M2芯片安装es的步骤
背景:因为最近经常用到es,但是测试环境没有es,自己本地也没安装,为了方便测试,然后安装一下,但是刚开始安装就报错,记录一下,安装的版本为8.16.1
第一步:去官网下载macos版本的es

解决方案:
在终端中输入:sudo spctl --master-disable
然后再启动,显示如下

第二步:上一步中没有配置es默认这些用不的账户、密码,这一步中配置es的账户、密码,(我修改用户的密码没用这个命令,用的是./elasticsearch-reset-password -u elastic -i命令)
执行命令:
./elasticsearch-setup-passwords interactive
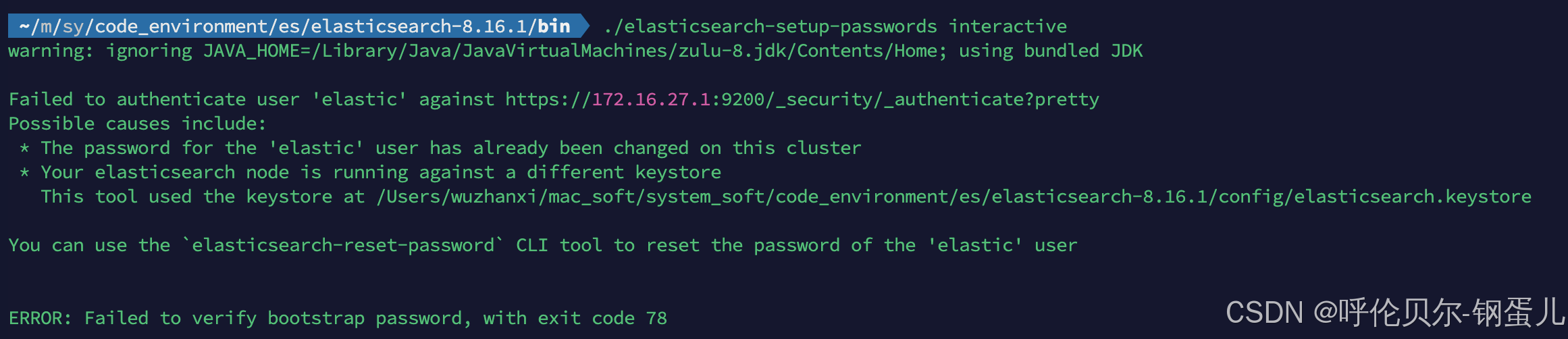
报错如下;
warning: ignoring JAVA_HOME=/Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home; using bundled JDKFailed to authenticate user 'elastic' against https://172.16.27.1:9200/_security/_authenticate?pretty
Possible causes include:* The password for the 'elastic' user has already been changed on this cluster* Your elasticsearch node is running against a different keystoreThis tool used the keystore at /Users/wuzhanxi/mac_soft/system_soft/code_environment/es/elasticsearch-8.16.1/config/elasticsearch.keystoreYou can use the `elasticsearch-reset-password` CLI tool to reset the password of the 'elastic' userERROR: Failed to verify bootstrap password, with exit code 78
图片截图:
解决方案:
执行修改用户的命令
./elasticsearch-reset-password -u elastic -i
执行成功返回如下;
~/m/sy/c/es/elasticsearch-8.16.1/bin ./elasticsearch-reset-password -u elastic -i ✔ took 14s base Py at 10:14:23
warning: ignoring JAVA_HOME=/Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home; using bundled JDK
This tool will reset the password of the [elastic] user.
You will be prompted to enter the password.
Please confirm that you would like to continue [y/N]yEnter password for [elastic]:
Re-enter password for [elastic]:
Password for the [elastic] user successfully reset.
我elasticsearch的配置文件如下;
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: wzx-es-cluster
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: wzx-node
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data
#
# Path to log files:
#
#path.logs: /path/to/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# By default Elasticsearch is only accessible on localhost. Set a different
# address here to expose this node on the network:
#
#network.host: 192.168.0.1
network.host: localhost
#
# By default Elasticsearch listens for HTTP traffic on the first free port it
# finds starting at 9200. Set a specific HTTP port here:
#
http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
discovery.seed_hosts: ["localhost"]
#
# Bootstrap the cluster using an initial set of master-eligible nodes:
#
cluster.initial_master_nodes: ["wzx-node-1"]
#
# For more information, consult the discovery and cluster formation module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Allow wildcard deletion of indices:
#
#action.destructive_requires_name: false#----------------------- BEGIN SECURITY AUTO CONFIGURATION -----------------------
#
# The following settings, TLS certificates, and keys have been automatically
# generated to configure Elasticsearch security features on 28-11-2024 09:11:45
#
# --------------------------------------------------------------------------------# Enable security features
xpack.security.enabled: truexpack.security.enrollment.enabled: true# Enable encryption for HTTP API client connections, such as Kibana, Logstash, and Agents
xpack.security.http.ssl:enabled: falsekeystore.path: certs/http.p12# Enable encryption and mutual authentication between cluster nodes
xpack.security.transport.ssl:enabled: falseverification_mode: certificatekeystore.path: certs/transport.p12truststore.path: certs/transport.p12
# Create a new cluster with the current node only
# Additional nodes can still join the cluster later
#cluster.initial_master_nodes: ["wuzhanxideMBP-2"]# Allow HTTP API connections from anywhere
# Connections are encrypted and require user authentication
http.host: 0.0.0.0# Allow other nodes to join the cluster from anywhere
# Connections are encrypted and mutually authenticated
#transport.host: 0.0.0.0#----------------------- END SECURITY AUTO CONFIGURATION -------------------------
配置kibana连接elasticsearch的配置文件如下;
# For more configuration options see the configuration guide for Kibana in
# https://www.elastic.co/guide/index.html# =================== System: Kibana Server ===================
# Kibana is served by a back end server. This setting specifies the port to use.
server.port: 5601# Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values.
# The default is 'localhost', which usually means remote machines will not be able to connect.
# To allow connections from remote users, set this parameter to a non-loopback address.
server.host: "localhost"# Enables you to specify a path to mount Kibana at if you are running behind a proxy.
# Use the `server.rewriteBasePath` setting to tell Kibana if it should remove the basePath
# from requests it receives, and to prevent a deprecation warning at startup.
# This setting cannot end in a slash.
#server.basePath: ""# Specifies whether Kibana should rewrite requests that are prefixed with
# `server.basePath` or require that they are rewritten by your reverse proxy.
# Defaults to `false`.
#server.rewriteBasePath: false# Specifies the public URL at which Kibana is available for end users. If
# `server.basePath` is configured this URL should end with the same basePath.
#server.publicBaseUrl: ""# The maximum payload size in bytes for incoming server requests.
#server.maxPayload: 1048576# The Kibana server's name. This is used for display purposes.
#server.name: "your-hostname"# =================== System: Kibana Server (Optional) ===================
# Enables SSL and paths to the PEM-format SSL certificate and SSL key files, respectively.
# These settings enable SSL for outgoing requests from the Kibana server to the browser.
#server.ssl.enabled: false
#server.ssl.certificate: /path/to/your/server.crt
#server.ssl.key: /path/to/your/server.key# =================== System: Elasticsearch ===================
# The URLs of the Elasticsearch instances to use for all your queries.
elasticsearch.hosts: ["http://localhost:9200"]# If your Elasticsearch is protected with basic authentication, these settings provide
# the username and password that the Kibana server uses to perform maintenance on the Kibana
# index at startup. Your Kibana users still need to authenticate with Elasticsearch, which
# is proxied through the Kibana server.
elasticsearch.username: "kibana_system"
#elasticsearch.username: "elastic"
elasticsearch.password: "es123!@#"
#elasticsearch.password: "pass"# Kibana can also authenticate to Elasticsearch via "service account tokens".
# Service account tokens are Bearer style tokens that replace the traditional username/password based configuration.
# Use this token instead of a username/password.
# elasticsearch.serviceAccountToken: "my_token"# Time in milliseconds to wait for Elasticsearch to respond to pings. Defaults to the value of
# the elasticsearch.requestTimeout setting.
#elasticsearch.pingTimeout: 1500# Time in milliseconds to wait for responses from the back end or Elasticsearch. This value
# must be a positive integer.
#elasticsearch.requestTimeout: 30000# The maximum number of sockets that can be used for communications with elasticsearch.
# Defaults to `Infinity`.
#elasticsearch.maxSockets: 1024# Specifies whether Kibana should use compression for communications with elasticsearch
# Defaults to `false`.
#elasticsearch.compression: false# List of Kibana client-side headers to send to Elasticsearch. To send *no* client-side
# headers, set this value to [] (an empty list).
#elasticsearch.requestHeadersWhitelist: [ authorization ]# Header names and values that are sent to Elasticsearch. Any custom headers cannot be overwritten
# by client-side headers, regardless of the elasticsearch.requestHeadersWhitelist configuration.
#elasticsearch.customHeaders: {}# Time in milliseconds for Elasticsearch to wait for responses from shards. Set to 0 to disable.
#elasticsearch.shardTimeout: 30000# =================== System: Elasticsearch (Optional) ===================
# These files are used to verify the identity of Kibana to Elasticsearch and are required when
# xpack.security.http.ssl.client_authentication in Elasticsearch is set to required.
#elasticsearch.ssl.certificate: /path/to/your/client.crt
#elasticsearch.ssl.key: /path/to/your/client.key# Enables you to specify a path to the PEM file for the certificate
# authority for your Elasticsearch instance.
#elasticsearch.ssl.certificateAuthorities: [ "/path/to/your/CA.pem" ]# To disregard the validity of SSL certificates, change this setting's value to 'none'.
#elasticsearch.ssl.verificationMode: full# =================== System: Logging ===================
# Set the value of this setting to off to suppress all logging output, or to debug to log everything. Defaults to 'info'
#logging.root.level: debug# Enables you to specify a file where Kibana stores log output.
#logging.appenders.default:
# type: file
# fileName: /var/logs/kibana.log
# layout:
# type: json# Example with size based log rotation
#logging.appenders.default:
# type: rolling-file
# fileName: /var/logs/kibana.log
# policy:
# type: size-limit
# size: 256mb
# strategy:
# type: numeric
# max: 10
# layout:
# type: json# Logs queries sent to Elasticsearch.
#logging.loggers:
# - name: elasticsearch.query
# level: debug# Logs http responses.
#logging.loggers:
# - name: http.server.response
# level: debug# Logs system usage information.
#logging.loggers:
# - name: metrics.ops
# level: debug# Enables debug logging on the browser (dev console)
#logging.browser.root:
# level: debug# =================== System: Other ===================
# The path where Kibana stores persistent data not saved in Elasticsearch. Defaults to data
#path.data: data# Specifies the path where Kibana creates the process ID file.
#pid.file: /run/kibana/kibana.pid# Set the interval in milliseconds to sample system and process performance
# metrics. Minimum is 100ms. Defaults to 5000ms.
#ops.interval: 5000# Specifies locale to be used for all localizable strings, dates and number formats.
# Supported languages are the following: English (default) "en", Chinese "zh-CN", Japanese "ja-JP", French "fr-FR".
#i18n.locale: "en"# =================== Frequently used (Optional)===================# =================== Saved Objects: Migrations ===================
# Saved object migrations run at startup. If you run into migration-related issues, you might need to adjust these settings.# The number of documents migrated at a time.
# If Kibana can't start up or upgrade due to an Elasticsearch `circuit_breaking_exception`,
# use a smaller batchSize value to reduce the memory pressure. Defaults to 1000 objects per batch.
#migrations.batchSize: 1000# The maximum payload size for indexing batches of upgraded saved objects.
# To avoid migrations failing due to a 413 Request Entity Too Large response from Elasticsearch.
# This value should be lower than or equal to your Elasticsearch cluster’s `http.max_content_length`
# configuration option. Default: 100mb
#migrations.maxBatchSizeBytes: 100mb# The number of times to retry temporary migration failures. Increase the setting
# if migrations fail frequently with a message such as `Unable to complete the [...] step after
# 15 attempts, terminating`. Defaults to 15
#migrations.retryAttempts: 15# =================== Search Autocomplete ===================
# Time in milliseconds to wait for autocomplete suggestions from Elasticsearch.
# This value must be a whole number greater than zero. Defaults to 1000ms
#unifiedSearch.autocomplete.valueSuggestions.timeout: 1000# Maximum number of documents loaded by each shard to generate autocomplete suggestions.
# This value must be a whole number greater than zero. Defaults to 100_000
#unifiedSearch.autocomplete.valueSuggestions.terminateAfter: 100000
启动kibana时,需要登录用户名、密码,但是用kibana_system用户登录时权限不够,需要用elastic用户登录才可以
相关文章:
M2芯片安装es的步骤
背景:因为最近经常用到es,但是测试环境没有es,自己本地也没安装,为了方便测试,然后安装一下,但是刚开始安装就报错,记录一下,安装的版本为8.16.1 第一步:去官网下载maco…...

macos下brew安装redis
首先确保已安装brew,接下来搜索资源,在终端输入如下命令: brew search redis 演示如下: 如上看到有redis资源,下面进行安装,执行下面的命令: brew install redis 演示效果如下: …...
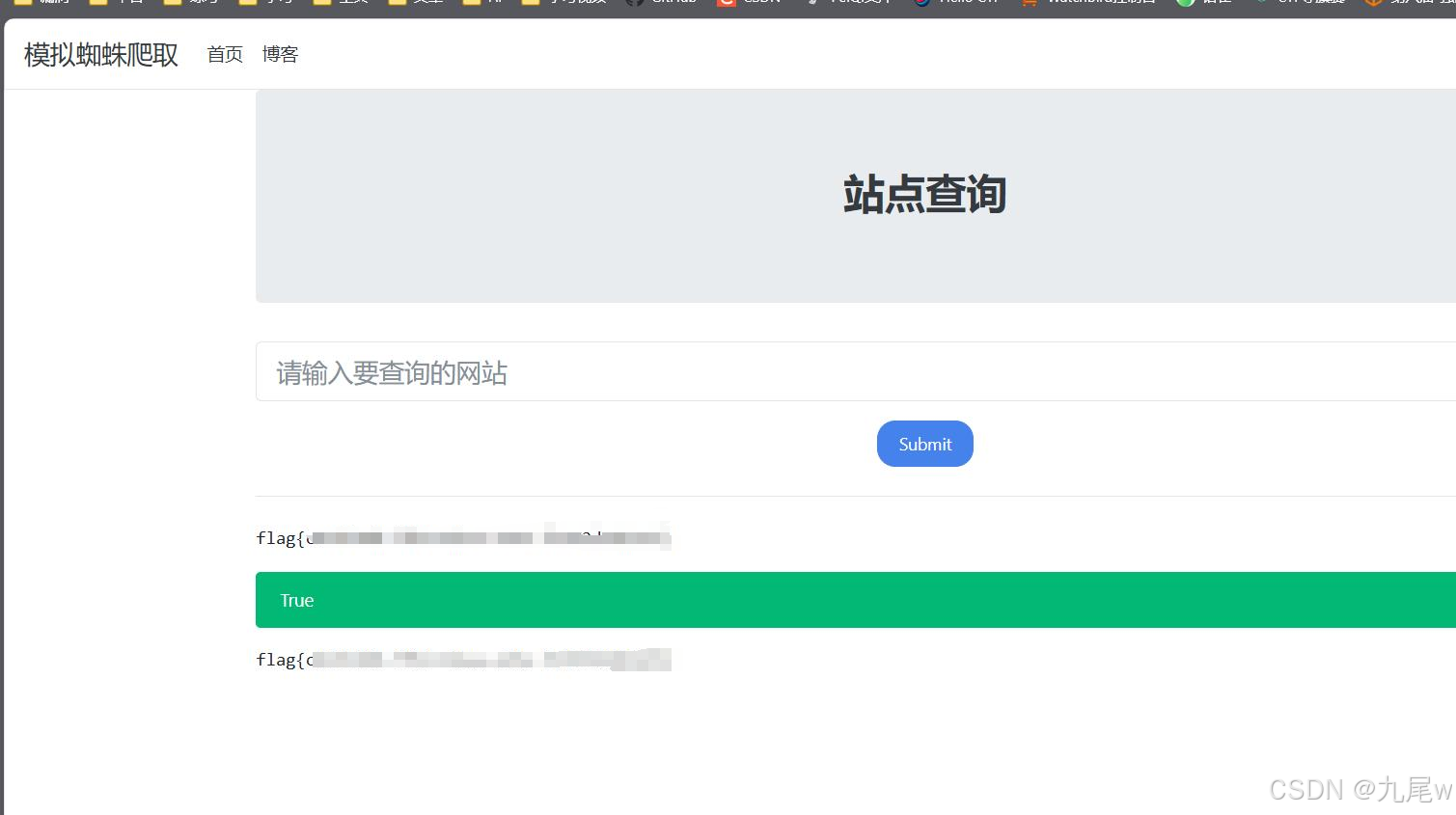
第六届金盾信安杯-SSRF
操作内容: 进入环境 可以查询网站信息 查询环境url https://114.55.67.167:52263/flag.php 返回 flag 就在这 https://114.55.67.167:52263/flag.php 把这个转换成短连接,然后再提交 得出 flag...

【论文投稿】国产游戏技术:迈向全球引领者的征途
【IEEE出版南方科技大学】第十一届电气工程与自动化国际会议(IFEEA 2024)_艾思科蓝_学术一站式服务平台 更多学术会议论文投稿请看:https://ais.cn/u/nuyAF3 目录 国产游戏技术能否引领全球? 一、国产游戏技术的崛起之路 1.1 初期探索与积…...
面试题及参考答案)
腾讯微众银行大数据面试题(包含数据分析/挖掘方向)面试题及参考答案
为什么喜欢使用 XGBoost,XGBoost 的主要优势有哪些? XGBoost 是一个优化的分布式梯度增强库,在数据科学和机器学习领域应用广泛,深受喜爱,原因主要在于其众多突出优势。 首先,它的精度高,在许多机器学习竞赛和实际应用中,XGBoost 都展现出卓越的预测准确性。其基于决策…...

【Linux】死锁、读写锁、自旋锁
文章目录 1. 死锁1.1 概念1.2 死锁形成的四个必要条件1.3 避免死锁 2. 读者写者问题与读写锁2.1 读者写者问题2.2 读写锁的使用2.3 读写策略 3. 自旋锁3.1 概念3.2 原理3.3 自旋锁的使用3.4 优点与缺点 1. 死锁 1.1 概念 死锁是指在⼀组进程中的各个进程均占有不会释放的资源…...
Spring Web开发(请求)获取JOSN对象| 获取数据(Header)
大家好,我叫小帅今天我们来继续Spring Boot的内容。 文章目录 1. 获取JSON对象2. 获取URL中参数PathVariable3.上传⽂件RequestPart3. 获取Cookie/Session3.1 获取和设置Cookie3.1.1传统获取Cookie3.1.2简洁获取Cookie 3. 2 获取和存储Session3.2.1获取Session&…...

用c语言完成俄罗斯方块小游戏
用c语言完成俄罗斯方块小游戏 这估计是你在编程学习过程中的第一个小游戏开发,怎么说呢,在这里只针对刚学程序设计的学生,就是说刚接触C语言没多久,有一点功底的学生看看,简陋的代码,简陋的实现࿰…...
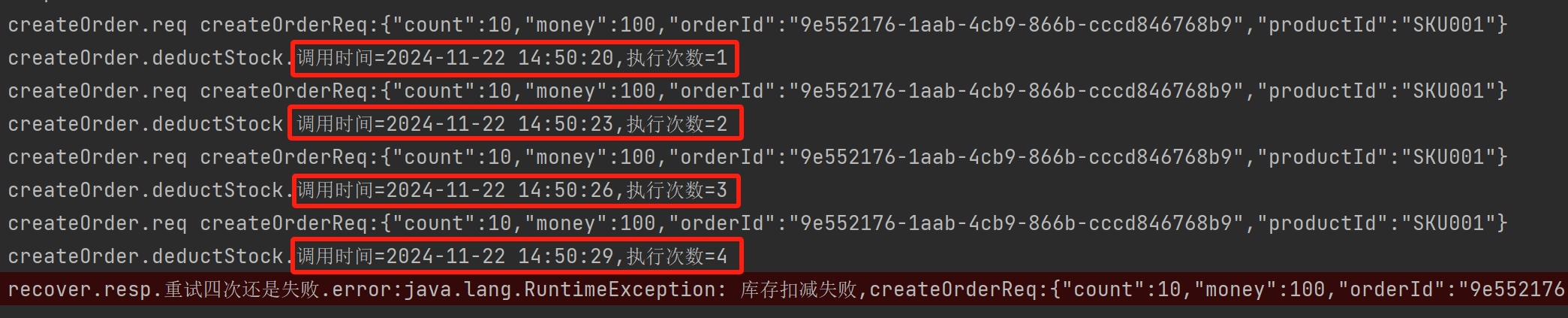
SpringBoot整合Retry详细教程
问题背景 在现代的分布式系统中,服务间的调用往往需要处理各种网络异常、超时等问题。重试机制是一种常见的解决策略,它允许应用程序在网络故障或临时性错误后自动重新尝试失败的操作。Spring Boot 提供了灵活的方式来集成重试机制,这可以通过…...
JS API事件监听(绑定)
事件监听 语法 元素对象.addEventListener(事件监听,要执行的函数) 事件监听三要素 事件源:那个dom元素被事件触发了,要获取dom元素 事件类型:用说明方式触发,比如鼠标单击click、鼠标经过mouseover等 事件调用的函数&#x…...

ceph手动部署
ceph手动部署 一、 节点规划 主机名IP地址角色ceph01.example.com172.18.0.10/24mon、mgr、osd、mds、rgwceph02.example.com172.18.0.20/24mon、mgr、osd、mds、rgwceph03.example.com172.18.0.30/24mon、mgr、osd、mds、rgw 操作系统版本: Rocky Linux release …...
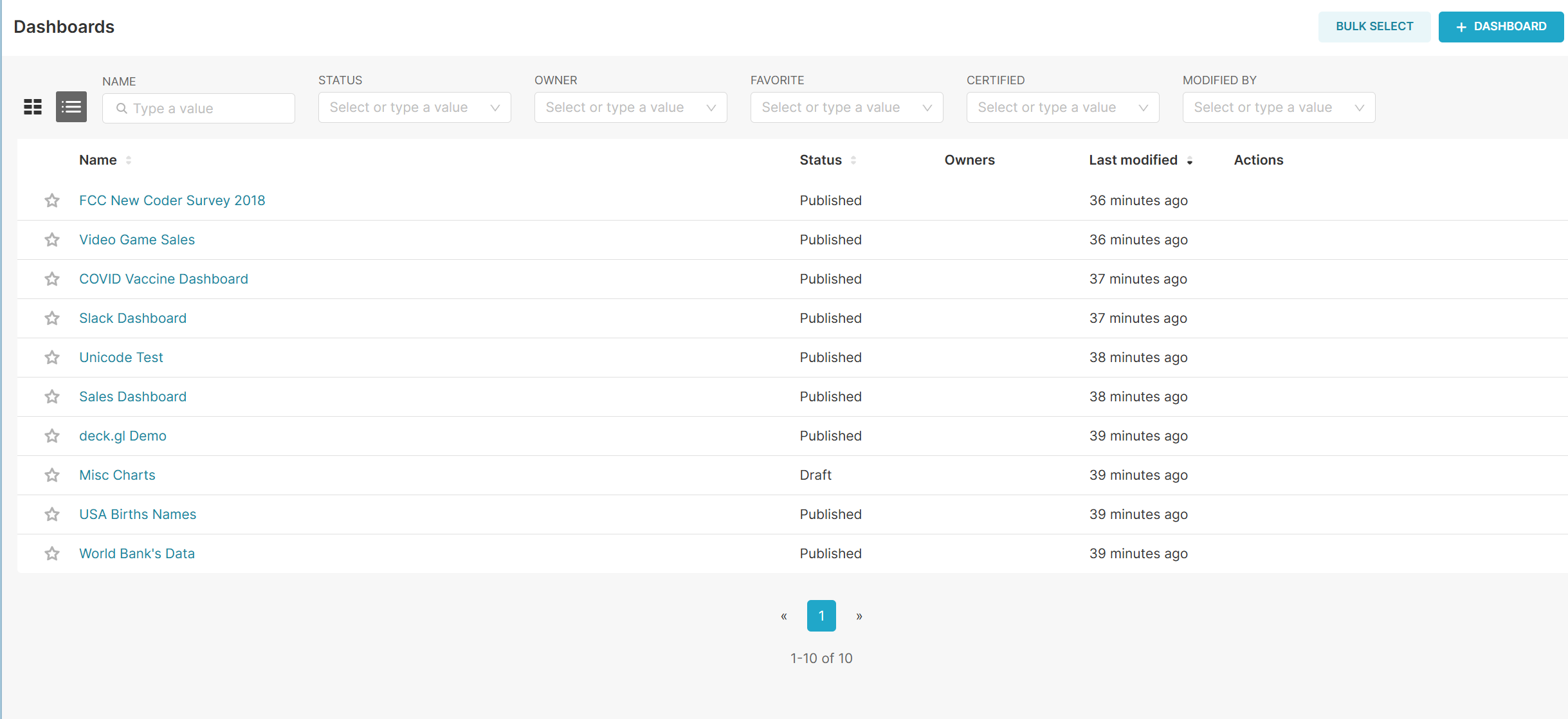
superset load_examples加载失败解决方法
如果在执行load_examples命令后,出现上方图片情况,或是相似报错(url error\connection error),大概率原因是python程序请求github数据,无法访问. 因此我们可以将数据下载在本地来解决. 1.下载zip压缩文件,存放到本地 官方示例地址:GitHub - apache-superset/examples-data …...

wareshark分析mysql协议的数据包
使用wareshark 分析mysql协议的数据包,是每个dba都应该掌握的技能,掌握以后,就可以通过tcpdump抓包分析,得到连接报错的信息了。 tcpdump抓包命令: tcpdump -nn -i bond0 dst 10.21.6.72 and port 4002 -w 1129_tcpdu…...
------UIAbility启动模式(文档编辑案例))
HarmonyOS4+NEXT星河版入门与项目实战(25)------UIAbility启动模式(文档编辑案例)
文章目录 1、启动模式2、Specified启动模式实现步骤3、文档编辑案例1、文件创建2代码实现3、Statge 创建4、添加配置1、启动模式 Singleton启动模式: 每个 UIAbility 只存在一个实例,是默认的启动模式,任务列表中只会存在一个相同的 UIAbilityStandard启动模式: 每次启动 U…...
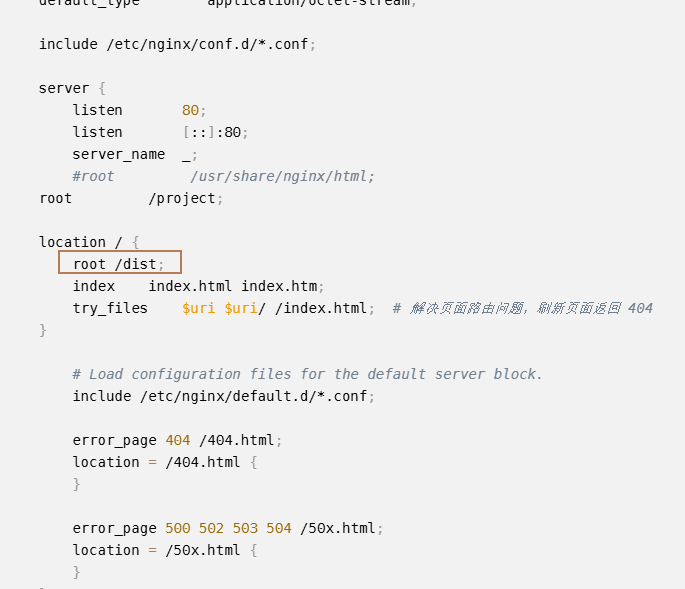
webpack 项目访问静态资源
使用 webpack dev serve 启动 react 项目后,发现无法使用 http://localhost:8080/1.png 访问到项目的 /static 目录下的 1.png 文件。我的 webpack-dev.js 配置如下: const webpack require(webpack) const webpackMerge require(webpack-merge) cons…...

UNION和UNION ALL区别
文章目录 结果集的处理方式:对重复记录的处理:排序处理:执行效率: UNION和UNION ALL的主要区别在于结果集的处理方式、对重复记录的处理、排序处理以及执行效率。 结果集的处理方式: UNION…...
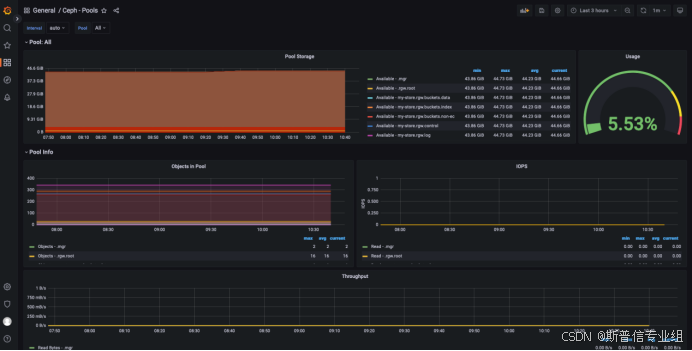
Rook入门:打造云原生Ceph存储的全面学习路径(下)
文章目录 六.Rook部署云原生CephFS文件系统6.1 部署cephfs storageclass6.2 创建容器所需cephfs文件系统6.3创建容器pod使用rook-cephfs提供pvc6.4 查看pod是否使用rook-cephfs 七.Ceph Dashboard界面7.1 启用dashboard开关7.2 ceph-dashboard配置外部访问7.3 Dashboard web ad…...

RabbitMQ消息可靠性保证机制6--可靠性分析
在使用消息中间件的过程中,难免会出现消息错误或者消息丢失等异常情况。这个时候就需要有一个良好的机制来跟踪记录消息的过程(轨迹溯源),帮助我们排查问题。 在RabbitMQ中可以使用Firehose实现消息的跟踪,Firehose可…...

k8s容器存储接口 CSI 相关知识
容器存储接口 CSI 相关知识 参考: https://blog.csdn.net/lovely_nn/article/details/122880876 https://developer.aliyun.com/article/783464 https://www.cnblogs.com/varden/p/15139819.html存储商需实现 CSI 插件的 NodeGetVolumeStats 接口,Kube…...
jmeter基础_打开1个jmeter脚本(.jmx文件)
课程大纲 方法1.菜单栏“打开” 菜单栏“文件” - “打开” (或快捷键,mac为“⌘ O”),打开文件选择窗口 - 选择脚本文件,点击“open”,即可打开脚本。 方法2.工具栏“打开”图标 工具栏点击“打开”图标&…...


管理幅度怎样设置才合理?
https://mp.weixin.qq.com/s/aoUgKUmsOUyC7wWOONMIIw...
)
别再只会用IP核了!手把手教你用Verilog从零实现一个16阶FIR滤波器(附完整代码)
从零构建16阶FIR滤波器:Verilog实战指南与工程思维解析 在FPGA开发领域,FIR(有限脉冲响应)滤波器是数字信号处理的基础模块,但大多数工程师习惯直接调用厂商提供的IP核,这就像只会开自动挡汽车的司机——虽…...

63岁黄仁勋再添博士头衔、英特尔CEO为其披袍,最新演讲刷屏:人类编写软件、计算机执行指令的范式已终结!
整理 | 苏宓 出品 | CSDN(ID:CSDNnews) 日前,在卡内基梅隆大学(CMU)的 2026 届毕业典礼上,英伟达 CEO 黄仁勋的头衔再加一,最新获得 CMU 科学与技术荣誉博士学位,而这也是…...
从零构建Transformer:机器学习深度研习笔记与实战解析
1. 从零到一:我的机器学习深度研习之旅作为一名在数据科学和机器学习领域摸爬滚打了十多年的从业者,我深知这个领域的知识迭代速度有多快。从早期的统计学习到如今的生成式AI,技术栈的深度和广度都在以惊人的速度扩展。几年前,当我…...

基于GitHub Actions打造自动化工作流:测试、构建、部署
从手工到自动化的测试交付变革在软件研发流程中,测试从来不是孤立环节。每一次代码提交,都可能触发一轮新的构建、部署与验证。传统模式下,测试人员往往需要等待开发手动打包、手动部署到测试环境,再通过人工触发或定时执行测试脚…...

基于Refine框架的企业级后台管理系统实战开发指南
1. 项目概述与核心价值最近在梳理企业内部后台管理系统的技术栈时,我又一次把目光投向了refine这个框架。如果你也和我一样,长期被各种业务后台的重复性开发工作所困扰——比如没完没了的增删改查(CRUD)界面、复杂的权限控制、数据…...

Blitz.js全栈开发框架:基于Next.js的Zero-API数据层实践
1. 项目概述:Blitz.js,一个被低估的全栈开发框架如果你和我一样,在过去几年里一直在用 Next.js 构建全栈应用,那你肯定经历过这种场景:前端页面写得飞快,但一到后端 API 路由、数据库操作、身份验证这些环节…...
)
西门子S7-300/400老系统改造:用DP/DP Coupler打通新旧产线数据(附Step7组态避坑点)
西门子S7-300/400老系统改造:用DP/DP Coupler打通新旧产线数据(附Step7组态避坑点) 在工业自动化领域,老旧产线升级改造往往面临新旧设备通讯协议不兼容的难题。当传统S7-300系统需要与现代化S7-400或带PN接口的PLC进行数据交互时…...

如何用Rye与Docker打造无缝Python容器开发环境:完整实践指南
如何用Rye与Docker打造无缝Python容器开发环境:完整实践指南 【免费下载链接】rye a Hassle-Free Python Experience 项目地址: https://gitcode.com/gh_mirrors/ry/rye Rye是一款旨在提供无忧Python开发体验(a Hassle-Free Python Experience&am…...