对于大规模的淘宝API接口数据,有什么高效的处理方法?
1.数据分批处理
- 原理:当处理大规模数据时,一次性将所有数据加载到内存中可能会导致内存溢出。将数据分成较小的批次进行处理可以有效避免这个问题。
- 示例代码:假设通过淘宝 API 获取到了一个包含大量商品详情的 JSON 数据列表,每个元素代表一个商品的信息。可以使用如下代码进行分批处理:
import json# 假设这是从淘宝API获取的大规模数据(模拟数据) api_data_str = '[{"product_id": "1", "name": "商品1",...}, {"product_id": "2", "name": "商品2",...},...]' api_data_list = json.loads(api_data_str) batch_size = 100 for i in range(0, len(api_data_list), batch_size):batch = api_data_list[i:i + batch_size]# 在这里对每一批数据进行处理,比如打印商品名称for product in batch:print(product.get("name"))2.使用多线程或多进程
- 原理:多线程或多进程可以充分利用计算机的多核处理器,同时处理多个数据块,从而加快数据处理速度。多线程适用于 I/O 密集型任务(如网络请求、文件读取等),多进程适用于 CPU 密集型任务。
- 示例代码 - 多线程:
import json import threadingapi_data_str = '[{"product_id": "1", "name": "商品1",...}, {"product_id": "2", "name": "商品2",...},...]' api_data_list = json.loads(api_data_str) lock = threading.Lock() def process_batch(batch):# 在这里对每一批数据进行处理,加锁是为了避免多个线程同时访问共享资源产生冲突with lock:for product in batch:print(product.get("name")) num_threads = 4 batch_size = len(api_data_list) // num_threads threads = [] for i in range(0, len(api_data_list), batch_size):batch = api_data_list[i:i + batch_size]thread = threading.Thread(target=process_batch, args=(batch,))thread.start()threads.append(thread) for thread in threads:thread.join()示例代码 - 多进程(需要注意进程间通信和资源共享的复杂性):
import json import multiprocessingapi_data_str = '[{"product_id": "1", "name": "商品1",...}, {"product_id": "2", "name": "商品2",...},...]' api_data_list = json.loads(api_data_str) def process_batch(batch):for product in batch:print(product.get("name")) num_processes = 4 batch_size = len(api_data_list) // num_processes processes = [] for i in range(0, len(api_data_list), batch_size):batch = api_data_list[i:i + batch_size]process = multiprocessing.Process(target=process_batch, args=(batch,))process.start()processes.append(process) for process in processes:process.join()3.使用数据库存储中间结果
- 原理:如果在处理数据过程中需要保存中间结果,或者需要对数据进行复杂的查询和筛选,将数据存储到数据库中是一个很好的选择。可以使用关系型数据库(如 MySQL、PostgreSQL)或非关系型数据库(如 MongoDB)。
- 示例代码 - 使用 MongoDB 存储数据(需要安装 pymongo 库):
import json import pymongoapi_data_str = '[{"product_id": "1", "name": "商品1",...}, {"product_id": "2", "name": "商品2",...},...]' api_data_list = json.loads(api_data_str) client = pymongo.MongoClient("mongodb://localhost:27017/") db = client["taobao_data"] collection = db["products"] collection.insert_many(api_data_list) # 从数据库中读取数据进行后续处理,例如查询价格大于某个值的商品 query_result = collection.find({"price": {"$gt": 100}}) for product in query_result:print(product.get("name"))4.数据过滤和预处理
- 原理:在处理大规模数据之前,先对数据进行过滤和预处理,只保留需要的信息,可以减少数据量,提高处理效率。例如,如果只关心商品的价格和销量信息,可以在解析数据时只提取这两个字段。
- 示例代码:
import jsonapi_data_str = '[{"product_id": "1", "name": "商品1", "price": 10, "sales": 100}, {"product_id": "2", "name": "商品2", "price": 20, "sales": 200}]' api_data_list = json.loads(api_data_str) filtered_data = [] for product in api_data_list:filtered_product = {"price": product.get("price"), "sales": product.get("sales")}filtered_data.append(filtered_product) # 对过滤后的数据集进行处理 for product in filtered_data:print(product.get("price"), product.get("sales"))
相关文章:

对于大规模的淘宝API接口数据,有什么高效的处理方法?
1.数据分批处理 原理:当处理大规模数据时,一次性将所有数据加载到内存中可能会导致内存溢出。将数据分成较小的批次进行处理可以有效避免这个问题。示例代码:假设通过淘宝 API 获取到了一个包含大量商品详情的 JSON 数据列表,每个…...

openharmony 使用uvc库获取摄像头数据使用nativewindow显示
界面代码: XComponent({ id: xcomponentId, type: texture, libraryname: entry }).width(800).height(500) Natvie代码: 1、头文件 //NativeWindow #include <ace/xcomponent/native_interface_xcomponent.h> #include <cstdint> #incl…...

SQL Server 实战 - 多种连接
目录 背景 一、多种连接 1. 复合连接条件 2. 跨数据库连接 3. 隐连接 4. 自连接 5. 多表外连接 6. UNION ALL 二、一个对比例子 背景 本专栏文章以 SAP 实施顾问在实施项目中需要掌握的 sql 语句为偏向进行选题: 用例:SAP B1 的数据库工具&am…...

【手术显微镜】市场高度集中,由于高端手术显微镜的制造技术主要掌握于欧美企业
摘要 HengCe (恒策咨询)是全球知名的大型咨询机构,长期专注于各行业细分市场的调研。行业层面,重点关注可能存在“卡脖子”的高科技细分领域。企业层面,重点关注在国际和国内市场在规模和技术等层面具有代表性的企业,…...

IDEA 2024 配置Maven
Step 1:确定下载Apache Maven版本 在IDEA 2024中,随便新建一个Maven项目; 在File下拉菜单栏中,找到Setings; 在Build,Execution,Deployment中找到Maven 确定下载的Apache Maven版本应略低于或等于IDEA绑…...

Admin.NET框架使用宝塔面板部署步骤
文章目录 Admin.NET框架使用宝塔面板部署步骤🎁框架介绍部署步骤1.Centos7 部署宝塔面板2.部署Admin.NET后端3.部署前端Web4.访问前端页面 Admin.NET框架使用宝塔面板部署步骤 🎁框架介绍 Admin.NET 是基于 .NET6 (Furion/SqlSugar) 实现的通用权限开发…...

Flutter中的Future和Stream
在 Flutter 中,Future 和 Stream 都是用于处理异步操作的类,它们都基于 Dart 的异步编程模型,但是它们的使用场景和工作方式有所不同。以下是它们的区别以及各自适用的场景。 目录 一、Future1、基本使用2、异常处理1. catchError2. onError…...

107.【C语言】数据结构之二叉树求总节点和第K层节点的个数
目录 1.求二叉树总的节点的个数 1.容易想到的方法 代码 缺陷 思考:能否在TreeSize函数内定义静态变量解决size的问题呢? 其他写法 运行结果 2.最好的方法:分而治之 代码 运行结果 2.求二叉树第K层节点的个数 错误代码 运行结果 修正 运行结果 其他写法 1.求二…...

spring boot支持那些开发工具?
Spring Boot 支持多种开发工具,以帮助开发者更高效地进行应用开发。以下是小编给大家分享几种常用的开发工具及其特点: IntelliJ IDEA: IntelliJ IDEA 是一款非常流行的 Java IDE,它提供了对 Spring Boot 的全面支持,…...

Go-MediatR:Go语言中的中介者模式
在Go语言中,确实存在一个与C#中的MediatR类似的组件包,名为Go-MediatR。 Go-MediatR是一个受.NET中MediatR库启发的Go语言实现,它专注于通过中介者模式简化命令查询责任分离(CQRS)模式的处理和在事件驱动架构中的应用…...

5.11【机器学习】
先是对图像进行划分 划分完后, 顺序读取文件夹,在文件夹里顺序读取图片, 卷积层又称为滤波器,通道是说滤波器的个数,黑白通道数为1,RGB通道个数为3 在输入层,对于输入层而言,滤波…...

在 CentOS 上安装 Docker:构建容器化环境全攻略
一、引言 在当今的软件开发与运维领域,Docker 无疑是一颗璀璨的明星。它以轻量级虚拟化的卓越特性,为应用程序的打包、分发和管理开辟了崭新的高效便捷之路。无论是开发环境的快速搭建,还是生产环境的稳定部署,Docker 都展现出了…...
)
Python练习(2)
重复元素判定续。利用集合的无重复性来编写一个程序如果有一个元素出现了不止一次则返回true但不要改变原来列表的值: 一: def has_duplicates(lst): # 使用集合来存储已经见过的元素 seen set() for item in lst: if item in seen: # 如果元素已经在…...
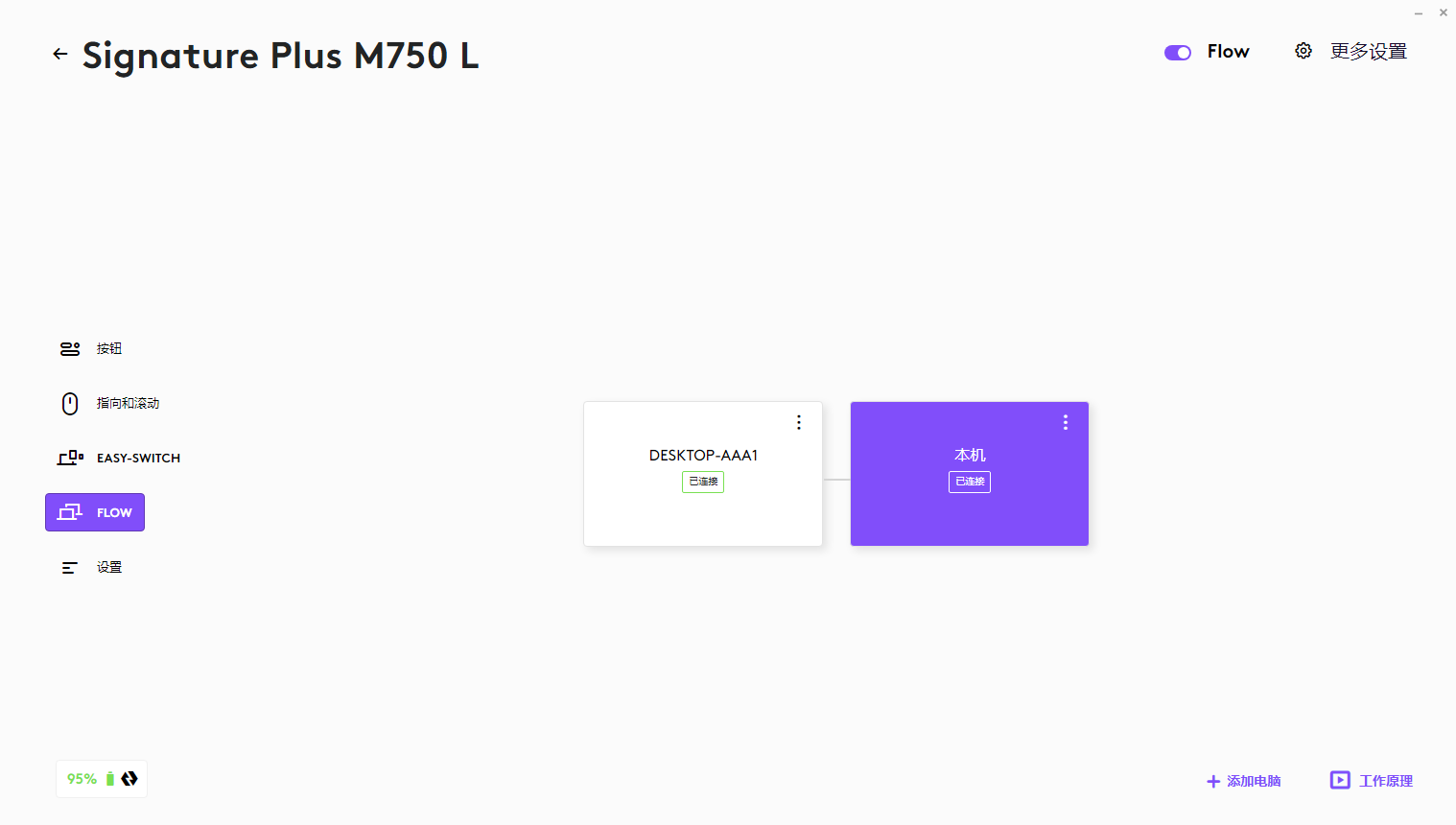
如何实现一套键盘鼠标控制两台计算机(罗技Options+ Flow功能快速实现演示)
需求背景 之前我写过一篇文章如何实现一套键盘鼠标控制两台计算机(Mouse Without Borders快速上手教程)_一套键鼠控制两台电脑-CSDN博客 当我们在局域网内有两台计算机,想使用一套键鼠操控时,可以安装Mouse Without Borders软件…...

现代应用程序中基于 Cell 架构的安全防护之道
在飞速发展的软件开发领域,基于 Cell 的架构日益流行起来。其概念源自船舶舱壁的设计准则,即单独的水密舱室能允许故障孤立存在。通过将这个概念应用于软件,我们创建了一个架构,将应用程序划分为离散的、可管理的组件,…...

【导航查询】.NET开源 ORM 框架 SqlSugar 系列
.NET开源 ORM 框架 SqlSugar 系列 【开篇】.NET开源 ORM 框架 SqlSugar 系列【入门必看】.NET开源 ORM 框架 SqlSugar 系列【实体配置】.NET开源 ORM 框架 SqlSugar 系列【Db First】.NET开源 ORM 框架 SqlSugar 系列【Code First】.NET开源 ORM 框架 SqlSugar 系列【数据事务…...

【基础分析】——Qt 信号和槽的机制 优点
QT信号和槽机制的优点包括: 1、类型安全: 信号和槽的签名必须是等同的,即信号的参数类型和参数个数必须与接收该信号的槽的参数类型和参数个数相同。 2、松散耦合: 信号和槽机制减弱了Qt对象的耦合度。激发信号的Qt对象无须知道…...

Vue3学习宝典
1.ref函数调用的方式生成响应式数据,可以传复杂和简单数据类型 <script setup> // reactive接收一个对象类型的数据 import { reactive } from vue;// ref用函数调用的方式生成响应式数据,可以传复杂和简单数据类型 import { ref } from vue // 简…...

leecode96.不同的二叉搜索树
在画的过程中发现规律,每次选择不同的节点作为根节点,左右两边的节点再排列组合一下就能求出总数 class Solution { public:int numTrees(int n) {vector<int> dp(n1,0);dp[0]1;for(int i1;i<n;i)for(int j0;j<i;j)dp[i]dp[i-j-1]*dp[j];ret…...

树莓派基本配置-基础配置配置
树莓派基本配置 文章目录 树莓派基本配置前言硬件准备树莓派刷机串口方式登录树莓派接入网络ssh方式登录树莓派更换国内源xrdp界面登录树莓派远程文件传输FileZilla 前言 树莓派是一款功能强大且价格实惠的小型计算机,非常适合作为学习编程、物联网项目、家庭自动化…...

为什么头部科技公司集体弃用Workday转向Lindy?——基于14家客户迁移数据的自动化人效拐点分析
更多请点击: https://intelliparadigm.com 第一章:Lindy人力资源自动化方案的演进逻辑与战略定位 Lindy人力资源自动化方案并非孤立的技术堆叠,而是根植于企业数字化成熟度跃迁与HR职能价值重构双重驱动下的系统性进化。其演进逻辑呈现清晰的…...

3步掌握AI图像分层:零基础快速入门指南
3步掌握AI图像分层:零基础快速入门指南 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 想象一下,你手中有一张精美的插画…...

WinCC Runtime Advanced项目实战:从TIA Portal组态到PC Station部署的完整流程解析
WinCC Runtime Advanced项目实战:从TIA Portal组态到PC Station部署的完整流程解析 在工业自动化领域,HMI系统的部署往往是项目落地的最后关键一步。对于习惯了传统HMI硬件的工程师来说,首次接触基于PC的WinCC Runtime Advanced解决方案时&a…...

Play Integrity API Checker:三步快速检测你的Android设备安全完整指南 [特殊字符]
Play Integrity API Checker:三步快速检测你的Android设备安全完整指南 🔐 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-i…...

DownKyi完整教程:如何快速下载B站8K超高清视频的终极指南
DownKyi完整教程:如何快速下载B站8K超高清视频的终极指南 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&am…...
3步搞定日语Galgame翻译的终极方案:TsubakiTranslator完全指南
3步搞定日语Galgame翻译的终极方案:TsubakiTranslator完全指南 【免费下载链接】TsubakiTranslator 一款Galgame文本翻译工具,支持Textractor/剪切板/OCR翻译 项目地址: https://gitcode.com/gh_mirrors/ts/TsubakiTranslator 还在为看不懂日语Ga…...

硬件性能突破:免费AMD处理器调试工具SMUDebugTool终极指南
硬件性能突破:免费AMD处理器调试工具SMUDebugTool终极指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:…...

ARM编译器符号排列机制解析与工程实践
1. ARM编译器符号排列机制深度解析在嵌入式开发中,全局常量的内存布局往往会对系统行为产生微妙影响。最近在将项目从ARMCC v5迁移到ARMCLANG v6时,我遇到了一个有趣的差异现象:相同源代码中的const数组,在两个工具链中竟然产生了…...

手把手教你把Windows虚拟内存文件pagefile.sys从C盘挪走,给SSD系统盘腾出几十G空间
彻底解放C盘空间:Windows虚拟内存文件迁移全指南 你是否遇到过这样的场景:刚装完系统时C盘还剩下大半空间,用着用着却突然弹出"磁盘空间不足"的警告?打开资源管理器一看,一个名为pagefile.sys的"巨无霸…...

开发靠 AI 提效,测试成最大瓶颈,现状过于真实
📝 面试求职: 「面试试题小程序」 ,内容涵盖 测试基础、Linux操作系统、MySQL数据库、Web功能测试、接口测试、APPium移动端测试、Python知识、Selenium自动化测试相关、性能测试、性能测试、计算机网络知识、Jmeter、HR面试,命中…...