腾讯云流式湖仓统一存储实践
点击蓝字⬆ 关注我们
本文共计5107 预计阅读时长16分钟
*
本文将分享腾讯云流式湖仓的架构与实践。主要内容包括:
流计算Oceanus介绍
腾讯云流式湖仓架构
腾讯云流式湖仓实践
腾讯云流式湖仓发展规划
一、流计算Oceanus介绍
随着大数据技术的发展,客户对实时处理与分析需求日益增长,实时数据分析已成为驱动业务创新、提升竞争力的关键要素。传统批处理方式存在时效性差、数据孤岛、难以扩展等问题,因此需要实时计算来弥补。

腾讯云流计算基于开源的Apache Flink搭建,作为腾讯云大数据产品中的实时链路,是企业级实时大数据平台,具备一站式开发、5秒无缝衔接、亚秒延迟、低成本、安全稳定等特性。
二、腾讯云流式湖仓架构
接下来进入本次分享的核心部分,详细介绍腾讯云流式湖仓解决方案。
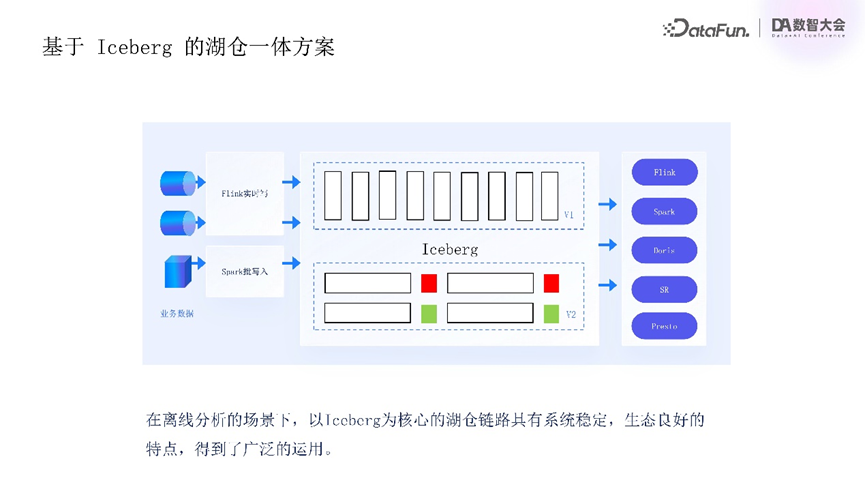
首先来介绍基于Iceberg的湖仓一体化基础方案,该方案以Iceberg为核心,其生态稳定,能提供强大的表管理与数据组织能力,支持大规模数据集高效处理,即便海量数据场景也可稳定运行,且生态集成良好,与主流大数据计算引擎(如Spark、Flink、Presto等)无缝对接,在腾讯云内部与DLC、EMR等大数据产品深度结合。Iceberg湖仓链路可以覆盖从实时流处理到离线批处理的完整数据链路,在腾讯云内部广泛应用于离线分析场景,因此腾讯云流式湖仓基于Iceberg设计。
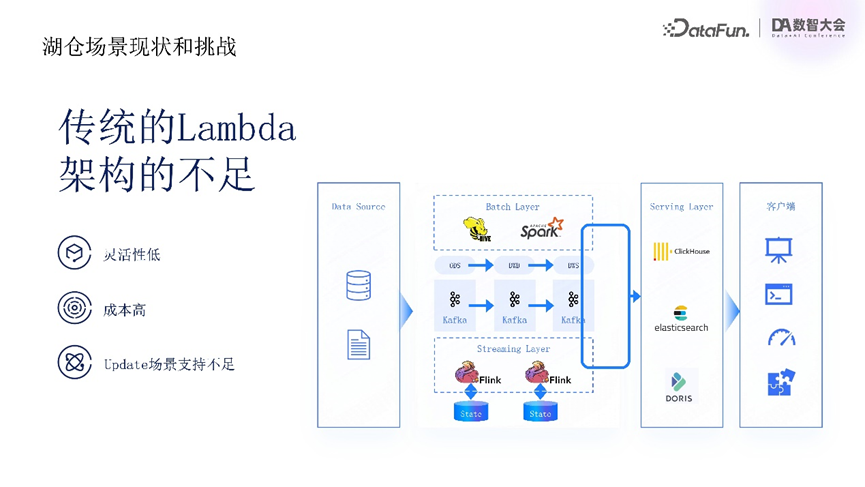
回顾大数据链路发展,除离线链路外,许多客户都有实时链路需求。传统上,实时与离线业务客户常用Lambda架构搭建实时分析链路。在Lambda架构中,离线与实时链路分离,离线链路数据存储于Iceberg等离线存储引擎,后用Spark进行多层数据转换。在时效需求不高时,在数据规模支持与成本方面有优势。但随着实时场景增加,单一Iceberg方式难以满足业务需求,客户常采用Flink加Kafka方式构建实时分层链路,数据最终写入数据仓库或主流数据库(如CK、Doris等)。此链路虽可实现秒级延迟,但存在诸多问题。
其一,灵活性低,Kafka仅作数据管道,无法应用于数据探索、分析场景,且不能保存较长历史数据,限制用户使用灵活性,导致数据处理问题排查困难。
其二,成本高,实时链路单独存在,Kafka与Flink对state维护及存储计算资源需求大,导致成本较高。
其三,对update场景支持不足,Kafka写入非完整change log流时,后续接入Fink作业进行流式处理困难,虽Flink提供upset Kafka解决,但依赖本地状态存储,成本较高。
此外,Lambda架构将离线与实时链路、存储及计算引擎隔离,相同数据需多次重复存储,实时与离线计算逻辑需单独开发,维护、管理及业务变更成本高,因此需要新的架构来统一实时与离线分析链路,降低成本。
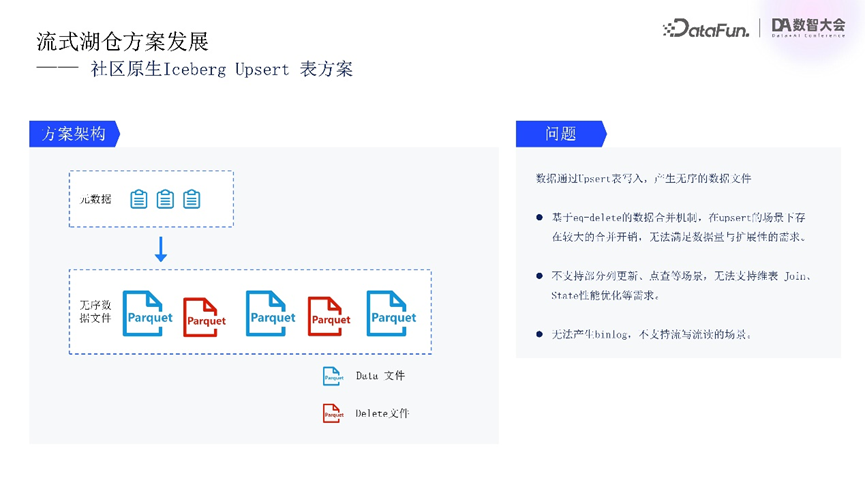
基于此,内部调研了社区原生Iceberg Upsert表方案,发现其存在一些问题。如Iceberg通过upsert表写入数据时,产生的数据是无序的,数据管理面临挑战。基于EQ DELETE的数据合并机制,在update场景下会产生非常大的合并开销,无法满足高数据量与扩展性需求。且无法支持点查与部分列更新功能,不能满足维表join和性能优化的需求。同时,该链路缺乏生成binlog的能力,无法适应流式写入与流读场景,限制了其在实时链路中的有效性。
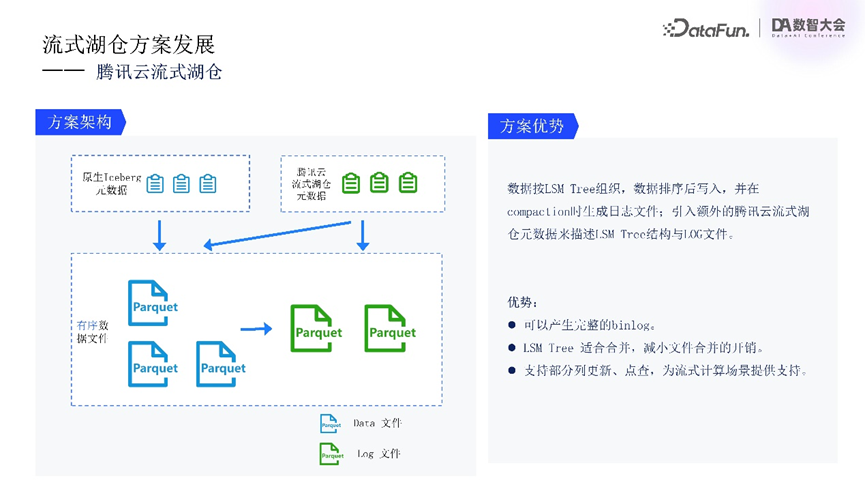
针对这些问题,我们设计了全新的流式湖仓架构。该架构引入了LSM Tree来组织数据,解决数据无序问题。先排序再写入,确保高效的数据管理。Compaction过程中生成逻辑日志文件,并引入了额外的元数据描述LSM Tree结构与日志文件关系。
该方案的优势包括,可生成完整binlog,增强对实时数据流支持;LSM Tree自身的合并特性,可以减少数据合并开销,提升系统性能;支持部分列更新与点查功能,为后续state优化与增量计算方案提供了基础。
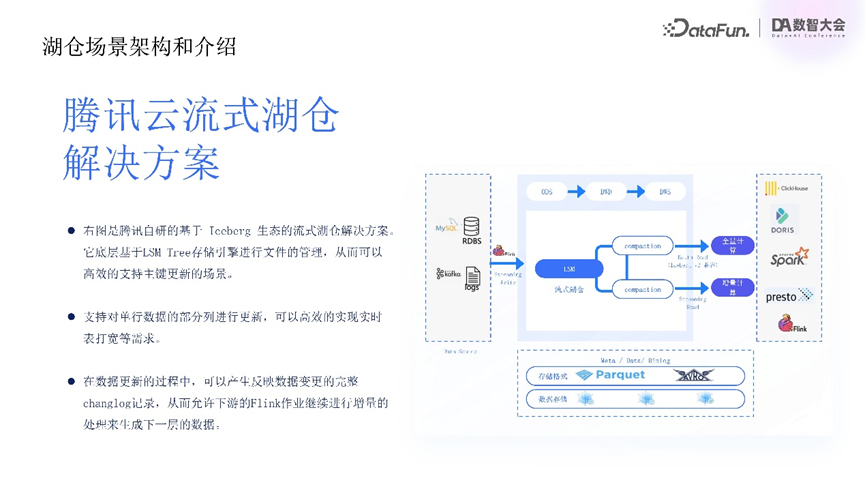
基于Iceberg生态的流式湖仓解决方案,采用了LSM Tree进行存储管理,支持高效逐行更新场景,数据写入时通过增强数据合并优化效率,支持单行数据部分列更新,使用户能够精准管理数据变更,应对复杂业务需求。流式湖仓可在数据处理过程中生成完整的change log记录,为下游(如Flink)提供支持,使增量处理与实时数据流管理成为可能。下游Flink作业可基于变更记录生成下一层数据,实现流式数据的高效管理。整体方案增强了数据的实时性与灵活性,提供了一体化流式湖仓体验。
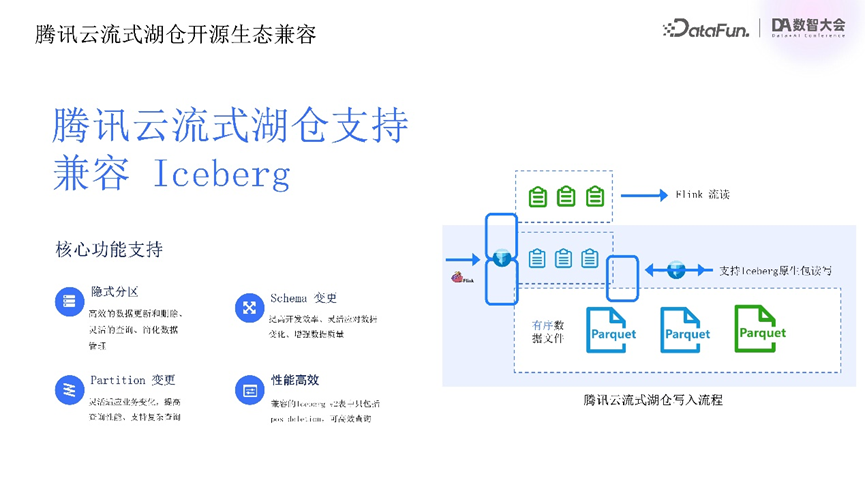
从整体架构看,流式湖仓方案基于开源Iceberg生态建设,天然支持Iceberg兼容能力。如上图所示,蓝框部分为普通Iceberg写入,Flink写入数据并生成快照时生成Iceberg元数据。
腾讯云流式湖仓写入流程中,数据除先排序外,格式与原生Iceberg相同,生成原生元数据时,同时生成两份元数据。一份是调用原生Iceberg包生成的兼容元数据,与开源Iceberg社区完全一致,支持Iceberg主要功能(如影视分区、schema变更、partition变更等)及所有版本系统高效支持;另一份是湖仓原生元数据,包含LSM tree结构与逻辑日志文件等原生不支持信息,支持额外性能优化与流读场景。借助数据合并能力,生成的Iceberg表不含EQ DELETE记录,可高效读取。
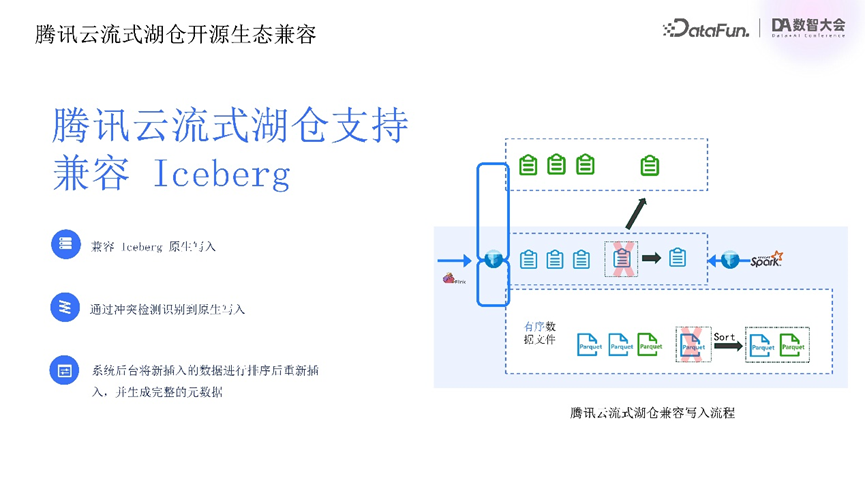
支持用户基于Iceberg原生客户端数据写入能力,实现无缝集成与多数据源接入。其原理为客户通过原生客户端写入数据后,先在兼容元数据版本中生成新快照记录,系统定时任务或下次数据提交时,通过冲突检测识别新提交快照中的新增数据文件,提取并重新排序插入LSM tree的L0层,在兼容与流式湖仓元数据中重复提交,分别生成完整snapshot实现数据的正式提交。
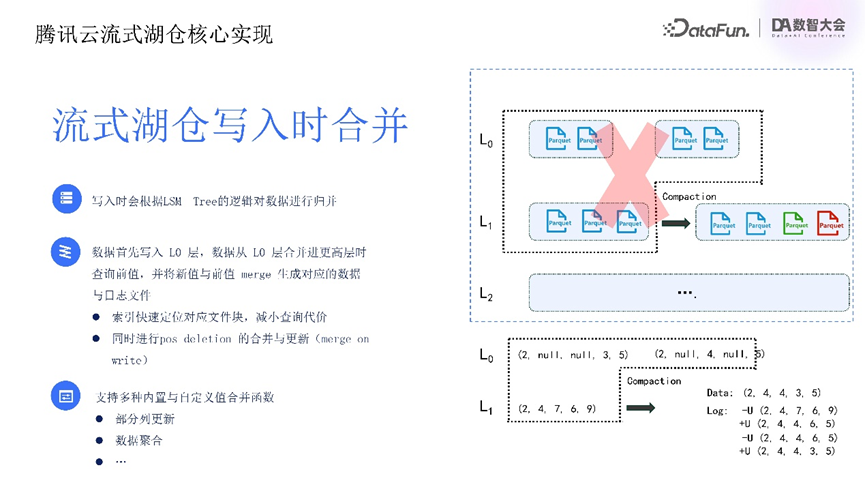
基于LSM Tree的流式湖仓在写入过程中进行数据合并操作,确保数据准确有序及一致性,为后续数据读取提供性能保障。整体采用universal compaction策略平衡读写放大,保证全局有序并减少文件数量。
数据从L0层首次合并至L0层以上时,系统查询现有文件中相同组件前值,与新写入值合并生成binlog,更新现有pos deletion记录。为提升合并性能,引入了索引定位数据位置,并且在本地增加了热点文件缓存,以提升索引与合并性能。
支持pos deletion合并与更新,优化数据更新性能,系统支持内置与自定义值合并函数,应对不同业务需求,并实现了部分列更新与点查能力,丰富数据链路处理能力,满足复杂场景需求。
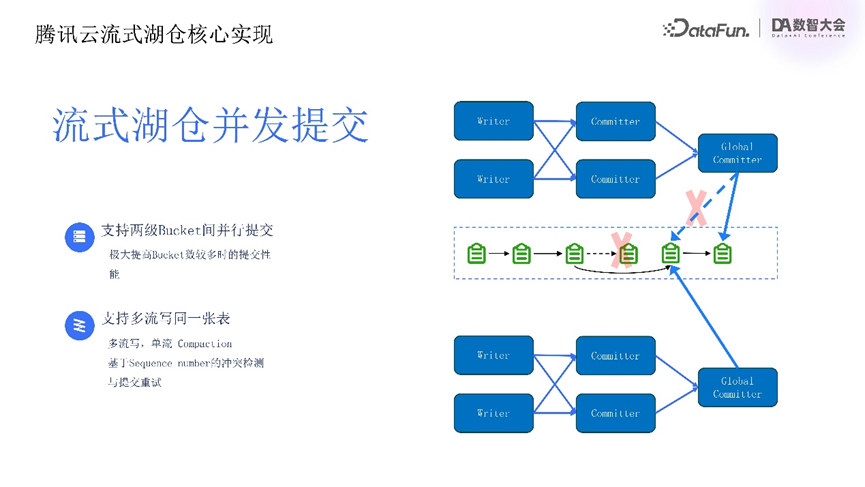
除数据合并外,流式湖仓在数据并发提交方面也有实现。数据文件写入后,流式湖仓通过提交生成众多源数据文件,在提交部分进行了并发提交优化,以提升性能。对比传统Iceberg单一节点完成snapshot生成,流式湖仓采用两阶段提交流程。多bucket需要提交时,commit算子并行完成所分配bucket源数据文件更新与历史文件合并操作,生成bucket级别的元数据文件后,由全局global committer算子完成快照生成。此设计在bucket较多时可显著提高数据提交性能,避免数据提交过程中的OM情况,保证高效数据处理。同时支持多流写入同一表,多个数据流可同时写入,结合部分列更新能力,实现类似多流join的效果。多流写入同一表时,每个流写入并提交,需保证写入快照可序列化,采用基于sequence number的冲突检测与提交重试机制。每次提交时,若发现更新快照,对应流需合并之前提交文件变化与最终快照并重新提交,确保数据一致性。此提交创新提高流式湖仓高并发场景性能,为用户提供灵活高效的数据管理体验。在该场景下,一般采用多流单流compaction方式实现数据合并,避免多流compaction冲突,优化数据合并与整理过程,保证数据高效存储与快速访问。

在CDC优化方面,CDC入湖是流式湖仓架构关键部分。流式湖仓架构中,客户先将业务数据同步至腾讯云流式湖仓,CDC是常用实时数据抽取方法,可及时捕捉原系统数据变化并传输至目标系统,保证数据实时性与一致性。在CDC过程中,提供整库同步能力,便于客户迁移数据库数据至流式湖仓,系统支持自动表结构变更,简化了数据同步管理操作,用户可轻松应对数据库schema调整。
具体实现中,CDC采用高效at-least-once数据同步模式,即便网络波动或系统故障,也能确保数据至少传输一次,避免丢失,通过目标端upsert功能保证端到端一致性,即数据传输中重复时,目标端可通过upsert操作更新已有数据,避免冗余与不一致。
在存量数据同步阶段,进行了显著优化,通过改进同步机制,经内部性能测试,实现了与开源相比10倍以上性能提升,体现在数据传输速度与系统资源占用上,同步大规模数据时可显著减少系统延迟与资源占用。
总体而言,CDC场景优化提升了数据同步效率与一致性,可为企业提供可靠的实时数据同步解决方案,从而更好地应对大规模数据管理与分析需求。
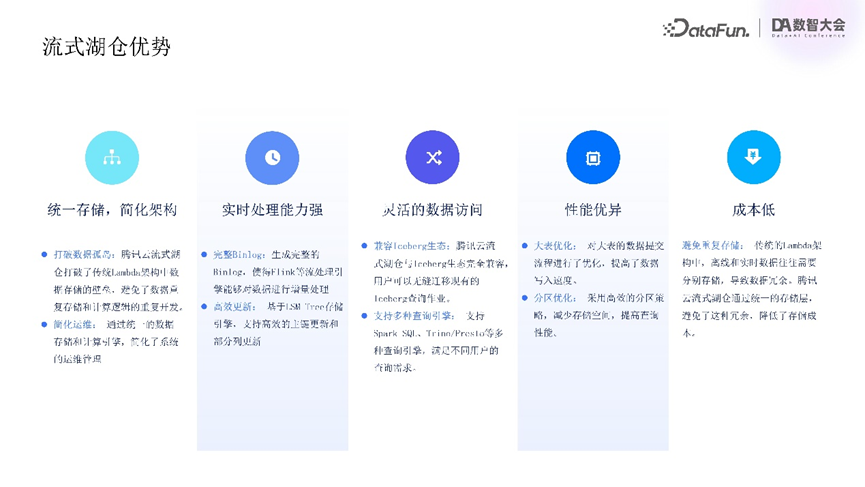
腾讯云流式湖仓的主要优势包括:
其一,统一存储,可简化离线与实时两套链路架构,打破传统Lambda架构数据存储壁垒,避免业务数据重复存储与不同引擎计算逻辑重复开发,通过统一数据存储与计算引擎可简化系统运维管理,降低运维成本。
其二,具有较强的实时处理能力,可生成完整changelog,使流处理引擎(如Flink)可对数据进行增量处理,保证实时数据实时性,基于RSM Tree引擎支持高效组件更新与部分列更新,以满足业务快速响应需求。
其三,数据访问灵活,基于开源Iceberg架构,与Iceberg生态完全兼容,支持无缝迁移现有Iceberg作业,支持Spark SQL、Trainer、Presto等多种查询引擎,可满足不同客户查询需求。
其四,性能优化,对大表数据提交流程进行了优化,提高了写入速度,采用高效分区策略,可减少存储空间,提高查询性能。
其五,成本低,通过实现存储与计算引擎统一,可避免数据冗余,降低企业成本。
三、腾讯云流式湖仓实践
腾讯流式湖仓方案广泛应用于多个行业与场景,如游戏、出行、教育、电商等。
以游戏行业为例,可实时采集玩家行为数据,反馈给开发团队,从而快速调整游戏内容、优化用户体验,通过实时湖仓增量处理数据,了解玩家偏好,推出个性化活动与推荐,增强用户粘性。
出行行业中,提供实时数据分析能力,监控交通流量与用户实时出行需求,动态调整车辆分配与路线规划,减少等待时间,提升服务质量,通过整合历史与实时数据预测需求高峰,优化调度资源配置,提升运营效率。
教育行业可在直播场景下跟踪学生学习进度,基于数据提供个性化教学建议。
电商行业通过流式湖仓帮助商家分析用户画像,实时监测行为数据,调整推荐算法与营销策略,快速适应市场变化,优化促销活动。
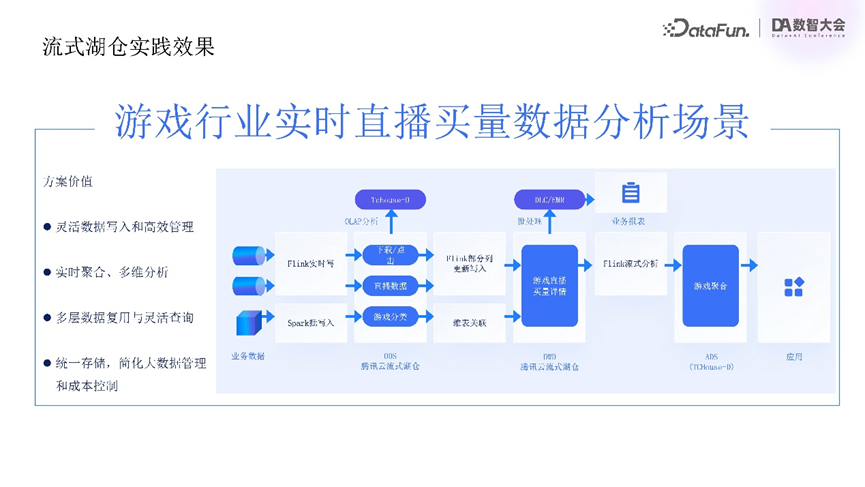
在基于腾讯流式湖仓的游戏行业实时直播买量数据分析场景中,用户链路为通过Flink或Spark将业务数据导入腾讯流式湖仓并实时整合。如玩家在游戏直播中点击、下载等互动行为数据与游戏分类等相关数据实时汇总,通过流式湖仓架构实时收集并分析。用户行为数据聚合到ODS层,小文件合并等治理操作可以保证查询准确性与高效性。流式湖仓的每一层可通过Doris关联外表进行OLAP分析,实现数据多次复用,也可通过DRC、MR中的Spark、Presto等引擎进行离线业务报表计算。
通过该案例可以展现出腾讯云流式湖仓的诸多优势,如灵活的数据写入与高效管理。直播中用户互动数据以实时或批量方式同步,系统根据业务需求灵活处理不同更新频率。批量数据写入时,Iceberg可自动完成小文件合并等优化操作,确保系统性能不因小文件过多而下降。还可进行实时聚合与多维分析,ODS层聚合数据通过流式湖仓生成changelog,经Flink进一步处理,如游戏直播下载与点击数据与用户信息、游戏分类等维表关联生成宽表,实现更深入实时分析,监控用户行为趋势,优化广告投放策略与直播内容,同时也可以通过部分列更新能力提高系统效率。
此外,多层数据复用与灵活查询,在流式湖仓架构中的每一层可多种方式分析计算,全面复用链路数据,如分析直播中历史行为数据,用Spark引擎离线处理并决策分析。
最后,统一存储简化了大数据管理,实现了成本控制,游戏行业需实时响应用户行为与离线分析历史数据,传统架构较为复杂,而流式湖仓实现了离线与实时链路统一,可避免重复存储与复杂系统维护。
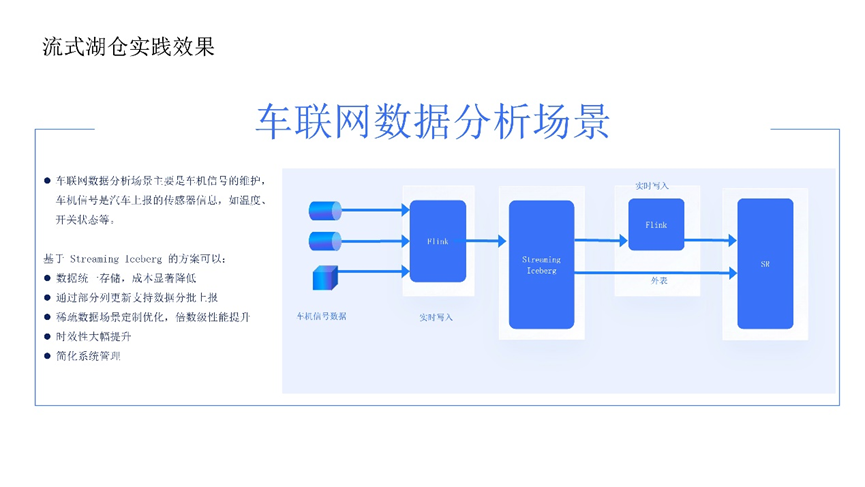
针对车企与出行行业的车联网场景,需要分析运行过程中的车机信号,这些信号由车辆传感器上报,可能分批次上传,涉及大量数据更新操作。
客户早期使用传统架构,采用HBase加Hive链路,HBase用于快速检索,满足车辆上报场景下对单辆车特定信号快捷分析需求,但保存数据有限,无法长期管理;Hive用于离线分析,生成全面历史性报告,但分析延迟高,只能达到小时级。
客户痛点为储存成本高,同一数据在HBase与Hive中重复存储,受系统储存性能限制,成本较高;另外,时效性不够,基于Hive的离线分析在车辆运行出现问题需快速了解分析结果时,延时较高。
引入腾讯云流式湖仓方案后,数据采用Iceburg统一存储,既具备传统HBase按key查询的能力,又可以满足实时检索需求,也可实现离线分析能力,从而降低数据储存成本。流式湖仓还可实现实时增量计算,支持生成binlog能力,系统可以捕捉数据实时变更,将计算逻辑转换为增量计算,数据上报时无需等待批量处理结束,即可实时计算更新分析结果,提高分析实时性,在紧急业务场景(如故障发生)下可分钟级获取分析结果,未来有望优化至秒级。同时,系统管理优化,统一存储与计算。
四、腾讯云流式湖仓发展规划
最后简单分享一下后续发展规划。

腾讯云流式湖仓基于Iceberg生态系统,除了Iceberg之外,市面上还有其它一些优秀的湖格式。我们后续会考虑兼容Paimon,通过Paimon Adapter写入腾讯云流式湖仓中。同时会在稀疏数据场景、数据提交、合并检索加速等方面提供额外的优势。
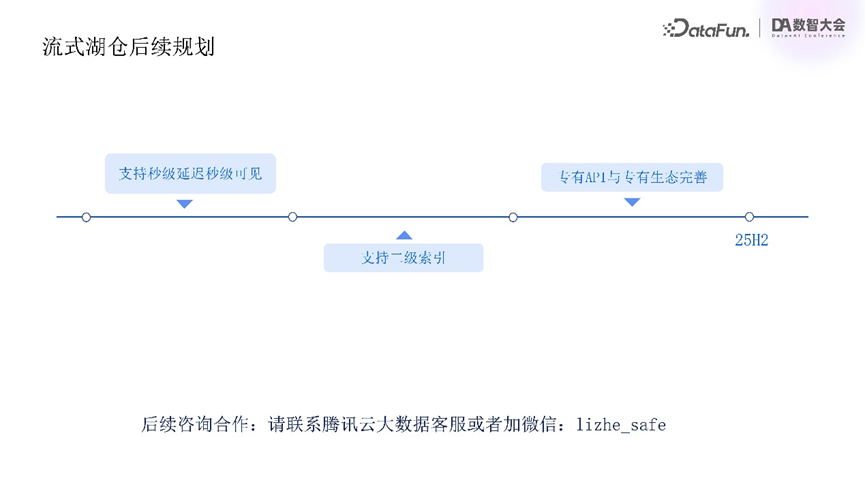
后续还将支持秒级延迟秒级可见,支持二级索引,并考虑为流式湖仓提供专有API与完善的生态。
Q&A环节
Q
车联网场景中,热数据和冷数据是如何存储的?
A
目前均统一存储在Iceberg中。
Q
每个阶段为保证准确性,链路延迟大概是多少?
A
具体时间暂无法给出,但在车联网客户使用场景下,相比之前链路,延迟性能更优。
Q
车联网或其他场景的并发度如何?如何解决高并发场景问题?
A
高并发场景下,我们对提交部分进行了优化。传统Iceberg用单节点生成snapshot,我们采用两阶段提交流程。多个bucket提交时,先并行完成bucket元数据文件更新与历史文件合并,生成bucket级元数据文件,再由全局global committer完成快照生成。此设计在bucket数量较多时可提高写入性能,避免并发高导致的OM情况。
Q
计算过程中,使用Iceberg与Spark本身计算在性能对比(查询效率、内存使用、CPU使用等)方面的情况如何?
A
目前产品处于内测与标杆客户落地阶段,性能数据暂不方便提供。后续产品上线后,将基于市面上所有湖格式在基础场景上进行全面性能对比,届时可关注。
Q
这套能力能否在私有化部署中获得?
A
可以。最初在公有云产品上线,已通过客户落地,后续计划将场景下沉到私有化部署中,可实现完整1:1对应。
Q
湖格式中,Iceberg部分列更新特性及与Paimon的对比,以及流式湖仓对Paimon的支持计划如何?
A
最初选择Iceberg后发现其部分问题,在现有架构中已补齐列更新、检查、流读等能力。Paimon推广较多,客户有使用需求,计划在明年年初或今年年底兼容现有Paimon格式,并针对Paimon与Iceberg后续发展进行功能更新。
END
关注腾讯云大数据╳探索数据的无限可能

⏬点击阅读原文
了解更多产品详情

我知道你在看哟

相关文章:
腾讯云流式湖仓统一存储实践
点击蓝字⬆ 关注我们 本文共计5107 预计阅读时长16分钟 * 本文将分享腾讯云流式湖仓的架构与实践。主要内容包括: 流计算Oceanus介绍腾讯云流式湖仓架构腾讯云流式湖仓实践腾讯云流式湖仓发展规划 一、流计算Oceanus介绍 随着大数据技术的发展࿰…...
)
18 设计模式之迭代器模式(书籍遍历案例)
一、什么是迭代器模式 迭代器模式(Iterator Pattern)是一种行为型设计模式,允许客户端通过统一的接口顺序访问一个集合对象中的元素,而无需暴露集合对象的内部实现。这个模式主要用于访问聚合对象(如集合、数组等&…...

超清4K视频素材哪里找?优质下载资源网站分享
我是你们的自媒体UP主小李。现在是高清、4K视频大行其道的时代,想要制作出吸引眼球的优质内容,超清4K视频素材必不可少。今天就为大家分享几个宝藏网站,让你的视频创作更轻松、更出彩! 蛙学网 首先推荐 蛙学网,这是国内…...

刷题日志【1】
目录 1.全排列【力扣】 代码1: 代码2: 2、子集【力扣】 3、全排列Ⅱ【力扣】 4、组合【力扣】 1.全排列【力扣】 代码1: class Solution {bool check[7];vector <int> path;vector<vector<int>> ret;public:vecto…...

【C++算法】32.前缀和_矩阵区域和
文章目录 题目链接:题目描述:解法C 算法代码: 题目链接: 1314. 矩阵区域和 题目描述: 解法 防止有人看不明白题目,先解释一下题目 二维前缀和思想: 使用前缀和矩阵 ret [x1,y1]~[x2,y2] D …...
)
使用堆栈(Stack)
集合类型(Collection)下篇_xml collection-CSDN博客 以上是堆栈的简单介绍,下方是堆栈的使用 题目:给定一个逆波兰表达式(后缀表达式)的字符串数组tokens,其中每个元素是一个操作数(数字&…...

雨晨 2610(2)0.2510 Windows 11 24H2 Iot 企业版 LTSC 2024 极简 2in1
文件: 雨晨 2610(2)0.2510 Windows 11 24H2 Iot 企业版 LTSC 2024 极简 2in1 install.esd 索引: 1 名称: Windows 11 IoT 企业版 LTSC 极简 26100.2510 描述: Windows 11 IoT 企业版 LTSC 极简 26100.2510 By YCDISM RTM 2025 24-12-07 大小: 8,176,452,990 个字节 索引: 2 …...

HDD 2025年技术趋势深度分析报告
随着数据量的指数级增长以及人工智能(AI)、物联网(IoT)、云计算和视频监控等领域的需求激增,硬盘驱动器(HDD)行业正面临着前所未有的挑战与机遇。本报告旨在深入剖析2025年HDD技术的发展方向&am…...

算法-字符串-22.括号生成
一、题目 二、思路解析 1.思路: 生成所有可能并且有效的括号组合——回溯方法 2.常用方法: a.数组,因为需要增删元素,所以选择LinkedList LinkedList<String> resnew LinkedList<>(); b.StringBuilder创建࿰…...

Free-RTOS实现LED闪烁
开发板:正点原子探索者 F407 LED定时定时闪烁 本次实验验证: 配置文件 1、打开CubeMX 2、选择芯片型号,然后点击开始项目 3、配置时钟 配置烧录引脚,与FreeRTOS系统时钟 选择FreeRTOS 这里已经默认有一个任务ÿ…...

NLP论文速读(斯坦福大学)|使用Tree将语法隐藏到Transformer语言模型中正则化
论文速读|Sneaking Syntax into Transformer Language Models with Tree Regularization 论文信息: 简介: 本文的背景是基于人类语言理解的组合性特征,即语言处理本质上是层次化的:语法规则将词级别的意义组合成更大的成分的意义&…...

再谈多重签名与 MPC
目录 什么是 MPC 钱包以及它们是如何出现的 多重签名和智能合约钱包已经成熟 超越 MPC 钱包 关于小队 多重签名已经成为加密货币领域的一部分,但近年来,随着 MPC(多方计算)钱包的出现,多重签名似乎被掩盖了。MPC 钱包之…...

CTF学习24.11.19[音频隐写]
MISC07[音频隐写] 隐写术 隐写术是一门关于信息隐藏的技巧与科学,所谓信息隐藏指的是不让除预期的接收者之外的任何人知晓信息的传递事件或者信息的内容。隐写术的英文叫做Steganography,来源于特里特米乌斯的一本讲述密码学与隐写术的著作Steganograp…...

vue的watch是否可以取消? 怎么取消?
发现宝藏 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【宝藏入口】。 Vue 可以通过 watch API 返回的一个 取消函数,可以在需要时取消该监听。 如何取消 watch? 当你使用 Vu…...

23、枚举
1、枚举 罗列一些标识符,当做整型数据使用。为了代码的易读性 1.1、枚举定义 enum 枚举名{大写标识符,大写标识符....}; 枚举类型名:enum 枚举名 枚举里面如果不给标识符赋值,默认从0开始,依次增1 如果里面的标识符有赋值…...
Java基本概念
Java特点 简单性。容易使用,比如没有C复杂的指针 面向对象。将对象属性剥离,当属性需要大量调用时节省代码,比如把大象装进冰箱,JAVA将大象分成跑、睡觉等不同功能,当需要就调用 分布式。 健壮性 安全性 体系结构…...

C++学习——如何析构派生类
C——继承关系中的虚函数 析构派生类纯虚构函数和抽象类 析构派生类 先看一段简单的代码: #include <iostream>using namespace std;class AA { public:AA() {cout << "调用了基类构造" << endl;}virtual void func() {cout <<…...

SpringCloud与Dubbo的区别
在构建分布式系统时,SpringCloud和Dubbo是两个常用的框架。虽然它们都能帮助开发者实现服务之间的通信和治理,但在设计理念、使用场景和技术实现上,两者存在明显的区别。本文将详细探讨SpringCloud与Dubbo的不同之处,以帮助开发者…...
)
C# 设计模式--建造者模式 (Builder Pattern)
定义 建造者模式是一种创建型设计模式,它允许你逐步构建复杂对象,而无需使用多个构造函数或重载。建造者模式将对象的构建过程与表示分离,使得相同的构建过程可以创建不同的表示。 正确写法 假设我们有一个复杂的 Car 对象,需要…...

leetcode 23. 合并 K 个升序链表
给你一个链表数组,每个链表都已经按升序排列。 输入:lists [[1,4,5],[1,3,4],[2,6]] 输出:[1,1,2,3,4,4,5,6] 解释:链表数组如下: [1->4->5,1->3->4,2->6 ] 将它们合并到一个有序链表中得到。 1->…...

从零构建μC/OS-II硬件抽象层:以ARM7 LPC2292为例详解移植核心
1. 项目概述与核心思路十年前,我第一次把μC/OS-II从一个ARM7开发板搬到另一个不同型号的ARM7芯片上,光是改启动文件和中断向量表就折腾了一周。那时候我就想,要是有一套标准化的“中间层”,能把芯片底层的差异给屏蔽掉࿰…...

【NotebookLM学术写作黄金法则】:20年科研老炮亲授5大避坑指南与3步合规提速法
更多请点击: https://intelliparadigm.com 第一章:NotebookLM学术写作规范的底层逻辑与认知革命 NotebookLM 并非传统意义上的文档编辑器,而是一个以“语义锚点”和“引用可追溯性”为基石的学术协作文本引擎。其底层逻辑颠覆了线性写作范式…...

5分钟快速上手:Proxmark3GUI图形界面终极指南
5分钟快速上手:Proxmark3GUI图形界面终极指南 【免费下载链接】Proxmark3GUI A cross-platform GUI for Proxmark3 client | 为PM3设计的跨平台图形界面 项目地址: https://gitcode.com/gh_mirrors/pr/Proxmark3GUI 对于RFID技术初学者来说,Proxm…...

SoC芯片设计全流程解析:从架构定义到流片制造
1. 项目概述:从“黑盒子”到“城市蓝图”当我们谈论智能手机、智能手表、路由器乃至汽车里的智能座舱时,我们谈论的核心,往往是一个被称为“片上系统”或SoC的硅片。对于很多刚入行的朋友,甚至是一些有经验的软件工程师来说&#…...

QMCDump终极指南:快速免费解锁QQ音乐加密文件,重获数字音乐自由 [特殊字符]
QMCDump终极指南:快速免费解锁QQ音乐加密文件,重获数字音乐自由 🎵 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.co…...

告别Windows激活烦恼:KMS智能激活工具一站式解决方案
告别Windows激活烦恼:KMS智能激活工具一站式解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出的激活提醒而困扰吗?是否曾经因为Office办…...

Python 开发者五分钟接入 Taotoken 调用 GPT 与 Claude 模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python 开发者五分钟接入 Taotoken 调用 GPT 与 Claude 模型 对于需要在项目中集成大语言模型的 Python 开发者而言,逐…...

3分钟掌握APK Installer:在Windows电脑上轻松安装安卓应用的终极方案
3分钟掌握APK Installer:在Windows电脑上轻松安装安卓应用的终极方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想在Windows电脑上直接运行An…...

二叉搜索树:高效查找与增删详解
引言在上一篇树结构开篇文章中,我们建立了树的基本概念、二叉树的定义和四种遍历方式。本文将继续深入,讲解二叉搜索树(Binary Search Tree,BST)——它是最基础的"有组织"二叉树,也是后续学习 AV…...

在线水印去除工具怎么选?2026年实测去水印方法+五大工具推荐
不管是做内容创作、整理素材,还是处理自己拍摄的视频和图片,水印问题都是绕不开的痛点。抖音、快手、小红书的视频里都带着平台水印,图片上有时也会被加上各种标记。那些网上找的素材更是五花八门的水印。怎么才能干净利落地去掉这些水印&…...