神经网络进行波士顿房价预测
前言
前一阵学校有五一数模节校赛,和朋友一起参加做B题,波士顿房价预测,算是第一次自己动手实现一个简单的小网络吧,虽然很简单,但还是想记录一下。
题目介绍
波士顿住房数据由哈里森和鲁宾菲尔德于1978年Harrison and Rubinfeld1收集。它包括了波士顿大区每个调查行政区的506个观察值。1980年Belsley et al.2曾对此数据做过分析。
数据一共14列,每一列的含义分别如下:
英文简称 详细含义
CRIM 城镇的人均犯罪率
ZN 大于25,000平方英尺的地块的住宅用地比例。
INDUS 每个镇的非零售业务英亩的比例。
CHAS 查尔斯河虚拟变量(如果环河,则等于1;否则等于0)
NOX 一氧化氮的浓度(百万分之几)
RM 每个住宅的平均房间数
AGE 1940年之前建造的自有住房的比例
DIS 到五个波士顿就业中心的加权距离
RAD 径向公路通达性的指标
TAX 每一万美元的全值财产税率
PTRATIO 各镇的师生比率
B 计算方法为 $1000(B_k-0.63)^2$,其中Bk是按城镇划分的非裔美国人的比例
LSTAT 底层人口的百分比(%)
price 自有住房数的中位数,单位(千美元)
基于上述数据,请完成以下问题:
建立波士顿房价预测模型并对预测结果进行评价。
问题分析
首先这道题目的很明确,数据一共是 $506×14$ 的一个矩阵,有十三维的自变量,通过建立一个模型来拟合回归出最终的因变量 price,即户主拥有住房价值的中位数。这是一个回归问题,综合考虑有以下两个思路
通过各种回归算法(GradientBoostingRegressor,RandomForestRegressor,ExtraTreesRegressor,LinearRegressor等)结合全部或部分自变量来回归最终的price
建立前馈神经网络模型,根据通用逼近定理,我们可以拟合此回归模型。
我们对上述模型来进行实现并确定评估标准来对他们进行比较,选择最优的模型作为预测模型。
算法流程
传统的回归算法
自变量的选择
首先,考虑到数据集中13列自变量其中某一些可能和最终的房价并无强相关性,如果全部使用进行预测可能会对模型引入噪声,因此我们首先计算了房价price与各个自变量之间的相关系数 $r$ ,其中 $r$ 计算公式如下: $$ r = \frac{\sum(x_i-\bar{x})(y_i-\bar{y})}{\sqrt{\sum(x_i-\bar{x})^2\sum(y_i-\bar{y})^2}} $$ 其中 $x_i,y_i$ 为数据的每个分量,$\bar{x},\bar{y}$ 为数据的均值
该系数反映了两变量之间的相关性,$r$ 的绝对值介于 $[0,1]$ 区间内,$|r|$ 越接近1,表示两数据相关性越高,反之越低。计算后结果如下:

观察结果可以发现,在给定的十三个变量中,LSTAT 与 price 的相关程度最高$(|r|>0.7)$,其次是 RM 与PTRATIO $(|r|>0.5)$,再者是 TAX,INDUS,NOX $(|r|>0.4)$,除上述之外的七个变量都与 price 无较强的相关性,因此我们考虑使用六个相关性较强变量和十三个变量分别来对房价进行预测,并对他们进行对比,来寻找最优的回归模型。
模型的构建
首先我们使用了sklearn中自带的 boston 数据集,并将整体数据集随机划分为了训练集和测试集两部分,所占比例分别为80%和20%。
然后,我们利用Linear,Ridge,Lasso,ElasticNet,DecisionTree,GradientBoosting,RandomForest,ExtraTrees八种模型通过训练集对其进行训练。
接下来,我们利用训练集拟合得到的模型,使用测试集对其进行测试,与 Ground Truth 进行对比,并通过 $R^2$ 来评价该预测结果,其中 $R^2$ 计算公式如下,其是衡量回归模型好坏的常见指标,其值一般处于[0,1]之间,$R^2$ 越接近1,说明模型的性能越好。 $$ R^2 = 1-\frac{\sum(\hat{y_i}-y_i)^2}{\sum(\bar{y}-y_i)^2} $$
最后,考虑到模型的训练及预测可能具有偶然性,因此我们对于每一个模型进行20次训练及预测,利用20次的结果对其进行综合评价。利用得到的结果绘制 箱线图 所得结果如下:
分析最终结果可以发现,无论是使用六个相关性较强变量还是十三个变量来进行预测,GradientBoost(梯度提升决策树)回归模型都是最好的,此外,我们可以发现,利用十三个变量要比利用六个主要变量来进行预测比有着更好的效果。
前馈神经网络
模型的构建
近年来,神经网络理论不断发展,前馈神经网络(多层感知机、全连接神经网络)越来越多的被利用到数据分析中,因此考虑使用前馈神经网络来解决此问题。
前馈神经网络(全连接神经网络)的网络结构一般由三部分构成,输入层,隐藏层,以及输出层,输入层与输出层一般只有一层,隐藏层可有多层。中间利用非线性函数作为激活函数可以使得网络具有拟合非线性函数的能力
根据通用近似定理:
通用近似定理
对于具有线性输出层和至少一个使用“挤压”性质的激活函数的隐藏层组成的前馈神经网络,只要其隐藏层神经元的数量足够,它可以以任意精度来近似任何从一个定义在实数空间中的有界闭集函数。
只要隐藏层网络维度够高,就可以拟合任意的函数。
考虑到我们的模型有六维or十三维的数据输入,因此我们建立两层前馈神经网络,中间具有一层隐藏层,维度为1000维,激活函数使用Relu,Relu函数有以下优点:
Relu相比于传统的Sigmoid、Tanh,导数更加好求,反向传播就是不断的更新参数的过程,因为其导数不复杂形式简单,可以使得网络训练更快速。
此外,当数值过大或者过小,Sigmoid,Tanh的导数接近于0,Relu为非饱和激活函数则不存在这种现象,可以很好的解决梯度消失的问题
Relu函数及网络结构图如图所示:
$$ Relu:f(x) = max(0,x) $$
具体实现
利用流行的深度学习框架 Pytorch 来对模型进行实现。
首先,将数据集随机划分为训练集和测试集两部分,分别占80%和20%,并将其转化为Pytorch中的张量形式。
然后,利用MinMaxScaler对输入数据进行归一化,利用下列公式将其统一归一化为 $[0,1]$ 之间,以求模型能够更快的收敛。
$$ MinMaxScaler:x^{*} = \frac{x-min(x)}{max(x)-min(x)} $$
接下来,构建网络模型,利用 mseloss 作为损失函数,在训练过程中利用反向传播使其最终收敛为0。
$$ MseLoss = \frac{1}{2n}\sum||y(x)-a^L(x)||^2 $$
最后,我们设置网络的学习率为0.01,训练10000个epoch,发现其loss最终降低到0.3%左右,我们利用上文提到的 $R^2$ 对结果进行评估并与回归模型进行对比,通过观察图片可以发现,前馈神经网络相比于传统的回归模型有着更好的拟合效果, 20次预测得到的$R^2$平均值达到了0.95,此外中位数,最大值,最小值也要比回归模型更加优秀,因此我们采用前馈神经网络模型来对最后的房价进行预测。
最终预测
最终我们利用构建的前馈神经网络模型进行预测,利用测试集对其进行对比,绘制预测如下:
可以看到其中很多点都覆盖的很好,即预测准确。
通过理论对模型进行量化分析,计算预测的 $R^2$ $$ R^2 = 1-\frac{\sum(\hat{y_i}-y_i)^2}{\sum(\bar{y}-y_i)^2} = 1-0.01357 = 0.98643=98.643% $$ 可以发现 $R^2$ 十分接近1,说明回归模型性能良好,符合要求。
相关文章:
神经网络进行波士顿房价预测
前言 前一阵学校有五一数模节校赛,和朋友一起参加做B题,波士顿房价预测,算是第一次自己动手实现一个简单的小网络吧,虽然很简单,但还是想记录一下。 题目介绍 波士顿住房数据由哈里森和鲁宾菲尔德于1978年Harrison …...

C++builder中的人工智能(7)如何在C++中开发特别的AI激活函数?
在当今的AI开发中,人工智能模型正迅速增加。这些模型使用数学函数来执行和学习,以便在传播时优化最佳结果,或在反向传播时选择最佳解决方案。其中之一就是激活函数。也称为转移函数或阈值函数,它决定了神经元的激活值作为输出&…...

更改lvgl图片的分辨率(减少像素)达到减小内存占用的目的
lvgl的内存占比过大,更改图片的分辨率(减少像素)达到减小内存占用的目的,可以用更多的空间去开发其他的功能 -- 由于lvgl中图片占的内存过大,所以需要更改图片的分辨率(降低像素的方式) --注意…...

python的socket库的基本使用总目录
章节总目录 一、Python 实现UDP通讯的简单模型 二、Python 实现TCP通讯的简单模型 三、Python 实现TCP和UDP通讯代码的区别...

golang学习3
Go 语言之旅...
(详解+注释))
Python解力扣算法题(六)(详解+注释)
# 1.学校打算为全体学生拍一张年度纪念照。根据要求,学生需要按照 非递减 的高度顺序排成一行。 # 排序后的高度情况用整数数组 expected 表示,其中 expected[i] 是预计排在这一行中第 i 位的学生的高度(下标从 0 开始)。 # 给你一…...

【C++】继承和多态常见的面试问题
文章目录 继承笔试面试题1. 什么是菱形继承?菱形继承的问题是什么?2. 什么是菱形虚拟继承?如何解决数据冗余和二义性?3. 继承和组合的区别?什么时候用继承?什么时候用组合? 选择题 多态概念考察…...

入门网络安全工程师要学习哪些内容(详细教程)
🤟 基于入门网络安全/黑客打造的:👉黑客&网络安全入门&进阶学习资源包 大家都知道网络安全行业很火,这个行业因为国家政策趋势正在大力发展,大有可为!但很多人对网络安全工程师还是不了解,不知道网…...

【游戏引擎之路】登神长阶(十二)——DirectX11教程:If you‘re going through hell, keep going!
【游戏引擎之路】登神长阶(十二)——DirectX11教程:If youre going through hell, keep going! 2024年 5月20日-6月4日:攻克2D物理引擎。 2024年 6月4日-6月13日:攻克《3D数学基础》。 2024年 6月13日-6月20日&#x…...
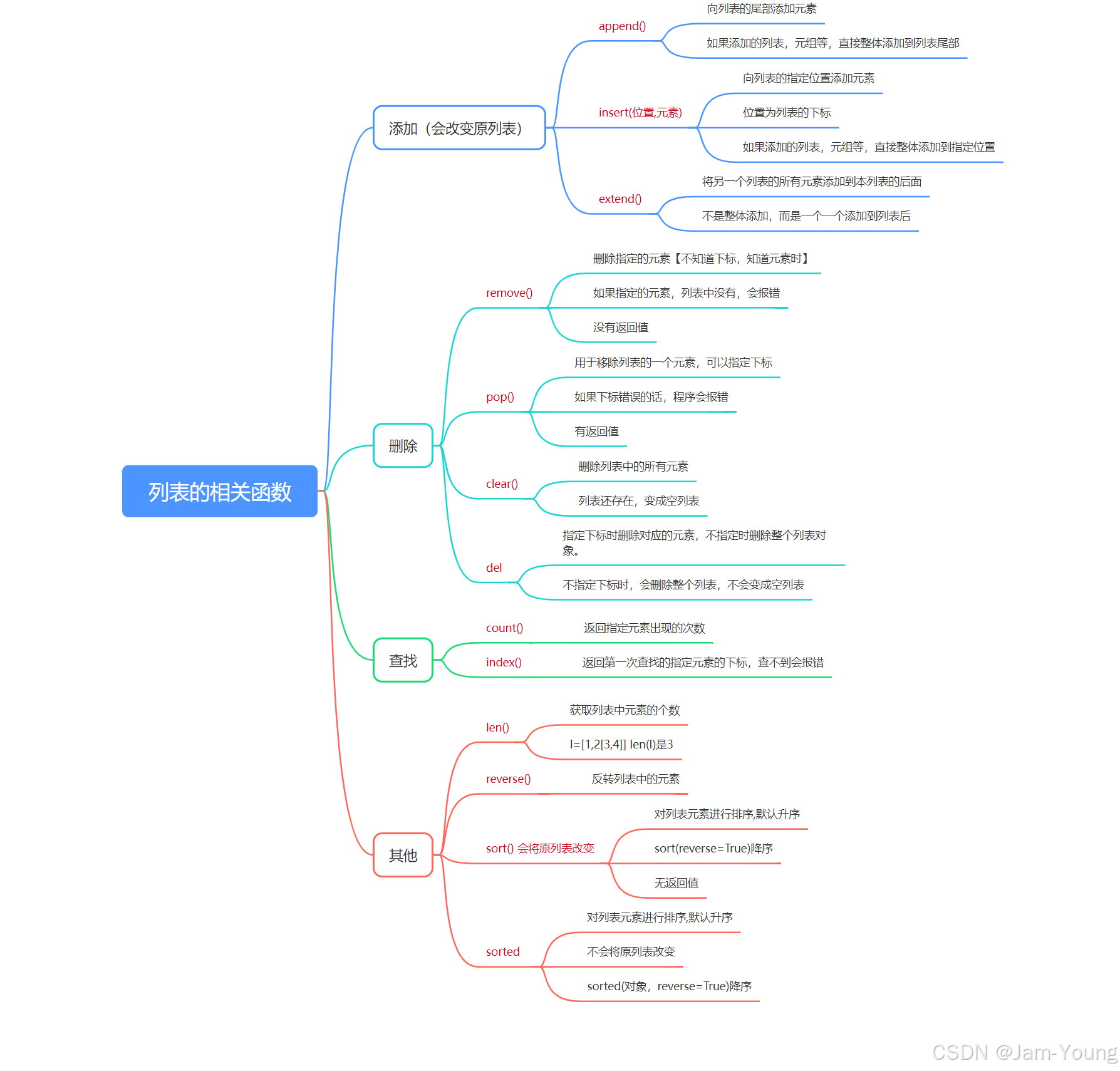
Python列表(一图秒了)
一、概念 所谓的列表是由一些列按照顺序存储的元素组成,区别于C语言中的数组,可以存储多种类型的数据,其中元素之间是没有任何关系的。 注意: 元素放在[]里面的,多个元素之间用 逗号 隔开列表的元素可以修改 定义 …...

雷池社区版 7.1.0 LTS 发布了
LTS(Long Term Support,长期支持版本)是软件开发中的一个概念,表示该版本将获得较长时间的支持和更新,通常包含稳定性、性能改进和安全修复,但不包含频繁的新特性更新。 作为最受欢迎的社区waf,…...
推荐一款功能强大的数据库开发管理工具:SQLite Expert Pro
SQLite Expert Professional是一个功能强大的工具,旨在简化SQLite3数据库的开发。 它是SQLite的一个功能丰富的管理和开发工具,旨在满足所有用户从编写简单SQL查询到开发复杂数据库的需求。 图形界面支持所有SQLite功能。 它包括一个可视化查询构建器&a…...

动态规划 之 路径问题 算法专题
一. 不同路径 不同路径 状态表示 dp[i][j] 表示走到[i][j]位置, 有几种不同的路径状态转移方程 以离[i][j] 最近的位置划分问题 1.从[i - 1][j] 到[i][j], 到[i][j]位置的不同路径数 就是和 到[i - 1][j]位置的不同路径数相同, 即dp[i][j] dp[i - 1][j] 2.从[i][j - 1] 到[i…...

从office套件接入GPT4谈自动化测试的前景
微软前几天发布了集成了GPT-4模型的office套件,从演示视频看,大概可以做这样一些事情 输入指令自动做表输入指令写邮件输入指定自动做ppt,而且一做就是好多页,挺震撼的 稍微了解了一下原理,大概流程是 用户发送prom…...

CentOS操作系统安装过程简介
以下是在CentOS(以CentOS 7为例)中使用Anaconda安装器的一般步骤: 1. 准备工作 - 首先,需要获取CentOS 7的安装介质,可以是光盘或者制作好的USB启动盘。然后将计算机设置为从对应的安装介质启动。 2. 启动安装程序 -…...

基于Multisim光控夜灯LED电路(含仿真和报告)
【全套资料.zip】光控夜灯LED电路设计Multisim仿真设计数字电子技术 文章目录 功能一、Multisim仿真源文件二、原理文档报告资料下载【Multisim仿真报告讲解视频.zip】 功能 1.采用纯数字电路,非单片机。 2.通过检测周围光线,光线暗且有声音时自动开灯…...

导师双选系统开发:Spring Boot技术详解
第一章 绪论 1.1 选题背景 如今的信息时代,对信息的共享性,信息的流通性有着较高要求,尽管身边每时每刻都在产生大量信息,这些信息也都会在短时间内得到处理,并迅速传播。因为很多时候,管理层决策需要大量信…...
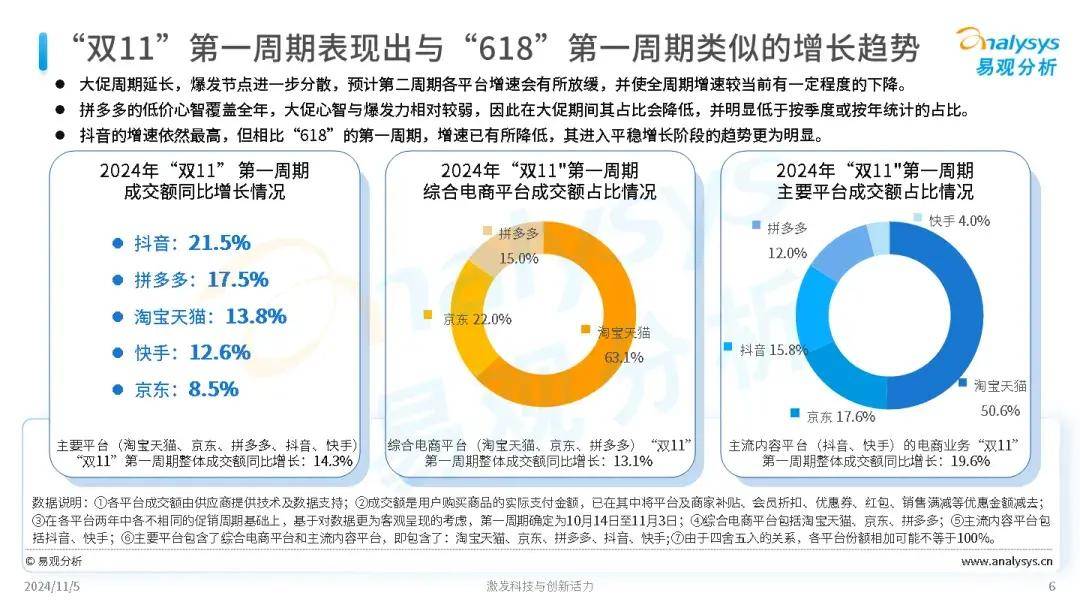
双11花了“一部手机钱”买手机壳的年轻人,究竟在买什么?
【潮汐商业评论/原创】 这个双十一,Elsa在天猫多了一笔新支出——手机壳。和大家都熟悉的“义乌制造”不同的是,她的手机壳支出单件就已经到了500块,加上配套的手机链、支架、卡包、耳机壳,总共1000多元,足够买一部学…...

rediss数据结构及其底层实现
Redis 是一个基于内存的高性能键值对数据库,它支持多种数据结构,每种数据结构都有其特定的底层实现。以下是Redis中一些主要数据结构及其底层实现: 字符串(String): Redis的字符串类型使用简单动态字符串&a…...

自动化测试中使用Pytest Fixture?推荐10种常见用法!
Pytest 是一个功能强大的 Python 测试框架,其中的Fixture 是 Pytest 中的一个重要功能。它允许你设置一些特定的测试环境或准备测试数据,这些环境和数据可以在多个测试用例中重复使用。通过使用fixture,你可以避免在每个测试函数中编写重复的…...

免费文档下载终极方案:如何优雅获取百度文库等30+平台资源
免费文档下载终极方案:如何优雅获取百度文库等30平台资源 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是为…...

代码优化的10个技巧:让你的代码既高效又优雅
对于软件测试从业者而言,编写高质量的测试代码是保障测试效率、提升测试可靠性的核心基础。无论是自动化测试脚本、测试工具开发还是测试框架搭建,臃肿、低效、可读性差的代码不仅会拖慢测试执行速度,还会增加缺陷排查的难度,提升…...
)
空气动力学计算 · 趋势图谱(学生学习版)
<!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>空气动力学计算 趋势图谱(学生学习版…...

Supermask:冻结权重+二值掩码的神经网络子结构发现方法
1. 什么是 Supermasks?——不是“超级面具”,而是神经网络里的“先天直觉” 你有没有试过教一个刚学会走路的孩子认苹果?你不需要从零开始教他光谱分析、细胞结构或者植物分类学,只要拿个红彤彤的苹果在他眼前晃一晃,再…...

python旅游分享点评网系统
目录同行可拿货,招校园代理 ,本人源头供货商项目概述核心功能技术栈扩展功能建议项目亮点项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货,招校园代理 ,本人源头供货商 项目概述 Python旅游分…...

python拼装模型商城销售管理系统
目录同行可拿货,招校园代理 ,本人源头供货商项目概述核心功能技术栈特色亮点适用场景项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货,招校园代理 ,本人源头供货商 项目概述 Python拼装模型商…...

如何永久保存微信聊天记录?5分钟掌握免费开源工具WeChatMsg
如何永久保存微信聊天记录?5分钟掌握免费开源工具WeChatMsg 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/…...

Spek音频频谱分析器:如何免费快速可视化音频频率的秘密世界
Spek音频频谱分析器:如何免费快速可视化音频频率的秘密世界 【免费下载链接】spek Acoustic spectrum analyser 项目地址: https://gitcode.com/gh_mirrors/sp/spek Spek是一款功能强大的开源音频频谱分析工具,能够将复杂的音频信号转换为直观的彩…...
3个步骤快速掌握Py Eddy Tracker:海洋中尺度涡旋识别与追踪的完整解决方案
3个步骤快速掌握Py Eddy Tracker:海洋中尺度涡旋识别与追踪的完整解决方案 【免费下载链接】py-eddy-tracker Eddy identification and tracking 项目地址: https://gitcode.com/gh_mirrors/py/py-eddy-tracker Py Eddy Tracker是一个专门用于海洋中尺度涡旋…...

Ender-3固件配置终极指南:5步简单快速性能优化
Ender-3固件配置终极指南:5步简单快速性能优化 【免费下载链接】Ender-3 The Creality3D Ender-3, a fully Open Source 3D printer perfect for new users on a budget. 项目地址: https://gitcode.com/gh_mirrors/en/Ender-3 Ender-3固件配置是解锁3D打印机…...