算法深度剖析:前缀和
文章目录
- 前言
- 一、一维前缀和模板
- 二、二维前缀和模板
- 三、寻找数组的中心下标
- 四、除自身以外数组的乘积
- 五、和为 K 的子数组
- 六、和可被 K 整除的子数组
- 七、连续数组
- 八、矩阵区域和
前言
本章将深度剖析前缀和,以及总结前缀和模板。
前缀和是一种在算法和数据处理中的重要技巧,特别适合解决连续子数组求和的问题。通过构建一个前缀和数组,我们可以快速查询任意连续区间的和,从而在一定程度上优化时间复杂度。
基本原理
前缀和的核心思想是预先计算数组的前缀和,使得区间求和可以在常数时间内完成。假设有一个数组 ( arr ),其前缀和数组定义如下:
- 设 ( prefix[i] ) 表示从数组起点到位置 ( i ) 的元素之和。
- 因此,前缀和数组 ( prefix ) 可以定义为:
[
prefix[i] = arr[0] + arr[1] + \dots + arr[i]
]
计算任意区间和 ( arr[l] + arr[l+1] + \dots + arr[r] ) 可以通过前缀和快速得到:
[
arr[l] + arr[l+1] + \dots + arr[r] = prefix[r] - prefix[l-1]
]
其中, ( prefix[r] ) 是从 ( arr[0] ) 到 ( arr[r] ) 的和,减去从 ( arr[0] ) 到 ( arr[l-1] ) 的和就得到了区间 ( [l, r] ) 的和。
例子
假设有数组 ( arr = [1, 2, 3, 4, 5] ),构建前缀和数组 ( prefix ) 如下:
- ( prefix[0] = 1 )
- ( prefix[1] = 1 + 2 = 3 )
- ( prefix[2] = 1 + 2 + 3 = 6 )
- ( prefix[3] = 1 + 2 + 3 + 4 = 10 )
- ( prefix[4] = 1 + 2 + 3 + 4 + 5 = 15 )
那么,求区间和 ( arr[1] + arr[2] + arr[3] ) 就可以通过前缀和数组计算:
[
arr[1] + arr[2] + arr[3] = prefix[3] - prefix[0] = 10 - 1 = 9
]
时间复杂度
- 构建前缀和数组的时间复杂度为 ( O(n) ),其中 ( n ) 是数组的长度。
- 一旦构建好前缀和数组,查询任意区间的和的时间复杂度为 ( O(1) )。
前缀和技术通常用于快速解决子数组求和、二维区域求和等问题。

一、一维前缀和模板
【模板】前缀和


#include <iostream>
using namespace std;
#include<vector>
typedef long long LL;int n,q;int main()
{cin >> n >> q;vector<LL> arr(n + 1);for (int i = 1; i <= n; i++){cin >> arr[i];}//定义前缀和数组vector<LL> dp(n + 1);for (int i = 1; i <= n; i++){dp[i] = dp[i - 1] + arr[i];}//使用前缀和数组while (q--){LL l, r;cin >> l >> r;cout << dp[r] - dp[l - 1] << endl;}return 0;
}
二、二维前缀和模板
【模板】二维前缀和


#include <iostream>
using namespace std;#include<vector>
typedef long long LL;int main()
{int n, m, q;cin >> n >> m >> q;//初始化原始数据vector<vector<LL>> arr(n + 1, vector<LL> (m + 1));for (int i = 1; i <= n; i++){for (int j = 1; j <= m; j++){cin >> arr[i][j];}}//定义前缀和数组vector<vector<LL>> dp(n + 1, vector<LL> (m + 1));for (int i = 1; i <= n; i++){for (int j = 1; j <= m; j++){dp[i][j] = dp[i - 1][j] + dp[i][j - 1] + arr[i][j] - dp[i - 1][j - 1];}}//使用前缀和数组while (q--){LL x1, y1, x2, y2;cin >> x1 >> y1 >> x2 >> y2;cout << dp[x2][y2] - dp[x2][y1 - 1] - dp[x1 - 1][y2] + dp[x1 - 1][y1 - 1] << endl;}return 0;
}
三、寻找数组的中心下标
寻找数组的中心下标


算法思路:
根据中心下标的定义,除中心下标元素外,该元素左边的「前缀和」应等于右边的「后缀和」。
- 因此,可以先预处理两个数组,一个表示前缀和,另一个表示后缀和。
- 然后,用一个
for循环枚举可能的中心下标,判断每个位置的前缀和和后缀和是否相等,如果相等,则返回该下标。
class Solution {
public:int pivotIndex(vector<int>& nums) {int n = nums.size();//构建前缀和vector<int> dp_first(n);dp_first[0] = 0;for (int i = 1; i < n; i++){dp_first[i] = dp_first[i - 1] + nums[i - 1];}//构建后缀和vector<int> dp_end(n);dp_end[n - 1] = 0;for (int i = n - 2; i >= 0; i--){dp_end[i] = dp_end[i + 1] + nums[i + 1];}//使用前缀和for (int i = 0; i < n; i++){if (dp_first[i] == dp_end[i])return i;}return -1;}
};
四、除自身以外数组的乘积
除自身以外数组的乘积

算法思路:
题目要求不能使用除法,并要求在 O ( N ) O(N) O(N) 时间复杂度内完成,排除了暴力解法和计算数组乘积后除以单个元素的方法。
分析可知,每个位置的最终结果 ret[i] 可以分为两部分:
- 前缀积部分:
nums[0] * nums[1] * ... * nums[i - 1] - 后缀积部分:
nums[i + 1] * nums[i + 2] * ... * nums[n - 1]
可以利用前缀和的思想,定义两个数组 post 和 suf,分别存储两部分信息:
post:表示i位置之前所有元素的前缀乘积,即[0, i - 1]区间的乘积。suf:表示i位置之后所有元素的后缀乘积,即[i + 1, n - 1]区间的乘积。
最后,根据 post 和 suf 计算出每个位置的最终结果。

class Solution {
public:vector<int> productExceptSelf(vector<int>& nums) {int n = nums.size();//构建前缀积vector<int> dp_first(n);dp_first[0] = 1;for (int i = 1; i < n; i++){dp_first[i] = dp_first[i - 1] * nums[i - 1];}//构建后缀积vector<int> dp_end(n);dp_end[n - 1] = 1;for (int i = n - 2; i >= 0; i--){dp_end[i] = dp_end[i + 1] * nums[i + 1];}//使用前后缀积vector<int> answer(n);for (int i = 0; i < n; i++){answer[i] = dp_first[i] * dp_end[i];}return answer;}
};
五、和为 K 的子数组
和为 K 的子数组

(将前缀和存入哈希表):
算法思路:
设 i 为数组中的任意位置,sum[i] 表示 [0, i] 区间内所有元素的和。
- 我们需要找到“以
i为结尾且和为k的子数组”,这等价于找出所有可能的起始位置x1, x2, x3...,使得[x, i]区间的和为k。 - 此时,
[0, x]区间的和应为sum[i] - k。
因此,问题转化为:
- 找出
[0, i - 1]区间内有多少前缀和等于sum[i] - k。
无需真正初始化前缀和数组,因为我们只关注 i 位置之前,前缀和为 sum[i] - k 的次数。我们可以使用一个哈希表,在计算当前位置的前缀和时,同时记录每个前缀和出现的次数。

class Solution {
public:int subarraySum(vector<int>& nums, int k) {// 哈希表模拟前缀和数组unordered_map<int, int> hash;hash[0] = 1;//使用前缀和数组int sum = 0, ret = 0;for (auto e : nums){sum += e;if (hash.count(sum - k)) ret += hash[sum - k];hash[sum]++;}return ret;}
};
六、和可被 K 整除的子数组
和可被 K 整除的子数组



本题需要的前置知识:
-
同余定理:
若(a - b) % n == 0,则a % n == b % n。也就是说,如果两个数之差能被n整除,那么这两个数对n取模的结果相同。
例如,(26 - 2) % 12 == 0,所以26 % 12 == 2 % 12 == 2。 -
C++ 中负数取模结果的处理:
- 在 C++ 中,负数取模的结果会保留负号,例如
-1 % 3 = -1。 - 为防止负数结果影响,常用
(a % n + n) % n确保结果为正,例如:-1 % 3 = (-1 % 3 + 3) % 3 = 2。
- 在 C++ 中,负数取模的结果会保留负号,例如
算法思路:
此题与 LeetCode 560 题“和为 K 的子数组”思路类似。
设 i 为数组中的任意位置,sum[i] 表示 [0, i] 区间内的和。
- 要找出“以
i为结尾、和可被k整除的子数组”,需要找到所有起点x1, x2, x3...使得[x, i]的和能被k整除。 - 假设
[0, x - 1]的和为a,[0, i]的和为b,则有(b - a) % k == 0。 - 根据同余定理,[0, x - 1] 区间和 [0, i] 区间的前缀和同余。因此问题变成:
- 找到
[0, i - 1]中前缀和的余数等于sum[i] % k的个数。
- 找到
无需初始化前缀和数组,只需用一个哈希表记录每种前缀和的出现次数,同时计算当前位置的前缀和。
class Solution {
public:int subarraysDivByK(vector<int>& nums, int k) {// 哈希表模拟前缀和数组unordered_map<int,int> hash;hash[0] = 1;//使用前缀和数组int sum = 0, ret = 0;for (auto e : nums){sum += e;int r = (sum % k + k) % k;if (hash.count(r)) ret += hash[r];hash[r]++;}return ret;}
};
七、连续数组
连续数组

算法思路:
稍作转换,这道题可以化为经典问题:
- 本题需要找一个连续区间,使得 0 和 1 出现的次数相同。
- 将 0 视为 -1,1 视为 1,问题就转化为找一个区间,使其和等于 0。
这样问题与 LeetCode 560 题“和为 K 的子数组”思路相似。
设 i 为数组中任意位置,用 sum[i] 表示 [0, i] 区间内所有元素的和。我们希望找到最大长度的“以 i 为结尾、和为 0 的子数组”,这需要找到从左至右第一个位置 x1 使得 [x1, i] 的和为 0。此时 [0, x1 - 1] 区间的和等于 sum[i]。因此问题变成:
- 找到
[0, i - 1]区间内首次出现sum[i]的位置即可。
我们无需真正初始化一个前缀和数组,因为只关心 i 位置之前,首次出现等于 sum[i] 的前缀和位置。只需一个哈希表,在计算当前位置前缀和的同时,记录该前缀和的首次出现位置。

class Solution {
public:int findMaxLength(vector<int>& nums) {// 哈希表模拟前缀和数组unordered_map<int, int> hash;hash[0] = -1; // 使用前缀和数组int sum = 0, ret = 0;for (int i = 0; i < nums.size(); i++){sum += nums[i] == 0 ? -1 : 1;if (hash.count(sum)) ret = max(ret, i - hash[sum]);else hash[sum] = i;} return ret;}
};
八、矩阵区域和
矩阵区域和

算法思路:
这道题主要是二维前缀和的基本应用,关键在于填写结果矩阵时,找到原矩阵对应区域的「左上角」和「右下角」坐标(建议画图理解)。
- 左上角坐标:
x1 = i - k,y1 = j - k,为了不超出矩阵范围,需要对 0 取max,修正后的坐标为:x1 = max(0, i - k),y1 = max(0, j - k)。 - 右下角坐标:
x2 = i + k,y2 = j + k,同理,为避免超出矩阵范围,需要对m - 1和n - 1取min,修正后的坐标为:x2 = min(m - 1, i + k),y2 = min(n - 1, j + k)。
最后将修正后的坐标代入二维前缀和的计算公式即可(注意下标的映射关系)。

class Solution {
public:vector<vector<int>> matrixBlockSum(vector<vector<int>>& mat, int k) {// 构建二维前缀和int n = mat.size(), m = mat[0].size();vector<vector<int>> dp(n + 1, vector<int> (m + 1));for (int i = 1; i <= n; i++){for (int j = 1; j <= m; j++){dp[i][j] = dp[i - 1][j] + dp[i][j - 1] + mat[i - 1][j - 1] - dp[i - 1][j - 1];}} //使用二维前缀和vector<vector<int>> answer(n, vector<int> (m));for (int i = 0; i < n; i++){for (int j = 0; j < m; j++){int a, b, c, d;a = i - k < 0 ? 1 : i - k + 1;b = j - k < 0 ? 1 : j - k + 1;c = i + k >= n ? n : i + k + 1;d = j + k >= m ? m : j + k + 1;answer[i][j] = dp[c][d] - dp[c][b - 1] - dp[a - 1][d] + dp[a - 1][b - 1];}}return answer;}
};

相关文章:
算法深度剖析:前缀和
文章目录 前言一、一维前缀和模板二、二维前缀和模板三、寻找数组的中心下标四、除自身以外数组的乘积五、和为 K 的子数组六、和可被 K 整除的子数组七、连续数组八、矩阵区域和 前言 本章将深度剖析前缀和,以及总结前缀和模板。 前缀和是一种在算法和数据处理中…...

【双目视觉标定】——1原理与实践
0 前言 双目视觉定位是目前机器(机器人)等领域中使用得非常广泛的视觉定位技术,双目视觉是模拟人的视觉系统利用两个不同位置的摄像头的视差来确定物体的位置。由于有需要采集两个摄像头的图像共同参与计算,所以双目相机装配要求…...
)
Java学习笔记(十二)
Mysql explain Extra MySQL的EXPLAIN语句是优化数据库查询的重要手段,其中的Extra列包含了不适合在其他列中显示但十分重要的额外信息。以下是对Extra列的详细介绍及举例: 一、Using filesort 解释:表示MySQL会对数据使用一个外部的索引排序…...

《Java 实现希尔排序:原理剖析与代码详解》
目录 一、引言 二、希尔排序原理 三、代码分析 1. 代码整体结构 2. main方法 3. sort方法(希尔排序核心逻辑) 四、测试结果 一、引言 在排序算法的大家族中,希尔排序是一种改进的插入排序算法,它通过将原始数据分成多个子序…...

RDMA驱动学习(二)- command queue
为了实现用户对网卡硬件的配置,查询,或者执行比如create_cq等命令,mellanox网卡提供了command queue mailbox的机制,本节将以create_cq为例看下这个过程。 command queue(后续简称cmdq)是一个4K对齐的长度…...

H2 Database IDEA 源码 DEBUG 环境搭建
H2 Database IDEA 源码 DEBUG 环境搭建 基于最新的 version-2.3.230 拉取分支。 git remote add h2 https://github.com/h2database/h2database.git git fetch h2 git checkout -b version-2.3.230 version-2.3.230使用 # 启动 java -jar h2*.jar# H2 shell 方式使用 java …...
--http)
nginx系列--(三)--http
本文主要介绍http模块accept read流程,!!!请求对应的响应直接在read流程里就会返回给用户,而不需要通过write事件,和redis一样,基本都不通过eventloop write事件来发送响应给客户端,…...

通过Wireshark抓包分析,体验HTTP请求的一次完整交互过程
目录 一、关于Wireshark 1.1、 什么是Wireshark 1.2、下载及安装 二、HTTP介绍 2.1、HTTP请求过程介绍 2.2 、TCP协议基础知识 2.2.1、概念介绍 2.2.2、TCP协议的工作原理 2.2.3、三次握手建立连接 2.3.4、四次挥手断开连接 2.3、Wireshark抓包分析过程 2.3.1、三次握…...

Requestium:Python中的Web自动化新贵
文章目录 Requestium:Python中的Web自动化新贵背景:为何选择Requestium?Requestium是什么?如何安装Requestium?简单的库函数使用方法场景应用常见Bug及解决方案总结 Requestium:Python中的Web自动化新贵 背…...
2024版红娘金媒10.3婚恋相亲系统源码小程序(亲测)
1. 红娘服务 红娘服务模块是该系统的一大特色。专业红娘会通过分析用户的个人资料和偏好, 为用户提供精准的配对建议和个性化服务。用户可以预约红娘服务,通过红娘的介入,提升配对成功率。 2. 相亲活动 相亲活动模块用于组织和管理线下或线…...

k8s-实战——ES集群部署
文章目录 yaml文件es-pvc.yamles-svc.yamles-cluster-sts.yaml创建elasticsearch集群yaml文件 es-pvc.yaml 通过nfs服务进行新增pv并通过labels关联pvc前置准备需要提前准备pv的服务器以及挂在路径--- apiVersion: v1 kind: PersistentVolume metadata:name: nfs-es-pv-data-...
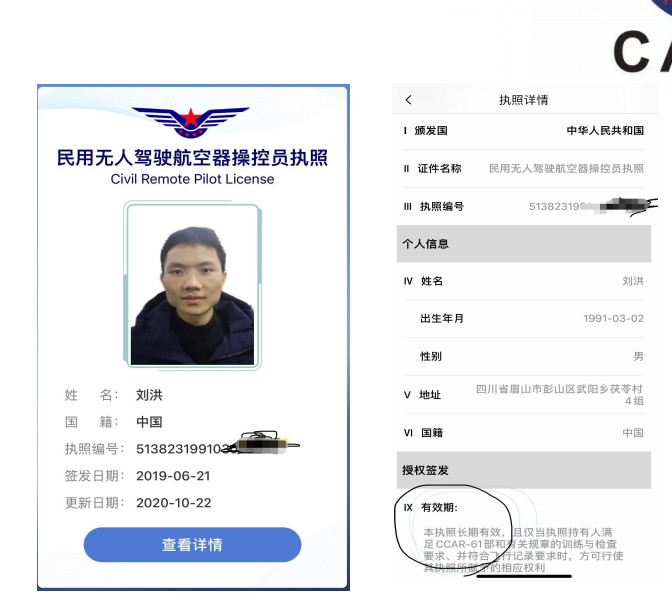
无人机的就业前景怎么样?
无人机的就业前景在当前及未来一段时间内都非常广阔。随着低空经济的蓬勃发展,无人机在农业、公安、测绘、交通、应急救援、影视拍摄等多个领域得到了广泛应用,对无人机操控员和相关专业人才的需求也随之急剧增加。 一、无人机操控员的就业前景 1. 高需…...

【学习】软件测试中V模型、W模型、螺旋模型三者介绍
在软件工程的星辰大海之中,存在着三种独特的航路图:V模型、W模型以及螺旋模型。它们分别以各自的方式描绘了软件开发与测试的不同旅程。 首先映入眼帘的是V模型——一个以垂直线条贯穿始终的简洁图形。这个模型如同一座倒立的“V”字形山峰,…...

Kafka存储机制大揭秘:从日志结构到清理策略的全面解析
文章目录 一、前言二、日志存储结构1.日志文件结构2.topic3.partition4.segment索引文件5.message结构6.message查找过程 三、存储策略1.顺序写2.页缓存3.零拷贝4.缓存机制 四、日志格式演变1.V0 版本2.V1 版本3.V0/V1消息集合4.V2 版本消息格式5.V2版本消息集合 五、偏移量维护…...

显卡服务器和普通服务器之间的区别有哪些?
显卡服务器也被称之为GPU服务器,显卡服务器与普通的服务器之间有着很明显的区别,下面就让我们共同来了解一下吧! 普通服务器的主要处理器通常都是配备的中央处理器,可以用于执行大部分通用计算任务和操作系统的管理;而…...

国产科技里程碑:自主算力走向世界,“表格编程”横空出世
近日,中国高科技领域迎来里程碑式的进展。 据安徽省量子计算工程研究中心官方消息,本源量子计算科技(合肥)股份有限公司(简称“本源量子”)成功向海外销售了其第三代自主超导量子计算机“本源悟空”的机时。…...

人工智能如何改变未来生活:从医疗到日常的全面升级
人工智能如何改变未来生活:从医疗到日常的全面升级 随着人工智能(AI)技术的进步,我们正逐渐看到它为各行各业带来的巨大变革。从医疗、企业到日常生活,AI通过简化流程、提高效率,甚至改善生活质量…...

第112届全国糖酒会(3月成都)正式官宣!
作为食品饮料行业内备受瞩目的年度盛事,全国糖酒商品交易会(简称“糖酒会”)一直是各大厂商与经销商展现企业风采、寻觅合作伙伴及签署订单的关键舞台。2024年10月31日,第111届全国糖酒商品交易会(秋糖)在深…...

NFT Insider #154:The Sandbox Alpha 4 第四周开启,NBA Topshot NFT 销量激增至新高
市场数据 加密艺术及收藏品新闻 NBA 赛季开幕推动 Topshot NFT 销量激增至新高 随着波士顿凯尔特人队和纽约尼克斯队在 10 月 22 日开启 2024-2025 NBA 赛季的序幕,NBA Topshot 的 NFT 销售量达到了自上赛季季后赛以来的最高水平。截止到 10 月 27 日的这一周&…...

【Canal 中间件】Canal 实现 MySQL 增量数据的异步缓存更新
文章目录 一、安装 MySQL1.1 启动 mysql 服务器1.2 开启 Binlog 写入功能1.2.1创建 binlog 配置文件1.2.2 修改配置文件权限1.2.3 挂载配置文件1.2.4 检测 binlog 配置是否成功 1.3 创建账户并授权 二、安装 RocketMQ2.1 创建容器共享网络2.2 启动 NameServer2.3 启动 Broker2.…...

AX-MES生产制造管理系统-总览
前言说起 MES 就不得不说 ERP,但是 ERP 大家基本上都知道,MES 就不一定了,常见的 ERP 系统包括 SAP、金蝶、用友等,ERP的流程相对来说也比较统一;MES就不同了,基本上熟悉业务流程的软件公司都可以开发并实施…...

DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉!
更多请点击: https://kaifayun.com 第一章:DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉! 当 DeepSeek 的系统设计辅助能力突然变“笨”——接口建议频繁失准、上下文感知错乱、生成代码无法通过基础编…...

全链路压测实战:双十一级别的流量,我是这样扛住的
作为一名在质量保障领域摸爬滚打多年的测试工程师,我深知传统的单接口压测在如今分布式架构下的无力感。当业务流量达到双十一这种脉冲式、高并发的级别时,任何一个非核心链路上的“短板”都可能引发系统性的雪崩。全链路压测不再是选择题,而…...
)
CentOS服务器上VNC连接失败?手把手教你排查并修复个人端口问题(附重启命令)
CentOS服务器VNC连接故障深度排查指南:从原理到实战当你在深夜赶项目时,突然发现VNC连接不上服务器,那种焦虑感我深有体会。去年参与半导体器件仿真项目时,我也曾被这个问题困扰整整两天。本文将分享一套经过实战检验的排查方法论…...

随机森林算法在儿童出行方式预测中的实战应用与优化
1. 项目概述:用随机森林预测孩子怎么上学做城市交通规划或者做家长接送方案的时候,你肯定想过一个问题:孩子们到底是怎么上学的?是走路、骑车、坐公交还是家长开车送?这个问题看似简单,背后却牵扯到城市规划…...

原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析
原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析 【免费下载链接】KCN-GenshinServer 基于GC制作的原神一键GUI多功能服务端。 项目地址: https://gitcode.com/gh_mirrors/kc/KCN-GenshinServer 你是否曾想过拥有一个完全由自己掌控的提瓦特大陆&am…...
 指针的常见操作)
C语言(12) 指针的常见操作
指针的常见操作指针变量,有两方面的意思:一个指针指向的内容(数据值,一级)指针变量本身存储的数据 (地址值)#include <stdio.h>int main() {int a 10;int b 0 ;int c 50;int *p NULL;int *q NULL;p &a; // 对指针变量本身进行修改// 对指…...

网安学习第24天 PHP安全——PHP反序列化
一、序列化与反序列化 1、序列化serialize() 序列化是什么?序列化就是把程序中的对象、数组、结构体等复杂数据,转换成可以存储或传输的格式。 简单说: 把“内存里的对象”变成“字符串/字节流”。 例如 PHP 中有一个对象: $u…...

告别KITTI!用TartanAir数据集在Unreal Engine+AirSim里复现那些让VSLAM算法“翻车”的雨天和黑夜
超越KITTI:用TartanAir数据集在虚拟极端环境中锤炼VSLAM算法当视觉SLAM算法在KITTI数据集上取得95%的准确率时,开发者们常常会松一口气——直到这些算法被部署到真实世界的雨夜街道上。突然之间,那些在阳光明媚的德国道路上表现优异的特征点检…...

Hitboxer:终极SOCD按键重映射解决方案,彻底解决游戏按键冲突问题
Hitboxer:终极SOCD按键重映射解决方案,彻底解决游戏按键冲突问题 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在激烈的游戏对战中,你是否曾因同时按下左右方向键而导致角色…...