【卡尔曼滤波】数据预测Prediction观测器的理论推导及应用 C语言、Python实现(Kalman Filter)
【卡尔曼滤波】数据预测Prediction观测器的理论推导及应用 C语言、Python实现(Kalman Filter)
更新以gitee为准:
文章目录
- 数据预测概念和适用方式
- 线性系统的适用性
- 数据预测算法和卡尔曼滤波公式推导
- 状态空间方程和观测器
- 先验估计
- 后验估计
- 卡尔曼增益系数计算
- 先验误差协方差矩阵求解
- 卡尔曼滤波五大公式
- 预测
- 校正
- 更新
- 公式简化和应用
- Python实现
- C语言实现
- 附录:压缩字符串、大小端格式转换
- 压缩字符串
- 浮点数
- 压缩Packed-ASCII字符串
数据预测概念和适用方式
实际上 数据预测才是卡尔曼滤波器最常见、最普通的功能
通常用在嵌入式领域和现代控制理论中
如传感器数据处理滤波等等
而数据预测在处理数据时 也跟递归一样可以减小方差
但总体而言 数据预测会跟随当前时刻的测量值变化而变化
递归测量到一定次数后则与上一次的估计值相近
这在第一章中我们有探讨
递归的公式中也可以看出来 随着时间增加 K会越来越小

无论是算术平均算法 还是卡尔曼算法 其都会逐渐减小


递归算法 适用条件是在测量静态目标时 由于测量有误差(通常正态分布) 而进行的类似算术平均根的求解
数据预测则适用于线性动态变化的目标
注意是线性 非线性需要用泰勒展开的扩展卡尔曼滤波
数据预测本质上就是将递归算法、数据融合、协方差矩阵等 共同融合起来的一个算法
在数据融合中 我们探讨了估计值与两种不同方式测量值的融合方式
其卡尔曼增益与两种测量方式的方差有关

在协方差矩阵中 两种完全不同的变量 其方差与协方差构成的矩阵可以反应出数据的相关性
协方差越大 数据相关性越强
数据预测则是综合考虑了以上等多方面算法 得出的一个最优解
可以理解成 数据预测就是在变化的数据中 综合考虑了上一次估计值与当前测量值的关系 并将其融合
也就是将一个不太准的计算结果和一个不太准的测量结果进行融合
从而可以用来预测下一时刻的变量变化 (也就是这一时刻到下一时刻的变化)
同时运用在测量方面 也可以有效减小数据的方差(也就是上一时刻到这一时刻的变化)
这就导致了两种情况:
- 数据变化较大时 譬如从50变化到100 变化量会被拉低 可能最后预测值算出来就是75
- 数据静态变化时 譬如跟递归算法中的例子相同 数据在一个期望值左右波动 且满足正态分布 预测值会减小方差
线性系统的适用性
另外 在前面两个章节中 都是对静态目标的求解
静态目标肯定是满足线性关系的
但对于非线性系统 普通的卡尔曼滤波算法也就不适用了 必须用扩展卡尔曼滤波
但是在实际应用中 我们可以把每次的数据变化都当作是线性的 因为我们要得到的是稳定后的数据
譬如角度计的值的变化 虽然卡尔曼滤波没法跟踪这种毫无规律的系统
但可以减小整体的方差 并且我们在读值的时候 也是读一个相对静态的值
再比如一个斜率为正值的线性系统 突然斜率为负值了 那么在转折点卡尔曼滤波肯定不适用
但是在斜率为负后 多测几组数据 卡尔曼滤波的误差又会再次收敛
对于完全处于运动状态的系统 普通的卡尔曼滤波就不适用了 这时候本来估计值就是个不准确的值 应选择更加相信测量值而非估计值
数据预测算法和卡尔曼滤波公式推导
一个典型的卡尔曼滤波数据预测例子就是:
一天中 天气的温度变化 满足一定规律 通常是晚上冷 白天热
譬如 20 21 24 28 30 29 26 25 23 22 21
在实际测量中 可能会出现:
20.5 21.3 24.5 28.7 30.1 29.5 26.2 25.4 22.8 22.9 22.1
可以看到 最后一次温度出现了小范围的波动
假如温度计测量误差是0.5 那么这个波动情有可原 这是偶然出现的
这个测量值也并不能说明那个时间点 温度又有了回升
而如果加了卡尔曼滤波 就会将这一部分滤掉 从新变成从低到高 再从高到低的关系
这个是针对线性变化的数据
这个是一维的线性变化
另外 卡尔曼滤波还主要用于数据预测
状态空间方程和观测器
针对某一系统 其随时间变化有一定的规律
根据现代控制理论递归思想 我们可以写成如下形式:

其中 Xk是当前状态变量
X(k-1)是上一时刻的状态变量
A是状态转移矩阵(状态矩阵)
B是控制输入矩阵(控制矩阵)
Uk是当前的控制输入
状态转移矩阵:一个系统的某些因素在转移中,第n次结果只受第n-1的结果影响,即只与当前所处状态有关,而与过去状态无关。
如果是静态系统 那么就是单位矩阵1 但通常写成[1 1 / 0 1]的形式 其模就是1
控制输入矩阵:即改变状态变量的外部输入值
控制输入:外部影响系统变量的输入 如果没有外部扰动 那么通常取0
譬如温度的变化满足一次关系
也就是y=kx+b
那么当前时刻的值 就等于上一时刻的值 加上k*单位时间
譬如y=2k+3
第0时刻为3 第1时刻为5 第2时刻为7…
每一时刻都是上一次时刻的值 加上k*单位时间1 也就是2
那么状态转移矩阵算出来就是2 控制输入矩阵是0
如果 某一时刻 外部输入导致了数据变化 那么控制输入矩阵就不是0了
同时 如果某一时刻对系统进行了加热 那么就有了外部输入 Uk 就需要在数据上再加上一个Uk的值
Uk是一个变化的值 静态时就为0
比如加5度 那么就变成了y=2k+3+5
第0时刻为2 第1时刻为10 第2时刻为12…
同时 如果对该系统进行测量 如果测量准确 则每次测量的结果都是当前的状态变量值
譬如第1时刻温度为5 测量出来也肯定是1*5
可以表达成以下形式:

其中 H是测量矩阵 通常为单位矩阵 写作[1 0 / 0 1]的形式(除非测量结果是成比例不准的 但这几乎不存在 如果存在 人为换算即可)
同时 每次系统的更新都会存在噪声 称为过程噪声或者系统噪声 引入并记为w
譬如就算每小时温度增加1度 但可能某一时刻只增加了0.9度
另外 测量也是有误差的 就像先前数据融合讨论的一样 存在测量噪声 引入并记为v
那么就可以写成如下形式:

次公式就是状态空间方程
过程噪声和测量噪声通常都满足正态分布
且期望值为0
过程噪声的协方差矩阵为Q
测量噪声的协方差矩阵为R

这里的Q、R值可以就直接叫做系统误差和测量误差
同时也是系统噪声和测量噪声的方差
所以本质上卡尔曼滤波 就是用数据融合的思想 融合了系统误差和测量误差 最后得到一个最优的估计值
也就是将一个不太准的计算结果和一个不太准的测量结果进行融合
最后得到的估计值误差要比这两者都要小 所以能有效减小系统数据的方差
同时也能预测下一个时刻的估计值
在预测方面 就是将状态空间方程作为一个观测器使用 已知当前时刻的值 来估计后一时刻的值
先验估计
在状态空间方程中 可以看到状态和误差噪声的关系
如果没有噪声 我们可以直接得到当前的系统变量值:

但噪声是不可避免的
所以我们只能得到估计系统值 记为X_Hat 再加一个上标的-表示算出来的估计值 也就是系统估计值
对于系统估计值X_Hat有以下关系:

也就是上一次的估计值与这一时刻的系统估计值关系
这也就是先验估计
同时 对于测量结果而言 测量估计值与当前测量值的关系为:

也就是测量矩阵的逆矩阵*测量值
这两个算出来的和测出来的X估计值都是不准确的
因为误差没法准确估计
后验估计
得到先验估计以后 我们要引入噪声
那么现在就要用到卡尔曼滤波器 做数据融合 去得到最终的估计值 X_Hat 也就是后验估计
结合卡尔曼滤波的数据融合思想 我们可以定义估计结果为:

其中 G是一个系数
同样 当G为0时 估计值=先验估计值 当G为1时 估计值=测量估计值
也就融合了系统估计值和测量估计值的最终结果
而G的大小决定了是相信根据系统变化规律算出来的结果 还是根据测量算出来的结果
G与卡尔曼增益系数的关系为:

那么方程就写成了:

这里K的取值范围为0到H逆
且:

那么现在就又要找到一个最佳的卡尔曼增益系数 使得估计值最贴近真实值(误差最小)
卡尔曼增益系数计算
不用猜就知道 K的取值与上面提到的系统误差和测量误差有关
引入估计误差ek 则与估计值、真实值的关系为:

e也满足正态分布 且方差为P P也是e矩阵和e矩阵转置的期望

假如有两项e1和e2(也就是两种误差)
则:

那么它的期望就为:

根据概率论公式:

某样本的方差=该样本平方的期望-该样本期望的平方
而对于期望为0的正态分布 该样本期望的平方为0
所以:

其中σ1和σ2就是两种误差的标准差
这就是两种误差的协方差公式
要使误差e的方差P最小 那就是这个协方差矩阵的迹最小
那么就是要找到K 使得以下式子的值最小:

带入估计误差公式得:

其中:

I是单位矩阵
同样 先验也有误差 记为ek上标- 等于实际值与先验估计值的误差

则P就为:

根据公式:

带入得:

对于独立事件A、B有:
E(AB)=E(A)E(B)
所以:

则:

计P上标-为先验误差的方差

则:

同理

所以

即测量误差
代入后得到估计误差的协方差矩阵方程:

它的迹为:

现在要求K 使得迹最小 则就是对dK求导为0:

其中 矩阵相乘的求导公式为:

那么就可以求得卡尔曼增益系数

当R特别大时 Kk趋近于0
当R特别小时 Kk趋近于H的逆矩阵

这就是误差最小时卡尔曼增益的计算公式
再看到先前的公式 满足规律

先验误差协方差矩阵求解
上文提到的先验误差公式:

如果要求Kk则需要先求Pk-
代入先验估计方程:

得到:

还是带入独立事件期望公式
另外 e(k-1)和其转置的期望就是上一次的估计误差协方差矩阵
同时带入系统误差Q
得到当前的先验误差协方差矩阵与上一次的估计误差协方差矩阵的关系:

到此就可以求出卡尔曼滤波的五大公式了 并且可以将其应用出来了
卡尔曼滤波五大公式
进行卡尔曼滤波共有三个部分要做
按步骤顺序分为五个公式
预测
求出先验估计和先验误差协方差矩阵

校正
求出卡尔曼增益和后验估计

更新
代入Kk的值 最后得到Pk
更新估计误差协方差矩阵

公式简化和应用
在嵌入式、现代控制理论中
A矩阵通常为1
B矩阵未知但不受外部输入影响的话 U通常就为0
H矩阵也为1
并且如果是针对静态目标的话 这几项矩阵实际上也就为1
那么就可以简化为以下几个公式
按步骤分别是:

Python实现
上面公式按Python来实现的话就是:
def Prediction(measure,result_last=0,covariance_last=0,Q=0.018,R=0.0542):result_priori = result_lastcovariance_priori = covariance_last + Qkg = covariance_priori/(covariance_priori + R)result_last = result_priori + kg*(measure - result_priori)covariance_last = (1-kg)*covariance_priorireturn result_last,covariance_last
运行和调用结果:
v = [10.5,20.6,30.8,40.6,45.3,48.0,47.5,44.5,46.0,43.8,55.5,53.5,56.1,65.2,67.6,68.9,72.2,80.1,81.5,82.6,83.4,84.6,83.5,83.1,85.0,84.5,84.0,83.6,83.9,83.2,84.1,85.6,84.3,84.0,86.5,85.5,85.0,84.8,84.5,84.5,85.1]a=[]
b=[]
c=[]
d=[]def Prediction(measure,result_last=0,covariance_last=0,Q=0.018,R=0.0542):result_priori = result_lastcovariance_priori = covariance_last + Qkg = covariance_priori/(covariance_priori + R)result_last = result_priori + kg*(measure - result_priori)covariance_last = (1-kg)*covariance_priorireturn result_last,covariance_lastresult_last = v[0]
covariance_last = 0for i in range(len(v)):result_last,covariance_last = Prediction(v[i],result_last,covariance_last,5,3)a.append(result_last)print(result_last)plt.figure(4)
plt.plot(v,color="g")
plt.plot(a,color="b")
10.5
17.531645569620252
26.854454203262236
36.52035749751738
42.694663752563144
46.42567852323806
47.181203021790296
45.29562713905005
45.79098257239374
44.390809326126174
52.20342998159353
53.115252454036465
55.21429828136791
62.23681700454024
66.00851518486351
68.04197330570614
70.96613638757006
77.38959365081972
80.28026737213725
81.91163653085387
82.95833916863266
84.11284931225781
83.68185849247561
83.27266219633323
84.48742530555566
84.49626855259646
84.14726401585693
83.7623965417261
83.85916719333677
83.39560298049119
83.89097540372485
85.09285961415652
84.53527521576893
84.1588389541316
85.80527780658561
85.59058892713347
85.17525288812938
84.9113535140978
84.62206610736457
84.53622221290566
84.93270311901878
图像:

可以看到蓝线显著在绿线突变时变得平滑
如果减小R 即减小测量误差则会:

表示相信测量结果
反之减小Q则会:

表示相信先验估计结果
C语言实现
函数:
typedef struct
{double Measure_Now;double Result_Last;double Covariance_Last;double Q;double R;
}Kalman_Filter_Prediction_Struct;Kalman_Filter_Prediction_Struct Kalman_Filter_Prediction(Kalman_Filter_Prediction_Struct Stu);Kalman_Filter_Prediction_Struct Kalman_Filter_Prediction(Kalman_Filter_Prediction_Struct Stu)
{double Result_Priori = Stu.Result_Last;double Covariance_Priori = Stu.Covariance_Last + Stu.Q;double kg = Covariance_Priori/(Covariance_Priori + Stu.R);Stu.Result_Last = Result_Priori + kg*(Stu.Measure_Now - Result_Priori);Stu.Covariance_Last = (1-kg)*Covariance_Priori;return Stu;
}调用:
void Prediction(void)
{double v[41] = {10.5,20.6,30.8,40.6,45.3,48.0,47.5,44.5,46.0,43.8,55.5,53.5,56.1,65.2,67.6,68.9,72.2,80.1,81.5,82.6,83.4,84.6,83.5,83.1,85.0,84.5,84.0,83.6,83.9,83.2,84.1,85.6,84.3,84.0,86.5,85.5,85.0,84.8,84.5,84.5,85.1};Kalman_Filter_Prediction_Struct Stu;uint8_t i=0;Stu.Q=5;Stu.R=3; Stu.Covariance_Last=0.0f;Stu.Result_Last=v[0];for(i=0;i<41;i++){Stu.Measure_Now=v[i];Stu = Kalman_Filter_Prediction(Stu);printf("%f \n",Stu.Result_Last);}
}
调用结果:
10.500000
17.531646
26.854454
36.520357
42.694664
46.425679
47.181203
45.295627
45.790983
44.390809
52.203430
53.115252
55.214298
62.236817
66.008515
68.041973
70.966136
77.389594
80.280267
81.911637
82.958339
84.112849
83.681858
83.272662
84.487425
84.496269
84.147264
83.762397
83.859167
83.395603
83.890975
85.092860
84.535275
84.158839
85.805278
85.590589
85.175253
84.911354
84.622066
84.536222
84.932703
与Python保持一致
附录:压缩字符串、大小端格式转换
压缩字符串
首先HART数据格式如下:


重点就是浮点数和字符串类型
Latin-1就不说了 基本用不到
浮点数
浮点数里面 如 0x40 80 00 00表示4.0f
在HART协议里面 浮点数是按大端格式发送的 就是高位先发送 低位后发送
发送出来的数组为:40,80,00,00
但在C语言对浮点数的存储中 是按小端格式来存储的 也就是40在高位 00在低位
浮点数:4.0f
地址0x1000对应00
地址0x1001对应00
地址0x1002对应80
地址0x1003对应40
若直接使用memcpy函数 则需要进行大小端转换 否则会存储为:
地址0x1000对应40
地址0x1001对应80
地址0x1002对应00
地址0x1003对应00
大小端转换:
void swap32(void * p)
{uint32_t *ptr=p;uint32_t x = *ptr;x = (x << 16) | (x >> 16);x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);*ptr=x;
}压缩Packed-ASCII字符串
本质上是将原本的ASCII的最高2位去掉 然后拼接起来 比如空格(0x20)
四个空格拼接后就成了
1000 0010 0000 1000 0010 0000
十六进制:82 08 20
对了一下表 0x20之前的识别不了
也就是只能识别0x20-0x5F的ASCII表

压缩/解压函数后面再写:
//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_ASCII_to_Pack(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{if(str_len%4){return 0;}uint8_t i=0;memset(buf,0,str_len/4*3); for(i=0;i<str_len;i++){if(str[i]==0x00){str[i]=0x20;}}for(i=0;i<str_len/4;i++){buf[3*i]=(str[4*i]<<2)|((str[4*i+1]>>4)&0x03);buf[3*i+1]=(str[4*i+1]<<4)|((str[4*i+2]>>2)&0x0F);buf[3*i+2]=(str[4*i+2]<<6)|(str[4*i+3]&0x3F);}return 1;
}//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_Pack_to_ASCII(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{if(str_len%4){return 0;}uint8_t i=0;memset(str,0,str_len);for(i=0;i<str_len/4;i++){str[4*i]=(buf[3*i]>>2)&0x3F;str[4*i+1]=((buf[3*i]<<4)&0x30)|(buf[3*i+1]>>4);str[4*i+2]=((buf[3*i+1]<<2)&0x3C)|(buf[3*i+2]>>6);str[4*i+3]=buf[3*i+2]&0x3F;}return 1;
}相关文章:
【卡尔曼滤波】数据预测Prediction观测器的理论推导及应用 C语言、Python实现(Kalman Filter)
【卡尔曼滤波】数据预测Prediction观测器的理论推导及应用 C语言、Python实现(Kalman Filter) 更新以gitee为准: 文章目录 数据预测概念和适用方式线性系统的适用性 数据预测算法和卡尔曼滤波公式推导状态空间方程和观测器先验估计后验估计…...

【SQL50】day 2
目录 1.每位经理的下属员工数量 2.员工的直属部门 3.判断三角形 4.上级经理已离职的公司员工 5.换座位 6.电影评分 7.修复表中的名字 8.患某种疾病的患者 9.删除重复的电子邮箱 1.每位经理的下属员工数量 # Write your MySQL query statement below #e1是经理,…...

【内存管理】理解 `WeakReference` 以更好地管理 Android 应用中的内存
在 Android 应用开发中,内存管理至关重要。糟糕的内存管理可能导致“内存泄漏”,即一些不再需要的对象仍然留在内存中,最终导致性能下降,甚至应用崩溃。WeakReference 就是帮助解决这个问题的一种工具。在本文中,我们将…...

解决IDEA中Maven管理界面不是层级结构的问题
文章目录 0. 前言1. 点击Maven管理界面右上角的三个点2. 勾选将模块分组3. 分组后的层级结构 更多 IDEA 的使用技巧可查看 IDEA 专栏中的文章:IDEA 0. 前言 在 IDEA 中,如果项目中有很多子模块,每个子模块中又有一个或多个子模块时…...

Linux运维篇-iscsi存储搭建
目录 概念实验介绍环境准备存储端软件安装使用targetcli来管理iSCSI共享存储 客户端软件安装连接存储 概念 iSCSI是一种在Internet协议上,特别是以太网上进行数据块传输的标准,它是一种基于IP Storage理论的存储技术,该技术是将存储行业广泛…...

深度学习基础练习:代码复现transformer重难点
2024/11/10-2024/11/18: 主要对transformer一些比较难理解的点做了一些整理,希望对读者有所帮助。 前置知识: 深度学习基础练习:从pytorch API出发复现LSTM与LSTMP-CSDN博客 【神经网络】学习笔记十四——Seq2Seq模型-CSDN博客 【官方双语】一…...

141. Sprite标签(Canvas作为贴图)
上节课案例创建标签的方式,是把一张图片作为Sprite精灵模型的颜色贴图,本节给大家演示把Canvas画布作为Sprite精灵模型的颜色贴图,实现一个标签。 注意:本节课主要是技术方案讲解,默认你有Canvas基础,如果没有Canvas基…...

【IDEA】解决总是自动导入全部类(.*)问题
文章目录 问题描述解决方法 我是一名立志把细节说清楚的博主,欢迎【关注】🎉 ~ 原创不易, 如果有帮助 ,记得【点赞】【收藏】 哦~ ❥(^_-)~ 如有错误、疑惑,欢迎【评论】指正探讨,我会尽可能第一时间回复…...

python中的OS模块的基本使用
🎉🎉🎉欢迎来到我的博客,我是一名自学了2年半前端的大一学生,熟悉的技术是JavaScript与Vue.目前正在往全栈方向前进, 如果我的博客给您带来了帮助欢迎您关注我,我将会持续不断的更新文章!!!🙏🙏🙏 文章目录…...

【Qt】QComboBox设置默认显示为空
需求 使用QComboBox,遇到一个小需求是,想要设置未点击出下拉列表时,内容显示为空。并且不想在下拉列表中添加一个空条目。 实现 使用setPlaceholderText()接口。我们先来看下帮助文档: 这里说的是,placeholderText是…...

LeetCode - #139 单词拆分
文章目录 前言摘要1. 描述2. 示例3. 答案题解动态规划的思路代码实现代码解析1. **将 wordDict 转换为 Set**2. **初始化 DP 数组**3. **状态转移方程**4. **返回结果** **测试用例**示例 1:示例 2:示例 3: 时间复杂度空间复杂度总结关于我们 前言 本题由于没有合适答案为以往遗…...

服务器作业4
[rootlocalhost ~]# vim 11.sh #关闭防火墙 systemctl stop firewalld setenforce 0 #1.接收用户部署的服务名称 read -p "服务名称:(nginx)" server_name if [ $server_name ! nginx ];then echo "输入的不是nginx,脚本退出" exit 1 fi # 判断是…...
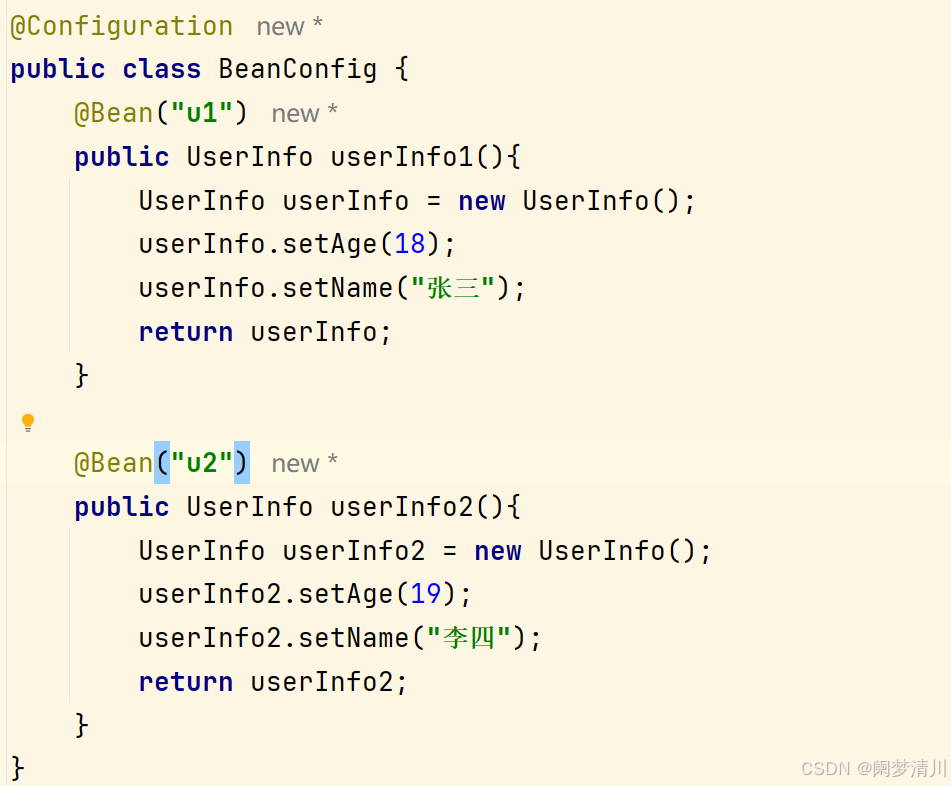
IOC控制反转---相关的介绍和6大注解解读(类注解+方法注解)
文章目录 1.传统方式造车2.传统方法的弊端3.IOC的引入3.IOC对于图书管理系统进行改进(初识)4.注解的使用说明4.1controller注解4.2service注解4.3component注解4.4关于spring命名的问题4.5component重命名4.6repository注解4.7configuration注解4.8注解之…...

SpringBoot(8)-任务
目录 一、异步任务 二、定时任务 三、邮件任务 一、异步任务 使用场景:后端发送邮件需要时间,前端若响应不动会导致体验感不佳,一般会采用多线程的方式去处理这些任务,但每次都需要自己去手动编写多线程来实现 1、编写servic…...

【机器学习】如何配置anaconda环境(无脑版)
马上就要上机器学习的实验,这里想写一下我配置机器学习的anaconda环境的二三事 一、首先,下载安装包: Download Now | Anaconda 二、打开安装包,一直点NEXT进行安装 这里要记住你要下载安装的路径在哪,后续配置环境…...

java 可以跨平台的原因是什么?
我们对比一个东西就可以了,那就是chrome浏览器。 MacOS/Linux/Windows上的Chrome浏览器,那么对于HTML/CSS/JS的渲染效果都一样的。 我们就可以认为ChromeHTML/CSS/JS是跨平台的。 这里面,HTML/CSS/JS是不变的的,对于一个网页&a…...

Solana应用开发常见技术栈
编程语言 Rust Rust是Solana开发中非常重要的编程语言。它具有高性能、内存安全的特点。在Solana智能合约开发中,Rust可以用于编写高效的合约代码。例如,Rust的所有权系统可以帮助开发者避免常见的内存错误,如悬空指针和数据竞争。通过合理利…...

npm | Yarn | pnpm Node.js包管理器比较与安装
一、包管理器比较 参考原文链接: 2024 Node.js Package Manager 指南:npm、Yarn、pnpm 比较 — 2024 Node.js Package Manager Guide: npm, Yarn, pnpm Compared (nodesource.com) 以下是对 Node.js 的三个包管理工具 npm、Yarn 和 pnpm 的优缺点总结&am…...
Linux下编译MFEM
本文记录在Linux下编译MFEM的过程。 零、环境 操作系统Ubuntu 22.04.4 LTSVS Code1.92.1Git2.34.1GCC11.4.0CMake3.22.1Boost1.74.0oneAPI2024.2.1 一、安装依赖 二、编译代码 附录I: CMakeUserPresets.json {"version": 4,"configurePresets": [{&quo…...

【团购核销】抖音生活服务商家应用快速接入②——商家授权
文章目录 一、前言二、授权流程三、授权Url3.1 Url参数表3.2 授权能力表3.3 源码示例 四、授权回调4.1 添加授权回调接口4.2 授权回调接口源码示例 五、实际操作演示六、参考 一、前言 目的:将抖音团购核销的功能集成到我们自己开发的App和小程序中 【团购核销】抖音…...

仿冒 Word 钓鱼攻击中可信远程工具滥用机理与企业防御研究
摘要 2026 年 5 月安全事件监测显示,以仿冒 Word 在线页面为诱饵、滥用合法远程管理工具实现内网渗透的新型钓鱼攻击,正成为企业安全防护的典型盲区。该攻击以 Outlook 钓鱼邮件为入口,诱导用户访问伪造的 Word Online/OneDrive 预览页面&…...

Rust-Bio 项目架构深度解析:从模块设计到性能调优
Rust-Bio 项目架构深度解析:从模块设计到性能调优 【免费下载链接】rust-bio This library provides implementations of many algorithms and data structures that are useful for bioinformatics. All provided implementations are rigorously tested via conti…...

Windows热键冲突终极解决方案:Hotkey Detective帮你找回失窃的快捷键
Windows热键冲突终极解决方案:Hotkey Detective帮你找回失窃的快捷键 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective…...

9. Python 文件与输入输出 深度解析
Python 文件与输入输出 深度解析 目录 Python I/O 概述文件对象与基本操作 2.1 打开文件:open 与模式2.2 读取数据2.3 写入数据2.4 使用 with 自动管理文件 文件指针与随机访问路径操作:os、os.path 与 pathlib 4.1 os 模块与 os.path 基础4.2 现代路径…...

SVM实战手记:从核函数选择到上线避坑的工程指南
1. 这不是数学课,是帮你把SVM用对、用稳、用出效果的实战手记你打开一篇SVM教程,三行之后就卡在“最大间隔超平面”“核函数映射到高维空间”“拉格朗日对偶问题”上——不是你基础差,是绝大多数资料从一开始就走错了路:它们把SVM…...

工业智能网关:三菱FX3U PLC数据采集
调试准备: 需要准备的材料:HINET 智能网关、现场安装三菱 FX3U、网线等;网关和 PLC 的连接方式:网关 LAN 口直接和 PLC 网线连接; PLC 和网关的 IP 地址以及现场联网条件说明: 三菱 FX3U 的 IP:…...

Unity 2D项目初始化实战:从零搭建可维护游戏骨架
1. 这不是“又一个Unity入门教程”,而是我带三个实习生从零做出第一个可玩Demo的真实路径你搜“Unity 2D 教程”,首页全是“5分钟创建角色”“10行代码实现跳跃”——画面很炫,但关掉视频后,你连项目文件夹里该删哪个.meta、该留哪…...

3步搞定歌词管理难题:LDDC歌词下载工具的完整实战指南
3步搞定歌词管理难题:LDDC歌词下载工具的完整实战指南 【免费下载链接】LDDC 简单易用的精准歌词(逐字歌词/卡拉OK歌词)下载匹配工具|A simple and user-friendly tool for downloading and matching precise lyrics (word-by-word lyrics/Karaoke lyrics) 项目地…...

MediaCrawler:企业级社交媒体数据采集的终极架构实践
MediaCrawler:企业级社交媒体数据采集的终极架构实践 【免费下载链接】MediaCrawler 小红书笔记 | 评论爬虫、抖音视频 | 评论爬虫、快手视频 | 评论爬虫、B 站视频 | 评论爬虫、微博帖子 | 评论爬虫、百度贴吧帖子 | 百度贴吧评论…...

7.跨品牌手机刷机原理深度解析|BL 解锁机制 + 分区读写 + 故障修复全方案
摘要 本文系统性地阐述主流品牌智能手机(华为、小米、OPPO、vivo、一加、苹果)刷机与维修的核心原理与操作流程。针对不同品牌底层架构差异,提供从Bootloader解锁、Recovery刷写到系统固件注入的完整技术方案。所有操作步骤均基于实际硬件环境验证,包含完整可运行的Python…...