Elman 神经网络算法详解
Elman 神经网络算法详解
一、引言
Elman 神经网络作为一种经典的递归神经网络(RNN),在处理动态系统和时间序列数据方面具有独特的优势。它通过特殊的结构设计,能够有效地捕捉数据中的时间依赖关系,在语音识别、自然语言处理、系统建模与预测等众多领域都有着广泛的应用。本文将对 Elman 神经网络算法进行全面深入的讲解,包括其网络结构、工作原理、训练算法,并通过大量的代码示例来展示其实现过程。
二、Elman 神经网络的结构
(一)输入层
输入层接收外部输入数据,其节点数量由输入数据的特征维度决定。例如,若输入是一个二维向量,如 ( x 1 , x 2 ) (x_1, x_2) (x1,x2),则输入层有两个节点。设输入向量为 x ( t ) x(t) x(t),在时间步 t t t,它为网络提供当前时刻的信息。
(二)隐含层
隐含层是 Elman 神经网络进行信息处理的核心部分。它包含多个神经元,每个神经元接收来自输入层和上下文层的输入。设隐含层神经元数量为 n n n,隐含层神经元 i i i 的激活函数为 f ( ⋅ ) f(\cdot) f(⋅)。隐含层的输出不仅取决于当前时刻的输入,还与上一时刻的状态有关。
(三)上下文层(Context Layer)
上下文层是 Elman 神经网络区别于传统前馈神经网络的关键结构。它的节点数量与隐含层神经元数量相同,用于存储隐含层上一时刻的输出状态。在每个时间步,上下文层将上一时刻的隐含层输出反馈给隐含层,使得网络具有了记忆能力,能够处理时间序列数据中的动态信息。
(四)输出层
输出层根据隐含层的输出产生最终的预测结果。输出层节点数量由输出变量的数量决定。例如,如果要预测一个单一的值,输出层可能只有一个节点;如果要预测多个相关的值,如同时预测温度、湿度和气压,则输出层有相应数量的节点。
三、Elman 神经网络的工作原理
(一)前向传播
- 隐含层计算
在时间步 t t t,隐含层神经元 i i i 的净输入 n e t i ( t ) net_i(t) neti(t) 是输入层输入与上下文层反馈输入的加权和。设输入层到隐含层的连接权重矩阵为 W i h W_{ih} Wih,上下文层到隐含层的连接权重矩阵为 W h c W_{hc} Whc,则:
n e t i ( t ) = ∑ j = 1 m W i h i j x j ( t ) + ∑ k = 1 n W h c i k c k ( t − 1 ) net_i(t)=\sum_{j=1}^{m}W_{ih_{ij}}x_j(t)+\sum_{k = 1}^{n}W_{hc_{ik}}c_k(t - 1) neti(t)=∑j=1mWihijxj(t)+∑k=1nWhcikck(t−1)
其中, m m m 是输入层节点数量, c k ( t − 1 ) c_k(t - 1) ck(t−1) 是上下文层第 k k k 个节点在上一时刻( t − 1 t - 1 t−1)的值。
隐含层神经元 i i i 的输出 h i ( t ) h_i(t) hi(t) 通过激活函数计算:
h i ( t ) = f ( n e t i ( t ) ) h_i(t)=f(net_i(t)) hi(t)=f(neti(t))
- 输出层计算
设隐含层到输出层的连接权重矩阵为 W h o W_{ho} Who,输出层节点 l l l 的净输入 n e t l ( t ) net_l(t) netl(t) 为:
n e t l ( t ) = ∑ i = 1 n W h o l i h i ( t ) net_l(t)=\sum_{i=1}^{n}W_{ho_{li}}h_i(t) netl(t)=∑i=1nWholihi(t)
输出层节点 l l l 的输出 y l ( t ) y_l(t) yl(t) 根据输出层的激活函数(如果有)计算得到。如果输出层是线性输出,则 y l ( t ) = n e t l ( t ) y_l(t)=net_l(t) yl(t)=netl(t)。
- 上下文层更新
在完成当前时间步的前向传播后,上下文层更新其值,将当前时刻隐含层的输出保存下来,用于下一个时间步:
c i ( t ) = h i ( t ) , i = 1 , 2 , ⋯ , n c_i(t)=h_i(t), \quad i = 1, 2, \cdots, n ci(t)=hi(t),i=1,2,⋯,n
(二)误差反向传播与训练
- 误差计算
定义损失函数来衡量网络输出与实际目标输出之间的差异。常见的损失函数如均方误差(MSE):
E = 1 2 ∑ t ∑ l ( y l ( t ) − y ^ l ( t ) ) 2 E=\frac{1}{2}\sum_{t}\sum_{l}(y_l(t)-\hat{y}_l(t))^2 E=21∑t∑l(yl(t)−y^l(t))2
其中, y ^ l ( t ) \hat{y}_l(t) y^l(t) 是实际目标输出, y l ( t ) y_l(t) yl(t) 是网络预测输出。
- 反向传播算法(Back Propagation Through Time,BPTT)
与传统的前馈神经网络的反向传播算法类似,但由于 Elman 神经网络的递归性质,需要在时间维度上展开网络来计算梯度。
- 对于输出层到隐含层权重 W h o W_{ho} Who 的梯度计算:
根据链式法则,计算 ∂ E ∂ W h o l i \frac{\partial E}{\partial W_{ho_{li}}} ∂Wholi∂E。先计算 ∂ E ∂ n e t l ( t ) \frac{\partial E}{\partial net_l(t)} ∂netl(t)∂E,对于均方误差损失函数和线性输出层, ∂ E ∂ n e t l ( t ) = ( y l ( t ) − y ^ l ( t ) ) \frac{\partial E}{\partial net_l(t)}=(y_l(t)-\hat{y}_l(t)) ∂netl(t)∂E=(yl(t)−y^l(t))。然后通过 ∂ n e t l ( t ) ∂ W h o l i = h i ( t ) \frac{\partial net_l(t)}{\partial W_{ho_{li}}}=h_i(t) ∂Wholi∂netl(t)=hi(t) 得到 ∂ E ∂ W h o l i \frac{\partial E}{\partial W_{ho_{li}}} ∂Wholi∂E。 - 对于隐含层到输入层权重 W i h W_{ih} Wih 和上下文层到隐含层权重 W h c W_{hc} Whc 的梯度计算:
这部分计算更为复杂,因为需要考虑时间序列的递归关系。以计算 ∂ E ∂ W i h i j \frac{\partial E}{\partial W_{ih_{ij}}} ∂Wihij∂E 为例,需要通过隐含层输出对 W i h i j W_{ih_{ij}} Wihij 的导数以及时间序列上的累积效应来计算。具体计算涉及到对每个时间步的误差反向传播和梯度累加。
- 权重更新
根据计算得到的梯度,使用梯度下降算法或其变体(如随机梯度下降、Adam 等优化算法)来更新权重。例如,使用梯度下降算法更新 W h o W_{ho} Who 的公式为:
W h o l i ( t + 1 ) = W h o l i ( t ) − η ∂ E ∂ W h o l i W_{ho_{li}}(t + 1)=W_{ho_{li}}(t)-\eta\frac{\partial E}{\partial W_{ho_{li}}} Wholi(t+1)=Wholi(t)−η∂Wholi∂E
其中, η \eta η 是学习率。
四、Elman 神经网络的代码实现
(一)使用 Python 和 NumPy 实现基本的 Elman 神经网络结构(简化示例)
import numpy as np# 激活函数,这里使用 Sigmoid 函数
def sigmoid(x):return 1 / (1 + np.exp(-x))# Elman 神经网络类
class ElmanNetwork:def __init__(self, input_size, hidden_size, output_size):self.input_size = input_sizeself.hidden_size = hidden_sizeself.output_size = output_size# 随机初始化权重self.W_ih = np.random.rand(self.hidden_size, self.input_size)self.W_hc = np.random.rand(self.hidden_size, self.hidden_size)self.W_ho = np.random.rand(self.output_size, self.hidden_size)# 初始化上下文层self.context_layer = np.zeros((self.hidden_size, 1))def forward_propagation(self, input_data):# 输入层到隐含层计算input_data = np.reshape(input_data, (-1, 1))hidden_net_input = np.dot(self.W_ih, input_data) + np.dot(self.W_hc, self.context_layer)hidden_layer_output = sigmoid(hidden_net_input)# 更新上下文层self.context_layer = hidden_layer_output# 隐含层到输出层计算output_layer_net_input = np.dot(self.W_ho, hidden_layer_output)output_layer_output = sigmoid(output_layer_net_input)return output_layer_outputdef back_propagation(self, input_data, target_output):m = 1 # 这里假设每次只输入一个样本,批量大小为 1dZ_output = self.forward_propagation(input_data) - np.reshape(target_output, (-1, 1))dW_ho = np.dot(dZ_output, self.context_layer.T)dZ_hidden = np.dot(self.W_ho.T, dZ_output) * (self.context_layer * (1 - self.context_layer))dW_ih = np.dot(dZ_hidden, np.reshape(input_data, (1, -1)))dW_hc = np.dot(dZ_hidden, self.context_layer.T)return dW_ih, dW_hc, dW_hodef update_weights(self, dW_ih, dW_hc, dW_ho, learning_rate):self.W_ih -= learning_rate * dW_ihself.W_hc -= learning_rate * dW_hcself.W_ho -= learning_rate * dW_ho
(二)训练 Elman 神经网络示例
# 训练数据,这里简单示例,假设输入是一个一维数据,目标输出也是一维
input_data = np.array([[0.1], [0.2], [0.3], [0.4], [0.5]])
target_output = np.array([[0.2], [0.4], [0.6], [0.8], [1.0]])# 创建 Elman 神经网络实例
elman_network = ElmanNetwork(input_size=1, hidden_size=5, output_size=1)learning_rate = 0.1
epochs = 100for epoch in range(epochs):for i in range(len(input_data)):input_vector = input_data[i]target = target_output[i]dW_ih, dW_hc, dW_ho = elman_network.back_propagation(input_vector, target)elman_network.update_weights(dW_ih, dW_hc, dW_ho, learning_rate)# 可以在这里添加代码来计算每个 epoch 的损失,评估训练效果
五、Elman 神经网络的应用
(一)时间序列预测
- 经济领域
在预测股票价格、汇率、通货膨胀率等经济指标时,Elman 神经网络可以利用历史数据中的时间依赖关系。例如,通过分析过去一段时间内的股票价格走势、成交量等信息,预测未来的股票价格变化。它可以捕捉到市场中的短期和中期趋势,为投资者提供决策支持。 - 气象预测
对于气温、降水量、风速等气象数据,这些数据通常具有明显的季节性和周期性特征。Elman 神经网络可以处理这些时间序列数据,结合历史气象数据来预测未来的天气状况,提高气象预报的准确性。
(二)动态系统建模
- 工业过程控制
在化工生产、电力系统等工业领域,许多过程参数(如温度、压力、流量等)随时间动态变化。Elman 神经网络可以对这些动态过程进行建模,通过实时监测输入参数和系统状态,预测系统的未来状态,从而实现对工业过程的优化控制,提高生产效率和产品质量。 - 机器人运动控制
对于机器人的运动轨迹规划和控制,机器人的关节角度、速度等参数随时间变化。Elman 神经网络可以学习机器人运动的动力学特性,根据当前的运动状态和目标,预测下一步的运动参数,实现更精确和灵活的机器人运动控制。
(三)语音和自然语言处理
- 语音识别
在语音信号处理中,语音是一种连续的时间序列信号。Elman 神经网络可以处理语音的声学特征随时间的变化,识别不同的语音单元(如音素、音节等),进而将语音信号转换为文本。它可以利用语音信号中的上下文信息,提高语音识别的准确率,尤其是在处理连续语音和口音等复杂情况下。 - 自然语言理解
对于自然语言文本,句子中的单词顺序和语义关系具有时间序列的特点。Elman 神经网络可以对句子进行建模,分析单词之间的语法和语义依赖关系,用于词性标注、命名实体识别、语义角色标注等自然语言处理任务,帮助计算机更好地理解自然语言文本。
六、Elman 神经网络的优缺点
(一)优点
- 对时间序列的适应性
由于其特殊的上下文层结构,能够有效处理时间序列数据中的动态信息,捕捉数据中的时间依赖关系,这是传统的前馈神经网络所不具备的优势。 - 相对简单的结构
与一些更复杂的递归神经网络(如长短期记忆网络(LSTM)和门控循环单元(GRU))相比,Elman 神经网络的结构和算法相对简单,易于理解和实现,在一些对计算资源和时间要求较高的应用场景中具有一定的优势。
(二)缺点
- 长时依赖问题
虽然 Elman 神经网络可以处理一定程度的时间依赖,但在处理长时依赖关系时存在困难。随着时间间隔的增大,网络可能会丢失早期的信息,因为梯度在长时间的反向传播过程中可能会消失或爆炸,导致无法有效地学习长时依赖关系。 - 训练复杂度
由于需要在时间维度上展开网络进行误差反向传播,训练过程相对复杂,尤其是对于较长的时间序列数据。同时,训练过程中可能需要仔细调整学习率等参数,以避免训练过程中的不稳定现象,如梯度消失或爆炸,这增加了训练的难度和计算成本。
七、结论
Elman 神经网络算法作为一种重要的递归神经网络算法,在处理时间序列数据和动态系统建模方面有着独特的优势。通过其特殊的网络结构和基于 BPTT 的训练算法,它能够在多个领域实现有效的数据处理和预测。然而,它也存在一些局限性,如长时依赖问题和训练复杂度。在实际应用中,需要根据具体的问题场景和数据特点,合理选择和使用 Elman 神经网络,或者考虑与其他技术相结合,以克服其缺点,发挥其最大的价值。随着神经网络研究的不断发展,Elman 神经网络也为进一步改进和创新递归神经网络算法提供了重要的基础和启示。
相关文章:

Elman 神经网络算法详解
Elman 神经网络算法详解 一、引言 Elman 神经网络作为一种经典的递归神经网络(RNN),在处理动态系统和时间序列数据方面具有独特的优势。它通过特殊的结构设计,能够有效地捕捉数据中的时间依赖关系,在语音识别、自然语…...
)
卓胜微嵌入式面试题及参考答案(2万字长文)
freeRTOS 任务是怎么调度的? 在 freeRTOS 中,任务调度主要是基于优先级的抢占式调度。每个任务都有一个优先级,系统会根据任务的优先级来决定哪个任务获得 CPU 的使用权。 当一个高优先级的任务准备运行,并且当前运行的任务优先级较低时,高优先级任务会抢占 CPU。例如,假…...

【Python】爬虫使用代理IP
1、代理池 IP 代理池可以理解为一个池子,里面装了很多代理IP。 池子里的IP是有生命周期的,它们将被定期验证,其中失效的将被从池子里面剔除池子里的ip是有补充渠道的,会有新的代理ip不断被加入池子中池子中的代理ip是可以被随机…...
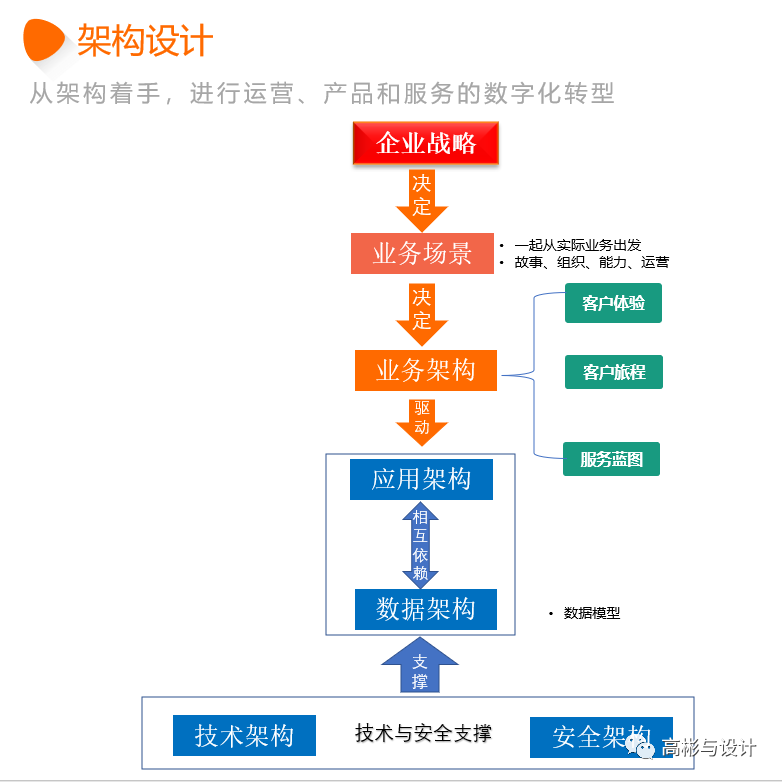
金融机构-业务架构方案(高光版)
一、金融机构的设计架构 首先视角很重要,比如这样的战略视角,站得高、看得远。设计业务架构,一定要有战略高度和前瞻性。 二、什么样的架构更适合你们公司呢? 三、从架构着手,进行产品和服务创新性变革 四、具体如何设计业务架构呢?...

ubuntu内核切换network unclaimed 网卡丢失
现象一、 查网络的时候 提示只有lo network unclaimed wifi 本地局域网全部丢失 显卡丢失 解决思路 首先查看了 网卡类型 sudo lshw -C network 会显示使用的网卡 然后把这个网卡 去到realtek的官网去找驱动 驱动下下来发现debug提示 没有build目录 /libs/modules/6.8…...
【人工智能】揭秘可解释性AI(XAI):从原理到实战的终极指南
文章目录 开篇:AI的黑箱时代,你准备好揭开真相了吗?🔍什么是可解释性AI(XAI)?XAI的定义XAI的分类 可解释性AI的重要性与价值建立用户信任遵循法规和伦理发现和纠正模型偏见提高模型性能促进跨领…...

小面馆叫号取餐流程 佳易王面馆米线店点餐叫号管理系统操作教程
一、概述 【软件资源文件下载在文章最后】 小面馆叫号取餐流程 佳易王面馆米线店点餐叫号管理系统操作教程 点餐软件以其实用的功能和简便的操作,为小型餐饮店提供了高效的点餐管理解决方案,提高了工作效率和服务质量 点餐管理:支持电…...

图形 2.6 伽马校正
伽马校正 B站视频:图形 2.6 伽马校正 文章目录 伽马校正颜色空间传递函数 Gamma校正校正过程为什么需要校正?CRT与转换函数 为什么sRGB在Gamma 0.45空间? 人对亮度的敏感韦伯定律中灰值 线性工作流不在线性空间下进行渲染的问题统一到线性空…...

LLM - 计算 多模态大语言模型 的参数量(Qwen2-VL、Llama-3.1) 教程
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/143749468 免责声明:本文来源于个人知识与公开资料,仅用于学术交流,欢迎讨论,不支持转载。 影响 (…...

数据可视化这样做,汇报轻松拿捏(附免费好用可视化工具推荐)
一、数据可视化的定义 数据可视化是数据分析中重要的工作之一。在完成数据采集之后,通过可视化方式,将数据转化为美观且浅显易懂的统计图/表/视频,从而进一步解读数据背后隐藏的价值,这种方数据处理方式就叫做数据可视化。近些年…...
 进行API认证和鉴权(Java版))
杂七杂八之基于JSON Web Token (JWT) 进行API认证和鉴权(Java版)
杂七杂八之基于JSON Web Token (JWT) 进行API认证和鉴权(Java版) 在现代Web应用和API开发中,JSON Web Token (JWT) 是一种广泛使用的认证和鉴权机制。JWT不仅简化了认证流程,还提供了安全的令牌传递方式,使得跨域认证…...
建设展示型网站企业渠道用户递达
展示型网站的主要作用便是作为企业线上门户平台、信息承载形式、拓客咨询窗口、服务/产品宣传订购、其它内容/个人形式呈现等,网站发展多年,现在依然是企业线上发展的主要工具之一且有建设的必要性。 谈及整体价格,自制、定制开发、SAAS系统…...

如何通过AB测试找到最适合的Yandex广告内容
想要在Yandex上找到最能吸引目标受众的广告内容,A/B测试是一个不可或缺的步骤。通过对比不同版本的广告,我们可以发现哪些元素最能引起用户的共鸣。首先,设计两个或多个广告版本,确保每个版本在标题、文案、图片等关键元素上有所不…...

AI写作(四)预训练语言模型:开启 AI 写作新时代(4/10)
一、预训练语言模型概述 预训练语言模型在自然语言处理领域占据着至关重要的地位。它以其卓越的语言理解和生成能力,成为众多自然语言处理任务的关键工具。 预训练语言模型的发展历程丰富而曲折。从早期的神经网络语言模型开始,逐渐发展到如今的大规…...

解决Anaconda出现CondaHTTPError: HTTP 000 CONNECTION FAILED for url
解决Anaconda出现CondaHTTPError: HTTP 000 CONNECTION FAILED for url 第一类情况 在anaconda创建新环境时,使用如下代码 conda create -n charts python3.7 错误原因: 默认镜像源访问速度过慢,会导致超时从而导致更新和下载失败。 解决方…...
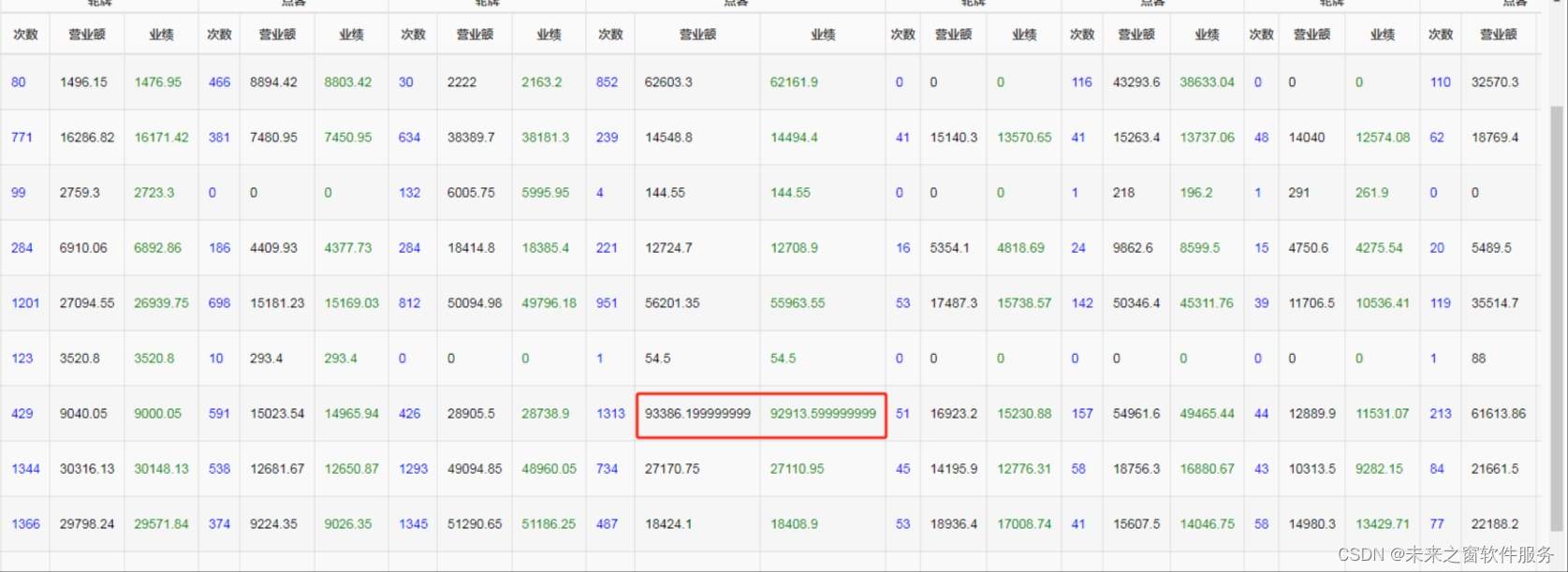
员工绩效统计出现很多小数点,处理方法大全
1.直接通过数据库修改数据类型 譬如采用DECIMAL类型 2.float 降低小数点位数 3.php 采用round函数...

【启明智显分享】5G CPE为什么适合应用在连锁店中?
连锁门店需要5G CPE来满足其日益增长的网络需求,提升整体运营效率和竞争力。那么为什么5G CPE适合连锁店应用呢,小编为此做了整理,主要是基于以下几个方面的原因: 一、高效稳定的网络连接 1、高速数据传输: 5G CPE能…...

十大经典排序算法-希尔排序与归并排序
1、希尔排序 希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是非稳定排序算法。 希尔排序是基于插入排序的以下两点性质而提出改进方法的: 插入排序在对几乎已经排好序的数据操作时,效率高&…...

gitlab和jenkins连接
一:jenkins 配置 安装gitlab插件 生成密钥 id_rsa 要上传到jenkins,id_rsa.pub要上传到gitlab cat /root/.ssh/id_rsa 复制查看的内容 可以看到已经成功创建出来了对于gitlab的认证凭据 二:配置gitlab cat /root/.ssh/id_rsa.pub 复制查…...

Qt Event事件系统小探2
目录 事件过滤器 来看一个例子 拖放事件和拖放操作 Qt官方文档给出的说明 拖放 拖放类 配置 拖动 放置 覆盖建议的操作 子类化复杂窗口小部件 拖放操作 添加新的拖放类型 放置操作 放置矩形 剪贴板 其他函数的介绍 事件过滤器 我们知道,有的时候想…...

LRCGET:如何一键批量下载本地音乐歌词的终极指南
LRCGET:如何一键批量下载本地音乐歌词的终极指南 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否厌倦了为每一首本地音乐手动寻找歌词…...

[智能体-2]:openAI API详解
下面从核心概念→认证→接口→参数→流式→函数调用→计费→国内兼容→最佳实践,把 OpenAI API 讲透。一、OpenAI API 是什么OpenAI API 一套标准化的 RESTful 大模型调用协议,基于 HTTP/JSON,提供:文本对话(GPT-4o/3…...

本地虚拟机停电启动异常:原理、诊断与四步修复
1. 停电不是“按了关机键”,而是对虚拟化环境的一次暴力断电冲击你有没有经历过这样的场景:凌晨三点,小区突然跳闸,家里那台跑着三台生产级虚拟机的NUC主机黑屏了;第二天早上开机,宿主机系统能进࿰…...

Unity PC端微信扫码登录:不拉起浏览器的原生UI集成方案
1. 这不是“微信扫码登录”的常规玩法,而是PC端Unity游戏的UI原生集成方案你有没有遇到过这样的场景:在Unity开发的PC单机游戏或局域网对战工具里,想让用户用微信账号快速登录,但一接入微信开放平台的标准OAuth2流程,点…...

嵌入式开发通用工具包设计:提升效率与代码质量的核心架构
1. 项目概述:为什么嵌入式开发需要一个“工具箱”?干了十几年嵌入式,从8位单片机玩到多核ARM Cortex-A,我最大的感受就是:重复造轮子和调试效率低下是拖慢项目进度的两大元凶。每次新项目启动,都得重新搭建…...
)
STM32 USB开发避坑指南:手把手教你读懂并配置端点描述符(附完整代码)
STM32 USB开发避坑指南:手把手教你读懂并配置端点描述符(附完整代码) 在嵌入式开发领域,USB通信一直是让工程师又爱又恨的技术。爱它的通用性和高速传输能力,恨它那晦涩难懂的协议栈和层出不穷的配置问题。特别是当项目…...
返回False)
保姆级排查指南:PyTorch装完CUDA不认账?手把手教你搞定torch.cuda.is_available()返回False
保姆级排查指南:PyTorch装完CUDA不认账?手把手教你搞定torch.cuda.is_available()返回False 刚装好PyTorch准备大展拳脚,结果torch.cuda.is_available()无情地返回False?这种挫败感我太懂了。作为过来人,我整理了这份…...
:发现其隐式支持马拉地语-印地语混合语境)
独家逆向分析ElevenLabs印地文语音模型架构(基于HTTP/3流量捕获+声学特征聚类):发现其隐式支持马拉地语-印地语混合语境
更多请点击: https://codechina.net 第一章:ElevenLabs印地文语音模型的逆向分析背景与核心发现 近年来,ElevenLabs 以高保真多语言语音合成能力著称,但其印地文(Hindi)语音模型未公开架构细节、训练数据构…...

免费图片去水印工具在线网站有哪些?2026年图片水印去除APP和软件推荐
在日常工作和生活中,我们经常会遇到需要去除图片水印的情况。无论是为了社交媒体分享、内容创作还是素材整理,找到一款高效的免费去水印工具都能节省不少时间。本文将为你详细介绍2026年最实用的免费图片去水印工具,包括在线网站、手机APP和电…...

RISC-V指令类型及核心功能解析
RV32I指令集通过六种基本指令格式(R、I、S、B、U、J)实现其核心功能,其中U型指令主要用于长立即数加载,而R、I、S、B、J型指令则承担了计算、访存、控制流等关键操作。根据博客内容提供的指令映射表(表2.3)…...