4、数组、切片、map、channel
目录
- 一、数组
- 二、切片
- 三、map
- 四、channel
- 五、引用类型
一、数组
- 数组:
- 数组是块连续的内存空间,在声明的时候必须指定长度,且长度不能改变
- 所以数组在声明的时候就可以把内存空间分配好,并赋上默认值,即完成了初始化
- 数组的地址就是首元素的地址
- 一维数组初始化
func main() {var arr1 [5]int = [5]int{} //数组必须指定长度和类型,且长度和类型指定后不可改变var arr2 = [5]int{}var arr3 = [5]int{3, 2} //给前2个元素赋值var arr4 = [5]int{2: 15, 4: 30} //指定index赋值var arr5 = [...]int{3, 2, 6, 5, 4} //根据{}里元素的个数推断出数组的长度var arr6 = [...]struct {name stringage int}{{"Tom", 18}, {"Jim", 20}} //数组的元素类型由匿名结构体给定
}
- 二维数组初始化
func main() {//5行3列,只给前2行赋值,且前2行的所有列还没有赋满var arr1 = [5][3]int{{1}, {2, 3}}//第1维可以用...推测,第2维不能用...var arr2 = [...][3]int{{1}, {2, 3}}
}
- 访问数组里的元素
- 通过index访问
- 首元素 arr[0]
- 末元素 arr[len(arr)-1]
- 访问二维数组里的元素
- 位于第三行第四列的元素 arr[2][3]
- 通过index访问
func main() {//遍历数组里的元素//i, ele := range的理解// -> range返回2个,1个是索引i,1个是元素ele// -> 将range的返回用来声明并初始化i和elefor i, ele := range arr {fmt.Printf("index=%d, element=%d\n", i, ele)}//或者这样遍历数组for i := 0; i < len(arr); i++ { //len(arr)获取数组的长度fmt.Printf("index=%d, element=%d\n", i, arr[i])}//遍历二维数组for row, array := range arr { //先取出某一行for col, ele := range array { //再遍历这一行fmt.Printf("arr[%d][%d]=%d\n", row, col, ele)}}
}
- 通过for range遍历数组时取得的是数组里每一个元素的拷贝
func main() {arr := [...]int{1, 2, 3}for i, ele := range arr { //ele是arr中元素的拷贝arr[i] += 8 //修改arr里的元素,不影响elefmt.Printf("%d %d %d\n", i, arr[i], ele) //0 9 1ele += 1 //修改ele不影响arrfmt.Printf("%d %d %d\n", i, arr[i], ele) //0 9 2}for i := 0; i < len(arr); i++ {fmt.Printf("%d %d\n", i, arr[i])//0 9//1 10//2 11}
}
- 数组的cap和len:
- 在数组上调用cap()函数表示capacity容量,即给数组分配的内存空间可以容纳多少个元素;
- len()函数代表length长度,即目前数组里有几个元素;
- 由于数组初始化之后长度不会改变,不需要给它预留内存空间,所以len(arr)==cap(arr);
- 对于多维数组,其cap和len指第一维的长度
- 数组的参数传递
- 数组的长度和类型都是数组类型的一部分,函数传递数组类型时这两部分都必须吻合;
- go语言没有按引用传参,
全都是按值传参,即传递数组实际上传的是数组的拷贝,当数组的长度很大时,仅传参开销都很大; - 如果想修改函数外部的数组,就把它的指针(数组在内存里的地址)传进来
// 值传递拷贝
func arrPoint(arr [5]int) {fmt.Println(arr[0]) //1arr[0] += 10fmt.Println(arr[0]) //11
}// 指针传递地址
func arrPPoint(arr *[5]int) {fmt.Println(arr[0]) //1arr[0] += 10fmt.Println(arr[0]) //11
}func main() {var crr [5]int = [5]int{1, 2, 3, 6, 9}arrPoint(crr)fmt.Println(crr[0]) //1arrPPoint(&crr)fmt.Println(crr[0]) //11
}//// 参数必须是长度为5的int型数组(注意长度必须是5)
func update_array1(arr [5]int) {fmt.Printf("array in function, address is %p\n", &arr[0])arr[0] = 888
}func update_array2(arr *[5]int) {fmt.Printf("array in function, address is %p\n", &((*arr)[0]))arr[0] = 888 //因为传的是数组指针,所以直接在原来的内存空间上进行修改
}// range遍历是元素拷贝
func forRange() {arr := [...]int{1, 2, 3, 4, 5}for _, ele := range arr { // ele是arr里元素的拷贝ele += 10}fmt.Println(arr) //[1 2 3 4 5]
}二、切片
- 切片概念:切片是一个结构体,包含三个成员变量,array指向一块连续的内存空间,cap表示这块内存的大小,len表示目前该内存里存储了多少元素
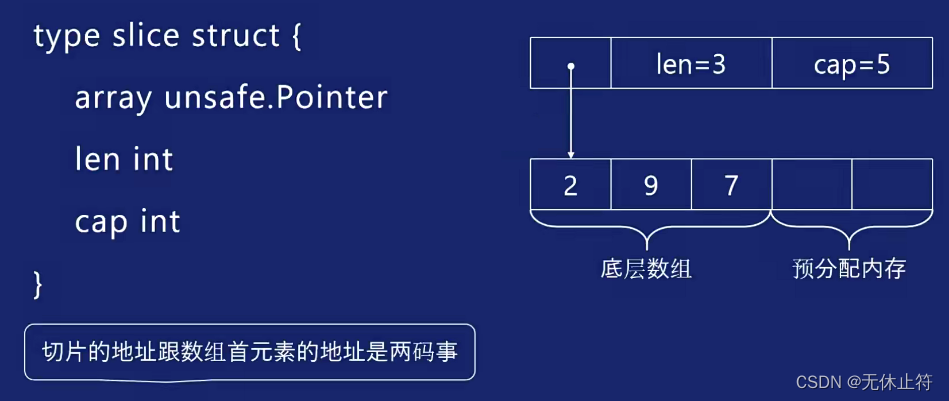
type slice struct {array unsafe.Pointerlen intcap int
}
- 切片的初始化
func main() {var s []int //切片声明,array=nil,len=cap=0s = []int{} //初始化,len=cap=0s = make([]int, 3) //初始化,len=cap=3s = make([]int, 3, 5) //初始化,len=3,cap=5s = []int{1, 2, 3, 4, 5} //初始化,len=cap=5s2d := [][]int{{1}, {2, 3}, //二维数组各行的列数相等,但二维切片各行的len可以不等}
}
- 切片的特点:
- 切片相对于数组最大的特点就是可以追加元素,可以自动扩容
- 追加的元素放到预留的内存空间里,同时len加1
- 如果预留空间已用完,则会重新申请一块更大的内存空间,capacity大约变成之前的2倍(cap<1024)或1.25倍(cap>1024);把原内存空间的数据拷贝过来,在新内存空间上执行append操作
func sliceAppend() {s := make([]int, 3, 5)fmt.Println(len(s), cap(s)) // 3 5s = append(s, 100)fmt.Println(len(s), cap(s)) // 4 5s = append(s, 100)fmt.Println(len(s), cap(s)) // 5 5s = append(s, 100)fmt.Println(len(s), cap(s)) // 6 10
}// 2倍扩容验证
// cap 5 -> 10
// cap 10 -> 20
// cap 20 -> 40
// cap 40 -> 80
// cap 80 -> 160
func coef_cap() {s := make([]int, 0, 5)preCap := cap(s)for i := 0; i < 100; i++ {s = append(s, 0)curCap := cap(s)if curCap > preCap {fmt.Printf("cap %d -> %d\n", preCap, curCap)preCap = curCap}}
}
- 截取子切片:子切片与目切片的内存共享与内存分离
func sub_slice() {arr := make([]int, 3, 5)crr := arr[0:2] //左闭右开crr[1] = 8fmt.Println(arr) // [0 8 0] 子切片与母切片共享内存空间crr = append(crr, 9)fmt.Println(arr) // [0 8 9]fmt.Printf("%p %p\n", &arr[0], &crr[0]) // 0xc0000103f0 0xc0000103f0crr = append(crr, 9)crr = append(crr, 9)// 此时子切片申请一片新的内存,把老数据先拷贝过来,在新内存上执行append操作// 此时子切片已经与母切片内存分离crr = append(crr, 9)fmt.Println(arr) // [0 8 9]fmt.Println(crr) // [0 8 9 9 9]fmt.Printf("%p %p\n", &arr[0], &crr[0]) // 0xc0000103f0 0xc000014230
}
- 子切片传参:
- go语言函数传参,传的都是值,即传切片会把切片的{arrayPointer, len, cap}这3个字段拷贝一份传进来
- 由于传的是底层数组的指针,所以可以直接修改底层数组里的元素
func update_slice(s []int) {s[0] = 100
}func main() {s := []int{1, 2, 3}update_slice(s)fmt.Println(s) // [100 2 3]
}
三、map
- map的底层原理:go map的底层实现是hash table,根据key查找value的时间复杂度是O(1)
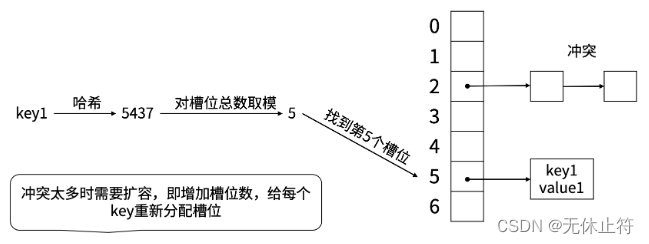
- map的初始化
func main() {var m map[string]int //声明map,指定key和value的数据类型m = make(map[string]int) //初始化,容量为0m = make(map[string]int, 5) //初始化,容量为5。强烈建议初始化时给一个合适的容量,减少扩容的概率m = map[string]int{"语文": 0, "数学": 39} //初始化时直接赋值
}
- 获取map的长度:len(m)获取map的长度(map中的key数量),go不支持对map上执行cap函数
- 添加和删除key
func main() {m["英语"] = 59 //往map里添加key-value对m["英语"] = 70 //会覆盖之前的值delete(m, "数学") //从map里删除key-value对
}
- map读取key对应的value值:读取key对应的value时,如果key不存在,则返回value类型的默认值,所以强烈建议先判断key是否存在
func main() {if value, exists := m["语文"]; exists {fmt.Println(value)} else {fmt.Println("map里不存在[语文]这个key")}
}
- map遍历:多次遍历map返回的顺序是不一样的,但相对顺序是一样的,因为每次随机选择一个开始位置,然后顺序遍历
func main() {m := make(map[string]int)m["a"] = 10m["b"] = 20m["c"] = 30//遍历mapfor key, value := range m {value += 100 //range的value是值拷贝fmt.Printf("%s=%d\n", key, value)//a=110//b=120//c=130}fmt.Println(m) //map[a:10 b:20 c:30]for key := range m {m[key] += 200 //使用key直接对map的原数据进行操作}fmt.Println(m) //map[a:210 b:220 c:230]}
四、channel
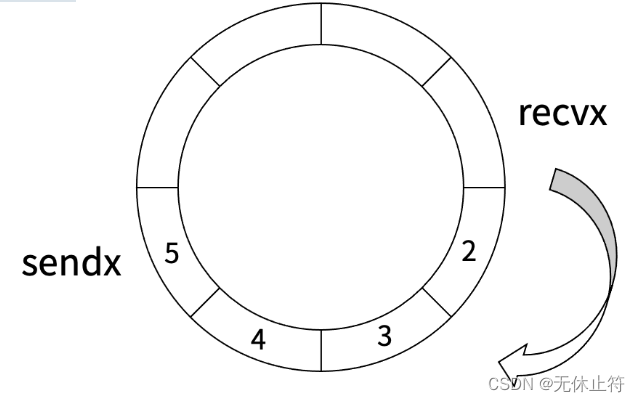
- channel底层:
- channel(管道)底层是一个环形队列(先进先出),send(插入)和recv(取走)从同一个位置沿同一个方向顺序执行
- sendx表示最后一次插入元素的位置,recvx表示最后一次取走元素的位置
- channel初始化
func main() {var ch chan int //声明ch = make(chan int, 8) //初始化,环形队列里可容纳8个int
}
- channel的len和cap
func main() {var ch chan intfmt.Printf("ch is nil %t\n", ch == nil) //ch is nil truefmt.Printf("len of ch is %d\n", len(ch)) //len of ch is 0ch = make(chan int, 10)fmt.Printf("len of ch is %d\n", len(ch)) //len of ch is 0fmt.Printf("cap of ch is %d\n", cap(ch)) //cap of ch is 10
}
- channel的cap上限:达到cap的上限后,继续send会导致管道阻塞
func main() {ch := make(chan int, 10)for i := 0; i < 10; i++ {ch <- 3}fmt.Printf("len of ch is %d\n", len(ch)) //len of ch is 10fmt.Printf("cap of ch is %d\n", cap(ch)) //cap of ch is 10ch <- 3 //阻塞fmt.Printf("len of ch is %d\n", len(ch)) //不会打印fmt.Printf("cap of ch is %d\n", cap(ch)) //不会打印
}
- send和recv
func main() {ch := make(chan int, 8) //初始化,环形队列里可容纳8个intch <- 1 //往管道里写入(send)数据ch <- 2ch <- 3ch <- 4ch <- 5v := <-ch //从管道里取走(recv)数据fmt.Println(v) //1v = <-chfmt.Println(v) //2
}
- channel遍历:
- 通过for range的方式遍历管道,遍历前必须先关闭
close(ch)管道,禁止再写入元素; - 一旦close就不能再往管道里面追加元素
- 通过for range的方式遍历管道,遍历前必须先关闭
close(ch) //遍历前必须先关闭管道,禁止再写入元素//遍历管道里剩下的元素for ele := range ch {fmt.Println(ele) //3 4 5}
五、引用类型
- 引用类型
- slice、map和channel是go语言里的3种引用类型,都可以通过make函数来进行初始化(申请内存分配)
- 因为它们都包含一个指向底层数据结构的指针,所以称之为“引用”类型
- 引用类型未初始化时都是nil,可以对它们执行len()函数,返回0
相关文章:
4、数组、切片、map、channel
目录一、数组二、切片三、map四、channel五、引用类型一、数组 数组: 数组是块连续的内存空间,在声明的时候必须指定长度,且长度不能改变所以数组在声明的时候就可以把内存空间分配好,并赋上默认值,即完成了初始化数组…...

270 uuid
270 uuid 用途 For the creation of RFC4122 UUIDs 可靠性 10000 星星 适应于浏览器或者服务器 官网链接 https://www.npmjs.com/package/uuid https://github.com/uuidjs/uuid 基本使用 import { v4 as uuidv4 } from uuid; uuidv4(); // ⇨ 9b1deb4d-3b7d-4bad-9bdd-2b0d7b3d…...

2023最新简历模板免费下载
下面分享5个简历模板网站,免费下载,建议收藏! 2023用最漂亮的简历模板,让面试官眼前一亮。 1、菜鸟图库 个人简历模板|WORD文档模板免费下载 - 菜鸟图库 菜鸟图库除了有超多设计类素材之外,还有很多办公类素材&#…...

【CSS】元素居中总结-水平居中、垂直居中、水平垂直居中
【CSS】元素居中一、 水平居中1.行内元素水平居中(1)text-align2.块级元素水平居中2.1 margin(1)margin2.2布局(1)flex justify-content(推荐)(2) flexmargin…...

spring实现AOP
文章目录前言一、AOP的底层实现原理二、AOP的两种开发模式1.使用xml配置文件1.1 添加AOP依赖1.2 创建UserService1.3创建UserServiceImpl1.4创建通知类1.5 创建applicationContext.xml(添加aop约束)1.6 测试2.使用注解开发2.1 创建bean.xml文件配置注解方…...

neovim搭建cpp环境
文章目录Windowns下NeoVim搭建cpp环境NeoVim安装插件vim-plugindentLinevim-airlinectagstagbarcoc.vimWindowns下NeoVim搭建cpp环境 在开发过程中习惯在DIE环境中使用vim作为编辑器,在单独的编辑器也常使用gvim图形化编辑器。最近看到NeoVim的特性及兼容性方面不输…...

SpringBoot AES加密 PKCS7Padding 模式
AES 简介:DES 全称为Data Encryption Standard,即数据加密标准,是一种使用密钥加密的块算法,1977年被美国联邦政府的国家标准局确定为联邦资料处理标准(FIPS) AES 密码学中的高级加密标准(Advan…...

按键输入驱动
目录 一、硬件原理 二、添加设备树 1、创建pinctrl 2、创建节点 3、检查 编译复制 三、修改工程模板编辑 四、驱动编写 1、添加keyio函数 2、添加调用 3、驱动出口函数添加释放 4、添加原子操作 5、添加两个宏定义 6、初始化原始变量 7、打开操作 8、读操作 总体代…...

2023年第七周总周结 | 开学倒数第三周
为什么要做周总结? 1.避免跳相似的坑 2.客观了解上周学习进度并反思,制定可完成的下周规划 一、上周问题解决情况 晚上熬夜导致第二天学习状态不好 这周熬夜一天,晚上帮亲戚修手机到22:30,可能是晚上自己的事什么都没做ÿ…...
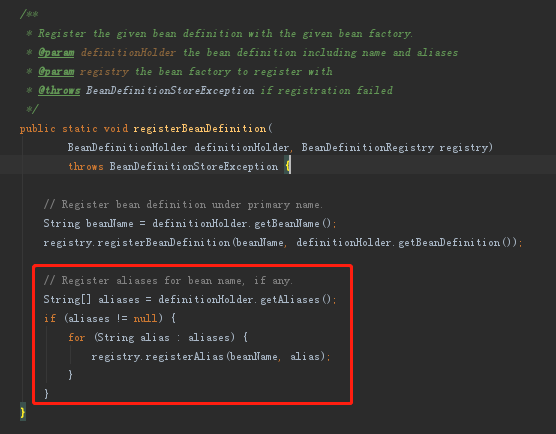
Springboot扫描注解类
Springboot扫描注解类的入口在AbstractApplicationContext的refresh中,对启动步骤不太了解的,可参考https://blog.csdn.net/leadseczgw01/article/details/128930925BeanDefinitionRegistryPostProcessor接口有多个实现类,扫描Controller、Se…...

Apache日志分析器
您的Apache HTTP服务器生成的日志数据是信息的宝库。使用这些信息,您可以判断您服务器的使用情况、找出漏洞所在,并设法改进服务器结构和整体性能。审核您的Apache日志可在以下情况派上用场,其中包括:识别和纠正频繁出现的错误以增…...

啪,还敢抛出异常
🙉 作者简介: 全栈领域新星创作者 ;天天被业务折腾得死去活来的同时依然保有对各项技术热忱的追求,把分享变成一种习惯,再小的帆也能远航。 🏡 个人主页:xiezhr的个人主页 前言 去年又重新刷了…...

Apache JMeter 5.5 下载安装以及设置中文教程
Apache JMeter 5.5 下载安装以及设置中文教程JMeter下载Apache JMeter 5.5配置环境变量查看配置JDK配置JMeter环境变量运行JMeter配置中文版一次性永久设置正文JMeter 下载Apache JMeter 5.5 官方网站:Apache JMeter 官网 版本介绍: 版本中一个是Bina…...
string类模拟实现
了解过string常用接口后,接下来的任务就是模拟实现string类。 目录 VS下的string结构 默认成员函数和简单接口 string结构 c_str()、size()、capacity()、clear()、swap() 构造函数 拷贝构造函数 赋值重载 析构函数 访问及遍历 容量操作 reserve resize …...
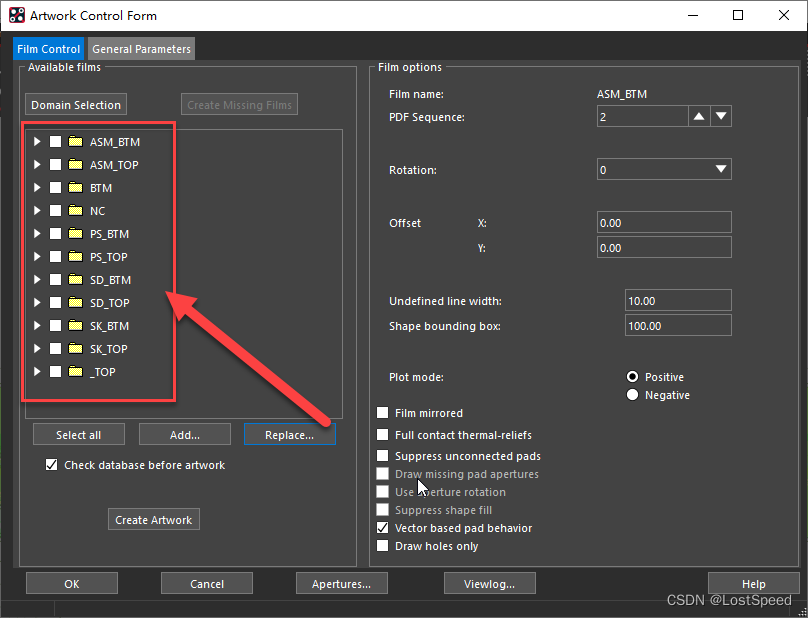
cadence SPB17.4 S032 - allegro - 保存/载入光绘层定义
文章目录cadence SPB17.4 S032 - allegro - 保存/载入光绘层定义概述保存光绘层在新板子中载入已经保存的相同类型老板子定义好的光绘层定义文件碎碎念ENDcadence SPB17.4 S032 - allegro - 保存/载入光绘层定义 概述 以前布线完成, 准备出板厂文件时, 总是要手工重新建立光绘…...

微服务实战--高级篇:分布式缓存 Redis
分布式缓存 – 基于Redis集群解决单机Redis存在的问题 单机的Redis存在四大问题: 1.Redis持久化 Redis有两种持久化方案: RDB持久化AOF持久化 1.1.RDB持久化 RDB全称Redis Database Backup file(Redis数据备份文件)…...

【C语言】可变参数列表
本篇博客让我们来认识一下C语言学习过程中往往被忽略的可变参数列表 所谓可变参数,就是一个不限定参数数量的函数,我们可以往里面传入任意个数的参数,以达成某些目的。 关联:C11可变模板参数;本文首发于 慕雪的寒舍 …...

目标检测的旋框框文献学习
这是最近打算看完的文献,一天一篇 接下来将记录一下文献阅读笔记,避免过两天就忘了 RRPN 论文题目:Arbitrary-Oriented Scene Text Detection via Rotation Proposals 论文题目:通过旋转方案进行任意方向的场景文本检测&#x…...

Hive 在工作中的调优总结
总结了一下在以往工作中,对于Hive SQL调优的一些实际应用,是日常积累的一些优化技巧,如有出入,欢迎在评论区留言探讨~ EXPLAIN 查看执行计划 建表优化 分区 分区表基本操作,partitioned二级分区动态分区 分桶 分…...

每天一道大厂SQL题【Day09】充值日志SQL实战
每天一道大厂SQL题【Day09】充值日志SQL实战 大家好,我是Maynor。相信大家和我一样,都有一个大厂梦,作为一名资深大数据选手,深知SQL重要性,接下来我准备用100天时间,基于大数据岗面试中的经典SQL题&#…...

Windows动态光标优化:LuumaCursorHelper工具包详解与实战指南
1. 项目概述与核心价值最近在折腾一个挺有意思的小工具,起因是发现很多朋友在用LuumaCursor这款动态光标主题时,总会遇到一些“小麻烦”。比如,安装后光标在某些应用里不显示、动画卡顿,或者想自定义一下效果却无从下手。我自己也…...

别再乱用`return`了!深入理解Lua函数多返回值:`table.unpack`的妙用与尾调用优化
别再乱用return了!深入理解Lua函数多返回值:table.unpack的妙用与尾调用优化 在游戏开发中,我们经常需要处理复杂的技能系统。比如一个火球术可能同时返回伤害值、燃烧效果、目标列表等多个数据。新手开发者往往会写出这样的代码:…...

【信息科学与工程学】【人工智能】【知识工程】企业知识库管理与评估-第四篇-市场篇
一、企业价格知识管理参数体系 1.1、价格知识管理参数列表 内部交易价格参数 参数名称 参数定义 计算公式 计量单位 数据来源 部门间转移定价准确率 内部转移定价的准确程度 准确转移定价次数 / 总转移定价次数 100% % 财务系统、转移定价记录 成本中心计价合规率…...

XUnity.AutoTranslator:5步实现Unity游戏实时翻译的完整解决方案
XUnity.AutoTranslator:5步实现Unity游戏实时翻译的完整解决方案 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾经因为语言障碍而错过心仪的外语游戏?XUnity.AutoTransla…...

深度实战:如何用League Akari将英雄联盟游戏效率提升300%的终极秘籍
深度实战:如何用League Akari将英雄联盟游戏效率提升300%的终极秘籍 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否经历过在…...

明日方舟基建自动化终极方案:Arknights-Mower 智能管理工具完全指南
明日方舟基建自动化终极方案:Arknights-Mower 智能管理工具完全指南 【免费下载链接】arknights-mower 《明日方舟》长草助手 项目地址: https://gitcode.com/gh_mirrors/ar/arknights-mower 还在为《明日方舟》中繁琐的基建管理而苦恼吗?每天需要…...

终极指南:如何快速解决Windows应用程序运行库缺失问题
终极指南:如何快速解决Windows应用程序运行库缺失问题 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过这样的情况:下载了…...

5分钟解锁B站视频解析:用开源工具实现自由播放的终极方案
5分钟解锁B站视频解析:用开源工具实现自由播放的终极方案 【免费下载链接】bilibili-parse bilibili Video API 项目地址: https://gitcode.com/gh_mirrors/bi/bilibili-parse 你知道吗?每次你在B站观看视频时,背后其实有一套精密的视…...

HC32F460移植指南:除了代码,你还需要搞定Keil、J-Flash和驱动库这三大件
HC32F460开发环境搭建实战:从工具链配置到驱动库迁移 第一次拿到华大HC32F460开发板时,我对着Keil里找不到的芯片型号和一堆陌生的驱动库文件陷入了沉思。与STM32生态相比,华大MCU的开发环境搭建确实存在不少"坑点"。本文将分享一套…...
)
Origin 9.1 保姆级教程:从数据归一化到论文级图表导出(附避坑指南)
Origin 9.1 科研数据处理与图表输出全流程实战指南 科研数据的可视化呈现是论文写作中不可或缺的一环。作为一款功能强大的科学绘图软件,Origin 9.1在学术界有着广泛的应用。本文将系统性地介绍从数据预处理到高质量图表导出的完整工作流程,特别针对科研…...