深度学习2
四、tensor常见操作
1、元素值
1.1、获取元素值
tensor.item() 返回tensor的元素;只能在一个元素值使用,多个报错,当存在多个元素值时需要使用索引进行获取到一个元素值时在使用 item。
1.2、元素值运算
tensor对元素值的运算:加、减、乘、除、取余、取整、幂
加减乘除:加法(+、add、add_),减法(-、sub、sub_),乘法(*、mul、mul_),除法(/、div、div_)
取整、取余、幂:取整(//)、取余(%):与python 列表操作一致,每个元素都进行单独运算。
# 运算 加减乘除
# 带_的方法基本上都是修改原数据
import torch
torch.manual_seed(666) # 设置随机种子
data1 = torch.randint(1,10,(3,3))
data2 = torch.randint(1,10,(3,3))# 加法
print("+++++++++")
x1 = data1+100
print(x1)
x1 = data1.add(100)
print(x1)
data2.add_(200)
print(data2)# 减法
print("----------")
x1 = data1-100
print(x1)
x1 = data1.sub(100)
print(x1)
data2.sub_(200)
print(data2)# 乘法
print("**********")
x1 = data1*100
print(x1)
x1 = data1.mul(100)
print(x1)
data2.mul_(200)
print(data2)# 除法
print("/")
x1 = data1/100
print(x1)
data2 =data2.type(torch.float16) # 原数据为整数,需要转为浮点数
x1 = data1.div(100)
print(x1)
data2.div_(200)
print(data2)2、阿达玛积
.dot 点积、* 乘法 、mul 、mm、matmul、@
直接相乘或mul方法都是元素对于位置相乘(形状相同,或者一个为标量)
tensor相乘:data1.dot(data2) 点积用于一阶张量;
data1.mm(data2) 用于二阶张量;
data1@data2、data1.matmul(data2) 用于一阶及以上张量
import torch# 相乘 * mul()
x = torch.tensor([[1,2],[3,4]])
y = torch.tensor([[11,22],[33,44]])
x1 = x*y
print(x1)
x2 = x.mul(y)
print(x2)# dot matmul
x = torch.tensor([1,2])
y = torch.tensor([11,22])
x3 = x.dot(y)
print(x3)
x3 = x.matmul(y)
print(x3)
x4 = x@y
print(x4)# @ matmul mm
x = torch.tensor([[1,2],[3,4]])
y = torch.tensor([[11,22],[33,44]])
x4 = x@(y)
print(x4)
x5 = x.matmul(y)
print(x5)
x6 = x.mm(y)
print(x6)
3、索引操作
3.1、下标索引
和列表操作一样,根据元素下标获取对应元素
import torch
torch.manual_seed(666)
x = torch.randint(1,10,(2,3,3))
print(x)
print(x[1])
print(x[1,2])
print(x[1,2,2])
print(x[1,2,2].item())3.2、切片索引
与列表操作一致
import torch
torch.manual_seed(666)
x = torch.randint(1,10,(2,3,3))
print(x[:5]) # 下标超出索引界限并不会报错,给出全部数据
print(x[:2,2])
print(x[:2,2:3])
print(x[:2,2:3,1])
print(x[:2,2:3,1:2])
print(x[:2,2:3,1:2][1])
print(x[:2,2:3,1:2][1].item())3.3、布尔索引
根据得到True返回对应位置的元素,单独索引列时,将该列数据变成一维布尔值结果,根据结果True的下标再去原函数获取对应数据
import torch
torch.manual_seed(666)
x = torch.randint(1,10,(5,5))
print(x)
print(x[x==1])
print(x[x>5])3.4、组合索引
将前面三种索引方式组合使用
多个下标索引:
下标索引使用列表时,分别取对于数据的多行或多列:
x[[1,2]] 取第二行和第三行的所有列;
x[,[1,2]] 取所有行的第二列和第三列;
当原数据的行和列都是列表形式时,数据一一对应:也就是从前往后是 1对1,1对n,n对1,n对n,不能n对m:
错误:x[[0,1],[0,1,2]]
正确应该是:x[1,[0,1]] 表示第二行的第一列和第二列;x[[0,1],1] 表示第一行和第二行的第二列;x[[0,1],[0,1]] 表示第一行的第一列和第二行的第二列数据
多个切片索引:维度保持不变,x[:2,:2]表示行取0-1,列取0-1的数据
布尔索引和切片索引:x[x[1]==1, :2]:将x中第二行等于1的数据下标返回作为行下标索引,切0-1列数据
import torch
torch.manual_seed(15)
x = torch.randint(2000,3000,(5,5))
print(x)
x1 = x[(x[:,0]%2==0) & (x[:,1]%2==1) & (x[:,2]%4==0) & (x[:,2]%100!=0),3:5]
print(x1)4、拼接
cat 和 stack ;
dim 表示维度
torch.cat([tensor1,tnsor2],dim =0):将tensor1和ensor2拼接;dim=0表示按照行第一维度拼接,添加行,列不变;dim=1表示按照列拼接,行不变;dim=3表示行列格式不变,将元素加维。
import torch
torch.manual_seed(666)
x = torch.randint(1,10,(2,2,2))
y = torch.randint(10,20,(2,2,2))
print(x)
print(y)
z = torch.cat([x,y],dim = 0)
print(z)
z = torch.cat([x,y],dim = 1)
print(z)
z = torch.cat([x,y],dim = 2)
print(z)
torch.stack([tensor1,tensor2],dim=0):表示将tensor1和tensor2连接;dim=0表示将两个整体放入列表的第一个元素和第二个元素的方式连接;dim=1表示扩展维度后将两个tensor的行下标相同作为同一列的不同行;dim=2表示将原本同一行的数据变成同一列不同行,相当于把第一个列拆分放入下面最接近的行,将第二个同样位置放入第二列,扩展维度后两个tensor的对应位置元素相同作为同一行的不同列
import torch
torch.manual_seed(666)
x = torch.randint(1,10,(2,2))
y = torch.randint(10,20,(2,2))
print(x)
print(y)
z = torch.stack([x,y],dim = 0)
print(z)
z1 = torch.stack([x,y],dim = 1)
print(z1)
z2 = torch.stack([x,y],dim = 2)
print(z2)5、形状操作
5.1、形状重组
reshape(size)、view(size)
reshape(size):与数组一致,改变tensor形状
import torch
# reshape
data = torch.randint(0, 10, (4, 3))
print(data)
# 1. 使用reshape改变形状
data1 = data.reshape(2, 2, 3)
print(data1)# 2. 使用-1表示自动计算
data2= data.reshape(2, -1)
print(data2)view(size):将内存连续的tensor形状改变返回新的内存连续tensor,reshape内存不连续
import torchtensor = torch.tensor([[1, 2, 3], [4, 5, 6]])# 使用view进行变形操作
tensor = tensor.view(2, -1)
print(tensor)# 再次使用view操作
try:tensor = tensor.view(3, -1)print("可以使用view")
except:print("不可以使用view")# 进行转置
tensor = tensor.t()
print(tensor)# 转置后使用view操作
try:tensor.view(3, -1)print("可以使用view")
except:print("不可以使用view")
5.2、维度元素个数交换
transpose(下标)、permute(下标)
transpose(维度下标):将两个指定的维度交换
import torch# transpose
x = torch.tensor([[[1, 2, 3], [4, 5, 6]],[[11, 22, 33], [44, 55, 66]]])
print(x,x.shape)
x1 = x.transpose(1,0) # 在不改变其他维度下进行了转置
print(x1,x1.shape)
permute(维度下标):多个下标,根据设置的顺序重新排列维度元素
import torch# permute
torch.manual_seed(666)
x = torch.randint(0,255,(2,3,4))
print(x,x.shape)
x2 = x.permute(2,0,1)
print(x2,x2.shape)
x3 = x.permute(2,1,0)
print(x3,x3.shape)5.3、维度展开
flatten(start_dim,end_dim)
flatten(start_dim,end_dim):默认从0到-1,所有维度都展开为一维;从start_dim维度开始,到end_dim-1维度结束展开
import torchx = torch.randint(0,255,(2,3,2))
print(x)
x1 = x.flatten()
print(x1)
x2 = x.flatten(start_dim=0,end_dim=1)
print(x2)5.4、降维和升维
squeeze()和unsqueeze()
squeeze:无参数默认将自动将所有元素个数为1的维度展开,参数为整数,表示维度下标
import torchimport torch
# 升维和降维
x = torch.randint(0,255,(1,3,4,1))
print(x.shape) # torch.Size([1, 3, 4, 1])# 元素个数为1的全部降维
x1= x.squeeze()
print(x1.shape) # torch.Size([3, 4])# 第一个维度释放
x11= x.squeeze(0) # torch.Size([3, 4, 1])
print(x11.shape)# 释放第二个维度操作失败,因为有多个元素
x11= x.squeeze(1) # torch.Size([1, 3, 4, 1])
print(x11.shape)# 升维度,必须填写参数
x2 = x.unsqueeze(0) # torch.Size([1, 1, 3, 4, 1])
print(x2.shape)x2 = x.unsqueeze(2) # torch.Size([1, 3, 1, 4, 1])
print(x2.shape)6、分割
chunk 和 split;参数都为(tensor,num,dim)
chunk 控制分割结果多少
split 控制分割数量大小
torch.chunk(x, 3,dim=0):参数1为tnsor对象;参数2为分割成多少个结果(不够数量,则值保留原大小,比如5个内容分为3份(2,2,1),2个内容分两份(1,1));参数3为dim,指定维度分隔
torch.split(x, 3,dim=0):参数1为tnsor对象;参数2为分割数量大小(不够数量,则值保留原大小,比如设置值为3,在原说内容切割3个内容分块,不够数量就只有一块);参数3为dim,指定维度分隔
import torchx = torch.tensor([[1, 2], [4, 5], [7, 8], [10, 11], [13, 14]])
# 分割成3块
print(torch.chunk(x, 3,dim=0))
print(torch.chunk(x, 3,dim=1))# 按照每块大小为4进行分割
print(torch.split(x, 4,dim=0))
print(torch.split(x, 4,dim=1))7、广播
两个tensor 直接加法或减法运算时,在某个维度的元素个数相等;某个tensor维度元素个数全是1;全部维度元素个数相等
若全部相等:直接对应元素计算
若某个维度相等,某个tenser其余维度元素个数全是1:将其广播到另一个tensor维度个数大小(复制1那个内容数据)在进行计算
若某个tensoru维度元素个数全为1,则广播值对应tensor维度个数
import torch# 某些维度相等,剩下维度个数为1
data1d = torch.tensor([[[1,1,1,1]],[[1,1,1,1]]])
data2d = torch.tensor([[[11,11,11,11], [22,22,22,22]],[[11,11,11,11], [22,22,22,22]]])
print(data1d.shape, data2d.shape)
# 进行计算:会自动进行广播机制
print(data1d + data2d)# 某些维度相等,剩下维度个数为1
data1d = torch.tensor([[[1,1,1,1]]])
data2d = torch.tensor([[[11,11,11,11], [22,22,22,22]],[[11,11,11,11], [22,22,22,22]]])
print(data1d.shape, data2d.shape)
# 进行计算:会自动进行广播机制
print(data1d + data2d)# 一个rensor维度个数全为1
data1d = torch.tensor([[1]])
data2d = torch.tensor([[[11,11,11,11], [22,22,22,22]],[[11,11,11,11], [22,22,22,22]]])
print(data1d.shape, data2d.shape)
# 进行计算:会自动进行广播机制
print(data1d + data2d)8、数据的函数运算
floor:向左取值;ceil:向右取值;round:四舍五入;trunc:保留整数;frac:保留小数;fix:向零方向取整数;abs:取绝对值;取余%:-3%2 结果为 1
import torch
data = torch.tensor([[1,2,-3.5],[4,5.1,6.5],[7.3,8,9.5],[10,11.8,-12.5]]
)
print(data)x1 = torch.floor(data) # 向左取值
print(x1)x1 = torch.ceil(data) # 向右取值
print(x1)# 使用python的round()函数
# 四舍六入,五看整数位数的奇偶性,奇进偶不进
x1 = torch.round(data) # 使用python的round()函数
print(x1)x1 = torch.trunc(data) # 只保留整数部分
print(x1)x1 = torch.frac(data) # 只保留小数部分
print(x1)x1 = torch.fix(data) # 向零方向保留整数(整数操作floor,负数操作ceil)
print(x1)x1 = data%2 # 取余 整数减,负数加
print(x1)x1 = torch.abs(data) # 取绝对值
print(x1)9、张量保存与加载
save 和 load
import torch
x = torch.tensor([1, 2 ,3])# save 保存到本地
torch.save(x, '../../data/tengsor_save.pt')# load 加载本地保存文件
x = torch.load("../../data/tengsor_save.pt",torch.device('cuda') )
print(x.device)10、并行化
get_num_threads 查看;set_num_threads 设置
线程数设置过高可能会导致线程竞争,反而降低性能;设置过低可能会导致计算资源未得到充分利用;当使用 GPU 进行计算时,线程数设置对性能影响较小,因为 GPU 计算并不依赖于 CPU 线程数
import torch
print(torch.get_num_threads())torch.set_num_threads(4)
print(torch.get_num_threads())相关文章:

深度学习2
四、tensor常见操作 1、元素值 1.1、获取元素值 tensor.item() 返回tensor的元素;只能在一个元素值使用,多个报错,当存在多个元素值时需要使用索引进行获取到一个元素值时在使用 item。 1.2、元素值运算 tensor对元素值的运算:…...
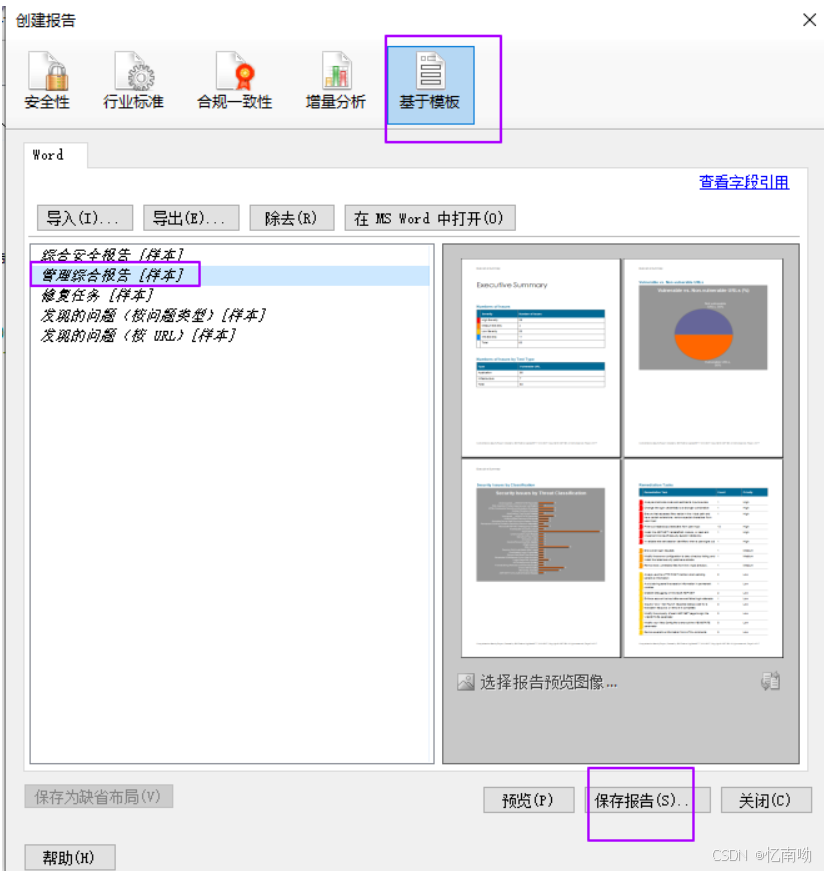
第六节-AppScan扫描报告
第六节-AppScan扫描报告 1.加载扫描结果 1.点击【打开】 2.选择之前保存过的扫描结果 3.等待加载完成 2.领导查看的报告 1.点击【报告】 2.模板选择为【缺省值】 3.最低严重性选择为【中】,测试类型选择为【应用程序】 4.点击【布局】 5.选择【其他徽标】&#x…...

【c++丨STL】stack和queue的使用及模拟实现
🌟🌟作者主页:ephemerals__ 🌟🌟所属专栏:C、STL 目录 前言 一、什么是容器适配器 二、stack的使用及模拟实现 1. stack的使用 empty size top push和pop swap 2. stack的模拟实现 三、queue的…...

基于SpringBoot的在线教育系统【附源码】
基于SpringBoot的在线教育系统 效果如下: 系统登录页面 系统管理员主页面 课程管理页面 课程分类管理页面 用户主页面 系统主页面 研究背景 随着互联网技术的飞速发展,线上教育已成为现代教育的重要组成部分。在线教育系统以其灵活的学习时间和地点&a…...

Kafka-副本分配策略
一、上下文 《Kafka-创建topic源码》我们大致分析了topic创建的流程,为了保持它的完整性和清晰度。细节并没有展开分析。下面我们就来分析下副本的分配策略以及副本中的leader角色的确定逻辑。当有了副本分配策略,才会得到分区对应的broker,…...

市场波动不断,如何自我提高交易心理韧性?
交易市场,一个由无数变量交织而成的复杂领域,常常因各方因素的微妙变化而掀起波澜。在这里,机遇与挑战并存,诱人的利润与潜在的风险如影随形,共同考验着每一位交易员的智慧与心理承受能力。在这样的环境下,…...

加速科技精彩亮相中国国际半导体博览会IC China 2024
11月18日—20日,第二十一届中国国际半导体博览会(IC China 2024)在北京国家会议中心顺利举办,加速科技携重磅产品及全系测试解决方案精彩亮相,加速科技创始人兼董事长邬刚受邀在先进封装创新发展论坛与半导体产业前沿与…...

利用c语言详细介绍下选择排序
选择排序(Selection sort)是一种简单直观的排序算法。它是每次选出最小或者最大的元素放在开头或者结尾位置(采用升序的方式),最终完成列表排序的算法。 一、图文介绍 我们还是使用数组【10,5,3…...

华为流程L1-L6业务流程深度细化到可执行
该文档主要介绍了华为业务流程的深度细化及相关内容,包括流程框架、建模方法、流程模块描述、流程图建模等,旨在帮助企业构建有效的流程体系,实现战略目标。具体内容如下: 华为业务流程的深度细化 流程层级:华为业务流程分为 L1 - L6 六个层级,L1 为流程大类,L2 为流程…...

bridge-multicast-igmpsnooping
# 1.topo # 2.创建命名空间 ip netns add ns0 ip netns add ns1 ip netns add ns2 ip netns add ns3 # 3.创建veth设备 ip link add ns0-veth0 type veth peer name hn0-veth0 ip link add ns1-veth0 type veth peer name hn1-veth0 ip link add ns2-veth0 type veth pe…...

git使用(一)
git使用(一) 为什么学习git?两种版本控制系统在github上创建一个仓库(repository)windows上配置git环境在Linux上配置git环境 为什么学习git? 代码写了好久不小心删了,可以使用git防止,每写一部分代码通…...

Linux环境安装MongoDB
文章目录 1. 查看Linux系统的发行版本2. 下载MongoDB3. 安装MongoDB3.1 新建几个目录,分别用来存储 MongoDB 的数据和日志3.2 新建日志文件3.3 新建配置文件 4. 将MongoDB注册为服务4.1 新建服务文件4.2 编写服务文件 5. MongoDB服务相关操作5.1 启动MongoDB服务5.2…...

Cyberchef使用功能之-多种压缩/解压缩操作对比
cyberchef的compression操作大类中有大量的压缩和解压缩操作,每种操作的功能和区别是什么,本章将进行讲解,作为我的专栏《Cyberchef 从入门到精通教程》中的一篇,详见这里。 关于文件格式和压缩算法的理论部分在之前的文章《压缩…...

TypeScript 装饰器都有那些应用场景?如何更快的上手?
TypeScript 装饰器简介 在 TypeScript 中,装饰器(Decorators)是一种特殊的语法,用于在类、类方法、属性、访问器等上动态地添加行为或修改现有行为。装饰器可以用来增强类的功能、修改方法的行为,或者修改类的元数据等…...

堆优化版本的Prim
prim和dijkstra每轮找最小边的松弛操作其实是同源的,因而受dijkstra堆优化的启发,那么prim也可以采用小根堆进行优化。时间复杂度也由 O ( n 2 ) O(n^2) O(n2)降为 O ( n l o g n ) O(nlogn) O(nlogn)。 测试一下吧:原题链接 #include <i…...

Ubuntu上安装MySQL并且实现远程登录
目录 下载网络工具 查看网络连接 更新系统软件包; 安装mysql数据库 查看mysql数据库状态 以数字ip形式显示mysql的监听状态。(默认监听端口是3306) 查看安装mysql数据库时系统创建的目录信息。 根据查询到的系统用户名以及随机密码&a…...

蓝桥杯每日真题 - 第21天
题目:(空间) 题目描述(12届 C&C B组A题) 解题思路: 转换单位: 内存总大小为 256MB,换算为字节: 25610241024268,435,456字节 计算每个整数占用空间: 每个 32 位整数占用…...

(长期更新)《零基础入门 ArcGIS(ArcMap) 》实验一(下)----空间数据的编辑与处理(超超超详细!!!)
续上篇博客(长期更新)《零基础入门 ArcGIS(ArcMap) 》实验一(上)----空间数据的编辑与处理(超超超详细!!!)-CSDN博客 继续更新 目录 什么是拓扑? 1.3.5道路…...

NLP论文速读(CVPR 2024)|使用DPO进行diffusion模型对齐
论文速读|Diffusion Model Alignment Using Direct Preference Optimization 论文信息: 简介: 本文探讨的背景是大型语言模型(LLMs)通过人类比较数据和从人类反馈中学习(RLHF)的方法进行微调,以…...

操作系统——揭开盖子
计算机执行时——取指执行 es:bx等于从0x9000开始,到0x90200结束...

从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器
从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器计算流体力学(CFD)的魅力在于它将抽象的数学方程转化为可执行的代码,让流体运动的奥秘在计算机中重现。对于已经掌握流体力学理论的中高级学习者来说&am…...

2026 西安 AI 问答曝光搭建技术解析:GEO 知识图谱 + 深度测评
随着大语言模型技术的快速普及,AI 搜索已经成为用户获取企业信息、商家服务的核心入口。根据中国互联网信息中心 2026 年发布的《中国人工智能搜索发展报告》显示,2025 年国内 AI 搜索用户规模突破 8.2 亿,日均搜索请求超过 20 亿次ÿ…...
:支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离)
Claude本地化部署终极方案(企业级容器化全栈手册):支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离
更多请点击: https://codechina.net 第一章:Claude本地化部署的架构全景与企业级价值定位 Claude本地化部署并非简单地将模型权重下载后运行,而是一套融合推理引擎优化、安全沙箱隔离、API网关治理与可观测性集成的端到端架构体系。其核心目…...

Burp Suite深度解析:从流量抓包到业务逻辑漏洞挖掘
1. 这不是“学个插件”——Burp Suite 是渗透测试的呼吸系统 很多人第一次听说 Burp Suite,是在某篇“三步拿下登录框”的速成教程里:装好Java、拖进浏览器代理、点几下Repeater就弹出密码明文。结果真去测一个中型SaaS后台,不到十分钟就卡在…...

自制极低频电流探头:负电阻补偿原理与低频方波测量实践
1. 项目概述:为极低频电流测量而生在电子测试领域,电流探头是个再常见不过的工具,无论是排查开关电源的纹波,还是分析电机驱动的波形,都离不开它。但如果你尝试用市面上常见的电流探头去观察一个频率低至几赫兹&#x…...

独立站内容分层:一层给 SEO,一层给 GEO
你的内容在喂两个完全不同的"阅读者" 你的博客文章,从来都不只有一个读者。 传统认知里,独立站内容的读者只有两类:真人访客和搜索引擎爬虫。SEO 优化的一切工作,本质上都是在讨好后者,顺带服务前者。 但…...

AI学习 - 大模型基础入门
AI学习 - 大模型基础入门 从零开始:Ollama 安装 → 本地模型运行 → Python 代码接入 → 理解核心概念 摘要 本文记录了在 Windows 上使用 Ollama 部署本地大模型、并通过 Python 代码接入调用的完整过程。内容涵盖:Ollama 安装与模型拉取、大模型基础概…...

GEO生成引擎优化:当AI成为信息分发的主角,品牌如何抢占对话窗口?
当用户不再"搜索-浏览",而是直接"AI提问-获取答案",传统SEO的逻辑正在被彻底改写。2026年,GEO(Generative Engine Optimization,生成式引擎优化)已经从概念走向规模化落地。本文从技术…...
)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)第一次戴上Meta Quest 3时,那种虚拟与现实交织的震撼感至今难忘。但作为开发者,更让我着迷的是如何让虚拟物体在真实空间中"记住"…...

通过用量看板分析团队大模型API消耗发现优化调用策略的机会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板分析团队大模型API消耗发现优化调用策略的机会 作为团队的技术负责人,确保大模型API调用在满足业务需求的…...