2024-11-12 问AI: [AI面试题] 您将如何设计一个人工智能系统来预测电信公司的客户流失?
文心一言
设计一个人工智能系统来预测电信公司的客户流失,是一个复杂但至关重要的任务,它涉及到多个步骤和关键要素。以下是一个详细的设计方案:
一、明确需求和目标
在设计智能系统之前,需要明确系统的需求和目标,即预测电信公司的客户流失。这包括确定预测的时间范围、准确率要求以及期望的输出结果等。明确需求和目标有助于后续步骤的精确执行和效果评估。
二、数据采集和处理
- 数据源:从电信公司的数据库中获取客户数据,包括客户的个人信息(如年龄、性别、地区、婚姻状况等)、服务使用情况(如电话、网络、电视等各项服务的使用时长、频率等)、账单支付情况(如账单金额、支付方式、欠费情况等)以及客户投诉和反馈等。
- 数据预处理:对数据进行清洗,处理缺失值和异常值,确保数据的质量和完整性。这一步骤对于后续的特征工程和模型训练至关重要。
三、特征工程
特征工程是构建预测模型的关键步骤,它直接影响到模型的性能和效果。从原始数据中提取特征,这些特征应该能够反映客户流失的潜在因素。常见的特征包括:
- 客户基本信息:年龄、性别、地区、婚姻状况等。
- 服务使用情况:各项服务的使用时长、频率、套餐类型等。
- 账单支付情况:账单金额、支付方式、欠费次数、欠费时长等。
- 投诉和反馈:投诉次数、投诉内容、反馈满意度等。
四、模型选择和训练
- 选择模型:根据问题的性质和数据的特征,选择合适的预测模型。常用的模型包括逻辑回归、决策树、随机森林、支持向量机等。这些模型在处理分类问题时表现较好,适用于客户流失的预测。
- 训练模型:利用训练数据集对模型进行训练,通过优化算法不断调整模型的参数,以使其具备良好的预测能力。在训练过程中,可以采用交叉验证的方法来评估模型的性能,并根据评估结果进行调参和优化。
五、模型评估和优化
- 评估指标:常用的评估指标包括准确率、精确率、召回率、F1分数等。这些指标能够全面反映模型的性能,帮助判断模型的优劣。
- 优化模型:根据评估结果,对模型进行调参和优化,以提高模型的预测性能。优化方法包括调整模型参数、增加特征数量、改进特征选择等。
六、系统集成和部署
- 系统集成:将训练好的模型集成到智能系统中,与数据库和其他系统进行连接,确保系统的稳定运行。
- 部署和监控:将系统部署到生产环境中,并应用于实际的客户流失预测中。同时,建立监控和反馈机制,定期对模型进行评估和更新,保持模型的有效性和适应性。
七、实施预防措施
基于预测结果,采取预防措施来防止客户流失。例如:
- 干预:向可能流失的客户发送提醒或优惠信息,以挽留他们。
- 改进服务:根据客户的反馈和投诉,改进服务质量,提升客户满意度。
- 个性化营销:针对不同类型的客户,制定个性化的营销策略,提高客户留存率。
综上所述,设计一个人工智能系统来预测电信公司的客户流失需要经历多个步骤和环节。通过明确需求和目标、数据采集和处理、特征工程、模型选择和训练、模型评估和优化、系统集成和部署以及实施预防措施等步骤,可以构建一个高效、准确的预测系统,为电信公司提供有力的决策支持。
智谱清言
设计一个人工智能系统来预测电信公司的客户流失(也称为客户流失率或客户流失预测),需要遵循以下步骤:
1. 问题定义
明确目标:预测哪些客户可能会流失,以便采取措施挽留。
2. 数据收集
收集与客户行为和服务使用情况相关的数据,可能包括:
- 客户基本信息(年龄、性别、地理位置等)
- 服务使用数据(通话时长、数据使用量、服务类型等)
- 账单信息(费用、支付方式、欠费情况等)
- 客户服务互动(投诉次数、服务请求、客户满意度调查等)
- 市场活动反应(参与促销活动、优惠反应等)
3. 数据预处理
- 数据清洗:处理缺失值、异常值、重复数据等。
- 数据转换:标准化或归一化数值数据,编码类别数据。
- 特征工程:提取和构造有助于预测的新特征。
4. 特征选择
使用统计测试、选择算法(如递归特征消除)或基于模型的特征选择方法来识别最重要的特征。
5. 模型选择
选择合适的机器学习算法来构建预测模型。常见的算法包括:
- 逻辑回归
- 决策树
- 随机森林
- 支持向量机
- 神经网络
- 集成学习方法(如XGBoost、LightGBM)
6. 模型训练与验证
- 划分数据集:通常分为训练集、验证集和测试集。
- 训练模型:使用训练集数据来训练模型。
- 调整参数:使用验证集来调整模型参数和避免过拟合。
- 评估模型:使用交叉验证等方法来评估模型性能。
7. 模型评估
使用以下指标来评估模型性能:
- 准确率(Accuracy)
- 精确率(Precision)
- 召回率(Recall)
- F1 分数
- ROC 曲线和 AUC 值
8. 部署模型
将模型部署到生产环境中,以便进行实时或批量预测。
9. 监控与维护
- 定期监控模型性能,确保预测准确性。
- 随着时间推移,重新训练模型以适应新的数据分布。
10. 实施反馈循环
- 分析模型预测结果,制定客户保留策略。
- 根据策略实施结果调整模型和策略。
以下是一些具体的实施建议:
技术栈建议
- 数据处理:Python(Pandas、NumPy、Scikit-learn)
- 模型训练:TensorFlow、PyTorch、XGBoost
- 部署:使用API(如Flask或FastAPI)进行模型服务化,容器化(如Docker)部署
- 监控:ELK Stack(Elasticsearch, Logstash, Kibana)或Prometheus和Grafana
实施注意事项
- 确保数据安全和隐私合规性。
- 考虑模型的解释性和透明度,以便业务团队能够理解和信任模型预测。
- 考虑到业务连续性,确保模型的可维护性和升级路径。
通过这样的流程,可以设计并实施一个有效的人工智能系统来预测电信公司的客户流失。
豆包
以下是设计一个用于预测电信公司客户流失的人工智能系统的步骤:
一、数据收集与理解
- 确定数据来源
- 从电信公司的客户关系管理系统(CRM)收集客户的基本信息,如年龄、性别、职业、地址等。这些信息可以帮助了解客户的人口统计学特征对流失的潜在影响。
- 从计费系统获取客户的账单信息,包括每月消费金额、套餐类型、缴费记录等。消费模式的变化可能是客户流失的一个信号。
- 收集客户服务记录,如投诉次数、咨询内容等。频繁的投诉或对服务不满意的咨询可能预示着客户即将流失。
- 数据理解与预处理
- 对收集到的数据进行探索性数据分析(EDA)。例如,通过绘制直方图来观察客户年龄的分布,或者使用箱线图来分析每月消费金额的分布情况。
- 处理缺失值。对于缺失的客户信息,可以采用均值、中位数填充或者根据其他相关特征进行预测填充。例如,如果客户的职业信息缺失,可以根据其消费模式和地址等信息来推测可能的职业。
- 对分类数据进行编码。例如,将客户的性别(男 / 女)编码为 0/1,套餐类型等分类变量也进行适当的数值编码,以便模型能够处理。
二、特征工程
- 提取有价值的特征
- 计算客户的忠诚度相关特征,如客户在网时长。在网时间较长的客户可能相对更忠诚,流失的可能性较低。
- 分析客户的消费行为变化特征。例如,计算近几个月消费金额的波动率,消费金额突然下降可能暗示客户有流失风险。
- 根据客户服务记录,创建一个 “服务满意度” 特征。可以通过对投诉和咨询内容进行情感分析,将客户的情绪分为正面、负面和中性,统计负面情绪的比例作为服务满意度的一个衡量指标。
- 特征选择
- 使用统计方法如相关性分析来选择与客户流失高度相关的特征。例如,计算每个特征与客户流失标签(流失 / 未流失)的相关性系数,选择绝对值较大的特征。
- 采用机器学习算法进行特征选择,如递归特征消除(RFE)。以决策树算法为例,RFE 可以通过反复构建决策树模型并剔除不重要的特征,最终留下对预测客户流失最有价值的特征子集。
三、模型选择与训练
- 选择合适的模型
- 逻辑回归模型:逻辑回归是一种简单而有效的分类模型,适用于二分类问题(客户流失或未流失)。它可以根据特征的线性组合来计算客户流失的概率,并且模型的解释性较强。
- 决策树模型:决策树可以直观地展示客户流失的决策规则。例如,它可以根据客户的消费金额、投诉次数等特征构建一棵决策树,每个节点代表一个特征的判断条件,叶子节点则是客户流失或未流失的预测结果。
- 随机森林模型:随机森林是由多个决策树组成的集成模型。它通过对多个决策树的结果进行投票或平均来提高预测的准确性和稳定性,能够处理高维数据和复杂的非线性关系。
- 梯度提升树模型(如 XGBoost、LightGBM):这些模型通过迭代地构建弱分类器来提升模型的性能。它们在处理客户流失预测这种结构化数据方面表现出色,能够捕捉到特征之间的复杂交互关系。
- 模型训练与评估
- 将数据集划分为训练集、验证集和测试集。一般可以按照 70%:15%:15% 的比例划分。
- 使用训练集对选定的模型进行训练,调整模型的参数。例如,对于逻辑回归模型,可以使用梯度下降法来优化模型的权重参数;对于随机森林模型,可以调整树的数量、树的深度等参数。
- 在验证集上评估模型的性能,使用评估指标如准确率、精确率、召回率、F1 - score 和 ROC - AUC 曲线下面积等。例如,准确率可以衡量模型预测正确的客户流失和未流失情况的比例;ROC - AUC 可以评估模型对正例(客户流失)和负例(客户未流失)的区分能力。
- 根据验证集的评估结果,对模型进行调整和优化。例如,如果发现模型在验证集上出现过拟合(在训练集上表现很好,但在验证集上表现差),可以采用正则化方法(如 L1 和 L2 正则化对于逻辑回归,或控制树的深度对于决策树模型)来缓解过拟合。
四、模型部署与监控
- 模型部署
- 将训练好的模型集成到电信公司的业务系统中。例如,可以将模型部署在云端服务器上,通过 API 接口与电信公司的 CRM 系统或其他相关系统进行交互。当需要预测客户流失情况时,相关系统可以将客户数据发送到模型服务器,模型返回流失概率或预测结果。
- 模型监控与更新
- 持续监控模型的性能。随着时间的推移,客户的行为模式和市场环境可能会发生变化,导致模型的性能下降。可以定期在新的数据上重新评估模型的性能。
- 根据监控结果对模型进行更新。如果发现模型的准确率、ROC - AUC 等指标明显下降,可以重新收集数据、进行特征工程,并重新训练和优化模型,以确保模型能够持续有效地预测客户流失情况。
讯飞星火
设计一个人工智能系统来预测电信公司的客户流失是一个典型的分类问题,通常涉及机器学习和数据挖掘技术。以下是一个详细的步骤指南:
1. 数据收集与预处理
数据收集
- 客户信息: 年龄、性别、地理位置、职业等。
- 使用行为: 通话时长、短信数量、数据使用量、网络质量评分等。
- 账单信息: 月费、额外费用、支付方式、是否有未付账单等。
- 合同信息: 合约期限、当前合约状态等。
- 客户服务记录: 投诉记录、服务请求记录等。
- 市场活动参与情况: 促销活动参与情况、优惠券使用情况等。
数据预处理
- 清洗数据: 处理缺失值、异常值。
- 特征工程: 生成新的特征,例如平均通话时长、每月的数据使用趋势等。
- 编码分类变量: 将非数值型数据(如性别、地理位置)转换为数值形式,可以使用独热编码或标签编码。
- 标准化/归一化: 确保不同特征在同一尺度上。
2. 特征选择
- 相关性分析: 使用统计方法(如皮尔逊相关系数)筛选出与客户流失高度相关的特征。
- 特征重要性评估: 使用决策树、随机森林等模型评估特征的重要性。
- 降维: 如果特征过多,可以使用PCA(主成分分析)或其他降维技术。
3. 模型选择与训练
模型选择
- 逻辑回归: 简单且解释性强的模型。
- 决策树/随机森林: 适用于非线性关系,可以捕捉复杂的模式。
- 梯度提升机(GBM): 强大的集成学习方法,适用于大规模数据集。
- 神经网络: 对于复杂模式和大量数据表现优异,但需要更多的计算资源和调参。
- XGBoost/LightGBM: 高效的梯度提升框架,适合处理大规模数据集。
模型训练
- 划分数据集: 将数据集分为训练集、验证集和测试集。
- 交叉验证: 使用K折交叉验证来评估模型的性能,防止过拟合。
- 超参数调优: 使用网格搜索或随机搜索优化模型的超参数。
4. 模型评估
- 准确率: 正确预测的比例。
- 召回率: 正确识别出的流失客户占实际流失客户的比例。
- 精确率: 正确识别出的流失客户占预测为流失客户的比例。
- F1分数: 召回率和精确率的调和平均值。
- ROC曲线和AUC值: 评估模型在不同阈值下的表现。
5. 部署与监控
部署
- API接口: 将模型封装成API接口,方便业务系统集成。
- 批处理系统: 定期运行模型对客户进行预测。
监控
- 性能监控: 持续监控模型的预测性能,确保其在实际环境中表现良好。
- 数据漂移检测: 监测输入数据的分布是否发生变化,及时调整模型。
- 反馈循环: 根据实际结果不断优化模型,提高预测准确性。
6. 业务应用
- 个性化营销: 针对高风险流失客户提供定制化的优惠和服务,以减少流失。
- 预警系统: 建立实时预警机制,当客户流失风险增加时,及时采取措施。
- 策略调整: 根据预测结果调整公司策略,例如改进客服质量、优化套餐设计等。
通过以上步骤,可以构建一个有效的人工智能系统来预测电信公司的客户流失,从而帮助公司采取针对性措施,保留更多客户。
通义
设计一个用于预测电信公司客户流失的人工智能系统需要综合考虑数据收集、数据预处理、特征选择、模型构建与训练、模型评估、部署及监控等多个环节。以下是一个概括的设计流程:
1. 定义目标
明确预测任务的具体目标,例如预测未来3个月内哪些客户最有可能流失。
2. 数据收集
- 历史数据:收集过去几年的客户数据,包括但不限于服务使用记录、账单信息、客户服务交互记录等。
- 实时数据:如果可能,集成实时数据流,以便更准确地反映客户的当前状态。
- 外部数据:考虑引入第三方数据,如社交媒体活动,以获得更全面的用户画像。
3. 数据预处理
- 清洗数据:处理缺失值、异常值和重复数据。
- 格式化数据:确保所有数据格式一致,便于后续分析。
- 数据转换:根据需要对数据进行标准化或归一化处理。
4. 特征工程
- 特征选择:基于领域知识和统计测试选择与客户流失相关的特征。
- 特征构造:创建新的特征,比如客户的消费习惯、服务满意度评分等。
- 特征降维:使用PCA(主成分分析)或其他技术减少特征数量,提高模型效率。
5. 模型构建与训练
- 选择算法:根据问题性质选择合适的机器学习算法,如逻辑回归、决策树、随机森林、梯度提升机(GBM)、支持向量机(SVM)、神经网络等。
- 交叉验证:通过K折交叉验证等方法评估模型性能,避免过拟合。
- 超参数调优:利用网格搜索或随机搜索等方法寻找最佳模型参数。
6. 模型评估
- 使用准确率、召回率、F1分数、AUC-ROC曲线等指标评估模型性能。
- 对模型进行稳定性测试,确保其在不同时间段的数据上表现一致。
7. 部署
- 将训练好的模型部署到生产环境中,可以是云平台、本地服务器或边缘设备。
- 开发API接口,使其他系统能够调用模型进行预测。
8. 监控与维护
- 实施持续监控机制,定期检查模型性能,确保其随时间推移仍保持准确性。
- 根据业务变化和技术进步定期更新模型。
9. 采取行动
- 基于模型预测结果,制定针对性的客户保留策略,如提供定制化优惠、改善服务质量等。
整个过程中,重要的是要保持对数据隐私和安全的关注,确保遵守相关法律法规。同时,也要注重与业务团队的合作,确保技术解决方案能够有效地转化为商业价值。
相关文章:

2024-11-12 问AI: [AI面试题] 您将如何设计一个人工智能系统来预测电信公司的客户流失?
文心一言 设计一个人工智能系统来预测电信公司的客户流失,是一个复杂但至关重要的任务,它涉及到多个步骤和关键要素。以下是一个详细的设计方案: 一、明确需求和目标 在设计智能系统之前,需要明确系统的需求和目标,…...

【数字静态时序分析】复杂时钟树的时序约束SDC写法
以上图为例,SoC芯片上往往存在几种不同的时钟源,有pll时钟、环振时钟、外部的晶振时钟,在SoC不同的模块或者不同的运行阶段使用的时钟也往往不同,所以在使用的时候,相同的模块会出现选择不同的时钟源的情况。上图的情形…...

springboot苍穹外卖实战:五、公共字段自动填充(aop切面实现)+新增菜品功能+oss
公共字段自动填充 不足 比起瑞吉外卖中的用自定义元数据类型mybatisplus的实现,这里使用的是aop切面实现,会麻烦许多,建议升级为mp。 定义好数据库操作类型 sky-common中已经定义好,OperationType。 自定义注解 AutoFill co…...

Go 语言中,golang结合 PostgreSQL 、MySQL驱动 开启数据库事务
Go 语言中,golang结合 PostgreSQL 、MySQL驱动 开启数据库事务 PostgreSQL代码说明: MySQL代码说明: PostgreSQL 在 Go 语言中,使用 database/sql 包结合 PostgreSQL 驱动(如 github.com/lib/pq)可以方便地…...
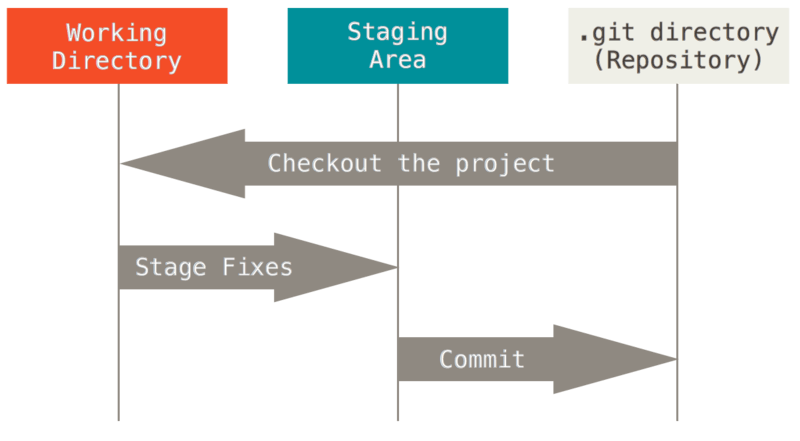
Git核心概念
目录 版本控制 什么是版本控制 为什么要版本控制 本地版本控制系统 集中化的版本控制系统 分布式版本控制系统 认识Git Git简史 Git与其他版本管理系统的主要区别 Git的三种状态 Git使用快速入门 获取Git仓库 记录每次更新到仓库 一个好的 Git 提交消息如下&#…...

网络安全技术在能源领域的应用
摘要 随着信息技术的飞速发展,能源领域逐渐实现了数字化、网络化和智能化。然而,这也使得能源系统面临着前所未有的网络安全威胁。本文从技术的角度出发,探讨了网络安全技术在能源领域的应用,分析了能源现状面临的网络安全威胁&a…...

这些场景不适合用Selenium自动化!看看你踩过哪些坑?
Selenium是自动化测试中的一大主力工具,其强大的网页UI自动化能力,让测试人员可以轻松模拟用户操作并验证系统行为。然而,Selenium并非万能,尤其是在某些特定场景下,可能并不适合用来自动化测试。本文将介绍Selenium不…...
)
PHP反序列化靶场(php-SER-libs-main 第一部分)
此次靶场为utools-php-unserialize-main。适合有一定基础的师傅,内容是比较全面的,含有我们的大部分ctf中PHP反序列化的题型。 level1: <?php highlight_file(__FILE__); class a{var $act;function action(){eval($this->act);} } …...
基于大数据爬虫+Python+SpringBoot+Hive的网络电视剧收视率分析与可视化平台系统(源码+论文+PPT+部署文档教程等)
博主介绍:CSDN毕设辅导第一人、全网粉丝50W,csdn特邀作者、博客专家、腾讯云社区合作讲师、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流✌ 技术范围…...

DHCP与FTP
DHCP dhcp:动态主机配置的协议,应用在大型的局域网环境中 服务端和客户端 服务端:提供IP地址,某种特定功能的提供者 客户端:请求IP地址,请求对应的功能的使用者 服务端的端口号:67 客户端的端…...
云渲染与云电脑,应用场景与技术特点全对比
很多朋友问,你们家一会宣传云渲染,一会宣传云电脑的,我到底用哪个?今天,渲染101云渲染和川翔云电脑就来对比下两者的区别! 渲染101&川翔云电脑,都是我们的产品,邀请码6666 一、…...

RockPI 4A单板Linux 4.4内核下的RK3399 GPIO功能解析
RockPI 4A单板Linux 4.4内核下的RK3399 GPIO功能解析 摘要:本文将基于RockPI 4A单板,介绍Linux 4.4内核下RK3399 GPIO(通用输入输出)功能的使用方法。通过详细的代码解析和示例,帮助读者理解如何在Linux内核中使用GPI…...
Vue3.0中$attrs 的概念和使用场景)
【Vue】Vue3.0(二十三)Vue3.0中$attrs 的概念和使用场景
文章目录 一、$attrs的概念和使用场景概念使用场景 二、代码解释Father.vueChild.vueGrandChild.vue 三、另一个$attrs使用的例子 一、$attrs的概念和使用场景 概念 在Vue 3.0中,$attrs是一个组件实例属性,它包含了父组件传递给子组件的所有非props属性…...
)
RHEL/CENTOS 7 ORACLE 19C-RAC安装(纯命令版)
一 首先需要安装两个CENTOS 7虚拟机(此处省略)。 由于我们是要安装ORCLE-RAC双节点集群所以至少每个CENTOS虚拟机上需要两块网卡,并且两块网卡都是HOST-ONLY具体步骤请看视频一《为虚拟机添加网卡》 这里大家需要注意的是,我们需要绑定两台机器的IP一共…...

CCSK:面试云计算岗的高频问题
在竞争激烈的云计算岗位求职市场中,拥有 CCSK云计算安全知识认证无疑能为你增添强大的竞争力。而深入了解云计算面试中的高频问题并熟练掌握答案,更是迈向成功的关键一步。 一、AWS 相关问题 AWS 是重要考点,常被问到其关键特性,…...

C++ String(1)
String的头文件是#include <string> String本质上是一个类,是C实现好的一个类 初学只用学重要的部分,不可能一次性全部学完 1.构造函数 我们先来看它的几个构造函数 首先(1)就是无参的构造 (2)是…...

ts 中 ReturnType 作用
ReturnType 用于获取函数的返回值类型。 一、基本概念和语法 1. 定义和语法结构 ReturnType是一个泛型类型,其语法为ReturnType<T>,其中T是一个函数类型。例如,如果有一个函数add,ReturnType<typeof add>就可以获取…...
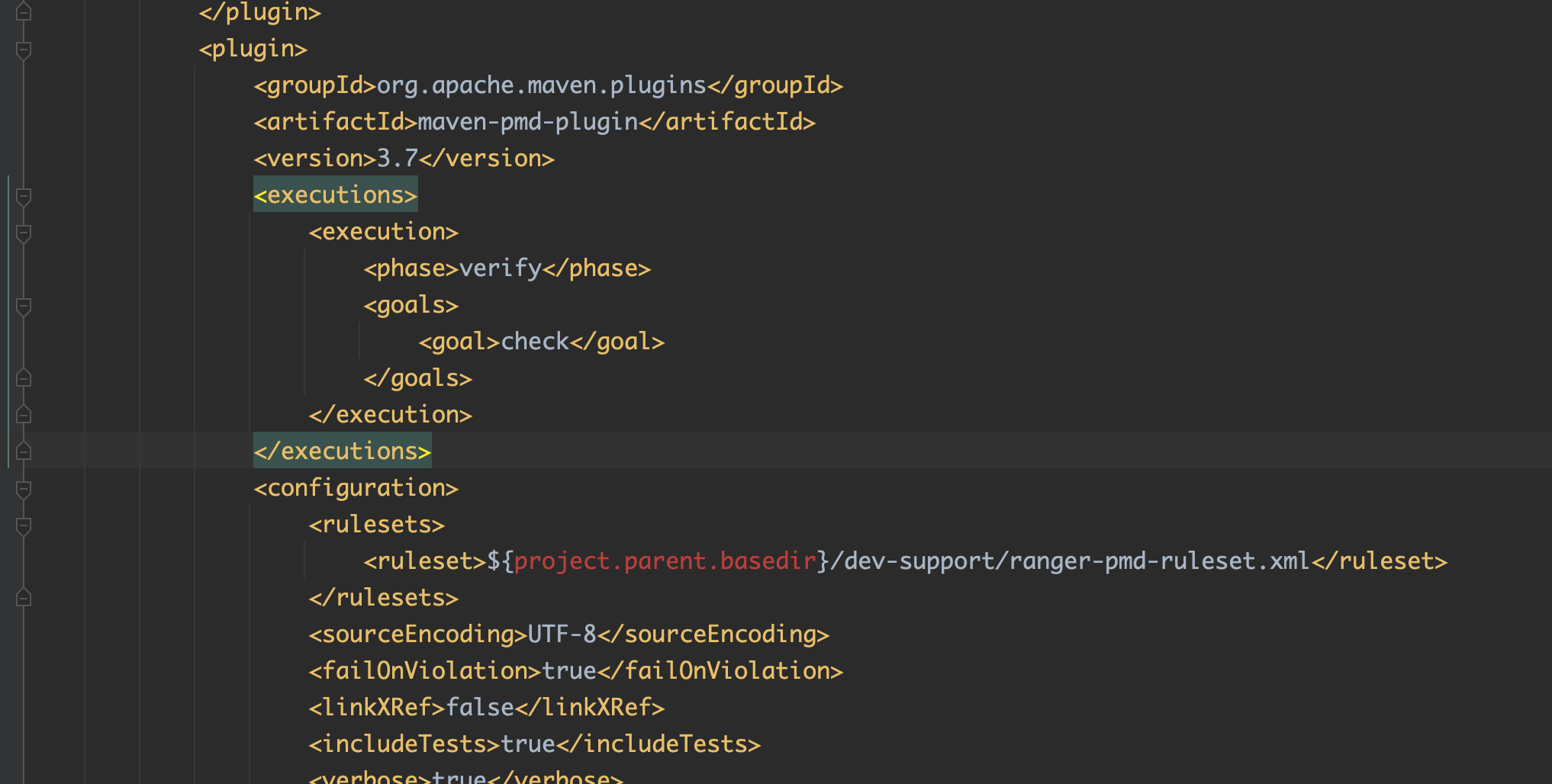
Hadoop + Hive + Apache Ranger 源码编译记录
背景介绍 由于 CDH(Clouderas Distribution Hadoop )近几年已经开始收费并限制节点数量和版本升级,最近使用开源的 hadoop 搭了一套测试集群,其中的权限管理组件用到了Apache Ranger,所以记录一下编译打包过程。 组件…...

Java从入门到精通笔记篇(十二)
枚举类型与泛型 枚举类型可以取代以往常量的定义方式,即将常量封装在类或接口中 使用枚举类型设置常量 关键字为enum 枚举类型的常用方法 values()方法 枚举类型实例包含一个values()方法,该方法将枚举中所有的枚举值以数组的形式返回。 valueOf()可…...

入侵排查之Linux
目录 1.黑客入侵后的利用思路 2.入侵排查思路 2.1.账号安全 2.1.1.用户信息文件/etc/passwd 2.1.2.影子文件/etc/shadow 2.1.3.入侵排查 2.1.3.1.排查当前系统登录信息 2.1.4.2.查询可以远程登录的账号信息 2.2.历史命令 2.2.1.基本使用 2.2.1.1.root历史命令 2.2.…...

MASA模组汉化终极指南:快速实现Minecraft中文界面本地化
MASA模组汉化终极指南:快速实现Minecraft中文界面本地化 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 你是否曾经因为MASA模组的英文界面而感到困扰?面对复杂的…...

<项目代码>yolo缆绳识别<目标检测>
项目代码下载链接 YOLOv8是一种单阶段(one-stage)检测算法,它将目标检测问题转化为一个回归问题,能够在一次前向传播过程中同时完成目标的分类和定位任务。相较于两阶段检测算法(如Faster R-CNN)࿰…...

Nmap零基础实战:从安装配置到渗透测试全流程解析
1. 别再被“零基础”三个字骗了:Nmap不是点开就用的玩具,而是你第一把真正能切开网络的手术刀很多人点开“渗透测试零基础入门”这类标题,心里想的是:“装个软件,敲几行命令,扫出一堆IP和端口,就…...

终极音乐解锁指南:3个简单步骤让加密音乐重获自由
终极音乐解锁指南:3个简单步骤让加密音乐重获自由 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://g…...

SPT-AKI Profile Editor:终极《逃离塔科夫》离线存档编辑器完全指南
SPT-AKI Profile Editor:终极《逃离塔科夫》离线存档编辑器完全指南 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com…...

DLSS Swapper完整指南:免费开源的游戏DLSS智能管理工具终极教程
DLSS Swapper完整指南:免费开源的游戏DLSS智能管理工具终极教程 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 你是否曾经为不同游戏需要管理不同版本的DLSS文件而烦恼?当《赛博朋克2077》需要…...

Hotkey Detective:3分钟解决Windows热键冲突的专业侦探工具
Hotkey Detective:3分钟解决Windows热键冲突的专业侦探工具 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是…...

Kubernetes服务发现与负载均衡机制:构建高效的服务通信网络
Kubernetes服务发现与负载均衡机制:构建高效的服务通信网络 一、服务发现概述 服务发现是微服务架构中服务之间相互定位和通信的核心机制。在Kubernetes中,服务发现通过Service资源实现,它为一组Pod提供稳定的网络标识和负载均衡能力。 1.…...

终极iOS越狱实战指南:解锁iPhone隐藏功能与深度定制方案
终极iOS越狱实战指南:解锁iPhone隐藏功能与深度定制方案 【免费下载链接】Jailbreak iOS 26.4 - 26, 17 - 17.7.5 & iOS 18 - 18.7.3 Jailbreak Tools, Cydia/Sileo/Zebra Tweaks & Jailbreak News Updates || AI Jailbreak Finder 👇 项目地址…...

大语言模型提示工程优化:精准解决机器翻译中的零代词恢复难题
1. 项目概述:当大语言模型遇上机器翻译的“隐形主语”在机器翻译的日常工程实践中,我们常常会遇到一个看似微小却影响深远的“幽灵”问题:零代词。尤其是在处理像中文到英文这类语言差异巨大的翻译任务时,这个问题尤为突出。中文讲…...