transformers microsoft--table-transformer 表格识别
一、安装包
pip install transformers
pip install torch
pip install SentencePiecepip install timm
pip install accelerate
pip install pytesseract pillow pandas
pip install tesseract下载模型:
https://huggingface.co/microsoft/table-transformer-structure-recognition/tree/main
https://huggingface.co/microsoft/table-transformer-detection/tree/main

二、安装tesseract-ocr
我这里用的windows
下载:tesseract-ocr-w64-setup-5.4.0.20240606.exe 安装
https://tesseract-ocr.github.io/tessdoc/Downloads.html
https://digi.bib.uni-mannheim.de/tesseract/ 【tesseract-ocr-w64-setup-5.4.0.20240606.exe】

添加环境变量:

三、准备图片
下载:https://download.csdn.net/download/xiaoxionglove/90063200

四、编写代码
from PIL import Image
from transformers import DetrImageProcessor
from transformers import TableTransformerForObjectDetectionimport torch
import matplotlib.pyplot as plt
import os
import psutil
import time
from transformers import DetrFeatureExtractor
feature_extractor = DetrFeatureExtractor()
import pandas as pdimport pytesseractmodel = TableTransformerForObjectDetection.from_pretrained("microsoft/table-transformer-detection")COLORS = [[0.000, 0.447, 0.741], [0.850, 0.325, 0.098], [0.929, 0.694, 0.125],[0.494, 0.184, 0.556], [0.466, 0.674, 0.188], [0.301, 0.745, 0.933]]def plot_results(pil_img, scores, labels, boxes):plt.figure(figsize=(16,10))plt.imshow(pil_img)ax = plt.gca()colors = COLORS * 100for score, label, (xmin, ymin, xmax, ymax),c in zip(scores.tolist(), labels.tolist(), boxes.tolist(), colors):ax.add_patch(plt.Rectangle((xmin, ymin), xmax - xmin, ymax - ymin,fill=False, color=c, linewidth=3))text = f'{model.config.id2label[label]}: {score:0.2f}'ax.text(xmin, ymin, text, fontsize=15,bbox=dict(facecolor='yellow', alpha=0.5))plt.axis('off')plt.show()def table_detection(file_path):image = Image.open(file_path).convert("RGB")width, height = image.sizeimage.resize((int(width *0.5), int(height *0.5)))feature_extractor = DetrImageProcessor()encoding = feature_extractor(image, return_tensors="pt")with torch.no_grad():outputs = model(**encoding)width, height = image.sizeresults = feature_extractor.post_process_object_detection(outputs, threshold=0.7, target_sizes=[(height, width)])[0]plot_results(image, results['scores'], results['labels'], results['boxes'])return results['boxes']ram_usage = psutil.Process(os.getpid()).memory_info().rss / 1024 / 1024print(f"ram usage : {ram_usage}")count = 0
root = "Detection_Images_Test/"for file in os.listdir(root):file_path = os.path.join(root, file)start_time = time.time()pred_bbox = table_detection(file_path)count += 1end_time = time.time()time_usage = end_time - start_timeram_usage = psutil.Process(os.getpid()).memory_info().rss / 1024 / 1024print(f"Iteration {count + 1} - RAM Usage: {ram_usage:.2f} MB, Time Usage: {time_usage:.2f} seconds")if count > 2:breakfile = 'img_test/PMC1064078_table_0.jpg.png'
image = Image.open(file).convert("RGB")
imagefrom huggingface_hub import hf_hub_download
from PIL import Imagefrom transformers import TableTransformerForObjectDetectionmodel = TableTransformerForObjectDetection.from_pretrained("microsoft/table-transformer-structure-recognition")def cell_detection(file_path):image = Image.open(file_path).convert("RGB")width, height = image.sizeimage.resize((int(width*0.5), int(height*0.5)))encoding = feature_extractor(image, return_tensors="pt")encoding.keys()with torch.no_grad():outputs = model(**encoding)target_sizes = [image.size[::-1]]results = feature_extractor.post_process_object_detection(outputs, threshold=0.6, target_sizes=target_sizes)[0]plot_results(image, results['scores'], results['labels'], results['boxes'])model.config.id2labelram_usage = psutil.Process(os.getpid()).memory_info().rss / 1024 / 1024print(f"ram usage : {ram_usage}")count = 0
root = "img_test/"
for file in os.listdir(root):file_path = os.path.join(root, file)start_time = time.time()cell_detection(file_path)count += 1end_time = time.time()time_usage = end_time - start_timeram_usage = psutil.Process(os.getpid()).memory_info().rss / 1024 / 1024print(f"Iteration {count + 1} - RAM Usage: {ram_usage:.2f} MB, Time Usage: {time_usage:.2f} seconds")if (count > 2):breakdef plot_results_specific(pil_img, scores, labels, boxes,lab):plt.figure(figsize=(16, 10))plt.imshow(pil_img)ax = plt.gca()colors = COLORS * 100for score, label, (xmin, ymin, xmax, ymax), c in zip(scores.tolist(), labels.tolist(), boxes.tolist(), colors):if label == lab:ax.add_patch(plt.Rectangle((xmin, ymin), xmax - xmin, ymax - ymin,fill=False, color=c, linewidth=3))text = f'{model.config.id2label[label]}: {score:0.2f}'ax.text(xmin, ymin, text, fontsize=15,bbox=dict(facecolor='yellow', alpha=0.5))plt.axis('off')plt.show()def draw_box_specific(image_path,labelnum):image = Image.open(image_path).convert("RGB")width, height = image.sizeencoding = feature_extractor(image, return_tensors="pt")with torch.no_grad():outputs = model(**encoding)results = feature_extractor.post_process_object_detection(outputs, threshold=0.7, target_sizes=[(height, width)])[0]plot_results_specific(image, results['scores'], results['labels'], results['boxes'],labelnum)def compute_boxes(image_path):image = Image.open(image_path).convert("RGB")width, height = image.sizeencoding = feature_extractor(image, return_tensors="pt")with torch.no_grad():outputs = model(**encoding)results = feature_extractor.post_process_object_detection(outputs, threshold=0.7, target_sizes=[(height, width)])[0]boxes = results['boxes'].tolist()labels = results['labels'].tolist()return boxes,labelsdef extract_table(image_path):image = Image.open(image_path).convert("RGB")boxes, labels = compute_boxes(image_path)cell_locations = []for box_row, label_row in zip(boxes, labels):if label_row == 2:for box_col, label_col in zip(boxes, labels):if label_col == 1:cell_box = (box_col[0], box_row[1], box_col[2], box_row[3])cell_locations.append(cell_box)cell_locations.sort(key=lambda x: (x[1], x[0]))num_columns = 0box_old = cell_locations[0]for box in cell_locations[1:]:x1, y1, x2, y2 = boxx1_old, y1_old, x2_old, y2_old = box_oldnum_columns += 1if y1 > y1_old:breakbox_old = boxheaders = []for box in cell_locations[:num_columns]:x1, y1, x2, y2 = boxcell_image = image.crop((x1, y1, x2, y2))new_width = cell_image.width * 4new_height = cell_image.height * 4cell_image = cell_image.resize((new_width, new_height), resample=Image.LANCZOS)cell_text = pytesseract.image_to_string(cell_image)headers.append(cell_text.rstrip())df = pd.DataFrame(columns=headers)row = []for box in cell_locations[num_columns:]:x1, y1, x2, y2 = boxcell_image = image.crop((x1, y1, x2, y2))new_width = cell_image.width * 4new_height = cell_image.height * 4cell_image = cell_image.resize((new_width, new_height), resample=Image.LANCZOS)cell_text = pytesseract.image_to_string(cell_image)if len(cell_text) > num_columns:cell_text = cell_text[:num_columns]row.append(cell_text.rstrip())if len(row) == num_columns:df.loc[len(df)] = rowrow = []return dfimage_path = 'img_test/PMC1112589_table_0.jpg'
draw_box_specific(image_path,1)
df = extract_table(image_path)
df.to_csv('data.csv', index=False)我们将图片中的表格识别并存到csv中


相关文章:
transformers microsoft--table-transformer 表格识别
一、安装包 pip install transformers pip install torch pip install SentencePiecepip install timm pip install accelerate pip install pytesseract pillow pandas pip install tesseract 下载模型: https://huggingface.co/microsoft/table-transformer-s…...

【Spark源码分析】规则框架-草稿
规则批:规则集合序列,由名称、执行策略、规则列表组成。一个规则批里使用一个执行规则。 执行策略 FixedPointOnce 规则: #mermaid-svg-1cvqR4xkYpMuAs77 {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px…...

迪米特原则的理解和实践
迪米特原则(Law of Demeter,简称LoD),也被称为最少知识原则(Least Knowledge Principle,LKP),是面向对象设计中的一个重要原则。其核心思想是:一个对象应该对其他对象有最…...
)
jQuery零基础入门速通(中)
大家好,我是小黄。 在上一篇文章中,我们初步了解了jQuery的基本概念、环境搭建、选择器、基本的DOM操作以及事件处理。接下来,我们将继续深入探讨jQuery的DOM操作和事件处理,以及一些实用的技巧和高级用法。 五、高级DOM操作 5…...

【设计模式系列】中介者模式(十八)
一、什么是中介者模式 中介者模式(Mediator Pattern)是一种行为型设计模式,其核心思想是通过一个中介者对象来封装一系列对象之间的交互,使这些对象不需要相互显式引用。中介者模式提供了一个中介层,用以协调各个对象…...

PDF版地形图矢量出现的问题
项目描述:已建风电场道路测绘项目,收集到的数据为PDF版本的地形图,图上标注了项目竣工时期的现状,之后项目对施工区域进行了复垦恢复地貌,现阶段需要准确的知道实际复垦修复之后的道路及其它临时用地的面积 解决方法&…...

小迪安全第四十二天笔记 简单的mysql注入 mysql的基础知识 用户管理数据库模式 mysql 写入与读取 跨库查询
前言 之前的安全开发我们学习了 php联动数据库的模式 ,这个模式是现在常用的模式 这一节来学习 如何 进行数据库的注入和数据库相关知识 1、了解数据库的结构 我们使用 navicate连接数据库之后看一下 一共四层结构 库 》表》字段》数据 这个层级关系…...

11.25.2024刷华为OD
文章目录 HJ76 尼科彻斯定理(观察题,不难)HJ77 火车进站(DFS)HJ91 走格子方法,(动态规划,递归,有代表性)HJ93 数组分组(递归)语法知识…...
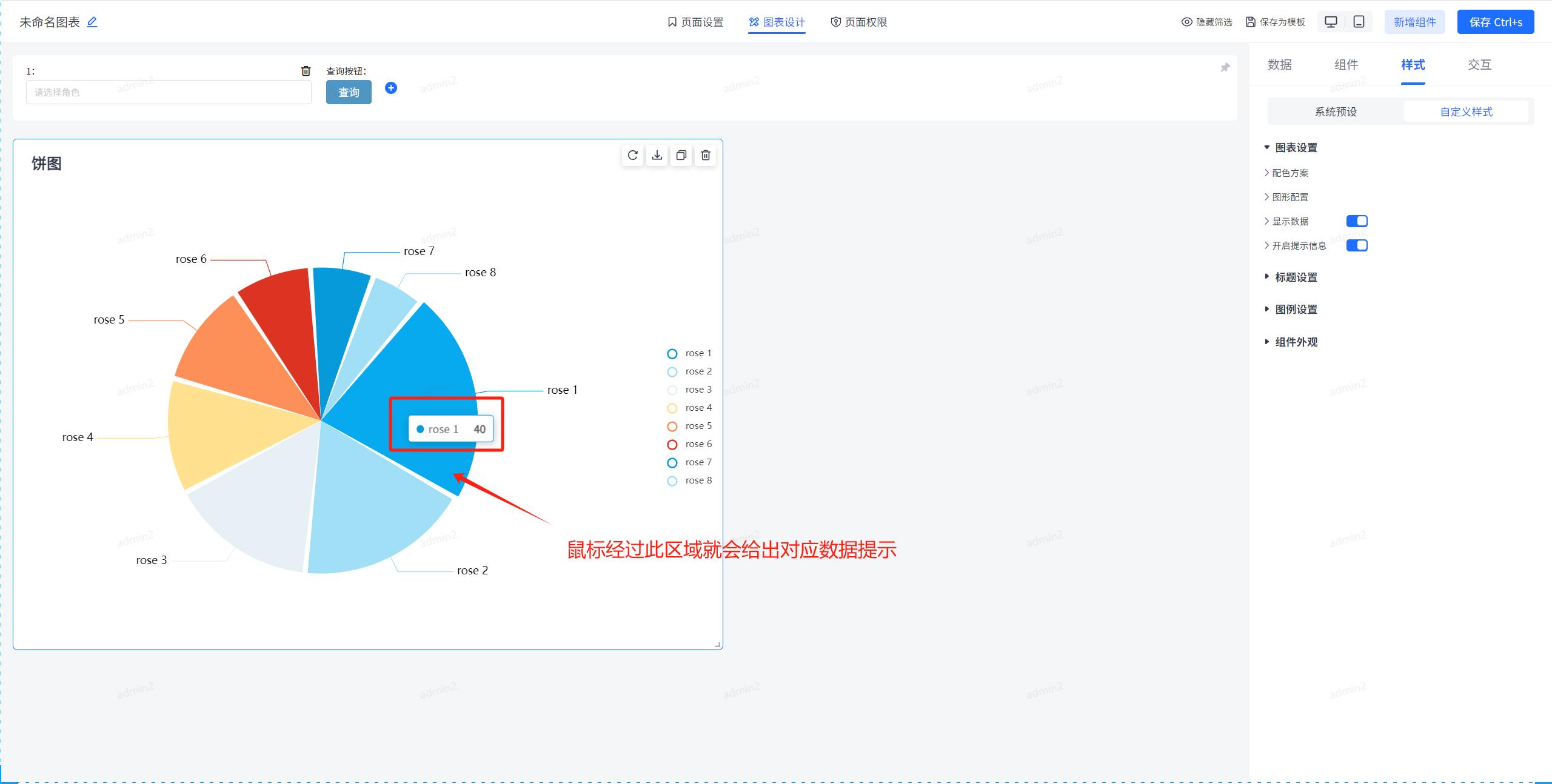
你真的会用饼图吗?JVS-智能BI饼图组件深度解析
在数据可视化的世界里,饼图是我们常见的一种可视化图形。在JVS-智能BI中提供了数据可视化饼图组件,接下来我通过这篇文章详细介绍,从配色方案到图形配置,从显示数据到提示信息,饼图的每一个细节配置。 饼图类图表概述…...

HarmonyOS Next 模拟器安装与探索
HarmonyOS 5 也发布了有一段时间了,不知道大家实际使用的时候有没有发现一些惊喜。当然随着HarmonyOS 5的更新也带来了很多新特性,尤其是 HarmonyOS Next 模拟器。今天,我们就来探索一下这个模拟器,看看它能给我们的开发过程带来什…...

医学机器学习:数据预处理、超参数调优与模型比较的实用分析
摘要 本文介绍了医学中的机器学习,重点阐述了数据预处理、超参数调优和模型比较的技术。在数据预处理方面,包括数据收集与整理、处理缺失值、特征工程等内容,以确保数据质量和可用性。超参数调优对模型性能至关重要,介绍了多种调…...

单片机知识总结(完整)
1、单片机概述 1.1. 单片机的定义与分类 定义: 单片机(Microcontroller Unit,简称MCU)是一种将微处理器、存储器(包括程序存储器和数据存储器)、输入/输出接口和其他必要的功能模块集成在单个芯片上的微型…...

【C++】auto和decltype类型推导关键字
1.C11关键字 auto和decltype是C11引入的关键字,负责类型的推导。所有不同的是: auto可直接用来定义变量,编译器会自动推导出变量的类型。decltype是推导出一个操作数的类型,然后用这个类型再去定义。 2.两者区别 尽管两者都是宏…...

OGRE 3D----3. OGRE绘制自定义模型
在使用OGRE进行开发时,绘制自定义模型是一个常见的需求。本文将介绍如何使用OGRE的ManualObject类来创建和绘制自定义模型。通过ManualObject,开发者可以直接定义顶点、法线、纹理坐标等,从而灵活地构建各种复杂的几何体。 Ogre::ManualObject 是 Ogre3D 引擎中的一个类,用…...

ARM + Linux 开发指南
随想:想写一个系列来讲如何嵌入式开发,然后能形成一个知识体系,帮助那些刚刚做嵌入开发的同学们. 1. ARM Linux从开机到Linux完全启动的流程和代码分析 ARM Linux从开机到完全启动的流程与代码分析 ARM Linux的启动过程主要涉及从设备上电开始,到Linux内核完全启动并进入…...

facebook欧洲户开户条件有哪些又有何优势?
在当今数字营销时代,Facebook广告已成为企业推广产品和服务的重要渠道。而为了更好地利用这一平台,广告主们需要理解不同类型的Facebook广告账户。Facebook广告账户根据其属性可分为多种类型,包括个人广告账户、企业管理(BM&#…...
二刷第三十一天 | 1049. 最后一块石头的重量 II、494. 目标和、*474. 一和零)
算法训练(leetcode)二刷第三十一天 | 1049. 最后一块石头的重量 II、494. 目标和、*474. 一和零
刷题记录 1049. 最后一块石头的重量 II*494. 目标和二维数组滚动数组 *474. 一和零 1049. 最后一块石头的重量 II leetcode题目地址 本题与416. 分割等和子集类似。依旧是01背包问题,本题尽可能将石头分为相等(相近)的两堆,然后…...

软件测试丨Pytest生命周期与数据驱动
Pytest的生命周期概述 Pytest 是一个强大的测试框架,提供了丰富的特性来简化测试执行。它的生命周期包括多个阶段,涉及从准备测试、执行测试到报告结果的完整流程。因此,理解Pytest的生命周期将帮助我们更好地设计和管理测试用例。 开始阶段…...
Figma入门-原型交互
Figma入门-原型交互 前言 在之前的工作中,大家的原型图都是使用 Axure 制作的,印象中 Figma 一直是个专业设计软件。 最近,很多产品朋友告诉我,很多原型图都开始用Figma制作了,并且很多组件都是内置的,对…...

网络安全防范技术
1 实践内容 1.1 安全防范 为了保障"信息安全金三角"的CIA属性、即机密性、完整性、可用性,信息安全领域提出了一系列安全模型。其中动态可适应网络安全模型基于闭环控制理论,典型的有PDR和P^2DR模型。 1.1.1 PDR模型 信息系统的防御机制能抵抗…...

Audacity音频编辑教程:免费开源音频处理软件的完整使用指南
Audacity音频编辑教程:免费开源音频处理软件的完整使用指南 【免费下载链接】audacity Audio Editor 项目地址: https://gitcode.com/GitHub_Trending/au/audacity Audacity是一款功能强大的免费开源音频编辑软件,支持录音、剪辑、混音和音频效果…...

iOSDeviceSupport终极指南:如何快速解决Xcode设备支持文件缺失问题
iOSDeviceSupport终极指南:如何快速解决Xcode设备支持文件缺失问题 【免费下载链接】iOSDeviceSupport All versions of iOS Device Support 项目地址: https://gitcode.com/gh_mirrors/ios/iOSDeviceSupport 你是否曾经在iOS开发中遇到过这样的困扰…...
)
手把手教你用MOS管搭建防反接电路:从原理图到PCB布局的避坑指南(以立创EDA为例)
从零构建MOS管防反接电路:立创EDA实战全流程解析 电源反接是电子设计中最常见的"低级错误"之一,却可能造成毁灭性后果。想象一下:你花费数周完成的智能家居控制器,因为电池装反而瞬间烧毁主控芯片——这种场景在创客社区…...

Perplexity接入Google Scholar的5大避坑指南:实测失效率下降87%的权威配置方案
更多请点击: https://intelliparadigm.com 第一章:Perplexity接入Google Scholar的整合背景与价值定位 学术信息检索正经历从“关键词匹配”向“语义理解可信溯源”的范式跃迁。Perplexity 作为基于大语言模型的实时问答引擎,其核心优势在于…...

从V100到A100:手把手教你理解Ampere架构的7个关键性能优化点
从V100到A100:手把手教你理解Ampere架构的7个关键性能优化点 如果你正在使用NVIDIA V100进行深度学习训练或高性能计算,那么升级到A100可能已经在你的考虑范围内。但这次升级究竟能带来多少实际性能提升?本文将带你深入Ampere架构的7个核心优…...

CTF出题人视角:我是如何设计ctfshow F5杯那些“脑洞大开”的MISC题的
CTF出题人视角:如何设计令人拍案叫绝的MISC赛题 在CTF竞赛中,MISC(杂项)题目往往是最能体现创意与思维碰撞的领域。作为F5杯的核心出题人之一,我想分享几个设计"脑洞题"的底层逻辑——这些题目后来被参赛选手…...

关于python中打开文件,以及可能错误,介绍
**该mode是基于open()函数里参数的调整** 错误代码 f r"C:\dj\dw1.txt" b f.read(c) print(b) f.close() 正确代码 f open(r"C:\dj\dw1.txt") s f.read() print(s) f.close()open()函数需要后面的打开路径,r/R表示该代码的的原意 mode…...

OpenClaw微信公众号插件wemp v2:双Agent路由与混合知识库实战
1. 项目概述:一个为OpenClaw设计的微信公众号插件如果你正在寻找一个能够将你的AI助手能力无缝接入微信公众号,实现自动化客服、智能问答甚至更复杂交互的解决方案,那么你找对地方了。wemp(WeChat MP Plugin)正是这样一…...

深度解析开源AI工具库:OpenAI API封装库的设计与实战应用
1. 项目概述:一个开源AI工具库的深度解构最近在GitHub上看到一个名为“anasfik/openai”的项目,这个标题乍一看有点意思。它不像官方SDK那样直接叫“openai”,而是带上了个人或组织的命名空间前缀“anasfik/”。这通常意味着这是一个第三方封…...
)
Gemini Deep Research调用失败?5类报错代码详解+官方未公开的API绕过方案(限时技术内参)
更多请点击: https://intelliparadigm.com 第一章:Gemini Deep Research功能怎么用 Gemini Deep Research 是 Google 推出的面向专业研究者的增强型推理能力模块,专为长上下文分析、跨文档信息整合与假设验证设计。启用该功能需通过 Gemini …...