirname函数返回解析路径的第一部分,将basename的结果和dirname结果结合就可以得到原来的路径。
import os.pathPATHS = ['/one/two/three','/one/two/three/','/','.','',
]for path in PATHS:print('{!r:>17} : {!r}'.format(path, os.path.dirname(path)))运行结果
'/one/two/three' : '/one/two'
'/one/two/three/' : '/one/two/three''/' : '/''.' : '''' : ''
2.4.扩展名称解析路径splitext
splitext函数与split函数相似,不过它不是根据目录分隔符拆分路径,而是根据扩展名分隔符。
import os.pathPATHS = ['filename.txt','filename','/path/to/filename.txt','/','','my-archive.tar.gz','no-extension.',
]for path in PATHS:print('{!r:>21} : {!r}'.format(path, os.path.splitext(path)))
运行结果
'filename.txt' : ('filename', '.txt')'filename' : ('filename', '')
'/path/to/filename.txt' : ('/path/to/filename', '.txt')'/' : ('/', '')'' : ('', '')'my-archive.tar.gz' : ('my-archive.tar', '.gz')'no-extension.' : ('no-extension', '.')2.5.返回公共前缀路径commonprefix
commonprefix函数返回路径列表中最大公共前缀,这个值可能表示一个不存在的路径,而且并不考虑路径的分隔符,所以这个前缀可能并不落在一个分隔符边界上。
import os.pathpaths = ['/one/two/three/four','/one/two/threefold','/one/two/three/',]
for path in paths:print('PATH:', path)print()
print('PREFIX:', os.path.commonprefix(paths))
运行结果
PATH: /one/two/three/four
PATH: /one/two/threefold
PATH: /one/two/three/PREFIX: /one/two/three3.创建路径
3.1.拼接路径join
使用join将多个路径拼接成一个路径,如果要拼接的参数以分隔符开头 ,前面所有的参数都会丢弃,新参数会成为返回这的开始部分。
import os.pathPATHS = [('one', 'two', 'three'),('/', 'one', 'two', 'three'),('/one', '/two', '/three'),
]for parts in PATHS:print('{} : {!r}'.format(parts, os.path.join(*parts)))
结果
('one', 'two', 'three') : 'one/two/three'
('/', 'one', 'two', 'three') : '/one/two/three'
('/one', '/two', '/three') : '/three'
3.2.获取家目录
一般如果你自己使用系统的时候,是可以用~来代表"/home/你的名字/"这个路径的,但是python是不认识~这个符号的,如果你写路径的时候直接写"~/balabala",程序是跑不动的。
expanduser函数可以将~获取服务器家目录,方便我们访问或创建家目录后面的路径。如果用户的家目录找不到,字符串将不做任何改动,直接返回。
import os.pathfor user in ['', '/dhellmann', '/nosuchuser']:lookup = '~' + userprint('{!r:>15} : {!r}'.format(lookup, os.path.expanduser(lookup)))
运行结果
# /Users/edy 是当前服务器上的家目录'~' : '/Users/edy''~/dhellmann' : '/Users/edy/dhellmann''~/nosuchuser' : '/Users/edy/nosuchuser'3.3.规范化路径normpath
使用join函数或者添加单独字符串路径时,得到的路径可能会有多余的分隔符。使用normpath函数可以清除这些内容
import os.pathPATHS = ['one//two//three','one/./two/./three','one/../alt/two/three',
]for path in PATHS:print('{!r:>22} : {!r}'.format(path, os.path.normpath(path)))
运行结果
'one//two//three' : 'one/two/three''one/./two/./three' : 'one/two/three'
'one/../alt/two/three' : 'alt/two/three'
3.4.相对路径转化为绝对路径abspath
abspath函数的作用是将给定的文件路径转为绝对路径,例如下面的例子PATHS列表中给的是文件相对路径,然后在他们的前面拼接上当前工作目录,将他们转为绝对路径。而不是根据给定的一个文件或相对路径,去查找该文件的绝对路径。
import os
import os.pathos.chdir('/usr')PATHS = ['.','..','./one/two/three','../one/two/three',
]for path in PATHS:print('{!r:>21} : {!r}'.format(path, os.path.abspath(path)))
运行结果
# 获取当前的工作目录的绝对路径'.' : '/usr''..' : '/'# 相对路径拼接上当前工作目录,转为绝对路径'./one/two/three' : '/usr/one/two/three'
# 当前工作目录的上级目录拼接上相对路径,转为绝对路径'../one/two/three' : '/one/two/three'
4.获取文件属性
os.path除了操作路径,还可以获取文件属性。
import os.path
import time
# 获取文件的绝对路径
print('File :', __file__)
# 获取文件访问时间
print('Access time :', time.ctime(os.path.getatime(__file__)))
# 获取文件修改时间
print('Modified time:', time.ctime(os.path.getmtime(__file__)))
# 获取创建时间
print('Change time :', time.ctime(os.path.getctime(__file__)))
# 获取文件大小以字节为单位
print('Size :', os.path.getsize(__file__))
运行结果
# 获取文件的绝对路径
File : /Users/edy/create_path.py
# 获取文件访问时间
Access time : Mon Feb 13 14:38:26 2023
# 获取文件修改时间
Modified time: Mon Feb 13 14:38:26 2023
# 获取创建时间
Change time : Mon Feb 13 14:38:26 2023
# 获取文件大小以字节为单位
Size : 1338
5.测试文件
当程序遇到一个路径时,需要判断当前路径是一个文件,文件夹,还是一个链接,是否存在等,这些os.path提供了函数用来判断。
import os.pathFILENAMES = [__file__,os.path.dirname(__file__),'/','./broken_link',
]for file in FILENAMES:print('File : {!r}'.format(file))# 是否是绝对路径print('Absolute :', os.path.isabs(file))# 是否是文件print('Is File? :', os.path.isfile(file))# 是否是目录print('Is Dir? :', os.path.isdir(file))# 是否是一个链接print('Is Link? :', os.path.islink(file))# 是否是一个挂载点print('Mountpoint? :', os.path.ismount(file))# 判断文件是否存在print('Exists? :', os.path.exists(file))# 判断路径是否存在,如果存在,则返回 True;反之,返回 Falseprint('Link Exists?:', os.path.lexists(file))print()
运行结果
File : '/Users/edy/my_path'
Absolute : True
Is File? : False
Is Dir? : True
Is Link? : False
Mountpoint? : False
Exists? : True
Link Exists?: TrueFile : '/'
Absolute : True
Is File? : False
Is Dir? : True
Is Link? : False
Mountpoint? : True
Exists? : True
Link Exists?: TrueFile : './broken_link'
Absolute : False
Is File? : False
Is Dir? : False
Is Link? : False
Mountpoint? : False
Exists? : False
Link Exists?: False相关文章:

文件路径模块os.path
文件路径模块os.path 文章目录文件路径模块os.path1.概述2.解析路径2.1.拆分路径和文件名split2.2.获取文件名称basename2.3.返回路径第一部分dirname2.4.扩展名称解析路径splitext2.5.返回公共前缀路径commonprefix3.创建路径3.1.拼接路径join3.2.获取家目录3.3.规范化路径nor…...
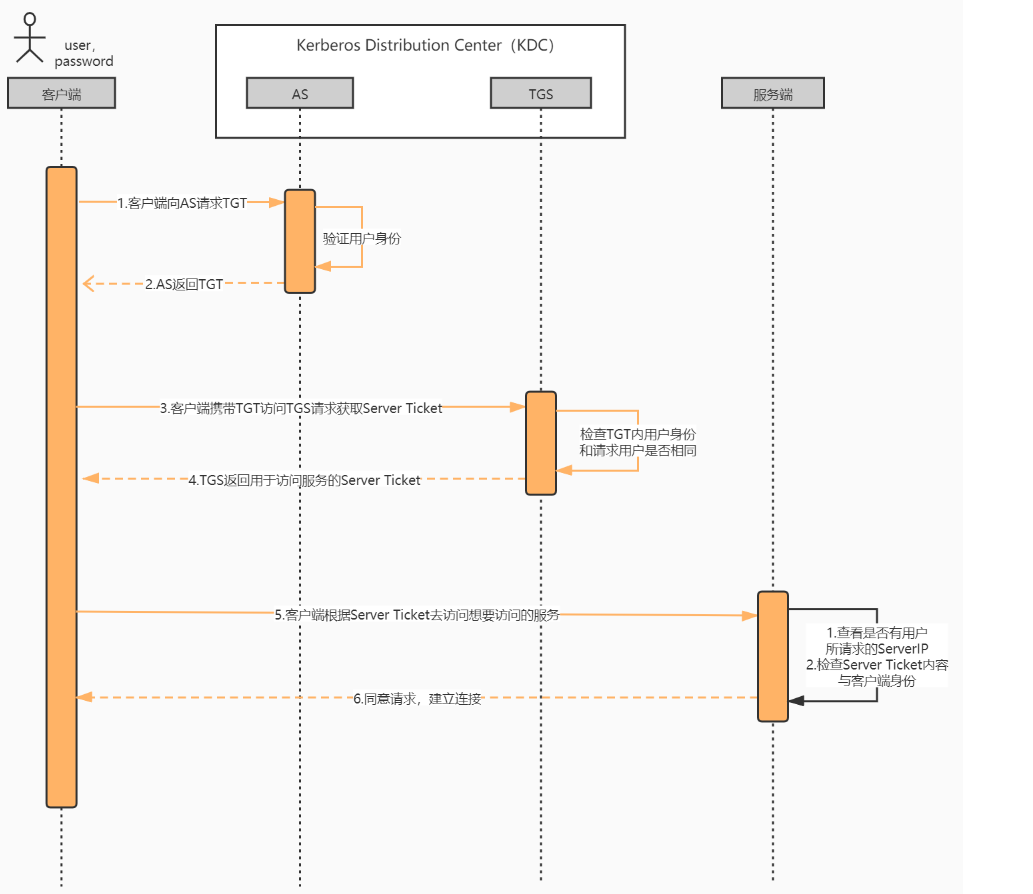
Kerberos简单介绍及使用
Kerberos作用 简单来说安全相关一般涉及以下方面:用户认证(Kerberos的作用)、用户授权、用户管理.。而Kerberos功能是用户认证,通俗来说解决了证明A是A 的问题。 认证过程(时序图) 核心角色/概念 KDC&…...

DOM编程-全选、全不选和反选
<!DOCTYPE html> <html> <head> <meta charset"utf-8"> <title>全选、全不选和反选</title> </head> <body bgcolor"antiquewhite"> <script type"text/jav…...

C++11可变模板参数
C11可变模板参数一、简介二、语法三、可变模版参数函数3.1、递归函数方式展开参数包3.2、逗号表达式展开参数包一、简介 C11的新特性–可变模版参数(variadic templates)是C11新增的最强大的特性之一,它对参数进行了高度泛化,它能…...

Linux多线程
目录 一、认识线程 1.1 线程概念 1.2 页表 1.3 线程的优缺点 1.3.1 优点 1.3.2 缺点 1.4 线程异常 二、进程 VS 线程 三、Linux线程控制 3.1 POSIX线程库 3.1 线程创建 3.3 线程等待 3.4 线程终止 3.4.1 return退出 3.4.2 pthread_exit() 3.4.3 pthread_cancel…...
Webpack5 环境下 Openlayers 标注(Icon) require 引入图片问题
Webpack5 环境下 Openlayers 标注(Icon) require 引入图片问题环境版本Openlayers 使用 require 问题Webpack5 正确配置构建新环境的时候,偶然发现 Openlayers 使用 require 的方式加载图片(Icon)报错,开始…...

Zookeeper安装部署
文章目录Zookeeper安装部署Zookeeper安装部署 将Zookeeper安装包解压缩, [rootlocalhost opt]# ll 总用量 14032 -rw-r--r--. 1 root root 12392394 10月 13 11:44 apache-zookeeper-3.6.0-bin.tar.gz drwxrwxr-x. 6 root root 4096 10月 18 01:44 redis-5.0.4 …...
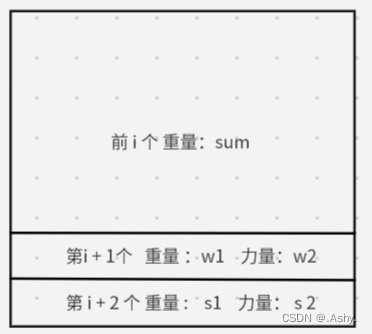
Cow Acrobats ( 临项交换贪心 )
题目大意: N 头牛 , 每头牛有一个重量(Weight)和一个力量(Strenth) , N头牛进行排列 , 第 i 头牛的风险值为其上所有牛总重减去自身力量 , 问如何排列可以使最大风险值最小 , 求出这个最小的最大风险值&am…...

MySQL:为什么说应该优先选择普通索引,尽量避免使用唯一索引
前言 在使用MySQL的过程中,随着表数据的逐渐增多,为了更快的查询我们需要的数据,我们会在表中建立不同类型的索引。 今天我们来聊一聊,普通索引和唯一索引的使用场景, 以及为什么说推荐大家优先使用普通索引…...

Spring Cloud alibaba之Feign
JAVA项目中如何实现接口调用?HttpclientHttpclient是Apache Jakarta Common下的子项目,用来提供高效的、最新的、功能丰富的支持Http协议的客户端编程工具包,并且它支持HTTP协议最新版本和建议。HttpClient相比传统JDK自带的URL Connection&a…...
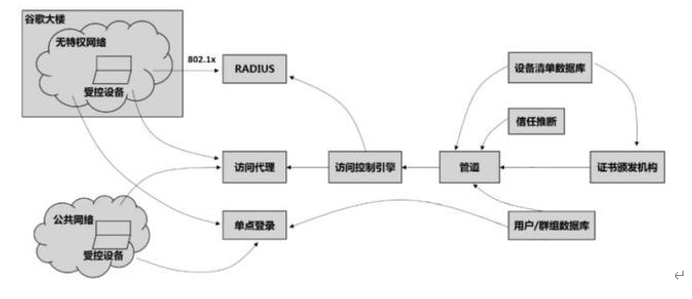
零信任-Google谷歌零信任介绍(3)
谷歌零信任的介绍? "Zero Trust" 是一种网络安全模型,旨在通过降低网络中的信任级别来防止安全威胁。在零信任模型中,不论请求来自内部网络还是外部网络,系统都将对所有请求进行详细的验证和审核。这意味着每次请求都需…...
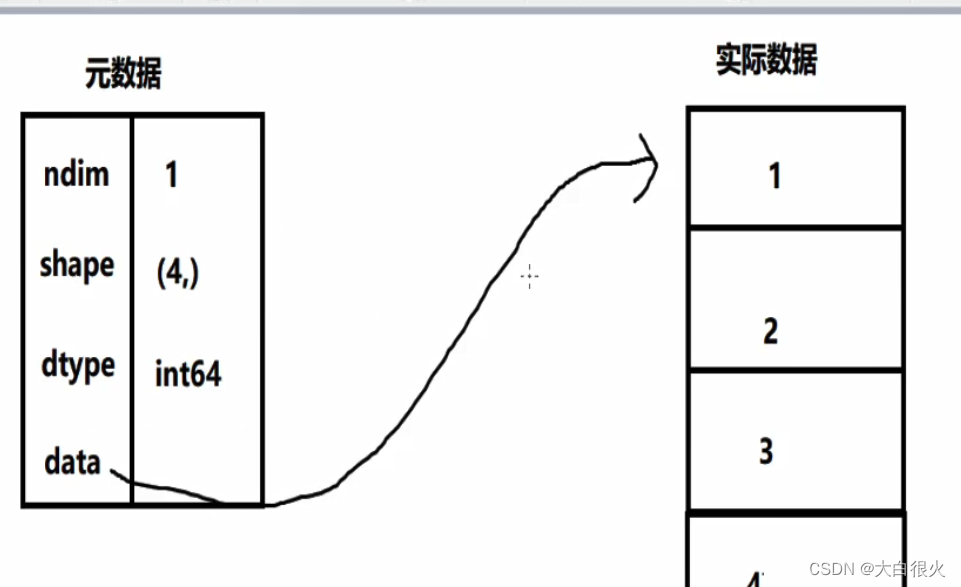
Numpy基础——人工智能基础
文章目录一、Numpy概述1.优势2.numpy历史3.Numpy的核心:多维数组4.numpy基础4.1 ndarray数组4.2 内存中的ndarray对象一、Numpy概述 1.优势 Numpy(Nummerical Python),补充了Python语言所欠缺的数值计算能力;Numpy是其它数据分析及机器学习库的底层库&…...

电商仓储与配送云仓是什么?
仓库是整个供给链的关键局部。它们是产品暂停和触摸的点,耗费空间和时间(工时)。空间和时间反过来也是费用。经过开发数学和计算机模型来微调仓库的规划和操作,经理能够显著降低与产品分销相关的劳动力本钱,进步仓库空间应用率,并…...

【零基础入门前端系列】—HTML介绍(一)
【零基础入门前端系列】—HTML介绍(一) 一、什么是HTML HTML是用来描述网页的一种语言HTML指的是超文本标记语言:HyperText Markup LanguageHTML不是一种编程语言,而是一种超文本标记语言,标记语言是一套标记标签(ma…...

Elasticsearch索引库和文档的相关操作
前言:最近一直在复习Elasticsearch相关的知识,公司搜索相关的技术用到了这个,用公司电脑配了环境,借鉴网上的课程进行了总结。希望能够加深自己的印象以及帮助到其他的小伙伴儿们😉😉。 如果文章有什么需要…...

使用Python,Opencv检测图像,视频中的猫
使用Python,Opencv检测图像,视频中的猫🐱 这篇博客将介绍如何使用Python,OpenCV库附带的默认Haar级联检测器来检测图像中的猫。同样的技术也可以应用于视频流。这些哈尔级联由约瑟夫豪斯(Joseph Howse)训练…...

浅谈域名和服务器集约化管理的误区
一个正常的网站通常由域名、网站程序、服务器三个部分组成,网站程序由单位开发设计,而域名和服务器则需要租用购买,那么域名和服务器之间的关系是什么?如何实现域名和服务器的有效管理呢? 服务器和域名的关系 服务器…...

迪赛智慧数——柱状图(正负条形图):20212022人才求职最关注的因素
效果图从近两年职场跳槽方向看,相比此前人们对高薪大厂趋之若鹜,如今职场人更关注业务前景。根据相关数据显示,职场人求职最关注的因素中,“薪资福利”权重下降,“个人发展”权重上升,“业务前景”首次进入…...

网络安全-黑帽白帽红客与网络安全法
网络安全-黑帽白帽红客与网络安全法 本章内容较少,因为刚开端。 黑客来源于hacker 指的是信息安全里面,能够自由出入对方系统,指的是擅长IT技术的电脑高手 黑帽黑客-坏蛋,研究木马的,找漏洞的,攻击网络或者…...

Xpath元素定位之同级节点,父节点,子节点
XPath学习:轴(8)——following-siblingXPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 同时被构建于 XPath 表达之上。推荐一个挺不错的网站:htt…...

Sora 2如何“唤醒”3D Gaussian Splatting?:从神经辐射场到毫秒级动态场景生成的4层技术跃迁解析
更多请点击: https://intelliparadigm.com 第一章:Sora 2与3D Gaussian Splatting融合的范式革命 传统视频生成模型受限于体素网格或NeRF隐式表示的计算开销与几何保真度瓶颈,而Sora 2通过引入时空一致性token压缩机制,与3D Gaus…...

C#元组类型简介
元组是 C# 7.0 引入的轻量级数据结构,用于临时组合多个值,无需定义专门的类或结构。 元组是有序的数据结构,成员按声明/创建时的顺序排列。(这里的元组只指值元组)元组类型在C#7.0前是有一个专门的内置类型,…...

JPlag代码抄袭检测:17种编程语言的智能原创守护者
JPlag代码抄袭检测:17种编程语言的智能原创守护者 【免费下载链接】JPlag State-of-the-Art Source Code Plagiarism & Collusion Detection. Check for plagiarism in a set of programs. 项目地址: https://gitcode.com/gh_mirrors/jp/JPlag 在数字化教…...

AI时代算力、模型与安全的三角博弈:从Nvidia生态到工程实践
1. 项目概述:当算力、智能与安全交织的时代最近和几个在芯片设计、大模型应用以及安全服务公司工作的朋友聊天,大家不约而同地都聊到了一个话题:我们正处在一个由Nvidia芯片驱动的AI浪潮之巅,但这场盛宴似乎并非没有天花板。一方面…...

RAD-NeRF:面向实时人像合成的神经辐射场高效架构
1. 项目概述:当NeRF遇上实时人像,RAD-NeRF到底在解决什么问题?我第一次看到“Efficient NeRFs for Real-Time Portrait Synthesis (RAD-NeRF)”这个标题时,手边正调试一个跑在RTX 4090上的标准NeRF模型——单帧渲染耗时23秒&#…...

新手也能看懂的CrackMe逆向实战:从查壳到用OD改跳转,一步步带你破解
新手也能看懂的CrackMe逆向实战:从查壳到用OD改跳转,一步步带你破解 逆向工程就像拆解一个神秘的黑匣子,而CrackMe则是专门为练习破解设计的"玩具程序"。记得我第一次接触CrackMe时,面对满屏的汇编代码完全不知所措。本…...

小白程序员必看:收藏这份AI黑话指南,轻松入门大模型世界!
本文用大白话解释了AI领域几个核心概念:AI是总称,LLM是推理模型,Agent能独立执行任务,MCP是标准化接口,Skills是技能包。文章通过生活化比喻和实例,帮助读者理解这些概念如何协同工作,实现高效自…...

XUnity.AutoTranslator终极指南:5分钟破解Unity游戏语言障碍
XUnity.AutoTranslator终极指南:5分钟破解Unity游戏语言障碍 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 当你打开心爱的日系RPG游戏,却因为语言不通而无法理解剧情时ÿ…...
)
公交查询|智能公交|公交线路查询|基于SprinBoot+vue智能公交系统(源码+数据库+文档)
公交查询|智能公交|公交线路查询系统 目录 基于SprinBootvue智能公交系统 一、前言 二、系统设计 三、系统功能设计 1用户模块实现 2管理员服务端模块实现 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介…...

多渠道订单数据处理自动化,落地步骤与ERP打通方案 | 2026企业级智能体实战手册
在2026年的数字化转型深水区,企业面临的不再是“是否要自动化”的问题, 而是如何在高并发、多维度的全渠道业务压力下, 实现订单流、资金流与信息流的绝对同步。 传统的OMS(订单管理系统)与ERP(企业资源计划…...