PostgreSQL 性能优化全方位指南:深度提升数据库效率
PostgreSQL 性能优化全方位指南:深度提升数据库效率
别忘了请点个赞+收藏+关注支持一下博主喵!!!
在现代互联网应用中,数据库性能优化是系统优化中至关重要的一环,尤其对于数据密集型和高并发的应用而言,PostgreSQL(以下简称PG)凭借其丰富的特性和强大的功能,成为很多企业的首选。然而,随着数据规模的扩展和查询复杂度的提升,PostgreSQL的性能问题逐渐显现。本文将详细介绍PostgreSQL性能优化的各个方面,涵盖硬件调优、数据库配置、索引使用、查询优化等内容,帮助你全方位提升数据库的效率。
一、系统资源优化:硬件和操作系统配置
1.1 使用SSD硬盘
硬件是数据库性能的基础。相比传统HDD,SSD硬盘具有极快的随机读取和写入速度,能够显著缩短数据库的响应时间,尤其是处理大量随机I/O操作时。因此,在条件允许(富哥v我50TvT)的情况下,建议使用SSD作为数据库存储设备。
1.2 调整内核参数
内存分页和缓存调优:在Linux系统中,PostgreSQL会依赖操作系统的缓存机制来提升性能。可以通过调整vm.swappiness参数降低系统内存换页的频率,避免频繁的磁盘I/O:
————————————————
vm.swappiness=10-
文件描述符限制:PostgreSQL在高并发情况下需要处理大量的文件句柄(如表、索引等文件),因此建议增加文件描述符的上限:
-
ulimit -n 655361.3 CPU与内存
PostgreSQL对CPU的使用是高度并行的,尤其是在执行复杂查询时,多个CPU核可以同时处理。因此,选择多核的CPU能提高查询性能。同时,更多的内存也能提升缓存效率,减少磁盘I/O操作。二、数据库配置调优:调整PostgreSQL参数
PostgreSQL有许多可以调整的配置参数,这些参数也是会影响性能滴。下面是一些关键的配置项以及优化建议。2.1 内存相关配置
shared_buffers:这是PostgreSQL用于缓存表数据的共享内存区域,通常建议设置为物理内存的25%-40%。如果设置过低,会导致频繁的磁盘访问;设置过高则会占用操作系统内存,减少可用的文件缓存。 -
shared_buffers = 4GB -
work_mem:每个查询操作(如排序、哈希表)所使用的内存。这个参数是每个查询连接单独分配的,因此需要根据查询复杂度和并发量合理设置。如果过小,查询需要频繁进行磁盘交换;过大会导致内存不足。典型值在10MB-100MB之间。
-
work_mem = 64MB -
maintenance_work_mem:此参数控制PostgreSQL在执行维护操作时使用的内存大小,比如创建索引、
VACUUM。推荐设置为较大的值,尤其是在大规模数据集上操作时。 -
maintenance_work_mem = 1GB2.2 并发相关配置
-
max_connections:决定允许的最大数据库连接数。过多的连接会增加系统开销和资源竞争。通常可以使用连接池工具(如
PgBouncer)来控制并发连接数。 -
max_connections = 300 -
effective_cache_size:PostgreSQL根据此参数判断系统可用的文件系统缓存大小,从而决定是否使用索引扫描或全表扫描。建议设置为物理内存的50%-75%。
-
effective_cache_size = 12GB2.3 WAL相关配置
WAL(Write-Ahead Logging)是PostgreSQL用来保证数据一致性的日志机制,调整WAL相关参数可以减少I/O负担。wal_buffers:建议设置为shared_buffers的1/32,用于缓冲WAL数据,避免频繁写入磁盘。
-
wal_buffers = 16MB -
checkpoint_completion_target:设置为接近1的值可以平滑WAL日志写入压力,减少突发I/O操作。
-
checkpoint_completion_target = 0.9三、SQL查询优化:高效使用SQL和索引
PostgreSQL的查询优化器会生成查询执行计划,选择最优的执行路径,但这依赖于数据库的统计信息、表结构和SQL的写法。下面详细介绍如何优化SQL查询,提升数据库性能。3.1 使用合适的索引
B-tree索引:最常用的索引类型,适合范围查询和相等查询。通常为WHERE子句中的过滤条件或JOIN操作创建索引。 -
CREATE INDEX idx_users_email ON users (email); -
GIN和GiST索引:对于全文搜索、数组操作等复杂类型数据,可以使用GIN索引。比如对JSONB字段进行查询时,使用GIN索引能够大大提高查询效率:
-
CREATE INDEX idx_jsonb_data ON my_table USING GIN (jsonb_column); -
覆盖索引(Covering Index):通过包含查询中需要返回的列,可以减少访问表的数据,降低I/O操作。例如:
-
CREATE INDEX idx_users_email ON users (email) INCLUDE (name, created_at);3.2 查询计划分析
使用
EXPLAIN或EXPLAIN ANALYZE查看查询的执行计划,分析查询是否存在性能瓶颈。 -
EXPLAIN ANALYZE SELECT * FROM users WHERE email = 'example@example.com';观察是否发生了Seq Scan(全表扫描)。
索引扫描是否被使用,如果没有,可能需要检查统计信息是否更新,或者是否应该调整索引。
是否存在嵌套循环(Nested Loop),这通常在大表联结时效率较低。
3.3 合理使用子查询与JOIN
子查询(Subquery):避免在WHERE子句中使用不必要的嵌套子查询,尽量将其转化为JOIN或WITH查询。不推荐:
-
SELECT * FROM users WHERE id IN (SELECT user_id FROM orders WHERE total > 100);推荐:
-
SELECT u.* FROM users u JOIN orders o ON u.id = o.user_id WHERE o.total > 100; -
JOIN优化:使用小表驱动大表,即在
JOIN时将小表放在左边,大表放在右边,减少内存消耗和查询时间。 -
3.4 分页优化
在大数据量分页时,直接使用
OFFSET会随着页数增大而变慢。可以采用基于主键或唯一索引的方式分页。 -
SELECT * FROM users WHERE id > 100 ORDER BY id LIMIT 10;这种方式能有效减少OFFSET的性能开销。
四、表设计优化:合理的表结构和分区
4.1 合理设计表结构
规范化与反规范化:通常情况下,数据库表应该保持高度的规范化以减少数据冗余。然而,在高并发查询的场景中,适当的反规范化(如将一些查询频繁的字段冗余存储)可以减少JOIN操作,提高查询效率。数据类型选择:选择适合的数据类型也至关重要。比如,对于固定长度的字符串,使用TEXT可能比VARCHAR(n)更高效,因为TEXT类型不需要额外的长度检查。
4.2 分区表(Partitioning)
当表的数据量非常大时,可以使用表分区来优化查询性能。PostgreSQL支持基于范围(Range Partitioning)和列表(List Partitioning)的分区。例如,对于按日期查询频繁的表,可以按时间分区: -
CREATE TABLE orders (id SERIAL PRIMARY KEY,created_at TIMESTAMP NOT NULL,total DECIMAL(10, 2) ) PARTITION BY RANGE (created_at);CREATE TABLE orders_2023 PARTITION OF orders FOR VALUES FROM ('2023-01-01') TO ('2024-01-分区表可以有效减少每次查询所需扫描的数据量。
五、日常维护:保持数据库健康
5.1 VACUUM与ANALYZE
PostgreSQL使用MVCC(多版本并发控制)机制,更新和删除的记录不会立即从物理表中删除,而是打上"死亡标记",这些记录需要通过VACUUM命令定期清理。VACUUM:释放无效的行版本,防止表膨胀。
ANALYZE:更新统计信息,帮助优化器生成更好的查询计划。
可以通过autovacuum自动进行清理,但在高负载场景下,也可以定期手动执行: -
VACUUM ANALYZE;5.2 索引维护
索引随着数据的不断插入、更新和删除,可能会变得碎片化,导致查询性能下降。定期使用
REINDEX命令重建索引: -
REINDEX INDEX idx_users_email;欢迎交流和讨论,如果在优化PostgreSQL的过程中遇到问题,欢迎在评论区提出,和咱一起探讨如何进一步优化数据库性能!
当然别忘了请点个赞+收藏+关注支持一下博主喵!!!
相关文章:

PostgreSQL 性能优化全方位指南:深度提升数据库效率
PostgreSQL 性能优化全方位指南:深度提升数据库效率 别忘了请点个赞收藏关注支持一下博主喵!!! 在现代互联网应用中,数据库性能优化是系统优化中至关重要的一环,尤其对于数据密集型和高并发的应用而言&am…...

Flutter鸿蒙next 使用 BLoC 模式进行状态管理详解
1. 引言 在 Flutter 中,随着应用规模的扩大,管理应用中的状态变得越来越复杂。为了处理这种复杂性,许多开发者选择使用不同的状态管理方案。其中,BLoC(Business Logic Component)模式作为一种流行的状态管…...
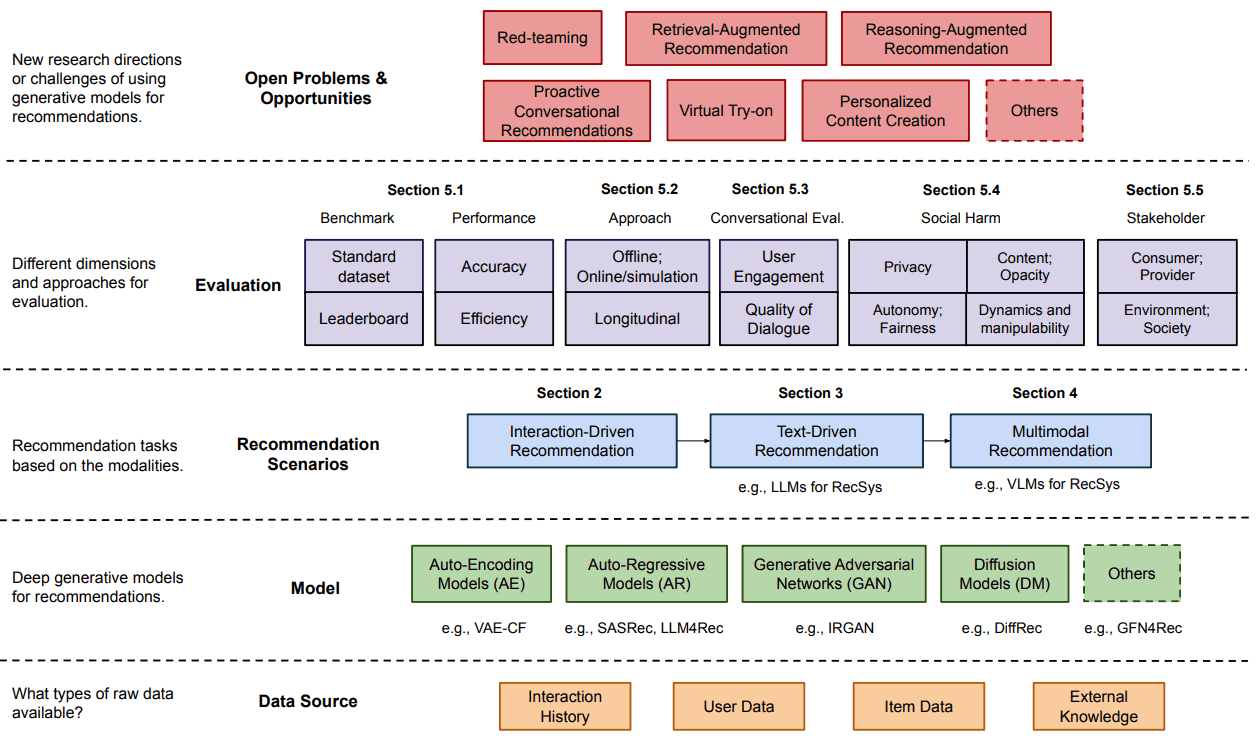
Gen-RecSys——一个通过生成和大规模语言模型发展起来的推荐系统
概述 生成模型的进步对推荐系统的发展产生了重大影响。传统的推荐系统是 “狭隘的专家”,只能捕捉特定领域内的用户偏好和项目特征,而现在生成模型增强了这些系统的功能,据报道,其性能优于传统方法。这些模型为推荐的概念和实施带…...

Android 重新定义一个广播修改系统时间,避免系统时间混乱
有时候,搞不懂为什么手机设备无法准确定义系统时间,出现混乱或显示与实际不符,需要重置或重新设定一次才行,也是真的够无语的!! vendor/mediatek/proprietary/packages/apps/MtkSettings/AndroidManifest.…...

第3章:角色扮演提示-Claude应用开发教程
更多教程,请访问claude应用开发教程 设置 运行以下设置单元以加载您的 API 密钥并建立 get_completion 辅助函数。 !pip install anthropic# Import pythons built-in regular expression library import re import anthropic# Retrieve the API_KEY & MODEL…...

【FAQ】HarmonyOS SDK 闭源开放能力 —Vision Kit
1.问题描述: 人脸活体检测页面会有声音提示,如何控制声音开关? 解决方案: 活体检测暂无声音控制开关,但可通过其他能力控制系统音量,从而控制音量。 活体检测页面固定音频流设置的是8(无障碍…...

【问题解决】Tomcat由低于8版本升级到高版本使用Tomcat自带连接池报错无法找到表空间的问题
问题复现 项目上历史项目为解决漏洞扫描从Tomcat 6.0升级到了9.0版本,服务启动的日志显示如下警告,数据源是通过JNDI方式在server.xml中配置的,控制台上狂刷无法找到表空间的错误(没截图) 报错: 06-Nov-…...

Git LFS
Git LFS(Git Large File Storage)是一个用于管理和版本控制大文件的工具,它扩展了 Git 的功能,帮助处理大文件或二进制文件的存储和管理问题。 为什么需要 Git LFS? Git 默认是针对文本文件进行优化的,尤…...

基于Redis缓存机制实现高并发接口调试
创建接口 这里使用的是阿里云提供的接口服务直接做的测试,接口地址 curl http://localhost:8080/initData?tokenAppWithRedis 这里主要通过参数cacheFirstfalse和true来区分是否走缓存,正常的业务机制可能是通过后台代码逻辑自行控制的,这…...

数字化转型实践:金蝶云星空与钉钉集成提升企业运营效率
数字化转型实践:金蝶云星空与钉钉集成提升企业运营效率 本文介绍了深圳一家电子设备制造企业在数字化转型过程中,如何通过金蝶云星空与钉钉的高效集成应对挑战、实施解决方案,并取得显著成果。集成项目在提高沟通效率、自动化审批流程和监控异…...

Flutter 鸿蒙next 中使用 MobX 进行状态管理
Flutter & 鸿蒙next 中使用 MobX 进行状态管理 在应用开发中,状态管理是一个至关重要的环节,特别是在复杂的Flutter或鸿蒙next项目中。状态的变化往往会影响UI的更新,因此,选择一种高效、灵活的状态管理工具显得尤为重要。Mo…...

1.62亿元!812个项目立项!上海市2024年度“科技创新行动计划”自然科学基金项目立项
本期精选SCI&EI ●IEEE 1区TOP 计算机类(含CCF); ●EI快刊:最快1周录用! 知网(CNKI)、谷歌学术期刊 ●7天录用-检索(100%录用),1周上线; 免费稿件评估 免费匹配期…...

Redis数据库测试和缓存穿透、雪崩、击穿
Redis数据库测试实验 实验要求 1.新建一张user表,在表内插入10000条数据。 2.①通过jdbc查询这10000条数据,记录查询时间。 ②通过redis查询这10000条数据,记录查询时间。 3.①再次查询这一万条数据,要求根据年龄进行排序&#…...

[vulnhub] DarkHole: 2
https://www.vulnhub.com/entry/darkhole-2,740/ 端口扫描主机发现 探测存活主机,185是靶机 # nmap -sP 192.168.75.0/24 Starting Nmap 7.94SVN ( https://nmap.org ) at 2024-11-08 18:02 CST Nmap scan report for 192.168.75.1 Host is up (0.…...

《XGBoost算法的原理推导》12-2 t轮迭代中对样本i的预测值 公式解析
本文是将文章《XGBoost算法的原理推导》中的公式单独拿出来做一个详细的解析,便于初学者更好的理解。 好的,公式(12-2)表示的是 XGBoost 在第 t t t 轮迭代中对样本 i i i 的预测值。它说明了在第 t t t 轮迭代中,模型的预测是通过累加之前…...

./bin/mindieservice_daemon启动成功
接MindIE大模型测试及报错Fatal Python error: PyThreadState_Get: the function must be called with the GIL held,-CSDN博客经过调整如下红色部分参数,昇腾310P3跑起来了7b模型: rootdev-8242526b-01f2-4a54-b89d-f6d9c57c692d-qjhpf:/home/apulis-de…...

Linux: network: ip link M-DOWN的具体含义是什么?
文章目录 参考简介实例代码解释openstack上的显示如果是在一个interface上建立了vlan参考 https://unix.stackexchange.com/questions/348327/using-ip-what-does-m-down-mean www.policyrouting.org/iproute2.doc.html#ss9.1 简介 是指上一级的接口的状态。 实例 4: ersp…...

Spring中的过滤器和拦截器
Spring中的过滤器和拦截器 一、引言 在Spring框架中,过滤器(Filter)和拦截器(Interceptor)是实现请求处理的两种重要机制。它们都基于AOP(面向切面编程)思想,用于在请求的生命周期…...

leetcode20.括号匹配
题目描述 给定一个只包括 ‘(’,‘)’,‘{’,‘}’,‘[’,‘]’ 的字符串 s ,判断字符串是否有效。 有效字符串需满足: 左括号必须用相同类型的右括号闭合。 左括号必须以正确的顺序闭合。 每个…...

Unity性能优化-具体操作
批量渲染是通过减少CPU向GPU发送渲染命令(DrawCall)的次数,以及减少GPU切换渲染状态的次数,尽量让GPU一次多做一些事情,来提升逻辑线和渲染线的整体效率。 Draw Call性能消耗原因是命令从Runtime到Driver的过程中&…...
)
别再问同事了!SAP顾问私藏的5个BAPI查找技巧(附SWO3/SE37实战)
SAP顾问实战指南:5种高效定位BAPI的进阶技巧 每次接到业务部门急吼吼的电话:"这个功能对应的BAPI是哪个?"时,作为ABAP顾问的你是否有种想摔键盘的冲动?十年前我刚入行时,也曾像个无头苍蝇般在SE3…...

Obsidian笔记一键发布:soulmatesmd.singles静态网站生成器实战
1. 项目概述与核心价值最近在折腾个人数字资产管理的时候,偶然间发现了一个挺有意思的项目,叫tfpickard/soulmatesmd.singles。乍一看这个标题,可能会有点摸不着头脑,它不像常见的“个人博客系统”或者“笔记工具”那么直白。但如…...

网盘直链解析方案:如何通过浏览器脚本实现多平台文件下载优化
网盘直链解析方案:如何通过浏览器脚本实现多平台文件下载优化 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

Python实战:利用pymodbus构建工业数据采集与监控系统
1. 工业数据采集为什么需要Modbus? 在工厂车间里,你可能见过各种钢铁巨兽般的设备——数控机床、PLC控制器、温度传感器。这些设备每天都在产生海量数据,但如何让这些"哑巴设备"开口说话?Modbus协议就是它们的通用语言。…...

常用命令大全
一、日常工具(最常用)calc:计算器notepad:记事本mspaint:画图工具osk:屏幕键盘write / wordpad:写字板explorer:文件资源管理器shell:recyclebinfolder:回收站shell:down…...

终极NS模拟器管理工具:三分钟搞定Switch模拟器安装配置
终极NS模拟器管理工具:三分钟搞定Switch模拟器安装配置 【免费下载链接】ns-emu-tools 一个用于安装/更新 NS 模拟器的工具 项目地址: https://gitcode.com/gh_mirrors/ns/ns-emu-tools 还在为复杂的Switch模拟器安装配置而头疼吗?NsEmuTools是你…...

Open-CLI技能扩展框架:构建模块化命令行工具生态
1. 项目概述:一个为Open-CLI设计的技能扩展框架最近在折腾命令行工具,特别是那些支持插件或技能扩展的CLI框架时,发现了一个挺有意思的项目:GloriaGuo/opencli-skill。简单来说,这是一个为“Open-CLI”设计的技能&…...

测试环境搭建指南:从零开始构建完善的测试体系
测试环境搭建指南:从零开始构建完善的测试体系 前言 各位前端小伙伴,不知道你们有没有这样的经历:在自己电脑上测试好好的,一到CI环境就各种失败。 我曾经因为测试环境和生产环境不一致,导致线上出现了一个严重bug。后…...

CFD热分析中绝热传热系数与叠加核函数原理及应用
1. CFD热分析中的绝热传热系数与叠加核函数原理剖析在电子设备热管理领域,随着功率密度的不断提升,传统的热设计方法已难以满足精度和效率的双重要求。绝热传热系数(Adiabatic Heat Transfer Coefficient, AHTC)与叠加核函数(Superposition Kernel Funct…...

WarcraftHelper技术方案:游戏兼容性修复工具的现代化适配实践
WarcraftHelper技术方案:游戏兼容性修复工具的现代化适配实践 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 随着Windows操作系统和硬件架…...