数据库操作、锁特性
1. DML、DDL和DQL是数据库操作语言的三种主要类型
1.1 DML(Data Manipulation Language)数据操纵语言
-
DML是用于检索、插入、更新和删除数据库中数据的SQL语句。
-
主要的DML语句包括:
-
SELECT:用于查询数据库中的数据。 -
INSERT:用于向数据库表中插入新数据。 -
UPDATE:用于修改数据库表中的现有数据。 -
DELETE:用于从数据库表中删除数据。
-
-
DML语句通常不涉及数据库结构的修改。
1.1.1 SELECT
-
用于查询数据库中的数据,可以结合WHERE子句、GROUP BY子句、HAVING子句和ORDER BY子句等进行复杂的查询。
SELECT column1, column2 FROM table_name WHERE condition;1.1.2 INSERT
-
用于向数据库表中插入新的数据行。
INSERT INTO table_name (column1, column2) VALUES (value1, value2);-
如果不指定列名,将插入所有列的默认值:
INSERT INTO table_name VALUES (value1, value2);1.1.3 UPDATE
-
用于修改数据库表中的现有数据。
UPDATE table_name SET column1 = value1, column2 = value2 WHERE condition;1.1.4 DELETE
-
用于从数据库表中删除数据。
DELETE FROM table_name WHERE condition;-
注意:如果没有WHERE子句,将删除表中的所有行。
1.2 DDL(Data Definition Language)数据定义语言
-
DDL用于定义和管理数据库的结构,如创建、修改和删除数据库对象(如表、索引、视图、触发器等)。
-
主要的DDL语句包括:
-
CREATE:用于创建新的数据库对象,如表、索引或视图。 -
ALTER:用于修改现有数据库对象的结构。 -
DROP:用于删除数据库对象。 -
TRUNCATE:用于快速删除表中的所有行。
-
-
DDL语句通常会影响数据库的元数据,并且需要数据库管理员权限。
1.2.1 CREATE:创建新的数据库对象。
-
创建数据库:
CREATE DATABASE test;-
创建表:
CREATE TABLE employees ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(100) NOT NULL, position VARCHAR(100), hire_date DATE );-
创建索引:
CREATE INDEX idx_lastname ON employees (name);-
创建视图:
CREATE VIEW employee_positions AS SELECT name, position FROM employees;-
创建触发器:在指定的数据库表上特定事件(如INSERT、UPDATE或DELETE)发生时自动执行。
CREATE TRIGGER before_insert_employee BEFORE INSERT ON employees FOR EACH ROW BEGIN SET NEW.name = CONCAT('Mr/Ms ', NEW.name); END;注:创建一个名为before_insert_employee的触发器,在employees表中执行插入操作之前,在名字之前加上'Mr/Ms'。
1.2.2 ALTER:修改现有数据库对象的结构。
-
修改表结构,添加新列:
ALTER TABLE employees ADD COLUMN salary DECIMAL(10, 2);-
修改列的数据类型:
ALTER TABLE employees MODIFY COLUMN name VARCHAR(150);-
重命名表:
ALTER TABLE employees RENAME TO staff;1.2.3 DROP:删除数据库对象。
-
删除表:
DROP TABLE IF EXISTS staff;-
删除数据库:
DROP DATABASE IF EXISTS mydatabase;-
删除视图:
DROP VIEW IF EXISTS employee_positions;-
删除触发器:
DROP TRIGGER IF EXISTS before_insert_employee;1.2.4 TRUNCATE:快速删除表中的所有行。
-
快速删除表中的所有行,不记录行删除操作:
TRUNCATE TABLE employees;1.3 DQL(Data Query Language)数据查询语言:
-
DQL是用于查询或检索数据库中数据的SQL语句。
-
DQL实际上主要是
SELECT语句,它允许用户指定他们想要检索的数据。 -
DQL语句可以包含多个子句,如
WHERE、GROUP BY、HAVING和ORDER BY,以提供更复杂的查询能力。
1.3.1 基本查询
SELECT column1, column2 FROM table_name;1.3.2 条件查询
SELECT column1, column2 FROM table_name WHERE condition;1.3.3 分组查询
SELECT column1, COUNT(*) FROM table_name GROUP BY column1;1.3.4 分组后筛选
SELECT column1, SUM(column2) FROM table_name GROUP BY column1 HAVING SUM(column2) > 100;1.3.5 排序查询
SELECT column1, column2 FROM table_name ORDER BY column1 ASC, column2 DESC;1.3.6 聚合查询
SELECT column1, AVG(column2), MAX(column3), MIN(column3), COUNT(*) FROM table_name GROUP BY column1;1.3.7 联结查询
SELECT a.column1, b.column2 FROM table_name AS a JOIN another_table AS b ON a.common_column = b.common_column;1.3.8 子查询
SELECT * FROM table_name WHERE column1 IN (SELECT column1 FROM another_table WHERE condition);2. 简单的示例
2.1 DQL语句关键字执行顺序
-
FROM
-
首先确定查询的数据来源,即指定的表或子查询。
-
-
JOIN
-
接下来执行连接操作,根据JOIN关键字(INNER JOIN, LEFT JOIN, RIGHT JOIN等)将多个表连接起来。
-
-
WHERE
-
应用WHERE子句的条件过滤数据,只有满足条件的记录才会被保留。
-
-
GROUP BY
-
将结果集按照GROUP BY子句中的列进行分组。
-
-
HAVING
-
对分组后的结果应用HAVING子句的条件过滤,类似于WHERE,但是用于过滤分组后的结果。
-
-
SELECT
-
选择特定的列或计算后的列。
-
-
DISTINCT
-
如果使用DISTINCT关键字,去除结果中的重复行。
-
-
ORDER BY
-
对结果集进行排序。
-
-
LIMIT(在某些数据库系统中,如MySQL)
-
限制返回的结果数量。
-
-
OFFSET(与LIMIT一起使用)
-
指定从哪一条记录开始返回结果。
-
2.2 左连接示例
mysql> select * from employees e left join departments d on e.department = d.department_name;
+----+------------+-----------+---------------------------+------------+------------+-----------+---------------+-----------------+
| id | first_name | last_name | email | department | hire_date | salary | department_id | department_name |
+----+------------+-----------+---------------------------+------------+------------+-----------+---------------+-----------------+
| 1 | John | Doe | john.doe@example.com | Finance | 2023-01-10 | 70000.00 | 1 | Finance |
| 2 | Jane | Smith | jane.smith@example.com | IT | 2023-02-15 | 75000.00 | 3 | IT |
| 3 | Alice | Johnson | alice.johnson@example.com | HR | 2023-03-20 | 65000.00 | 2 | HR |
| 4 | Mike | Brown | mike.brown@example.com | Marketing | 2023-04-25 | 80000.00 | 4 | Marketing |
| 5 | yang | rongkai | 1968497756@qq.com | IT | NULL | 100000.00 | 3 | IT |
+----+------------+-----------+---------------------------+------------+------------+-----------+---------------+-----------------+
5 rows in set (0.00 sec)mysql> select * from employees e left join departments d on e.department = d.department_name where id = 1;
+----+------------+-----------+----------------------+------------+------------+----------+---------------+-----------------+
| id | first_name | last_name | email | department | hire_date | salary | department_id | department_name |
+----+------------+-----------+----------------------+------------+------------+----------+---------------+-----------------+
| 1 | John | Doe | john.doe@example.com | Finance | 2023-01-10 | 70000.00 | 1 | Finance |
+----+------------+-----------+----------------------+------------+------------+----------+---------------+-----------------+
1 row in set (0.00 sec)mysql> select * from employees e left join departments d on e.department = d.department_name order by id desc limit 3;
+----+------------+-----------+---------------------------+------------+------------+-----------+---------------+-----------------+
| id | first_name | last_name | email | department | hire_date | salary | department_id | department_name |
+----+------------+-----------+---------------------------+------------+------------+-----------+---------------+-----------------+
| 5 | yang | rongkai | 1968497756@qq.com | IT | NULL | 100000.00 | 3 | IT |
| 4 | Mike | Brown | mike.brown@example.com | Marketing | 2023-04-25 | 80000.00 | 4 | Marketing |
| 3 | Alice | Johnson | alice.johnson@example.com | HR | 2023-03-20 | 65000.00 | 2 | HR |
+----+------------+-----------+---------------------------+------------+------------+-----------+---------------+-----------------+
3 rows in set (0.00 sec)
注:inner join...on、left join...on、right join...on是一样的写法,主要在于以哪一个表为核心连接。
3. 锁

MySQL中的锁机制是确保数据一致性和隔离性的关键技术,主要分为以下几种类型:
-
全局锁
-
锁定整个数据库,使其处于只读状态。适用于全库备份等需要确保数据一致性的场景。使用
FLUSH TABLES WITH READ LOCK;命令可以获取全局锁。
-
-
表级锁
-
对某个表加锁,包括表锁和元数据锁(MDL)。表锁分为读锁(共享锁)和写锁(排他锁)。表级锁是粗粒度的锁,适用于不需要并发操作的场景。
-
读锁(共享锁)允许多个事务同时读取数据,而写锁(排他锁)在操作未完成前会阻塞其他读和写操作。
-
-
意向锁(Intention Lock)
-
表级锁的一种,标记当前事务对表中行的锁定意图,用于加速表锁和行锁之间的协调。分为意向共享锁(IS)和意向排他锁(IX)。
-
-
行级锁
-
每次操作锁住对应的行数据。主要分为记录锁(Record Lock)、间隙锁(Gap Lock)和临键锁(Next-Key Lock)。InnoDB通过行级锁实现了更细粒度的控制,支持更高的并发更新和查询。
-
记录锁(Record Lock)针对索引记录的锁定,防止其他事务对特定行进行update和delete。
-
间隙锁(Gap Lock)锁定索引记录间隙,确保索引记录间隙不变,防止其他事务在这个间隙进行insert,产生幻读。
-
临键锁(Next-Key Lock)结合了记录锁和间隙锁的功能,在RR隔离级别下支持。
-
-
共享锁(S锁)与排他锁(X锁)
-
共享锁允许多个事务同时获取,而排他锁则确保同一时间内只有一个事务可以获取。
-
-
乐观锁与悲观锁
-
乐观锁认为自己的操作会成功,先尝试执行,失败时再获取锁;悲观锁则认为自己的操作可能不成功,会先获取锁再执行。
-
-
页面锁
-
针对数据库表中的页进行加锁的机制,适用于对某一页中的多行进行操作时,减少锁的粒度,提高并发性能。
-
不积跬步,无以至千里 --- xiaokai
相关文章:
数据库操作、锁特性
1. DML、DDL和DQL是数据库操作语言的三种主要类型 1.1 DML(Data Manipulation Language)数据操纵语言 DML是用于检索、插入、更新和删除数据库中数据的SQL语句。 主要的DML语句包括: SELECT:用于查询数据库中的数据。 INSERT&a…...

学习笔记039——SpringBoot整合Redis
文章目录 1、Redis 基本操作Redis 默认有 16 个数据库,使用的是第 0 个,切换数据库添加数据/修改数据查询数据批量添加批量查询删除数据查询所有的 key清除当前数据库清除所有数据库查看 key 是否存在设置有效期查看有效期 2、Redis 数据类型String追加字…...

(笔记)简单了解ZYNQ
1、zynq首先是一个片上操作系统(Soc),结合了arm(PS)和fpga(PL)两部分组成 Zynq系统主要由两部分组成:PS(Processing System)和PL(Programmable L…...

大众点评小程序mtgsig1.2算法
测试效果: var e function _typeof(o) {return "function" typeof Symbol && "symbol" typeof Symbol.iterator? function (o) {return typeof o;}: function (o) {return o && "function" typeof Symbol &…...

七牛云AIGC内容安全方案助力企业合规创新
随着人工智能生成内容(AIGC)技术的飞速发展,内容审核的难度也随之急剧上升。在传统审核场景中,涉及色情、政治、恐怖主义等内容的标准相对清晰明确,但在AIGC的应用场景中,这些界限变得模糊且难以界定。用户可能通过交互性引导AI生成违规内容,为审核工作带来了前所未有的不可预测…...

.net的winfrom程序 窗体透明打开窗体时出现在屏幕右上角
窗体透明, 将Form的属性Opacity,由默认的100% 调整到 80%,这个数字越小越透明(尽量别低于50%,不信你试试看)! 打开窗体时出现在屏幕右上角 //构造函数 public frmCalendarList() {InitializeComponent();//打开窗体&…...
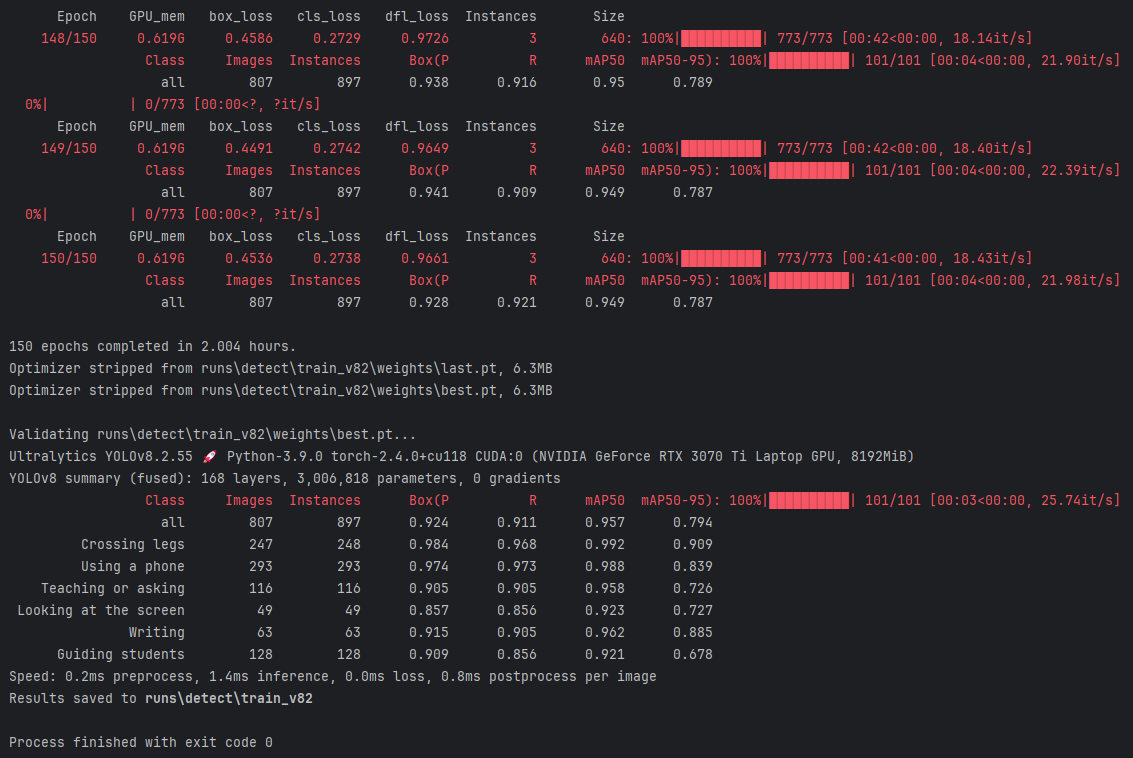
基于YOLOv8深度学习的智慧课堂教师上课行为检测系统研究与实现(PyQt5界面+数据集+训练代码)
随着人工智能技术的迅猛发展,智能课堂行为分析逐渐成为提高教学质量和提升教学效率的关键工具之一。在现代教学环境中,能够实时了解教师的课堂表现和行为,对于促进互动式教学和个性化辅导具有重要意义。传统的课堂行为分析依赖于人工观测&…...

使用 Tkinter 创建一个简单的 GUI 应用程序来合并视频和音频文件
使用 Tkinter 创建一个简单的 GUI 应用程序来合并视频和音频文件 Python 是一门强大的编程语言,它不仅可以用于数据处理、自动化脚本,还可以用于创建图形用户界面 (GUI) 应用程序。在本教程中,我们将使用 Python 的标准库模块 tkinter 创建一…...

【C++笔记】模板进阶
前言 各位读者朋友们大家好!上一期我们讲了stack、queue以及仿函数。先前我们讲过模板的初阶内容,这一期我们来更深入的学习一下模板。 一. 非类型模板参数 1.1 非类型模板参数 模板参数分为类型形参和类类型形参: 类型形参:…...

Soul App创始人张璐团队亮相GITEX GLOBAL 2024,展示多模态AI的交互创新
随着全球AI领域的竞争加剧,越来越多的科技巨头和创新企业纷纷致力于多模态AI的开发。2024年10月14日至18日,GITEX GLOBAL海湾信息技术博览会在迪拜举行,吸引了超过6700家全球科技巨头和创新公司参与,展示了智能互联、人工智能等领域的新成果。 此次展会中,Soul App创始人张璐团…...

ffmpeg.wasm 在浏览器运行ffmpeg操作视频
利用ffmpeg.wasm,可以在浏览器里运行ffmpeg,实现对音视频的操作 参考链接: https://blog.csdn.net/jchsgwbr/article/details/143252044 https://gitee.com/CXBalCai/ffmpeg-template 其他参考 https://github.com/ffmpegwasm/ffmpeg.wasm https://b…...

用Python爬虫“偷窥”1688商品详情:一场数据的奇妙冒险
引言:数据的宝藏 在这个信息爆炸的时代,数据就像是一座座等待挖掘的宝藏。而对于我们这些电商界的探险家来说,1688上的商品详情就是那些闪闪发光的金子。今天,我们将化身为数据的海盗,用Python这把锋利的剑࿰…...

CentOS上如何离线批量自动化部署zabbix 7.0版本客户端
CentOS上如何离线批量自动化部署zabbix 7.0版本客户端 管理的服务器大部分都是CentOS操作系统,版本主要是CentOS 7。因为监控服务器需要,要在前两天搭建的Zabbix 7.0系统上把这些CentOS 7系统都监控起来。因为服务器数量众多,而且有些服务器…...
采集及转换(Java版),含SQL格式及JSON格式)
【开源项目】ChinaAddressCrawler 中国行政区划数据(1980-2023年)采集及转换(Java版),含SQL格式及JSON格式
ChinaAddressCrawler 开源项目地址:https://gitee.com/li_yu_jiang/ChinaAddressCrawler 来源于国家民政部的数据只包括省级(省/直辖市/自治区/特别行政区)、地级(地级市/地区/自治州/盟)、县级(县/市辖区…...

React中事件处理和合成事件:理解与使用
🤍 前端开发工程师、技术日更博主、已过CET6 🍨 阿珊和她的猫_CSDN博客专家、23年度博客之星前端领域TOP1 🕠 牛客高级专题作者、打造专栏《前端面试必备》 、《2024面试高频手撕题》 🍚 蓝桥云课签约作者、上架课程《Vue.js 和 E…...

Local Changes不展示,DevEco Studio的git窗口中没有Local Changes
DevEco Studio的git窗口中,没有Local Changes,怎么设置可以调出? 进入File-->Settings-->Version Control,将Use non-modal commit interface前的勾选框取消勾选,点击OK即可在打开git窗口,就可以看到…...

大数据笔记
第一章、大数据概述 人类的行为及产生的事件的一种记录称之为数据。 1、大数据时代的特征,并结合生活实例谈谈带来的影响。 (一)特征 1、Volume 规模性:数据量大。 2、Velocity高速性:处理速度快。数据的生成和响…...

【Linux网络编程】TCP套接字
TCP与UDP的区别: udp是无连接的、面向数据报(通信时以数据报为单位传输)的传输层通信协议,其中每个数据报都是独立的,通信之前不需要建立连接,bind绑定套接字后直接可以进行通信。 tcp是面向连接的、基于字…...

在Manjaro Gnome桌面的基础上安装Budgie桌面环境
在Manjaro上安装Budgie桌面环境 Budgie是Solus团队开发的一种简单而优雅的桌面环境。 Budgie是由Solus项目主要开发的流行桌面环境,与GNOME堆栈紧密集成。它提供了简单而优雅的用户体验,并且可用于大多数发行版,如Arch、Debian、Manjaro等。…...

vscode可以编译通过c++项目,但头文件有红色波浪线的问题
1、打开 VSCode 的设置,可以通过快捷键 Ctrl Shift P 打开命令面板,然后搜索并选择 “C/C: Edit Configurations (JSON)” 命令,这将在 .vscode 文件夹中创建或修改 c_cpp_properties.json 文件 {"configurations": [{"name…...

高校邮件安全体系升级与 Proofpoint 部署实践研究 —— 以特拉华大学为例
摘要:随着网络钓鱼、垃圾邮件与恶意邮件攻击持续威胁高校信息系统,电子邮件安全已成为校园网络防护的核心环节。特拉华大学自 2026 年 6 月 1 日起全面启用 Proofpoint 邮件安全平台,构建覆盖邮件过滤、威胁隔离、用户自助处置与安全运营的全…...

如何构建高效笔记系统:解锁OneNote智能编辑新体验
如何构建高效笔记系统:解锁OneNote智能编辑新体验 【免费下载链接】NoteWidget Markdown add-in for Microsoft Office OneNote 项目地址: https://gitcode.com/gh_mirrors/no/NoteWidget 在数字时代,高效的知识管理已成为专业人士的核心竞争力。…...

第39天:SQL详解之DQL
Python学习100天(从入门到精通系列文章) 文章目录 Python学习100天(从入门到精通系列文章) 前言 一、基本查询与投影 1.1 查询所有列 1.2 投影与别名 二、数据筛选(WHERE 子句) 2.1 等值与比较筛选 2.2 多条件组合(AND / OR) 2.3 范围查询(BETWEEN) 2.4 CASE 表达式与…...

不变性假设下的PAC学习:从VC维到不变性VC维的样本效率提升
1. 项目概述:不变性假设下的PAC学习理论在机器学习领域,我们经常希望模型不仅能拟合训练数据,更能捕捉数据背后的本质规律,从而对未见过的数据做出可靠预测。PAC(Probably Approximately Correct)学习理论为…...

论文提速的终极秘籍!常用的AI论文软件,秒出初稿不费力
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题纠结、资料收集困难、逻辑梳理不清、反复修改头疼、格式排版繁琐... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接翻倍,原本…...

Web 世界的基石:深入解析 HTTP/1.1 的六大核心特点
🏛️ Web 世界的基石:深入解析 HTTP/1.1 的六大核心特点 🤔 为什么 HTTP/1.1 如此重要? HTTP/1.1 发布于 1997 年(RFC 2068),并在 1999 年更新(RFC 2616)。它统治了互联…...

量化精度不妥协,吞吐翻2.8倍——DeepSeek-R1推理优化黄金参数组合大曝光,仅限本周公开
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1推理优化的底层逻辑与精度守恒原理 DeepSeek-R1作为面向长上下文、高吞吐场景设计的开源大语言模型,其推理优化并非以牺牲数值精度为代价换取速度提升,而是建立在计算…...

如何用roop-unleashed三分钟制作专业级AI换脸视频:零门槛人脸替换终极指南
如何用roop-unleashed三分钟制作专业级AI换脸视频:零门槛人脸替换终极指南 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 还在为复杂的AI换脸工…...

3步实现缠论自动化:ChanlunX让复杂技术分析变得简单高效
3步实现缠论自动化:ChanlunX让复杂技术分析变得简单高效 【免费下载链接】ChanlunX 缠中说禅炒股缠论可视化插件 项目地址: https://gitcode.com/gh_mirrors/ch/ChanlunX 还在为缠论分析中的笔段划分和中枢识别而烦恼吗?ChanlunX通达信缠论插件正…...

Postman便携版:基于Portapps架构的无痕API测试环境构建方案
Postman便携版:基于Portapps架构的无痕API测试环境构建方案 【免费下载链接】postman-portable 🚀 Postman portable for Windows 项目地址: https://gitcode.com/gh_mirrors/po/postman-portable 在API开发与测试领域,Postman已成为开…...