基于 RNN(GRU, LSTM)+CNN 的红点位置检测(pytorch)
文章目录
- 1 项目背景
- 2 数据集
- 3 思路
- 4 实验结果
- 5 代码
1 项目背景
需要在图片精确识别三跟红线所在的位置,并输出这三个像素的位置。

其中,每跟红线占据不止一个像素,并且像素颜色也并不是饱和度和亮度极高的红黑配色,每个红线放大后可能是这样的。

而我们的目标是精确输出每个红点的位置,需要精确到像素。也就是说,对于每根红线,模型需要输出橙色箭头所指的像素而不是蓝色箭头所指的像素的位置。
之前尝试过纯 RNN 的实验,也试过在 RNN 前用 CNN,给数据带上卷积的信息。在图片长度为1080、低噪声环境时,对比实验的结果如下:
| 实验 | loss | 完全准确的点 |
|---|---|---|
| GRU | 129.6641 | 1762.0/9000 (20%) |
| LSTM | 249.2053 | 1267.0/9000 (14%) |
| CNN+GRU | 1419.5781 | 601.0/9000 (7%) |
| CNN+LSTM | 1166.4599 | 762.0/9000 (8%) |
对的,这个方法甚至起到反效果了。问了做过类似尝试的同事,他表示效果其实跟直接使用 RNN 区别不大。
2 数据集
还是之前那个代码合成的数据集数据集,每个数据集规模在15000张图片左右,在没有加入噪音的情况下,每个样本预览如图所示:

加入噪音后,每个样本的预览如下图所示:

图中黑色部分包含比较弱的噪声,并非完全为黑色。
数据集包含两个文件,一个是文件夹,里面包含了jpg压缩的图像数据:

另一个是csv文件,里面包含了每个图像的名字以及3根红线所在的像素的位置。

3 思路
之前 CNN+RNN 的思路是把 CNN 作为一个特征提取器,RNN 作为决策模型。这次主要是想看看直接用 CNN 做决策会比 RNN 强多少,因为其实 CNN 在这类任务上的优势应该会大很多。也就是说把RNN当作一个特征提取器处理图片数据,再用CNN找到这三个点的位置。按照这个思路,RNN+CNN 的处理流程如下:

然后再在模型上加一点Attention:

4 实验结果
| 实验 | train loss | val loss | test loss | test 完全准确样本 | 点1平均偏移量 | 点2平均偏移量 | 点3平均偏移量 |
|---|---|---|---|---|---|---|---|
| GRU | 17.1150 | 16.2752 | 233.5694 | 536.0/4500 (12%) | 3.3181 | 3.0701 | 3.3957 |
| LSTM | 378.7690 | 47.6191 | 367.7041 | 499.0/4500 (11%) | 4.2166 | 3.6437 | 4.0777 |
| CNN | 6.6049 | 13.6372 | 231.4501 | 650.0/4500 (14%) | 2.1816 | 3.0884 | 3.9680 |
| CNN+RNN | 5.3883 | 6.6833 | 76.0979 | 821.0/4500 (18%) | 1.8977 | 2.5229 | 1.8854 |
| RNN+CNN | 2.6558 | 1.7714 | 28.4280 | 1318.0/4500 (29%) | 1.4926 | 1.3679 | 1.5234 |
| RNN+CNN+Attention | 6.5938 | 42.4060 | 41.9453 | 1264.0/4500 (28%) | 1.5860 | 1.5557 | 1.8804 |
| Multi-Head Attention + RNN | 174.5019 | 18.1041 | 149.0297 | 645.0/4500 (14%) | 2.6598 | 3.2243 | 2.4309 |
GRU那个妥妥过拟合,CNN 做决策效果确实暴打之前的 RNN,只能说卷积还是适合图像类的任务,RNN 这种针对序列信息的可能效果还是有限。画出前6个模型预测中三个点的偏移量,可以看出 RNN+CNN 模型的预测结果的偏差大多集中于0和1这块:

关于多头注意力机制在 RNN 中的效果以及注意力机制在 CNN 中的效果,我也做了实验,事实证明 CNN 中的 Attention 并不合适,起了反效果:
| 实验 | train loss | val loss | test loss | test 完全准确样本 | 点1平均偏移量 | 点2平均偏移量 | 点3平均偏移量 |
|---|---|---|---|---|---|---|---|
| RNN+CNN | 2.6558 | 1.7714 | 28.4280 | 1318.0/4500 (29%) | 1.4926 | 1.3679 | 1.5234 |
| RNN+CNN+Attention | 6.5938 | 42.4060 | 41.9453 | 1264.0/4500 (28%) | 1.5860 | 1.5557 | 1.8804 |
| RNN(Attention)+CNN | 3.3199 | 3.7312 | 22.7644 | 1498.0/4500 (33%) | 1.4721 | 1.2609 | 1.2932 |
| RNN+CNN(Attention) | 4.2012 | 4.5143 | 65.8752 | 1039.0/4500 (23%) | 1.5869 | 2.3705 | 1.9389 |

从上图也能看出,RNN(Attention)+CNN 的效果明显优于其他两种方案。
关于位置信息,因为在之前的实验中,对 RNN 嵌入位置信息能够显著提高模型的效果,但是在该问题中,效果不佳。这意味着位置信息其实对 CNN 的决策起到非常大的干扰作用。
| 实验 | train loss | val loss | test loss | test 完全准确样本 | 点1平均偏移量 | 点2平均偏移量 | 点3平均偏移量 |
|---|---|---|---|---|---|---|---|
| RNN+CNN+Attention+Position | 11.9669 | 88.9042 | 103.9887 | 739.0/4500 (16%) | 2.4452 | 2.3939 | 2.3833 |
| RNN+CNN+Attention+learnable embedding | 19.2102 | 23.4937 | 223.7447 | 473.0/4500 (11%) | 2.9559 | 3.0082 | 3.6864 |
| RNN+CNN+Attention+learnable embedding with position | 21.5659 | 25.1544 | 170.9156 | 677.0/4500 (15%) | 2.3320 | 2.6873 | 2.9070 |
上表中 Position 代表采取使用 transformer 中的 sin cos 的位置编码,learnable embedding 意味着直接把 [0,seq_length] 的转化为可学习的embedding,learnable embedding with position 表示在 learnable embedding 中采用 sin cos 的位置编码作为初始化的参数。
从结果来看,无论是 transformer 的位置编码还是 learnable embedding 都没有提升原来模型表现。

5 代码
GRU+CNN+Attention
import torch
import torch.nn as nnclass Config(object):def __init__(self, device, csv_file, img_dir, width, input_size):self.device = deviceself.model_name = 'GRU_CNN_Attention'self.input_size = input_sizeself.hidden_size = 128self.num_layers = 2self.epoch_number = 150self.batch_size = 32self.learn_rate = 0.0002self.csv_file = csv_fileself.img_dir = img_dirself.width = widthclass GRU_CNN(nn.Module):def __init__(self, config):super(GRU_CNN, self).__init__()self.hidden_size = config.hidden_sizeself.num_layers = config.num_layersself.device = config.deviceself.sequence_length = config.widthself.channels = config.input_sizeself.gru = nn.GRU(input_size=self.channels, hidden_size=self.hidden_size, num_layers=self.num_layers,batch_first=True, bidirectional=True, dropout=0.6)self.attention = nn.MultiheadAttention(embed_dim=2 * self.hidden_size, num_heads=4, batch_first=True)self.fc = nn.Linear(2 * self.hidden_size, 4)self.conv1 = nn.Conv2d(4 + self.channels, 32, kernel_size=(1, 3), stride=1, padding=(0, 1))self.se1 = SEAttention(32)self.relu = nn.ReLU()self.pool1 = nn.MaxPool2d(kernel_size=(1, 2), stride=(1, 2))self.conv2 = nn.Conv2d(32, 64, kernel_size=(1, 3), stride=1, padding=(0, 1))self.se2 = SEAttention(64)self.pool2 = nn.MaxPool2d(kernel_size=(1, 2), stride=(1, 2))self.conv3 = nn.Conv2d(64, 128, kernel_size=(1, 3), stride=1, padding=(0, 1))self.se3 = SEAttention(128)self.pool3 = nn.MaxPool2d(kernel_size=(1, 2), stride=(1, 2))self.fc1 = nn.Linear(128 * (self.sequence_length // 8), 128)self.fc2 = nn.Linear(128, 3)def forward(self, x):rnn_x = x.squeeze(2).permute(0, 2, 1)# x = x + self.pos_encoding[:, :x.size(1), :].to(x.device)h0 = torch.zeros(self.num_layers * 2, rnn_x.size(0), self.hidden_size).to(x.device)gru_output, _ = self.gru(rnn_x, h0) # batch_size, sequence_length, 2 * hidden_sizecontext_vector, _ = self.attention(gru_output, gru_output, gru_output) # batch_size, sequence_length, 2 * hidden_sizegru_output_fc = self.fc(context_vector) # batch_size, sequence_length, 3gru_output_fc = gru_output_fc.transpose(1, 2).unsqueeze(2) # batch_size, 3, 1, sequence_lengthx = torch.cat((x, gru_output_fc), dim=1)x = self.pool1(self.se1(self.relu(self.conv1(x))))x = self.pool2(self.se2(self.relu(self.conv2(x))))x = self.pool3(self.se3(self.relu(self.conv3(x))))x = x.view(-1, 128 * (self.sequence_length // 8))x = self.relu(self.fc1(x))x = self.fc2(x)return xclass SEAttention(nn.Module):def __init__(self, channel, reduction=16):super(SEAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc = nn.Sequential(nn.Linear(channel, channel // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channel // reduction, channel, bias=False),nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * y.expand_as(x)
GRU+CNN
import torch
import torch.nn as nnclass Config(object):def __init__(self, device, csv_file, img_dir, width, input_size):self.device = deviceself.model_name = 'GRU_CNN'self.input_size = input_sizeself.hidden_size = 128self.num_layers = 2self.epoch_number = 100self.batch_size = 32self.learn_rate = 0.001self.csv_file = csv_fileself.img_dir = img_dirself.width = widthclass GRU_CNN(nn.Module):def __init__(self, config):super(GRU_CNN, self).__init__()self.hidden_size = config.hidden_sizeself.num_layers = config.num_layersself.device = config.deviceself.sequence_length = config.widthself.channels = config.input_sizeself.gru = nn.GRU(input_size=self.channels, hidden_size=self.hidden_size, num_layers=self.num_layers,batch_first=True, bidirectional=True, dropout=0.6)self.fc = nn.Linear(2 * self.hidden_size, 3)self.conv1 = nn.Conv2d(3 + self.channels, 32, kernel_size=(1, 3), stride=1, padding=(0, 1))self.relu = nn.ReLU()self.pool1 = nn.MaxPool2d(kernel_size=(1, 2), stride=(1, 2))self.conv2 = nn.Conv2d(32, 64, kernel_size=(1, 3), stride=1, padding=(0, 1))self.pool2 = nn.MaxPool2d(kernel_size=(1, 2), stride=(1, 2))self.conv3 = nn.Conv2d(64, 128, kernel_size=(1, 3), stride=1, padding=(0, 1))self.pool3 = nn.MaxPool2d(kernel_size=(1, 2), stride=(1, 2))self.fc1 = nn.Linear(128 * (self.sequence_length // 8), 128)self.fc2 = nn.Linear(128, 3)def forward(self, x):rnn_x = x.squeeze(2).permute(0, 2, 1)# x = x + self.pos_encoding[:, :x.size(1), :].to(x.device)h0 = torch.zeros(self.num_layers * 2, rnn_x.size(0), self.hidden_size).to(x.device)gru_output, _ = self.gru(rnn_x, h0) # batch_size, sequence_length, 2 * hidden_sizegru_output_fc = self.fc(gru_output) # batch_size, sequence_length, 3gru_output_fc = gru_output_fc.transpose(1, 2).unsqueeze(2) # batch_size, 3, 1, sequence_lengthx = torch.cat((x, gru_output_fc), dim=1)x = self.pool1(self.relu(self.conv1(x)))x = self.pool2(self.relu(self.conv2(x)))x = self.pool3(self.relu(self.conv3(x)))x = x.view(-1, 128 * (self.sequence_length // 8))x = self.relu(self.fc1(x))x = self.fc2(x)return x
learnable embedding 与 transformer 编码的结合:
class GRU_CNN(nn.Module):def __init__(self, config):super(GRU_CNN, self).__init__()self.hidden_size = config.hidden_sizeself.num_layers = config.num_layersself.device = config.deviceself.sequence_length = config.widthself.channels = config.input_sizeself.gru = nn.GRU(input_size=self.channels, hidden_size=self.hidden_size, num_layers=self.num_layers,batch_first=True, bidirectional=True, dropout=0.6)self.attention = nn.MultiheadAttention(embed_dim=2 * self.hidden_size, num_heads=4, batch_first=True)self.fc = nn.Linear(2 * self.hidden_size, 4)self.conv1 = nn.Conv2d(4 + self.channels, 32, kernel_size=(1, 3), stride=1, padding=(0, 1))self.relu = nn.ReLU()self.pool1 = nn.MaxPool2d(kernel_size=(1, 2), stride=(1, 2))self.conv2 = nn.Conv2d(32, 64, kernel_size=(1, 3), stride=1, padding=(0, 1))self.pool2 = nn.MaxPool2d(kernel_size=(1, 2), stride=(1, 2))self.conv3 = nn.Conv2d(64, 128, kernel_size=(1, 3), stride=1, padding=(0, 1))self.pool3 = nn.MaxPool2d(kernel_size=(1, 2), stride=(1, 2))self.fc1 = nn.Linear(128 * (self.sequence_length // 8), 128)self.fc2 = nn.Linear(128, 3)self.positional_embedding = self.generate_positional_encoding(config.width, self.channels).to(self.device)def generate_positional_encoding(self, seq_length, d_model):def generate_sin_cos_positional_encoding(seq_len, d_model):pos = torch.arange(seq_len).unsqueeze(1) # (seq_len, 1)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)) # (d_model / 2)pe = torch.zeros(seq_len, d_model)pe[:, 0::2] = torch.sin(pos * div_term)pe[:, 1::2] = torch.cos(pos * div_term)return pepositional_encoding = generate_sin_cos_positional_encoding(seq_length, d_model)embedding = nn.Embedding(seq_length, d_model)embedding.weight = nn.Parameter(positional_encoding, requires_grad=True)return embeddingdef forward(self, x):rnn_x = x.squeeze(2).permute(0, 2, 1)positions = torch.arange(rnn_x.size(1), device=x.device).unsqueeze(0).expand(rnn_x.size(0), -1)rnn_x = rnn_x + self.positional_embedding(positions)h0 = torch.zeros(self.num_layers * 2, rnn_x.size(0), self.hidden_size).to(x.device)gru_output, _ = self.gru(rnn_x, h0) # batch_size, sequence_length, 2 * hidden_sizecontext_vector, _ = self.attention(gru_output, gru_output, gru_output) # batch_size, sequence_length, 2 * hidden_sizegru_output_fc = self.fc(context_vector) # batch_size, sequence_length, 3gru_output_fc = gru_output_fc.transpose(1, 2).unsqueeze(2) # batch_size, 3, 1, sequence_lengthx = torch.cat((x, gru_output_fc), dim=1)x = self.pool1(self.relu(self.conv1(x)))x = self.pool2(self.relu(self.conv2(x)))x = self.pool3(self.relu(self.conv3(x)))x = x.view(-1, 128 * (self.sequence_length // 8))x = self.relu(self.fc1(x))x = self.fc2(x)return x相关文章:
基于 RNN(GRU, LSTM)+CNN 的红点位置检测(pytorch)
文章目录 1 项目背景2 数据集3 思路4 实验结果5 代码 1 项目背景 需要在图片精确识别三跟红线所在的位置,并输出这三个像素的位置。 其中,每跟红线占据不止一个像素,并且像素颜色也并不是饱和度和亮度极高的红黑配色,每个红线放大…...

L2G3000-LMDeploy 量化部署实践
文章目录 LMDeploy 量化部署实践闯关任务环境配置W4A16 量化 KV cacheKV cache 量化Function call LMDeploy 量化部署实践闯关任务 环境配置 conda create -n lmdeploy python3.10 -y conda activate lmdeploy conda install pytorch2.1.2 torchvision0.16.2 torchaudio2.1.…...

verilog编程规范
verilog编程规范 文章目录 verilog编程规范前言一、代码划分二、verilog编码ABCDEFG 前言 高内聚,低耦合,干净清爽的代码 一、代码划分 高内聚: 一个功能一个模块干净的接口提取公共的代码 低耦合: 模块之间低耦合尽量用少量…...

飞飞5.4游戏源码(客户端+服务端+工具完整源代码+5.3fix+5.4patch+数据库可编译进游戏)
飞飞5.4游戏源码(客户端服务端工具完整源代码5.3fix5.4patch数据库可编译进游戏) 下载地址: 通过网盘分享的文件:【源码】飞飞5.4游戏源码(客户端服务端工具完整源代码5.3fix5.4patch数据库可编译进游戏) 链…...

【MySQL】——用一文领悟表的增删查改
目录 前言 🍃1.表的增加 🍙1.1增——insert 🍙1.2插入否则更新 🍤1.2.1影响行说明 🍂2.表的查询 🍘2.1查询——select 🍘2.2特殊表查询 🍥2.2.1添加表达式 🍥…...

Zabbix监控Oracle 19c数据库完整配置指南
Zabbix监控Oracle 19c数据库完整配置指南 本文将详细介绍如何使用Zabbix配置Oracle 19c数据库监控,包括安装、配置、问题排查等全过程。本指南适合新手独立完成配置。 1. 环境准备 1.1 系统要求 Oracle 19c数据库服务器Zabbix服务器(版本5.0或更高&a…...
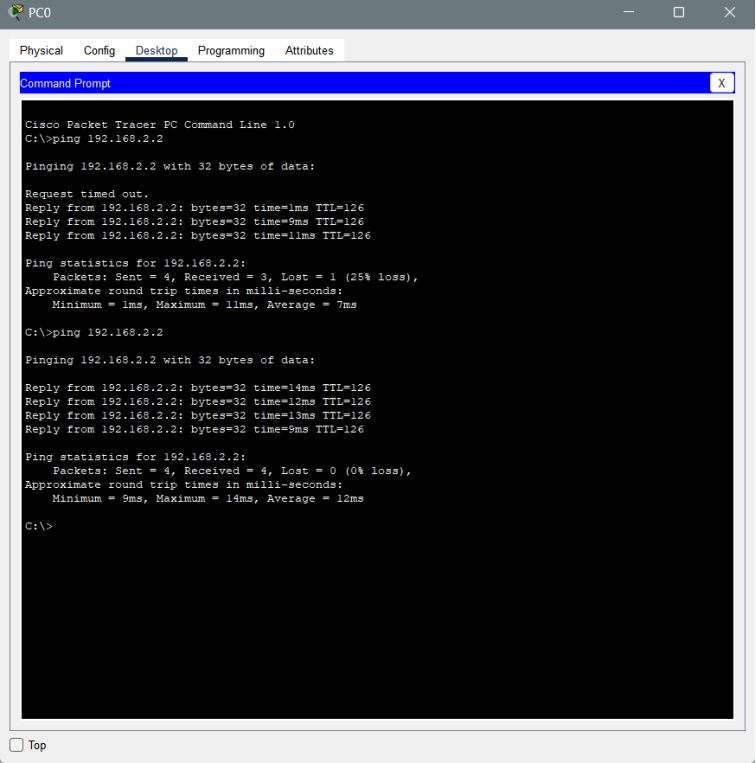
静态路由与交换机配置实验
1.建立网络拓扑 添加2台计算机,标签名为PC0、PC1;添加2台二层交换机2960,标签名为S0、S1;添加2台路由器2811,标签名为R0、R1;交换机划分的VLAN及端口根据如下拓扑图,使用直通线、DCE串口线连接…...

【jvm】讲讲jvm中的gc
目录 1. 说明2. 主要算法2.1 标记-清除算法2.2 复制算法2.3 标记-整理算法3. 主要回收器3.1 Serial GC3.2 Parallel GC3.3 CMS(Concurrent Mark-Sweep)GC3.4 G1(Garbage-First)GC 4. 触发条件4.1 Minor GC(Young GC&am…...

openlayers地图事件
OpenLayers是一个开源的JavaScript库,用于在Web上创建交互式地图。它提供了许多地图事件,使用户可以与地图进行交互。以下是OpenLayers常用的地图事件: 1. click:当用户单击地图时触发该事件。 2. dblclick:当用户双…...

杂记9---一些场景git操作汇总
背景:不同项目需求,所需要git操作集合,不太一样,这里汇总记录一下。 场景1:给本地项目添加到远程仓库的新建分支上 把本地节点保存在自己库的一个分支: git init git remote add origin xxx.git 远程仓库…...

Mysql索引,聚簇索引,非聚簇索引,回表查询
什么是索引 数据库索引是为了实现高效数据查询的一种有序的数据数据结构,类似于书的目录,通过目录可以快速的定位到想要的数据,因为一张表中的数据会有很多,如果直接去表中检索数据效率会很低,所以需要为表中的数据建立…...

【优选算法 二分查找】二分查找算法入门详解:二分查找小专题
x 的平方根 题目解析 算法原理 解法一: 暴力解法 如果要求一个数(x)的平方根,可以从 0 往后枚举,直到有一个数(a),a^2<x,(a1)^2>x,a即为所求; 解法二:二分查找 …...

如何将CSDN博客下载为PDF文件
1.打开CSDN文章内容 2.按键盘上的f12键(或者右键—审查元素)进入浏览器调试模式,点击控制台(Console)进入控制台 3.在控制台输入以下代码,回车 4.在弹出的打印页面中将布局设置成横向,纵向会…...

pdf转word/markdown等格式——MinerU的部署:2024最新的智能数据提取工具
一、简介 MinerU是开源、高质量的数据提取工具,支持多源数据、深度挖掘、自定义规则、快速提取等。含数据采集、处理、存储模块及用户界面,适用于学术、商业、金融、法律等多领域,提高数据获取效率。一站式、开源、高质量的数据提取工具&…...

2024年下半年网络工程师案例分析真题及答案解析
2024年下半年网络工程师案例分析真题及答案解析 试题一(15分) [说明] 公司为某科技园区的不同企业提供网络服务,不同企业的业务有所不同,每个企业因业务需要在不同的地点有多个分支机构。其拓扑结构如图1所示。企业用户通过楼层接入交换机、楼栋汇聚交换机和区域交换机接…...

English phonetic symbol
英语音标发音表-英语48个音标在线读 (jiwake.com) 【英语音标教程】从此学会国际音标|英式音标|BBC音标教程全解_哔哩哔哩_bilibili 元音 单元音 /iː/,/ɪ/ 这两个音不是发音长短的区别, /uː/ /ʊ/ 上面那个就正常读,下面那个她的气大概是往你斜…...

普及组集训--图论最短路径设分层图
P4568 [JLOI2011] 飞行路线 - 洛谷 | 计算机科学教育新生态 可以设置分层图:(伪代码) E(u,v)w;无向图 add(u,v,w),add(v,u,w); for(j1~k){add(ujn,vjn,w);add(vjn,ujn,w);add(ujn-j,vjn-j,0);add(vjn-j,ujn-j,0); } add(ujn-j,vjn-j,0); add(vjn-j,uj…...

SYN6288语音合成模块使用说明(MicroPython、STM32、Arduino)
模块介绍 SYN6288中文语音合成模块是北京宇音天下科技有限公司推出的语音合成模块。该模块通过串口接收主控传来的语音编码后,可自动进行自然流畅的中文语音播报。 注:SYN6288模块无法播报英文单词和句子,只能按字母播报英文 ;而…...

Spring完整知识三(完结)
Spring集成MyBatis 注意 Spring注解形式集成MyBatis时,若SQL语句比较复杂则仍采用映射文件形式书写SQL语句;反之则用注解形式书写SQL语句,具体可详见Spring注解形式 环境准备相同步骤 Step1: 导入相关坐标,完整pom.…...

保姆级教程Docker部署Redis镜像
目录 1、创建挂载目录和配置文件 2、运行Redis镜像 3、查看redis运行状态 1、创建挂载目录和配置文件 # 创建宿主机Redis配置文件存放目录 sudo mkdir -p /data/docker/redis/conf# 创建Redis配置文件 cd /data/docker/redis/conf sudo touch redis.conf 到Github上找到Redi…...

AI智能体任务编排框架:从概念到实战的Mission Control指南
1. 项目概述:为AI智能体打造一个“任务控制中心”最近在折腾AI智能体(Agent)的开发,发现一个挺普遍的问题:当你想让多个智能体协同工作,或者想让单个智能体执行一系列复杂、有依赖关系的任务时,…...

别再只盯着wx.login了!SpringBoot后端实战:用getPhoneNumber接口搞定小程序用户手机号绑定
微信小程序用户手机号绑定:SpringBoot后端深度实践指南 在当今移动互联网生态中,微信小程序已成为连接用户与服务的重要桥梁。对于需要强实名认证或直接触达用户的业务场景(如电商交易、金融服务、政务办理等),仅依赖w…...

3步掌握yfinance:从金融数据获取到智能分析的完整指南
3步掌握yfinance:从金融数据获取到智能分析的完整指南 【免费下载链接】yfinance Download market data from Yahoo! Finances API 项目地址: https://gitcode.com/GitHub_Trending/yf/yfinance yfinance是一个强大的Python库,能够轻松从Yahoo! F…...

LVGL在无显存TFT屏上的驱动适配:双缓冲与DMA优化实践
1. 项目概述:当TFT屏幕遇上LVGL最近在做一个嵌入式GUI项目,核心任务是把LVGL这个轻量级图形库,适配到一块分辨率不算高但接口比较“个性”的TFT屏幕上。这活儿听起来像是把标准插头插到非标插座上,得自己动手改改线序。LVGL这几年…...

fold命令行工具:高效文本数据聚合与分析的瑞士军刀
1. 项目概述:一个为“折叠”而生的高效工具 最近在折腾一些数据处理和文件整理的工作流时,我一直在寻找一个能让我“折叠”起来思考的工具。我说的“折叠”,不是物理上的,而是逻辑上的——把复杂的、多维度的信息,按照…...
)
保姆级教程:INCA 7.2.3 从新建工程到观测标定的完整流程(附A2L文件处理技巧)
INCA 7.2.3 全流程实战指南:从工程搭建到参数标定的深度解析 在汽车电子开发领域,标定工具链的掌握程度直接影响开发效率。作为行业标准的INCA软件,其7.2.3版本在工程管理、实时观测和参数标定方面提供了更完善的解决方案。本文将采用"操…...

终极指南:5分钟掌握League Akari英雄联盟工具箱的强大功能
终极指南:5分钟掌握League Akari英雄联盟工具箱的强大功能 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款基于…...

Linux压缩归档与备份文件管理
Linux压缩归档与备份文件管理在 Linux 运维工作中,压缩与归档几乎无处不在。日志备份、数据迁移、配置留档、故障现场保存,都会涉及文件打包和压缩。如果缺乏规范,备份文件很容易散落各处、命名混乱、占用失控,最终从保障手段变成…...

AI Agent无障碍审查:自动化集成WCAG标准与axe-core实践
1. 项目概述:一个为AI助手打造的“无障碍”审查官最近在折腾AI应用开发,特别是那些能自动处理任务的智能体(AI Agent),发现一个挺有意思但容易被忽略的问题:我们费尽心思让AI能写代码、分析数据、生成报告&…...

PaperDebugger:用代码调试思维提升学术论文可复现性的工具实践
1. 项目概述:一个为学术论文“排雷”的智能调试器如果你和我一样,常年混迹在学术圈或者技术研发一线,肯定对下面这个场景深恶痛绝:好不容易读完一篇几十页的论文,满心欢喜地准备复现其中的算法或实验,结果发…...