RNN模型文本预处理--数据增强方法
数据增强方法
数据增强是自然语言处理(NLP)中常用的一种技术,通过生成新的训练样本来扩充数据集,从而提高模型的泛化能力和性能。回译数据增强法是一种常见的数据增强方法,特别适用于文本数据。
回译数据增强法
定义
- 通过将一种语言翻译成不同的语言,再转换回来的一种方式。例如,将中文文本翻译成英文,然后再将英文翻译回中文。
优势
- 操作简便:只需要使用现有的翻译工具即可实现。
- 获得新语料质量高:翻译后的文本通常能够保持较高的语义一致性,且语法结构合理。
目的
- 增加数据集:通过生成新的训练样本来扩展数据集,从而提高模型的泛化能力。
存在的问题
- 高重复率:在短文本回译过程中,新语料与原语料可能存在很高的重复率,这并不能有效增大样本的特征空间。
高重复率解决办法
- 进行连续的多语言翻译:例如,中文→韩文→日语→英文→中文。最多只采用3次连续翻译,更多的翻译次数将产生效率低下、语义失真等问题。
使用工具
- ChatGPT:可以利用 ChatGPT 进行多语言翻译。
- 有道翻译接口:基于有道翻译接口进行多语言翻译。
具体步骤
-
准备原始数据
- 收集并准备好需要增强的原始文本数据。
-
选择翻译工具
- 可以选择 ChatGPT 或者有道翻译接口等工具进行翻译。
-
进行多语言翻译
- 将原始文本翻译成另一种语言,再从该语言翻译回原始语言。
- 为了减少重复率,可以进行多次连续翻译,但不超过3次。
-
合并新旧数据
- 将生成的新文本与原始文本合并,形成扩增后的数据集。
示例代码
以下是使用有道翻译接口进行回译数据增强的示例代码:
import requests
import time# 有道翻译API
def translate(text, from_lang, to_lang):url = "http://fanyi.youdao.com/translate"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}data = {'doctype': 'json','type': f'{from_lang}-{to_lang}','i': text}response = requests.post(url, headers=headers, data=data)result = response.json()return result['translateResult'][0][0]['tgt']# 回译数据增强
def back_translation(text, lang_sequence):for i in range(len(lang_sequence) - 1):text = translate(text, lang_sequence[i], lang_sequence[i + 1])time.sleep(1) # 防止请求过于频繁return text# 示例
original_text = "我喜欢编程。"
lang_sequence = ['zh', 'en', 'ko', 'ja', 'zh']
augmented_text = back_translation(original_text, lang_sequence)
print("Original Text:", original_text)
print("Augmented Text:", augmented_text)
使用 ChatGPT 进行回译
如果你使用的是 ChatGPT API,可以通过以下方式实现回译:
import openai# 设置 OpenAI API 密钥
openai.api_key = 'your_openai_api_key'# 使用 ChatGPT 进行翻译
def translate_with_chatgpt(text, from_lang, to_lang):prompt = f"Translate the following {from_lang} text to {to_lang}: {text}"response = openai.Completion.create(engine="text-davinci-003",prompt=prompt,max_tokens=100)return response.choices[0].text.strip()# 回译数据增强
def back_translation_with_chatgpt(text, lang_sequence):for i in range(len(lang_sequence) - 1):text = translate_with_chatgpt(text, lang_sequence[i], lang_sequence[i + 1])time.sleep(1) # 防止请求过于频繁return text# 示例
original_text = "我喜欢编程。"
lang_sequence = ['Chinese', 'English', 'Korean', 'Japanese', 'Chinese']
augmented_text = back_translation_with_chatgpt(original_text, lang_sequence)
print("Original Text:", original_text)
print("Augmented Text:", augmented_text)
总结
回译数据增强法是一种简单且有效的方法,通过多语言翻译来生成新的训练样本。虽然存在一定的重复率问题,但通过连续多语言翻译可以有效缓解这一问题。
相关文章:

RNN模型文本预处理--数据增强方法
数据增强方法 数据增强是自然语言处理(NLP)中常用的一种技术,通过生成新的训练样本来扩充数据集,从而提高模型的泛化能力和性能。回译数据增强法是一种常见的数据增强方法,特别适用于文本数据。 回译数据增强法 定义…...

maven 中<packaging>pom</packaging>配置使用
在 Maven 项目的 pom.xml 文件中, 元素用于指定项目的打包类型。默认情况下,如果 元素没有被显式定义,Maven 会假设其值为 jar。但是,当您设置 pom 时,这意味着该项目是一个 POM(Project Object Model&…...

【Python中while循环】
一、深拷贝、浅拷贝 1、需求 1)拷贝原列表产生一个新列表 2)想让两个列表完全独立开(针对改操作,读的操作不改变) 要满足上述的条件,只能使用深拷贝 2、如何拷贝列表 1)直接赋值 # 定义一个…...

【深度学习】服务器常见命令
1、虚拟环境的安装位置 先进入虚拟环境 which python2、升序查看文件内容 ls -ltr3、查看服务器主机空间使用情况 df -hdf -h .4、查看本地空间使用情况 du -sh ./*du -sh * | sort -nr5、查找并删除进程 # 查找 ps aux# 删除 kill -KILL pid6、查看服务器配置 lscpuuna…...

技术分析模板
文章目录 概要整体架构流程技术名词解释技术细节小结 概要 提示:这里可以添加技术概要 例如: openAI 的 GPT 大模型的发展历程。 整体架构流程 提示:这里可以添加技术整体架构 例如: 在语言模型中,编码器和解码器…...

python:文件操作
一、文件路径 在Windows系统中,每个磁盘都有自己的根目录,用分区名加反斜杠来表示。我们定位文件的位置有两种方法,一种是绝对路径,另一种是相对路径。绝对路径是从根目录出发的路径,路径中的每个路径之间用反斜杠来分…...

Nginx和Apache有什么异同?
Nginx和Apache都是广泛使用的Web服务器软件,它们各自具有独特的特点和优势,适用于不同的应用场景。以下是关于Nginx和Apache的不同、相同以及使用区别的详细分析: 一、不同点 资源占用与并发处理能力: Nginx使用更少的内存和CPU资…...

泰州榉之乡全托机构探讨:自闭症孩子精细动作训练之法
当发现自闭症孩子精细动作落后时,家长们往往会感到担忧和困惑。那么,自闭症孩子精细动作落后该如何训练呢?今天,泰州榉之乡全托机构就来为大家详细解答。 榉之乡大龄自闭症托养机构在江苏、广东、江西等地都有分校,一直…...

Cookie跨域
跨域:跨域名(IP) 跨域的目的是共享Cookie。 session操作http协议,每次既要request,也要response,cookie在创建的时候会产生一个字符串然后随着response返回。 全网站的各个页面都会带着登陆的时候的cookie …...

qt QGraphicsPolygonItem详解
1、概述 QGraphicsPolygonItem是Qt框架中QGraphicsItem的一个子类,它提供了一个可以添加到QGraphicsScene中的多边形项。通过QGraphicsPolygonItem,你可以定义和显示一个多边形,包括其填充颜色、边框样式等属性。QGraphicsPolygonItem支持各…...

“harmony”整合不同平台的单细胞数据之旅
其实在Seurat v3官方网站的Vignettes中就曾见过该算法,但并没有太多关注,直到看了北大张泽民团队在2019年10月31日发表于Cell的《Landscap and Dynamics of Single Immune Cells in Hepatocellular Carcinoma》,为了同时整合两类数据…...
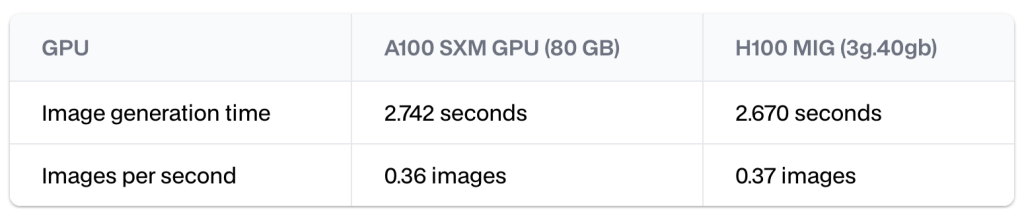
如何构建一个可扩展、全球可访问的 GenAI 架构?
你有没有尝试过使用人工智能生成图像? 如果你尝试过,你就会知道,一张好的图像的关键在于一个详细具体的提示。 我不擅长这种详细的视觉提示,所以我依赖大型语言模型来生成详细的提示,然后使用这些提示来生成出色的图像…...

QT实战--qt各种按钮实现
本篇介绍qt一些按钮的实现,包括正常按钮;带有下拉箭头的按钮的各种实现;按钮和箭头两部分分别响应;图片和按钮大小一致;图片和按钮大小不一致的处理;文字和图片位置的按钮 效果图如下: 详细实现…...

RNN And CNN通识
CNN And RNN RNN And CNN通识一、卷积神经网络(Convolutional Neural Networks,CNN)1. 诞生背景2. 核心思想和原理(1)基本结构:(2)核心公式:(3)关…...

生产环境中:Flume 与 Prometheus 集成
在生产环境中,将 Apache Flume 与 Prometheus 集成的过程,需要借助 JMX Exporter 或 HTTP Exporter 来将 Flume 的监控数据转换为 Prometheus 格式。以下是详细的实现方法,连同原理和原因进行逐步解释,让刚接触的初学者也能完成集…...

求平均年龄
求平均年龄 C语言代码C 代码Java代码Python代码 💐The Begin💐点点关注,收藏不迷路💐 班上有学生若干名,给出每名学生的年龄(整数),求班上所有学生的平均年龄,保留到小数…...
——AP_Arming_Sub)
Ardusub源码剖析(1)——AP_Arming_Sub
代码 AP_Arming_Sub.h #pragma once#include <AP_Arming/AP_Arming.h>class AP_Arming_Sub : public AP_Arming { public:AP_Arming_Sub() : AP_Arming() { }/* Do not allow copies */CLASS_NO_COPY(AP_Arming_Sub);bool rc_calibration_checks(bool display_failure)…...

【NLP 2、机器学习简介】
人生的苦难不过伏尔加河上的纤夫 —— 24.11.27 一、机器学习起源 机器学习的本质 —— 找规律 通过一定量的训练样本找到这些数据样本中所蕴含的规律 规律愈发复杂,机器学习就是在其中找到这些的规律,挖掘规律建立一个公式,导致对陌生的数…...

数据结构与算法——N叉树(自学笔记)
本文参考 N 叉树 - LeetBook - 力扣(LeetCode)全球极客挚爱的技术成长平台 遍历 前序遍历:A->B->C->E->F->D->G后序遍历:B->E->F->C->G->D->A层序遍历:A->B->C->D->…...

【趣味升级版】斗破苍穹修炼文字游戏HTML,CSS,JS
目录 图片展示 开始游戏 手动升级(满100%即可升级) 升级完成,即可解锁打怪模式 新增功能说明: 如何操作: 完整代码 实现一个简单的斗破苍穹修炼文字游戏,你可以使用HTML、CSS和JavaScript结合来构建…...

深入Acid引擎架构:模块化设计与现代C++17的最佳实践指南
深入Acid引擎架构:模块化设计与现代C17的最佳实践指南 【免费下载链接】Acid A high speed C17 Vulkan game engine 项目地址: https://gitcode.com/gh_mirrors/ac/Acid Acid引擎是一个基于Vulkan API的高性能C17游戏引擎,采用先进的模块化架构设…...

AI绘画工作流自动化:从NovelAI到Pixiv的Semi-Auto工具实战
1. 项目概述:从手动到自动,解放AI绘画生产力的桌面利器如果你和我一样,是个深度沉迷于AI绘画的创作者,那你一定经历过这样的痛苦:在NovelAI的WebUI里,吭哧吭哧地调好一组参数,生成一张图&#x…...

CANN昇腾算子开发套件
SetSingleOutputShape 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://g…...

如何快速解密网易云音乐NCM文件:5步完成格式转换的完整指南
如何快速解密网易云音乐NCM文件:5步完成格式转换的完整指南 【免费下载链接】ncmdump ncmdump - 网易云音乐NCM转换 项目地址: https://gitcode.com/gh_mirrors/ncmdu/ncmdump 还在为网易云音乐的NCM加密格式烦恼吗?想要在任意播放器上畅听你收藏…...

AI智能体如何通过区块链钱包实现自动化加密云存储
1. 项目概述:当AI智能体遇上加密云存储如果你正在使用OpenClaw这类AI智能体平台,并且头疼于如何让它们自动、安全地处理云端数据——比如备份对话记录、上传生成的文件,或者管理需要付费的API服务——那么你很可能需要一个既懂区块链支付、又…...

Godot 4中构建真实水体渲染:从PBR原理到性能优化实践
1. 项目概述:从像素到波光,在Godot中构建真实水体如果你正在用Godot引擎开发一款开放世界游戏、一个宁静的模拟场景,或者任何需要水体表现的项目,那么“水”的质量几乎直接决定了场景的沉浸感上限。静态的、像果冻一样的平面贴图早…...

AXI4协议实战:从零构建一个支持突发传输的从机接口
1. AXI4协议基础与从机接口设计概述 AXI4协议作为AMBA总线家族中最核心的成员,已经成为现代SoC设计中事实上的标准互联规范。我第一次接触AXI4是在2015年设计图像处理芯片时,当时为了连接DMA控制器和DDR控制器,不得不硬着头皮研究这个看似复杂…...

RPC的了解
文章目录1. RPC的概述2. RPC的核心工作原理3. RPC与 HTTP 的区别4. RPC 框架的核心功能5. 常见的RPC框架对比6. 什么时候考虑引入RPC7. 选型8. Dubbo1)概述2. Dubbo核心功能3. Dubbo 具体使用1. RPC的概述 RPC(Remote Procedure Call,远程过程…...

Dify-Flow:构建复杂AI工作流的流程编排引擎设计与实现
1. 项目概述:当Dify遇上Flow,一个面向开发者的AI应用编排新范式如果你最近在折腾AI应用开发,特别是想把大语言模型(LLM)的能力集成到自己的业务流程里,那你大概率听说过Dify。它作为一个开源的LLM应用开发平…...

AI不是功能叠加,而是范式重铸:揭秘奇点大会首次披露的“AI原生产品熵减评估矩阵”及4类高危反模式
更多请点击: https://intelliparadigm.com 第一章:AI不是功能叠加,而是范式重铸:从工具思维到原生心智的跃迁 当开发者仍在用“给CMS加个AI摘要按钮”的方式理解大模型时,真正的变革早已发生在架构底层——AI正从可插…...