人工智能-深度学习-Torch框架-手动构建回归流程
from sklearn.datasets import make_regression
import math
import random
import torch-
from sklearn.datasets import make_regression: 导入make_regression函数,用于生成回归数据集。 -
import math: 导入math模块,用于进行数学计算,例如向上取整。 -
import random: 导入random模块,用于随机打乱数据集。 -
import torch: 导入torch库,用于张量操作和神经网络训练。
构建数据集
def build_data():'''构建数据集'''noise = 14.6#噪声n_sample = 1000#样本数量X,y,coef = make_regression(n_samples=n_sample,n_features=4,coef=True)X = torch.tensor(X,dtype=torch.float64,requires_grad=True)y = torch.tensor(y,dtype=torch.float64,requires_grad=True)return X,y,coef-
def build_data():: 定义一个名为build_data的函数,用于构建数据集。 -
noise = 14.6: 设置噪声水平为14.6,用于生成带有噪声的数据。 -
n_sample = 1000: 设置样本数量为1000,用于生成1000个样本。 -
X, y, coef = make_regression(n_samples=n_sample, n_features=4, coef=True): 使用make_regression生成回归数据集,包含1000个样本和4个特征,并返回真实系数。 -
X = torch.tensor(X, dtype=torch.float64, requires_grad=True): 将生成的特征矩阵X转换为PyTorch张量,数据类型为torch.float64,并设置requires_grad=True以启用梯度计算。 -
y = torch.tensor(y, dtype=torch.float64, requires_grad=True): 将生成的目标向量y转换为PyTorch张量,数据类型为torch.float64,并设置requires_grad=True以启用梯度计算。 -
return X, y, coef: 返回特征矩阵X、目标向量y和真实系数coef。
构建数据加载器
def data_loader(x,y):'''数据加载器'''#配置参数batch_size = 16#一个批次的数量n_sample = x.shape[0]#len(x)长度n_batches = math.ceil(n_sample/batch_size)#一轮的训练次数index = [i for i in range(n_sample)]random.shuffle(index)for i in range(0,n_batches):indexs = index[i*batch_size:min((i+1)*batch_size,n_sample)]yield x[indexs],y[indexs]-
def data_loader(x, y):: 定义一个名为data_loader的函数,用于加载数据。 -
batch_size = 16: 设置每个批次的样本数量为16,用于控制每次训练的样本数量。 -
n_sample = x.shape[0]: 获取样本数量,用于计算批次数量。 -
n_batches = math.ceil(n_sample / batch_size): 计算每轮的批次数量,使用math.ceil向上取整,确保所有样本都能被处理。 -
index = [i for i in range(n_sample)]: 创建一个包含所有样本索引的列表,用于随机打乱样本顺序。 -
random.shuffle(index): 打乱样本索引,以随机化样本顺序,避免训练过程中的顺序偏差。 -
for i in range(0, n_batches):: 遍历每个批次,确保每个批次都能被处理。 -
indexs = index[i * batch_size:min((i + 1) * batch_size, n_sample)]: 获取当前批次的索引,确保最后一个批次也能被处理。 -
yield x[indexs], y[indexs]: 返回当前批次的特征矩阵和目标向量,使用yield生成一个生成器,用于按需加载数据。
构建模型函数
def myregreser(x,w,b):return x@w+b#一个容器中装着的是每一条样本数据的预测值x@w+b 跟 y = x*w+b差不多,无需多言哈
-
def myregreser(x, w, b):: 定义一个名为myregreser的函数,用于计算线性回归模型的预测值。 -
return x @ w + b: 返回预测值,使用矩阵乘法@计算x和w的乘积,然后加上偏置b,实现线性回归模型.
![]()
构建损失函数
def MSE(y_pred,y_true):return torch.mean((y_pred-y_true)**2)
-
def MSE(y_pred, y_true):: 定义一个名为MSE的函数,用于计算均方误差(MSE)损失。 -
return torch.mean((y_pred - y_true) ** 2): 返回预测值和真实值之间的均方误差,用于衡量模型的预测精度。
把参数初始化
def initialize(n_featrue):torch.manual_seed(666)w = torch.randn(n_featrue,requires_grad=True,dtype=torch.float64)# print(w)b = torch.tensor(14.5,requires_grad=True,dtype=torch.float64)return w,b-
def initialize(n_feature):: 定义一个名为initialize的函数,用于初始化模型参数。 -
torch.manual_seed(666): 设置随机种子为666,以确保结果可重复,避免随机性带来的不确定性。 -
w = torch.randn(n_feature): 使用随机值初始化权重w,确保模型初始状态具有一定的随机性。 -
b = torch.tensor(14.5, requires_grad=True, dtype=torch.float64): 初始化偏置b,并设置requires_grad=True以启用梯度计算,确保偏置可以被优化。 -
return w, b: 返回初始化的权重和偏置。
构建梯度下降函数
def optim_step(w,b,dw,db,lr):
#更新梯度,朝着梯度下降的方向去更新梯度w.data = w.data-lr*dw.datab.data = b,data-lr*db.data-
def optim_step(w, b, dw, db, lr):: 定义一个名为optim_step的函数,用于更新模型参数。 -
w.data = w.data - lr * dw.data: 更新权重w,沿着梯度下降的方向,使用学习率lr控制更新的步长。 -
b.data = b.data - lr * db.data: 更新偏置b,沿着梯度下降的方向,使用学习率lr控制更新的步长。
使用上面构建的函数进行实战训练
def train():#生成数据x,y,coef = build_data()#初始化参数w,b = initialize(x.shape[1])#定义训练参数lr = 0.01epoch = 100for i in range(epoch):loss_e = 0count = 0for batch_x,batch_y_true in data_loader(x,y):y_bacth_pred = myregreser(batch_x,w,b)loss = MSE(y_bacth_pred,batch_y_true)loss_e+=losscount+=1#梯度清零if w.grad is not None:w.data.zero_()if b.grad is not None:b.data.zero_()#反向传播(梯度计算)loss.backward()#梯度更行optim_step(w,b,w.grad,b.grad,lr)print(f'epoch:{i},loss:{loss_e/count}')return w,b,coef
if __name__=='__main__':w,b,coef = train()print(w,b)print(coef)print(torch.allclose(w,torch.tensor(coef)))-
def train():: 定义一个名为train的函数,用于训练模型。 -
x, y, coef = build_data(): 生成数据集,获取特征矩阵x、目标向量y和真实系数coef。 -
w, b = initialize(x.shape[1]): 初始化模型参数,获取初始化的权重w和偏置b。 -
lr = 0.01: 设置学习率为0.01,控制参数更新的步长。 -
epoch = 100: 设置训练轮数为100,控制训练的迭代次数。 -
for i in range(epoch):: 外层循环,遍历每个训练轮,确保模型在多个轮次中进行训练。 -
loss_e = 0: 初始化每轮的总损失为0,用于累加每个批次的损失。 -
count = 0: 初始化批次计数为0,用于计算每轮的平均损失。 -
for batch_x, batch_y_true in data_loader(x, y):: 内层循环,遍历每个批次的数据,确保每个批次都能被处理。 -
y_batch_pred = myregreser(batch_x, w, b): 计算预测值,使用当前的权重和偏置进行预测。 -
loss = MSE(y_batch_pred, batch_y_true): 计算损失,使用均方误差衡量预测值和真实值之间的差异。 -
loss_e += loss: 累加损失,用于计算每轮的总损失。 -
count += 1: 计数批次数量,用于计算每轮的平均损失。 -
if w.grad is not None:: 检查权重w的梯度是否存在,确保梯度已经计算。 -
w.grad.zero_(): 清零权重w的梯度,避免梯度累积。 -
if b.grad is not None:: 检查偏置b的梯度是否存在,确保梯度已经计算。 -
b.grad.zero_(): 清零偏置b的梯度,避免梯度累积。 -
loss.backward(): 反向传播,计算梯度,用于更新模型参数。 -
optim_step(w, b, w.grad, b.grad, lr): 更新参数,沿着梯度下降的方向更新权重和偏置。 -
print(f'epoch:{i}, loss:{loss_e / count}'): 打印每轮的平均损失,用于监控训练过程。 -
return w, b, coef: 返回训练后的权重、偏置和真实系数,用于评估模型性能。
相关文章:

人工智能-深度学习-Torch框架-手动构建回归流程
from sklearn.datasets import make_regression import math import random import torch from sklearn.datasets import make_regression: 导入make_regression函数,用于生成回归数据集。 import math: 导入math模块,用于进行数学计算,例如…...
SpringBoot源码解析(五):准备应用环境
SpringBoot源码系列文章 SpringBoot源码解析(一):SpringApplication构造方法 SpringBoot源码解析(二):引导上下文DefaultBootstrapContext SpringBoot源码解析(三):启动开始阶段 SpringBoot源码解析(四):解析应用参数args Sp…...

MySQL面试-1
InnoDB中ACID的实现 先说一下原子性是怎么实现的。 事务要么失败,要么成功,不能做一半。聪明的InnoDB,在干活儿之前,先将要做的事情记录到一个叫undo log的日志文件中,如果失败了或者主动rollback,就可以通…...

nginx配置不缓存资源
方法1 location / {index index.html index.htm;add_header Cache-Control no-cache,no-store;try_files $uri $uri/ /index.html;#include mime.types;if ($request_filename ~* .*\.(htm|html)$) {add_header Cache-Control "private, no-store, no-cache, must-revali…...

PHP导出EXCEL含合计行,设置单元格格式
PHP导出EXCEL含合计行,设置单元格格式,水平居中 垂直居中 public function exportSalary(Request $request){//水平居中 垂直居中$styleArray [alignment > [horizontal > Alignment::HORIZONTAL_CENTER,vertical > Alignment::VERTICAL_CE…...

RabbitMQ 之 死信队列
一、死信的概念 先从概念解释上搞清楚这个定义,死信,顾名思义就是无法被消费的消息,字面意思可以这样理 解,一般来说,producer 将消息投递到 broker 或者直接到 queue 里了,consumer 从 queue 取出消息进行…...

【创建型设计模式】单例模式
【创建型设计模式】单例模式 这篇博客接下来几篇都将阐述设计模式相关内容。 接下来的顺序大概是:单例模式、工厂方法模式、抽象工厂模式、建造者模式、原型模式。 一、什么是单例模式 单例模式是一种创建型设计模式,它保证一个类仅有一个实例&#…...
Charles抓包工具-笔记
摘要 概念: Charles是一款基于 HTTP 协议的代理服务器,通过成为电脑或者浏览器的代理,然后截取请求和请求结果来达到分析抓包的目的。 功能: Charles 是一个功能全面的抓包工具,适用于各种网络调试和优化场景。 它…...

Go语言使用 kafka-go 消费 Kafka 消息教程
Go语言使用 kafka-go 消费 Kafka 消息教程 在这篇教程中,我们将介绍如何使用 kafka-go 库来消费 Kafka 消息,并重点讲解 FetchMessage 和 ReadMessage 的区别,以及它们各自适用的场景。通过这篇教程,你将了解如何有效地使用 kafk…...

【论文笔记】Number it: Temporal Grounding Videos like Flipping Manga
🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。 基本信息 标题: Number it: Temporal Grou…...

C语言菜鸟入门·关键字·int的用法
目录 1. int关键字 1.1 取值范围 1.2 符号类型 1.3 运算 1.3.1 加法运算() 1.3.2 减法运算(-) 1.3.3 乘法运算(*) 1.3.4 除法运算(/) 1.3.5 取余运算(%) 1.3.6 自增()与自减(--) 1.3.7 位运算 2. 更多关键字 1. int关键字 int 是一个关键字࿰…...

基于企业微信客户端设计一个文件下载与预览系统
在企业内部沟通与协作中,文件分享和管理是不可或缺的一部分。企业微信(WeCom)作为一款广泛应用于企业的沟通工具,提供了丰富的API接口和功能,帮助企业进行高效的团队协作。然而,随着文件交换和协作的日益增…...
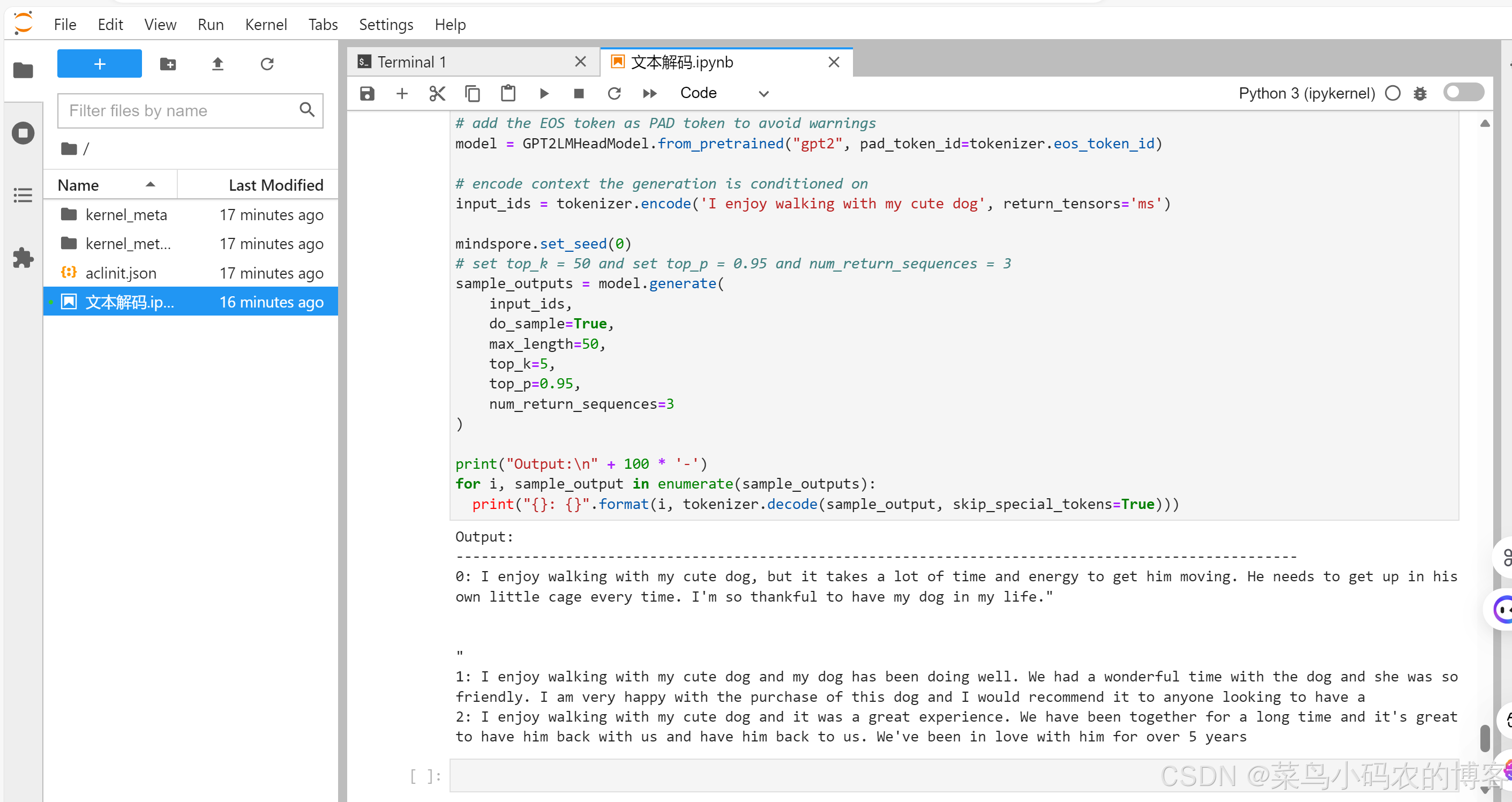
昇思MindSpore第七课---文本解码原理
1. 文本解码原理 文本解码是将模型的输出(通常是概率分布或词汇索引)转换为可读的自然语言文本的过程。在生成文本时,常见的解码方法包括贪心解码、束搜索(BeamSearch)、随机采样等。 2 实践 2.1 配置环境 安装mindn…...

C# 数据结构之【图】C#图
1. 图的概念 图是一种重要的数据结构,用于表示节点(顶点)之间的关系。图由一组顶点和连接这些顶点的边组成。图可以是有向的(边有方向)或无向的(边没有方向),可以是加权的ÿ…...

传输控制协议(TCP)和用户数据报协议(UDP)
一、传输控制协议(TCP) 传输控制协议(Transmission Control Protocol,TCP)是一种面向连接的、可靠的、基于字节流的传输层通信协议,由 IETF 的 RFC 793 定义。 它通过三次握手建立连接,确保数…...

【Python爬虫】Scrapy框架实战---百度首页热榜新闻
如何利用Scrapy框架实战提取百度首页热榜新闻的排名、标题和链接 一、安装Scrapy库 二、创建项目(以BaiduSpider为例) scrapy startproject BaiduSpider生成每个文件的功能: 二、 创建爬虫脚本(爬虫名:newsÿ…...

采用python3.12 +django5.1 结合 RabbitMQ 和发送邮件功能,实现一个简单的告警系统 前后端分离 vue-element
一、开发环境搭建和配置 #mac环境 brew install python3.12 python3.12 --version python3.12 -m pip install --upgrade pip python3.12 -m pip install Django5.1 python3.12 -m django --version #用于检索系统信息和进程管理 python3.12 -m pip install psutil #集成 pika…...

Qt 实现网络数据报文大小端数据的收发
1.大小端数据简介 大小端(Endianness)是计算机体系结构的一个术语,它描述了多字节数据在内存中的存储顺序。以下是大小端的定义和它们的特点: 大端(Big-Endian) 在大端模式中,一个字的最高有效…...

[译]Elasticsearch Sequence ID实现思路及用途
原文地址:https://www.elastic.co/blog/elasticsearch-sequence-ids-6-0 如果 几年前,在Elastic,我们问自己一个"如果"问题,我们知道这将带来有趣的见解: "如果我们在Elasticsearch中对索引操作进行全面排序会怎样…...

Java基于SpringBoot+Vue的藏区特产销售平台
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...

别再只会用Burpsuite爆破DVWA了!手把手教你用Python脚本+自定义字典搞定暴力破解
从零构建Python暴力破解工具:DVWA实战进阶指南 在渗透测试领域,暴力破解(Brute Force)始终是基础却有效的攻击手段。虽然Burpsuite这类工具提供了便捷的图形化操作界面,但真正理解其底层原理并能够自主开发定制化破解工具,才是安全…...

Sora全面下线,AI界背后的商业逻辑是什么?
你敢相信吗?那个曾以一己之力震撼全球影视圈、让无数视频创作者彻夜难眠、被视为AI视频生成之王的Sora,被它的亲生父母OpenAI,亲手按下了停止键。一觉醒来,没有降级,没有合并,Sora独立App的API接口直接下线…...

安全治理加速金融AI收入增长
金融机构正在学习如何部署合规的AI解决方案,以实现更大的收入增长和市场优势。在过去十年的大部分时间里,金融机构主要将AI视为提高纯粹效率的机制。在那个时代,量化团队编写系统来发现账本差异或减少自动交易执行时间中的毫秒。只要季度资产…...

终极指南:深度解锁联想拯救者Y7000系列Insyde BIOS隐藏选项
终极指南:深度解锁联想拯救者Y7000系列Insyde BIOS隐藏选项 【免费下载链接】LEGION_Y7000Series_Insyde_Advanced_Settings_Tools 支持一键修改 Insyde BIOS 隐藏选项的小工具,例如关闭CFG LOCK、修改DVMT等等 项目地址: https://gitcode.com/gh_mirr…...
)
从零搭建一个游戏设置面板:用Horizontal Layout Group搞定选项排布(Unity 2022 LTS)
从零搭建游戏设置面板:Horizontal Layout Group实战指南 在Unity游戏开发中,一个直观易用的设置面板是提升玩家体验的关键组件。本文将带你从零开始,使用Horizontal Layout Group组件构建一个专业的游戏设置界面,涵盖音量控制、画…...

VideoAgentTrek-ScreenFilter视觉盛宴:处理4K超高清屏幕录像的效果与性能挑战
VideoAgentTrek-ScreenFilter视觉盛宴:处理4K超高清屏幕录像的效果与性能挑战 最近在折腾一些屏幕录像的后期处理,特别是那些4K分辨率、高帧率的超高清素材。说实话,直接处理这种级别的视频,对硬件和软件都是不小的考验。我试用了…...
)
保姆级教程:在STM32F103上从零移植FreeModbus V1.6(RTU模式)
保姆级教程:在STM32F103上从零移植FreeModbus V1.6(RTU模式) Modbus协议作为工业自动化领域的"普通话",其开源实现FreeModbus凭借轻量级和可移植性成为嵌入式开发者的首选。本文将手把手带你在STM32F103C8T6开发板上完成…...

5步快速上手:百度网盘直链解析工具实现高速下载
5步快速上手:百度网盘直链解析工具实现高速下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘的下载速度限制而烦恼吗?百度网盘直链解…...

舰艇推进电机供电流程优化方案
舰艇推进电机供电流程优化方案 第一章 绪论 1.1 背景与意义 现代舰艇(如驱逐舰、潜艇、全电推进船舶)广泛采用综合电力系统。传统的供电流程中,推进电机作为最大的非线性负载,其负载突变(如急加速、倒车、波浪冲击导致的螺旋桨甩尾)会通过直流母线回馈至发电机组,导致…...

Zotero中文文献管理终极指南:茉莉花插件一键解决三大痛点
Zotero中文文献管理终极指南:茉莉花插件一键解决三大痛点 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 如果你正在使…...