OpenCV从入门到精通实战(五)——dnn加载深度学习模型
从指定路径读取图像文件、利用OpenCV进行图像处理,以及使用Caffe框架进行深度学习预测的过程。
下面是程序的主要步骤和对应的实现代码总结:
1. 导入必要的工具包和模型
程序开始先导入需要的库os、numpy、cv2,同时导入utils_paths模块,后者用于处理图像路径。接着,读取Caffe模型和配置文件,这些文件提供了使用预训练深度学习模型进行图像分类的基础。
import utils_paths
import numpy as np
import cv2net = cv2.dnn.readNetFromCaffe("bvlc_googlenet.prototxt", "bvlc_googlenet.caffemodel")
2. 读取图像文件
使用utils_paths.list_images函数遍历指定目录,获取所有图像文件的路径。
imagePaths = sorted(list(utils_paths.list_images("images/")))
3. 图像预处理
选择路径列表中的第一个图像进行读取,调整其大小以符合模型输入需求,并通过cv2.dnn.blobFromImage创建适合Caffe模型的输入blob。
image = cv2.imread(imagePaths[0])
resized = cv2.resize(image, (224, 224))
blob = cv2.dnn.blobFromImage(resized, 1, (224, 224), (104, 117, 123))
4. 模型预测和结果展示
设定模型输入,执行前向传播获取预测结果,找出概率最高的类别,并在图像上显示预测标签和概率。
net.setInput(blob)
preds = net.forward()
idx = np.argsort(preds[0])[::-1][0]
text = "Label: {}, {:.2f}%".format(classes[idx], preds[0][idx] * 100)
cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.imshow("Image", image)
cv2.waitKey(0)
5. 批量图像处理
对多个图像执行上述步骤,生成多图像的输入blob,并对每个图像执行预测,展示结果。
images = []
for p in imagePaths[1:]:image = cv2.imread(p)image = cv2.resize(image, (224, 224))images.append(image)blob = cv2.dnn.blobFromImages(images, 1, (224, 224), (104, 117, 123))
net.setInput(blob)
preds = net.forward()for (i, p) in enumerate(imagePaths[1:]):image = cv2.imread(p)idx = np.argsort(preds[i])[::-1][0]text = "Label: {}, {:.2f}%".format(classes[idx], preds[i][idx] * 100)cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)cv2.imshow("Image", image)cv2.waitKey(0)
完整代码
utils_paths.py
import osimage_types = (".jpg", ".jpeg", ".png", ".bmp", ".tif", ".tiff")def list_images(basePath, contains=None):# return the set of files that are validreturn list_files(basePath, validExts=image_types, contains=contains)def list_files(basePath, validExts=None, contains=None):# loop over the directory structurefor (rootDir, dirNames, filenames) in os.walk(basePath):# loop over the filenames in the current directoryfor filename in filenames:# if the contains string is not none and the filename does not contain# the supplied string, then ignore the fileif contains is not None and filename.find(contains) == -1:continue# determine the file extension of the current fileext = filename[filename.rfind("."):].lower()# check to see if the file is an image and should be processedif validExts is None or ext.endswith(validExts):# construct the path to the image and yield itimagePath = os.path.join(rootDir, filename)yield imagePathblob_from_images.py
# 导入工具包
import utils_paths
import numpy as np
import cv2# 标签文件处理
rows = open("synset_words.txt").read().strip().split("\n")
classes = [r[r.find(" ") + 1:].split(",")[0] for r in rows]# Caffe所需配置文件
net = cv2.dnn.readNetFromCaffe("bvlc_googlenet.prototxt","bvlc_googlenet.caffemodel")# 图像路径
imagePaths = sorted(list(utils_paths.list_images("images/")))# 图像数据预处理
image = cv2.imread(imagePaths[0])
resized = cv2.resize(image, (224, 224))
# image scalefactor size mean swapRB
blob = cv2.dnn.blobFromImage(resized, 1, (224, 224), (104, 117, 123))
print("First Blob: {}".format(blob.shape))# 得到预测结果
net.setInput(blob)
preds = net.forward()# 排序,取分类可能性最大的
idx = np.argsort(preds[0])[::-1][0]
text = "Label: {}, {:.2f}%".format(classes[idx],preds[0][idx] * 100)
cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX,0.7, (0, 0, 255), 2)# 显示
cv2.imshow("Image", image)
cv2.waitKey(0)# Batch数据制作
images = []# 方法一样,数据是一个batch
for p in imagePaths[1:]:image = cv2.imread(p)image = cv2.resize(image, (224, 224))images.append(image)# blobFromImages函数,注意有s
blob = cv2.dnn.blobFromImages(images, 1, (224, 224), (104, 117, 123))
print("Second Blob: {}".format(blob.shape))# 获取预测结果
net.setInput(blob)
preds = net.forward()
for (i, p) in enumerate(imagePaths[1:]):image = cv2.imread(p)idx = np.argsort(preds[i])[::-1][0]text = "Label: {}, {:.2f}%".format(classes[idx],preds[i][idx] * 100)cv2.putText(image, text, (5, 25), cv2.FONT_HERSHEY_SIMPLEX,0.7, (0, 0, 255), 2)cv2.imshow("Image", image)cv2.waitKey(0)



以下是后续代码的改进:
6. 异常处理和验证
在处理文件读取和图像处理时,加入异常处理可以避免在文件不存在或损坏时程序崩溃。
try:image = cv2.imread(imagePath)if image is None:raise ValueError("无法读取图像: {}".format(imagePath))resized = cv2.resize(image, (224, 224))
except Exception as e:print("处理图像时发生错误: ", e)
7. 性能优化
对于图像处理和预测,尤其是批量操作时,可以通过并行处理技术来加速这些操作。例如,使用Python的concurrent.futures模块进行并行读取和预处理图像。
from concurrent.futures import ThreadPoolExecutordef process_image(path):image = cv2.imread(path)image = cv2.resize(image, (224, 224))return imagewith ThreadPoolExecutor() as executor:images = list(executor.map(process_image, imagePaths))
8. 动态输入和命令行工具
将脚本转换为可接受命令行参数的形式,使其更灵活,能够通过命令行直接指定图片路径、模型文件等。
import argparseparser = argparse.ArgumentParser(description='图像分类预测')
parser.add_argument('--image_dir', type=str, required=True, help='图像目录路径')
parser.add_argument('--model', type=str, required=True, help='模型文件路径')
args = parser.parse_args()imagePaths = sorted(list(utils_paths.list_images(args.image_dir)))
net = cv2.dnn.readNetFromCaffe("bvlc_googlenet.prototxt", args.model)
9. GUI界面
为了使程序更友好,可以开发一个基于图形用户界面的应用,允许用户通过图形界面选择图像和观看结果,而不是仅限于命令行。
import tkinter as tk
from tkinter import filedialogdef load_image():path = filedialog.askopenfilename()return cv2.imread(path), pathroot = tk.Tk()
load_button = tk.Button(root, text='加载图像', command=load_image)
load_button.pack()
root.mainloop()
初始代码 下载地址 dnn加载深度学习模型
相关文章:
OpenCV从入门到精通实战(五)——dnn加载深度学习模型
从指定路径读取图像文件、利用OpenCV进行图像处理,以及使用Caffe框架进行深度学习预测的过程。 下面是程序的主要步骤和对应的实现代码总结: 1. 导入必要的工具包和模型 程序开始先导入需要的库os、numpy、cv2,同时导入utils_paths模块&…...

【Leetcode Top 100】142. 环形链表 II
问题背景 给定一个链表的头节点 h e a d head head,返回链表开始入环的第一个节点。 如果链表无环,则返回 n u l l null null。 如果链表中有某个节点,可以通过连续跟踪 n e x t next next 指针再次到达,则链表中存在环。 为了…...

嵌入式Qt使用ffmpeg视频开发记录
在此记录一下Qt下视频应用开发的自学历程,可供初学者参考和避雷。 了解常用音频格式yuv420p、h264等了解QML,了解QVideoOutput类的使用,实现播放yuv420p流参考ffmpeg官方例程,调用解码器实现h264解码播放 不需要手动分帧。ffmpeg…...

iOS 17.4 Not Installed
0x00 系统警告 没有安装 17.4 的模拟器,任何操作都无法进行! 点击 OK 去下载,完成之后,依旧是原样! 0x01 解决办法 1、先去官网下载对应的模拟器: https://developer.apple.com/download/all/?q17.4 …...
)
CTF之WEB(sqlmap tamper 参数)
apostropheask.py 作用:将单引号替换为UTF-8,用于过滤单引号。 base64encode.py 作用:替换为base64编码。 multiplespaces.py 作用:绕过SQL关键字添加多个空格。 space2plus.py 作用:用号替换…...

多点DMALL启动招股:将在港交所上市,聚焦数字零售服务
近日,多点数智有限公司(Dmall Inc.,下称“多点”或“多点DMALL”)发布全球发售文件,于11月28日至12月3日招股,预计将于2024年12月6日在港交所主板挂牌上市。 招股书显示,多点DMALL本次全球发售的…...

【c++篇】:解读Set和Map的封装原理--编程中的数据结构优化秘籍
✨感谢您阅读本篇文章,文章内容是个人学习笔记的整理,如果哪里有误的话还请您指正噢✨ ✨ 个人主页:余辉zmh–CSDN博客 ✨ 文章所属专栏:c篇–CSDN博客 文章目录 前言一.set和map的初步封装1.树的节点封装修改2.Find()查找函数3.红…...

ollama部署bge-m3,并实现与dify平台对接
概述 这几天为了写技术博客,各种组件可谓是装了卸,卸了装,只想复现一些东西,确保你们看到的东西都是可以复现的。 (看在我这么认真的份上,求个关注啊,拜托各位观众老爷了。) 这不,为了实验在windows上docker里运行pytorch,把docker重装了。 dify也得重装: Dify基…...

在并发情况下,Elasticsearch如果保证读写一致?
大家好,我是锋哥。今天分享关于【在并发情况下,Elasticsearch如果保证读写一致?】面试题。希望对大家有帮助; 在并发情况下,Elasticsearch如果保证读写一致? 1000道 互联网大厂Java工程师 精选面试题-Java…...

AMD的AI芯片Instinct系列介绍
AMD最强AI芯片发布! 在旧金山举行的Advancing AI 2024大会上,AMD推出Instinct MI325X AI加速器(以下简称MI325X),直接与英伟达的Blackwell芯片正面交锋。 现场展示的数据显示,与英伟达H200的集成平台H200 …...

【知识科普】设计模式之-责任链模式
这里写自定义目录标题 概述责任链模式的详细描述责任链模式的使用场景 使用场景举例1. 审批流程示例:2. 过滤器链示例:3. 事件处理系统示例:4. 插件系统示例: Java代码示例及注释代码解释 概述 责任链模式的详细描述 责任链模式…...

fiddler安卓雷电模拟器配置踩坑篇
一、fiddler端配置 和网页版fiddler一样,需要首先再本机安装证书,可以参考我之前的fiddler浏览器配置文章,前期操作一致: 此处需要注意的是connections里面需要勾选allow remote这个选项,这个主要是为了后来再安卓模拟…...

机器学习5-多元线性回归
多元线性回归 主要了解多元线性回归的原理以及数学推导。 只有损失函数是凸函数才能确认是最优解,极值不一定是最优解 判定凸函数的方式非常多,其中一个方法是看黑塞矩阵是否是半正定的。 黑塞矩阵(hessian matrix)是由目标函数在…...
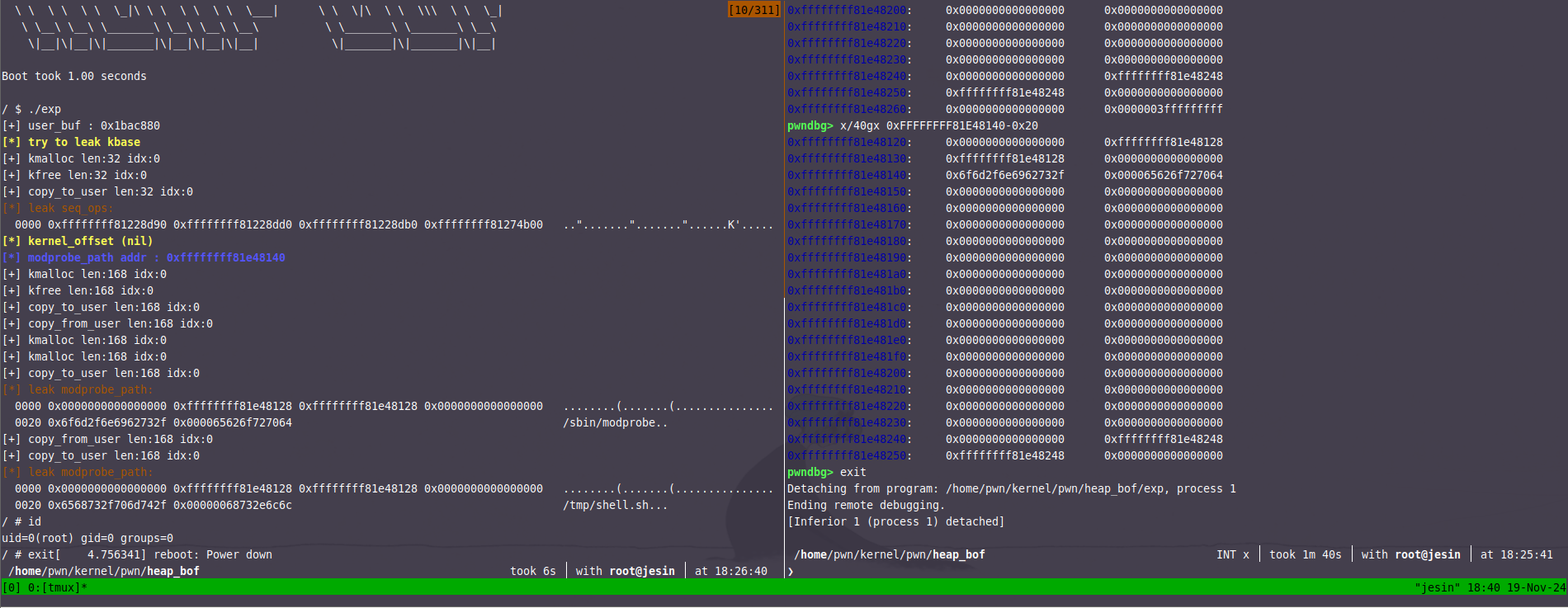
Linux kernel 堆溢出利用方法(三)
前言 本文我们通过我们的老朋友heap_bof来讲解Linux kernel中任意地址申请的其中一种比赛比较常用的利用手法modprobe_path(虽然在高版本内核已经不可用了但ctf比赛还是比较常用的)。在通过两道道近期比赛的赛题来讲解。 Arbitrary Address Allocation…...
对于GC方面,在使用Elasticsearch时要注意什么?
大家好,我是锋哥。今天分享关于【对于GC方面,在使用Elasticsearch时要注意什么?】面试题。希望对大家有帮助; 对于GC方面,在使用Elasticsearch时要注意什么? 1000道 互联网大厂Java工程师 精选面试题-Java…...

Xilinx PCIe高速接口入门实战(一)
引言:本文对Xilinx 7 Series Intergrated Block for PCI Express PCIe硬核IP进行简要介绍,主要包括7系列FPGA PCIe硬核资源支持、三IP硬核差异、PCIe硬核资源利用等相关内容。 1. 概述 1.1 7系列FPGA PCIe硬件资源支持 7系列FPGA对PCIe接口最大支持如…...

Flume 监控配置和实践
要解释 Flume 的监控机制,需要了解 Flume 是如何设计其监控架构的,以及如何将性能指标暴露给用户或集成工具。下面我将详细分解 Flume 的监控机制,从基础架构、实现原理到源码解析,并提供非专业人也能理解的通俗解释。 Flume 的监…...

深度学习基础1
目录 1. 深度学习的定义 2.神经网络 2.1. 感知神经网络 2.2 人工神经元 2.2.1 构建人工神经元 2.2.2 组成部分 2.2.3 数学表示 2.2.4 对比生物神经元 2.3 深入神经网络 2.3.1 基本结构 2.3.2 网络构建 2.3.3 全连接神经网络 3.神经网络的参数初始化 3.1 固定值初…...

《FPGA开发工具》专栏目录
《FPGA开发工具》专栏目录 1.Vivado开发 1.1使用相关 Vivado工程创建、仿真、下载与固化全流程 Vivado工程快速查看软件版本与器件型号 Vivado IP核的快速入门 官方手册和例程 Vivado中对已调用IP核的重命名 Vivado中增加源文件界面中各选项的解释 Vivado IP中Generate…...

李春葆《数据结构》-查找-课后习题代码题
一:设计一个折半查找算法,求查找到关键字为 k 的记录所需关键字的比较次数。假设 k 与 R[i].key 的比较得到 3 种情况,即 kR[i].key,k<R[i].key 或者 k>R[i].key,计为 1 次比较(在教材中讨论关键字比…...
树莓派智能画布:从Raspbian部署到NeoPixel灯光系统集成
1. 项目概述:打造一个会发光的智能画布如果你和我一样,对嵌入式硬件和创意编程的结合着迷,那么将一块普通的画布变成一个由代码控制的动态灯光装置,绝对是一件充满乐趣和成就感的事情。这个项目,我称之为“CompuCanvas…...
!)
仅1月Accepted!恭喜北大学者独作发表Nature子刊(IF 10.1)!
源自风暴统计网:一键统计分析与绘图的AI网站 引言 非协作者且是独作,用GBD 2023发表顶刊Nature是什么概念?来看今天这篇由北大学者发表的硬核文章!GBD 2023发文依然很顶,郑老师团队的专属科研训练营帮你实现从0到1的…...

国货视光标杆|欧普康视企业实力与DreamVision SL巩膜镜产品详解
一、企业简介欧普康视科技股份有限公司成立于2000年,由留美工程博士陶悦群创立,是国内深耕眼视光医疗器械领域的高新技术企业。企业专注于眼视光产品的自主研发、智能化生产与合规销售,同时配套全周期专业化眼健康服务,业务覆盖屈…...

WarcraftHelper终极指南:魔兽争霸3优化工具完整教程
WarcraftHelper终极指南:魔兽争霸3优化工具完整教程 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸III》的陈旧限制而烦…...

Minecraft服务器技能数据自动化管理:mcpskills-cli命令行工具实战指南
1. 项目概述与核心价值 最近在折腾一些Minecraft服务器的自动化管理,发现很多重复性的技能配置、权限同步工作特别耗时。手动去游戏里敲指令,或者对着配置文件一条条改,效率低还容易出错。就在这个当口,我发现了 alibiinformatio…...

如何3分钟精准定位Windows热键冲突:Hotkey Detective深度技术解析
如何3分钟精准定位Windows热键冲突:Hotkey Detective深度技术解析 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

AI驱动软件架构可视化:C4模型与生成式AI的融合实践
1. 项目概述:当企业架构图遇上生成式AI 最近在技术社区里,一个名为 codecentric/c4-genai-suite 的项目引起了我的注意。乍一看标题,它融合了两个看似不相关的领域:C4模型和生成式AI。C4模型,对于软件架构师和开发者…...
)
科研绘图避坑指南:手把手教你用Cytoscape处理String PPI数据(TSV文件导入、节点筛选与双环图制作)
科研绘图避坑指南:Cytoscape实战PPI网络分析与双环图设计 在生物医学研究中,蛋白互作网络(PPI)可视化是揭示分子机制的重要工具。许多研究者在使用String数据库和Cytoscape软件时会遇到数据导入失败、节点筛选困难、图形美化耗时等问题。本文将针对这些痛…...

4.【Python】Python3 注释
第一步:分析与整理 注释1. 注释的作用 不影响程序执行,只提高可读性。帮助理解代码逻辑,方便团队协作。2. 单行注释 以 # 开头,直到行末的所有内容均为注释。 # 这是一个注释 print("Hello, World!") # 这也是注释3. 多…...
开源清理工具OpenClearn:透明可控的数字垃圾管理方案
1. 项目概述:一个开源的“清洁工”如何重塑你的数字生活如果你和我一样,是个在数字世界里摸爬滚打了十几年的老鸟,那你电脑里肯定也有一堆“数字垃圾”。这些垃圾不是指那些过时的文件,而是那些你明明已经删除了,但操作…...