【大数据技术基础 | 实验十】Hive实验:部署Hive

文章目录
- 一、实验目的
- 二、实验要求
- 三、实验原理
- 四、实验环境
- 五、实验内容和步骤
- (一)安装部署
- (二)配置HDFS
- (三)启动Hive
- 六、实验结果
- (一)启动结果
- (二)Hive基本命令
- 七、实验心得
一、实验目的
- 理解Hive存在的原因;
- 理解Hive的工作原理;
- 理解Hive的体系架构;
- 并学会如何进行内嵌模式部署;
- 启动Hive,然后将元数据存储在HDFS上。
二、实验要求
- 完成Hive的内嵌模式部署;
- 能够将Hive数据存储在HDFS上;
- 待Hive环境搭建好后,能够启动并执行一般命令。
三、实验原理
Hive是Hadoop 大数据生态圈中的数据仓库,其提供以表格的方式来组织与管理HDFS上的数据、以类SQL的方式来操作表格里的数据,Hive的设计目的是能够以类SQL的方式查询存放在HDFS上的大规模数据集,不必开发专门的MapReduce应用。
Hive本质上相当于一个MapReduce和HDFS的翻译终端,用户提交Hive脚本后,Hive运行时环境会将这些脚本翻译成MapReduce和HDFS操作并向集群提交这些操作。
当用户向Hive提交其编写的HiveQL后,首先,Hive运行时环境会将这些脚本翻译成MapReduce和HDFS操作,紧接着,Hive运行时环境使用Hadoop命令行接口向Hadoop集群提交这些MapReduce和HDFS操作,最后,Hadoop集群逐步执行这些MapReduce和HDFS操作,整个过程可概括如下:
(1)用户编写HiveQL并向Hive运行时环境提交该HiveQL。
(2)Hive运行时环境将该HiveQL翻译成MapReduce和HDFS操作。
(3)Hive运行时环境调用Hadoop命令行接口或程序接口,向Hadoop集群提交翻译后的HiveQL。
(4)Hadoop集群执行HiveQL翻译后的MapReduce-APP或HDFS-APP。
由上述执行过程可知,Hive的核心是其运行时环境,该环境能够将类SQL语句编译成MapReduce。
Hive构建在基于静态批处理的Hadoop之上,Hadoop通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive在几百MB的数据集上执行查询一般有分钟级的时间延迟。
因此,Hive并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive查询操作过程严格遵守Hadoop MapReduce的作业执行模型,Hive将用户的HiveQL语句通过解释器转换为MapReduce作业提交到Hadoop集群上,Hadoop监控作业执行过程,然后返回作业执行结果给用户。Hive并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
Hive架构与基本组成如图所示:

四、实验环境
- 云创大数据实验平台:

- Java 版本:jdk1.7.0_79
- Hadoop 版本:hadoop-2.7.1
- Hive 版本:hive-1.2.1
五、实验内容和步骤
相对于其他组件,Hive部署要复杂得多,按metastore存储位置的不同,其部署模式分为内嵌模式、本地模式和完全远程模式三种。当使用完全模式时,可以提供很多用户同时访问并操作Hive,并且此模式还提供各类接口(BeeLine,CLI,甚至是Pig),这里我们以内嵌模式为例。
由于使用内嵌模式时,其Hive会使用内置的Derby数据库来存储数据库,此时无须考虑数据库部署连接问题,整个部署过程可概括如下。
(一)安装部署
在master机上操作:首先确定存在Hive
ls /usr/cstor/hive/

(二)配置HDFS
先为Hive配置Hadoop安装路径。
待解压完成后,进入Hive的配置文件夹conf目录下,接着将Hive的环境变量模板文件复制成环境变量文件。
cd /usr/cstor/hive/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
这里使用cp命令而不是mv命令,是因为我们可以备份一份之前的文件,我们只是复制一份修改,而不是替换。
在配置文件中加入以下语句:
HADOOP_HOME=/usr/cstor/hadoop

然后在HDFS里新建Hive的存储目录,进入hadoop的bin目录内:
cd /usr/cstor/hadoop/
在HDFS中新建/tmp和/usr/hive/warehouse两个文件目录,并对同组用户增加写权限。
bin/hadoop fs -mkdir /tmp
bin/hadoop fs -mkdir -p /usr/hive/warehouse
bin/hadoop fs -chmod g+w /tmp
bin/hadoop fs -chmod g+w /usr/hive/warehouse

(三)启动Hive
在内嵌模式下,启动Hive指的是启动Hive运行时环境,用户可使用下述命令进入Hive运行时环境。
启动Hive命令行:
cd /usr/cstor/hive/
bin/hive

六、实验结果
(一)启动结果
使用bin/hive命令进入Hive环境验证Hive是否启动成功。
cd /usr/cstor/hive/
bin/hive
(二)Hive基本命令
进入Hive环境后,使用show tables,show function后如下图所示则表示配置成功。
显示表:
show tables;

因为目前我们没有创建表所以返回了一个OK。
显示Hive内置函数:
show functions;

退出Hive环境:
exit;
七、实验心得
通过本次Hive部署实验,我深刻理解了Hive在Hadoop大数据生态圈中的重要地位和作用。Hive作为一个数据仓库,不仅提供了以表格方式组织和管理HDFS上数据的便利,更以类SQL的方式简化了对大规模数据集的操作,极大地降低了开发成本。
在实验过程中,我学习了Hive的内嵌模式部署方法,掌握了如何将Hive数据存储在HDFS上,并成功启动了Hive环境。通过实际操作,我深刻体会到了Hive环境搭建的复杂性和细致性,每一个步骤都需要谨慎操作,稍有疏忽就可能导致部署失败。
同时,我也认识到Hive并非为联机事务处理而设计,其查询操作过程严格遵守Hadoop MapReduce的作业执行模型,因此在大规模数据集上实现低延迟快速查询方面存在一定的局限性。这使我更加明确了Hive的最佳使用场合——大数据集的批处理作业。此外,我还学会了使用Hive的基本命令,如查看表格和函数等,这些命令为我在后续的实验和学习中提供了有力的支持。
总之,本次Hive部署实验不仅让我掌握了Hive的部署和使用方法,更让我对Hive的工作原理和体系架构有了更深入的理解。我相信,在未来的学习和工作中,我将能够更好地运用Hive来处理和分析大规模数据集。
附:以上文中的数据文件及相关资源下载地址:
链接:https://pan.quark.cn/s/b0f6f0d06704
提取码:PNp2
相关文章:
【大数据技术基础 | 实验十】Hive实验:部署Hive
文章目录 一、实验目的二、实验要求三、实验原理四、实验环境五、实验内容和步骤(一)安装部署(二)配置HDFS(三)启动Hive 六、实验结果(一)启动结果(二)Hive基…...

Golang常见编码
1. URL 编码、解码 2. base64 编码、解码 3. hex 编码、解码 4. md5 编码 5. sha-1 编码 6. sha-256 编码 7. sha-512 编码 package mainimport ("crypto/md5""crypto/sha256""crypto/sha512""encoding/base64""encoding/h…...

搭建Spring gateway网关微服务
在使用微服务架构时,往往我们需要搭建一个网关服务,作为各个微服务的统一入口。Spring gateway作为网关服务的后起之秀,受到各大企业的欢迎。下面介绍下网关服务Spring gateway的搭建。 引入依赖,这一步比较重要,也需要…...

性能测试|JMeter接口与性能测试项目
前言 在软件开发和运维过程中,接口性能测试是一项至关重要的工作。JMeter作为一款开源的Java应用,被广泛用于进行各种性能测试,包括接口性能测试。本文将详细介绍如何使用JMeter进行接口性能测试的过程和步骤。 JMeter是Apache组织开发的基…...

spring boot 难点解析及使用spring boot时的注意事项
1、难点解析: 1.1 配置管理: --- 尽管Spring Boot强调“习惯优于配置”,但在实际项目中,仍然需要面对大量的配置问题。如何合理地组织和管理这些配置,以确保项目的稳定性和可维护性,是一个挑战。 --- Sp…...

通过投毒Bingbot索引挖掘必应中的存储型XSS
简介 在本文中,我将讨论如何通过从外部网站对Bingbot进行投毒,来在Bing.com上实现持久性XSS攻击。 什么是存储型或持久性XSS?存储型攻击指的是将恶意脚本永久存储在目标服务器上,例如数据库、论坛、访问日志、评论栏等。受害者在…...
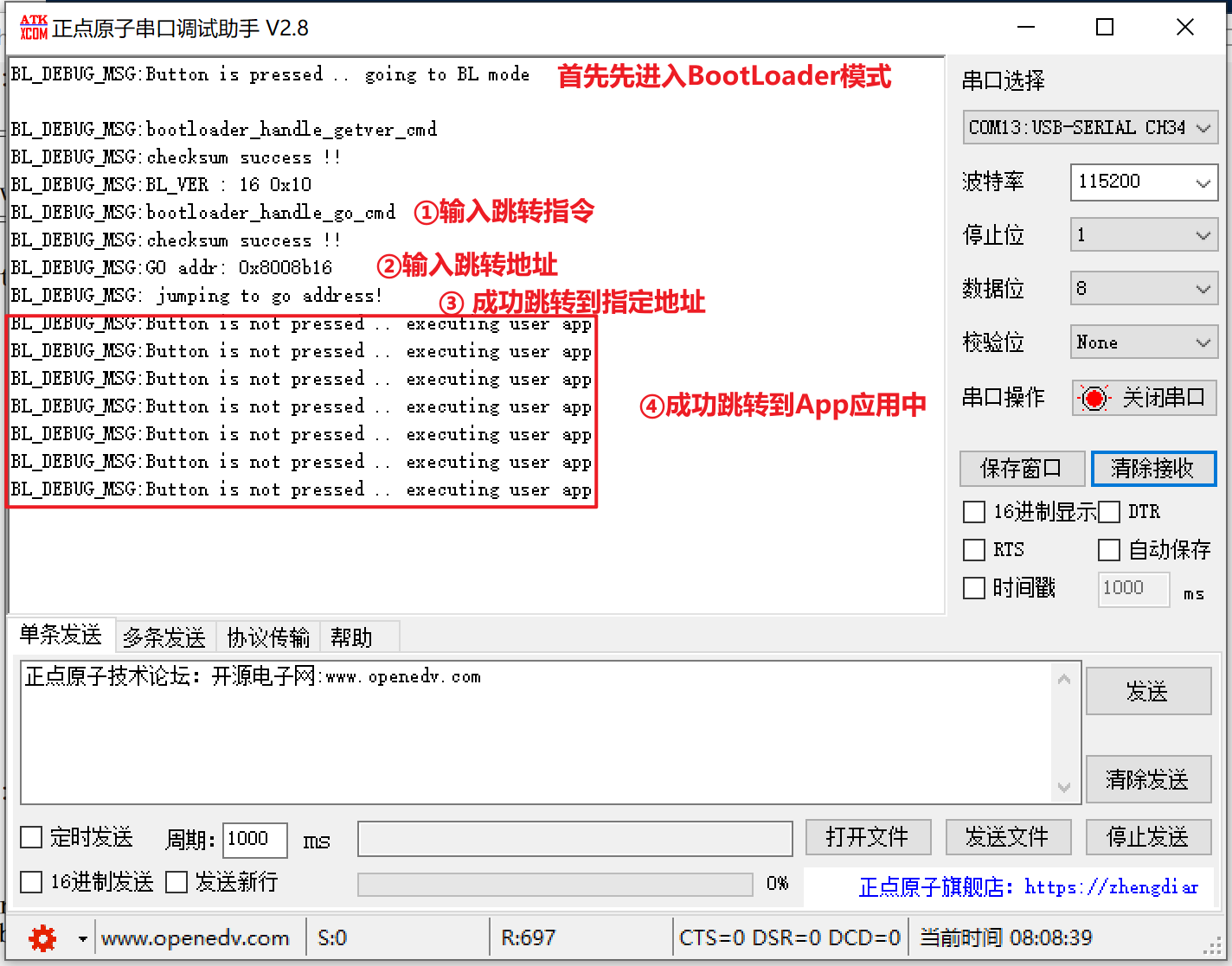
STM32 BootLoader 刷新项目 (九) 跳转指定地址-命令0x55
STM32 BootLoader 刷新项目 (九) 跳转指定地址-命令0x55 前面我们讲述了几种BootLoader中的命令,包括获取软件版本号、获取帮助、获取芯片ID、读取Flash保护Level。 下面我们来介绍一下BootLoader中最重要的功能之一—跳转!就像BootLoader词汇中的Boot…...

【Linux篇】面试——用户和组、文件类型、权限、进程
目录 一、权限管理 1. 用户和组 (1)相关概念 (2)用户命令 ① useradd(添加新的用户账号) ② userdel(删除帐号) ③ usermod(修改帐号) ④ passwd&…...

PET-文件包含
include发生错误报warning,继续执行。require发生错误直接error,不继续执行 无视扩展名,只要能解析,就能当可执行文件执行,哪怕文件后缀或没后缀 1 条件竞争 pass17 只需要知道tmp的路径。把xieshell.jpg上传&…...

实现uniapp-微信小程序 搜索框+上拉加载+下拉刷新
pages.json 中的配置 { "path": "pages/message", "style": { "navigationBarTitleText": "消息", "enablePullDownRefresh": true, "onReachBottomDistance": 50 } }, <template><view class…...

PostgreSQL 修改字段类型但是存在视图依赖
其实视图的存在与否在数据库界一直是一个话题。用好视图可以简化程序的很多代码,用不好视图不仅会给维护带来很多的不便,也会造成很大的性能问题。下面我从维护方面给出案例,以及当存在这种问题的时候,如何去解决这个问题。 假设…...

基于.NET 9实现实时进度条功能:前后端完整示例教程
要在基于.NET 9的应用中实现进度条功能,我们可以通过HttpContext.Response来发送实时的进度更新到前端。以下是一个简单的示例,展示了如何在ASP.NET Core应用中实现这一功能。 但是,我在.net framework4.7.2框架下,实际不了HttpC…...

力扣 LeetCode 19. 删除链表的倒数第N个结点(Day2:链表)
解题思路: 快慢指针 class Solution {public ListNode removeNthFromEnd(ListNode head, int n) {ListNode dummy new ListNode(-1);dummy.next head;ListNode fast dummy;ListNode slow dummy;for (int i 0; i < n; i) {fast fast.next;}while (fast.ne…...

音频格式转换
一、场景 项目需求需要App实现声纹识别功能,调用科大讯飞接口: 声纹识别 API 文档 | 讯飞开放平台文档中心 其接口要求音频文件格式为mp3 二、问题产生 在安卓端根据官方文档说明,系统并不支持直接录制mp3格式音频,支持格式如…...
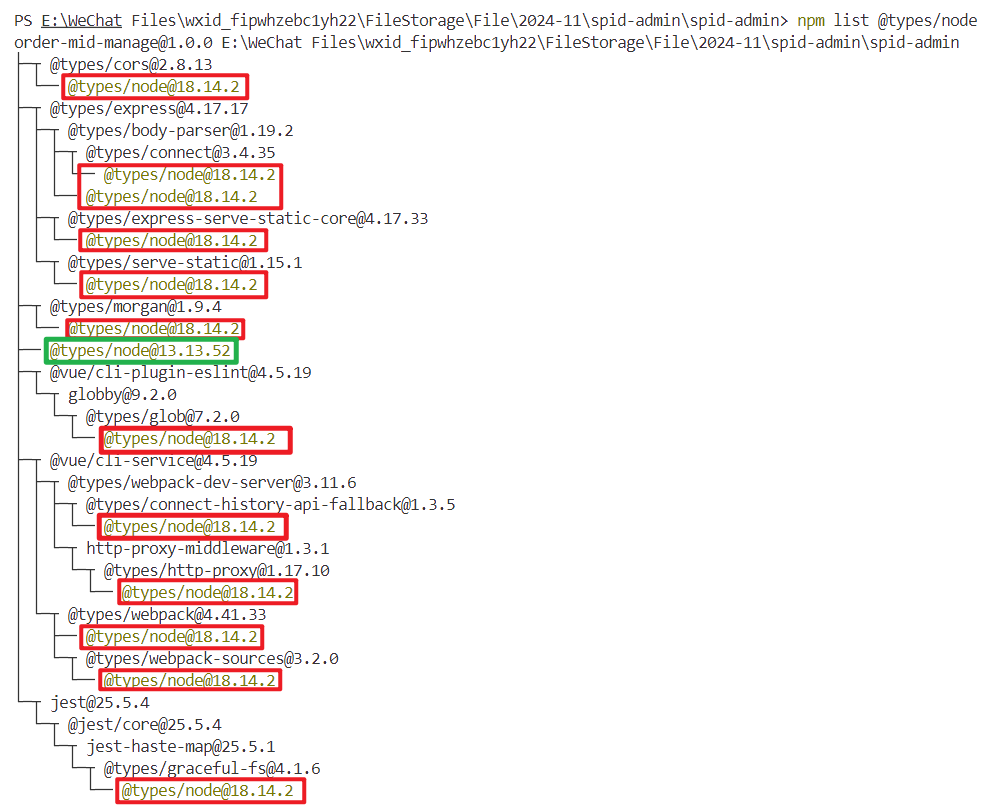
npm list @types/node 命令用于列出当前项目中 @types/node 包及其依赖关系
文章目录 作用示例常用选项示例命令注意事项 1、实战举例**解决方法**1. **锁定唯一的 types/node 版本**2. **清理依赖并重新安装**3. **设置 tsconfig.json 的 types**4. **验证 Promise 类型支持** **总结** npm list types/node 命令用于列出当前项目中 types/node 包及其…...

【Spring】Spring框架中有有哪些常见的设计模式
Spring 框架中广泛运用了多种设计模式,今天让我们来学习一下 1. 单例模式(Singleton Pattern) 用途:在Spring框架中,Bean默认是单例的,也就是说在容器中每种类型的Bean只有一个实例。这个设计可以节省资源…...

提升百度排名的有效策略与技巧解析
内容概要 提升百度排名对于网站的成功至关重要。首先,了解百度排名的基本原则,掌握搜索引擎是如何评估网页质量的,是优化过程中不可或缺的一部分。搜索引擎越来越倾向于将用户需求放在首位,因此提供高质量的内容和良好的用户体验…...

【Linux】Linux下查看cpu信息指令(top/mpstat/iostat/pidstat)说明
top命令 top(1) - Linux manual page (man7.org) top查看总的CPU利用率 us: 用户空间消耗的CPU资源占比,进程在用户态执行函数调用,编解码消耗的都是us sy: 内核空间消耗的CPU资源占比,进程调用系统调用达到内核后会增加sy的消耗 ni&…...

HDLBIts习题(3):使用冒号表示位宽时,冒号两端必须是常量
(1)易错习题1:Circuits - Combinational Logic - Multiplexers - 256-to-1 4bit multiplexer 使用冒号表示位宽时,冒号两端必须是常量,因此如果使用变量,可以使用位拼接的方法。 (2)…...

C++20协程详解
文章目录 什么是协程为什么需要协程什么时候使用协程协程的类别C20的协程协程的使用关键字co_wait框架一阶段完成数据交换co_yieldco_return 什么是协程 我们在学习编程的过程中,逐渐从单线程,到多线程,再到异步编程和并发处理 这些异步与并…...

C#实现ASCII和字符串相互转换的代码示例
知识点 string 1 Stirng.Empty 表示空字符串。 此字段为只读。此字段的值为零长度字符串“”。string为引用数据类型。会在内存的栈和堆上分配存储空间。因此string.Empty与“”都会在栈上保存一个地址,这个地址占4字节,指向内存堆中的某个长度为0的空间…...
全解析)
C#实现稳定Windows低级鼠标钩子(WH_MOUSE_LL)全解析
1. 为什么“鼠标钩子”不是炫技,而是解决真实问题的底层能力在Windows桌面应用开发中,我见过太多人把“全局鼠标监听”当成一个玄乎其玄的功能——要么觉得它危险、难搞、容易被杀毒软件误报;要么干脆绕开,用轮询GetCursorPos这种…...

CoQMoE:面向FPGA的MoE-ViT量化与硬件协同设计实践
1. 项目概述:当视觉Transformer遇上FPGA,为何需要“协同设计”?最近几年,视觉Transformer(ViT)在图像识别、目标检测等任务上展现出了不输甚至超越传统卷积神经网络(CNN)的性能。但随…...
)
告别K-means!用DBSCAN搞定雷达点云聚类,手把手教你调参(附Matlab代码)
毫米波雷达点云聚类的DBSCAN实战:从算法原理到参数调优 在自动驾驶和智能交通系统中,毫米波雷达因其全天候工作能力和稳定的测距测速性能,成为不可或缺的环境感知传感器。然而,原始雷达数据往往呈现为稀疏、噪声密集且分布不规则的…...

Android高版本HTTPS抓包解法:Magisk+MoveCert证书升权实战
1. 为什么高版本安卓抓包越来越像在拆炸弹? 你有没有试过在Android 12或13上用Charles抓App的HTTPS流量,结果刚装完证书就弹出“此证书不受信任”?App死活不走代理,甚至直接闪退——不是网络问题,不是Charles没配好&a…...

数据标注中的权力博弈与主观性:从规则制定到模型偏见的全链路解析
1. 项目概述:当数据标注不再是“客观”的技术活“数据标注”,在很多人眼里,可能就是一个坐在电脑前,对着图片画框、打标签的“体力活”或“技术活”。它听起来中立、客观,是人工智能模型训练前一道标准化的工序。然而&…...

类和对象概括
类与对象的概念在Java中,类是对象的模板或蓝图,定义了对象的属性和行为。对象是类的实例,具有类定义的属性和方法。类的定义类通过class关键字定义,包含成员变量(属性)和方法(行为)。…...

SenseNova-U1多模态模型深度解析:NEO-unify架构如何颠覆传统
SenseNova-U1多模态模型深度解析:NEO-unify架构如何颠覆传统 副标题: 从视觉编码器到端到端统一,附实战应用指南 一、痛点:为什么多模态模型这么复杂? 很多开发者第一次接触多模态模型时,会被各种架构绕晕:视觉编码器、文本解码器、适配器、投影层… 感觉像在看天书。 …...

【AI Agent娱乐行业落地实战指南】:2024年头部平台已验证的7大爆款应用模型与避坑清单
更多请点击: https://intelliparadigm.com 第一章:AI Agent在娱乐行业的核心价值与演进趋势 AI Agent正从被动响应工具跃升为娱乐内容生态的主动协作者与智能策展者。其核心价值不仅体现在效率提升,更在于重构创意生产链路、深化用户参与机制…...

STM32F103驱动TFT-LCD屏避坑指南:FSMC时序配置与ILI9341初始化那些事儿
STM32F103驱动TFT-LCD屏的实战技巧:时序优化与初始化陷阱全解析 1. 硬件连接与FSMC基础配置 对于STM32F103开发者而言,驱动TFT-LCD屏最常见的硬件方案是通过FSMC(灵活的静态存储控制器)接口模拟8080并行时序。这种设计巧妙利用了S…...