大数据调度组件之Apache DolphinScheduler
Apache DolphinScheduler 是一个分布式易扩展的可视化 DAG 工作流任务调度系统。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
主要特性
- 易于部署,提供四种部署方式,包括Standalone、Cluster、Docker和Kubernetes
- 易于使用,可以通过四种方式创建和管理工作流,包括Web UI、Python SDK和Open API
- 高可靠高可用,多主多从的去中心化架构,原生支持横向扩展
- 高性能,性能比其他编排平台快N倍,每天可支持千万级任务
- Cloud Native,DolphinScheduler支持编排多云/数据中心工作流,支持自定义任务类型
- 对工作流和工作流实例(包括任务)进行版本控制
- 工作流和任务的多种状态控制,支持随时暂停/停止/恢复它们
- 多租户支持
- 其他如补数支持(Web UI 原生),包括项目和数据源的权限控制
单节点部署
安装包下载
- JDK:下载JDK (1.8+),安装并配置
JAVA_HOME环境变量,并将其下的bin目录追加到PATH环境变量中。如果你的环境中已存在,可以跳过这步。 - 二进制包:在下载页面下载 DolphinScheduler 二进制包
解压并启动 DolphinScheduler
二进制压缩包中有 Standalone 启动的脚本,解压后即可快速启动。
切换到有sudo权限的用户,运行脚本:
# 解压并运行 Standalone Server
tar -xvzf apache-dolphinscheduler-*-bin.tar.gz
cd apache-dolphinscheduler-*-bin
bash ./bin/dolphinscheduler-daemon.sh start standalone-server登录 DolphinScheduler
浏览器访问地址 http://localhost:12345/dolphinscheduler/ui 即可登录系统UI。
默认的用户名和密码是 admin/dolphinscheduler123
启停服务
脚本 ./bin/dolphinscheduler-daemon.sh 除了可以快捷启动 standalone 外,还能停止服务运行,全部命令如下
# 启动 Standalone Server 服务
bash ./bin/dolphinscheduler-daemon.sh start standalone-server
# 停止 Standalone Server 服务
bash ./bin/dolphinscheduler-daemon.sh stop standalone-server配置数据库
Standalone server 使用 H2 数据库作为其元数据存储数据,这是为了上手简单,用户在启动服务器之前不需要启动数据库。
但是如果用户想将元数据库存储在 MySQL 或 PostgreSQL 等其他数据库中,他们必须更改一些配置。
请参考 数据源配置 Standalone 切换元数据库 创建并初始化数据库
伪集群部署
安装包下载
伪分布式部署 Apache DolphinScheduler 需要有外部软件的支持
- JDK:下载JDK (1.8+),安装并配置
JAVA_HOME环境变量,并将其下的bin目录追加到PATH环境变量中。如果你的环境中已存在,可以跳过这步。 - 二进制包:在下载页面下载 DolphinScheduler 二进制包
- 数据库:PostgreSQL (8.2.15+) 或者 MySQL (5.7+),两者任选其一即可,如 MySQL 则需要 JDBC Driver 8.0.16
- 注册中心:ZooKeeper (3.4.6+),下载地址
- 进程树分析
- macOS安装
pstree - Fedora/Red/Hat/CentOS/Ubuntu/Debian安装
psmisc
- macOS安装
注意:\ DolphinScheduler 本身不依赖 Hadoop、Hive、Spark,但如果你运行的任务需要依赖他们,就需要有对应的环境支持
配置用户免密及权限
创建部署用户,并且一定要配置 sudo 免密。以创建 dolphinscheduler 用户为例
# 创建用户需使用 root 登录
useradd dolphinscheduler# 添加密码
echo "dolphinscheduler" | passwd --stdin dolphinscheduler# 配置 sudo 免密
sed -i '$adolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' /etc/sudoers
sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers# 修改目录权限,使得部署用户对二进制包解压后的 apache-dolphinscheduler-*-bin 目录有操作权限
chown -R dolphinscheduler:dolphinscheduler apache-dolphinscheduler-*-bin启动zookeeper
进入 zookeeper 的安装目录,将 zoo_sample.cfg 配置文件复制到 conf/zoo.cfg,并将 conf/zoo.cfg 中 dataDir 中的值改成 dataDir=./tmp/zookeeper
# 启动 zookeeper
./bin/zkServer.sh start修改 install_env.sh 文件
文件 install_env.sh 描述了哪些机器将被安装 DolphinScheduler 以及每台机器对应安装哪些服务。
您可以在路径 bin/env/install_env.sh 中找到此文件,可通过以下方式更改env变量,export =,配置详情如下。
# ---------------------------------------------------------
# INSTALL MACHINE
# ---------------------------------------------------------
# Due to the master, worker, and API server being deployed on a single node, the IP of the server is the machine IP or localhost
ips="localhost"
sshPort="22"
masters="localhost"
workers="localhost:default"
alertServer="localhost"
apiServers="localhost"# DolphinScheduler installation path, it will auto-create if not exists
installPath=~/dolphinscheduler# Deploy user, use the user you create in section **Configure machine SSH password-free login**
deployUser="dolphinscheduler"修改 dolphinscheduler_env.sh 文件
文件 ./bin/env/dolphinscheduler_env.sh 描述了下列配置:
- DolphinScheduler 的数据库配置,详细配置方法见初始化数据库
- 一些任务类型外部依赖路径或库文件,如
JAVA_HOME和SPARK_HOME都是在这里定义的 - 注册中心
zookeeper - 服务端相关配置,比如缓存,时区设置等
如果不使用某些任务类型,可以忽略任务外部依赖项,但必须根据环境更改 JAVA_HOME、注册中心和数据库相关配置。
# JAVA_HOME, will use it to start DolphinScheduler server
export JAVA_HOME=${JAVA_HOME:-/opt/soft/java}# Database related configuration, set database type, username and password
export DATABASE=${DATABASE:-postgresql}
export SPRING_PROFILES_ACTIVE=${DATABASE}
export SPRING_DATASOURCE_URL="jdbc:postgresql://127.0.0.1:5432/dolphinscheduler"
export SPRING_DATASOURCE_USERNAME={user}
export SPRING_DATASOURCE_PASSWORD={password}# DolphinScheduler server related configuration
export SPRING_CACHE_TYPE=${SPRING_CACHE_TYPE:-none}
export SPRING_JACKSON_TIME_ZONE=${SPRING_JACKSON_TIME_ZONE:-UTC}
export MASTER_FETCH_COMMAND_NUM=${MASTER_FETCH_COMMAND_NUM:-10}# Registry center configuration, determines the type and link of the registry center
export REGISTRY_TYPE=${REGISTRY_TYPE:-zookeeper}
export REGISTRY_ZOOKEEPER_CONNECT_STRING=${REGISTRY_ZOOKEEPER_CONNECT_STRING:-localhost:2181}# Tasks related configurations, need to change the configuration if you use the related tasks.
export HADOOP_HOME=${HADOOP_HOME:-/opt/soft/hadoop}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/opt/soft/hadoop/etc/hadoop}
export SPARK_HOME1=${SPARK_HOME1:-/opt/soft/spark1}
export SPARK_HOME2=${SPARK_HOME2:-/opt/soft/spark2}
export PYTHON_HOME=${PYTHON_HOME:-/opt/soft/python}
export HIVE_HOME=${HIVE_HOME:-/opt/soft/hive}
export FLINK_HOME=${FLINK_HOME:-/opt/soft/flink}
export DATAX_HOME=${DATAX_HOME:-/opt/soft/datax}export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$FLINK_HOME/bin:$DATAX_HOME/bin:$PATH初始化数据库
DolphinScheduler 元数据存储在关系型数据库中,目前支持 PostgreSQL 和 MySQL。
下面分别介绍如何使用 MySQL 和 PostgresQL 初始化数据库。
如果使用 MySQL 需要手动下载 mysql-connector-java 驱动 (8.0.16) 并移动到 DolphinScheduler 的每个模块的 libs 目录下,其中包括
api-server/libs和alert-server/libs和master-server/libs和worker-server/libs。
对于MySQL 5.6 / 5.7:
mysql -uroot -pmysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;# 修改 {user} 和 {password} 为你希望的用户名和密码
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'%' IDENTIFIED BY '{password}';
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'localhost' IDENTIFIED BY '{password}';mysql> flush privileges;对于MySQL 8:
mysql -uroot -pmysql> CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;# 修改 {user} 和 {password} 为你希望的用户名和密码
mysql> CREATE USER '{user}'@'%' IDENTIFIED BY '{password}';
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'%';
mysql> CREATE USER '{user}'@'localhost' IDENTIFIED BY '{password}';
mysql> GRANT ALL PRIVILEGES ON dolphinscheduler.* TO '{user}'@'localhost';
mysql> FLUSH PRIVILEGES;对于 PostgreSQL:
# 采用命令行工具登陆 PostgreSQL
psql
# 创建数据库
postgres=# CREATE DATABASE dolphinscheduler;
# 修改 {user} 和 {password} 为你希望的用户名和密码
postgres=# CREATE USER {user} PASSWORD {password};
postgres=# ALTER DATABASE dolphinscheduler OWNER TO {user};
# 退出 PostgreSQL
postgres=#\q
# 在终端执行如下命令,向配置文件新增登陆权限,并重载 PostgreSQL 配置,替换 {ip} 为对应的 DS 集群服务器 IP 地址段
echo "host dolphinscheduler {user} {ip} md5" >> $PGDATA/pg_hba.conf
pg_ctl reload然后修改./bin/env/dolphinscheduler_env.sh,将username和password改成你在上一步中设置的用户名{user}和密码{password}
对于 MySQL:
# for mysql
export DATABASE=${DATABASE:-mysql}
export SPRING_PROFILES_ACTIVE=${DATABASE}
export SPRING_DATASOURCE_URL="jdbc:mysql://127.0.0.1:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=false"
export SPRING_DATASOURCE_USERNAME={user}
export SPRING_DATASOURCE_PASSWORD={password}对于 PostgreSQL:
# for postgresql
export DATABASE=${DATABASE:-postgresql}
export SPRING_PROFILES_ACTIVE=${DATABASE}
export SPRING_DATASOURCE_URL="jdbc:postgresql://127.0.0.1:5432/dolphinscheduler"
export SPRING_DATASOURCE_USERNAME={user}
export SPRING_DATASOURCE_PASSWORD={password}完成上述步骤后,您已经为 DolphinScheduler 创建一个新数据库,现在你可以通过快速的 Shell 脚本来初始化数据库
bash tools/bin/upgrade-schema.sh启动 DolphinScheduler
使用上面创建的部署用户运行以下命令完成部署,部署后的运行日志将存放在 logs 文件夹内。
bash ./bin/install.sh注意:\ 第一次部署的话,可能出现 5 次
sh: bin/dolphinscheduler-daemon.sh: No such file or directory相关信息,此为非重要信息直接忽略即可
登录 DolphinScheduler
浏览器访问地址 http://localhost:12345/dolphinscheduler/ui 即可登录系统UI。默认的用户名和密码是 admin/dolphinscheduler123
启停服务
# 一键停止集群所有服务
bash ./bin/stop-all.sh# 一键开启集群所有服务
bash ./bin/start-all.sh# 启停 Master
bash ./bin/dolphinscheduler-daemon.sh stop master-server
bash ./bin/dolphinscheduler-daemon.sh start master-server# 启停 Worker
bash ./bin/dolphinscheduler-daemon.sh start worker-server
bash ./bin/dolphinscheduler-daemon.sh stop worker-server# 启停 Api
bash ./bin/dolphinscheduler-daemon.sh start api-server
bash ./bin/dolphinscheduler-daemon.sh stop api-server# 启停 Alert
bash ./bin/dolphinscheduler-daemon.sh start alert-server
bash ./bin/dolphinscheduler-daemon.sh stop alert-serverDocker 部署
使用 standalone-server 镜像
使用 Standalone-server 镜像启动一个 DolphinScheduler standalone-server 容器应该是最快体验 DolphinScheduler 的方法。
通过这个方式 你可以最快速的体验到 DolphinScheduler 的大部分功能,了解主要和概念和内容。
DOLPHINSCHEDULER_VERSION=3.1.5
docker run --name dolphinscheduler-standalone-server -p 12345:12345 -p 25333:25333 -d apache/dolphinscheduler-standalone-server:"${DOLPHINSCHEDULER_VERSION}"注意:请不要将 apache/dolphinscheduler-standalone-server 镜像作为生产镜像,应该仅仅作为快速体验 DolphinScheduler 的功能的途径。
除了因为他将全部服务运行在一个进程中外,还因为其使用内存数据库 H2 储存其元数据,当服务停止时内存数据库中的数据将会被清空。 另外 apache/dolphinscheduler-standalone-server 仅包含 DolphinScheduler 核心服务,部分任务组件(如 Spark 和 Flink 等), 告警组件(如 Telegram 和 Dingtalk 等)需要外部的组件或对应的配置后
使用 docker-compose 启动服务
使用 docker-compose启动服务相比 standalone-server 的优点是 DolphinScheduler 的各个是独立的容器和进程,相互影响降到最小,且能够在服务重启的时候保留元数据(如需要挂载到本地路径需要做指定)。
更健壮,能保证用户体验更加完整的 DolphinScheduler 服务。
这种方式需要先安装 docker-compose,链接适用于 Mac,Linux,Windows。
安装完成 docker-compose 后我们需要修改部分配置以便能更好体验 DolphinScheduler 服务,我们需要配置不少于 4GB 的空闲内存:
- Mac:点击
Docker Desktop -> Preferences -> Resources -> Memory调整内存大小 - Windows Docker Desktop:
- Hyper-V 模式:点击
Docker Desktop -> Settings -> Resources -> Memory调整内存大小 - WSL 2 模式 模式:参考 WSL 2 utility VM 调整内存大小
- Hyper-V 模式:点击
配置完成后我们需要获取 docker-compose.yaml 文件,通过下载页面下载对应版本源码包可能是最快的方法,源码包对应的值为 "Total Source Code"。
当下载完源码后就可以运行命令进行部署了。
DOLPHINSCHEDULER_VERSION=3.1.5
tar -zxf apache-dolphinscheduler-"${DOLPHINSCHEDULER_VERSION}"-src.tar.gz
# Mac Linux 用户
cd apache-dolphinscheduler-"${DOLPHINSCHEDULER_VERSION}"-src/deploy/docker
# Windows 用户, `cd apache-dolphinscheduler-"${DOLPHINSCHEDULER_VERSION}"-src\deploy\docker`# 如果需要初始化或者升级数据库结构,需要指定profile为schema
docker-compose --profile schema up -d# 启动dolphinscheduler所有服务,指定profile为all
docker-compose --profile all up -d提醒:通过 docker-compose 启动服务时,除了会启动 DolphinScheduler 对应的服务外,还会启动必要依赖服务,如数据库 PostgreSQL(用户
root, 密码root, 数据库dolphinscheduler) 和 服务发现 ZooKeeper。
沿用已有的 PostgreSQL 和 ZooKeeper 服务
使用 docker-compose 启动服务会新启动数据库,以及 ZooKeeper 服务。
如果你已经有在运行中的数据库,或者 ZooKeeper 且不想启动新的服务,可以使用这个方式分别启动 DolphinScheduler 容器。
DOLPHINSCHEDULER_VERSION=3.1.5
# 初始化数据库,其确保数据库 <DATABASE> 已经存在
docker run -d --name dolphinscheduler-tools \-e DATABASE="postgresql" \-e SPRING_DATASOURCE_URL="jdbc:postgresql://localhost:5432/<DATABASE>" \-e SPRING_DATASOURCE_USERNAME="<USER>" \-e SPRING_DATASOURCE_PASSWORD="<PASSWORD>" \--net host \apache/dolphinscheduler-tools:"${DOLPHINSCHEDULER_VERSION}" tools/bin/upgrade-schema.sh
# 启动 DolphinScheduler 对应的服务
docker run -d --name dolphinscheduler-master \-e DATABASE="postgresql" \-e SPRING_DATASOURCE_URL="jdbc:postgresql://localhost:5432/dolphinscheduler" \-e SPRING_DATASOURCE_USERNAME="<USER>" \-e SPRING_DATASOURCE_PASSWORD="<PASSWORD>" \-e REGISTRY_ZOOKEEPER_CONNECT_STRING="localhost:2181" \--net host \-d apache/dolphinscheduler-master:"${DOLPHINSCHEDULER_VERSION}"
docker run -d --name dolphinscheduler-worker \-e DATABASE="postgresql" \-e SPRING_DATASOURCE_URL="jdbc:postgresql://localhost:5432/dolphinscheduler" \-e SPRING_DATASOURCE_USERNAME="<USER>" \-e SPRING_DATASOURCE_PASSWORD="<PASSWORD>" \-e REGISTRY_ZOOKEEPER_CONNECT_STRING="localhost:2181" \--net host \-d apache/dolphinscheduler-worker:"${DOLPHINSCHEDULER_VERSION}"
docker run -d --name dolphinscheduler-api \-e DATABASE="postgresql" \-e SPRING_DATASOURCE_URL="jdbc:postgresql://localhost:5432/dolphinscheduler" \-e SPRING_DATASOURCE_USERNAME="<USER>" \-e SPRING_DATASOURCE_PASSWORD="<PASSWORD>" \-e REGISTRY_ZOOKEEPER_CONNECT_STRING="localhost:2181" \--net host \-d apache/dolphinscheduler-api:"${DOLPHINSCHEDULER_VERSION}"
docker run -d --name dolphinscheduler-alert-server \-e DATABASE="postgresql" \-e SPRING_DATASOURCE_URL="jdbc:postgresql://localhost:5432/dolphinscheduler" \-e SPRING_DATASOURCE_USERNAME="<USER>" \-e SPRING_DATASOURCE_PASSWORD="<PASSWORD>" \-e REGISTRY_ZOOKEEPER_CONNECT_STRING="localhost:2181" \--net host \-d apache/dolphinscheduler-alert-server:"${DOLPHINSCHEDULER_VERSION}"注意:如果你本地还没有对应的数据库和 ZooKeeper 服务,但是想要尝试这个启动方式,可以先安装并启动 PostgreSQL(8.2.15+) 以及 ZooKeeper(3.8.0)
本文完!
本文由 白鲸开源科技 提供发布支持!
相关文章:
大数据调度组件之Apache DolphinScheduler
Apache DolphinScheduler 是一个分布式易扩展的可视化 DAG 工作流任务调度系统。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。 主要特性 易于部署,提供四种部署方式,包括Standalone、Cluster、Docker和…...

介绍一下strlwr(arr);(c基础)
hi , I am 36 适合对象c语言初学者 strlwr(arr);函数是把arr数组变为小写字母 格式 #include<string.h> strlwr(arr); 返回值为arr 链接分享一下arr的意义(c基础)(必看)(牢记)-CSDN博客 #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #incl…...

meterpreter常用命令 上
Meterpreter 是 Metasploit 框架中的一个高级 Payload,广泛用于渗透测试和攻击模拟。以下是一些常用的 Meterpreter 命令: 1. 基本命令 sysinfo 显示目标系统的基本信息(操作系统、架构等)。 getuid 获取当前用户的身份信息。…...

【kubernetes】kubernetes各组件的调用关系
目录 1. 说明2. Kubernetes组件概述2.1 控制平面组件2.2 节点组件 3. Kubernetes组件调用关系4. 示例说明 1. 说明 1.Kubernetes是一个开源的容器编排工具,其各个组件之间存在着复杂的调用关系,共同构建起一个完整的容器编排系统。2.Kubernetes集群主要…...

Java-08 深入浅出 MyBatis - 多对多模型 SqlMapConfig 与 Mapper 详细讲解测试
点一下关注吧!!!非常感谢!!持续更新!!! 大数据篇正在更新!https://blog.csdn.net/w776341482/category_12713819.html 目前已经更新到了: MyBatisÿ…...

Vue.js修饰符
Vue.js 是一个渐进式JavaScript框架,用于构建用户界面。在Vue.js中,修饰符(Modifiers)是一种增强指令行为的工具,它们可以改变指令的默认行为。本文将详细讲解Vue.js中的修饰符,并提供实际示例,…...
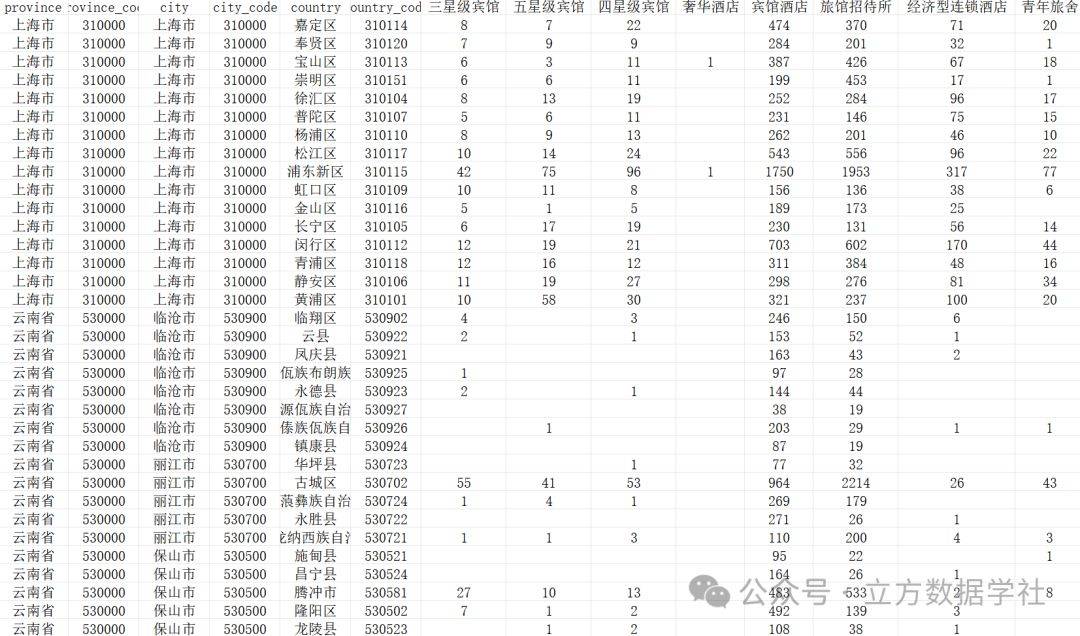
【数据分享】2024年我国省市县三级的住宿服务设施数量(8类住宿设施/Excel/Shp格式)
宾馆酒店、旅馆招待所等住宿服务设施的配置情况是一个城市公共基础设施完善程度的重要体现,一个城市住宿服务设施种类越丰富,数量越多,通常能表示这个城市的公共服务水平越高! 本次我们为大家带来的是我国各省份、各地级市、各区…...

【含文档】基于.NET的医院医保管理系统(含源码+数据库+lw)
1.开发环境 开发系统:Windows10/11 架构模式:MVC/前后端分离 JDK版本: Java JDK1.8 开发工具:IDEA 数据库版本: mysql5.7或8.0 数据库可视化工具: navicat 主要技术:mysql,vue 2.视频演示地址 3.功能 系统定义了两个角色:管理员和用户。 管理员进入主界面&…...

c++源码阅读__smart_ptr__正文阅读
文章目录 简介源码解析1. 引用计数的实现方式2. deleter静态方法的赋值时间节点3.make_smart的实现方式 与 好处4. 几种构造函数4.1 空构造函数4.2 接收指针的构造函数4.3 接收指针和删除方法的构造函数 , 以及auto进行模板lambda的编写4.4 拷贝构造函数4.5 赋值运算符 5. rele…...

图形化界面MySQL(MySQL)(超级详细)
1.官网地址 MySQL :: Download MySQL Workbench 1.1在Linux直接点击NO thanks..... 下载完后是这个页面 1.2任何远端登录,再把jj数据库给授权 1.3建立新用户 进行连接 点击这个就运行了 只执行show tables;要先选中 圆圈处支持自己输入 点击这个就执…...

【2024 Optimal Control 16-745】Julia语法
Lecture 2 θ和它的导数符号是通过 Julia 中的变量命名方式实现的 变量 θ 的输入: 在 Julia 中,θ 是一个合法的变量名,就像普通的字母 x 或 y 一样。要输入 θ,可以使用以下方法: 在 Jupyter Notebook 或 Julia REP…...
Opencv+ROS实现摄像头读取处理画面信息
一、工具 ubuntu18.04 ROSopencv2 编译器:Visual Studio Code 二、原理 图像信息 ROS数据形式:sensor_msgs::Image OpenCV数据形式:cv:Mat 通过cv_bridge()函数进行ROS向opencv转换 cv_bridge是在ROS图像消息和OpenCV图像之间进行转…...

网络安全,文明上网(2)加强网络安全意识
前言 在当今这个数据驱动的时代,对网络安全保持高度警觉已经成为每个人的基本要求。 网络安全意识:信息时代的必备防御 网络已经成为我们生活中不可或缺的一部分,信息技术的快速进步使得我们对网络的依赖性日益增强。然而,网络安全…...

深度学习实战图像缺陷修复
这里写目录标题 概述1. 图像缺陷修复的研究背景2. 传统图像缺陷修复方法的局限性(1) 基于纹理合成的方法(2) 基于偏微分方程(PDE)的方法 3. 深度学习在图像缺陷修复中的兴起(1) 深度学习的基本思路(2) 深度学习方法的优势(3) 关键技术的引入 4. 深度学习…...

jenkins 2.346.1最后一个支持java8的版本搭建
1.jenkins下载 下载地址:Index of /war-stable/2.346.1 2.部署 创建目标文件夹,移动到指定位置 创建一个启动脚本,deploy.sh #!/bin/bash set -eDATE$(date %Y%m%d%H%M) # 基础路径 BASE_PATH/opt/projects/jenkins # 服务名称。同时约定部…...

【数据库原理】创建与维护表,DDL数据定义语言
数据描述语言(数据定义语言) 就是管理数据库整个库,整个表,表的属性列的语句。 常用词儿就是数据库或表的增删改查:CREATE创建、DROP删除、ALTER修改、SHOW查看、USE进入表。 表的字段控制:PRIMARY KEY主键…...

驾驭Go语言中的不确定性:深入错误处理机制
驾驭Go语言中的不确定性:深入错误处理机制 在Go语言的编程世界中,错误处理是确保程序健壮性的关键。Go语言通过显式的错误返回值和panic/recover机制,提供了一套独特的错误处理策略。本文将深入探讨Go语言中的错误处理,包括原理、技术细节和实际案例,帮助读者在实际编程中…...

3D Gaussian Splatting在鱼眼相机中的应用与投影变换
paper:Fisheye-GS 1.概述 3D 高斯泼溅 (3DGS) 因其高保真度和实时渲染而备受关注。然而,由于独特的 3D 到 2D 投影计算,将 3DGS 适配到不同的相机型号(尤其是鱼眼镜头)带来了挑战。此外,基于图块的泼溅效率低下,尤其是对于鱼眼镜头的极端曲率和宽视野,这对于其更广泛…...

【Unity踩坑】在Mac上安装Cocoapods失败
在集成Unity Ad时,如果是第一次在iOS上集成,会在Mac上安装Cocoapods。 安装时提示下面的错误: Error installing cocoapods:The last version of drb (> 0) to support your Ruby & RubyGems was 2.0.5. Try installing it with gem…...
uni-app 认识条件编译,了解多端部署
一. 前言 在使用 uni-app 进行跨平台开发的过程中,经常会遇到需要针对不同平台或不同环境进行条件编译的情况。条件编译是一种在编译过程中根据指定条件选择不同代码路径的技术,可以帮助我们在不同平台或环境下编写不同的代码,以适应不同的平…...

对比直接使用原厂api体验taotoken在稳定性与成本上的差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用原厂 API 与 Taotoken 在稳定性与成本上的体验 作为一名个人开发者,我在日常项目中需要频繁调用大模型 AP…...

【算法分析与设计】第4篇:分治策略的理论框架与经典案例
在计算机科学中,很少有比“分而治之”更自然的解题思路了。面对一个庞杂的问题,先把它切成几个小块,逐个击破,再拼回整体——这种朴素的分割策略,经过严谨的形式化之后,便成了我们所说的分治范式。一个标准…...

开发者在进行多轮对话应用测试时如何利用Taotoken快速切换模型对比
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发者在进行多轮对话应用测试时如何利用Taotoken快速切换模型对比 在开发基于大语言模型的多轮对话应用时,评估不同模…...

OpenSSH ssh-agent CVE-2023-38408 漏洞修复实战指南
1. 这个漏洞不是“修个配置就能好”的那种——它藏在ssh-agent的共享库加载机制里OpenSSH-ssh-agent CVE-2023-38408,光看编号你可能觉得是又一个常规权限提升补丁。但实际动手前我翻了三天源码才意识到:这不是改几行配置、重启服务就能闭环的问题。它直…...

多重插补与MICE:量化ESG评分不确定性的工程实践
1. 项目概述:当ESG评分遇上数据“黑洞”,我们如何量化不确定性?在金融和可持续投资领域,ESG评分正成为评估公司长期价值与风险的关键标尺。然而,从业者们都心知肚明一个公开的秘密:支撑这些评分的底层数据&…...

79万中文医疗对话数据集:构建智能医疗问答系统的核心技术资源
79万中文医疗对话数据集:构建智能医疗问答系统的核心技术资源 【免费下载链接】Chinese-medical-dialogue-data Chinese medical dialogue data 中文医疗对话数据集 项目地址: https://gitcode.com/gh_mirrors/ch/Chinese-medical-dialogue-data 在医疗人工智…...

QKeyMapper:Windows平台开源按键映射解决方案完全指南
QKeyMapper:Windows平台开源按键映射解决方案完全指南 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到键鼠,…...

行人动力学新视角:用速度、密度、避免数与侵入数量化交叉人流行为
1. 项目概述:当行人流交汇时,我们如何“看懂”人群?想象一下早高峰的地铁换乘通道,或是大型演唱会散场时的十字路口。两股、甚至多股人流以不同的角度交汇、穿插、最终分离。作为城市管理者或空间设计师,你可能会问&am…...
)
保姆级教程:用AKShare+Backtrader+quantstats搭建你的第一个本地量化回测环境(避坑指南)
从零搭建本地量化回测系统:AKShare数据抓取Backtrader策略开发quantstats绩效分析实战指南第一次尝试量化投资的开发者常会遇到这样的困境:在线回测平台担心策略泄露,本地搭建环境又卡在依赖安装、数据格式转换等基础环节。本文将用最简化的方…...

League Akari:英雄联盟玩家的终极智能助手工具包
League Akari:英雄联盟玩家的终极智能助手工具包 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联盟游戏中的繁琐操作而…...