(自用)机器学习python代码相关笔记
一些自存的机器学习函数和详细方法记录,欢迎指错。
前言:读取数据方法
import pandas as pd
import pandas as pddf = pd.read_csv('数据集.csv', header=0)
# header是从哪一行开始读起,一般是0,也可以取'infer'一、数据处理(基本)
数据编码:
from sklearn.preprocessing import LabelEncoder
用于为非数值数据编码
使用例子:
from sklearn.preprocessing import LabelEncoder #用于将分类变量转换为数字形式。
#对非数值类型数据编码
for i in df.columns: #遍历df中每一列if df[i].dtypes == "object": #若该列为非数值数据,则对其编码lable = LabelEncoder() #创建新的LabelEncoder()lable = lable.fit(df[i]) #训练LabelEncoder(),使其适用于数据df[i] = lable.transform(df[i].astype(str)) #将原数据用训练好的LabelEncoder()替换缺失值处理:
删除缺失值函数:pandas库里的dropna
df["year"] = df["year"].replace("N.V.", np.nan)
df = df.dropna(how='any')
#any表示只要有空缺就删除,还可选'all'也可以采用平均值/中位数/knn填补法:
from sklearn.impute import KNNImputer # sklearn自带knn填补模型"""
# 平均值填补
pj = np.nanmean(X_train, axis=0)
for i in range(X_train.shape[0]):for j in range(X_train.shape[1]):if math.isnan(X_train[i][j]):X_train[i][j] = pj[j]
for i in range(X_test.shape[0]):for j in range(X_test.shape[1]):if math.isnan(X_test[i][j]):X_test[i][j] = pj[j]"""
"""
# 中位数填补
zw = np.nanmedian(X_train, axis=0)
print(zw)
for i in range(X_train.shape[0]):for j in range(X_train.shape[1]):if math.isnan(X_train[i][j]):X_train[i][j] = zw[j]"""
# KNN填补
imputer = KNNImputer(n_neighbors=5)
X_train = pd.DataFrame(imputer.fit_transform(X_train))数据类型转换:
df['year'] = df['year'].astype(np.int64)
#将year这一列转化为int数据类型文本类型转数值:
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import CountVectorizerver = CountVectorizer()
X = ver.fit_transform(df['text']).toarray()二、标准化特征
from sklearn.preprocessing import StandardScaler
#用于标准化特征,使其均值为0,方差为1。
from imblearn.over_sampling import RandomOverSampler
#用于处理类别不平衡问题(长尾分布),随机增加少数类样本的数量。
下面是数据挖掘课一个处理长尾分布的实验中对长尾分布数据预处理的一部分
from sklearn.preprocessing import StandardScaler
from imblearn.over_sampling import RandomOverSampler
import pandas as pdros = RandomOverSampler(sampling_strategy='minority')
# 初始化RandomOverSampler,samping_strategy='minority'表示要增加少数类样本的数量
X, y = ros.fit_resample(X, y)
# 执行RandomOverSampler,平衡特征X和标签yscaler = StandardScaler()
# 初始化StandardScaler
X_standardized = scaler.fit_transform(X)
# 使用StandardScaler对X进行拟合并转换,返回标准化后的数据X_standardizedX_std = pd.DataFrame(X_standardized, columns = X.columns)
#使用pandas.DataFrame将标准化后的数据转换为数据框形式,并保留原始的列名三、train_test_split划分训练集测试集
from sklearn.model_selection import train_test_split
用于划分数据
from sklearn.model_selection import train_test_splitX = df.drop("region",axis=1)
# 将读取的处理好的数据去除特征行存入X中
y = df['region']
# 将特征行分开存入y中X_train, X_test, y_train, y_test = train_test_split(X_std, y, test_size=0.6, random_state=42)
#其中test_size表示划分比例,如值为0.6表示训练集占0.6
#random_state表示随机数,取的随机数相同那么划分也会一模一样四、一些机器学习模型(分类)
支持向量机(SCV):from sklearn.svm import SVC
K近邻:from sklearn.neighbors import KNeighborsClassifier
随机森林:from sklearn.ensemble import RandomForestClassifier
多层感知机(神经网络)(MLP):from sklearn.neural_network import MLPClassifier
高斯朴素贝叶斯:from sklearn.naive_bayes import GaussianNB
决策树:from sklearn.tree import DecisionTreeClassifier
梯度提升树:from xgboost import XGBClassifier
使用实例(都套这个模板就行):
from sklearn.ensemble import RandomForestClassifiermodel = RandomForestClassifier()model.fit(X_train, y_train)y_pred = model.predict(X_predict)在长尾分布实验中,我学到了一个对数据重加权的方法:使用class_weight参数
from sklearn.utils.class_weight import compute_class_weighty_uni = y["winery"].unique().ravel()classes = np.array(y_uni)
class_weights = compute_class_weight('balanced', classes=classes, y=y)
class_weight_dict = {0: class_weights[0], 1: class_weights[1]}model = RandomForestClassifier(class_weight=class_weight_dict)五、一些机器学习模型(回归)
决策树:from sklearn.tree import DecisionTreeRegressor
(别的把上面的Classifier改成Regressor应该就行了)
六、准确度计算
from sklearn.metrics import accuracy_score
计算准确度,前一个参数是实际结果,后一个参数是预测结果。
from sklearn.metrics import accuracy_scoreACC = accuracy_score(y_test, y_pred)七、画图方法
import matplotlib.pyplot as plt
比如要画出样本特征柱状图:
import matplotlib.pyplot as pltplt.figure(figsize=(15,5)) # 图的大小plt.subplot(121) # 分成两个图,121分别是三个参数,表示有1行表2列表(共两个表),现在取第1行表
df['type'].hist() # 生成‘type’的柱状图
plt.subplot(122) # 现在取第二行表
df['region'].hist() # 生成‘region’的柱状图相关文章:
机器学习python代码相关笔记)
(自用)机器学习python代码相关笔记
一些自存的机器学习函数和详细方法记录,欢迎指错。 前言:读取数据方法 import pandas as pd import pandas as pddf pd.read_csv(数据集.csv, header0) # header是从哪一行开始读起,一般是0,也可以取infer 一、数据处理&#…...

docker复现pytorch_cyclegan
1、安装docker 配置docker镜像 添加镜像源至docker engine 2、wsl2安装nvidia-docker 要在Ubuntu中安装NVIDIA Docker,需要满足以下条件: 确保主机已安装NVIDIA的CUDA驱动程序,并使用适用于您操作系统的正确版本。 wsl --update在Ubuntu…...

IDEA2024下安装kubernetes插件并配置进行使用
【1】安装插件 其实2024.2.3下默认已经安装了kubernetes插件,如果你发现自己IDEA中没有,在市场里面检索并下载即可。 【2】kubernetes配置 ① 前置工作 首先你要准备一个config文件和一个kubectl.exe 。 config文件类似如下: apiVersi…...
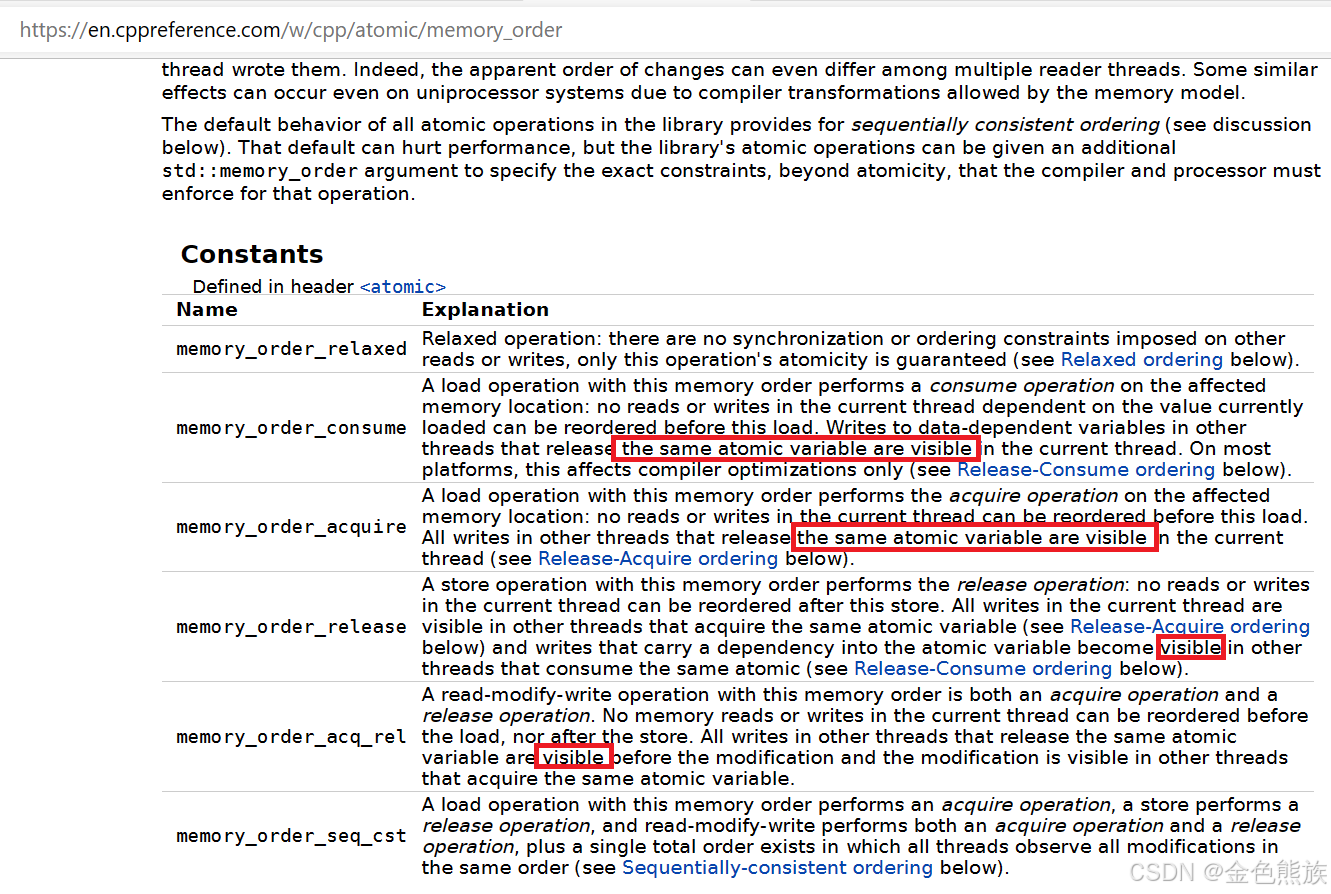
理解原子变量之二:从volatile到内存序-进一步的认识
目录 实例1 实例2 实例3 内存序中两个最重要的概念 补记 结论 实例1 看下面的例子:在vs2013中建立如下工程: #include <thread> #include <iostream> #include <chrono>bool done false;void worker(){std::this_thread::sle…...

DICOM标准:MR图像模块属性详解——磁共振成像(MR)在DICOM中的应用
目录 引言 磁共振成像(MR) 一、MR图像模块 二、MR图像属性描述 1、图像类型 (Image Type) 2、抽样每个象素 (Sampling per Pixel) 3、光度插值 (Photometric Interpretation) 4、位分配 (Bits Allocated) 结论 引言 数字成像和通信在医学(…...

Linux内核与用户空间
Linux内核与用户空间是Linux操作系统中的两个重要概念,它们各自承担着不同的功能和职责,并通过特定的机制进行交互。以下是对Linux内核与用户空间的详细解释: 一、Linux内核 定义:Linux内核是Linux操作系统的核心组件,…...

计算机网络-以太网小结
前导码与帧开始分界符有什么区别? 前导码--解决帧同步/时钟同步问题 帧开始分界符-解决帧对界问题 集线器 集线器通过双绞线连接终端, 学校机房的里面就有集线器 这种方式仍然属于共享式以太网, 传播方式依然是广播 网桥: 工作特点: 1.如果转发表中存在数据接收方的端口信息…...

找树根和孩子c++
题目描述 给定一棵树,输出树的根root,孩子最多的结点max以及他的孩子 输入 第一行:n(0<结点数<100),m(0<边数<200)。 以下m行;每行两个结点x和y…...

植物源UDP-糖基转移酶及其分子改造-文献精读75
植物源UDP-糖基转移酶及其分子改造 摘要 糖基化能够增加化合物的结构多样性,有效改善水溶性、药理活性和生物利用度,对植物天然产物的药物开发至关重要。UDP-糖基转移酶(UGTs)能够催化糖基从活化的核苷酸糖供体转移到受体形成糖苷键,植物中天然产物的糖基化修饰主要通过UGTs实…...

Redis中String 的底层实现是什么?
Redis中String 的底层实现是什么? Redis 是基于 C 语言编写的,但 Redis 的 String 类型的底层实现并不是 C 语言中的字符串(即以空字符 \0 结尾的字符数组),而是自己编写了 SDS(Simple Dynamic String&…...

像mysql一样查询es
先简单介绍一下这个sql查询,因为社区一直反馈这个Query DSL 实在是太难用了。大家可以感受一下下面这个es的查询。 GET /my_index/_search { “query”: { “bool”: { “must”: [ { “match”: { “title”: “search” } }, { “bool”: { “should”: [ { “te…...

SpringBoot中@Validated或@Valid注解校验的使用
文章目录 SpringBoot中Validated或Valid注解校验的使用1. 添加依赖2. 使用示例准备2-1 测试示例用到的类2-2 实体Dto,加入校验注解2-2 Controller 3. 示例测试4. Valid 和 Validated注解详解4-1 常用规则注解4-2 分组验证4-2-1 示例准备4-2-2 Controller接口4-2-3 P…...

HashMap为什么线程不安全?
一、Put操作(数据覆盖) HashMap底层是基于数组 链表(在 Java 8 以后,当链表长度超过一定阈值时会转换为红黑树)的数据结构。在多线程环境下,当多个线程同时对HashMap进行put操作时,可下面这种…...

类加载器及反射
目录 1.类加载器 1.1类加载【理解】 1.2类加载器【理解】 1.2.1类加载器的作用 1.2.2JVM的类加载机制 1.2.3Java中的内置类加载器 1.2.4ClassLoader 中的两个方法 2.反射 2.1反射的概述【理解】 2.2获取Class类对象的三种方式【应用】 2.2.1三种方式分类 2.2.2示例…...

aws boto3 下载文件
起因:有下载 aws s3 需求,但只有web 登录账号,有 id 用户名 密码,没有 boto3 的 key ID 经过分析,发现网页版有个地址会返回临时 keyID,playwright 模拟登录,用 page.on 监测返回数据ÿ…...

3DDFA-V3——基于人脸分割几何信息指导下的三维人脸重建
1. 研究背景 从二维图像中重建三维人脸是计算机视觉研究的一项关键任务。在虚拟现实、医疗美容、计算机生成图像等领域中,研究人员通常依赖三维可变形模型(3DMM)进行人脸重建,以定位面部特征和捕捉表情。然而,现有的方…...
)
求串长(不使用任何字符串库函数)
问题描述 编写一个程序,输入一个字符串,输出串的长度。 要求: (1)字符串长度不超过100个字符。 (2)不使用任何字符串库函数,建议使用堆串存储结构。 输入描述 输入一个字符串。 …...

第02章 MySQL环境搭建
一、MySQL的卸载 如果安装mysql时出现问题,则需要将mysql卸载干净再重新安装。如果卸载不干净,仍然会报错安装不成功。 步骤1:停止MySQL服务 在卸载之前,先停止MySQL8.0的服务。按键盘上的“Ctrl Alt Delete”组合键࿰…...

linux系统编程 man查看manual.stat
获取文件属性,(从inode结构体中获取) stat/lstat 函数 int stat(const char *path, struct stat *buf); 参数: path: 文件路径 buf:(传出参数) 存放文件属性,inode结构体…...

从网络到缓存:在Android中高效管理图片加载
文章目录 在Android应用中实现图片缓存和下载项目结构使用 代码解析关键功能解析1. 图片加载方法2. 下载图片3. 保存图片到缓存4. 文件名提取 总结 首先我们需要在配置AndroidManifest.xml里面添加 <uses-permission android:name"android.permission.INTERNET" …...

进化算法驱动机械爪设计优化:从原理到EvoClaw项目实践
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“EvoClaw”。光看这个名字,可能有点摸不着头脑,但点进去一看,发现这是一个关于“进化算法驱动的机械爪设计优化”的开源项目。简单来说,就是利用计算机…...

Steam成就管理器终极指南:3步修复错失的游戏成就
Steam成就管理器终极指南:3步修复错失的游戏成就 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager Steam Achievement Manager(SAM&a…...

Kubernetes部署Valheim游戏服务器:云原生技术赋能游戏运维实践
1. 项目概述:当维京英灵殿遇上容器编排如果你和我一样,既沉迷于《英灵神殿》(Valheim)里与好友共建家园、挑战上古巨兽的乐趣,又恰好是一名整天和Kubernetes(k8s)打交道的开发者或运维ÿ…...

RFM69无线通信进阶:从基础收发到可靠数据传输系统构建
1. 项目概述:从点对点收发迈向可靠通信在物联网和嵌入式开发领域,无线通信模块是连接物理世界与数字世界的桥梁。RFM69系列模块,特别是工作在433MHz或915MHz等Sub-GHz频段的RFM69HCW,因其出色的抗干扰能力、较远的传输距离以及相对…...

OpenClaw量化回测性能调优指南:从数据加载到并行计算的实战优化
1. 项目概述:从开源工具到性能调优的艺术最近在跟几个做量化交易的朋友聊天,他们都在为一个问题头疼:策略回测和实盘执行的速度。动辄几十个G的历史数据,复杂的因子计算,加上高频的模拟交易,一套流程跑下来…...

低多边形风出图总显廉价?揭秘Midjourney v6中--stylize、--polarize与--no纹理干扰的黄金配比公式
更多请点击: https://intelliparadigm.com 第一章:低多边形风出图的视觉认知陷阱与Midjourney v6风格断层解析 低多边形(Low-Poly)风格在AI图像生成中常被误认为“简约即可控”,实则构成一类典型的视觉认知陷阱&#…...

PPO 原理与应用
1. PPO 在 RLHF 里到底是干什么的? 在 RLHF 里,我们通常已经有了一个经过 SFT 的模型。这个模型已经比较会回答问题了,但还不一定最符合人类偏好。 于是我们再训练一个 奖励模型 Reward Model,让它模仿人类判断: 这个回…...

FanControl终极指南:如何突破NVIDIA显卡风扇30%限制实现0 RPM静音控制
FanControl终极指南:如何突破NVIDIA显卡风扇30%限制实现0 RPM静音控制 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/Git…...

如何用FanControl快速解决电脑风扇噪音问题:完整免费指南
如何用FanControl快速解决电脑风扇噪音问题:完整免费指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending…...

从零开始通过Taotoken平台文档快速完成首个大模型API调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从零开始通过Taotoken平台文档快速完成首个大模型API调用 对于初次接触大模型API的开发者而言,面对众多模型厂商、复杂…...