关于SpringBoot集成Kafka
关于Kafka
Apache Kafka 是一个分布式流处理平台,广泛用于构建实时数据管道和流应用。它能够处理大量的数据流,具有高吞吐量、可持久化存储、容错性和扩展性等特性。
Kafka一般用作实时数据流处理、消息队列、事件架构驱动等
Kafka的整体架构

- ZooKeeper:
位于架构的顶部,负责管理和协调 Kafka 集群的各种元数据,包括集群配置、主题信息、分区领导者的选举等。
- Producers (生产者):
Kafka体系中的主要角色之一,它们负责产生消息并将其发送到 Kafka 集群中的相应主题。
- Brokers (代理/服务器):节点,也就是具体的Kafka实例,集群的组成单元,多个 Broker 组成一个集群。每个 Broker 存储着一部分主题的分区数据。
- Topics (主题):主题是消息的类别,生产者将消息发布到特定的主题。一个Brokers包含多个topic。
- Partitions (分区):每个主题可以划分为一个或多个分区,分区是物理上存储消息的地方。一个主题可以有多个分区
- Leaders and Followers (领导者和跟随者):对于每个分区,有一个 Leader 负责接受所有生产和消费请求,而 Follower 则复制 Leader (图中红色部分)的数据。
- Segments (段): 分区内部又细分为多个 Segment,每个 Segment 包括一个 .log 文件和其他相关文件,用于消息数据持久化。
- Partitions (分区):每个主题可以划分为一个或多个分区,分区是物理上存储消息的地方。一个主题可以有多个分区
- Topics (主题):主题是消息的类别,生产者将消息发布到特定的主题。一个Brokers包含多个topic。
- Consumers (消费者):
Kafka体系中的另一个主要角色,它们订阅主题并从 Kafka 集群中拉取消息。消费者可以组织成消费者组,同一组内的消费者共享消息。
Kafka的工作流程

- 消息发布
生产者创建消息并将它们发送到指定的主题。生产者可以选择将消息发送到特定的分区,或者让 Kafka 根据某种策略(如轮询、哈希等)自动选择分区。
- 消息存储
当消息到达Broker时,它会被追加到指定分区的日志文件末尾。每个分区都是一个独立的日志文件,按照偏移量(Offset)进行索引,确保消息的顺序性。
- 消息消费
消费者订阅感兴趣的主题,并从指定的分区读取消息。消费者通过维护一个偏移量来跟踪已经处理的消息,确保不会重复消费。
- 故障恢复
如果Broker发生故障,Kafka会从其他副本中选举一个新的Leader分区来继续提供服务,确保系统的高可用性。
SpringBoot集成Kafka
引入依赖
在SpringBoot框架下,可以直接通过引入Kafka依
<!-- Spring Kafka Starter --><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency>yaml配置详解
关于SpringBoot中使用Kafka的配置结构如下:
spring:kafka:bootstrap-servers: localhost:9092 # Kafka整体配置:服务器地址,可以是多个以逗号分隔consumer: #作为消费者的具体配置group-id: my-group # 消费者的组ID,属于同一组的消费者会互相竞争消费消息# …… 消费者其他的配置producer: #作为生产者的具体配置value-serializer: org.apache.kafka.common.serialization.StringSerializer # 值的序列化器#……其他控制生产者的配置各类参数配置说明:
| 归属 | 配置项 | 说明 | 默认值 | 作用 |
|---|---|---|---|---|
| 全局 | bootstrap-servers | 指定Kafka集群的地址,可以是多个地址,用逗号分隔 | - | 生产者和消费者通过这些地址与Kafka集群建立连接 |
| 消费者 | consumer.group-id | 指定消费者的组ID | - | 属于同一组的消费者会互相竞争消费消息,确保每个消息只被组内的一个消费者消费 |
consumer.auto-offset-reset | 当没有初始偏移量可用或当前偏移量不再存在时,自动重置偏移量的策略 | latest | 决定了在消费者组没有已知偏移量时,从哪里开始读取消息 | |
consumer.key-deserializer | 指定键的反序列化器 | org.apache.kafka.common.serialization.ByteArrayDeserializer | 将从Kafka接收到的字节数据转换为Java对象 | |
consumer.value-deserializer | 指定值的反序列化器 | org.apache.kafka.common.serialization.ByteArrayDeserializer | 将从Kafka接收到的字节数据转换为Java对象 | |
consumer.enable-auto-commit | 是否启用自动提交偏移量 | true | 如果启用,消费者会定期自动提交偏移量,否则需要手动提交 | |
consumer.auto-commit-interval | 自动提交偏移量的时间间隔(毫秒) | 5000(5秒) | 控制自动提交的频率 | |
consumer.max-poll-records | 单次轮询返回的最大记录数 | 500 | 控制每次轮询从Kafka获取的消息数量 | |
consumer.fetch-min-bytes | 消费者从Kafka获取数据的最小字节数 | 1 | 如果小于该值,Kafka不会立即返回数据,而是等待更多数据积累 | |
consumer.fetch-max-wait | 消费者从Kafka获取数据的最大等待时间(毫秒) | 500 | 控制消费者在没有足够数据时的等待时间 | |
consumer.session-timeout | 消费者会话超时时间(毫秒) | 10000(10秒) | 控制消费者在未发送心跳的情况下,Kafka认为其失效的时间 | |
| 生产者 | producer.key-serializer | 指定键的序列化器 | org.apache.kafka.common.serialization.ByteArraySerializer | 将Java对象转换为字节数据,以便发送到Kafka |
producer.value-serializer | 指定值的序列化器 | org.apache.kafka.common.serialization.ByteArraySerializer | 将Java对象转换为字节数据,以便发送到Kafka | |
producer.acks | 生产者发送消息时的确认模式 | 1 | 控制消息发送的可靠性 | |
producer.retries | 生产者发送消息失败时的重试次数 | 0 | 控制消息发送失败时的重试机制 | |
producer.batch-size | 生产者批量发送消息的大小(字节) | 16384(16KB) | 控制消息的批量发送,提高性能 | |
producer.linger-ms | 生产者在发送消息前等待的时间(毫秒),以便收集更多的消息进行批量发送 | 0 | 控制消息的批量发送,提高性能 |
示例配置
spring:kafka:# 指定Kafka集群的地址,可以是多个地址,用逗号分隔# 生产者和消费者通过这些地址与Kafka集群建立连接bootstrap-servers: localhost:9092consumer:# 指定消费者的组ID# 属于同一组的消费者会互相竞争消费消息,确保每个消息只被组内的一个消费者消费group-id: my-group# 当没有初始偏移量可用或当前偏移量不再存在时,自动重置偏移量的策略# 可选值: earliest, latest, none# earliest: 自动重置为最早的偏移量# latest: 自动重置为最新的偏移量# none: 如果没有找到消费者组的偏移量,则抛出异常auto-offset-reset: earliest# 指定键的反序列化器# 将从Kafka接收到的字节数据转换为Java对象key-deserializer: org.apache.kafka.common.serialization.StringDeserializer# 指定值的反序列化器# 将从Kafka接收到的字节数据转换为Java对象value-deserializer: org.apache.kafka.common.serialization.StringDeserializer# 是否启用自动提交偏移量# 如果启用,消费者会定期自动提交偏移量,否则需要手动提交enable-auto-commit: true# 自动提交偏移量的时间间隔(毫秒)# 控制自动提交的频率auto-commit-interval: 5000# 单次轮询返回的最大记录数# 控制每次轮询从Kafka获取的消息数量max-poll-records: 100# 消费者从Kafka获取数据的最小字节数# 如果小于该值,Kafka不会立即返回数据,而是等待更多数据积累fetch-min-bytes: 1# 消费者从Kafka获取数据的最大等待时间(毫秒)# 控制消费者在没有足够数据时的等待时间fetch-max-wait: 500# 消费者会话超时时间(毫秒)# 控制消费者在未发送心跳的情况下,Kafka认为其失效的时间session-timeout: 10000producer:# 指定键的序列化器# 将Java对象转换为字节数据,以便发送到Kafkakey-serializer: org.apache.kafka.common.serialization.StringSerializer# 指定值的序列化器# 将Java对象转换为字节数据,以便发送到Kafkavalue-serializer: org.apache.kafka.common.serialization.StringSerializer# 生产者发送消息时的确认模式# 可选值: 0, 1, all# 0: 不等待任何确认# 1: 等待leader节点确认# all: 等待所有副本节点确认acks: all# 生产者发送消息失败时的重试次数# 控制消息发送失败时的重试机制retries: 3# 生产者批量发送消息的大小(字节)# 控制消息的批量发送,提高性能batch-size: 16384# 生产者在发送消息前等待的时间(毫秒),以便收集更多的消息进行批量发送# 控制消息的批量发送,提高性能linger-ms: 1关于消费者的 auto-commit属性:
enable-auto-commit 是Kafka消费者的一个重要配置属性,它决定了消费者是否自动提交偏移量。
如果设置为true,即自动提交:
- 消费者会定期自动提交偏移量。
- 提交的频率由 auto-commit-interval 配置项决定,默认为5秒。
- 消费者在每次轮询后会检查是否需要提交偏移量,如果达到提交间隔时间,则提交当前偏移量。
设置为true的优势主要在于简化开发,如果消费者崩溃,重新启动后可以从上次提交的偏移量继续消费,避免重复消费大量消息。劣势则是自动提交的频率在处理大数据量是会有性能风险。
如果设置为false,即手动提交:
- 消费者不会自动提交偏移量。
- 开发者需要手动调用方法来提交偏移量(具体提交方法在下文)
- 可以在消息处理完成后立即提交偏移量,也可以批量提交。
设置为false的优势在于更为精准的控制,能有效提升性能,开发者可以完全控制何时提交偏移量,确保消息处理的可靠性和一致性。可以根据业务需求选择同步提交或异步提交,具有更强的灵活性。劣势则是如果忘记提交偏移量,可能会导致消息重复消费或丢失。
消费与生成的使用
进行消息监听与消费
消息的监听主要是通过@KafkaListener注解来完成,以下是一个例子:
@Service
public class KafkaConsumer {@Autowiredprivate DataService dataService;@KafkaListener(topics = "my-topic", groupId = "my-group")public void listen(String message) {//如果你的方法参数是一个 String 类型,那么默认情况下,这个参数会被解析为消息的值(Value)log.info("Received Message: {}" , message);dataService.OpData(message); }//如果你想同时获取消息的键(Key)和值(Value),可以使用 ConsumerRecord 对象。ConsumerRecord 包含了消息的所有信息,包括键、值、分区、偏移量等。@KafkaListener(topics = "my-topic")public void listen(ConsumerRecord<String, String> record) {log.info("Received Message Key: " + record.key());log.info("Received Message Value: " + record.value());log.info("Partition: " + record.partition());log.info("Offset: " + record.offset());}}关于@KafkaListener注解的参数如下:
| 参数 | 类型 | 说明 | 示例 |
|---|---|---|---|
topics | String[] | 指定要监听的主题列表。 | @KafkaListener(topics = "my-topic") |
topicPartitions | TopicPartitionOffset[] | 指定要监听的主题和分区。可以用于更细粒度的控制。 | @KafkaListener(topicPartitions = @TopicPartition(topic = "my-topic", partitions = { "0", "1" })) |
groupId | String | 指定消费者的组ID。如果在配置文件中已经指定了组ID,这里可以省略。 | @KafkaListener(topics = "my-topic", groupId = "my-group") |
containerFactory | String | 指定用于创建监听器容器的工厂Bean的名称。通常在配置类中定义。 | @KafkaListener(topics = "my-topic", containerFactory = "kafkaListenerContainerFactory") |
id | String | 指定监听器的唯一标识符。可以在监控和管理中使用。 | @KafkaListener(topics = "my-topic", id = "myListener") |
concurrency | String | 指定并发消费者线程的数量。 | @KafkaListener(topics = "my-topic", concurrency = "3") |
autoStartup | boolean | 指定监听器是否在应用程序启动时自动启动。 | @KafkaListener(topics = "my-topic", autoStartup = "false") |
properties | Map<String, String> | 指定额外的Kafka消费者属性。 | @KafkaListener(topics = "my-topic", properties = "max.poll.interval.ms:120000") |
groupIdPrefix | String | 指定组ID的前缀。实际的组ID将是前缀加上方法名。 | @KafkaListener(topics = "my-topic", groupIdPrefix = "prefix-") |
clientIdPrefix | String | 指定客户端ID的前缀。实际的客户端ID将是前缀加上方法名。 | @KafkaListener(topics = "my-topic", clientIdPrefix = "client-") |
containerProperties | ContainerProperties | 指定容器的属性。 | @KafkaListener(topics = "my-topic", containerProperties = @ContainerProperties(ackMode = AckMode.MANUAL)) |
errorHandler | String | 指定错误处理器Bean的名称。 | @KafkaListener(topics = "my-topic", errorHandler = "myErrorHandler") |
replyTemplate | String | 指定回复模板Bean的名称。 | @KafkaListener(topics = "my-topic", replyTemplate = "myReplyTemplate") |
replyTopic | String | 指定回复主题。 | @KafkaListener(topics = "my-topic", replyTopic = "reply-topic") |
replyTimeout | long | 指定回复超时时间(毫秒)。 | @KafkaListener(topics = "my-topic", replyTimeout = 5000) |
replyHeaders | String[] | 指定要传递的回复头。 | @KafkaListener(topics = "my-topic", replyHeaders = { "header1", "header2" }) |
groupIdIsolationLevel | IsolationLevel | 指定隔离级别。 | @KafkaListener(topics = "my-topic", groupIdIsolationLevel = IsolationLevel.READ_COMMITTED) |
containerGroup | String | 指定容器组。 | @KafkaListener(topics = "my-topic", containerGroup = "group1") |
额外说明一下containerFactory 参数,为了使用 containerFactory 参数,你需要在配置类中定义相应的工厂Bean:
@Configuration
@EnableKafka
public class KafkaConfig {@Beanpublic ConsumerFactory<String, String> consumerFactory() {Map<String, Object> props = new HashMap<>();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");props.put(ConsumerConfig.GROUP_ID_CONFIG, "my-group");props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);return new DefaultKafkaConsumerFactory<>(props);}@Beanpublic ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();factory.setConsumerFactory(consumerFactory());factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);return factory;}
}基于使用containerFactory配置一般主要用于手动提交的时候,可以在方法中使用提交参数,如下:
@Service
public class KafkaConsumer {@KafkaListener(topics = "my-topic",containerFactory = "kafkaListenerContainerFactory")public void listen(ConsumerRecord<String, String> record, Acknowledgment acknowledgment){log.info("Received Message: " + record.value());// 处理消息try {// 模拟消息处理Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}// 手动提交偏移量 enable-auto-commit为false的话acknowledgment.acknowledge();}
}消息生产
主要是基于KafkaTemplate进行消息的发送,可以根据需求,先定义生产者的工厂Bean:
@Configuration
public class KafkaProducerConfig {@Beanpublic ProducerFactory<String, String> producerFactory() {Map<String, Object> configProps = new HashMap<>();configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);return new DefaultKafkaProducerFactory<>(configProps);}@Beanpublic KafkaTemplate<String, String> kafkaTemplate() {return new KafkaTemplate<>(producerFactory());}
}封装生产者方法:
@Service
public class KafkaProducer {@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;/*** 发送字符串消息到指定主题** @param topic 主题名称* @param message 消息内容*/public void sendMessage(String topic, String message) {kafkaTemplate.send(topic, message);}/*** 发送带键的字符串消息到指定主题** @param topic 主题名称* @param key 消息键* @param message 消息内容*/public void sendMessageWithKey(String topic, String key, String message) {kafkaTemplate.send(topic, key, message);}/*** 异步发送消息并处理回调** @param topic 主题名称* @param message 消息内容* @param callback 回调函数*/public void sendAsyncMessage(String topic, String message, KafkaCallback<String, String> callback) {kafkaTemplate.send(topic, message).addCallback(callback);}/*** 异步发送带键的消息并处理回调** @param topic 主题名称* @param key 消息键* @param message 消息内容* @param callback 回调函数*/public void sendAsyncMessageWithKey(String topic, String key, String message, KafkaCallback<String, String> callback) {kafkaTemplate.send(topic, key, message).addCallback(callback);}
}为了支持异步发送消息并处理回调,定义回调不同的接口:
public interface KafkaCallback<K, V> extends ListenableFutureCallback<SendResult<K, V>> {@Overridedefault void onSuccess(SendResult<K, V> result) {//回调处理}@Overridedefault void onFailure(Throwable ex) {//处理}
}直接使用
@RestController
@RequestMapping("/kafka")
public class KafkaController {@Autowiredprivate KafkaProducerService kafkaProducerService;@PostMapping("/send")public String sendMessage(@RequestBody String message) {kafkaProducerService.sendMessage("my-topic", message);return "Message sent: " + message;}@PostMapping("/send-with-key")public String sendMessageWithKey(@RequestBody String message) {kafkaProducerService.sendMessageWithKey("my-topic", "key1", message);return "Message with key sent: " + message;}@PostMapping("/send-async")public String sendAsyncMessage(@RequestBody String message) {kafkaProducerService.sendAsyncMessage("my-topic", message, new KafkaCallback<String, String>());return "Async message sent: " + message;}@PostMapping("/send-async-with-key")public String sendAsyncMessageWithKey(@RequestBody String message) {kafkaProducerService.sendAsyncMessageWithKey("my-topic", "key1", message, new KafkaCallback<String, String>());return "Async message with key sent: " + message;}
}相关文章:
关于SpringBoot集成Kafka
关于Kafka Apache Kafka 是一个分布式流处理平台,广泛用于构建实时数据管道和流应用。它能够处理大量的数据流,具有高吞吐量、可持久化存储、容错性和扩展性等特性。 Kafka一般用作实时数据流处理、消息队列、事件架构驱动等 Kafka的整体架构 ZooKeeper:…...

4.STM32之通信接口《精讲》之IIC通信---软件实现IIC《深入浅出》面试必备!
接下正式,进入软件编写IIC时序了,并实现对MPU6050的控制,既然是软件实现,那么硬件方面,我仅需两根控制线即可,即:数据控制线SDA,时钟控制线SCL。(人为软件层面定义的&…...

6G通信技术对比5G有哪些不同?
6G,即第六代移动通信技术,是5G之后的延伸,代表了一种全新的通信技术发展方向。与5G相比,6G在多个方面都有显著的不同和提升,以下是对6G通信技术及其与5G差异的详细分析: 一、6G的基本特点 更高的传输速率…...

「Mac玩转仓颉内测版28」基础篇8 - 元组类型详解
本篇将介绍 Cangjie 中的元组类型,包括元组的定义、创建、访问、数据解构以及应用场景,帮助开发者掌握元组类型的使用。 关键词 元组类型定义元组创建元组访问数据解构应用场景 一、元组类型概述 在 Cangjie 中,元组是一种用于存储多种数据…...

WebStorm 2024.3/IntelliJ IDEA 2024.3出现elementUI提示未知 HTML 标记、组件引用爆红等问题处理
WebStorm 2024.3/IntelliJ IDEA 2024.3出现elementUI提示未知 HTML 标记、组件引用爆红等问题处理 1. 标题识别elementUI组件爆红 这个原因是: 在官网说明里,才版本2024.1开始,默认启用的 Vue Language Server,但是在 Vue 2 项目…...

机械设计学习资料
免费送大家学习资源,已整理好,仅供学习 下载网址: https://www.zzhlszk.com/?qZ02-%E6%9C%BA%E6%A2%B0%E8%AE%BE%E8%AE%A1%E8%A7%84%E8%8C%83SOP.zip...

Python 快速入门(上篇)❖ Python 字符串
Python 字符串 字符串格式化输出字符串拼接获取字符串长度字符串切片字符串处理方法 字符串格式化输出 name “xhx” age 30 # 方法1 print("我的名字是%s,今年%s岁了。 " % (name, age)) # 方法2 print(f"我的名字是{name},今年{age}岁了。")字符串拼接…...

Ubuntu中使用多版本的GCC
我的系统中已经安装了GCC11.4,在安装cuda时出现以下错误提示: 意思是当前的GCC版本过高,要在保留GCC11.4的同时安装GCC9并可以切换,可以通过以下步骤实现: 步骤 1: 安装 GCC 9 sudo apt-get update sudo apt-get ins…...

1+X应急响应(网络)文件包含漏洞:
常见网络攻击-文件包含漏洞&命令执行漏洞: 文件包含漏洞简介: 分析漏洞产生的原因: 四个函数: 产生漏洞的原因: 漏洞利用条件: 文件包含: 漏洞分类: 本地文件包含: …...
)
机器学习实战记录(1)
决策树——划分数据集 def splitDataSet(dataSet, axis, value): retDataSet [] #创建返回的数据集列表for featVec in dataSet: #遍历数据集if featVec[axis] value:reducedFeatVec featVec[:axis] #去掉axis特征reducedFeatVec.extend(featVec[axis1…...

PHP8解析php技术10个新特性
PHP8系列是 PHP编程语言的最新主线版本,带来了许多激动人心的新特性和改进。作为一名PHP开发者,了解这些更新能够帮助你编写更高效、安全和现代的代码。 8的核心技术知识点,包括语言特性、性能优化、安全增强以及开发者工具的改进。 Just-In…...

C++模版特化和偏特化
什么是模版特化 特化的含义:所谓特化,就是将泛型搞得具体化一些,从字面上来解释,就是为已有的模板参数进行一些使其特殊化的指定,使得以前不受任何约束的模板参数,或受到特定的修饰(例如const或…...
Simulink中Model模块的模型保护功能
在开发工作过程中,用户为想要知道供应商的开发能力,想要供应商的模型进行测试。面对如此要求,为了能够尽快拿到定点项目,供应商会选择一小块算法或是模型以黑盒的形式供客户测试。Simulink的Model模块除了具有模块引用的功能之外&…...
:文本编辑器的使用)
Linux常用工具的使用(2):文本编辑器的使用
实验题目:Linux常用工具的使用(2):文本编辑器的使用 实验目的: (1)理解文本编辑器vi的工作模式; (2)掌握文本编辑器的使用方法 实验内容: &a…...

【StarRocks】starrocks 3.2.12 【share-nothing】 多Be集群容器化部署
文章目录 一. 集群规划二.docker compose以及启动脚本卷映射对于网络环境变量 三. 集群测试用户新建、赋权、库表初始化断电重启扩容 BE 集群 一. 集群规划 部署文档 https://docs.starrocks.io/zh/docs/2.5/deployment/plan_cluster/ 分类描述FE节点1. 主要负责元数据管理、…...
联想ThinkServer服务器主要硬件驱动下载
联想ThinkServer服务器主要硬件驱动下载: 联想ThinkServer服务器主要硬件Windows Server驱动下载https://newsupport.lenovo.com.cn/commonProblemsDetail.html?noteid156404#D50...
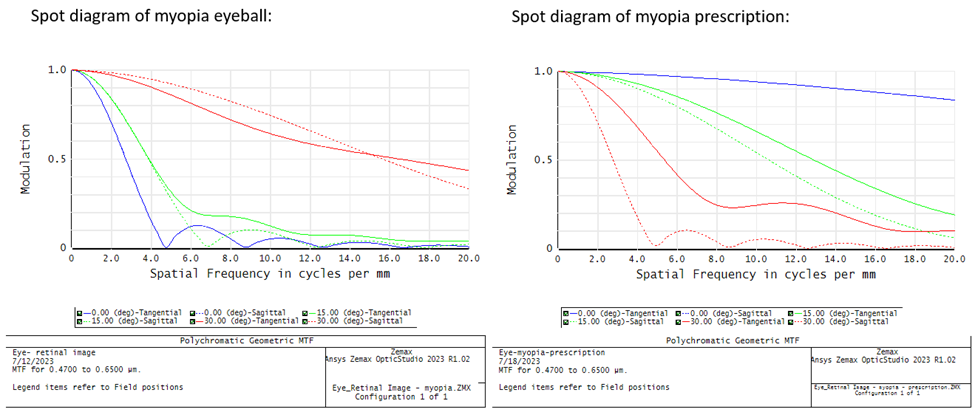
Ansys Zemax Optical Studio 中的近视眼及矫正
近视,通常称为近视眼,是一种眼睛屈光不正,导致远处物体模糊,而近处物体清晰。这是一种常见的视力问题,通常发生在眼球过长或角膜(眼睛前部清晰的部分)过于弯曲时。因此,进入眼睛的光…...

三次握手后的数据传输
一旦三次握手成功完成,TCP连接便正式建立,双方可以开始传输数据。在这个阶段,TCP协议利用其独特的可靠性和流控机制,确保数据的有序、无差错传输。 序列号与确认号:在数据传输过程中,TCP会为每个报文段分配…...

企业OA管理系统:Spring Boot技术实现与案例研究
摘要 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成熟。本文介绍了企业OA管理系统的开发全过程。通过分析企业OA管理系统管理的不足,创建了一个计算机管理企业OA管理系统的方案。文章介绍了企业OA管理系统的系统分析部…...

(免费送源码)计算机毕业设计原创定制:Java+JSP+HTML+JQUERY+AJAX+MySQL springboot计算机类专业考研学习网站管理系统
摘 要 大数据时代下,数据呈爆炸式地增长。为了迎合信息化时代的潮流和信息化安全的要求,利用互联网服务于其他行业,促进生产,已经是成为一种势不可挡的趋势。在大学生在线计算机类专业考研学习网站管理的要求下,开发一…...

CentOS 8/Stream 8系统DNF换源后,安装软件还是慢?试试这几个排查命令和优化技巧
CentOS 8/Stream 8系统DNF换源后安装缓慢的深度排查与优化指南当你已经按照教程将CentOS 8/Stream 8的DNF源切换为国内镜像,却发现软件安装速度依然不尽如人意时,这种体验确实令人沮丧。作为长期使用CentOS系统的技术专家,我完全理解这种&quo…...

为什么你明明很努力,领导却总看不到?问题出在这
许多测试同行在深夜加班排查Bug时,在凌晨赶写自动化脚本时,在对着海量数据做性能分析时,内心都会浮现一个共同的困惑:我明明已经这么拼了,为什么在领导眼里,我依然是个“找茬的”,而不是“创造价…...

ROS机器人仿真架构解析:基于wpr_simulation的移动操作机器人技术实现
ROS机器人仿真架构解析:基于wpr_simulation的移动操作机器人技术实现 【免费下载链接】wpr_simulation 项目地址: https://gitcode.com/gh_mirrors/wp/wpr_simulation 在机器人操作系统(ROS)开发领域,硬件依赖和测试成本一直是制约算法迭代效率的…...

告别繁琐审核!实测AI Agent如何重塑复杂非结构化票据与合同处理流程?
摘要:在企业数字化转型步入深水区的2026年,处理复杂非结构化票据与合同已成为横亘在财务、法务部门面前的“最后一公里”难题。传统RPA因UI变动易崩溃、主流智能体因缺乏API适配而无法落地,导致大量业务仍依赖低效的人工操作。本文由「企服AI…...

Oracle数据库的DBCA界面创建数据库
一、采用DBCA界面方式创建数据库搜索dbca用管理员去运行疯狂的点下一步采用默认就行到监听这里会出有一些问题出问题了先把Enterprise Manager关掉就行,出问题了能自己找出来就行,一般不建议关掉,我这里直接图方便了这里选择所有账号使用同一…...

Wand-Enhancer:完全免费解锁WeMod专业版功能的终极指南
Wand-Enhancer:完全免费解锁WeMod专业版功能的终极指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高昂订阅费用而烦…...

从‘调参苦手’到‘一击即中’:实战解读glmnet中lambda.min与lambda.1se到底怎么选
从‘调参苦手’到‘一击即中’:实战解读glmnet中lambda.min与lambda.1se到底怎么选 在机器学习的世界里,LASSO回归就像一位精明的裁缝,能够为数据量身定制最合身的模型。而glmnet包中的lambda.min和lambda.1se,则是这位裁缝手中的…...

告别U盘!用CentOS 7.9 + iPXE + dnsmasq搭建一个能同时装CentOS 7、AlmaLinux 8和Ubuntu 22.04的万能PXE服务器
打造全能PXE装机服务器:CentOS 7.9iPXEdnsmasq混合系统部署指南 当机房里的服务器数量超过两位数时,U盘安装系统就像用滴管给游泳池注水——效率低得令人发指。我曾用三个通宵手动安装了50台服务器,直到发现PXE网络装机这个"工业级"…...

DS4Windows终极指南:5分钟让PS手柄在Windows电脑上完美运行
DS4Windows终极指南:5分钟让PS手柄在Windows电脑上完美运行 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PS4/PS5手柄在Windows电脑上无法识别而烦恼吗?DS…...

JMeter临界部分控制器正确用法与避坑指南
1. 为什么“临界部分控制器”是压测中真正卡住团队的隐形瓶颈很多人第一次在JMeter里看到临界部分控制器(Critical Section Controller),第一反应是:“这不就是个带锁的逻辑块?加个锁而已,能有多复杂&#…...