如何从 Hugging Face 数据集中随机采样数据并保存为新的 Arrow 文件
如何从 Hugging Face 数据集中随机采样数据并保存为新的 Arrow 文件
在使用 Hugging Face 的数据集进行模型训练时,有时我们并不需要整个数据集,尤其是当数据集非常大时。为了节省存储空间和提高训练效率,我们可以从数据集中随机采样一部分数据,并将其保存为新的 Arrow 文件格式。本文将介绍如何通过代码实现这一过程,并解释如何计算文件大小,以便在 dataset_info.json 文件中记录文件信息,方便后续训练使用。
1. 背景介绍
Hugging Face 提供的 datasets 库支持直接加载和操作 Arrow 格式的数据集。Arrow 是一个高效的列式数据格式,适用于大规模数据处理和分析。其高效性体现在对内存的友好支持和读取速度上,这使得它在深度学习中得到广泛应用。
然而,整个数据集可能会非常庞大,尤其是在进行大规模模型训练时。为了提高效率和减少内存占用,通常我们只需要数据集的一部分。在这种情况下,随机采样并保存为一个新的 Arrow 文件是一个很好的解决方案。
2. 代码实现
以下是从 Hugging Face 数据集中随机采样 1000 条数据,并将其保存为新的 Arrow 文件的代码:
from datasets import Dataset, DatasetDict
import os# 加载原始 Arrow 文件
dataset = Dataset.from_file("/.cache/huggingface/datasets/allenai___tulu-3-sft-mixture/default/0.0.0/55e9fd6d41c3cd1a98270dff07557bc2a1e1ba91/tulu-3-sft-mixture-train-00000-of-00001.arrow"
)# 采样 1000 条数据(随机采样)
sampled_dataset = dataset.shuffle(seed=42).select(range(1000))# 保存为新的 Arrow 文件
output_path = "/.cache/huggingface/datasets/allenai_test"
sampled_dataset.save_to_disk(output_path)# 计算文件大小
file_size = sum(os.path.getsize(os.path.join(dp, f)) for dp, dn, filenames in os.walk(output_path) for f in filenames
)# 打印采样结果和大小
print(f"采样数据集保存路径: {output_path}")
print(f"文件大小: {file_size / (1024 ** 2):.2f} MB") # 转换为 MB
print(file_size)
代码步骤解释:
-
加载原始 Arrow 文件:我们通过
Dataset.from_file()方法加载原始的 Arrow 文件。这个文件通常较大,包含了整个数据集的内容。 -
随机采样数据:使用
dataset.shuffle(seed=42).select(range(1000))随机采样出 1000 条数据。shuffle()方法随机打乱数据集,select()方法选择数据集的前 1000 条记录。 -
保存为新文件:通过
save_to_disk()方法将采样后的数据保存为新的 Arrow 文件。这时,我们可以将这个小型的数据集用于模型训练,而不需要加载整个大数据集。 -
计算文件大小:通过遍历文件夹的方式,使用
os.path.getsize()获取保存的 Arrow 文件的大小。计算结果以 MB 为单位输出,便于理解文件的存储需求。
3. 文件大小和 dataset_info.json
保存采样数据时,计算文件大小是非常重要的。这是因为在 Hugging Face 的数据集格式中,dataset_info.json 文件记录了数据集的基本信息,包括数据集的大小、特征、列数等。在训练时,Hugging Face 会根据 dataset_info.json 文件的信息来进行数据加载和管理。确保文件大小准确,可以帮助在加载数据集时正确管理内存和硬盘空间。
下面是新的dataset_info.json文件内容,需要改的地方有
“num_bytes”: 3781998,
“num_examples”: 1000,
“download_size”: 3781998,
“dataset_size”: 3781998,
“size_in_bytes”: 3781998
这些,这里的3781998就是上面的file_size,num_examples是上面提到的采样1000条数据。
{"description": "A sampled version of tulu-3-sft-mixture dataset with 1000 examples.","citation": "","homepage": "","license": "","features": {"id": {"dtype": "string","_type": "Value"},"messages": [{"content": {"dtype": "string","_type": "Value"},"role": {"dtype": "string","_type": "Value"}}],"source": {"dtype": "string","_type": "Value"}},"builder_name": "parquet","dataset_name": "tulu-3-sft-mixture","config_name": "default","version": {"version_str": "0.0.0","major": 0,"minor": 0,"patch": 0},"splits": {"train": {"name": "train","num_bytes": 3781998,"num_examples": 1000,"shard_lengths": [1000],"dataset_name": "tulu-3-sft-mixture"}},"download_checksums": {},"download_size": 3781998,"dataset_size": 3781998,"size_in_bytes": 3781998
}然后记得把之前的数据集文件夹改名为其他,比如改成这里的allenai___tulu-3-sft-mixture1,然后将新的数据集放到/.cache/huggingface/datasets/allenai___tulu-3-sft-mixture/default/0.0.0/55e9fd6d41c3cd1a98270dff07557bc2a1e1ba91/这个路径下,请注意,这个路径应该与hf下载下来的路径完全相同。这个是新建的,可以使用LInux命令来新建:mkdir命令后面记得加-p参数
mkdir -p /.cache/huggingface/datasets/allenai___tulu-3-sft-mixture/default/0.0.0/55e9fd6d41c3cd1a98270dff07557bc2a1e1ba91/

如下图所示:需要在这里放入新的arrow文件(只需要放自己的那1000条数据的arrow即可,其他cache开头的arrow文件是系统自己生成的,不用管)和dataset_info.json文件(这个是需要按照上面更改后的,不能用之前的),然后arrow文件记得改名:tulu-3-sft-mixture-train-00000-of-00001.arrow,这里记得按照原始文件中的arrow文件命名格式,比如原来的是tulu-3-sft-mixture-train-00000-of-00006.arrow,tulu-3-sft-mixture-train-00001-of-00006.arrow这样,后面的00006是分块的个数,由于我们只有一个arrow文件,后面的00006应该改为00001。

4. 如何使用新的 Arrow 文件进行训练
在 Hugging Face 上使用数据集时,我们通常指定一个数据集路径,比如:
--dataset_mixer_list allenai/tulu-3-sft-mixture 1.0
这个参数指定了使用某个数据集进行训练。当我们使用采样的 Arrow 文件时,文件路径应该指向我们保存的采样文件(这里由于我们用新的arrow覆盖掉了原来的文件,所以不用指定新的路径,默认即可),而无需更改 --dataset_mixer_list 参数。这样,我们就可以利用数据集的一部分进行训练,而不需要更改 Hugging Face 数据集的整体配置。
5. 下载后的文件为何变成 Arrow 格式
在使用 Hugging Face 的数据集时,很多时候我们会下载数据集并看到它是以 .arrow 格式存储的。这是因为 Arrow 格式在性能和存储上优于其他格式,尤其是在大规模数据集的处理过程中,能够提供更高效的内存和磁盘使用。下载到本地后,文件会以 Arrow 格式存储,便于后续使用和处理。
6. 结论
通过从 Hugging Face 数据集中随机采样一部分数据并保存为新的 Arrow 文件,我们可以更高效地进行模型训练,特别是当数据集庞大时。通过计算文件大小并更新 dataset_info.json 文件,我们可以确保训练过程中数据管理的准确性。
这种方法不仅适用于大数据集,也为需要快速原型设计或进行小规模实验的研究人员提供了便利。
相关文章:
如何从 Hugging Face 数据集中随机采样数据并保存为新的 Arrow 文件
如何从 Hugging Face 数据集中随机采样数据并保存为新的 Arrow 文件 在使用 Hugging Face 的数据集进行模型训练时,有时我们并不需要整个数据集,尤其是当数据集非常大时。为了节省存储空间和提高训练效率,我们可以从数据集中随机采样一部分数…...
)
11 设计模式之代理模式(送资料案例)
一、什么是代理模式? 在现实生活中,我们常常遇到这样的场景:由于某些原因,我们可能无法亲自完成某个任务,便会委托他人代为执行。在设计模式中,代理模式 就是用来解决这种“委托”问题的࿰…...

MongoDB聚合操作
1.聚合操作 聚合操作处理数据记录并返回计算结果。聚合操作组值来自多个文档,可以对分组数据执行各种操作以返回单个结果。聚合操作包含三类:单一作用聚合、聚合管道、MapReduce。 单一作用聚合:提供了对常见聚合过程的简单访问,…...
第二十三周周报:High-fidelity Person-centric Subject-to-Image Synthesis
目录 摘要 Abstract TDM SDM SNF 测试时的人物细节捕捉 主要贡献 总结 摘要 本周阅读了一篇2024年CVPR的关于高保真度、以人物为中心的图像合成方法的论文:High-fidelity Person-centric Subject-to-Image Synthesis。该论文提出了一种名为Face-diffuser的…...

Cesium 与 Leaflet:地理信息可视化技术比较
在现代地理信息系统(GIS)和空间数据可视化领域,Cesium 和 Leaflet 是两种非常常见的地理可视化库,它们各自适用于不同的应用场景。Cesium 专注于三维地球视图和复杂空间分析,而 Leaflet 则注重轻量级的二维地图展示。本文将对这两种技术进行详细的对比,帮助开发者根据具体…...

Linux 服务器使用指南:诞生与演进以及版本(一)
一、引言 在当今信息技术的浪潮中,Linux 操作系统无疑是一个关键的支柱😎。无论是在服务器管理、软件开发还是大数据处理领域,Linux 都以其卓越的适应性和优势脱颖而出👍。然而,对于许多新手而言,Linux 系统…...

龙蜥 Linux 安装 JDK
龙蜥 Linux 安装 JDK 下载安装解压到目标路径设置环境变量直接在启动脚本中临时设置 参考资料 下载 这个就不赘述了,参考资料中的另外两篇安装帖,都有。 如果不能上网,也可以去内网其他之前装过JDK的服务器,直接复制过来。 tar …...
)
Python小白语法基础20(模块与包)
0) 参考文章 python的模块(module)、包(package)及pip_python package-CSDN博客Python之函数、模块、包库_python函数、模块和包-CSDN博客Python函数模块自定义封装及模块嵌套导入(手把手教程)_python如何封装一个模块-CSDN博客 1) 模块与包说明 软件…...

详解 Qt QtPDF之QPdfPageNavigator 页面跳转
文章目录 前言头文件: 自 Qt 6.4 起继承自: 属性backAvailable : const boolcurrentLocation : const QPointFcurrentPage : const intcurrentZoom : const qrealforwardAvailable : const bool 公共函数QPdfPageNavigator(QObject *parent)virtual ~QPd…...

通俗易懂:序列标注与命名实体识别(NER)概述及标注方法解析
目录 一、序列标注(Sequence Tagging)二、命名实体识别(Named Entity Recognition,NER)**命名实体识别的作用****命名实体识别的常见实体类别** : 三、标签类型四、序列标注的三种常见方法1. **BIO…...

【C语言】二叉树(BinaryTree)的创建、3种递归遍历、3种非递归遍历、结点度的实现
代码主要实现了以下功能: 二叉树相关数据结构定义 定义了二叉树节点结构体 BiTNode,包含节点数据值(字符类型)以及指向左右子树的指针。 定义了顺序栈结构体 SqStack,用于存储二叉树节点指针,实现非递归遍历…...

2024年11月文章一览
2024年11月编程人总共更新了21篇文章: 1.2024年10月文章一览 2.《使用Gin框架构建分布式应用》阅读笔记:p307-p392 3.《使用Gin框架构建分布式应用》阅读笔记:p393-p437 4.《使用Gin框架构建分布式应用》读后感 5.《Django 5 By Example…...

重生之我在异世界学编程之C语言:二维数组篇
大家好,这里是小编的博客频道 小编的博客:就爱学编程 很高兴在CSDN这个大家庭与大家相识,希望能在这里与大家共同进步,共同收获更好的自己!!! 本文目录 引言正文一 二维数组的创建1. 二维数组的…...

和鲸科技创始人CEO范向伟出席首届工业智算产业发展研讨会,共话 AI 创新与产业化落地
11 月 22 日,首届工业智算产业发展研讨会在中国工业互联网研究院召开。工业和信息化部党组成员、副部长单忠德,国家信息中心大数据发展部副主任魏颖出席会议并致辞。中国工程院院士、北京化工大学教授高金吉,工业和信息化部信息通信发展司二级…...

postgres数据备份与主从配置
备份PostgreSQL数据库 备份格式有几种选择: bak:压缩二进制格式 sql:明文转储 tar: tarball mydb# \q -bash-4.2$ pg pgawk pg_dump pgrep pg_basebackup pg_dumpall pg_restore# 备份所有的 -bash-4.2$ pg_dumpall &…...

【二分查找】力扣 275. H 指数 II
一、题目 二、思路 h 指数是高引用引用次数,而 citations 数组中存储的就是不同论文被引用的次数,并且是按照升序排列的。也就是说 h 指数将整个 citations 数组分成了两部分,左半部分是不够引用 h 次 的论文,右半部分论文的引用…...

使用uni-app进行开发前准备
使用uni-app进行开发,需要遵循一定的步骤和流程。以下是一个详细的指南,帮助你开始使用uni-app进行开发: 一、开发环境搭建 安装Node.js: 首先,从Node.js的官方网站(https://nodejs.org/)下载并…...

AI开发-深度学习框架-PyTorch-torchnlp
1 需求 Welcome to Pytorch-NLP’s documentation! — PyTorch-NLP 0.5.0 documentation 2 接口 3 示例 4 参考资料...
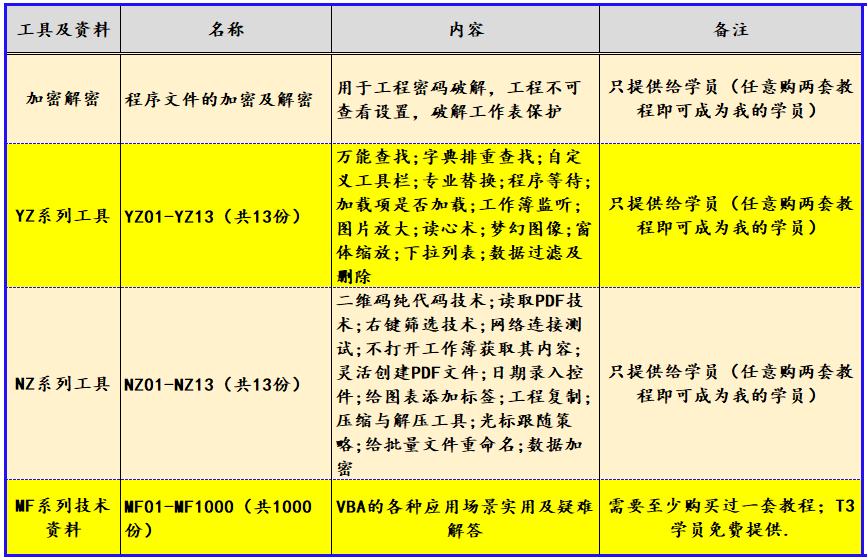
VBA数据库解决方案第十七讲:Recordset对象记录位置的定位方法
《VBA数据库解决方案》教程(版权10090845)是我推出的第二套教程,目前已经是第二版修订了。这套教程定位于中级,是学完字典后的另一个专题讲解。数据库是数据处理的利器,教程中详细介绍了利用ADO连接ACCDB和EXCEL的方法…...

Ubuntu 操作系统
一、简介 Ubuntu 是一个基于 Linux 的开源操作系统,它由 Canonical Ltd. 公司维护和资助。Ubuntu 以其易用性、强大的社区支持和定期的安全更新而闻名,一个一桌面应用为主的操作系统。 二、用户使用 1、常规用户的登陆方式 在登录时一般使用普通用户&…...

QKeyMapper:Windows平台下无需重启系统的终极按键映射解决方案
QKeyMapper:Windows平台下无需重启系统的终极按键映射解决方案 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到键鼠&am…...

利用Taotoken透明计费与账单追溯功能优化项目成本管理
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken透明计费与账单追溯功能优化项目成本管理 对于项目管理者或独立开发者而言,大模型API的调用成本常常是一个…...

Vue项目引入vue-particles插件避坑指南:从安装到性能优化的全流程
Vue项目引入vue-particles插件避坑指南:从安装到性能优化的全流程 在当今前端开发领域,视觉效果已成为提升用户体验的关键因素之一。vue-particles作为一款广受欢迎的粒子背景插件,能够为Vue项目添加动态的粒子效果,增强页面的视觉…...

别再关DRC警告了!手把手教你用AD19正确设置3D封装高度偏移,解决PCB叠层干涉
彻底解决PCB叠层干涉:Altium Designer 19中3D封装高度偏移的实战指南 在PCB设计领域,3D封装的高度管理一直是工程师们容易忽视却又至关重要的环节。许多硬件工程师在遇到DRC(设计规则检查)警告时,第一反应往往是寻找关…...

TQVaultAE终极指南:告别泰坦之旅仓库混乱,打造完美装备管理系统
TQVaultAE终极指南:告别泰坦之旅仓库混乱,打造完美装备管理系统 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 还在为《泰坦之旅》的仓库空间不足而…...

NestJS微服务架构实战:从模块化设计到AI辅助开发
1. 项目概述:一个为现代开发者量身定制的NestJS后端起点 如果你正在寻找一个能让你快速启动、结构清晰且面向未来的NestJS后端项目模板,那么 nestjs-vibe-coding 这个项目很可能就是你需要的。它不是又一个简单的“Hello World”示例,而是…...

容器化运维利器:Crusty工具箱镜像的设计原理与实战应用
1. 项目概述:一个为容器化环境而生的轻量级工具箱最近在折腾容器化部署和运维时,发现了一个挺有意思的开源项目,叫cloudwithax/crusty。这个名字本身就挺有画面感的,“crusty”在英文里有“硬壳的”、“有外壳的”意思,…...

ChatGPT-RetrievalQA数据集解析:用合成数据训练检索模型的实践指南
1. 项目概述与核心问题最近在信息检索和自然语言处理社区里,一个话题讨论得挺热:既然像ChatGPT这样的大语言模型已经能生成相当不错的答案,我们为什么还需要传统的检索模型?更进一步,ChatGPT生成的这些答案,…...

CANN/pyasc:add_deq_relu API文档
asc.language.basic.add_deq_relu 【免费下载链接】pyasc 本项目为Python用户提供算子编程接口,支持在昇腾AI处理器上加速计算,接口与Ascend C一一对应并遵守Python原生语法。 项目地址: https://gitcode.com/cann/pyasc asc.language.basic.add_…...

基于.NET 8与Semantic Kernel的AI智能体框架TerraMours.Chat.Ava实战解析
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫TerraMours.Chat.Ava。乍一看这个名字,你可能觉得它就是个普通的聊天应用,但如果你像我一样,深入扒了扒它的代码仓库和设计文档,就会发现它的野心远不止于此…...