【大数据学习 | Spark-SQL】Spark-SQL编程

上面的是SparkSQL的API操作。
1. 将RDD转化为DataFrame对象
DataFrame:
DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这样的数据集可以用SQL查询。

创建方式
准备数据
1 zhangsan 20 male
2 lisi 30 female
3 wangwu 35 male
4 zhaosi 40 femaletoDF方式。
package com.hainiu.sparkimport org.apache.spark.sql.SQLContext
import org.apache.spark.{SparkConf, SparkContext}object TestSparkSql{def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setAppName("test sql")conf.setMaster("local[*]")val sc = new SparkContext(conf)val sqlSc = new SQLContext(sc)//环境对象包装import sqlSc.implicits._//引入环境信息val rdd = sc.textFile("data/a.txt").map(t => {val strs = t.split(" ")(strs(0).toInt, strs(1), strs(2).toInt)})//增加字段信息val df = rdd.toDF("id", "name", "age")df.show() //展示表数据df.printSchema() //展示表格字段信息}
}使用样例类定义schema:
object TestSparkSql{def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setAppName("test sql")conf.setMaster("local[*]")val sc = new SparkContext(conf)val sqlSc = new SQLContext(sc)import sqlSc.implicits._val rdd = sc.textFile("data/a.txt").map(t => {val strs = t.split(" ")Student(strs(0).toInt, strs(1), strs(2).toInt)})// val df = rdd.toDF("id", "name", "age")val df = rdd.toDF()df.show() //打印数据,以表格的形式打印数据df.printSchema() //打印表的结构信息}
}
case class Student(id:Int,name:String,age:Int)createDataFrame方式
这种方式需要将rdd和schema信息进行合并,得出一个新的DataFrame对象
package com.hainiu.sparkimport org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}object TestSparkSqlWithCreate {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setAppName("test create")conf.setMaster("local[*]")val sc = new SparkContext(conf)val sqlSc = new SQLContext(sc)val rdd = sc.textFile("data/a.txt").map(t => {val strs = t.split(" ")Row(strs(0).toInt, strs(1), strs(2).toInt)})
// rdd + schemaval schema = StructType(Array(StructField("id",IntegerType),StructField("name",StringType),StructField("age",IntegerType)))val df = sqlSc.createDataFrame(rdd, schema)df.show()df.printSchema()}
}2. SparkSQL的查询方式(推荐第二种写法)

第二个部分关于df的查询
第一种sql api的方式查询
- 使用的方式方法的形式编程
- 但是思想还是sql形式
- 和rdd编程特别相似的一种写法
object TestSql {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setAppName("test sql")conf.setMaster("local[*]")val sc = new SparkContext(conf)val sqlSc = new SQLContext(sc)import sqlSc.implicits._val rdd = sc.textFile("data/a.txt").map(t => {val strs = t.split(" ")(strs(0).toInt, strs(1), strs(2).toInt,strs(3))})val df = rdd.toDF("id", "name", "age","gender")//select * from student where age >20//df.where("age >20")//分组聚合//df.groupby("gender").sum("age")//几个问题//聚合函数不能增加别名 聚合函数不能多次聚合 orderby不识别desc // df.groupBy("gender").agg(count("id").as("id"),sum("age").as("age")).orderBy($"age".desc) //字段标识可以是字符串,也可以是字段对象//df.orderBy($"age".desc) //df.orderBy(col("age").desc) //df.orderBy(df("age").desc) //增加字段对象可以实现高端操作//df.select($"age".+(1)) //join问题//val df1 = sc.makeRDD(Array(// (1,100,98),// (2,100,95),// (3,90,92),//(4,90,93)//)).toDF("id","chinese","math")//df.join(df1,"id") //字段相同 //df.join(df1,df("id")===df1("id")) //窗口函数//普通函数 聚合函数 窗口函数 sum|count|rowkey over (partition by gender order by age desc)//按照条件分割完毕进行数据截取//班级的前两名 每个性别年龄最高的前两个//select *,row_number() over (partition by gender order by age desc) rn from tableimport sqlSc.implicits._import org.apache.spark.sql.functions._df.withColumn("rn",row_number().over(Window.partitionBy("gender").orderBy($"age".desc))).where("rn = 1").show()}
}第二种纯sql形式的查询
- 首先注册表
- 然后使用sql查询
- 最终得出的还是dataFrame的对象
- 其中和rdd的编程没有任何的区别,只不过现在使用sql形式进行处理了而已
package com.hainiu.sparkimport org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}object TestSparkSqlWithCreate {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setAppName("test create")conf.setMaster("local[*]")val sc = new SparkContext(conf)val sqlSc = new SQLContext(sc)val rdd = sc.textFile("data/a.txt").map(t => {val strs = t.split(" ")Row(strs(0).toInt, strs(1), strs(2).toInt,strs(3))})
// rdd + schemaval schema = StructType(Array(StructField("id",IntegerType),StructField("name",StringType),StructField("age",IntegerType),StructField("gender",StringType),))val df = sqlSc.createDataFrame(rdd, schema)//sql形式查询//select col from tabledf.createTempView("student")val df1 = sqlSc.sql("""|select count(1) cnt,gender from student group by gender|""".stripMargin)df1.createTempView("student1")val df2 = sqlSc.sql("""|select * from student1 where cnt>1|""".stripMargin)df2.show()df2.printSchema()}
}相关文章:
【大数据学习 | Spark-SQL】Spark-SQL编程
上面的是SparkSQL的API操作。 1. 将RDD转化为DataFrame对象 DataFrame: DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这样的数…...
15分钟做完一个小程序,腾讯这个工具有点东西
我记得很久之前,我们都在讲什么低代码/无代码平台,这个概念很久了,但是,一直没有很好的落地,整体的效果也不算好。 自从去年 ChatGPT 这类大模型大火以来,各大科技公司也都推出了很多 AI 代码助手ÿ…...
manim动画编程(安装+入门)
文章目录 1.基本介绍2.效果展示3.安装步骤3.1安装manba软件3.2配置环境变量3.3查看是否成功3.4什么是mamba3.5创建虚拟环境3.6尝试进入虚拟环境 4.vscode操作4.1默认配置文件 5.安装ffmpeg6.安装manim软件6.vscode制作7.我的学习收获 1.基本介绍 这个manim就是一款软件&#x…...

STL算法之数值算法<stl_numeric.h>
这一节介绍的算法,统称为数值(numeric)算法。STL规定,欲使用它们,客户端必须包含头文件<numeric>.SGI将它们实现与<stl_numeric.h>文件中。 目录 运用实例 accumulate adjacent_difference inner_product partial_sum pow…...

Oracle如何记录登录用户IP
在运维场景中,在定位到某个SQL引起系统故障之后,想知道是哪台机器发过来的,方便定位源头,该如何解决? 在 Oracle 数据库中记录登录用户的 IP 地址可以通过多种方法实现。以下是几种常见的方法,包括使用触发…...

Python图像处理:打造平滑液化效果动画
液化动画中的强度变化是通过在每一帧中逐渐调整液化效果的强度参数来实现的。在提供的代码示例中,强度变化是通过一个简单的线性插值方法来控制的,即随着动画帧数的增加,液化效果的强度也逐渐增加。 def liquify_image(image, center, radius…...

构建Ceph分布式文件共享系统:手动部署指南
#作者:西门吹雪 文章目录 micro-Services-TutorialCeph分布式文件共享方案部署Ceph集群使用CephCeph在kubernetes集群中的使用 micro-Services-Tutorial 微服务最早由Martin Fowler与James Lewis于2014年共同提出,微服务架构风格是一种使用一套小服务来开发单个应…...

数据结构——用数组实现栈和队列
目录 用数组实现栈和队列 一、数组实现栈 1.stack类 2.测试 二、数组实现队列 1.Queue类 2.测试 查询——数组:数组在内存中是连续空间 增删改——链表:链表的增删改处理更方便一些 满足数据先进后出的特点的就是栈,先进先出就是队列…...
vue3typescript,shims-vue.d.ts中declare module的vue声明
webpack已经有了vue-loader这些loader了,为什么还需要declare module *.vue’呢? declare module 是为了告诉 tsc 这是一个“模块”。 如果不声明, IDE 里因为 tsc 类型检查, lint 会标红。 但vue-loader 是在 Webpack 构建阶段使…...
)
C/C++基础知识复习(30)
1) 什么是 C 中的 Lambda 表达式?它的作用是什么? Lambda 表达式: 在 C 中,Lambda 表达式是一种可以定义匿名函数的机制,可以在代码中快速创建一个内联的函数对象,而不需要显式地定义一个函数。Lambda 表…...

【NLP 1、人工智能与NLP简介】
人人都不看好你,可偏偏你最争气 —— 24.11.26 一、AI和NLP的基本介绍 1.人工智能发展流程 弱人工智能 ——> 强人工智能 ——> 超人工智能 ① 弱人工智能 人工智能算法只能在限定领域解决特定的问题 eg:特定场景下的文本分类、垂直领域下的对…...
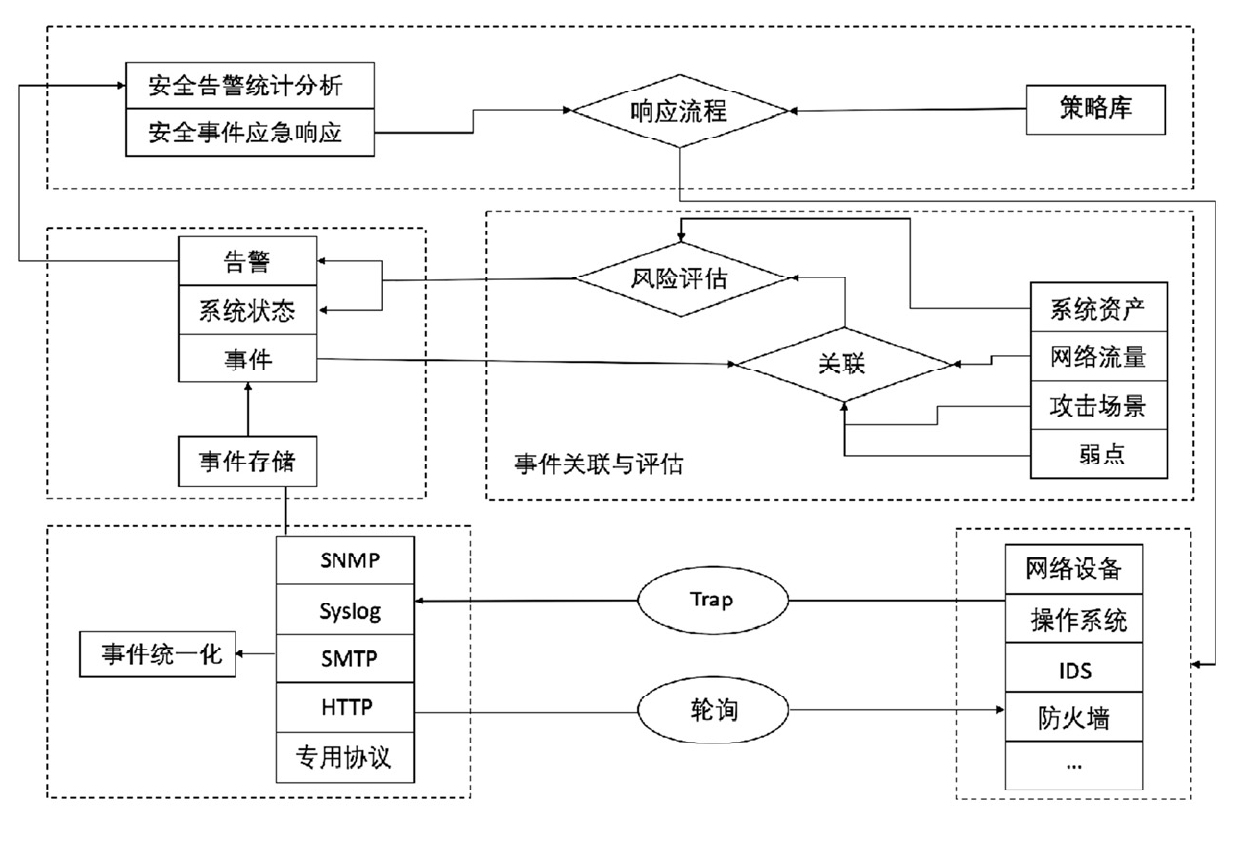
网络安全事件管理
一、背景 信息化技术的迅速发展已经极大地改变了人们的生活,网络安全威胁也日益多元化和复杂化。传统的网络安全防护手段难以应对当前繁杂的网络安全问题,构建主动防御的安全整体解决方案将更有利于防范未知的网络安全威胁。 国内外的安全事件在不断增…...

Swagger记录一次生成失败
最近在接入Swagger的时候遇到一个问题,就是Swagger UI可以使用的,但是/v3/docs 这个接口的json返回的base64类型的json,并不是纯json,后来检查之后是因为springboot3里面配置了json压缩。 Beanpublic HttpMessageConverters cusHt…...

Go 语言常用工具方法总结
在 Go 语言开发中,常常需要进行一些常见的类型转换、字符串处理、时间处理等操作。本文将总结一些常用的工具方法,帮助大家提高编码效率,并提供必要的代码解释和注意事项(go新人浅浅记录一下,以后来翻看🤣&…...

ThingsBoard规则链节点:GCP Pub/Sub 节点详解
目录 引言 1. GCP Pub/Sub 节点简介 2. 节点配置 2.1 基本配置示例 3. 使用场景 3.1 数据传输 3.2 数据分析 3.3 事件通知 3.4 任务调度 4. 实际项目中的应用 4.1 项目背景 4.2 项目需求 4.3 实现步骤 5. 总结 引言 ThingsBoard 是一个开源的物联网平台࿰…...

【Linux】select,poll和epoll
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符fd,一旦某个描述符就绪(一般是读就绪或者写就绪),系统会通知有I/O事件发生了(不能定位是哪一个)。但sel…...

Qt程序发布及打包成exe安装包
参考:Qt之程序发布以及打包成exe安装包 目录 一、简述 Qt 项目开发完成之后,需要打包发布程序,而因为用户电脑上没有 Qt 配置环境,所以需要将 release 生成的 exe 文件和所依赖的 dll 文件复制到一个文件夹中,然后再用 Inno Setup 打包工具打包成一个 exe 安装包,就可以…...

python怎样运行js语句
1. 安装 pip install PyExecJS # 需要注意, 包的名称:PyExecJS 2. 简单使用 import execjs execjs.eval("new Date") 返回值为: 2018-04-04T12:53:17.759Z execjs.eval("Date.now()") 返回值为:152284700108…...

汽车渲染领域:Blender 和 UE5 哪款更适用?两者区别?
在汽车渲染领域,选择合适的工具对于实现高质量的视觉效果至关重要。Blender和UE5(Unreal Engine 5)作为两大主流3D软件,各自在渲染动画方面有着显著的差异。本文将从核心定位与用途、工作流程、渲染技术和灵活性、后期处理与合成四…...

JAVA实现将PDF转换成word文档
POM.xml <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.…...

硬件工程师必读:九大核心算法如何重塑芯片与系统设计
1. 项目概述:一次关于算法之美的深度阅读作为一名在电子工程和数字设计领域摸爬滚打了十几年的工程师,我的日常工作就是和FPGA、ASIC、各种EDA工具以及层出不穷的硬件描述语言打交道。我们这行,天天谈的是时序收敛、功耗优化、面积利用&#…...

reverse-geocoder未来展望:AI增强地理编码与智能位置预测
reverse-geocoder未来展望:AI增强地理编码与智能位置预测 【免费下载链接】reverse-geocoder A fast, offline reverse geocoder in Python 项目地址: https://gitcode.com/gh_mirrors/re/reverse-geocoder 在当今数据驱动的世界中,地理编码技术已…...

基于Node.js的Gemini CLI蓝图:构建高效AI命令行工具
1. 项目概述:一个让Gemini API在命令行中“活”起来的蓝图 如果你和我一样,日常工作中大量时间都泡在终端里,那么你肯定理解那种感觉:为了调用一个AI模型,不得不频繁地在浏览器、API文档和命令行之间来回切换ÿ…...

告别网络盲区:用RTL8811CU让旧笔记本变身Linux双频WiFi网卡/AP二合一网关
旧硬件新生:用RTL8811CU打造Linux双频无线网关实战指南 每次升级笔记本后,那些陪伴我们多年的旧设备往往被束之高阁。作为一名网络技术爱好者,我发现这些"退役"笔记本其实蕴藏着巨大的再利用价值——特别是当它们遇到RTL8811CU这样…...

商业航天崛起:从SpaceX看工程创新与政策博弈的融合
1. 商业航天崛起的时代背景与技术逻辑2012年5月,当SpaceX的“龙”飞船与国际空间站成功对接时,我正和几位航天领域的同行在会议室里盯着直播画面。那一刻的安静与随后爆发的掌声,不仅仅是为一次技术成功,更是为一个新时代的开启感…...

AI编程助手实战指南:从GitHub Copilot到全流程开发效率提升
1. 项目概述:当AI遇见编码的“氛围感”最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫Sunil6512/awesome-ai-vibe-coding。光看名字,awesome-ai-vibe-coding,就透着一股子新潮味儿。它不是一个具体的工具或者框架&am…...

告别龟速下载!用阿里云Maven仓库和离线驱动包,5分钟搞定DBeaver所有JDBC驱动配置
极速配置DBeaver JDBC驱动的双轨方案:阿里云Maven加速与离线整合包实战 每次打开DBeaver准备连接数据库时,看着进度条缓慢爬升的驱动下载界面,你是否也感到焦虑?特别是在紧急排查生产环境问题的关键时刻,这种等待简直让…...

Perplexity Stack Overflow查询响应延迟超8秒?紧急修复指南:从token压缩到领域微调的4层加速方案
更多请点击: https://intelliparadigm.com 第一章:Perplexity Stack Overflow查询响应延迟超8秒?紧急修复指南:从token压缩到领域微调的4层加速方案 当Perplexity在Stack Overflow数据源上出现平均响应延迟 > 8s 的告警时&am…...

告别运行库安装烦恼:Visual C++ AIO合集一键搞定所有版本
告别运行库安装烦恼:Visual C AIO合集一键搞定所有版本 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经为了运行某个软件而四处寻找不同版…...

优化ESP32 ADF 音频问题
可以,现在已经进入音质调试阶段了,不是“能不能播放”的阶段。 你现在的问题大概率不是一个单点问题,而是下面几类之一: 1. 音量 / 增益太大,导致 ES8388 或 MD8002A 功放削顶失真 2. I2S 时钟不准,导致声音…...