2024.6使用 UMLS 集成的基于 CNN 的文本索引增强医学图像检索
Enhancing Medical Image Retrieval with UMLS-Integrated CNN-Based Text Indexing
问题
- 医疗图像检索中,图像与相关文本的一致性问题,如患者有病症但影像可能无明显异常,影响图像检索系统准确性。
- 传统的基于文本的医学图像检索(TBMIR)方法存在不足,如简单关键字方法忽略医学实体含义,概念方法则耗时耗空间。
- 卷积神经网络(CNN)模型在医疗图像检索尤其是 TBMIR 中的应用效果不佳,原因是排名过程复杂,且现有模型未充分考虑医学领域特异性。
挑战
- 确定如何将 TBMIR 任务视为图像检索任务,而非传统信息检索或自然语言处理(NLP)任务,以充分发挥 CNN 在医疗图像检索中的潜力。
- 处理医疗图像和文本数据的语义关系,克服低级视觉特征与高级语义特征之间的差距,提高检索准确性。
创新点
- 提出一种基于深度匹配模型(DMM)和医学相关特征(MDF)的新方法,用于重新排序医疗图像,有效考虑了 TBMIR 任务特性。
- 利用统一医学语言系统(UMLS)构建语义相似性矩阵,通过个性化卷积神经网络(CNN)生成查询和图像元数据的有效表示,以实现更准确的匹配。
贡献
- 提出了一种创新的 SemRank 模型,利用 MDF 和 UMLS 改进医疗图像检索中的排名。
- 通过实验证明了将 MDF 和 UMLS 集成到 DMM 中可显著改善重排序过程,提高检索性能。
提出的方法
- 总体流程:利用相关性反馈整合图像和文本查询信息,将文本查询和图像元数据表示为 MDF,通过 UMLS 构建语义相似性矩阵,使用个性化 CNN 构建查询和文档的良好表示,计算匹配分数,最后结合基线分数进行重新排序。
- 具体步骤
- 初步步骤:将查询和文档表示为 MDF 集合,通过 MetaMap 工具将 MDF 转换为概念,使用 UMLS Similarity 工具计算概念间相似度构建语义相似性矩阵,将每个查询 / 文档转换为语义相似性矩阵。
- 深度匹配模型(DMM)构建
- 查询和文档矩阵提取:将查询和文档转换为 MDF 向量,再转换为语义相似性矩阵,通过与语义相似性矩阵相乘得到新的查询矩阵。
- 个性化 CNN
- 卷积层:设计多种查询和文档过滤器,计算如 MDF 共现、文档排名等特征,通过卷积操作产生输出向量。
- 激活函数:采用 ReLU 函数进行非线性变换。
- 池化层:使用最大池化聚合信息、减少表示并提取全局特征。
- 全连接层:生成最终的查询或文档向量表示。
- 匹配函数:采用基于表示的模型,使用余弦相似度计算查询和文档的相关性得分。
- SemRank 语义重新排序模型:结合 DMM 得分和基线得分(如 BM25),通过线性组合计算 SemRank 分数,对文档进行重新排序。
指标
- 平均准确率(MAP):用于衡量检索系统在多个查询下的平均性能。
- 精确率(P@5、P@10):分别表示在前 5 个和前 10 个检索结果中的精确率。
模型结构
- 输入层:接收以 MDF 表示的查询和文档。
- 隐藏层
- 包含卷积层,应用多种查询和文档过滤器提取特征。
- 激活函数层,使用 ReLU 函数进行非线性变换。
- 池化层,采用最大池化操作。
- 全连接层,生成最终向量表示。
- 输出层:输出查询和文档的相关性得分,用于排序。
结论
- 提出的 SemRank 模型利用外部语义资源(MDF 和 UMLS)改进了医疗图像检索排名。
- 在 Medical ImageCLEF 数据集上的实验表明,该模型在重排序过程中显著提升了性能,与多种现有方法相比具有优势。
剩余挑战和未来工作
- 剩余挑战:数据集的版权限制导致实验数据有限,部分模型(如 Bo1PRF)在处理包含大量非临床图像的数据集时表现较好,凸显了现有模型对图像多样性处理的不足。
- 未来工作
- 增强 CNN 模型,集成更多包含广泛检索属性的过滤器。
- 改进 SemRank 模型,融入视觉特征以提高图像检索精度。
抽象的
1. 简介
2.相关工作
2.1. 用于医学图像检索的 CNN
2.2. 医学图像检索中的语义
3. 我们的方法概述

- 初步步骤:
- 深度匹配模型流程:
4. 深度匹配模型:初步步骤
4.1. 医疗依赖特征
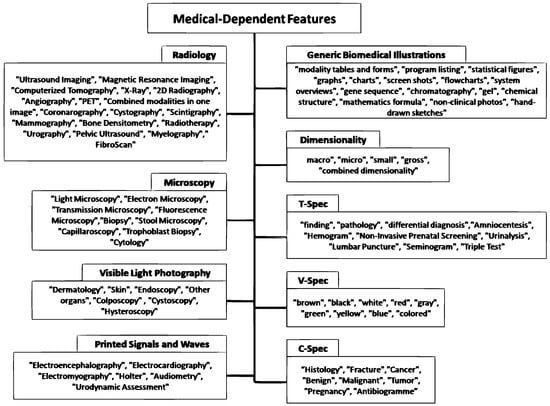
- 放射学= “超声成像”、“磁共振成像”、“计算机断层扫描”、“X 射线”、“2D 射线成像”、“血管造影”、“PET”、“单幅图像中的组合模式”、“冠状动脉造影”、“膀胱造影”、“闪烁显像”、“乳房 X 线摄影”、“骨密度测定”、“放射治疗”、“泌尿道造影”、“盆腔超声”、“脊髓造影”、“FibroScan”
- 显微镜检查= “光学显微镜检查”、“电子显微镜检查”、“透射显微镜检查”、“荧光显微镜检查”、“活检”、“粪便显微镜检查”、“毛细血管镜检查”、“滋养层活检”、“细胞学”
- 可见光摄影=“皮肤科”、“皮肤”、“内窥镜检查”、“其他器官”、“阴道镜检查”、“膀胱镜检查”、“宫腔镜检查”
- 打印信号和波= “脑电图”、“心电图”、“肌电图”、“动态心电图”、“听力测定”、“尿动力学评估”
- 通用生物医学插图= “模态表格和表格”、“程序列表”、“统计数字”、“图形”、“图表”、“屏幕截图”、“流程图”、“系统概述”、“基因序列”、“色谱”、“凝胶”、“化学结构”、“数学公式”、“非临床照片”、“手绘草图”
- 维度= “宏观”、“微观”、“小”、“总体”、“综合维度”
- V-Spec =“棕色”、“黑色”、“白色”、“红色”、“灰色”、“绿色”、“黄色”、“蓝色”、“彩色”
- T-spec = “发现”、“病理学”、“鉴别诊断”、“羊膜穿刺术”、“血象”、“无创产前筛查”、“尿液分析”、“腰椎穿刺”、“精液图”、“三重测试”
- C-spec = “组织学”、“骨折”、“癌症”、“良性”、“恶性”、“肿瘤”、“妊娠”、“抗生素谱”
4.2 语义矩阵构建
- 步骤 1:使用MetaMap 工具 [ 38 ] 将每个 MDF 转换为概念。
- 步骤 2:使用 UMLS相似度工具 [37,39 ]计算每对医学概念之间的相似度。这些语义相似度得分排列在语义矩阵中。更准确地说,我们使用 Resnik 度量来确定提取的概念之间的语义关系,因为根据 [ 40 ],它比基于路径的度量表现更好。
5.深度匹配模型构建
5.1 查询和文档矩阵提取
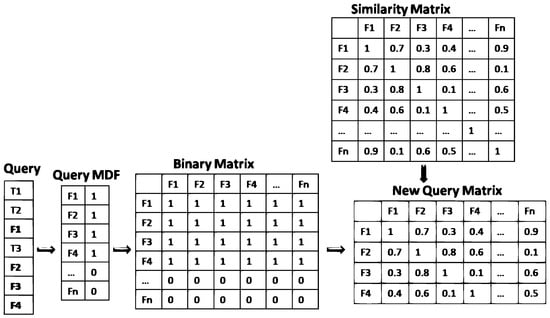
- 步骤 1:对于每个查询/文档向量,我们根据查询/文档是否包含特征值为每个 MDF 分配一个二进制值。结果向量V的长度等于n,其中n是 MDF 的数量。该向量被转换为𝑛 ∗ 𝑛n∗n矩阵M/ ∀ 𝑖 ∈ 𝑛 , ∀ 𝑗 ∈ 𝑛 , 𝑀 [ 𝑖 ] [ 𝑗 ] = 𝑉[ 𝑖 ]/∀我∈n,∀杰∈n,米[我][杰]=五[我]其中i表示行索引,j表示列索引。
- 第 2 步:将结果矩阵 M 与语义相似度矩阵 SSM 相乘,得到新的查询矩阵 NQM,如下所示:𝑁𝑄 𝑀 [ 𝑖 ] [ 𝑗 ] = 𝑀 [ 𝑖 ] [ 𝑗 ] ∗ 𝑆 𝑆 𝑀 [ 𝑖 ] [ 𝑗 ]否问米[我][杰]=米[我][杰]∗年代年代米[我][杰]计算说明如图3所示。
5.2. 个性化 CNN
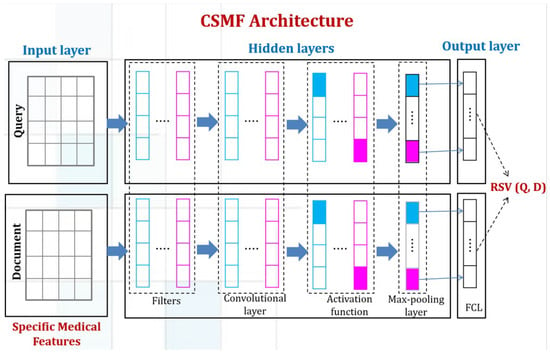
5.2.1. 卷积层
- 查询过滤器:
- 置信度查询过滤器 (CoQF):其思想包括计算查询 MDF 与所有 MDF 的共现。其中Q是查询 MDF,D是文档 MDF,𝑓𝑟 (𝑓𝑗)fr(f杰)是集合中查询 MDF 的共现,𝑓𝑟 (𝑓𝑖)fr(f我)是集合中文档 MDF 的共现,并且𝑓𝑟 (𝑓𝑖,𝑓𝑗)fr(f我,f杰)是集合中查询 MDF 和文档 MDF 的共现。𝐶 𝑜 𝑄 𝐹 =∑𝑗 ∈ 𝑄∑𝑖 ∈ 𝐷𝑓𝑟 (𝑓𝑖,𝑓𝑗)∑𝑖 ∈ 𝐷𝑓𝑟 (𝑓𝑖)碳o问F=∑杰∈问∑我∈德fr(f我,f杰)∑我∈德fr(f我)(1)为了考虑文档的长度,我们使用了这个过滤器。仅包含查询 MDF 的文档应该比除查询之外还包含其他 MDF 的文档更相关。事实上,两个文档都是具体的,但第一个文档更详尽。为此,我们建议用文档和查询中的 MDF 数量除以文档 MDF 的数量。如果文档不包含任何查询 MDF,则该值为 0。
- 长度查询过滤器 (LQF):对于每个查询,如果文档包含所有查询 MDF,则我们将文档和查询中的 MDF 数量除以文档 MDF 数量。否则,该值将等于 0。在哪里| 𝑀 𝐷 𝐹 ∈ ( 𝑄 , 𝐷 ) |米德F∈(问,德)是查询 MDF Q和文档 MDF D中的 MDF 数量,并且| 𝑀 𝐷 𝐹 ∈ 𝐷 |米德F∈德是包含所有查询 MDF 的文档中的 MDF 数量。𝐿 𝑄 𝐹 =| 𝑀 𝐷 𝐹 ∈ ( 𝑄 , 𝐷 ) || 𝑀 𝐷 𝐹 ∈ 𝐷 |大号问F=米德F∈(问,德)米德F∈德(2)
- 排名查询过滤器 (RQF):我们计算逆文档排名。如果文档未出现在第一次搜索中,则 RQF 将相等。𝑅 𝑄 𝐹 =1她的母亲R问F=1docr一个n钾(3)
- 邻近查询过滤器 (PQF):如果文档包含查询 MDF,我们将计算文档中这些 MDF 之间的距离的倒数。在这种情况下,两个特征之间的距离由位于它们之间的特征总数表示。在哪里𝑑 𝑖 𝑠 𝑡 𝑀 𝐷 𝐹 ∈ 𝐷d我s吨米德F∈德是文档 MDF 之间的距离。𝑃 𝑄 𝐹 =11 + ∑ 𝑑 𝑖 𝑠 𝑡 𝑀 𝐷 𝐹 ∈ 𝐷磷问F=11+∑d我s吨米德F∈德(4)
- PMI 查询过滤器 (PMIQF):PMI(逐点互信息)[ 41 ] 是一种用于查找具有相近含义的特征的度量。事实上,MDF 的 PMI𝑓𝑖f我和𝑓𝑗f杰是使用以下情况定义的𝑓𝑖f我(𝑓𝑟 (𝑓𝑖)fr(f我)) 和𝑓𝑗f杰(𝑓𝑟 (𝑓𝑗)fr(f杰)), 共现𝑓𝑟 (𝑓𝑖,𝑓𝑗)fr(f我,f杰)在特征向量内,N是集合大小。藝術本身𝐹 ( 𝑄 𝐹 ) = 𝑙 𝑜 𝑔𝑁× 𝑓𝑟 (𝑓𝑖,𝑓𝑗)𝑓𝑟 (𝑓𝑖) ×𝑓𝑟 (𝑓𝑗)磷米我F(问F)=升o克否×fr(f我,f杰)fr(f我)×fr(f杰)(5)该方程计算集合中语义上最接近的 MDF𝑓𝑖f我和𝑓𝑗f杰。
- 特征差异查询过滤器 (FDQF):未找到的查询 MDF 越少,文档的相关性越高。对于每个查询,我们计算不在文档 MDF 中的查询 MDF 数量的倒数。𝐹 𝐷 𝑄 𝐹 =11 + | 𝑀 𝐷 𝐹 ∈ { 𝑄 ∩ 𝐷 } |−−−−−−−−−−−−−−−−−−√F德问F=11+米德F∈问∩德(6)
- 文档过滤器:
- 置信度文档过滤器 (CoDF):此文档过滤器确定查询中包含的 MDF 文档总数。文档的相关性将与其包含的查询 MDF 数量成正比增加。在哪里(𝑓𝑖𝑞̲∩𝑓𝑗𝑑̲)f我问̲∩f杰d̲是查询中常见 MDF 的数量。𝐶 𝑜 𝐷 𝐹 = ∑ (𝑓𝑖𝑞̲∩𝑓𝑗𝑑̲)碳o德F=∑f我问̲∩f杰d̲(7)
- 长度文档过滤器 (LDF):对于文档,首先我们确定相关查询中包含的文档 MDF 的数量,得到该数量后,我们将其除以文档长度(𝐿 𝐷大号德)。事实上,如果文档的大小适中,并且与正在进行的查询具有几个共同的特征,那么文档的相关性就会增加。在哪里|他是一个强大的恶魔|米德Fdoc我n问你埃r是是文档和查询中的 MDF 数量,并且𝐿 𝐷大号德是使用 MDF 特征的文档长度。𝐿 𝐷 𝐹 =|他是一个强大的恶魔|𝐿 𝐷大号德F=米德Fdoc我n问你埃r是大号德(8)
- 排序文档过滤器 (RDF):𝑅 𝐷 𝐹 =∑𝑖∈𝑞𝑓𝑟 (𝑓𝑖𝑖 𝑛 𝑑 𝑜 𝑐 ) × 𝛾R德F=∑我∈问fr(f我我ndoc)×γ(9)变量𝑓𝑟 (𝑓𝑖)fr(f我)表示文档中查询 MDF 的频率,而𝛾γ表示查询在文档中的组织因子。𝛾γ如果查询在文档中保留其组织,则为 1,否则为 0.5。
- 邻近文档过滤器(PDF):查询中存在的文档特征越接近,其相关性就越高。在哪里𝐹𝐷∈𝑄F德∈问是查询中的文档 MDF。𝑃 𝐷 𝐹 =1|𝑓𝑖∈𝑄 |磷德F=1f我∈问(10)
- PMI 文档过滤器 (PMIDF):与查询过滤器中的 PMI 类似,文档过滤器中的 PMI 尝试查找具有相近含义的 MDF。它具有相同的公式,只是此过滤器中的N是文档大小。藝術本身𝐹 ( 𝐷𝐹 ) = 𝑙𝑜𝑔𝑁× 𝑓𝑟 (𝑓𝑖,𝑓𝑗)𝑓𝑟 (𝑓𝑖) ×𝑓𝑟 (𝑓𝑗)磷米我F(德F)=升o克否×fr(f我,f杰)fr(f我)×fr(f杰)(11)该方程计算文档中语义最接近的 MDF。
- 特征差异文档过滤器(FDDF):不在查询中的文档MDF数量越少,文档的相关性就越高。其中D是文档 MDF,Q是查询 MDF。𝐹 𝐷 𝐷 𝐹 =11 + | 𝑀 𝐷 𝐹 ∈ 𝐷 − 𝑄 |−−−−−−−−−−−−−−−−√F德德F=11+米德F∈德−问(12)
5.2.2. 激活函数
5.2.3. 池化层
5.2.4. 全连接层
5.3. 匹配函数
6. SemRank:基于DMM的语义重排序模型
7.实验与结果
7.1. 实验数据集

7.2. SemRank 模型在图像重排序中的有效性
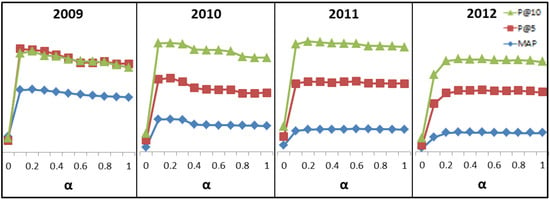
7.3. SemRank 模型与文献模型的比较

8. 结论和未来工作
作者贡献
资金
机构审查委员会声明


- McInnes, B.; Liu, Y.; Pedersen, T.; Melton, G.; Pakhomov, S. Umls::Similarity: Measuring the Relatedness and Similarity of Biomedical Concepts; Association for Computational Linguistics: Stroudsburg, PA, USA, 2013. [Google Scholar]
- Torjmen-Khemakhem, M.; Gasmi, K. Document/query expansion based on selecting significant concepts for context based retrieval of medical images. J. Biomed. Inform. 2019, 95, 103210. [Google Scholar] [CrossRef] [PubMed]
- Resnik, P. Semantic similarity in a taxonomy: An information-based measure and its application to problems of ambiguity in natural language. J. Artif. Intell. Res. 1999, 11, 95–130. [Google Scholar] [CrossRef]
相关文章:
2024.6使用 UMLS 集成的基于 CNN 的文本索引增强医学图像检索
Enhancing Medical Image Retrieval with UMLS-Integrated CNN-Based Text Indexing 问题 医疗图像检索中,图像与相关文本的一致性问题,如患者有病症但影像可能无明显异常,影响图像检索系统准确性。传统的基于文本的医学图像检索࿰…...

了解Redis(第一篇)
目录 Redis基础 什么事Redis Redis为什么这么快 除了 Redis,你还知道其他分布式缓存方案吗? 说-下 Redis 和 Memcached 的区别和共同点 为什么要用Redis? 什么是 Redis Module?有什么用? Redis基础 什么事Redis Redis (REmote DIctionary S…...

UE5 第一人称射击项目学习(二)
在上一章节中。 得到了一个根据视角的位置创建actor的项目。 现在要更近一步,对发射的子弹进行旋转。 不过,现在的子弹是圆球形态的,所以无法分清到底怎么旋转,所以需要把子弹变成不规则图形。 现在点开蓝图。 这里修改一下&…...

npm/cnpm的使用
npm 1、安装npm 前往nodejs官网下载安装node 验证是否安装成功node node -v node安装npm也会安装 npm -v 2、使用npm 1. 初始化项目 在一个项目文件夹中运行: npm init 根据提示输入项目信息(如项目名称、版本号等)。 如果你希望快速初…...

go-zero(六) JWT鉴权
go-zero JWT鉴权 还记得我们之前登录功能,返回的信息是token吗? 这个token其实就是JSON Web Token简称JWT,它是一种开放标准(RFC 7519),用于在网络应用环境间安全地传递声明信息。 它是一种基于 JSON 的令牌…...

做一个FabricJS.cc的中文文档网站——面向markdown编程
📢欢迎点赞 :👍 收藏 ⭐留言 📝 如有错误敬请指正,赐人玫瑰,手留余香!📢本文作者:由webmote 原创📢作者格言:新的征程,用爱发电&#…...

开发 + 安全:网络安全的协作方法
开发团队和安全团队之间由来已久的紧张关系一直是组织内部摩擦的根源。开发人员优先考虑速度和效率,旨在通过快节奏、迭代的开发周期快速交付功能和产品并高效前进。另一方面,安全团队努力平衡风险和创新,但必须专注于使用护栏保护敏感数据和…...

Next.js- App Router 概览
#题引:我认为跟着官方文档学习不会走歪路 一:App Router与Page Router 在 v13 版本中,Next.js 引入了一个基于 React 服务器组件 构建的新的 App Router,而在这之前,Next.js 使用的是Page Router。 目录结构 pages …...

python oa服务器巡检报告脚本的重构和修改(适应数盾OTP)有空再去改
Two-Step Vertification required: Please enter the mobile app OTPverification code: 01.因为巡检的服务器要双因子认证登录,也就是登录堡垒机时还要输入验证码。这对我的巡检查服务器的工作带来了不便。它的机制是每一次登录,算一次会话…...

【工控】线扫相机小结 第四篇
背景 这一片主要是对第三篇继续补充。话说上一篇讲到了两种模式的切换,上一篇还遗留了一个Bug,在这一篇里进行订正! 代码回顾 /// <summary>/// 其实就是打开触发/// </summary>void SetLineSacanWorkMode(){-----首先设置为帧…...

亲测解决Unpack operator in subscript requires Python 3.11 or newer
这个问题是在小虎想提前定义一个list,然后作为index list来调用另一个list里面的变量出现的问题。 环境 Ubuntu 22.04 + python 3.10 故障代码示例 NoneList = [None] * opt.spatial_dims TargetMask = Target[i] == torch.arange(1...

数据结构 ——— 堆排序算法的实现
目录 前言 向下调整算法(默认建大堆) 堆排序算法的实现(默认升序) 前言 在之前几章学习了如何用向上调整算法和向下调整算法对数组进行建大/小堆数据结构 ——— 向上/向下调整算法将数组调整为升/降序_对数组进行降序排序代码…...

On-Chip-Network之Topology
片上网络拓扑决定了网络中节点和通道之间的物理布局和连接。拓扑对整体网络性价比的影响是巨大的。拓扑决定了消息 必须经过的跳数(或路由器)以及跳数之间的互连长度,从而显著影响网络延迟。由于经过路由器和链路会产生功耗,因此 …...

2024年11月21日Github流行趋势
项目名称:twenty 项目维护者:charlesBochet, lucasbordeau, Weiko, FelixMalfait, bosiraphael项目介绍:正在构建一个由社区支持的现代化Salesforce替代品。项目star数:21,798项目fork数:2,347 项目名称:p…...

第三十八章 IOT 通信协议MQTT协议实现的中间件EMQXDocker安装与验证指南
EMQX概述以及Docker安装与验证指南 一、EMQX概述 EMQX(原名EMQ X),是一款完全开源、高度可伸缩、高可用的分布式MQTT消息服务器。它不仅支持MQTT协议,还兼容CoAP/LwM2M等多种物联网协议,是5G时代万物互联的重要消息引擎。这款软件由杭州映云科技有限公司开发,基于Erlan…...

Flume日志采集系统的部署,实现flume负载均衡,flume故障恢复
目录 安装包 flume的部署 负载均衡测试 故障恢复 安装包 在这里给大家准备好了flume的安装包 通过网盘分享的文件:apache-flume-1.9.0-bin.tar.gz 链接: https://pan.baidu.com/s/1DXMA4PxdDtUQeMB4J62xoQ 提取码: euz7 --来自百度网盘超级会员v4的分享 ----…...

CodiMD导出pdf失败或无中文
CodiMD导出pdf失败,弹出文件保存窗口,有个pdf文件能下载,但是保存的时候提示“网站出问题了”,实际到服务器上看会发现docker崩溃了。 解决办法: 使用最新的CodiMD镜像,如nabo.codimd.dev/hackmdio/hackmd:…...

数字图像处理(2):Verilog基础语法
(1)Verilog常见数据类型: reg型、wire型、integer型、parameter型 (2)Verilog 常见进制:二进制(b或B)、十进制(d或D)、八进制(o或O)、…...

Kafka 工作流程解析:从 Broker 工作原理、节点的服役、退役、副本的生成到数据存储与读写优化
Kafka:分布式消息系统的核心原理与安装部署-CSDN博客 自定义 Kafka 脚本 kf-use.sh 的解析与功能与应用示例-CSDN博客 Kafka 生产者全面解析:从基础原理到高级实践-CSDN博客 Kafka 生产者优化与数据处理经验-CSDN博客 Kafka 工作流程解析:…...

爬虫重定向问题解决
一,问题 做爬虫时会遇到强制重定向的链接,此时可以手动获取重定向后的链接 如下图情况 第二个链接是目标要抓取的,但它是第一个链接重定向过去的,第一个链接接口状态也是302 二,解决方法 请求第一个链接࿰…...

3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题
3个关键功能解析:USBToolBox如何简化macOS与Windows的USB端口映射难题 【免费下载链接】tool the USBToolBox tool 项目地址: https://gitcode.com/gh_mirrors/too/tool 在Hackintosh和跨平台开发领域,USB端口映射一直是个令人头疼的技术难题。US…...

AMLP:基于大语言模型的自动化机器学习势函数构建平台
1. 项目概述:当AI遇见原子模拟,AMLP如何重塑机器学习势函数构建在计算材料科学和化学物理领域,分子动力学模拟是我们窥探微观世界动态行为的“显微镜”。无论是研究新材料的相变过程,还是探索生物大分子的折叠机制,其核…...

从入门到上岗,Java+AI 复合型人才养成攻略
当下编程行业格局正在悄然改变,纯 Java 后端岗位内卷日趋严重,薪资增长逐步放缓;纯粹的 AI 算法岗门槛居高不下,对学历、数理功底要求严苛,普通开发者很难入局。 而Java+AI 复合型开发顺势成为行业刚需岗位,既依托成熟的 Java 体系承接业务开发,又能融入人工智能技术实…...

如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南
如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software developme…...

为内部知识库问答机器人接入Taotoken多模型增强回答效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答机器人接入Taotoken多模型增强回答效果 构建一个高效的企业内部知识库问答机器人,核心挑战在于如何让…...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...

收藏|2026年AI大模型就业爆发!岗位暴涨12倍、月薪6W+,小白零基础入门指南
2026年,AI已从“科技热点”彻底变为职场“刚需赛道”!脉脉高聘人才智库最新发布的《2026年1-2月中高端人才求职招聘洞察》,用硬核数据揭示行业真相:AI人才成招聘市场顶流,岗位量、薪资双双爆发式增长。尤其对零基础小白…...
)
Sora 2 GIF导出速度提升300%?20年多媒体架构师亲授GPU加速转码链路(CUDA 12.4 + cuVID硬编实测)
更多请点击: https://kaifayun.com 第一章:Sora 2 GIF导出方法概览 Sora 2 并非 OpenAI 官方发布的模型,当前(截至2024年)并无名为“Sora 2”的公开产品。因此,所谓“Sora 2 GIF导出”实为社区对视频生成工…...

Visual C++运行库一键安装指南:彻底解决Windows应用依赖问题
Visual C运行库一键安装指南:彻底解决Windows应用依赖问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过打开软件时弹出"缺少…...

Windows Cleaner如何5步解决C盘爆红问题?完全指南助你释放宝贵空间
Windows Cleaner如何5步解决C盘爆红问题?完全指南助你释放宝贵空间 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾经面对C盘爆红的警告束手无…...