Me-LLaMA——用于医疗领域的新型开源大规模语言模型
摘要
大规模语言模型的出现是提高病人护理质量和临床操作效率的一个重大突破。大规模语言模型拥有数百亿个参数,通过海量文本数据训练而成,能够生成类似人类的反应并执行复杂的任务。这在改进临床文档、提高诊断准确性和管理病人护理方面显示出巨大的潜力。然而,像 ChatGPT 和 GPT-4 这样的大规模语言模型是封闭的,很难针对医疗保健领域所需的特定情况进行定制。
为解决这一问题,近年来开发了开源大规模语言模型。开源大规模语言模型是一种很有前景的解决方案,它提供了无限的访问权限,并可根据医疗保健领域的特定需求灵活定制。例如,LLaMA 模型是通用领域开源大规模语言模型的佼佼者,具有最先进的功能。但是,由于这些模型主要是在通用领域数据的基础上进行训练的,因此缺乏准确可靠的医疗应用所需的专业知识。
为了弥补这些不足,目前正在开发专门用于医疗保健的开源大规模语言模型,通过生物医学数据对其进行增强。然而,现有的研究,如 PMC-LaMA 和 Meditron,主要集中在生物医学领域,而且只评估问题解答(QA)任务。只有 GatorTronGPT 和 Clinical-LaMA 是例外。然而,由于缺乏教学协调以及模型和数据规模的限制,GatorTronGPT并未在各种临床环境中充分利用大规模语言模型,而 Clinical-LaMA 对临床文本的先验学习也很有限。此外,它还存在 "灾难性遗忘 "问题,即在整合新的医疗数据时,先前的知识会受到影响。
为了应对这些挑战,本文开发了一种新的大规模医学语言模型Me-LaMA,该模型可持续预训练 LLaMA2 模型、调整指令并纳入丰富的生物医学和临床数据。
这为研究医疗保健领域的大规模语言模型提供了一个全面的数据集,其中还包括一个大型预训练数据集、一个教学协调数据集和一个新的医疗评估基准 (MIBE)。
在使用 MIBE 进行的评估中,Me-LaMA 模型在零射、四射和监督学习方面的表现优于现有的开源大规模医学语言模型。通过针对特定任务的指令调整,Me-LaMA 模型在许多数据集上的表现优于 ChatGPT 和 GPT-4。
技术
Me-LaMA 是通过对 LLaMA2 的持续预研究和教学调整开发出来的。该过程包括 129B 标记样本和 214K 指示性研究,其中包括一般、生物医学和临床数据。
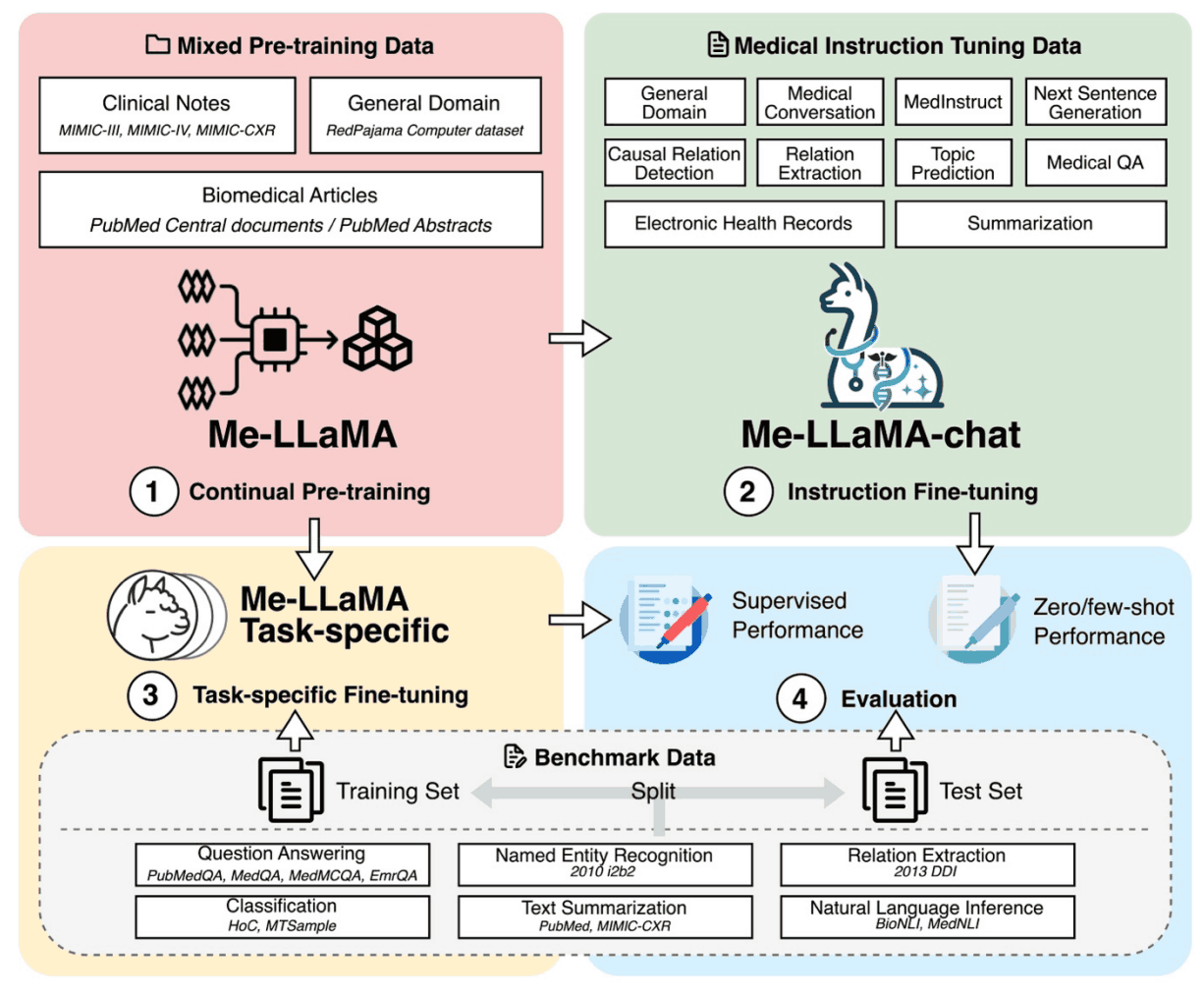
为使 LLaMA2 模型适用于医疗领域,我们创建了一个混合连续预训练数据集。该数据集包含 129B 标记,由生物医学文献、临床笔记和一般领域数据组成。这平衡了特定领域知识与广泛的上下文理解,减少了灾难性遗忘。
- 生物医学文献
- 它包含大量从 PubMed Central 和 PubMed Abstracts 收集的生物医学文献。
- 临床说明
- 使用 MIMIC-III、MIMIC-IV 和 MIMIC-CXR 中的匿名自由文本临床笔记来反映真实的临床场景和推理。
- 一般部门数据
- 为防止灾难性遗忘,我们重现了 LLaMA 研究前的数据,包括 RedPajama 数据集的一个子集。生物医学、临床和一般领域数据的比例为 15:1:4,重点放在医学领域,但也纳入了一般知识。
此外,我们还在开发一个新的医疗适应症调整数据集,以提高模型遵从指令的能力,并将其推广到各种医疗任务中。该数据集包含各种数据源,包括生物医学文献、临床笔记、临床指南、wikidoc、知识图谱和一般现场数据。数据集中的各种任务旨在完善模型准确处理和响应医疗信息的能力。最终数据集包含 214,595 个高质量样本,噪声(如空输入和响应)已被去除。
此外,医学领域的现有研究主要集中于质量保证任务的评估,而本文则引入了一个新的广泛评估基准,涵盖六项任务,即质量保证、独特表达提取(NER)、关系提取(RE)、分类(CF)、文本摘要(TS)和自然语言推理(NLI)。这些任务是这些任务包括从生物医学和临床领域精心挑选的 12 个数据集,提供了广泛的评估范围。我们还包括一般领域的质量保证数据 MMLU,以评估遗忘一般领域知识的问题。
该模型还在两种评估环境中进行了评估:情境学习(零拍和四拍学习)和监督学习,并与基线模型进行了比较,以评估其在不同任务中的性能和泛化能力。
实验结果
下表比较了 Me-LaMA 聊天模型和基线模型在各种 MIBE 任务中的零点性能。比较对象包括具有教学微调功能的大型语言模型,以提高遵从指令的能力,如 LLaMA2 聊天模型。
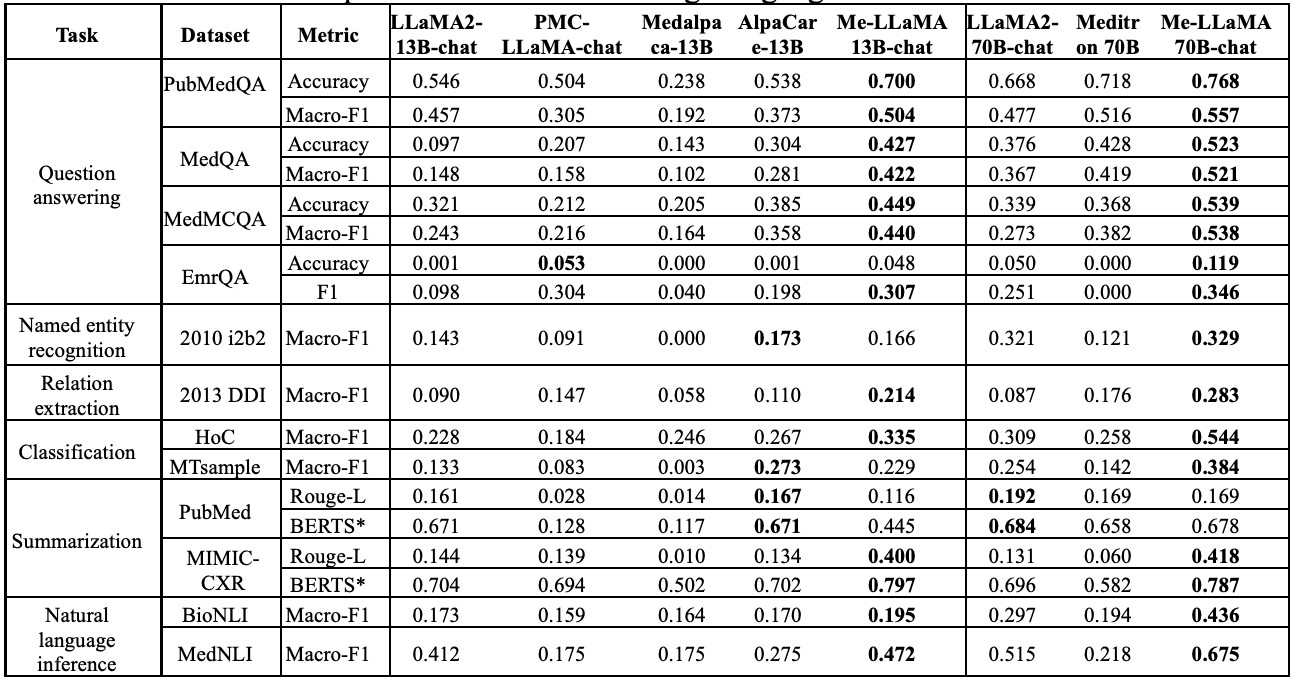
在具有 13B 参数的模型中,Me-LaMA 13B-chat 在几乎所有 12 个数据集中的表现都优于 LLaMA2 13B-chat 、PMC-LaMA-chat 和 Medalpaca 13B。唯一的例外是临床问答(QA)数据集 EmrQA,其准确率略有下降。此外,在 12 个数据集中,Me-LaMA 在 9 个数据集中的表现优于 AlpaCare-13B。
在具有 70B 参数的模型中,Me-LaMA 70B-chat 在所有 12 个数据集中的表现始终优于 Meditron 70B,在 11 个数据集中优于 LLaMA2-70B-chat。特别是在 PubMedQA 数据集中,Me-LaMA 70B-chat 的准确率比 LLaMA2-70B-chat 模型高出约 10%,Macro-F1 分数高出 8.0%。此外,Me-LaMA 13B-chat 在 12 个数据集中的 6 个数据集(包括 PubMedQA、MedQA、MedMCQA、2013 DDI、HoC 和 MIMIC-CXR)中的表现也优于 LLaMA2-70B-chat,其参数大小明显更大。而在另外三个数据集(包括 EmrQA、MTsample 和 MedNLI)中则具有竞争力。
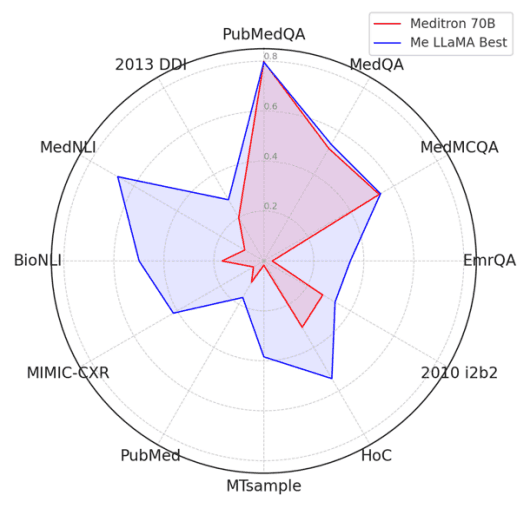
下图还比较了 Meditron 70B 和 Me-LLaMA 模型 Fewshot 的性能,Fewshot 是目前最先进的大型医学语言模型。该比较基于 PubMed Rouge-L 分数、三个 QA 数据集的准确度分数以及其他数据集的 F1 分数。由于 Meditron 遵循指令的能力有限,因此采用了 Fewshot 进行性能比较,对摘要数据集和数据集采用了一次拍摄法,而对其他数据集采用了五次拍摄法。结果,Me-LaMA 模型在 12 个数据集(不包括 PubMedQA)中的 11 个数据集上都取得了优异的性能。
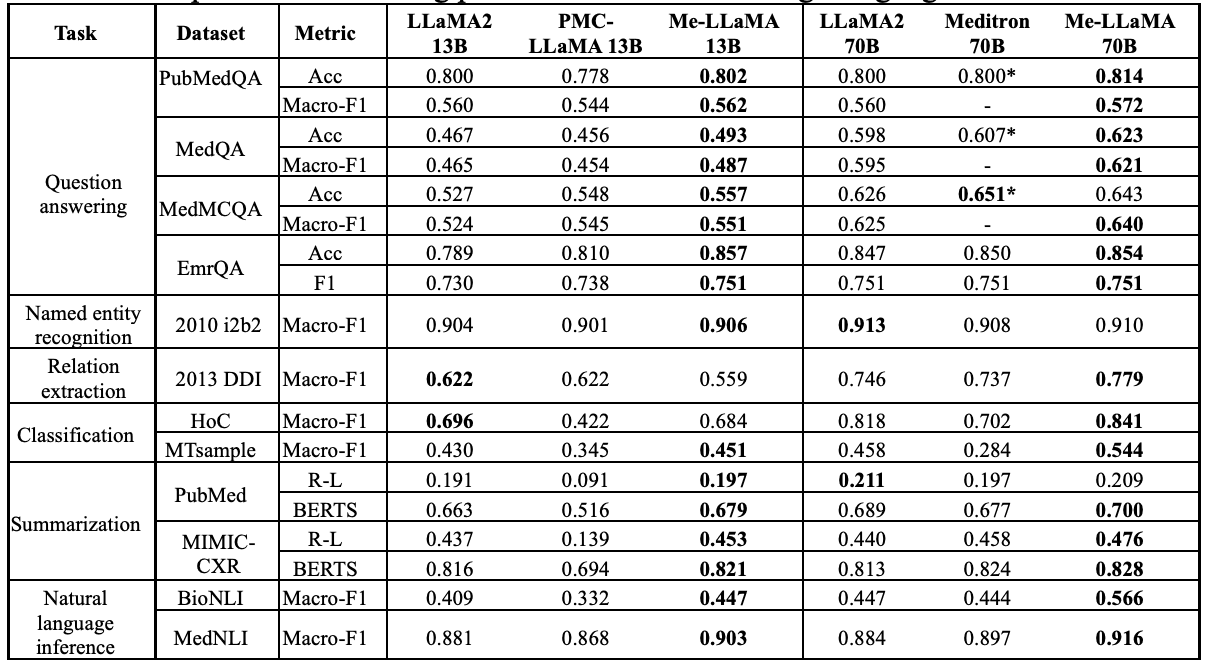
下表比较了 Me-LaMA 13/70B 基础架构模型与其他开源基础架构大规模语言模型在监督环境下的性能:在 12 个数据集中的 11 个数据集上,Me-LaMA 13B 模型的性能优于同等规模的医疗基础架构模型 PMC-LaMA 13B、在 10 个数据集(不包括 DDI 和 HoC)中的表现优于LLaMA2 13B。此外,在 12 个数据集中的 8 个数据集(PubMedQA、EmrQA、2010 i2b2、MTsample、PubMed、MIMIC-CXR、BioNLI 和 MedNLI),Me-LaMA 13B 模型与 LLaMA2 70B和 Meditron70B 相比也具有竞争力。就 70B 模型而言,与 LLaMA2 70B 和 Meditron 70B 相比,Me-LaMA 70B 在 12 个数据集中的 9 个数据集上取得了最佳性能(不包括 MedMCQA、2010 i2b2 和 PubMed)。
此外,下图还比较了 Me-LaMA 模型与 ChatGPT 和 GPT-4 在零拍摄和特定任务教学微调设置下的性能。由于隐私问题,向 ChatGPT 和 GPT-4 发送包含患者信息的临床数据集受到限制,因此使用了 8 个不受此限制的数据集(PubMedQA、MedQA、MedMCQA、HoC、MTsample、PubMed 和 BioNLI、2013 DDI)进行比较;三个 QA 数据集 ChatGPT 和 GPT-4 的结果参考 OpenAI 论文。
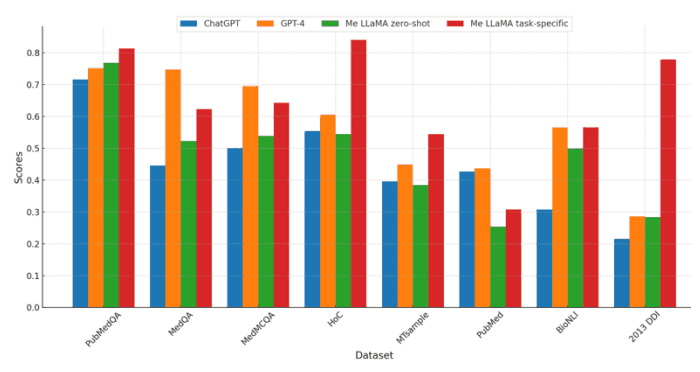
比较使用了汇总数据集 PubMed 的 Rouge-127 分数、三个 QA 数据集的准确率分数以及其他数据集的 Macro-F1 分数。通过特定任务指令调整,Me-LaMA 模型在八个数据集(不包括 PubMed)中的七个数据集上的表现优于 ChatGPT,在五个数据集(PubMedQA、HoC、MTsample、BioNLI 和 2013 DDI)上的表现优于 GPT-4。Me-LT 是唯一有 GPT-4 的数据集。在零镜头设置中,Me-LaMA 模型在五个数据集(PubMedQA、MedQA、MedMCQA、BioNLI 和 2013 DDI)中的表现优于 ChatGPT,但在七个数据集中的表现不如 GPT-4。
此外,还研究了连续预训练和指导性调整的影响。下表比较了连续预训练和指导性调整对零点大语言模型性能的影响。
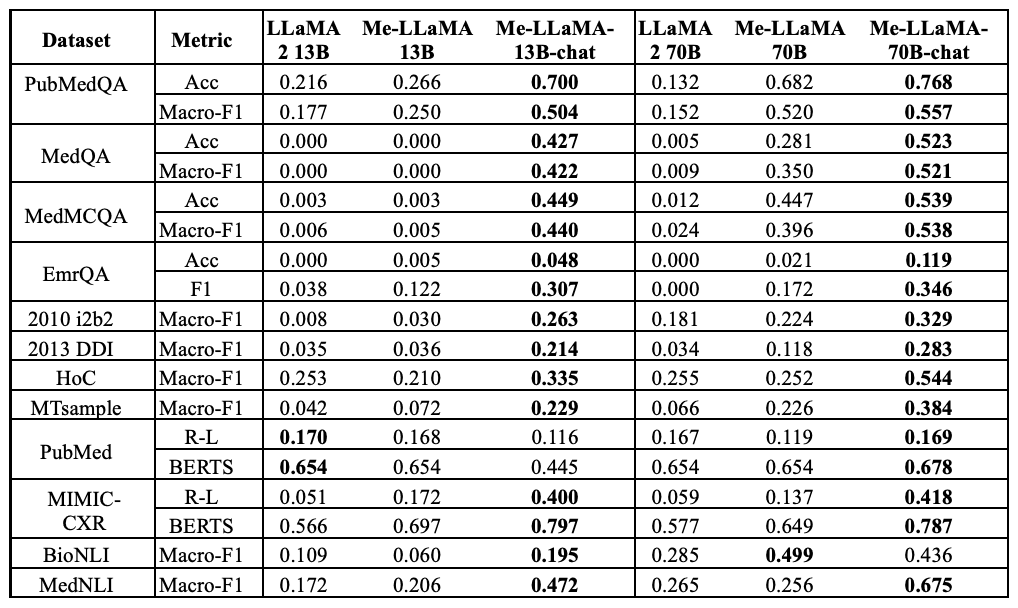
具体来说,它侧重于 Me-LaMA 13/70B 与其骨干模型 LLaMA2 13/70B 在零镜头设置中的差异,展示了持续预习的益处。它还将 Me-LaMA-13/70B-chat 与经过指令调整的聊天优化版 Me-LaMA-13/70B-chat 进行了比较,突出了零点场景下指令调整的优势。
总之,我们可以看到,持续的预训练和指导性调整都能显著提高模型的零误差能力。例如,与 LLaMA2 13B 模型相比,Me-LaMA 13B 模型在各种数据集上的性能提高了 0.5% 到 13.1%。这证明了持续预训练的好处。另一方面,与连续预训练相比,指导性调整能带来更大的零点性能提升。
具体来说,Me-LaMA-70B-chat 模型的性能比没有经过教学调整的 Me-LaMA 70B 基本模型提高了 3.7% 到 41.9%。这表明,即使没有监督微调或先验示例,教学调整在提高模型在学习任务中利用上下文的能力方面也发挥了重要作用。
它还研究了灾难性遗忘问题。对现有的大规模医学语言模型进行了比较,以评估它们在灾难性遗忘(在学习新数据时遗忘旧知识的现象)面前的脆弱性。这个问题对于大规模医学语言模型尤为重要,因为这些模型需要保持来自普通领域和医学领域的准确而一致的知识。
下表比较了各种大规模医学语言模型及其骨干模型在针对通用领域数据 MMLU28 和医学数据 MedQA 进行持续预训练后的性能。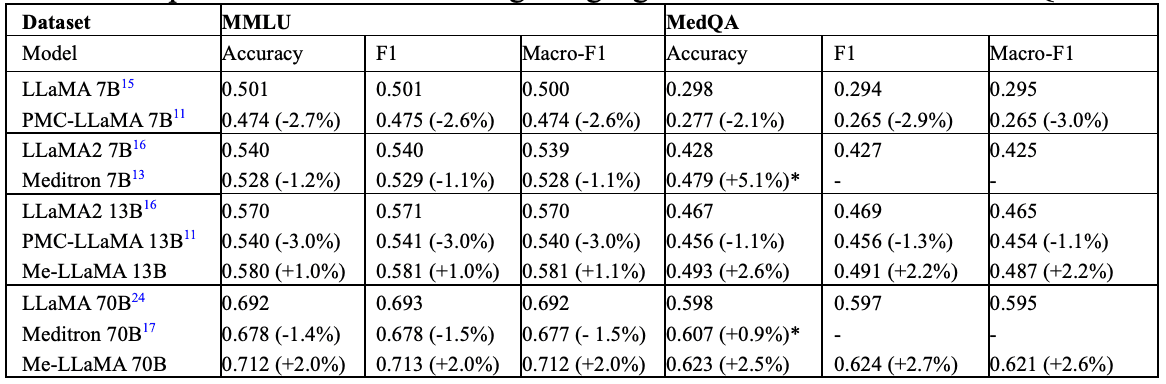
Me-LaMA 模型在普通领域和医疗领域的性能都有所提高。另一方面,一些模型仅在医疗数据上有所改善,而另一些模型在使用医疗数据进行持续预训练后,在两个领域的性能都有所下降。具体来说,Meditron 7/70B 在 MedQA 数据集上的表现有所改善,但在 MMLU 数据集上的表现有所下降;PMC-LaMA 7/13B 在两个数据集上的表现都有所下降;PMC-LaMA 7/13B 在两个数据集上的表现都有所下降;Meditron 7/70B 在 MedQA 数据集上的表现有所改善,但在 MMLU 数据集上的表现有所下降。这些结果凸显了在训练过程中平衡普通数据和医疗数据以防止知识丢失的重要性。
总结
本文开发了新的大规模医学语言模型 Me-LaMA 13B 和 Me-LaMA 70B 以及 Me-LaMA-13/70B-chat。这些模型是通过对 LLaMA2 模型进行持续的预训练和教学调整而开发出来的。所使用的数据包括来自生物医学、临床和一般领域的各种数据。
评估结果表明,Me-LaMA 模型在各种学习场景中的表现优于现有的开源大规模医学语言模型,并取得了与 ChatGPT 和 GPT-4 等领先商业模型相媲美的结果。这项研究为建立更准确、可靠和全面的大规模医学语言模型铺平了道路,并凸显了大规模语言模型在医学应用中的潜力。
然而,在 "0-shot "设置中,我们发现包括所提议的模型在内的大规模医疗保健语言模型在某些任务(如 NER 和 RE)中表现不佳。这可能是由于模型的响应缺乏预期的简洁性和准确性。例如,Me-LaMA-13B-chat 的零镜头输出在几个任务中都遇到了挑战,多标签分类经常产生冗余句子。NLI 任务也包含不准确的数字回答和不相关的字符串。
在有监督的微调设置中,Me-LaMA 模型在一些任务上的表现优于或类似于 SOTA 前的大规模语言模型。然而,在 PubMed 摘要数据集上,其性能明显低于基于预训练语言模型的方法(如 BART)。造成这一缺陷的原因是数据集中金标准摘要的质量较低,从而降低了模型生成摘要的质量,使评价指标出现偏差。
在模型开发、预培训和教学调整阶段,了解数据源多样性的重要性",从各种来源精心策划的高质量数据构成了模型性能的基础,并使模型能够准确捕捉各种医学和生物医学概念该模型的设计旨在确保其准确捕捉各种医学和生物医学概念。特别是,医学数据和通用领域数据之间的平衡非常重要,通用领域数据的整合在减轻知识遗忘问题方面发挥着关键作用。
论文发现,在 PMC-LaMA 13B 模型中,医学和普通领域数据的混合比例为 19:1,结果在普通任务和生物医学任务中都表现不佳。相比之下,比例为 4:1 的模型在普通任务和医疗任务中的表现都有所改善。这表明,需要进行仔细的经验分析,以找到最佳的数据平衡。
大型语言模型的预训练和指导性调整之间的成本和效率平衡也很重要。例如,LLaMA2 70B 模型的预训练非常耗费资源,以每个历元约 160 个 A100 GPU 计算,需要 700 个小时。相比之下,指令调整只需约 70 个小时,每历时 8 A100 GPU,比预训练经济得多。这一效率显示了在资源有限的情况下指令调整的优先性,并强调了经济高效地改进模型的潜力。
Me-LaMA 模型有 13B 和 70B 大小的基础版和聊天优化版,适用于广泛的医疗应用,在这些应用中,模型大小和资源可用性之间的平衡非常重要。基础模型为广泛的医学知识提供了坚实的基础,并可通过监督微调适应专业任务。
而聊天版本则在教学跟踪能力和上下文学习方面表现出色,在 "零拍 "或 "四拍 "学习场景中非常有效 70B 等大型模型是综合医学分析的理想选择,可提供更深入的理解和复杂的推理能力。.然而,这些部署需要大量的计算资源,这在资源有限的环境中可能是一个挑战。另一方面,13B 模型提供了一种实用的折中方案,兼顾了效率和效果,为广泛的应用提供了可能性。
必须认识到当前 Me-LaMA 模型的局限性。与所有现有的大规模语言模型一样,这些模型有可能产生事实错误和偏差信息。为了减少这种情况,未来的研究可以采用人类反馈强化学习(RLHF)等方法。
另一个限制是目前的标记处理能力仅限于 4096 个标记,这是从 LLaMA2 模型继承下来的限制。要解决这一限制,就需要扩展模型处理较长上下文的能力。
这项研究是进一步开发和实际应用新的大规模医学语言模型的重要一步:Me-LaMA 模型在医学应用方面具有巨大潜力,进一步的研究有望证明其实用性和有效性。
注:
论文地址:https://arxiv.org/abs/2402.12749
源码地址:https://github.com/bids-xu-lab/me-llama
相关文章:
Me-LLaMA——用于医疗领域的新型开源大规模语言模型
摘要 大规模语言模型的出现是提高病人护理质量和临床操作效率的一个重大突破。大规模语言模型拥有数百亿个参数,通过海量文本数据训练而成,能够生成类似人类的反应并执行复杂的任务。这在改进临床文档、提高诊断准确性和管理病人护理方面显示出巨大的潜…...
C#-常见异常的处理方式(持续更新)
1、从网络位置加载程序集失败,默认不启用CAS策略 错误原因:使用 Assembly.LoadFile(dllPath) 加载外部Dll时,DotNET安全机制阻止加载一个本地网或互联网上的程序集。 解决方案: ①配置app.config文件,在runtime节点…...

「Mac玩转仓颉内测版2」入门篇2 - 编写第一个Cangjie程序
本篇详细介绍在Mac系统上创建首个Cangjie项目并编写、运行第一个Cangjie程序的全过程。内容涵盖项目创建、代码编写、程序运行与调试,以及代码修改后的重新运行。通过本篇,掌握Cangjie项目的基本操作,进一步巩固开发环境的配置,迈…...

注册登录学生管理系统小项目
头文件 #ifndef _LOGINLINK_H_ #define _LOGINLINK_H_ #include<myhead.h> typedef struct {int id;char name[20];int age; }stu,*Pstu; typedef struct node {union{int len;stu data;};struct node *next; }node,*Pnode; int regist(); int login(); Pnode create()…...

qt QCompleter详解
1、概述 QCompleter是Qt框架中的一个类,用于为文本输入提供自动完成功能。它可以与Qt的输入控件(如QLineEdit、QTextEdit等)结合使用,根据用户的输入实时过滤数据源,并在输入控件下方或内部显示补全建议列表。用户可以…...

YOLOv11融合特征细化前馈网络 FRFN[CVPR2024]及相关改进思路
YOLOv11v10v8使用教程: YOLOv11入门到入土使用教程 一、 模块介绍 论文链接:Adapt or Rerish 代码链接:https://github.com/joshyZhou/AST 论文速览:基于 transformer 的方法在图像恢复任务中取得了有希望的性能,因为…...

【前端知识】JS模块规范
JS模块规范 概述CommonJS 规范 代码示例AMD 规范 代码示例ES6 Module 规范 代码示例IIFE 规范 代码示例全局变量 代码示例 CommonJS 模块和 ES6 模块有什么区别?1. 语法和声明方式2. 动态和静态导入3. 循环依赖4. 默认导出和命名导出5. 文件扩展名6. 环境和应用7. 工…...

vue3展示pag格式动态图
提示:如果是webpack环境的,参考:Pag格式在vue3中的简单使用方法_pag文件-CSDN博客 下面展示的是在vite环境下配置pag 1、安装libpag npm i libpag --save 2、安装rollup-plugin-copy npm i rollup-plugin-copy --save 3、封装pag组件 下…...

代码随想录算法训练营第三十九天|Day39 动态规划
198.打家劫舍 视频讲解:https://www.bilibili.com/video/BV1Te411N7SX https://programmercarl.com/0198.%E6%89%93%E5%AE%B6%E5%8A%AB%E8%88%8D.html 思路 #define max(a, b) ((a) > (b) ? (a) : (b)) int rob(int* nums, int numsSize) {if(numsSize 0){ret…...
qt QMovie详解
1、概述 QMovie 是 Qt 框架中用于处理动画文件的类。它支持多种动画格式,包括 GIF 和一些常见的视频格式(尽管对视频格式的支持依赖于底层平台)。QMovie 类主要用于在 QLabel 或 QGraphicsView 等控件中显示动画。通过加载动画文件ÿ…...

数据集整理
系列博客目录 文章目录 系列博客目录1.Visual Genome数据集2.COCO数据集3.Flickr30k数据集10.集合多个数据集的网站 1.Visual Genome数据集 官网链接:https://homes.cs.washington.edu/~ranjay/visualgenome/index.html Visual Genome数据集梳理 Visual Genome数据…...

认证授权基础概念详解
目录 认证 (Authentication) 和授权 (Authorization)的区别是什么? RBAC 模型了解吗? 什么是 Cookie ? Cookie 的作用是什么? 如何在项目中使用 Cookie 呢? 如何在 Spring Boot 中创建和读取 Cookie 创建 Cookie Cookie 到期日期 安全…...

美国地址生成器站点
推荐一:fakexy 官网地址:https://www.fakexy.com 推荐二:好维持官网地址: https://www.dizhishengcheng.com 官网除了支持生成美国地址信息外,还支持生成英国、加拿大、日朩、澳大利亚、德国、法国、意大利、西班牙、巴…...
微信4.0大版本升级跨平台支持界面全面改版
微信4.0公测版现已正式发布,作为微信的大版本升级,新版微信基于全新架构开发,跨平台支持Windows和MAC系统,界面也全面改版,聊天宝也第一时间适配微信4.0,为广大客户提供快捷回复支持 前言 微信4.0公测版现…...

不想贴秋膘?正确打开秋冬运动姿势
这个秋天想要轻装上阵,想健康入秋更要美美入冬怎么破?这期把正确打开秋冬姿势一次性告诉你哦~ 天气变凉,脂肪可要燃起来~想要无痛入秋,最重要的动起来!每天都抽出一点时间去运动一下,不光让身体燃起来&…...
)
【AIGC半月报】AIGC大模型启元:2024.11(上)
【AIGC半月报】AIGC大模型启元:2024.11(上) (1) Hunyuan-Large(腾讯开源大模型)(2) FLUX1.1 pro(文生图)(3) CogVideoX v1.5(智谱AI升级文生视频大模型) (1) Hunyuan-Lar…...
并下载保存或上传到OSS)
纯前端生成PDF(jsPDF)并下载保存或上传到OSS
前言 在工作中遇到了一个需求,就是把前端页面生成PDF并保存在本地,因为前端网站可能会展示各种表格,图表信息内容并带有比较鲜艳的色彩样式,如果让后端生产的PDF的话样式可能和前端页面展示的有所差异,所以这个任务就落…...

海外媒体发稿:旅游业媒体推广12个方面的注意事项-华媒舍
1.社交媒体推广过多 社交媒体是旅游业媒体推广的重要途径之一,过分依赖社交媒体将会成为一个常见误区。尽管社交媒体能够帮助旅行目的地提升知名度和曝光度,但如果过度投入精力与资源,可能忽视别的合理推广方式。 2.忽略SEO优化 搜索引擎提…...
)
分割回文串(DFS)
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串。返回 s 所有可能的分割方案。 示例 1: 输入:s "aab" 输出:[["a","a","b"],["aa","b&qu…...

Qt第三课 ----------容器类控件
作者前言 🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂 🎂 作者介绍: 🎂🎂 🎂 🎉🎉🎉…...
)
告别点灯:用STM32+FPGA+FSMC做个数据吞吐测试仪(附Quartus与标准库工程)
STM32与FPGA联袂打造:高性能数据吞吐测试仪实战指南 在嵌入式系统开发中,总线通信性能往往是决定整体系统响应速度的关键瓶颈。对于硬件爱好者、电子工程师和学生群体而言,如何直观测量和优化总线传输效率,是一个既具挑战性又充满…...

告别黑盒预测:用TFT模型的可解释性,看清电力负荷预测的‘为什么’
电力负荷预测的透明革命:如何用TFT模型打开时间序列黑箱 当电网调度员面对突如其来的负荷波动时,传统深度学习模型往往只能给出一个冷冰冰的预测数字,却无法解释"为什么会有这样的变化"。这种黑箱特性让关键决策充满不确定性——温…...
基于Circuit Playground Express与NeoPixel的智能光控花环制作全攻略
1. 项目概述:打造一个会“呼吸”的智能光之花环你是否想过,让一串普通的装饰灯带拥有感知环境、自动调节的“生命”?这听起来像是科幻电影里的场景,但实际上,利用今天唾手可得的开源硬件和图形化编程工具,任…...

技能图谱:构建结构化知识体系,实现高效学习与成长
1. 项目概述:一个技能图谱的诞生与价值在技术社区里,我们经常看到各种“Awesome List”——那些按领域整理的工具、库和资源清单。它们很有用,但总感觉缺了点什么。直到我偶然在 GitHub 上看到了tenequm/skills这个仓库,它给我带来…...

3分钟掌握:ncmdumpGUI免费转换网易云音乐ncm文件的完整指南
3分钟掌握:ncmdumpGUI免费转换网易云音乐ncm文件的完整指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经从网易云音乐下载了心爱的歌…...
的优缺点与选型指南)
别再只认Revit了!盘点7种主流BIM数据格式(RVT/IFC/FBX...)的优缺点与选型指南
建筑数字化进阶指南:7大BIM数据格式深度解析与实战选型策略 在建筑信息模型(BIM)与地理信息系统(GIS)加速融合的今天,数据格式的选择直接影响着项目协同效率与成果交付质量。当设计院的Revit模型需要与施工…...

【LangChain 】从一行 LCEL 代码,理解 LangChain 管道操作符 `|` 的自动转换机制
从一行 LCEL 代码,理解 LangChain 管道操作符 | 的自动转换机制一、从一个代码片段说起 先看这段处理用户反馈的 LCEL 代码: processing_chain (extract_chain| RunnablePassthrough.assign(analysislambda x: analysis_chain.invoke(x["original_…...

告别Keil报错!手把手教你用MDK为国民技术N32G030K8L7搭建标准工程模板
国民技术N32G030K8L7开发实战:从零构建MDK工程模板的避坑指南 引言:为什么你的Keil工程总是编译失败? 刚拿到国民技术N32G030K8L7开发板时,许多开发者会直接套用STM32的工程模板习惯,结果在MDK环境下遭遇各种"玄学…...

智慧桥梁之桥梁裂缝 钢筋裸露识别 墙面裂缝分割数据集 桥梁病害数据集 yolo格式 图像分割数据集地10171期
病理研究相关数据集简介项目详情数据集类别聚焦病理研究领域,涵盖多种与病理相关的图像类别,可能包含不同器官、组织或疾病类型对应的病理图像,例如常见的炎症、肿瘤等病理状态下的样本图像分类数据集数量总数3210张,但从数据集命…...

SaaS ERP和传统ERP,到底差在哪?
这几年,ERP这个词越来越火。但有意思的是,很多企业老板、管理层,甚至已经在用ERP的人,其实都没真正分清:“SaaS ERP”和“传统ERP”,到底差在哪。很多人会觉得:“不都是ERP吗?不就是…...