替换OpenTSDB和HBase,宝武集团使用IoTDB助力钢铁设备智能运维

时序数据库 IoTDB 应用于宝武集团全基地钢铁时序数据管理,激活数据资产,赋能大型设备智能运维。
1. 背景概述
宝武装备智能科技有限公司(以下简称:宝武智维)是中国宝武设备智能运维专业化平台公司,30 余年始终专注于钢铁行业设备技术服务,逐步打通检测、诊断、检修、制造等设备服务环节,形成系统解决方案服务模式,希望为用户提供稳定可靠、智能高效的设备运行保障。
随着工业物联网的迅速发展,面向钢铁领域设备的智能运维成为大数据、人工智能等先进技术重要的应用方向之一。钢铁产线设备大型化、复杂度高,设备之间相互耦合,现场问题定位和修复难度非常高。同时,钢铁设备通常处于连续运转状态,出现异常对于产线产能影响可观,实现设备的实时性、预防性维护对于保障产线效能、实现企业降本增效均十分重要。
为实现钢铁产线设备智能运维这一项极具挑战的复杂系统创新工程,宝武智维基于海量工业时序数据积累及其丰富的应用场景,自主构建具备低成本、大规模接入能力的设备远程智能运维平台,并于 2023 年全面融合国产时序数据库 IoTDB,作为该平台管理宝武全集团时序数据的核心组件。
通过 IoTDB,宝武智维得以“激活”时序数据价值,大幅提升宝武集团、基地侧智能化数据写入、存储、分析、传输性能,并为下游设备故障排查业务场景提供了坚实的数据支撑,形成了面向钢铁全流程,一个平台、一个专家系统、一套标准化体系的智能设备运维新模式。
2. 选型痛点
在全面接入 IoTDB 之前,宝武智维已经经过多年探索,并使用基于 Hadoop 的 HBase 和 OpenTSDB 作为钢铁设备的时序数据管理架构。业务初期,该架构应用效果较好,但随着更多数据量的接入,其慢慢成为了制约发展的底层瓶颈,主要体现在两个大方面:“慢”和“难”。
-
写入慢:常规情况下,旧版架构勉强能够达到写入性能要求,但后续业务的扩张伴随设备、数据量的激增,结合基地网络资源的有限性,写入性能逐渐捉襟见肘。如果碰到网络断线等异常场景,往往大量消息、数据出现堵塞,网络恢复后需要快速地进行消费,但旧版架构也无法支撑消费速度要求。
-
查询慢:宝武集团查询数据跨度可能以年为单位,并要求大跨度数据实现查询秒级响应,而在数据量增加后,旧版架构仅能实现 5-30 秒内返回,对于业务平台使用效果与实时监控设备状态的目的实现存在较大影响。
-
加工慢:数据写入存储后,需要使用聚合函数等方法实现多类数据加工,但基于旧版架构其速度非常有限,且很容易导致整体数据架构不稳定。
-
抽取慢、汇聚难:当进行集团-基地数据资产整合时,往往需要不断地将基地存储数据抽取至集团侧。旧版架构对于数据的实时传输支持不足,对持续的传输过程稳定性影响较大。
-
清理难:基于旧版架构的数据清理、删减主要依靠 TTL,过程复杂且灵活度较低。宝武集团实践时,曾出现磁盘将满情况下,定好的数据需要写程序进行导出,再导回系统的情况,数据运维工作十分繁琐。
-
备份难:庞大的数据体量下,基于旧版架构的策略化备份实现非常困难,基本无法备份,只能选择部署 3 节点集群以响应备份需求。
耗费大量成本获取的海量高价值数据,却变成了深不见底的数据黑洞。随着数据量不断增长,运行效率却无法提升,数据反而成为拖累,下游应用系统、团队的施展空间很低,无法将数据价值真正转化为业务价值。

因此,宝武智维的时序数据库选型标准可以概括为:
-
能够写入海量并发数据;
-
能够用更低成本存储全量数据、高频数据;
-
能够实时查询、分析数据,实现高效的数据清理与备份;
-
能够实现集团侧-基地侧数据实时同步、汇聚的易用方案。
3. 部署方案
2023 年开始,IoTDB 全面替换 OpenTSDB,成为宝武集团时序数据湖的数据底座。运用 IoTDB 为时序数据管理核心的宝武智维云平台,已部署至宝武集团全部生产基地,并逐步扩展至集团外,负责接入宝武全集团所有基地内的所有设备数据,并进行在线状态监测与设备智能运维业务。
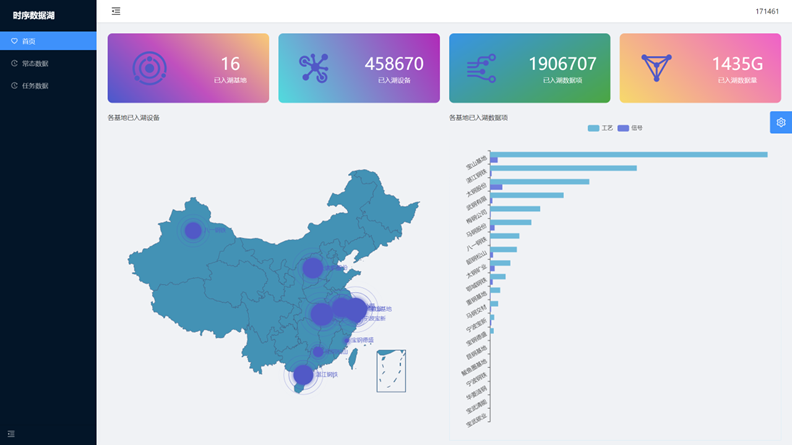
目前,宝武智维云全面覆盖宝武集团 21 大生产基地,接入 27 个子平台、60 万以上设备、240 万以上数据项,总数据量超 5 PB。平台配置规则超 10 万条,已沉淀智能模型超 40 大类,平台用户数超 1 万。
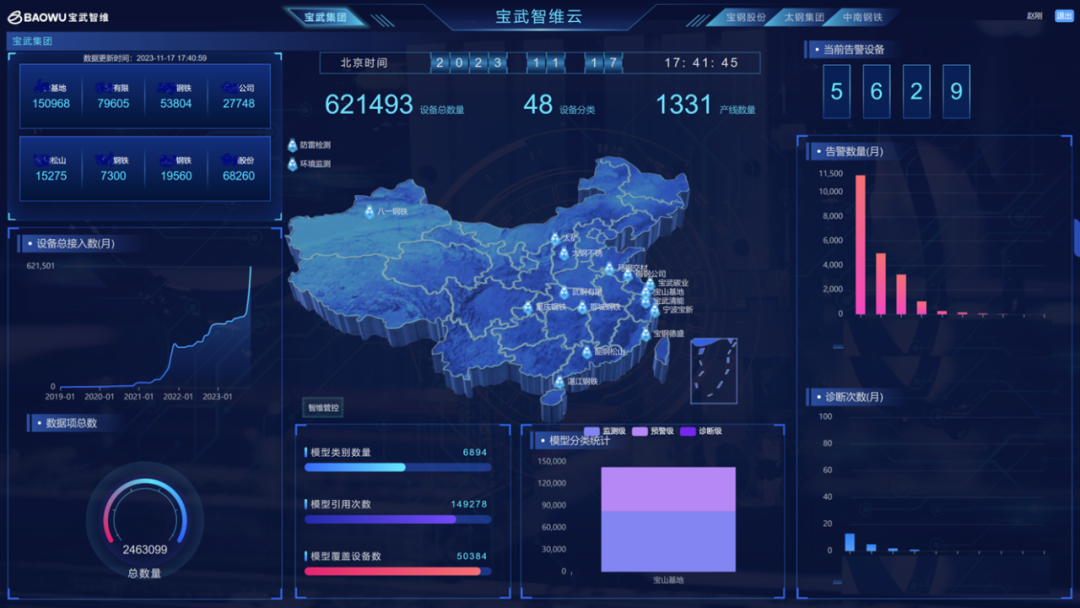
从以 IoTDB 进行重构的全新架构来看,宝武超大规模分布式数据湖由 1 个 E4-IoTDB 集团数据湖和 N 个 E3-IoTDB 基地数据湖集群组成。多个 E3-IoTDB 基地数据湖负责存储管理该基地的设备数据,而宝武集团层的 E4-IoTDB 数据湖主要覆盖常态数据的降频存储和故障相关数据的原始频率存储。同时,集团层可以通过下发任务方式,从各个基地抽取所需数据并进行存储,用于模型训练及定制化数据任务。
宝武集团与基地之间的数据同步方式目前有两种。第一种为通过 Pipe 使用 IoTDB 自研的时序数据标准文件格式 TsFile 进行高效传输,不需要数据的重新组织和重复写入,可实现数据端到端的直接使用。另一种为使用全贯通的 Kafka 数据总线进行数据上传,能够满足宝武各基地及集团的数据防火墙传输要求。

实现数据的高性能写入、存储,并打通数据抽取、传输链路后,宝武集团成功构建了 E4 集团数据湖与 E3 基地数据湖。集团数据湖包括一个主库、N 个功能库和一个备份库,功能库又包括故障特征库与 AI 训练库。故障特征库包括所有基地的设备故障特征,各基地一天几十条至几百条不等的故障事件所涉及到的相关数据均会上传并进行存储,方便集团集中分析故障趋势与原因。各基地数据湖则包括一个主库、一个功能库和一个备份库,功能库主要做为同步库使用。
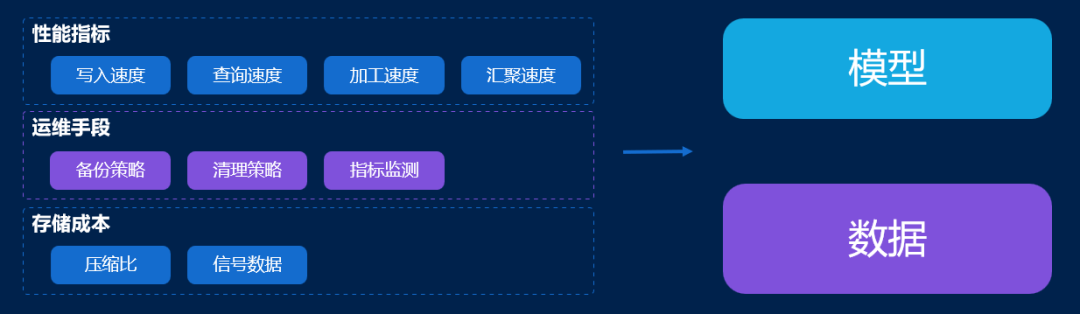
使用 IoTDB 后,宝武集团时序数据管理效果提升非常明显,实现性能提升 1 个量级,存储成本大幅下降,运维手段丰富,数据资产汇聚,AI 模型训练加速等有效成果。
存储成本方面,通过实践,基于 IoTDB 可实现 10 倍数据压缩比,并能够用少量服务器存储集团规模数据。对于钢铁领域最重要的数据类型之一——信号数据的存储成本也得到大幅降低。
运维手段方面,相比旧版架构僵化、暴力的数据清洗处理方式,宝武集团成功基于 IoTDB 实现备份、清理的灵活策略化,能够积累丰富的指标、监测信息,帮助运维人员实现对设备状态的更好理解。
性能指标方面,IoTDB 写入速度可实现千万点/秒,可以长时间稳定写入高频数据;基地上报的秒级数据及边缘侧上报的毫秒级数据,一年数据量查询可实现秒级返回,并能够覆盖长达十年、数百万点的设备数据降采样分析,性能获得用户认可。同时,IoTDB 提供了丰富的聚合函数,有效拓宽宝武集团的数据加工场景,加速原始数据加工,并通过上述数据传输方案提升数据汇聚速度,方便数据真正形成模型,实现规模化运用。
与前文中的选型要求对照可见,IoTDB 在写入、存储、查询、分析、运维、汇聚等方向,均契合了宝武智维的时序数据库选型标准,从根源处解决了 OpenTSDB 与 HBase 架构的多个性能与功能实践痛点。
4. 应用场景举例
场景一:波形信号数据处理
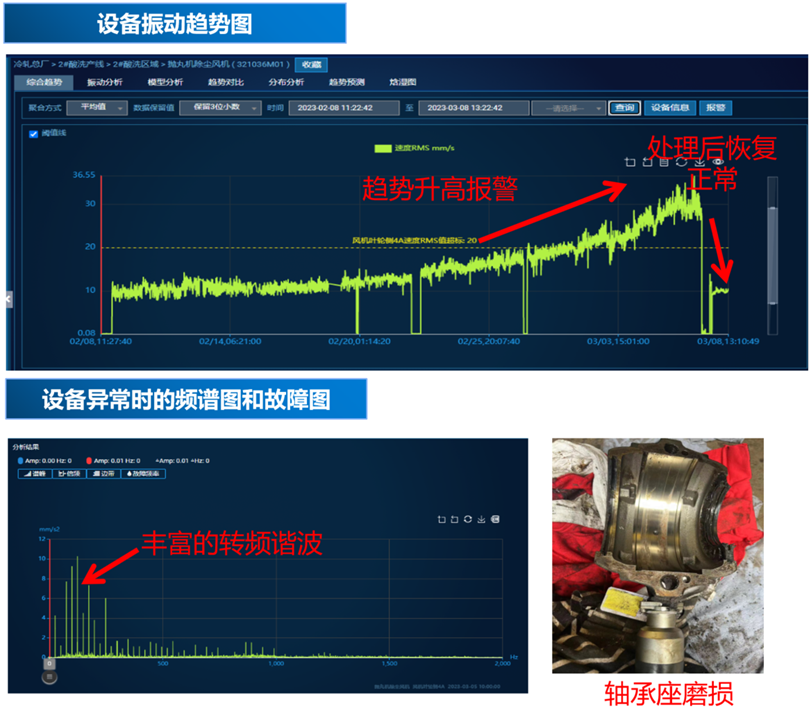
钢铁行业中,设备实时上报的振动波形数据是最可靠的时序数据资产之一,能够有效反映设备的运行状态。宝武集团的振动波形数据一般分为两类,一类是通过 PLC、DCS 采集上报的工艺量数据,一类是通过加装大量传感器,如温振传感器采集上报的振动波形数据。各类传感器安装数量庞大,因此后一类数据的体量十分可观。
旧版架构中,以上两类数据基本通过对象存储方式存入 HBase,存储量占比在某些基地达到 1:20。一个基地的数据中,20 份为振动数据,1 份为工艺量数据,可见振动传感器上传的时序数据体量十分庞大,存储管理的成本,以及后续使用处理的难度可想而知。
引入 IoTDB 之后,参考 IoTDB 团队所在的天谋科技技术人员的建议,宝武智维不再将振动波形数据作为对象进行存储,而是直接将数据拆散之后,以纳秒级精度存储到 IoTDB,这样能够有效提升该类数据的存储压缩比,大幅降低其存储成本。同时,存储模式发生变化后,应用模式也随之发生变化。宝武智维可以直接在 IoTDB 层面对振动波形数据进行处理,为后续的数据加工工作提供了有力支撑。宝武智维表示该项改良是“非常颠覆性的设计”。
场景二:结合 AI 的创新应用
IoTDB 有效解决了数据的抽取、存储、处理、上传问题后,丰富的时序数据资产被彻底激活,宝武智维也就能够拓宽目前应用数据的模式与发展空间。其 AI 团队成功从“找数据”改变为“要数据”,能够发散更多有想象力的创新应用场景,面向多设备、长周期数据进行进一步归纳与分析。衍生场景包括但不限于:
-
通用数据集的自动构建、自动标签化:基于反馈(误报和漏报) 和闭环进行标签化。
-
同类故障的数据集的构建:故障记录和多源数据的匹配映射,基于故障记录和故障匹配的数据对故障类型、故障程度进行标签化。
-
同类设备的数据集的构建:同类设备数据的归并和映射,基于设备基准、设备参数信息,对同类、同部件同型号进行匹配和标签化。
-
振动信号的特征提取:时域信号分段特征的提取、长周期信号特征的提取、频域特征的提取。
-
趋势特征的提取:长周期数据特征的提取,月度或年度数据特征的提取;生产周期的划分,周期性生产过程特征的提取。
-
数据对齐和数据融合:工况数据的匹配,多源异构数据(时序、文本、人工输入数据)的匹配。
-
文本对象数据集的构建:文本数据信息的抽取、实体的匹配。
-
AI 平台与 IoTDB 的双向通讯:数据集映射、抽取至 AI 平台,实现存储处理与深度分析的一体化融合。
5. 未来展望
宝武智维计划未来在与 IoTDB 深度融合的更多方面进行研究,包括但不限于:
-
视图功能:切实结合业务需求,实现测点数据扁平化。围绕生产、质量、运维等不同角度,结合 IoTDB 自带的时序数据树状模型,运用视图功能组织、复用数据资产,从业务方向组织成不同视角的数据树状架构,进一步降低团队运维学习成本。
-
中台功能:基于 IoTDB 进行通用数据 API 与专用数据 API 的研发,形成数据资产管理,并在该数据中台之上进行 APP 轻量化,以及数据可视化的自主探索。
-
UDF 函数:目前,IoTDB 主要用于构建宝武智维平台中的数据存储、处理底座,未来希望针对振动波形、信号数据、长周期趋势分析等关键场景,通过研发 UDF 自定义函数并内嵌至数据湖中,替代原有的外挂 Python 程序调用,结合数据 API、AI 模型,全面提升宝武集团工业数据应用分析能力。
-
AINode:通过引入 IoTDB 内生支持的机器学习智能节点,替代原有的数据再抽取、单独外部训练模式,支持使用已有模型直接在 IoTDB 内部进行推理,针对钢铁领域数据预测、异常检测等方面进行预制模型训练和加载,达到无需导出数据,直接使用内置模型进行数据推理的目标,实现端到端的数据深度分析。
以数据为牵引,以平台化为手段,IoTDB 将继续与宝武智维深度合作,更好地串联产业链上下游数据资源,共建钢铁生态圈智能运维服务生态,让数据赋能钢铁产业价值。
更多内容推荐:
• 了解更多 IoTDB 应用案例
相关文章:
替换OpenTSDB和HBase,宝武集团使用IoTDB助力钢铁设备智能运维
时序数据库 IoTDB 应用于宝武集团全基地钢铁时序数据管理,激活数据资产,赋能大型设备智能运维。 1. 背景概述 宝武装备智能科技有限公司(以下简称:宝武智维)是中国宝武设备智能运维专业化平台公司,30 余年始…...

MathGPT的原理介绍,在中小学数学教学的应用场景,以及代码样例实现
大家好,我是微学AI,今天给大家介绍一下MathGPT的原理介绍,在中小学数学教学的应用场景,以及代码样例实现。MathGPT的核心架构是一个精心设计的多层次系统,旨在有效处理复杂的数学问题。其主要组成部分包括 数学知识图谱…...

前端框架大比拼:React.js, Vue.js 及 Angular 的优势与适用场景探讨
文章目录 前言一、React.js特点使用方法适用场景 二、Vue.js特点使用方法适用场景 三、Angular特点使用方法适用场景 四、如何选择合适的前端框架五、前端框架对项目性能的影响结语 前言 随着互联网技术的飞速发展,前端开发已经从简单的页面展示演变为复杂的应用构…...

MySQL45讲 第二十讲 幻读是什么,幻读有什么问题?
文章目录 MySQL45讲 第二十讲 幻读是什么,幻读有什么问题?一、幻读的定义二、幻读带来的问题(一)语义问题(二)数据一致性问题 三、InnoDB 解决幻读的方法四、总结 MySQL45讲 第二十讲 幻读是什么࿰…...

MySQL技巧之跨服务器数据查询:进阶篇-从A数据库复制到B数据库的表中
MySQL技巧之跨服务器数据查询:进阶篇-从A数据库复制到B数据库的表中 基础篇已经描述:借用微软的SQL Server ODBC 即可实现MySQL跨服务器间的数据查询。 而且还介绍了如何获得一个在MS SQL Server 可以连接指定实例的MySQL数据库的连接名: MY_ODBC_MYSQ…...

【论文阅读】利用SEM二维图像表征黏土矿物三维结构
导言 在油气储层研究中,黏土矿物对流体流动的影响需要在微观尺度上理解,但传统的二维SEM图像难以完整地表征三维孔隙结构。常规的三维成像技术如FIB-SEM(聚焦离子束扫描电子显微镜)虽然可以获取高精度的3D图像,但成本…...

可靠UDP协议(KCP)使用说明
希望这篇文章,对学习和使用 KCP 协议的读者,有帮助。 1. KCPUDP 流程图 2. 示例代码(待补充) #include <iostream>int main() {// TODO: kcp examplereturn 0; }...

ffmpeg+D3D实现的MFC音视频播放器,支持录像、截图、音视频播放、码流信息显示等功能
一、简介 本播放器是在vs2019下开发,通过ffmpeg实现拉流解码功能,通过D3D实现视频的渲染功能。截图功能采用libjpeg实现,可以截取jpg图片,图片的默认保存路径是在C:\MYRecPath中。录像功能采用封装好的类Mp4Record实现,…...

【Flink】-- flink新版本发布:v2.0-preview1
目录 1、简介 2、非兼容变更 2.1、API 2.2、连接器适配计划 2.3、配置 2.4、其它 3、重要新特性 3.1、存算分离状态管理 3.2、物化表 3.3、批作业的自适应执行 3.4、流式湖仓 4、附加 4.1、非兼容性的 api 程序变更 4.1.2、Removed Classes # 4.1.3、Modified Cl…...

Node.js 版本管理的最终答案 Volta
文章目录 特点安装Unix系统安装Windows系统安装 常用命令volta fetchvolta installvolta uninstallvolta pinvolta listvolta completionsvolta whichvolta setupvolta runvolta help 建议 目前对于前端项目的node 版本,我们一般会在项目 package.json 的 engines 字…...

蓝桥杯每日真题 - 第11天
题目:(合并数列) 题目描述(14届 C&C B组D题) 解题思路: 题意理解:给定两个数组,目标是通过若干次合并操作使两个数组相同。每次合并操作可以将数组中相邻的两个数相加ÿ…...

Vue vs React:两大前端框架的区别解析
在现代前端开发中,Vue.js 和 React.js 是两个最受欢迎的框架和库。我们常常面临选择它们的困惑。虽然这两者在本质上都是为了构建用户界面而设计的,但它们在设计理念、使用方式和生态系统等方面有着显著的区别。今天,我们将通过深入分析这两个…...

【树莓派raspberrypi烧录Ubuntu远程桌面登入树莓派】
提示:本文利用的是Ubuntu主机和树莓派4B开发板,示例仅供参考 文章目录 一、树莓派系统安装下载前准备工作下载安装树莓派的官方烧录软件imagerimager的使用方法 二、主机与树莓SSH连接查看数梅派IP地址建立ssh连接更新树莓派源地址 三、主机端远程桌面配…...

c# 调用c++ 的dll 出现找不到函数入口点
今天在调用一个设备的dll文件时遇到了一点波折,因为多c 不熟悉,调用过程张出现了找不到函数入口点,一般我们使用c# 调用c 文件,还是比较简单。 [DllImport("AtnDll2.dll",CharSet CharSet.Ansi)]public static extern …...
LInux——环境基础开发工具使用(正在更新中...)
1.软件包管理器 Linux下安装软件的方案: 1. 源代码安装 2. rpm包安装 3. 包管理器安装 --- yum/ apt (此图片来自于比特就业课课件) 1.1 操作生态系统 好的操作系统定义: 生态环境好 不同的操作系统根本是生态不同(…...

linux 内核asmlinkage关键字总结
1,看一下asmlinkage的定义 CPP_ASMLINKAGE __attribute__((regparm(0))) GCC中使用__attribute__((regparm(n)))指定最多可以使用n个寄存器(eax, edx, ecx)传递参数,n的范围是0~3,超过n时则将参数压入栈中(…...

⚡️如何在 React 和 Next.js 项目里优雅的使用 Zustand
前言 你是否曾感觉在 React 中管理状态简直是一场噩梦?如果你已经厌倦了不停地处理 props、context 和 hooks,那么现在是时候认识 Zustand 了。Zustand 是一个轻量级的状态管理库,它简化了你处理应用状态的方式。在这篇文章中,我…...

Pinpoint(APM)进阶--Pinot指标采集(System Metric/Inspector)
接上文 Pinpoint使用Pinot进行指标数据存储,Pinot流摄入需要Kafka 本文详解Kafka和Pinot的安装部署,以及Pinpoint的指标采集 Pinot 简介 Apache Pinot是一个实时分布式OLAP数据存储,专为低延迟、高吞吐量分析而构建,非常适合面…...

Mysql:使用binlog的一些常用技巧
1、如何查看binlog的存放路径 show variables like log% 执行结果: 2、如何清除binlog (1)按时间清除 purge binary logs before ‘2023-06-5 10:12:00’ (2)按文件文件名清除 purge binary logs to ‘mybinlog.0000…...

Electron 项目启动外部可执行文件的几种方式
Electron 项目启动外部可执行文件的几种方式 序言 在开发 Electron 应用程序时,有时需要启动外部的可执行文件(如 .exe 文件)。这可能是为了调用系统工具、运行第三方软件或者集成现有的应用程序。 Electron 提供了多种方式来启动外部可执行…...

NoFences:免费开源的Windows桌面整理神器,让杂乱图标瞬间归位
NoFences:免费开源的Windows桌面整理神器,让杂乱图标瞬间归位 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为Windows桌面上堆积如山的图标而烦…...

Unity+C#开发万人MMO服务器的实战架构与同步优化
1. 这不是“写个服务器”那么简单:先撕开“万人在线”的真实含义很多人看到“UnityC#开发万人MMO服务器”这个标题,第一反应是:“哦,用Unity做客户端,C#写个后端,Socket连一连,再加个数据库&…...
)
今日算法(二叉搜索树)
题目描述给定一棵二叉搜索树(BST)的根节点 root,树中节点值各不相同。要求将其转换为累加树(Greater Sum Tree),规则如下:每个节点的新值 原节点值 所有比它大的节点值的总和二叉搜索树的性质…...
Translumo:实时屏幕翻译工具的完整实战指南
Translumo:实时屏幕翻译工具的完整实战指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否在玩外语游戏…...

Vanrafia阿曲生坦Atrasentan副作用贫血及头痛严重时如何治疗?
贫血与头痛是Vanrafia阿曲生坦治疗IgA肾病时最受临床关注的两项全身性不良反应。贫血侵蚀着患者的日常功能与运动耐量,头痛则是最常见的神经系统不适主诉。ALIGN三期临床试验及其长期扩展研究的完整安全性数据,为这两项副作用勾勒出了精确且不容回避的风…...

TDengine Tag 设计哲学与 Schema 变更机制
2.数据模型 > 04 Tag 设计哲学与 Schema 变更机制 — 静态属性建模与在线结构演进 适用版本:TDengine v3.x(v3.3.x / v3.4.x) | 最后更新:2026-05-16 概述 Tag(标签)是 TDengine 数据模型中区别于传统…...
)
主产区安全整改深化 行业加速洗牌(5 月 21 日)
1.湖南浏阳等产区开展全覆盖排查,重点整治违规库存、超量存放、追溯缺失等问题。 2.中小零售点面临搬迁 / 关停,合规化与信息化追溯成生存门槛。 3.海外市场:美国堪萨斯城皇家队赛事烟花秀(5 月 22 日),赛事…...

YAML | The Norway Problem
注:本文为 “YAML | The Norway Problem” 相关合辑。 英文引文,机翻未校。 略作重排,如有内容异常,请看原文。 The Norway Problem - why StrictYAML refuses to do implicit typing and so should you 挪威问题 - 为什么 Stric…...

OpenSCENARIO与OpenDRIVE如何协同工作?一份给仿真工程师的避坑指南
OpenSCENARIO与OpenDRIVE协同工程实践:从原理到避坑全指南 自动驾驶仿真测试中,动态场景与静态地图的精准配合如同交响乐团的指挥与乐谱——OpenSCENARIO负责编排车辆行为,OpenDRIVE则定义道路的物理结构。当两者协同出现毫米级偏差ÿ…...

探索AI图像智能标注新范式:ComfyUI JoyCaptionAlpha Two插件深度指南
探索AI图像智能标注新范式:ComfyUI JoyCaptionAlpha Two插件深度指南 【免费下载链接】ComfyUI_SLK_joy_caption_two ComfyUI Node 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI_SLK_joy_caption_two 在AI图像生成与内容创作领域,手动为…...