用pyspark把kafka主题数据经过etl导入另一个主题中的有关报错
首先看一下我们的示例代码
import os
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
"""
------------------------------------------Description : TODO:SourceFile : etl_stream_kafkaAuthor : zxxDate : 2024/11/14
-------------------------------------------
"""
if __name__ == '__main__':os.environ['JAVA_HOME'] = 'D:/bigdata/03-java/java-8/jdk'# 配置Hadoop的路径,就是前面解压的那个路径os.environ['HADOOP_HOME'] = 'D:/bigdata/04-Hadoop/hadoop/hadoop-3.3.1/hadoop-3.3.1'# 配置base环境Python解析器的路径os.environ['PYSPARK_PYTHON'] = 'D:/bigdata/22-spark/Miniconda3/python.exe' # 配置base环境Python解析器的路径os.environ['PYSPARK_DRIVER_PYTHON'] = 'D:/bigdata/22-spark/Miniconda3/python.exe'spark = SparkSession.builder.master("local[2]").appName("etl_stream_kafka").config("spark.sql.shuffle.partitions", 2).getOrCreate()# 连接kafkareadDF = spark.readStream.format("kafka") \.option("kafka.bootstrap.servers", "bigdata01:9092") \.option("subscribe", "topicA") \.load()# 使用DSL语句etlDF = readDF.selectExpr("cast(value as STRING)").filter(F.col("value").contains("success"))etlDF.writeStream \.format("kafka") \.option("kafka.bootstrap.servers", "bigdata01:9092") \.option("topic", "etlTopic") \.option("checkpointLocation", "../../datas/kafka_stream") \.start().awaitTermination()# 关闭spark.stop()
运行发现报错
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Traceback (most recent call last):File "D:\bigdata\18-python\pyspark_project\pythonProject1\main\streamingkafka\etl_stream_kafka.py", line 22, in <module>readDF = spark.readStream.format("kafka") \File "D:\bigdata\22-spark\Miniconda3\lib\site-packages\pyspark\sql\streaming.py", line 482, in loadreturn self._df(self._jreader.load())File "D:\bigdata\22-spark\Miniconda3\lib\site-packages\py4j\java_gateway.py", line 1304, in __call__return_value = get_return_value(File "D:\bigdata\22-spark\Miniconda3\lib\site-packages\pyspark\sql\utils.py", line 117, in decoraise converted from None
pyspark.sql.utils.AnalysisException: Failed to find data source: kafka. Please deploy the application as per the deployment section of "Structured Streaming + Kafka Integration Guide".
报错 : org.apache.spark.sql.AnalysisException: Failed to find data source: kafka. Please deploy the application as per the deployment section of "Structured Streaming + Kafka Integration Guide".;
解决:这个是因为缺少了Kafka和Spark的集成包,前往https://mvnrepository.com/artifact/org.apache.spark
下载对应的jar包即可,比如我是SparkSql写入的Kafka,那么我就需要下载Spark-Sql-Kafka.x.x.x.jar

进入网站(已打包放入文章末尾)

找到对应有关spark 和kafka的模块

找到对应的版本 ,这里我用的kafka是3.0版本,下载的是3.1.2版本

点进去,下载jar包

再次运行会发现仍然报错,这是因为jar包之间的依赖关系,从刚才下载的界面下面再下载有关的jar包





再次运行即可
jar包下载链接
【免费】用pyspark把数据从kafka的一个主题用流处理后再导入kafka的另一个主题的有关报错资源-CSDN文库
相关文章:
用pyspark把kafka主题数据经过etl导入另一个主题中的有关报错
首先看一下我们的示例代码 import os from pyspark.sql import SparkSession import pyspark.sql.functions as F """ ------------------------------------------Description : TODO:SourceFile : etl_stream_kafkaAuthor : zxxDate : 2024/11/…...

Redis的过期删除策略和内存淘汰机制以及如何保证双写的一致性
Redis的过期删除策略和内存淘汰机制以及如何保证双写的一致性 过期删除策略内存淘汰机制怎么保证redis双写的一致性?更新策略先删除缓存后更新数据库先更新数据库后删除缓存如何选择?如何保证先更新数据库后删除缓存的线程安全问题? 过期删除策略 为了…...

异常处理:import cv2时候报错No module named ‘numpy.core.multiarray‘
问题描述 执行一个将视频变成二值视频输出时候,报错。No module named numpy.core.multiarray,因为应安装过了numpy,所以比较不解。试了卸载numpy和重新安装numpy多次操作,也进行了numpy升级的操作,但是都没有用。 解…...

C++手写PCD文件
前言 一般pcd读写只需要调pcl库接口,直接用pcl的结构写就好了 这里是不依赖pcl库的写入方法 主要是开头写一个header 注意字段大小,类型不要写错 结构定义 写入点需要与header中定义一致 这里用的RoboSense的结构写demo 加了个1字节对齐 stru…...

优选算法(双指针)
1.双指针介绍 双指针算法是一种常用的算法思想,特别适用于处理涉及阵列、链表或字符串等线性数据结构的问题。通过操作两个一个指针来进行导航或操作数据结构,双指针可以最大程度优化解决方案的效率。提高效率并减少空间复杂度。 在Java中使用双指针的核…...
【保姆级】Mac上IDEA卡顿优化
保姆级操作,跟着操作即可~~~ 优化内存 在你的应用程序中,找到你的idea 按住control键+单击 然后点击“显示包内容” </...
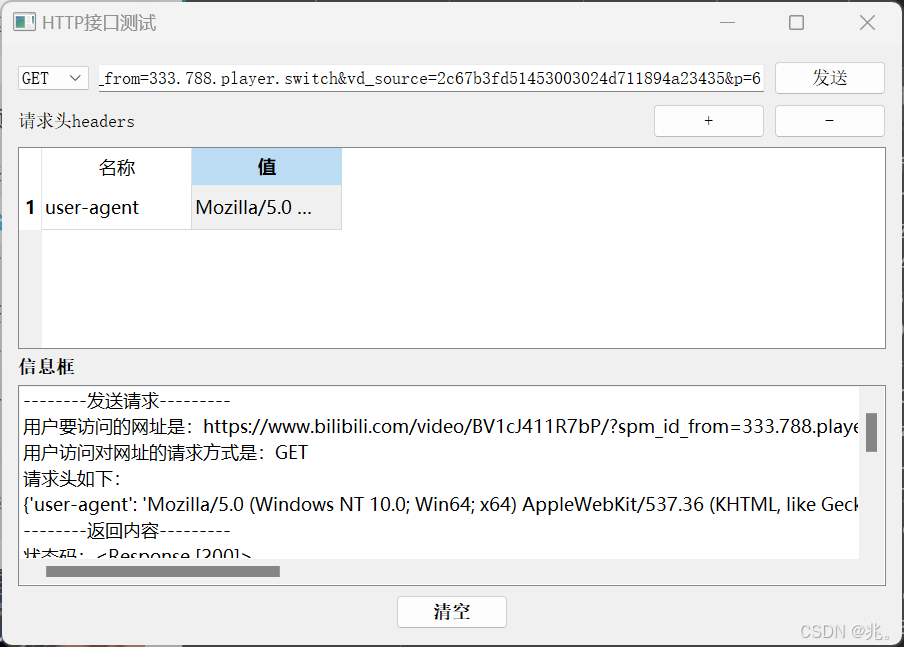
python实战案例----使用 PyQt5 构建简单的 HTTP 接口测试工具
python实战案例----使用 PyQt5 构建简单的 HTTP 接口测试工具 文章目录 python实战案例----使用 PyQt5 构建简单的 HTTP 接口测试工具项目背景技术栈用户界面核心功能实现结果展示完整代码总结 在现代软件开发中,测试接口的有效性与响应情况变得尤为重要。本文将指导…...

pytest 接口串联场景
在编写接口测试时,如果有多个接口需要串联在一起调用,并且这些接口共同构成了一个业务场景,通常可以使用以下几种方法来组织代码,使其更具可读性和维护性。以下是一些规范的建议: 1. 使用 pytest 的 fixture 来管理接…...

Springboot项目搭建(2)-用户详细信息查询
1. 提要信息 1.1 java四类八种 在Java中,四类指的是Java中的基本数据类型和引用数据类型: 基本数据类型:Java提供了八种基本数据类型,包括整数型、浮点型、字符型和布尔型。引用数据类型:指向对象的引用,…...

Stable Diffusion的加噪和去噪详解
SD模型原理: Stable Diffusion概要讲解Stable diffusion详细讲解Stable Diffusion的加噪和去噪详解Diffusion ModelStable Diffusion核心网络结构——VAEStable Diffusion核心网络结构——CLIP Text EncoderStable Diffusion核心网络结构——U-NetStable Diffusion中…...

解决 Gradle 报错:`Plugin with id ‘maven‘ not found` 在 SDK 开发中的问题
在 SDK 开发过程中,使用 Gradle 构建和发布 SDK 是常见的任务。在将 SDK 发布为 AAR 或 JAR 包时,你可能会使用 apply plugin: maven 来发布到本地或远程的 Maven 仓库。但是,随着 Gradle 版本的更新,特别是从 Gradle 7 版本开始&…...

EMD-KPCA-Transformer多变量回归预测!分解+降维+预测!多重创新!直接写核心!
EMD-KPCA-Transformer多变量回归预测!分解降维预测!多重创新!直接写核心! 目录 EMD-KPCA-Transformer多变量回归预测!分解降维预测!多重创新!直接写核心!效果一览基本介绍程序设计参…...

前端 px、rpx、em、rem、vh、vw计量单位的区别
目录 一、px 二、rpx 三、em 四、rem 五、vh和vw 六、rpx 和 px之间的区别 七、px 与 rem 的区别 一、px px(像素): 1、相对单位,代表屏幕上的一个基本单位,逻辑像素。 2、不会根据屏幕尺寸或分辨率自动调整大…...

OceanBase数据库产品与工具介绍
OceanBase:蚂蚁集团自主研发的分布式关系数据库 1、什么是 OceanBase? OceanBase 是由蚂蚁集团完全自主研发的企业级分布式关系数据库,始创于 2010 年。它具有以下核心特点: 数据强一致性:在分布式架构下确保数据强…...

学习threejs,对模型多个动画切换展示
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:threejs gis工程师 文章目录 一、🍀前言1.1 ☘️THREE.AnimationMixer 动画…...

【Bug合集】——Java大小写引起传参失败,获取值为null的解决方案
阿华代码,不是逆风,就是我疯 你们的点赞收藏是我前进最大的动力!! 希望本文内容能够帮助到你!! 目录 一:本文面向的人群 二:错误场景引入 三:正确场景引入 四…...

Python爬虫:如何从1688阿里巴巴获取公司信息
在当今的数字化时代,数据已成为企业决策和市场分析的重要资产。对于市场研究人员和企业分析师来说,能够快速获取和分析大量数据至关重要。阿里巴巴的1688.com作为中国最大的B2B电子商务平台之一,拥有海量的企业档案和产品信息。本文将介绍如何…...

单片机学习笔记 2. LED灯闪烁
更多单片机学习笔记:单片机学习笔记 1. 点亮一个LED灯 目录 0、实现的功能 1、Keil工程 2、代码实现 0、实现的功能 LED灯闪烁 1、Keil工程 闪烁原理:需要进行软件延时达到人眼能分辨出来的效果。常用的延时方法有软件延时和定时器延时。此次先进行软…...

折叠光腔衰荡高反射率测量技术的matlab模拟理论分析
折叠光腔衰荡高反射率测量技术的matlab模拟理论分析 1. 前言2. 光腔模型3. 光腔衰荡过程4. 衰荡时间与反射率的关系5. 测量步骤①. 光腔调节:②. 光腔衰荡测量:③. 计算衰荡时间常数:④. 反射率计算: 6. 实际应用中的调整7. 技术优…...

ubuntu 16.04 中 VS2019 跨平台开发环境配置
su 是 “switch user” 的缩写,表示从当前用户切换到另一个用户。 sudo 是 “superuser do” 的缩写,意为“以超级用户身份执行”。 apt 是 “Advanced Package Tool” 的缩写,Ubuntu中用于软件包管理的命令行工具。 1、为 root 用户设置密码…...

从STM32到华大HC32F460:USB HOST MSC + FatFs R0.13c移植避坑全记录
从STM32到华大HC32F460:USB HOST MSC FatFs R0.13c移植实战指南 作为一名长期使用STM32的嵌入式开发者,第一次接触华大半导体的HC32F460系列MCU时,既兴奋又忐忑。兴奋的是国产MCU的性能已经能够媲美国际大厂,忐忑的是生态差异带来…...

直面2026检测算法:英文论文降AI实战,3款工具深度避坑盘点
赶稿季来临,英文长稿的AI率到底该怎么降?不少同学愁的头都要秃了,不要再一个词一个词的扣了,这不仅慢,还会把好好的学术英语改得支离破碎。 坦率的讲,真正聪明的降ai,绝对不是机械替换…...
终极指南:3分钟掌握Translumo实时屏幕翻译工具,游戏外语学习两不误
终极指南:3分钟掌握Translumo实时屏幕翻译工具,游戏外语学习两不误 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr…...

OpenClaw AI代理成本监控:离线日志解析与Token用量分析实战
1. 项目概述与核心价值如果你和我一样,在日常工作中重度依赖像 OpenClaw 这样的 AI 代理框架来处理各种自动化任务,那么一个绕不开的“甜蜜的烦恼”就是成本监控。我们享受着 AI 带来的效率提升,但每次看到账单时,心里总会咯噔一下…...

Arch Linux扩展仓库:填补官方与AUR间的功能空白
1. 项目概述:一个为Arch Linux深度定制的扩展仓库如果你是一个Arch Linux的资深用户,或者正在从其他发行版转向这个以“极简”和“用户中心”著称的系统,那么你很可能已经不止一次地面对过这样的场景:官方仓库(core,ex…...

Zilliz-Skill:为向量数据库构建可插拔AI技能库的实战指南
1. 项目概述:一个为向量数据库赋能的技能库最近在折腾RAG(检索增强生成)应用,发现向量数据库虽然解决了海量非结构化数据的存储和检索问题,但要让一个应用真正“智能”起来,光有向量搜索是远远不够的。比如…...

WelsonJS:基于Windows原生WSH的现代JavaScript桌面应用开发框架
1. 项目概述:WelsonJS,一个被低估的Windows原生JavaScript框架如果你是一名Windows平台的开发者,或者经常需要处理一些自动化、脚本任务,你可能对Node.js、Electron甚至PowerShell都很熟悉。但今天我想聊一个有点“复古”却又极其…...

观察使用TokenPlan套餐后月度API成本的变化趋势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察使用TokenPlan套餐后月度API成本的变化趋势 对于依赖大模型API进行开发的中小型团队而言,每月产生的API调用成本是…...

Go语言服务网格负载均衡策略
Go语言服务网格负载均衡策略 1. 负载均衡算法 package loadbalancetype LoadBalancer interface {Select([]string) string }type RoundRobin struct {index intmu sync.Mutex }func NewRoundRobin() *RoundRobin {return &RoundRobin{} }func (r *RoundRobin) Select(e…...

Rust异步运行时:从Tokio到生产环境实践
Rust异步运行时:从Tokio到生产环境实践 引言 异步编程是现代高性能后端服务的关键技术。Rust通过async/await语法和强大的运行时实现,提供了卓越的异步性能。 本文将深入探讨Rust的异步运行时,包括Tokio、async-std等运行时的原理、使用方法和…...