wend看源码-APISJON
项目地址
腾讯APIJSON官方网站
定义
APIJSON 可以定义为一个面向HTTP 协议的JSON 规范,一个面向数据访问层的ORM 框架。其主要工作流程包括:前端按照既定格式组装 JSON 请求报文,通过 APIJSON-ORM 将这些报文直接转换为 SQL 语句,进而执行数据库操作,如增删改查等。完成后,系统将数据再按照指定格式封装成 JSON 响应报文,高效地实现前后端的数据交互,并将最终结果反馈给用户。
架构

图2.1 基于APIJSON的交互流程图
通过图2.1 基于APIJSON的交互流程图我们可以发现,APIJSON 的设计思路,主要用于前端可以通过基于APIJSON的语法格式直接处理数据的增删改查。也可以说是后端通过使用APIJSON-ORM 框架,定义了一个万能的Controller接口层,从而使得前端可以通过这个接口实现全部的CRUD 操作。
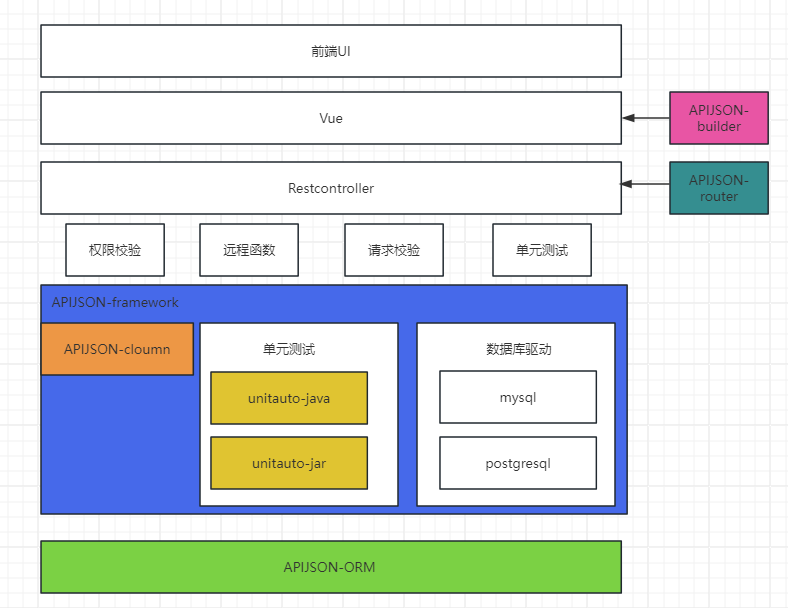
图2.2 基于APIJSON 构件生态的框架图
- APIJSON-ORM:APIJSON-ORM 是 APIJSON 框架的核心组件,它是一个对象关系映射(ORM)框架,专门用于将 JSON 格式的请求自动转换为 SQL 语句,从而快速实现对数据库的增删改查操作。
- APIJSON-framework:APIJSON-framework 是 APIJSON 的基础框架,它提供了一套完整的解决方案,包括请求的解析、处理、权限验证以及响应的封装等,还包含了基于unitAuto 的自动化单元测试的内容。这个框架使得开发者能够快速搭建起一个高效、安全、易用的后端 API 服务。
- APIJSON-cloumn:APIJSON 的字段处理插件,包含了表字段相关工具类
- unitauto-java:unitauto-java 是一个自动化测试框架,它可以自动生成和执行单元测试代码。这个框架旨在减少手动编写测试代码的工作量,提高代码质量和测试覆盖率。
- APIJSON-router:APIJSON 的路由插件,用于将Restful API 转成 APIJSON API格式请求
- APIJSON-builder:采用类似mybaits 中 wrapper 封装的方式组装前端请求报文。用于生成符合 APIJSON 规范的 JSON 请求和响应结构。
主要功能
- APIJSON 定义了前端请求后端操作数据库的JSON报文格式。
- APIJSON-framework 包含一套完整的前后端CRUD操作的解决方案,主要包括权限校验,远程函数/脚本调用,请求合法性校验, 单元测试等功能。
- APIJSON-ROM 简化了后端数据仓储层的操作,大大减少了软件运维过程中的重复造轮子过程,让开发者可以将精力专注于开发创新和商业赋能。
优缺点
- 优点:在此借用APIJSON 官网的图,来表述使用APIJSON的优点:


- 开发提速对比表:

- 缺点(个人观点):
- APIJSON-framework 依赖了mysql和postgresql两个数据库引擎,以及直接集成了作者的另一个自动化单元测试的项目UnitAuto。这使得APIJSON-framework 的技术架构耦合性比较高。
- APIJSON-cloumn 就是一个工具类,在我看来完全可以集成于APIJSON-framework
- APIJSON-ORM 的核心代码有待优化
使用规范
语法
"key[]":{} // 查询数组"key{}":[1,2,3] // 匹配选项范围"key{}":"<=10;length(key)>1..." // 匹配条件范围"key()":"function(arg0,arg1...)" // 远程调用函数"key@":"key0/key1.../targetKey" // 引用赋值"key$":"%abc%" // 模糊搜索"key~":"^[0-9]+$" // 正则匹配"key%":"2018-01-01,2018-10-01" // 连续范围"key+":[1] // 增加/扩展"key-":888.88 // 减少/去除 "name:alias" // 新建别名"@combine":"name~,tag~" // 条件组合"@column":"id,sex,name" // 返回字段"@group":"userId" // 分组方式"@having":"max(id)>=100" // 聚合函数"@order":"date-,name+" // 排序方式"@schema":"sys" // 集合空间"@database":"POSTGRESQL" // 跨数据库"@datasource":"DRUID" // 多数据源"@explain":true // 性能分析"@role":"LOGIN" // 访问角色功能列表
| 功能 | 键值对格式 | 使用示例 |
| 查询数组 | "key[]":{},后面是JSONObject,key可省略。当key和里面的Table名相同时,Table会被提取出来,即 {Table:{Content}} 会被转化为 {Content} | {"User[]":{"User":{}}}(opens new window) ,查询一个User数组。这里key和Table名都是User,User会被提取出来,即 {"User":{"id", ...}} 会被转化为 {"id", ...},如果要进一步提取User中的id,可以把User[]改为User-id[] |
| 匹配选项范围 | "key{}":[],后面是JSONArray,作为key可取的值的选项 | "id{}":[38710,82001,70793](opens new window) ,对应SQL是 ,查询id符合38710,82001,70793中任意一个的一个User数组 |
| 匹配条件范围 | "key{}":"条件0,条件1...",条件为SQL表达式字符串,可进行数字比较运算等 | "id{}":"<=80000,>90000"(opens new window) ,对应SQL是 ,查询id符合id<=80000 | id>90000的一个User数组 |
| 包含选项范围 | "key<>":Object => "key<>":[Object],key对应值的类型必须为JSONArray,Object类型不能为JSON | "contactIdList<>":38710(opens new window) ,对应SQL是 ,查询contactIdList包含38710的一个User数组 |
| 判断是否存在 | "key}{@":{ | "id}{@":{ "from":"Comment", "Comment":{ "momentId":15 }}(opens new window)
|
| 远程调用函数 | "key()":"函数表达式",函数表达式为 function(key0,key1...),会调用后端对应的函数 function(JSONObject request, String key0, String key1...),实现 参数校验、数值计算、数据同步、消息推送、字段拼接、结构变换 等特定的业务逻辑处理, | "isPraised()":"isContain(praiseUserIdList,userId)"(opens new window) ,会调用远程函数 boolean isContain(JSONObject request, String array, String value) ,然后变为 "isPraised":true 这种(假设点赞用户id列表包含了userId,即这个User点了赞) |
| 存储过程 | "@key()":"SQL函数表达式",函数表达式为 | "@limit":10,"@offset":0,"@procedure()":"getCommentByUserId(id,@limit,@offset)"(opens new window)
|
| 引用赋值 | "key@":"key0/key1/.../refKey",引用路径为用/分隔的字符串。以/开头的是缺省引用路径,从声明key所处容器的父容器路径开始;其它是完整引用路径,从最外层开始。 | "Moment":{ "userId":38710},"User":{ "id@":"/Moment/userId"}(opens new window)
|
| 子查询 | "key@":{ | "id@":{ "from":"Comment", "Comment":{ "@column":"min(userId)" }}(opens new window)
|
| 模糊搜索 | "key$":"SQL搜索表达式" => "key$":["SQL搜索表达式"],任意SQL搜索表达式字符串,如 %key%(包含key), key%(以key开始), %k%e%y%(包含字母k,e,y) 等,%表示任意字符 | "name$":"%m%"(opens new window) ,对应SQL是 ,查询name包含"m"的一个User数组 |
| 正则匹配 | "key~":"正则表达式" => "key~":["正则表达式"],任意正则表达式字符串,如 ^[0-9]+$ ,*~ 忽略大小写,可用于高级搜索 | "name~":"^[0-9]+$"(opens new window) ,对应SQL是 ,查询name中字符全为数字的一个User数组 |
| 连续范围 | "key%":"start,end" => "key%":["start,end"],其中 start 和 end 都只能为 Boolean, Number, String 中的一种,如 "2017-01-01,2019-01-01" ,["1,90000", "82001,100000"] ,可用于连续范围内的筛选 | "date%":"2017-10-01,2018-10-01"(opens new window) ,对应SQL是 ,查询在2017-10-01和2018-10-01期间注册的用户的一个User数组 |
| 新建别名 | "name:alias",name映射为alias,用alias替代name。可用于 column,Table,SQL函数 等。只用于GET类型、HEAD类型的请求 | "@column":"toId:parentId"(opens new window) ,对应SQL是 ,将查询的字段toId变为parentId返回 |
| 增加 或 扩展 | "key+":Object,Object的类型由key指定,且类型为Number,String,JSONArray中的一种。如 82001,"apijson",["url0","url1"] 等。只用于PUT请求 | "praiseUserIdList+":[82001],对应SQL是 ,添加一个点赞用户id,即这个用户点了赞 |
| 减少 或 去除 | "key-":Object,与"key+"相反 | "balance-":100.00,对应SQL是 ,余额减少100.00,即花费了100元 |
| 比较运算 | >, <, >=, <= 比较运算符,用于 | ① "id<=":90000(opens new window) ,对应SQL是 ,查询符合id<=90000的一个User数组
|
| 逻辑运算 | &, |, ! 逻辑运算符,对应数据库 SQL 中的 AND, OR, NOT。 | ① "id&{}":">80000,<=90000"(opens new window) ,对应SQL是 ,即id满足id>80000 & id<=90000 ,同"id{}":">90000,<=80000",对应SQL是 ,即id满足id>90000 | id<=80000 ,对应SQL是 ,即id满足 ! (id=82001 | id=38710),可过滤黑名单的消息 |
| 数组关键词,可自定义 | "key":Object,key为 "[]":{} 中{}内的关键词,Object的类型由key指定
| ① 查询User数组,最多5个:
|
| 对象关键词,可自定义 | "@key":Object,@key为 Table:{} 中{}内的关键词,Object的类型由@key指定 | ① 搜索name或tag任何一个字段包含字符a的User列表:
|
| 全局关键词 | 为最外层对象 {} 内的关键词。其中 @database,@schema, @datasource, @role, @explain 基本同对象关键词,见上方说明,区别是全局关键词会每个表对象中没有时自动放入,作为默认值。 | ① 查隐私信息:
|
适用场景
- 全栈开发一个小型web 项目:初识APIJSON,我认为APIJSON 可以大大简化后端,但需要前端同学学习APIJSON 定义的JSON 协议规则语法,以及需要前端同学对数据库操作语法有一定的理解。所以目前看来,我让前端同学直接从原有开发模式转成基于APIJSON 的开发是不现实的。所以我认为APIJSON 更适合个人全栈开发一个小型的web 项目。
- 报表类服务:报表类服务没有复杂的项目逻辑,大多数是基于数据的查询,APIJSON 比较适合。
- 数据维护服务:数据维护服务没有复杂的项目逻辑,大多数是基于数据的增删改查操作,APIJSON 比较适合。
项目重构思路
本人后续准备对APIJSON项目进行重构,编写一个基于APIJSON的开源项目:easy-APIJSON,重构的内容列表包括:
1. 使用配置文件的方式封装APIJSON-ORM 中AbstractSQLConfig 中关于数据库关键字,函数,运算符的配置,我想以文本文档的方式将这些内容封装整理,方便后续的软件维护工作
2. 整体重构 APIJSON-framework
- 去掉强相关的数据库依赖,以及单元测试依赖等;去掉APIJSON-framework 关于权限校验,请求校验等基于数据库操作的内容。
- 将APIJSON-clolumn 的内容集成与APIJSON-framework中;
- 加入通用排序工具,通用分页工具等,丰富APIJSON-framework的内容。

图3.1 easy-APIJSON 架构图
3. 我希望的easy-APIJSON的架构是这样的:easy-APIJSON 整体项目与三方依赖以及数据库无关,APIJSON 提供的是通用的处理方法。用户可以自主选择技术实现方案,如采用数据库配置、代码配置或文件配置等方式去实现某个功能。
4. 基于easy-APIJSON,APIJSON-builder 提供前端明确的语法文档和示例,在easy-APIJSON运行时可提供网页文档。
参考文献
APIJSON 官方网站:腾讯APIJSON官方网站
APIJSON 官方文档:介绍 | apijson-doc
相关文章:
wend看源码-APISJON
项目地址 腾讯APIJSON官方网站 定义 APIJSON 可以定义为一个面向HTTP 协议的JSON 规范,一个面向数据访问层的ORM 框架。其主要工作流程包括:前端按照既定格式组装 JSON 请求报文,通过 APIJSON-ORM 将这些报文直接转换为 SQL 语句,…...

堆外内存泄露排查经历
优质博文:IT-BLOG-CN 一、问题描述 淘宝后台应用从今年某个时间开始docker oom的量突然变多,确定为堆外内存泄露。 后面继续按照上一篇对外内存分析方法的进行排查(jemalloc、pmap、mallocpmap/mapsNMTjstackgdb),但都没有定位到问题。至于…...
SpringBoot Task
相关文章链接 定时任务工具类(Cron Util)SpringBoot Task 参数详解 Target({ElementType.METHOD, ElementType.ANNOTATION_TYPE}) Retention(RetentionPolicy.RUNTIME) Documented Repeatable(Schedules.class) public interface Scheduled {String C…...

学习路之压力测试--jmeter安装教程
Jmeter安装 0、先安装jdk:这里是安装jdk-8u211-windows-x64 1、百度网盘上下载 jdk和jmeter 链接: https://pan.baidu.com/s/1qqqaQdNj1ABT1PnH4hfeCw?pwdkwrr 提取码: kwrr 复制这段内容后打开百度网盘手机App,操作更方便哦 官网:Apache JMeter - D…...

大模型部署,运维,测试所需掌握的知识点
python环境部署: python3 -m site --user-base 返回用户级别的Python安装基础目录 sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.8 1 将python3的默认路径/usr/bin/python3替…...

ECharts柱状图-带圆角的堆积柱状图,附视频讲解与代码下载
引言: 在数据可视化的世界里,ECharts凭借其丰富的图表类型和强大的配置能力,成为了众多开发者的首选。今天,我将带大家一起实现一个柱状图图表,通过该图表我们可以直观地展示和分析数据。此外,我还将提供…...
Thread 类和 Runnable 接口详解)
java 并发编程 (2)Thread 类和 Runnable 接口详解
目录 1. Thread 类和 Runnable 接口的设计目的 1.1 为什么有 Thread 类和 Runnable 接口? 2. Thread 类实现的详细分析 2.1 Thread 类的构造方法 2.2 start() 方法的工作原理 2.3 run() 方法 2.4 join() 方法 3. Runnable 接口的实现和作用 3.1 Runnable 接…...

人工智能之数学基础:线性代数在人工智能中的地位
本文重点 从本文开始,我们将开启线性代数的学习,在线性代数中有向量、矩阵,以及各种性质,那么这些数学知识究竟和人工智能有什么关系呢? 重要性 机器学习和深度学习的本质就是训练模型,要想训练模型需要使…...

PostgreSQL WITH 子句:提高查询效率和可读性
PostgreSQL WITH 子句:提高查询效率和可读性 PostgreSQL 是一种功能强大的开源关系数据库管理系统,它以其稳定性、可靠性和高级功能而闻名。在 PostgreSQL 中,WITH 子句(也称为公用表表达式,CTE)是一种非常有用的特性,它允许用户在一个大的查询中创建一个临时的结果集,…...

TransFormer--解码器:前馈网络层、叠加和归一组件
TransFormer--解码器:前馈网络层、叠加和归一组件 解码器的下一个子层是前馈网络层,如下图所示。 解码器的前馈网络层的工作原理与我们在编码器中学到的完全相同 叠加和归一组件 和在编码器部分学到的一样,叠加和归一组件连接子层的输入和输…...

2024亚太杯国际赛C题参考文章50页+完整解题思路+数据处理+最终结果
中国宠物食品行业的发展趋势与汇率情景分析:基于多模型的量化预测与决策分析 一 、 摘要 本文针对宠物产业及相关产业的发展分析问题,采用多种数学建模方法和数据 分析技术,构建了一系列预测和评估模型。从宠物数量预测、全球市场分析、产业 …...

Kafka 分区分配及再平衡策略深度解析与消费者事务和数据积压的简单介绍
Kafka:分布式消息系统的核心原理与安装部署-CSDN博客 自定义 Kafka 脚本 kf-use.sh 的解析与功能与应用示例-CSDN博客 Kafka 生产者全面解析:从基础原理到高级实践-CSDN博客 Kafka 生产者优化与数据处理经验-CSDN博客 Kafka 工作流程解析:…...

useEffect、useCallback、useMemo和memo的区别
前言 在构建现代 React 应用时,性能优化是一个关键考虑因素。随着组件的复杂性增加,合理管理状态和副作用变得尤为重要。React 提供了多个工具来帮助开发者优化组件性能,其中最常用的包括 useEffect、useCallback、useMemo 和 React.memo。这…...

layui树形组件点击树节点后高亮的解决方案
效果显示: 代码 //节点高亮var nodes document.getElementsByClassName("layui-tree-txt");for (var i 0; i < nodes.length; i) {if (nodes[i].innerHTML obj.data.title){nodes[i].style.color "#006BF9";nodes[i].style.fontWeight …...
大语言模型(LLM)安全:十大风险、影响和防御措施
一、什么是大语言模型(LLM)安全? 大语言模型(LLM)安全侧重于保护大型语言模型免受各种威胁,这些威胁可能会损害其功能、完整性和所处理的数据。这涉及实施措施来保护模型本身、它使用的数据以及支持它的基…...

02 —— Webpack 修改入口和出口
概念 | webpack 中文文档 | webpack中文文档 | webpack中文网 修改入口 webpack.config.js (放在项目根目录下) module.exports {//entry设置入口起点的文件路径entry: ./path/to/my/entry/file.js, }; 修改出口 webpack.config.js const path r…...

Go语言进阶依赖管理
1. Go语言进阶 1.1 Goroutine package mainimport ("fmt""time" )func hello(i int) {println("hello goroutine : " fmt.Sprint(i)) }func main() {for i : 0; i < 5; i {go func(j int) { hello(j) }(i) // 启动一个新的 goroutine&…...

集成了高性能ARM Cortex-M0+处理器的一款SimpleLink 2.4 GHz无线模块-RF-BM-2340B1
蓝牙模组 - RF-BM-2340B1是基于美国TI的CC2340R5为核心设计的一款SimpleLink 2.4 GHz 无线模块。支持Bluetooth 5.3 Low Energy、Zigbee 、IEEE 802.15.4g、TI 15.4-Stack (2.4 GHz)及私有协议。集成了高性能ARM Cortex-M0处理器,具有512 KB Flash、32 KB超低泄漏SR…...

ffmpeg本地编译不容易发现的问题 — Error:xxxxx not found!
这里区分电脑CPU架构 本次编译是在Mac笔记本,M1芯片上进行! 前面大致流程:分为两种(1.仅适用,直接下载编译好的本地安装即可;2.使用并查看源码,自己修改编译运行)。这里介绍的是第…...

mybatis——Mapper代理方式
一、原始DAO开发问题 Dao接口实现类方法中存在大量模板方法,设想能否将这些代码提取出来,大大减轻程序员的工作 量。 调用sqlSession的数据库操作方法需要指定statement的id,这里存在硬编码,不利于开发维护。 调用SqlSession方…...

深入理解Android中startActivity的完整流程:聚焦IPC机制与Binder原理
引言 在Android开发中,startActivity() 方法是启动新Activity的核心API,它贯穿了应用的生命周期管理。理解其内部流程,不仅有助于优化性能、避免常见错误,还能提升开发者在面试中的竞争力。本文将以“一次完整的 startActivity 到底经历了什么”为主题,深入探讨整个流程,…...

告别频繁中断!华大HC32F4A0串口DMA接收实战:用TIMEOUT中断替代STM32的IDLE
HC32F4A0串口DMA接收优化:TIMEOUT中断替代STM32 IDLE的工程实践 对于习惯了STM32开发环境的工程师而言,华大半导体的HC32F4A0系列微控制器在串口通信处理上存在一个显著差异——缺少IDLE中断机制。这一差异在RS485通信等需要帧完整性判断的场景中尤为突出…...
)
四旋翼DIY实战:用STM32和ICM20602实现Mahony姿态解算(附完整代码)
四旋翼DIY实战:用STM32和ICM20602实现Mahony姿态解算 1. 项目背景与硬件选型 四旋翼飞行器的核心在于稳定控制,而姿态解算是实现这一目标的基础。ICM20602作为一款六轴IMU传感器,集成了三轴加速度计和三轴陀螺仪,配合STM32系列微控…...

AI-auth-toolkit安全架构解析:如何实现真正的不可链接性
AI-auth-toolkit安全架构解析:如何实现真正的不可链接性 【免费下载链接】genai-compliance-bench GenAI compliance benchmark is a evaluation benchmarks for generative AI in regulated industries. 项目地址: https://gitcode.com/gh_mirrors/ai/genai-comp…...

鸿蒙备考题库页面构建:今日计划与题目预览模块的详细解析
鸿蒙备考题库页面构建:今日计划与题目预览模块的详细解析 前言 在 HarmonyOS 6.0 应用开发中,在线教育类页面的学习计划展示和题目练习模块是用户停留时间最长的核心区域。本文将以“备考题库”应用中的“今日学习计划”任务列表和“题目预览”答题卡片为…...

如何快速掌握Prism-Samples-Wpf交互性编程:InvokeCommandAction事件驱动开发终极指南
如何快速掌握Prism-Samples-Wpf交互性编程:InvokeCommandAction事件驱动开发终极指南 【免费下载链接】Prism-Samples-Wpf Samples that demonstrate how to use various Prism features with WPF 项目地址: https://gitcode.com/gh_mirrors/pr/Prism-Samples-Wpf…...
:Handle——谁占着不放?句柄泄漏排查、强制解锁与检索技巧)
《Sysinternals实战指南》进程和诊断工具学习笔记(8.24):Handle——谁占着不放?句柄泄漏排查、强制解锁与检索技巧
🔥个人主页:杨利杰YJlio❄️个人专栏:《Sysinternals实战教程》《Windows PowerShell 实战》《WINDOWS教程》《IOS教程》《微信助手》《锤子助手》 《Python》 《Kali Linux》 《那些年未解决的Windows疑难杂症》🌟 让复杂的事情更…...

Promptfoo的搭建与测试,2026-0521成功版很简单
可能写的有点粗糙,但是我搞通了,有不懂的可以问我,懒得再更新了 其实我也是520当天搭建好的,现在的教程也不多,我就搜了搜,没什么具体的步骤,我想用windows感觉更方便一点但是一直不行各种版本…...

小学期第一周
理论部分:学会了低通滤波器原理:只允许低于截止频率的信号通过,高于截止频率的信号被大幅衰减方波变成正弦波的原理:方波是基波无数奇次谐波的叠加,低通滤波器只留基波、滤掉高频谐波,输出就接近正弦波二阶…...

Agent 一接 MCP 大结果集就开始失忆:从 Result Summarization 到 Cursor Paging 的工程实战
一、MCP 一接大结果集,Agent 最先坏掉的不是推理,而是记忆 🧠 很多团队把 MCP 当成 Agent 的万能扩展层:只要把数据库、工单、代码检索、指标平台都挂进去,模型就能“边查边做”。真正上线后最先暴露的问题却很一致&am…...