【数据结构】哈希 ---万字详解
unordered系列关联式容器
在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到log_2
N,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。最好
的查询是,进行很少的比较次数就能够将元素找到,因此在C++11中,STL又提供了4个
unordered系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本类似,只是
其底层结构不同。因为unordered_set与unordered_map使用方式类似,我们着重见介绍unordered_map,unordered_set见文档。
unordered_map(文档)
- unordered_map是存储<key, value>键值对的关联式容器,其允许通过keys快速的索引到与其对应的value。
- 在unordered_map中,键值通常用于惟一地标识元素,而映射值是一个对象,其内容与此键关联。键和映射值的类型可能不同。
- 在内部,unordered_map没有对<kye, value>按照任何特定的顺序排序, 为了能在常数范围内找到key所对应的value,unordered_map将相同哈希值的键值对放在相同的桶中。
- unordered_map容器通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭代方面效率较低。
- unordered_map实现了直接访问操作符(operator[]),它允许使用key作为参数直接访value。
- unordered_map是单向迭代器
接口
unordered_map容量相关
- bool empty()const (检测unordered_map是否为空)
- size_t size()const (获取unordered_map的有效元素个数)
unordered_map的元素访问
- operator[] (返回与key对应的value,没有一个默认值)
- 注意:该函数中实际调用哈希桶的插入操作,用参数key与V()构造一个默认值往底层哈希桶中插入,如果key不在哈希桶中,插入成功,返回V(),插入失败,说明key已经在哈希桶中,将key对应的value返回。
unordered_map的查询
- iterator find(const K& key) (返回key在哈希桶中的位置)
- size_t count(const K& key) (返回哈希桶中关键码为key的键值对的个数)
unordered_map的修改操作
- insert (向容器中插入键值对)
- erase (删除容器中的键值对)
- void clear() (清空容器中有效元素个数)
- void swap(unordered_map&) (交换两个容器中的元素)
unordered_map的桶操作
- size_t bucket_count()const (返回哈希桶中桶的总个数)
- size_t bucket_size(size_t n)const (返回n号桶中有效元素的总个数)
- size_t bucket(const K& key) (返回元素key所在的桶号)
使用
#include <iostream>
using namespace std;
#include <map>
#include <set>
#include <unordered_map>
#include <unordered_set>
void test_unordered_set()
{unordered_set<int> us;us.insert(4);us.insert(2);us.insert(1);us.insert(5);us.insert(6);/*us.insert(6);us.insert(6);*///可以去重 不能排序unordered_set<int>::iterator it = us.begin();while (it != us.end()){cout << *it << " ";++it; }cout << endl;
}
void test_op()
{unordered_set<int> us;set<int> s;const int n = 1000000;vector<int> v;v.reserve(n);srand(time(0));for (size_t i = 0; i < n; ++i){v.push_back(rand());} size_t begin1 = clock();for (size_t i = 0; i < n; ++i){us.insert(v[i]);}size_t end1=clock();size_t begin2 = clock();for (size_t i = 0; i < n; ++i){s.insert(v[i]);}size_t end2 = clock();size_t begin3 = clock();for (size_t i = 0; i < n; ++i){us.find(v[i]);}size_t end3 = clock();size_t begin4 = clock();for (size_t i = 0; i < n; ++i){s.find(v[i]);}size_t end4 = clock();size_t begin5 = clock();for (size_t i = 0; i < n; ++i){us.erase(v[i]);}size_t end5 = clock();size_t begin6 = clock();for (size_t i = 0; i < n; ++i){s.erase(v[i]);}size_t end6 = clock();cout << "set:(insert)" << end2 - begin2 << endl;cout << "unordered_set:(insert)" << end1 - begin1 << endl;cout << "set:(find)" << end4 - begin4 << endl;cout << "unordered_set:(find)" << end3 - begin3 << endl;cout << "set:(erase)" << end6 - begin6 << endl;cout << "unordered_set:(erase)" << end5 - begin5 << endl;
}从运行结果可以看出unordered_set容器增删查的效率比set快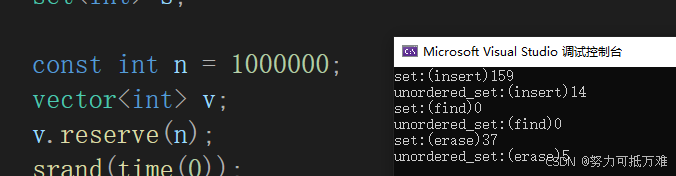
相关OJ题
- 重复n次的元素
- 两个数组的交集I
- 两个数组的交集II
- 存在重复元素
- 两句话中不常见的单词
底层结构
unordered系列的关联式容器之所以效率比较高,是因为其底层使用了哈希结构。
哈希是一种映射的对应关系,将存储的数据根存储的位置使用哈希函数建立出的映射关系,方便我们进行查找。在查找字符串中只出现过一次的字符中就可以创建一个256的int数组,去统计次数,因为字符总共只有256种,这里就建立了字符(char)与字符的值(int)的映射关系(直接定址法:映射只跟关键字直接相关或者间接相关)。 其次计数排序也是统计次数,建立类似的映射,进行排序。
1,2,5,9,1000000,888888,23存起来,方便查找,怎么存?(不使用搜索树)
如果每个值直接进行映射,那么我们要创建一个100w大小的数组,空间浪费十分严重。基于这个原因,哈希引申出一些映射的方式进行补救。
除留余数法(最常用)

不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞。把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。
现在我们要存11,就会发生冲突了,这种冲突叫做哈希冲突。(不同的值映射到了相同的位置)哈希通过映射关系进行查找,效率非常高,但是哈希最大的问题就是如何解决哈希冲突?这里就引入了很多种方法来解决哈希冲突。
哈希冲突解决
解决哈希冲突两种常见的方法是:闭散列和开散列
闭散列
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有
空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置
呢?
- 线性探测(从发生冲突的位置开始,依次向后探测,直到找到下一个空位置为止)
- key % 表大小 + i (i = 0,1,2,3,4,...)
- 二次探测(按2次方往后找空位置)
- key % 表大小 + i^2 (i = 0,1,2,3,...)
线性探测
插入
- 通过哈希函数获取待插入元素在哈希表中的位置如果该位置中没有元素则直接插入新元素
- 如果该位置中有元素发生哈希冲突,使用线性探测找到下一个空位置,插入新元素
删除
- 采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素,可能会影响其他元素的搜索。
- 比如删除元素4,如果直接删除掉,44查找起来可能会受影响。因此线性探测采用标记的伪删除法来删除一个元素。
enum State{EMPTY,EXITS,DELETE};线性探测的实现
#include <iostream>
#include <vector>
using namespace std;
enum State
{EMPTY,EXITS,DELETE
};
template<class T>
struct HashData
{T _data;State _state=EMPTY;
};template<class K>
struct SetOfT
{const K& operator()(const K& key){return key;}
};
//unordered_set<K> ->HashTable<K,K>
//unordered_map<K,V> ->HashTable<K,pair<K,V>>
template<class K,class T,typename KOfT>
class HashTable
{
public:bool Insert(const T& d){KOfT koft;/*if (Find(koft(d)))return false;*///闭散列哈希表不能满了再增容//因为如果哈希表快满了的时候插入数据,冲突的概率很大,效率会很低//快接近满的时候就增容//因此提出负载因子的概念=表中数据个数比上表的大小//一般情况下,负载因子越小,冲突的概率特低,效率越高//但是控制的太小,会导致大量的空间浪费,以空间换时间/*if (_tables.size()==0||_num * 10 / _tables.size() > 7){*/// //第一次会出现除0的问题// //1.开两倍大小的新表// //2.遍历旧表的数据,重新计算表中的位置// //3.释放旧表// size_t newsize = _tables.size() == 0 ? 10 : 2 * _tables.size();// vector<HashData<T>> newtables;// newtables.resize(newsize);// for (size_t i = 0; i < _tables.size(); ++i)// {// if (_tables[i]._state == EXITS)// {// //计算新表中的位置并处理冲突// int index = koft(_tables[i]._data) % newtables.size();// while (newtables[index]._state == EXITS)// {// ++index;// if (index == newtables.size())// index = 0;// }// newtables[index] = _tables[i];// }// }// _tables.swap(newtables);//}if (_tables.size() == 0 || _num * 10 / _tables.size() > 7){HashTable<K, T, KOfT> newht;size_t newsize = _tables.size() == 0 ? 10 : _tables.size() * 2;newht._tables.resize(newsize);for (auto& data : _tables){if (data._state == EXITS){newht.Insert(data._data);}}_tables.swap(newht._tables);}size_t index = koft(d) % _tables.size();while (_tables[index]._state == EXITS){++index;if (index == _tables.size())index = 0;}_tables[index]._data = d;_tables[index]._state = EXITS;++_num;return true;}HashData<T>* Find(const K& key){KOfT koft;size_t index = key % _tables.size();while (_tables[index]._state != EMPTY){if (koft(_tables[index]._data) == key){if (_tables[index]._state == EXITS){return &_tables[index];}else if (_tables[index]._state == DELETE)return nullptr;}++index;if (index == _tables.size())index = 0;}return nullptr;}bool Erase(const K& key){HashData<T>* ret = Find(key);if (ret){ret->_state = DELETE;--_num;return true;}else{return false;}}
private:vector<HashData<T>> _tables;size_t _num=0; //有效数据的个数
};
void test_HashTable()
{HashTable<int,int, SetOfT<int>> ht;ht.Insert(4);ht.Insert(14);ht.Insert(24);ht.Insert(5);ht.Insert(15);ht.Insert(25);ht.Insert(6);ht.Insert(16);
}线性探测的问题

线性探测的思路就是如果我的位置被占用了,我就挨着往后去占别人的位置,可能会导致一片一片的冲突,洪水效应。
- 线性探测优点:实现非常简单
- 线性探测缺点:一旦发生哈希冲突,所有的冲突连在一起,容易产生数据“堆积”,即:不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要许多次比较,导致搜索效率降低。如何缓解呢? 二次探测
开散列
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地
址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链
接起来,各链表的头结点存储在哈希表中。
 开散列中每个桶中放的都是发生哈希冲突的元素。
开散列中每个桶中放的都是发生哈希冲突的元素。
开散列实现
template<class T>
struct HashNode
{HashNode(const T& data):_next(nullptr),_data(data){}T _data;HashNode<T>* _next;
};template<class K>
struct _Hash
{
public:const K& operator()(const K& key){return key;}
};//特化 HashTable<string,string,SetOfT<string>> ht;
template<>
struct _Hash<string>
{size_t operator()(string key){size_t hash = 0;for (size_t i = 0; i < key.size(); ++i){hash *= 131;hash += key[i];}return hash;}
};
//HashTable<string,string,SetOfT<string>,_HashString> ht;
/*struct _HashString
{
public:size_t operator()(string key){size_t hash = 0;for (size_t i = 0; i < key.size(); ++i){hash *= 131;hash += key[i];}return hash;}
};*/
template<class K,class T,class KOFT,class Hash=_Hash<K>>
class HashTable
{typedef HashNode<T> Node;
public:~HashTable(){Clear();}void Clear(){for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){Node* _next = cur->_next;delete cur;cur = _next;}}}const size_t HashFunc(const K& key){Hash hash;return hash(key);}bool Insert(const T& data){KOFT koft;//增容 负载因子if (_num == _tables.size()){size_t newsize = (_tables.size() == 0 ? 10 : 2 * _num);vector<Node*> newtables;newtables.resize(newsize);for (int i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){size_t index = HashFunc(koft(cur->_data)) % newsize;Node* next = cur->_next;cur->_next = newtables[index];newtables[index] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}//计算在表中的映射位置size_t index = HashFunc(koft(data))%_tables.size();Node* cur = _tables[index];//查找这个值在不在表中while (cur){if (koft(cur->_data) == koft(data)){return false;}else{//头插到表中cur = cur->_next;}}Node* ret = new Node(data);ret->_next = _tables[index];_tables[index] = ret;_num++;return true;}Node* Find(const K& key){KOFT koft;size_t index = HashFunc(key) % _tables.size();Node* cur = _tables[index];while (cur){if (koft(cur->_data) == key){return cur;}else{cur = cur->_next;}}return nullptr;}bool Erase(const K& key){KOFT koft;size_t index = HashFunc(key) % _tables.size();Node* cur = _tables[index];Node* prev = nullptr;while (cur){if (koft(cur->_data) == key){if (prev == nullptr){_tables[index] = cur->_next;}else{prev->_next = cur->_next;}delete cur;_num--;return true;}else{prev = cur; cur = cur->_next;}}return false;}
private:vector<Node*> _tables;size_t _num=0;假设总有一些桶挂的数据很多,冲突很厉害怎么解决?
- 针对单个桶:一个桶链的长度超过一定值,就将挂链表改为挂红黑树。(Java HashMap就是当桶长度超过8就改成挂红黑树)
- 针对整体,控制负载因子
 仿函数Hash将对应的key转成可以取余的整型,默认的仿函数直接返回key,因为有些类型的key直接就可以取余;如果是其他自定义类型我们就自己构造一个哈希函数,作为仿函数,传入Hash模板中。(常见字符串哈希算法)
仿函数Hash将对应的key转成可以取余的整型,默认的仿函数直接返回key,因为有些类型的key直接就可以取余;如果是其他自定义类型我们就自己构造一个哈希函数,作为仿函数,传入Hash模板中。(常见字符串哈希算法)
开散列与闭散列比较
应用链地址法处理溢出,需要增设链接指针,似乎增加了存储开销。事实上:由于开地址法必须保持大量的空闲空间以确保搜索效率,如二次探查法要求装载因子a <=0.7,而表项所占空间又比指针大的多,所以使用链地址法反而比开地址法节省存储空间。
unordered_set与unordered_map的模拟实现
哈希表的改造
- 模板参数列表的改造
- 增加迭代器操作
- 增加通过key获取value操作
#pragma once
#include <iostream>
#include <vector>
#include <string>
using namespace std;
namespace wxy
{template<class T>struct HashNode{HashNode(const T& data):_next(nullptr),_data(data){}T _data;HashNode<T>* _next;};//前置声明 两者如果相互依赖,就需要对其中一个进行前置声明template<class K, class T, class KOFT, class Hash>class HashTable;template<class K>struct _Hash{size_t operator()(const K& key){return key;}};// 特化template<>struct _Hash<string>{// "int" "insert" // 字符串转成对应一个整形值,因为整形才能取模算映射位置// 期望->字符串不同,转出的整形值尽量不同// "abcd" "bcad"// "abbb" "abca"size_t operator()(const string& s){// BKDR Hashsize_t value = 0;for (auto ch : s){value += ch;value *= 131;}return value;}};template<class K, class T, class KOFT, class Hash>struct HTIterator{public:typedef HTIterator<K, T, KOFT, Hash> Self;typedef HashNode<T> Node;typedef HashTable<K, T, KOFT, Hash> HT; //这里会往前找 找不到HashTable? 怎么办 Node* _node;const HT* _pht;HTIterator(Node* node, HT* pht):_node(node), _pht(pht){}T operator*(){return _node->_data;}T* operator->(){return &(_node->_data);}bool operator!=(const Self& s){return (_node != s._node);}Self& operator++(){if (_node->_next){//当前桶还有数据,走到下一个节点_node = _node->_next;}else{KOFT koft;Hash hash;//如果一个桶走完了,找到下一个桶继续遍历size_t index = hash(koft(_node->_data))%_pht->_tables.size();++index;/*for (; index < _pht->_tables.size(); ++index){Node* cur = _pht->_tables[index];if (cur){_node = cur;return *this;}}*/while (index < _pht->_tables.size()){_node = _pht->_tables[index];if (_node)break;else++index;}if(index==_pht->_tables.size())_node = nullptr;}return *this;}};template<class K, class T, class KOFT, class Hash>class HashTable {public://友元声明 template<class K, class T, class KeyOfT, class Hash>friend struct HTIterator;typedef HTIterator<K, T, KOFT, Hash> Iterator;typedef HashNode<T> Node;size_t HashFunc(K key){Hash hash;return hash(key);}Iterator begin(){if (_num == 0)return end();for (size_t i = 0; i < _tables.size(); ++i){if (_tables[i]){return Iterator(_tables[i],this);}}return end();}Iterator end(){return Iterator(nullptr,this);}~HashTable(){Clear();}void Clear(){for (size_t i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){Node* _next = cur->_next;delete cur;cur = _next;}}}pair<Iterator,bool> Insert(const T& data){KOFT koft;Hash hash;//增容 负载因子if (_num == _tables.size()){size_t newsize = (_tables.size() == 0 ? 10 : 2 * _num);vector<Node*> newtables;newtables.resize(newsize);for (int i = 0; i < _tables.size(); ++i){Node* cur = _tables[i];while (cur){size_t index = HashFunc(koft(cur->_data)) % newsize;Node* next = cur->_next;cur->_next = newtables[index];newtables[index] = cur;cur = next;}_tables[i] = nullptr;}_tables.swap(newtables);}//计算在表中的映射位置size_t index = HashFunc(koft(data))%_tables.size();Node* cur = _tables[index];//查找这个值在不在表中while (cur){if (koft(cur->_data) == koft(data)){return make_pair(Iterator(cur,this),false);}else{//头插到表中cur = cur->_next;}}Node* ret = new Node(data);ret->_next = _tables[index];_tables[index] = ret;_num++;return make_pair(Iterator(ret,this), true);}Iterator Find(const K& key){KOFT koft;size_t index = HashFunc(koft(key)) % _tables.size();Node* cur = _tables[index];while (cur){if (koft(cur->_data) == key){return Iterator(cur,this);}else{cur = cur->_next;}}return end();}bool Erase(const K& key){KOFT koft;size_t index = HashFunc(koft(key)) % _tables.size();Node* cur = _tables[index];Node* prev = nullptr;while (cur){if (koft(cur->_data) == key){if (prev == nullptr){_tables[index] = cur->_next;}else{prev->_next = cur->_next;}delete cur;_num--;return true;}else{prev = cur;cur = cur->_next;}}return false;}private:vector<Node*> _tables;size_t _num = 0;};
}unordered_set的模拟实现
namespace wxy {template<class K,class Hash=_Hash<K>>class unordered_set{public:struct SetOfT{const K& operator()(const K& key){return key;}};typedef typename HashTable<K,K,SetOfT,Hash>::Iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator, bool> insert(const K& key){return _ht.Insert(key);}private:HashTable<K,K,SetOfT,Hash> _ht;};void test_unorderedset(){unordered_set<int> s;s.insert(1);s.insert(5);s.insert(4);s.insert(2);unordered_set<int>::iterator it = s.begin();while (it != s.end()){cout << *it<< " ";++it;}cout << endl;}
}unordered_map的模拟实现
namespace wxy {template<class K, class V,class Hash=_Hash<K>>class unordered_map{struct MapOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};public:typedef typename HashTable<K,pair<K, V>,MapOfT, Hash>::Iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator,bool> insert(const pair<K,V>& kv){return _ht.Insert(kv);}V& operator[](const K& key){pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));return ret.first->second;}iterator Find(const K& key){return _ht.Find(key);}bool Erase(const K& key){return _ht.Erase(key);}private:wxy::HashTable<K, pair<K, V>, MapOfT,Hash> _ht;};void test_unorderedmap(){unordered_map<string, string> dict;dict.insert({ "sort", "排序" });dict.insert({ "sort", "排序" });dict.insert({ "left", "左边" });dict.insert({ "right", "右边" });dict["left"] = "左边,剩余";dict["insert"] = "插入";dict["string"];for (auto kv : dict){cout << kv.first << ":" << kv.second << endl;}cout << endl;}
}
相关文章:
【数据结构】哈希 ---万字详解
unordered系列关联式容器 在C98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到log_2 N,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。最好 的查询是,…...
)
4399大数据面试题及参考答案(数据分析和数据开发)
对数据分析的理解 数据分析是一个从数据中提取有价值信息以支持决策的过程。它涵盖了数据收集、清洗、转换、建模和可视化等多个环节。 首先,数据收集是基础。这包括从各种数据源获取数据,例如数据库、文件系统、网络接口等。这些数据源可以是结构化的数据,如关系型数据库中…...

快速理解倒排索引在ElasticSearch中的作用
一.基础概念 定义: 倒排索引是一种数据结构,用来加速文本数据的搜索和检索,和传统的索引方式不同,倒排索引会被每个词汇项与包含该词汇项的文档关联起来,从而去实现快速的全文检索。 举例: 在传统的全文…...

C++趣味编程玩转物联网:基于树莓派Pico控制无源蜂鸣器-实现音符与旋律的结合
无源蜂鸣器是一种多功能的声音输出设备,与有源蜂鸣器相比,它能够通过不同频率的方波生成丰富多样的音调。本项目使用树莓派Pico开发板,通过编程控制无源蜂鸣器播放经典旋律《归来有风》。本文将详细介绍项目实现中的硬件连接、C++代码解析,以及无源蜂鸣器的工作原理。 一、…...

《RuoYi基于SpringBoot+Vue前后端分离的Java快速开发框架学习》系列博客_Part4_三模态融合
系列博客目录 文章目录 系列博客目录目标Step1:之前工作形成子组件Step2:弥补缺失的文本子组件,同时举例如何子组件向父组件传数据Step3:后端代码需要根据上传的文件传给python服务器Step4:python服务器进行分析 目标 实现三模态融合,将文本、图片、音频…...

springboot365高校疫情防控web系统(论文+源码)_kaic
毕 业 设 计(论 文) 题目:高校疫情防控的设计与实现 摘 要 互联网发展至今,无论是其理论还是技术都已经成熟,而且它广泛参与在社会中的方方面面。它让信息都可以通过网络传播,搭配信息管理工具可以很好地为…...

STM32 USART串口数据包
单片机学习! 目录 前言 一、数据包 二、HEX数据包 三、文本数据包 四、HEX数据包和文本数据包优缺点 4.1 HEX数据包 4.2 文本数据包 五、HEX数据包接收 六、文本数据包接收 总结 前言 本文介绍了串口数据包收发的思路和流程。 一、数据包 数据包的作用是把一个个单独…...

【LC】3232. 判断是否可以赢得数字游戏
题目描述: 给你一个 正整数 数组 nums。 Alice 和 Bob 正在玩游戏。在游戏中,Alice 可以从 nums 中选择所有个位数 或 所有两位数,剩余的数字归 Bob 所有。如果 Alice 所选数字之和 严格大于 Bob 的数字之和,则 Alice 获胜。如果…...
Linux基础学习--vi与vim
0.绪论 前面的内容基本学完了相关命令行,后面进行shell与shell script的学习。第一部分就是编辑器的学习,之前有写过vi/vim编辑器,但是我看了一下鸟哥这个非常详细,还是打算重头学习一下。 1.vi/vim的使用 一般命令模式(command…...

JavaScript 高级教程:异步编程、面向对象与性能优化
在前两篇教程中,我们学习了 JavaScript 的基础和进阶内容。这篇文章将带领你进入更深层次,学习 JavaScript 的异步编程模型、面向对象编程(OOP),以及性能优化的技巧。这些内容对于构建复杂、流畅的前端应用至关重要。 …...

qt QToolBox详解
1、概述 QToolBox是Qt框架中的一个控件,它提供了一个带标签页的容器,用户可以通过点击标签页标题来切换不同的页面。QToolBox类似于一个带有多页选项卡的控件,但每个“选项卡”都是一个完整的页面,而不仅仅是标签。这使得QToolBo…...

翁知宜荣获“易学名师”与“国学文化传承人”称号
在2024年10月19日举行的北京第六届国学文化传承峰会上,翁知宜老师以其在易学界的卓越成就和对国学文化的传承与发扬,荣获“易学名师”和“国学文化传承人”两项荣誉称号。 翁知宜老师在易经学术竞赛中荣获第一名,其深厚的易学造诣和对玄学学…...

20241128解决Ubuntu20.04安装libwxgtk3.0-dev异常的问题
20241128解决Ubuntu20.04安装libwxgtk3.0-dev异常的问题 2024/11/28 16:17 缘起:中科创达的高通CM6125开发板的Android10的编译环境需要。 安装异常:rootrootrootroot-X99-Turbo:~$ rootrootrootroot-X99-Turbo:~$ sudo apt-get install libwxgtk3.0-de…...

sql分类
SQL(Structured Query Language)是一种用于管理和操作关系数据库管理系统(RDBMS)的编程语言。SQL 可以分为几个主要类别,每个类别都有其特定的用途和功能。以下是 SQL 的主要分类: 1. 数据定义语言&#x…...

stm32里一个定时器可以提供多路信号吗?
在STM32中,一个定时器通常只能提供一组信号(如输出PWM波形、定时中断等)。但是,定时器的多个通道可以提供不同的信号。例如,STM32的定时器可以通过不同的输出通道产生多种PWM信号,每个通道可以配置为不同的…...

Java安全—原生反序列化重写方法链条分析触发类
前言 在Java安全中反序列化是一个非常重要点,有原生态的反序列化,还有一些特定漏洞情况下的。今天主要讲一下原生态的反序列化,这部分内容对于没Java基础的来说可能有点难,包括我。 序列化与反序列化 序列化:将内存…...

2023考研王道计算机408数据结构+操作系统+计算机组成原理+计算机网络
from: https://blog.csdn.net/weixin_46118419/article/details/125611299 写得很好! 轻重缓急 2023考研计算机408【王-道计算机408】数据结构操作系统计算机组成原理计算机网络 网盘-链接:https://pan.baidu.com/s/13JraxUYwNVPeupdzprx5hA?pwd5h3d 提…...

YOLOv8-ultralytics-8.2.103部分代码阅读笔记-files.py
files.py ultralytics\utils\files.py 目录 files.py 1.所需的库和模块 2.class WorkingDirectory(contextlib.ContextDecorator): 3.def spaces_in_path(path): 4.def increment_path(path, exist_okFalse, sep"", mkdirFalse): 5.def file_age(path__fi…...

「Mac畅玩鸿蒙与硬件34」UI互动应用篇11 - 颜色选择器
本篇将带你实现一个颜色选择器应用。用户可以从预设颜色中选择,或者通过输入颜色代码自定义颜色来动态更改界面背景。该应用展示了如何结合用户输入、状态管理和界面动态更新的功能。 关键词 UI互动应用颜色选择器状态管理用户输入界面动态更新 一、功能说明 颜色…...

ELK(Elasticsearch + logstash + kibana + Filebeat + Kafka + Zookeeper)日志分析系统
文章目录 前言架构软件包下载 一、准备工作1. Linux 网络设置2. 配置hosts文件3. 配置免密登录4. 设置 NTP 时钟同步5. 关闭防火墙6. 关闭交换分区7. 调整内存映射区域数限制8. 调整文件、进程、内存资源限制 二、JDK 安装1. 解压软件2. 配置环境变量3. 验证软件 三、安装 Elas…...

Podgrab源码架构分析:深入理解Go语言播客管理工具的设计原理
Podgrab源码架构分析:深入理解Go语言播客管理工具的设计原理 【免费下载链接】podgrab A self-hosted podcast manager/downloader/archiver tool to download podcast episodes as soon as they become live with an integrated player. 项目地址: https://gitco…...

AsyncRun.vim 项目根目录管理:智能识别和高效利用
AsyncRun.vim 项目根目录管理:智能识别和高效利用 【免费下载链接】asyncrun.vim :rocket: Run Async Shell Commands in Vim 8.0 / NeoVim and Output to the Quickfix Window !! 项目地址: https://gitcode.com/gh_mirrors/as/asyncrun.vim AsyncRun.vim 是…...

AI技能学习路径全解析:从数学基础到RAG实战与项目构建
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“HieuNghi-AI-Skills”。光看这个名字,你可能会有点摸不着头脑,这到底是做什么的?是教AI新技能,还是整理AI工具的使用技巧?点进去之后&…...

大型机场U型机坪推出等待点运行优化【附案例】
✨ 长期致力于机场、U型机坪区、推出等待点、运行程序优化、启发式算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅如需沟通交流,点击《获取方式》 (1)单通道U型机坪推出等待点位优化…...
)
避坑指南:在CentOS 7.5上成功安装Ansys 19.2的完整流程(附字体问题终极解决方案)
CentOS 7.5与Ansys 19.2黄金组合:工业仿真环境搭建实战手册 在工程仿真领域,Ansys作为行业标准工具链的核心组件,其Linux环境部署一直是技术人员的痛点。经过长达三个月的多版本交叉测试,我们意外发现CentOS 7.5与Ansys 19.2的组合…...

华为OD机试真题 新系统 2026-05-06 JavaGoC语言 实现【匹配命令行前缀关键字】
目录 题目 思路 Code 题目 给定一组命令行字符串和一个命令前缀,需要找出所有以前缀开头的命令行表达式中,前缀之后的第一个关键字,并将这些关键字按字典序排序后返回。 如果找不到匹配前缀则返回空;匹配出多个相同关键字时只返…...
)
告别手动计算!用C#给ArcGIS做个插件,一键搞定城市风环境评估(附源码思路)
从零构建ArcGIS风环境评估插件:C#实战与架构设计 在建筑规划与城市设计中,风环境评估往往需要反复计算迎风面指数这类专业指标。传统工作流中,规划师需要手动处理风向数据、编写脚本批处理建筑网格,不仅效率低下,还容易…...
 Linux和Unix的关系 linux和Windows比较)
Linux 基础篇 -- Linux介绍(怎么读、是什么、创始人、吉祥物、发版本、目前存在的操作系统) Linux和Unix的关系 linux和Windows比较
Linux 基础篇 – Linux介绍(怎么读、是什么、创始人、吉祥物、发版本、目前存在的操作系统) & Linux和Unix的关系 & linux和Windows比较 文章目录 1. Linux介绍 1.1 Linux怎么读:1.2 Linux是什么:1.3 Linux创始人:1.4 Linux 的吉祥…...
)
别再只用VGG19做分类了!手把手教你用PyTorch提取4096维图像特征向量(实战教程)
突破分类局限:用PyTorch解锁VGG19的深度特征提取实战 当你第一次接触VGG19时,可能被它的ImageNet分类能力所震撼。但如果你只把它当作一个分类器,那就如同用瑞士军刀只开瓶盖——大材小用。在计算机视觉领域,预训练模型真正的价值…...

别再只搜WOL教程了!华硕/微星主板BIOS里这两个隐藏选项没开,魔术包收到也白搭
华硕/微星主板WOL终极配置指南:破解BIOS隐藏选项的实战手册 深夜加班后想远程唤醒家里的台式机渲染视频,却发现魔术包石沉大海?你可能已经按照无数教程配置了网卡唤醒选项,却忽略了主板BIOS里那两个致命的隐藏开关。本文将用实验室…...