NLP信息抽取大总结:三大任务(带Prompt模板)
信息抽取大总结
- 1.NLP的信息抽取的本质?
- 2.信息抽取三大任务?
- 3.开放域VS限定域
- 4.信息抽取三大范式?
- 范式一:基于自定义规则抽取(2018年前)
- 范式二:基于Bert+下游任务建模抽取(2018年后)
- 范式三:基于大模型+Promt抽取(2022年后)
- 附1:Prompt信息抽取模板
- (1)实体抽取
- (2)关系抽取
- (3)事件抽取
- (4)三元组抽取
- 附2:中文大模型抽取哪家强?
- 附3:专用于信息抽取的模型
2024.11.27
I hear and I forget; I see and I know; I do and I understand
1.NLP的信息抽取的本质?
针对NLP领域的信息抽取,即是从原始文本数据中自动提取出结构化的信息,本质相当于是对原始数据进行了一次信息加工,把我们不关注的信息进行了剔除或把我们关注的信息进行提炼。
抽取后的信息就相当于一篇论文的摘要和关键词。
2.信息抽取三大任务?
信息抽取是一个较大的范畴,可以细分为很多任务,但我们通常关注以下三类:

-
实体抽取
实体抽取的总结可以查看我的另外一篇文章:
https://blog.csdn.net/xiangxiang613/article/details/143922862
-
关系抽取
待总结
-
事件抽取
待总结
这些任务在建模时可以独立建模(每种任务一个模型)或者统一建模(一个模型能同时处理多种任务,如上图的UIE)。
3.开放域VS限定域
- 开放域信息抽取,就是不限定实体和关系的类型,给定文本,抽取其包含的所有SPO三元组〈主,谓,宾〉,或者叫RDF三元组,这个通常就弱化了schema的设计(不需要设计);在大模型构建知识图谱时代,这个是趋势。
- 限定域信息抽取,就是限定抽取的实体和关系类型(此时可以画出清晰的schema),此时适合清晰的业务场景,具备推理价值。
4.信息抽取三大范式?
下面更侧重与实体抽取和关系抽取任务的处理,因为在知识抽取过程中更关注这两类。
范式一:基于自定义规则抽取(2018年前)
典型的,使用自定义词典+分词工具+词性标注完成实体抽取;基于依存句法分析+自定义关系创建规则完成关系抽取。这是在深度学习时代前常用的方法,优点是简单好理解,上手快,不需要标注数据和训练模型,只需要写规则;但规则的最大缺点就是不灵活,覆盖率低。
范式二:基于Bert+下游任务建模抽取(2018年后)

Bert的诞生重塑了NLP的任务构建范式,几乎所有的NLP任务都被转换为BERT的下游任务进行微调。在信息抽取领域,此时需要完成一定量的下游任务样本数据集标注(通常还伴随着标注规范的指定),针对一份数据集,会同时标注实体和实体间的关系。
一个样本标注完的数据,大概包含下面这些信息:
(人工标注的过程其实就是人在做信息抽取的过程)
{"sentences": ["维护V3^对蓄电池进行充电处理^由于蓄电池电量不足^无法启动↓↓充电处理*蓄电池↓蓄电池*电量不足↓[整车]无法启动"],"ner": [[[6, 8, "PART"], [11, 14, "METHOD"], [18, 20, "PART"], [21, 24, "STATUE"], [26, 29, "STATUE"], [32, 39, "SOLUTION"], [41, 48, "TROUBLE"], [50, 57, "TROUBLE"]]],"relations": [[]],"doc_key": "RID_2014010129978096","predicted_ner": [[[6, 8, "PART"], [11, 14, "METHOD"], [18, 20, "PART"], [21, 24, "STATUE"], [26, 29, "STATUE"], [32, 39, "SOLUTION"], [41, 48, "TROUBLE"], [50, 57, "TROUBLE"]]],"predicted_relations": [[]],"sections": [[[0, 3], [5, 14], [16, 24], [26, 29]]],"dtc": [[]],"part_no": [["00-000"]],"part_name": [["无零件"]],"relations_inside": [[[11, 14, 6, 8, "METH"], [18, 20, 21, 24, "TROU"]]],"combined_ner_to_rel": [{"充电处理*蓄电池": 0, "蓄电池*电量不足": 1}]
}基于标注完成的数据,可以分别训练实体抽取模型和关系抽取模型(pipeline方式),也可以同时训练实体-关系抽取模型(joint方式),此处不展开,后面再关系抽取总结的文章中再谈。
无论是那种方式,都会采用bert来作为底层的文本编码器,实现文本向量生成,区别在于bert向量生成后的下游任务建模方式不同。
在Bert时代,信息抽取任务通常是被当成一个序列标注型任务进行处理的,答案是存在于文本之中的。
即使在大模型时代,基于bert类的抽取方法也是性能最好的。在2024年了,都还有这方面的模型出现。如GliNER(基于DeBERTA v3 large)star1.5K,可以一看:
https://www.zhihu.com/people/luo-xie-yang-guang【GliNER 多任务: 适用于各种信息提取任务的通用轻量级模型】
补充:bert这么好,为什么大家要用大模型,因为要用bert一方面是要标注数据进行微调,另一方面是微调后的模型通常只能识别限定域的实体类型和关系类型(训练什么就识别什么),这个特点导致使用bert模型的成本很高,而大模型则是属于开放域信息抽取,不限制实体和关系的类型(更具应用场景可以限定)。
范式三:基于大模型+Promt抽取(2022年后)

这里的大模型准确来说是指生成式大模型,此时将信息抽取任务转换为文本生成任务进行处理。
在大模型时代下,信息抽取任务只需要编写一个少样本学习的Promt即可完成抽取,见后文。少样本学习(few-short)是指在Prompt中添加几个任务的示例样本,包含输入和输出。在信息抽取领域,这种方式明细优于零样本学习(zero-short)。可以参考:https://zhuanlan.zhihu.com/p/702821255
尽管大模型在各种NLP任务上取得了SOTA性能,但其在NER上的性能仍然明显低于监督基线。这是由于NER和llm两个任务之间的差距:前者本质上是一个序列标记任务,而后者是一个文本生成模型。
完整的大模型用于信息抽取综述性文章可以参考:《Large Language Models for Generative Information Extraction: A Survey》https://arxiv.org/pdf/2312.17617.pdf

附1:Prompt信息抽取模板
收集的一些Prompt模板如下,英文模板需要翻译为中文模板进行使用,陆续更新:
(1)实体抽取
- 模板1:来自oneKE
{"task": "NER","source": "NER","instruction": {"instruction": "你是专门进行实体抽取的专家。请从input中抽取出符合schema定义的实体,不存在的实体类型返回空列表。请按照JSON字符串的格式回答。","schema": ["人物", "地理位置", "组织机构"],"input": "在这里恕弟不恭之罪,敢在尊前一诤:前人论书,每曰“字字有来历,笔笔有出处”,细读公字,何尝跳出前人藩篱,自隶变而后,直至明季,兄有何新出?"},"output": {"人物": [],"地理位置": [],"组织机构": []}
}- 模板2:来自YAYI-UIE
{"Task": "NER","Dataset": "WikiNeural","instruction": "Text: In the Tour of Flanders , he took on a defensive role when his teammate Stijn Devolder escaped and won . \n【Named Entity Recognition】From the given text, extract all the entities and types. Please format the answer in json {location/person/organization:[entities]}. \nAnswer:","input": "","label": {"person": ["Stijn Devolder"]}
}-
模板3:来自Assessing the Performance of Chinese Open Source Large Language Models in Information Extraction Tasks[https://arxiv.org/abs/2406.02079]
包含普通的和二阶段,且NER两阶段性能大幅度优于普通

(2)关系抽取
- 模板1:来自oneKE
{"task": "RE","source": "RE","instruction": {"instruction": "你是专门进行关系抽取的专家。请从input中抽取出符合schema定义的关系三元组,不存在的关系返回空列表。请按照JSON字符串的格式回答。","schema": ["丈夫", "上映时间", "专业代码", "主持人"],"input": "如何演好自己的角色,请读《演员自我修养》《喜剧之王》周星驰崛起于穷困潦倒之中的独门秘笈"},"output": {"丈夫": [],"上映时间": [],"专业代码": [],"主持人": []}
}- 模板2:来自Assessing the Performance of Chinese Open Source Large Language Models in Information Extraction Tasks[https://arxiv.org/abs/2406.02079]
包含普通的和QA4RE

(3)事件抽取
- 模板1:来自oneKE
{"task": "EE","source": "PHEE","instruction": {"instruction": "You are an expert in event extraction. Please extract events from the input that conform to the schema definition. Return an empty list for events that do not exist, and return NAN for arguments that do not exist. If an argument has multiple values, please return a list. Respond in the format of a JSON string.","schema": [{"event_type": "potential therapeutic event","trigger": true,"arguments": ["Treatment.Time_elapsed","Treatment.Route","Treatment.Freq","Treatment","Subject.Race","Treatment.Disorder","Effect","Subject.Age","Combination.Drug","Treatment.Duration","Subject.Population","Subject.Disorder","Treatment.Dosage","Treatment.Drug"]},{"event_type": "adverse event","trigger": true,"arguments": ["Subject.Population","Subject.Age","Effect","Treatment.Drug","Treatment.Dosage","Treatment.Freq","Subject.Gender","Treatment.Disorder","Subject","Treatment","Treatment.Time_elapsed","Treatment.Duration","Subject.Disorder","Subject.Race","Combination.Drug"]}],"input": "Our findings reveal that even in patients without a history of seizures, pregabalin can cause a cortical negative myoclonus."},"output": {"potential therapeutic event": [],"adverse event": [{"trigger": "cause","arguments": {"Subject.Population": "NAN","Subject.Age": "NAN","Effect": "cortical negative myoclonus","Treatment.Drug": "pregabalin","Treatment.Dosage": "NAN","Treatment.Freq": "NAN","Subject.Gender": "NAN","Treatment.Disorder": "NAN","Subject": "patients without a history of seizures","Treatment": "pregabalin","Treatment.Time_elapsed": "NAN","Treatment.Duration": "NAN","Subject.Disorder": "NAN","Subject.Race": "NAN","Combination.Drug": "NAN"}}]}
}- 模板2:来自Assessing the Performance of Chinese Open Source Large Language Models in Information Extraction Tasks[https://arxiv.org/abs/2406.02079]
(4)三元组抽取
- 模板1:来自YAYI-UIE
{"Task": "CRE","Dataset": "SanWen_sample50000","instruction": "文本: 我与其他云南同学对视骇笑 \n【关系抽取】已知关系列表是['unknown', '造出', '使用', '临近', '社会关系', '位于', '拥有者', '隶属于', '亲属', '包含']\n根据关系列表抽取关系三元组,在这个句子中可能包含哪些关系三元组?请按照json[{'relation':'', 'head':'', 'tail':''}, ]的格式回答。\n答案:","input": "","label": [{"relation": "社会关系","head": "我","tail": "其他云南同学"}]
}- 模板2:来自textgraphs
prompt= """句子: {} 从句子中提取 RDF 三元组,格式如下: 主语:<主语> 谓词:<谓词> 宾语:<宾语,可选> """
text= """维尔纳·赫尔佐格是一位德国电影导演、编剧、作家、演员和歌剧导演,被认为是新德国电影的先驱。"""
附2:中文大模型抽取哪家强?
参考1:【哪个中文开源大模型在信息抽取上效果最好?】
结论:
-
实体抽取(零样本):qwen-14B >> Baichuan2-13B > qwen-7B > ChatGLM3-6B

注意:各模型少样本的性能会普遍强于零样本;
-
关系抽取(无限制):qwen-14B > qwen-7B > ChatGLM3-6B>Baichuan2-13B

-
事件抽取:Baichuan2-13B > qwen-14B >>qwen-7B > ChatGLM3-6B

整体来看,Qwen系列确实很强,特别是现在还升级到了2.5系列,在实际使用过程中,体验也不错,可以作为一个不错的基准大模型用于中文领域的信息抽取。
附3:专用于信息抽取的模型
印象中有这几个:
-
UIE:2022,开启基于promt的多任务统一建模方式;
-
InstructUIE:基于指令微调后的UIE?
-
oneKE:https://github.com/zjunlp/DeepKE/tree/main/example/llm/InstructKGC/data
-
UniLM:https://github.com/microsoft/unilm,微软出品,20+Kstar
-
UniIE:https://github.com/AAIG-NLP/UniIE
-
GliNER:https://github.com/urchade/GLiNER,2024新提出。1.5Kstar
-
openNRE:清华出品,基于CNN用于关系抽取?
待更新…
相关文章:
NLP信息抽取大总结:三大任务(带Prompt模板)
信息抽取大总结 1.NLP的信息抽取的本质?2.信息抽取三大任务?3.开放域VS限定域4.信息抽取三大范式?范式一:基于自定义规则抽取(2018年前)范式二:基于Bert下游任务建模抽取(2018年后&a…...
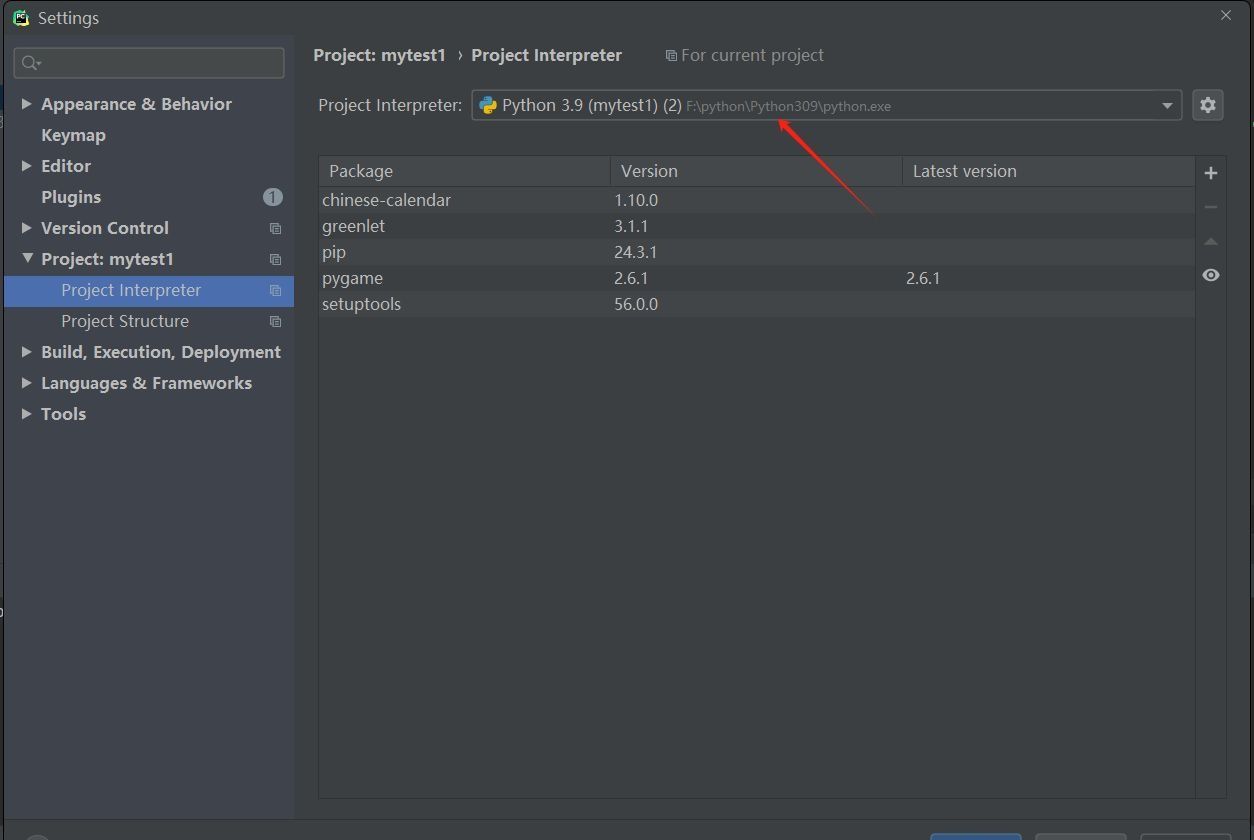
python常见问题-pycharm无法导入三方库
1.运行环境 python版本:Python 3.9.6 需导入的greenlet版本:greenlet 3.1.1 2.当前的问题 由于需要使用到greenlet三方库,所以进行了导入,以下是我个人导入时的全过程 ①首先尝试了第1种导入方式:使用pycharm进行…...

迅为RK3588开发板Android系统开发笔记-使用ADB工具
1 使用 ADB 工具 ADB 英文名叫 Android debug bridge ,是 Android SDK 里面的一个工具,用这个工具可以操作管理 Android 模拟器或者真实的 Android 设备,主要的功能如下所示: 在 Android 设备上运行 shell 终端,用命…...

什么是分布式数据库?
随着现代互联网应用和大数据时代的到来,分布式数据库成为了解决大规模数据存储和高并发处理的核心技术之一。本文将通过深入浅出的方式,带你全面理解分布式数据库的概念、工作原理以及底层实现技术。无论你是刚刚接触分布式数据库的开发者,还…...

Leetcode 3363. Find the Maximum Number of Fruits Collected
Leetcode 3363. Find the Maximum Number of Fruits Collected 1. 解题思路2. 代码实现 题目链接:3363. Find the Maximum Number of Fruits Collected 1. 解题思路 这一题是一道陷阱题…… 乍一眼看过去,由于三人的路线完全可能重叠,因此…...

【数据仓库 | Data Warehouse】数据仓库的四大特性
1. 前言 数据仓库是用于支持管理和决策的数据集合,它汇集了来自不同数据源的历史数据,以便进行多维度的分析和报告。数据仓库的四大特点是:主题性,集成性,稳定性,时变性。 2. 主题性(Subject-Oriented) …...

springboot配置多数据源mysql+TDengine保姆级教程
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、pom文件二、yamlDataSourceConfigServiceMapper.xml测试总结 前言 Mybatis-plus管理多数据源,数据库为mysql和TDengine。 一、pom文件 <de…...

dns实验2:反向解析
启动服务: 给虚拟机网卡添加IP地址: 查看有几个IP地址: 打开配置文件: 重启服务,该宽松模式,关闭防火墙: 本机测试: windows测试:(本地shell)...

ZooKeeper 基础知识总结
先赞后看,Java进阶一大半 ZooKeeper 官网这样介绍道:ZooKeeper 是一种集中式服务,用于维护配置信息、命名、提供分布式同步和提供组服务。 各位hao,我是南哥,相信对你通关面试、拿下Offer有所帮助。 ⭐⭐⭐一份南哥编写…...

npm库xss依赖的使用方法和vue3 中Web富文本编辑器 wangeditor 使用xss库解决 XSS 攻击的方法
npm库xss依赖的使用方法和vue3 中Web富文本编辑器 wangeditor 使用xss库解决 XSS 攻击的方法 1. npm库xss依赖的使用方法1.1 xss库定义1.2 xss库功能 2. vue3 中 wangeditor 使用xss库解决 XSS 攻击的方法和示例2.1 在终端执行如下命令安装 xss 依赖2.2 在使用 wangeditor 的地…...

微信小程序蓝牙writeBLECharacteristicValue写入数据返回成功后,实际硬件内信息查询未存储?
问题:连接蓝牙后,调用小程序writeBLECharacteristicValue,返回传输数据成功,查询硬件响应发现没有存储进去? 解决:一直以为是这个write方法的问题,找了很多相关贴,后续进行硬件日志…...

5G NR:带宽与采样率的计算
100M 带宽是122.88Mhz sampling rate这是我们都知道的,那它是怎么来的呢? 采样率 子载波间隔 * 采样长度 38.211中对于Tc的定义, 在LTE是定义了Ts,在NR也就是5G定义了Tc。 定义这个单位会对我们以后工作中的计算至关重要。 就是在…...

go 和java 编写方式的理解
1. go 推荐写流水账式的代码(非贬义),自己管自己。java喜欢封装各种接口供外部调用,让别人来管自己。 2. 因为协程的存在, go的变量作用域聚集在方法内部,即函数不可重入,而java线程的限制&…...

C# 7.1 .Net Framwork4.7 VS2017环境下,方法的引用与调用
方法的调用比较好理解,就是给方法传递实参,执行方法代码。 方法引用涉及委托,委托签名与其引用的方法必须一致。以下demo说明方法调用与引用在写程序时的区别: using System; using System.Collections.Generic; using System.L…...

etcd、kube-apiserver、kube-controller-manager和kube-scheduler有什么区别
在我们部署K8S集群的时候 初始化master节点之后(在master上面执行这条初始化命令) kubeadm init --apiserver-advertise-address10.0.1.176 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.16.0 --service…...

每日一题 LCR 057. 存在重复元素 III
LCR 057. 存在重复元素 III 滑动窗口二分查找 有序集合 有lower_bound(num) ,可以找到第一个大于其的数字 class Solution { public:bool containsNearbyAlmostDuplicate(vector<int>& nums, int k, int t) {set<long> win;for(int i0;i<nums.size();i){a…...

使用IDEA编写测试用例,复杂度校验
最近我们公司要求开发人员必须写测试用例,组织了TDD培训,测试驱动开发,同时衡量代码的圈复杂度,我记录下初次使用的过程。 编写测试用例,查看用例覆盖度 1、要编写测试用例,并看下测试用例的覆盖度&#…...

搭建私有云存储
1、安装LNMP环境 yum install nginx -y yum install -y nginx mariadb-server php php-fpm php-mysqlnd systemctl restart nginx.service --- 启动Nginx systemctl start mariadb.service ---启动数据库 mysql -e create database lxdb character set utf8 ---创建数据库 my…...

【从零开始的LeetCode-算法】3304. 找出第 K 个字符 I
Alice 和 Bob 正在玩一个游戏。最初,Alice 有一个字符串 word "a"。 给定一个正整数 k。 现在 Bob 会要求 Alice 执行以下操作 无限次 : 将 word 中的每个字符 更改 为英文字母表中的 下一个 字符来生成一个新字符串,并将其 追加 到原始的…...

深入解析分布式遗传算法及其Python实现
目录 深入解析分布式遗传算法及其Python实现目录第一部分:分布式遗传算法的背景与原理1.1 遗传算法概述1.2 分布式遗传算法的引入1.3 分布式遗传算法的优点与挑战优点:挑战:第二部分:分布式遗传算法的通用Python实现2.1 基本组件的实现第三部分:案例1 - 基于多种交叉与变异…...

工业网关、电机控制、人机界面:ATSAME70Q21B-AN的应用版图
ATSAME70Q21B-AN:300MHz Cortex-M7工业MCU的嵌入式应用解析在工业控制、人机界面和物联网网关等领域,微控制器需要在处理性能、外设集成度和环境适应性之间取得平衡。ATSAME70Q21B-AN是Microchip推出的基于ARM Cortex-M7内核的高性能32位微控制器&#x…...

终极指南:3分钟掌握Typora插件,让写作效率提升300%
终极指南:3分钟掌握Typora插件,让写作效率提升300% 【免费下载链接】typora_plugin Typora plugin. Feature enhancement tool | Typora 插件,功能增强工具 项目地址: https://gitcode.com/gh_mirrors/ty/typora_plugin Typora是一款广…...

微信机器人WeixinBot完整指南:从零构建自动化微信应用
微信机器人WeixinBot完整指南:从零构建自动化微信应用 【免费下载链接】WeixinBot 网页版微信API,包含终端版微信及微信机器人 项目地址: https://gitcode.com/gh_mirrors/we/WeixinBot 微信机器人WeixinBot是一个功能强大的网页版微信API框架&am…...

iOS 27 开放 AI 生态@ACP#专业视频处理新标杆 ——GSV9001E/S 赋能 iPhone AI 多屏智能显示
一、iOS 27 开放 AI:引爆专业视频处理与多屏显示刚需iOS 27 全面开放第三方 AI 模型,iPhone 成为 AI 内容生成、多源信号整合、智能交互核心,直接催生AI 多屏拼接、无缝切换、画中画、HDR/SDR 转换、车载 / 工控多视图、医疗 AI 显示六大专业…...

C++ 管理类使用单例模式的特点与最佳实践
摘要:在 C++ 项目开发中,管理类(如日志管理器、配置管理器、资源管理器等)通常需要全局唯一实例。本文结合栈对象与指针的性能差异,深入探讨单例模式在管理类设计中的特点,并给出一个可复用的 CRTP 单例模板实现。 一、为什么管理类需要单例模式? 在大型 C++ 项目中,我…...

英雄联盟智能辅助工具Seraphine:三步快速上手的终极指南
英雄联盟智能辅助工具Seraphine:三步快速上手的终极指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 你是否厌倦了在英雄联盟排位赛中手忙脚乱地查询对手战绩?是否希望有一个智能助…...

从蛋白质分类到社交网络:Graph Pooling在实际项目里到底怎么用?
从蛋白质分类到社交网络:Graph Pooling实战选型指南 在生物信息实验室里,研究员小李正盯着屏幕上错综复杂的蛋白质相互作用网络发愁——如何将这个包含数千个原子的三维结构转化为机器学习模型可处理的表征?与此同时,某社交平台算…...

3个步骤掌握Sketch MeaXure:设计师与开发者的终极协作桥梁
3个步骤掌握Sketch MeaXure:设计师与开发者的终极协作桥梁 【免费下载链接】sketch-meaxure 项目地址: https://gitcode.com/gh_mirrors/sk/sketch-meaxure 你是否厌倦了在Sketch中手动测量每个元素、反复截图标注的日子?Sketch MeaXure正是为解…...

学生党福音:用最便宜的TT马达和STM32F103C8T6,我焊出了能遥控的平衡小车
低成本DIY平衡小车:TT马达与STM32的极致性价比方案 当我在宿舍里第一次看到那辆价值近千元的商业平衡小车时,脑海中立刻浮现出一个问题:能不能用更便宜的材料实现类似功能?作为一名预算有限的学生,我开始探索如何用最…...

前端工程化:代码审查最佳实践
前端工程化:代码审查最佳实践 前言 代码审查是保障代码质量的第一道防线。一个好的代码审查流程不仅能发现潜在的bug,还能促进团队知识共享,提升整体代码水平。今天我就来给大家讲讲如何建立一套高效的代码审查流程。 什么是代码审查 代码审查…...