Elasticsearch入门之HTTP高级查询操作
前言
上一篇博客我们学习了es的一些基础操作如下:
- 创建索引(创建表 create table)
- 查看索引(查看表show tables)
- 查看单个索引(查看单个表show create table)
- 删除索引(删除表)
- 创建文档(插入数据)
- 根据唯一标识查看文档(根据主键查看一条数据)
- 根据唯一标识修改文档所有字段值(根据主键修改一条数据)
- 根据唯一标识修改文档指定字段值(根据主键修改指定字段的值)
- 根据唯一标识删除文档(根据主键删除对应的一条数据)
- 条件删除文档(根据条件删除数据)
- 创建映射(mysql中一般就是创建表,只不过es可以动态生成映射)
- 查看映射(查看表结构)
本篇我们继续学习es http的其它操作
高级查询
Elasticsearch 提供了基于 JSON 提供完整的查询 DSL 来定义查询
定义数据 :
# POST /student/_doc/1001
{
"name":"zhangsan",
"nickname":"zhangsan","sex":"男","age":30
}
# POST /student/_doc/1002
{
"name":"lisi",
"nickname":"lisi","sex":"男","age":20
}
# POST /student/_doc/1003
{
"name":"wangwu","nickname":"wangwu","sex":"女","age":40
}
# POST /student/_doc/1004
{
"name":"zhangsan1",
"nickname":"zhangsan1","sex":"女","age":50
}
# POST /student/_doc/1005
{
"name":"zhangsan aa",
"nickname":"zhangsan2","sex":"女","age":30
}
我们先根据上面的数据,用自定义的id给student索引中插入文档:

其它文档操作类似,这里就不截图展示了。
- 查询所有文档(类似于查询表中所有数据:select * from table)
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{"query": {"match_all": {}}
}
# "query":这里的 query 代表一个查询对象,里面可以有不同的查询属性
# "match_all":查询类型,例如:match_all(代表查询所有), match,term , range 等等
# {查询条件}:查询条件会根据类型的不同,写法也有差异

服务器响应结果如下:


这里就展示一部分数据。
{"took【查询花费时间,单位毫秒】" : 1116,"timed_out【是否超时】" : false,"_shards【分片信息】" : {"total【总数】" : 1,"successful【成功】" : 1,"skipped【忽略】" : 0,"failed【失败】" : 0},"hits【搜索命中结果】" : {"total"【搜索条件匹配的文档总数】: {"value"【总命中计数的值】: 3,"relation"【计数规则】: "eq" # eq 表示计数准确, gte 表示计数不准确},"max_score【匹配度分值】" : 1.0,"hits【命中结果集合】" : [。。。}]}
}
- 匹配查询
match 匹配类型查询,会把查询条件进行分词,然后进行查询,多个词条之间是 or 的关系
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search

服务器响应结果为:(篇幅原因这里json就不格式化了)

这里特别要注意,不同的es版本对于分词的处理也不同,我们可以看到zhangsan1并没有查出来,但是zhangsan aa查出来了,说明本次并没有把zhangsan1拆分出zhangsan来,因此查不出来。
- 字段匹配查询
multi_match 与 match 类似,不同的是它可以在多个字段中查询。
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search

服务器响应结果:

- 关键字精确查询(类似于:select * from table where name = ‘zhangsan’)
term 查询,精确的关键词匹配查询,不对查询条件进行分词。
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{"query": {"term": {"name": {"value": "zhangsan"}}}
}

服务器响应结果:

5. 多关键字精确查询(类似于:select * from table where name in (‘zhangsan’,‘lisi’))
terms 查询和 term 查询一样,但它允许你指定多值进行匹配。
如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件,类似于 mysql 的 in
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{"query": {"terms": {"name": ["zhangsan","lisi"]}}
}

服务器响应结果:

6. 指定查询字段(类似于:select name,nickname from table where nickname = ‘zhangsan’)
默认情况下,Elasticsearch 在搜索的结果中,会把文档中保存在_source 的所有字段都返回。
如果我们只想获取其中的部分字段,我们可以添加_source 的过滤
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{"_source": ["name","nickname"],"query": {"terms": {"nickname": ["zhangsan"]}}
}

服务器响应结果:

7. 过滤字段(还是类似与select 指定的字段)
我们也可以通过:
- includes:来指定想要显示的字段(这个和上面一样,只不过上面是把includes忽略了)
- excludes:来指定不想要显示的字段(这个在mysql中并没有类似的,一般mysql想选择什么字段,需要一个一个些出来,感觉用处是有,但没有那么大)
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{"_source": {"includes": ["name","nickname"]},"query": {"terms": {"nickname": ["zhangsan"]}}
}
服务器响应结果:

在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{"_source": {"excludes": ["name","nickname"]},"query": {"terms": {"nickname": ["zhangsan"]}}
}

服务器响应结果:

8. 组合查询
bool把各种其它查询通过must(必须 )、must_not(必须不)、should(应该)的方式进行组合
- must
含义:所有包含在 must 数组中的查询条件都必须为真(即所有条件都必须满足),文档才会被返回。
等价逻辑运算符:AND
应用场景:当你需要确保多个条件同时成立时使用。
假设你想查找姓名中包含“shangsan”并且nickname是“zhangsan”的学生,可以这样写:
{"query": {"bool": {"must": [{"match": {"name": "zhangsan"}},{"match": {"nickname": "zhangsan"}}]}}
}
- must_not
含义:所有包含在 must_not 数组中的查询条件都必须为假(即这些条件都不能满足),文档才会被返回。
等价逻辑运算符:NOT
应用场景:当你想要排除某些特定条件时使用。
如果你想查找name中包含“zhangsan”,但nickname不是“lisi”的学生,可以这样写:
{"query": {"bool": {"must": [{"match": {"name": "zhangsan"}}],"must_not": [{"match": {"nickname": "lis"}}]}}
}
- should
含义:should 数组中的查询条件至少有一个为真即可(即满足任意一个条件即可),文档就会被返回。你可以通过设置 minimum_should_match 参数来指定最少需要满足的条件数量。
等价逻辑运算符:OR
应用场景:当你希望满足任意一个或多个条件时使用。
如果你想查找name中包含“zhangsan”或nickname是“zhangsan1”的学生,可以这样写:
{"query": {"bool": {"should": [{"match": {"name": "zhangsan"}},{"match": {"nickname": "zhangsan1"}}]}}
}
当然可以组合查询:在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{"query": {"bool": {"must": [{"match": {"name": "zhangsan"}}],"must_not": [{"match": {"nickname": "lisi"}}]}}
}

服务器响应结果:

- 范围查询
range 查询找出那些落在指定区间内的数字或者时间。range 查询允许以下字符

在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{"query": {"range": {"age": {"gte": 30,"lte": 35}}}
}
报错了:Cannot search on field [age] since it is not indexed

根据上一篇博客,我们知道index一旦为false,那么就不能用来查询,所以我们看看age字段的index是不是为false:

果不其然,这就是上篇博客说的动态映射的缺点了,我们需要更改一下映射,更改索引的方法看下面修改索引,我们临时修改改了一个名字叫tmp_student的索引,修改完后我们再次执行

服务器响应结果:

10. 模糊查询(相当于sql中的select * from table where name like ‘%zhangsan%’)
返回包含与搜索字词相似的字词的文档。
编辑距离是将一个术语转换为另一个术语所需的一个字符更改的次数。这些更改可以包括:
- 更改字符(box → fox)
- 删除字符(black → lack)
- 插入字符(sic → sick)
- 转置两个相邻字符(act → cat)
为了找到相似的术语,fuzzy 查询会在指定的编辑距离内创建一组搜索词的所有可能的变体
或扩展。然后查询返回每个扩展的完全匹配。
通过 fuzziness 修改编辑距离。一般使用默认值 AUTO,根据术语的长度生成编辑距离。
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{"query": {"fuzzy": {"name": {"value": "zhangsan"}}}
}

服务器响应结果:

在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{"query": {"fuzzy": {"name": {"value": "zhangsan","fuzziness": 2}}}
}

fuzziness设置为2,
服务器响应结果:

- 单字段排序
sort 可以让我们按照不同的字段进行排序,并且通过 order 指定排序的方式。desc 降序,asc
升序。
我们现在索引中name为zhangsan相关的两个年龄都为30,我们再插入一条数据方便进行排序测试:

在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/tmp_student/_search
{"query": {"match": {"name": "zhangsan"}},"sort": [{"age": {"order": "desc"}}]
}

服务器响应结果:

12. 多字段排序
假定我们想要结合使用 age 和 _id 进行查询,并且匹配的结果首先按照年龄排序,然后
按照id排序
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{"query": {"match_all": {}},"sort": [{"age": {"order": "desc"}},{"_id": {"order": "desc"}}]
}

13. 高亮查询
在进行关键字搜索时,搜索出的内容中的关键字会显示不同的颜色,称之为高亮。

Elasticsearch 可以对查询内容中的关键字部分,进行标签和样式(高亮)的设置。
在使用 match 查询的同时,加上一个 highlight 属性:
- pre_tags:前置标签
- post_tags:后置标签
- fields:需要高亮的字段
- title:这里声明 title 字段需要高亮,后面可以为这个字段设置特有配置,也可以空
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/tmp_student/_search
{"query": {"match": {"name": "zhangsan"}},"highlight": {"pre_tags": "<font color='red'>","post_tags": "</font>","fields": {"name": {}}}
}

14. 分页查询
from:当前页的起始索引,默认从 0 开始。 from = (pageNum - 1) * size
size:每页显示多少条
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/tmp_student/_search
{"query": {"match_all": {}},"sort": [{"age": {"order": "desc"}}],"from": 0,"size": 2
}

15. 聚合查询
聚合允许使用者对 es 文档进行统计分析,类似与关系型数据库中的 group by,当然还有很多其他的聚合,例如取最大值、平均值等等。
- 对某个字段取最大值 max
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/tmp_student/_search
{"aggs": {"max_age": {"max": {"field": "age"}}},"size": 0
}

- 对某个字段取最小值 min
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/tmp_student/_search
{"aggs": {"min_age": {"min": {"field": "age"}}},"size": 0
}

- 对某个字段求和 sum
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/tmp_student/_search
{"aggs": {"sum_age": {"sum": {"field": "age"}}},"size": 0
}

- 对某个字段取平均值 avg
{"aggs": {"avg_age": {"avg": {"field": "age"}}},"size": 0
}

- 对某个字段的值进行去重之后再取总数
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/tmp_student/_search
{"aggs": {"distinct_age": {"cardinality": {"field": "age"}}},"size": 0
}

- State 聚合
stats 聚合,对某个字段一次性返回 count,max,min,avg 和 sum 五个指标
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/tmp_student/_search
{"aggs": {"stats_age": {"stats": {"field": "age"}}},"size": 0
}

16. 桶聚合查询
桶聚和相当于 sql 中的 group by 语句
- terms 聚合,分组统计
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/tmp_student/_search
{"aggs": {"age_groupby": {"terms": {"field": "age"}}},"size": 0
}

- 在 terms 分组下再进行聚合
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/tmp_student/_search
{"aggs": {"age_groupby": {"terms": {"field": "age"}}},"size": 0
}

修改索引
在es中,是不支持更改现有字段的映射或字段类型的,如果我们非得需要更改字段的类型,怎么办,数据迁移,重建索引,建立我们想要的正确的映射规则;
- 查看旧的索引

{"student": {"mappings": {"properties": {"age": {"type": "long","index": false},"name": {"type": "text"},"nickname": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"sex": {"type": "text","index": false}}}}
}
- 创建新的索引

{"mappings": {"properties": {"age": {"type": "long","index": true},"name": {"type": "text"},"nickname": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"sex": {"type": "text","index": false}}}
}
- 数据迁移

{"source": {"index": "student"},"dest": {"index": "tmp_student"}
}
match和term
当然可以。match 查询和 term 查询在 Elasticsearch 中确实有不同的行为,特别是在处理分析(分词)和全文搜索方面。下面通过具体的例子来说明它们之间的区别。
示例场景:图书索引
假设你有一个包含书籍信息的索引 books,每个文档代表一本书,并且有以下字段:
title: 书名,类型为text,并且默认包含一个keyword子字段title.keyword。author: 作者名,类型为text,并且默认包含一个keyword子字段author.keyword。
示例数据
| id | title | author |
|---|---|---|
| 1 | Elasticsearch Guide | John Doe |
| 2 | Learning Elasticsearch | Jane Smith |
| 3 | Mastering Elasticsearch | John Doe-Smith |
| 4 | Elasticsearch Basics | John Doe Jr. |
使用 match 查询
match 查询会分析查询字符串,并尝试匹配文档中的相应词条。这使得它可以用于全文搜索,支持部分匹配和模糊匹配。
示例查询:查找包含 “elasticsearch” 的书籍
GET /books/_search
{"query": {"bool": {"must": [{"match": {"title": "elasticsearch"}}]}}
}
这段查询会返回所有标题中包含词条 "elasticsearch" 的书籍,例如:
id: 1- “Elasticsearch Guide”id: 2- “Learning Elasticsearch”id: 3- “Mastering Elasticsearch”id: 4- “Elasticsearch Basics”
这是因为 match 查询会对查询字符串 "elasticsearch" 进行分析,并将其视为单个词条来匹配。
示例查询:查找作者名为 “John Doe” 的书籍
GET /books/_search
{"query": {"bool": {"must": [{"match": {"author": "John Doe"}}]}}
}
这段查询会返回所有作者名中包含词条 "john" 和 "doe" 的书籍,例如:
id: 1- “John Doe”id: 3- “John Doe-Smith”id: 4- “John Doe Jr.”
这是因为 match 查询会对查询字符串 "John Doe" 进行分析,并将它分解为两个词条 "john" 和 "doe" 来匹配。
使用 term 查询
term 查询不会对查询字符串进行任何分析或分词,而是直接将整个值作为单个词条来查找。这意味着它适合用于精确匹配,如用户ID、状态码、类别名称等。
示例查询:查找标题恰好为 “Elasticsearch Guide” 的书籍
GET /books/_search
{"query": {"bool": {"must": [{"term": {"title.keyword": "Elasticsearch Guide"}}]}}
}
这段查询只会返回 id: 1 的那本书,因为它完全匹配了给定的字符串。
示例查询:查找作者名为 “John Doe” 的书籍
GET /books/_search
{"query": {"bool": {"must": [{"term": {"author.keyword": "John Doe"}}]}}
}
这段查询只会返回 id: 1 的那本书,因为它完全匹配了给定的字符串 "John Doe"。id: 3 和 id: 4 的书籍不会被返回,因为它们的作者名不完全匹配。
关键区别总结
-
match查询:- 分析:对查询字符串进行分析(分词),然后匹配包含这些词条的文档。
- 应用场景:适用于全文搜索,支持部分匹配和模糊匹配。
- 示例:查询
"John Doe"可能返回包含"John","Doe","John Doe-Smith","John Doe Jr."等文档。
-
term查询:- 不分析:不进行分析,直接匹配完整词条。
- 应用场景:适用于精确匹配,如用户ID、状态码、类别名称等。
- 示例:查询
"John Doe"只会返回完全匹配"John Doe"的文档。
总结
match 查询和 term 查询在 Elasticsearch 中有着不同的用途和行为:
match查询 更适合用于全文搜索,支持分析和部分匹配,适用于text类型的字段。term查询 更适合用于精确匹配,不涉及分析过程,适用于keyword类型的字段。
通过正确理解和选择 match 和 term 查询,你可以构建更加高效和准确的查询逻辑。如果你需要进行全文搜索,请使用 match 查询;如果你需要进行精确匹配,请使用 term 查询并针对 keyword 字段。
模糊匹配(类似于sql中的like)
如果你希望查询能够匹配部分相似的字段,可以考虑以下几种方法:
1. 使用 wildcard 查询
wildcard 查询允许你使用通配符模式来进行模糊匹配。你可以用 * 表示任意数量的字符:
{"query": {"bool": {"must": [{"wildcard": {"name": "zhangsan*"}}]}}
}
这种方法适用于前缀匹配,但它可能比 match 查询更慢,特别是在大数据集上。
2. 使用 prefix 查询
prefix 查询用于查找以指定字符串开头的所有文档:
{"query": {"bool": {"must": [{"prefix": {"name": "zhangsan"}}]}}
}
这将返回所有 name 以 "zhangsan" 开头的文档。
3. 使用 fuzzy 查询
fuzzy 查询允许一定范围内的编辑距离(Levenshtein 距离),从而实现模糊匹配:
{"query": {"bool": {"must": [{"match": {"name": {"query": "zhangsan","fuzziness": "AUTO"}}}]}}
}
这将返回与 "zhangsan" 接近的名称,包括拼写错误或其他轻微变化。
4. 使用 keyword 子字段进行精确匹配或前缀匹配
如果你希望进行精确匹配或者基于原始值的前缀匹配,可以利用 name.keyword 子字段(假设你已经在映射中定义了这个子字段):
{"query": {"bool": {"must": [{"prefix": {"name.keyword": "zhangsan"}}]}}
}
这种方法确保了查询不会受到分析器的影响,提供了更精确的匹配。
总结
match 查询的行为是基于词条匹配的,而不是基于整个字符串的精确匹配。因此,它只会返回那些明确包含查询词条的文档。如果你想匹配部分相似的名字,可以考虑使用 wildcard、prefix、fuzzy 查询,或者直接针对 keyword 子字段进行查询。选择哪种方法取决于你的具体需求和性能考虑。
如果你的目标是实现类似于 MySQL LIKE 的前缀匹配行为,prefix 或 wildcard 查询通常是更好的选择。
相关文章:
Elasticsearch入门之HTTP高级查询操作
前言 上一篇博客我们学习了es的一些基础操作如下: 创建索引(创建表 create table)查看索引(查看表show tables)查看单个索引(查看单个表show create table)删除索引(删除表&#x…...

Java基础-异常
异常 什么是异常 在实际工作中,遇到的情况不可能是非常完美的。比如:你写一个模块,用户输入不一定符合你的要求、你的程序要打开某个文件,这个文件可能不存在或者文件格式不对,你要读取数据库的数据,数据…...

鲲鹏麒麟使用Docker部署Redis5
本次部署采用Docker方式进行部署,服务器为鲲鹏服务器,CPU架构为ARM64,操作系统版本信息为 # cat /etc/kylin-release Kylin Linux Advanced Server release V10 (Tercel)镜像 下载镜像鲲鹏麒麟Redis5镜像包 部署 1、上传镜像到服务器 2、…...

家政项目小程序+ssm
摘要 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成熟。本文介绍了微信小程序家政项目小程序的开发全过程。通过分析微信小程序家政项目小程序管理的不足,创建了一个计算机管理微信小程序家政项目小程序的方案。文章…...

Day7 苍穹外卖项目 缓存菜品、SpringCache框架、缓存套餐、添加购物车、查看购物车、清空购物车
目录 1.缓存菜品 1.1 问题说明 1.2 实现思路 1.3 代码开发 1.3.1 加入缓存 1.3.2 清除缓存 1.3.2.1 新增菜品优化 1.3.2.2 菜品批量删除优化 1.3.2.3 修改菜品优化 1.3.2.4 菜品起售停售优化 1.4 功能测试 1.4.1 加入缓存 1.4.2 菜品修改 1.5 代码提交 2.缓存套餐 2.1 Spring C…...

天天 AI-241207:今日热点- Windsurf:在工程能力上进一步进化的Cursor
2AGI.NET | 探索 AI 无限潜力,2AGI 为您带来最前沿资讯。 Windsurf:在工程能力上进一步进化的Cursor 介绍了一个新的AI代码编辑器Windsurf,它被认为是Cursor的进化版,具有更强的工程能力。文章强调了Windsurf在自动化编码和系统…...

Windows远程桌面连接到Linux
我的电脑是一台瘦客户端,公司设置的不能安装其他软件,里面只有几个软件,还好有一个远程桌面(Remote Desktop Connection),我想连接到另一台Linux的电脑上。 在Linux上安装xrdp: sudo apt insta…...

使用前,后端写 具有分页效果的数据展示
目录 前言 效果展示图如下 思路 服务器从前端界面获得什么? 前端界面从后端服务器应该拿到什么? 使用的技术 代码 前端代码 list.jsp中该功能的实现代码 后端代码 对应的servlet 代码 实体类代码 service的实现层 实现该功能的代码 dao层 实…...
——ebtables)
ubuntu防火墙管理(六)——ebtables
ebtables 是一个用于管理以太网帧的防火墙工具,主要用于在数据链路层(第 2 层)过滤和控制网络流量。它类似于 iptables,但专注于以太网流量。以下是 ebtables 的基本使用方法和示例。 基本命令 ebtables 的基本命令格式如下&…...
)
Oracle开发和应用——常用对象(表)
6.5. 常用对象 6.5.1. 表 1)概念 表(Table),是关系库中最基本、也是最常用的数据库对象,用户的数据存储在表中,用户使用数据时可以随时通过表进行检索或操作。也可以说,表是关系库最基本、最根本的特征。我们可以通过查询系统视图来获取表的相关信息。 D:\> sqlp…...

嵌入式蓝桥杯学习8 模拟电压测量
这里本来是要讲输入捕获的知识点的,但是由于学校校赛时间比较紧,校赛没考到输入捕获,所以先写ADC模拟电压测量的知识点。这里将的是单通道阻塞式采样。 Cubemx配置 点开cubemx。 1.将PB15配置为ADC2-IN15。 2.在Analog中点击ADC2ÿ…...

FFmpeg源码中,计算CRC校验的实现
一、CRC简介 CRC(Cyclic Redundancy Check),即循环冗余校验,是一种根据网络数据包或电脑文件等数据产生简短固定位数校核码的快速算法,主要用来检测或校核数据传输或者保存后可能出现的错误。CRC利用除法及余数的原理,实现错误侦…...

Android笔记【14】结合LaunchedEffect实现计时器功能。
一、问题 cy老师第五次作业 结合LaunchedEffect实现计时器功能。要求:动态计时,每秒修改时间,计时的时间格式为“00:00:00”(小时:分钟:秒)提交源代码的文本和运行截图…...

kubectl 和 kubeconfig 基本原理
云原生学习路线导航页(持续更新中) kubernetes学习系列 快捷连接 Kubernetes架构原则和对象设计(一) 本文介绍kubectl的几个常用命令,kubconfig文件基本属性,并开启kubectl debug日志分析其背后基本原理 …...
LVGL笔录----动画
最近在搞LVGL动画内容,发现网上能参考的资源太少了。现将自己学习到的内容做个笔录,仅供自己记录,若对你有帮助,那么最好不过,共勉! 首先,我是在CodeBlock上仿真 #define PI 3.14159265359stat…...

【LeetCode热题100】BFS解决FloodFill算法
这篇博客主要记录了使用BFS解决FloodFill算法的几道题目,包括图像渲染、岛屿数量、岛屿的最大面积、被包围的区域。 class Solution {using PII pair<int, int>; public:vector<vector<int>> floodFill(vector<vector<int>>& im…...

设计模式の软件设计原则
文章目录 前言一、聚合&组合&继承&依赖1.1、继承1.2、组合1.3、聚合1.4、依赖 二、单一职责原则2.1、单一职责原则反面案例2.2、单一职责原则反面案例的改进 三、接口隔离原则3.1、接口隔离原则反面案例3.2、接口隔离原则反面案例的改进 四、依赖倒转原则4.1、依赖…...

Linux centos7 下载MySQL5.7仓库的命令
wget 是一个非常强大的命令行工具,用于从网络上下载文件。它是 Linux 和其他 Unix-like 系统中常用的工具之一。wget 命令的各个参数有着不同的含义,下面是您提供的命令 wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.onarch.r…...
)
CSS flex布局踩坑小记:flex-basis属性之0px与0%的差异 (赞)
原文出处:CSS flex布局踩坑小记:flex-basis属性之0px与0%的差异_flex-basis 0%-CSDN博客 讲述flex容器被撑大的原因(误用:flex-basis: 0%;)及解决方法(用:flex-basis: 0px;)...
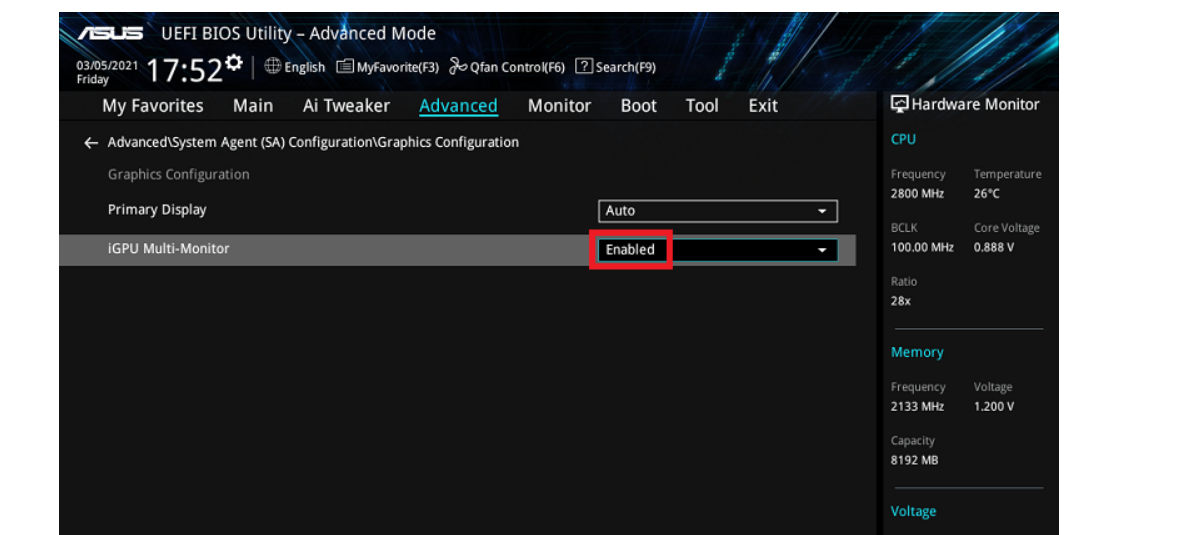
华硕主板不能开启
正常流程: [主機板]BIOS如何設置主機板整合圖形(內顯)和獨立顯示卡同時顯示輸出 | 官方支援 | ASUS 台灣 如果开启了CSR兼容性模式,在BIOS里面,就必须关掉,才能支持多显示器,如下图显示的标识才会出现。...

从零构建个人知识库:Go+React全栈项目RocketNotes实战解析
1. 项目概述:从零到一构建个人知识管理工具最近在整理个人笔记和代码片段时,发现了一个挺有意思的开源项目fynnfluegge/rocketnotes。乍一看这个名字,可能会联想到火箭(Rocket)和笔记(Notes)的结…...

避坑指南:Unity热重载插件内存占用高?可能是Windows Defender在搞鬼
Unity热重载性能优化:解决Windows Defender导致的资源占用问题 当你在Unity开发过程中频繁修改C#代码时,热重载(Hot Reload)功能无疑是提升效率的利器。它能让你在游戏运行状态下即时看到代码修改效果,避免反复重启带来的时间浪费。然而&…...

使用mcp-maker快速构建AI工具集成服务器:从MCP协议到实践
1. 项目概述:一个为AI应用注入“超能力”的MCP服务器工厂 如果你最近在折腾AI应用开发,特别是想给ChatGPT、Claude这类大模型配上“手和脚”,让它们能操作你的本地文件、查询数据库,甚至控制你的智能家居,那你大概率已…...

怎么判断一家工厂还在不在正常生产?6 类活跃度信号,从纸面到现场
跑工厂的销售员都遇到过这种事:手机里存着一份名单,导航开两小时,到门口才发现卷帘门焊死、车间长草、保安说"厂子去年就搬了"。 问题出在哪?大多数人判断"这家工厂在不在",靠的是工商登记——执照…...
用户指引自助教学源码—东方仙盟)
未来之窗昭和仙君(九十四)用户指引自助教学源码—东方仙盟
软件教学引导功能说明书未来之窗昭和仙君 - cyberwin_fairyalliance_webquery一、功能概述软件教学引导功能主要用于为用户提供软件操作的引导,通过一系列步骤逐步引导用户完成软件的重要操作。该功能会创建遮罩层、高亮框和提示框,引导用户点击特定元素…...

基于WLED分段功能与激光切割的多层智能艺术灯板制作全攻略
1. 项目概述与核心价值如果你和我一样,对那种能随着音乐呼吸、或者能独立变换不同区域色彩的智能灯光装置着迷,那么你一定会喜欢这个项目。它远不止是把LED灯条粘在板子后面那么简单,而是将激光切割的精密工艺、分层的艺术设计,与…...

Cursor编辑器状态快照插件开发:一键保存与恢复工作区
1. 项目概述:一个专为开发者设计的“后悔药”如果你是一名重度使用 Cursor 编辑器的开发者,那么你一定经历过这样的场景:在沉浸式编码时,为了快速定位或修改,你可能会频繁地使用CtrlClick跳转到函数定义,或…...

Proof Engine:简化零知识证明开发,降低区块链应用门槛
1. 项目概述:Proof Engine,一个为现代开发者设计的证明引擎如果你和我一样,在构建需要复杂逻辑验证、状态证明或零知识证明(ZKP)相关应用时,常常感到头疼——工具链复杂、学习曲线陡峭、不同框架间的兼容性…...

ncmdump终极指南:如何快速免费解锁网易云音乐NCM格式
ncmdump终极指南:如何快速免费解锁网易云音乐NCM格式 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的加密文件无法在其他设备播放而烦恼吗?ncmdump正是你需要的解决方案!这…...

子高斯随机变量与深度学习异常检测原理
1. 子高斯随机变量基础解析子高斯随机变量是概率论中一类具有特殊尾部性质的分布。简单来说,一个随机变量X如果满足存在常数σ>0,使得对于所有λ∈R都有E[exp(λX)] ≤ exp(λσ/2),那么我们就称X是σ-子高斯的。这类分布的关键特征是它们…...