24/12/9 算法笔记<强化学习> PPO,DPPO
PPO是目前非常流行的增强学习算法,OpenAI把PPO作为目前baseline算法,首选PPO,可想而知,PPO可能不是最强的,但是是最广泛的。
PPO是基于AC架构,因为AC架构有一个好处,就是解决了连续动作空间的问题。
AC输出连续动作
什么是连续动作呢,也就是不仅有动作,而且还有动作的力度大小的概念,就像开车,不仅有方向还要控制油门踩多深,刹车踩多少,转向多少的问题,离散动作是可数的,连续是不可数的。
On-Policy和Off-Policy
例如PG就是一个在线策略,因为PG用于产生数据的策略,和需要更新的策略是一致的。
而DQN是一个离线策略,简而言之就是可以运用之前的数据来更新。
但为什么PG和AC中的Actor更新不能像DQN一样,把数据存起来,更新多次呢?
答案是在一定条件下可以。PPO就是做这个工作的,在了解什么情况下可以的时候,我们先来了解下,为什么不能。

假设我们在一个已知环境下,有两个动作可以选择。现在两个策略,分别是P:[0.5,0.5]和B:[0.1,0.9]
现在我们按照两个策略,进行采样,也就是分别按照这两个策略,以S这套下出发,与环境进行10次互动。获得如图数据,那么,我们可以用B策略下获得的数据,更新P吗?
答案是不行,回顾一下PG算法,PG算法会按照TD-error作为权重,更新策略。权重越大,更新幅度越大,权重越小,更新幅度越小。
Important sampling
那么PPO是怎么做到离线更新策略的呢?答案是Important-sampling,重要性采样技术,如果我们想用策略B抽样出来的数据来更新策略P也不是不可以,但是我们要把TD-error乘以一个重要性权重IW(importance weight)。
IW = P(a) / B(a)
回到我们之前的例子,我们可以计算出,每个动作的重要性权重,P:[0.5,0.5]和B:[0.1,0.9]:
IWa1 = P/B = 0.5/0.1 = 5
IWa2 = P/B = 0.5/0.9 = 0.55
New TD error for a1 = 5 * 1.5 = 7.5
New TD error fot a2 = 0.55 * 1 = 0.55
我们把重要性权重乘以TD-error,我们发现,a1的TD-error大幅度提升,而a2 的TD-error减少了,现在即使我们用P策略:[0.5,0.5]进行更新,a1提升的概率也会比a2 的更多。
PPO应用了importance sampling,使得我们用行为策略获取的数据,能够更新目标策略,把AC从在线策略,变成离线策略。
那么我们为什么可以这样做呢?
回想PG
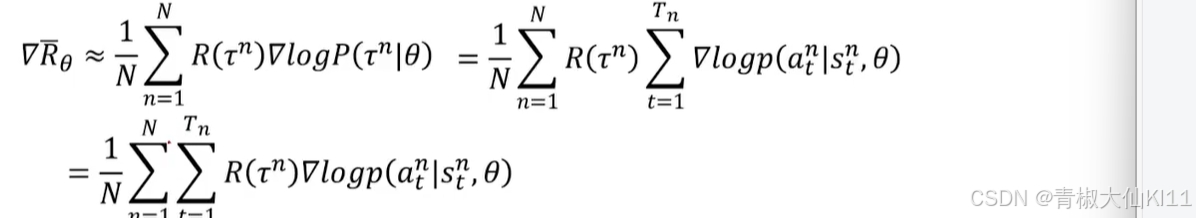
其实可以把它理解为是在求一个期望,通过不断的sample然后求平均去近似期望值

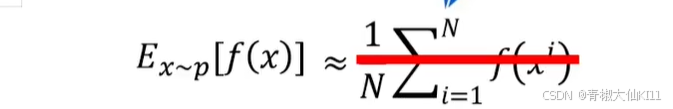
因为我们的经验数据中有很多模型的经验数据,比如B策略的这个经验数据
如果我们不能从p来sample,只能从q来sample,做一下变换。
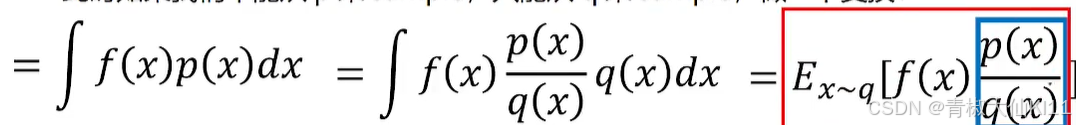
Importance sampling的问题
同学们都清楚,比如两个正态分布的期望一样,但是只要是
不同,就是不一样的正态分布,所以我们上面即使乘上了importance weight对q的期望
进行了修正,但是方差也是不同的
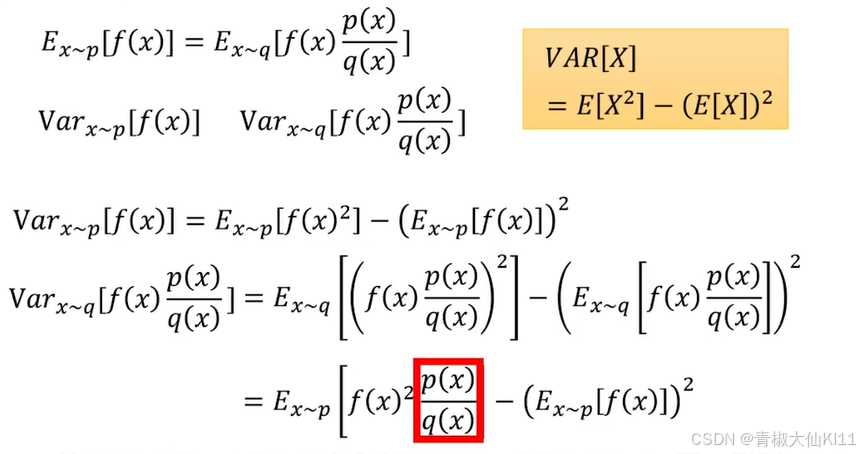
所以结论就是由于修正后期望是一样的,但是方差公式不同,假设我们对p和q采样sample的次数足够多,它们会是一样的,原因是期望;但是当sample次数不够多时,由于方差不一样,方差差距越大,那么sample就有可能得到非常大的差距。
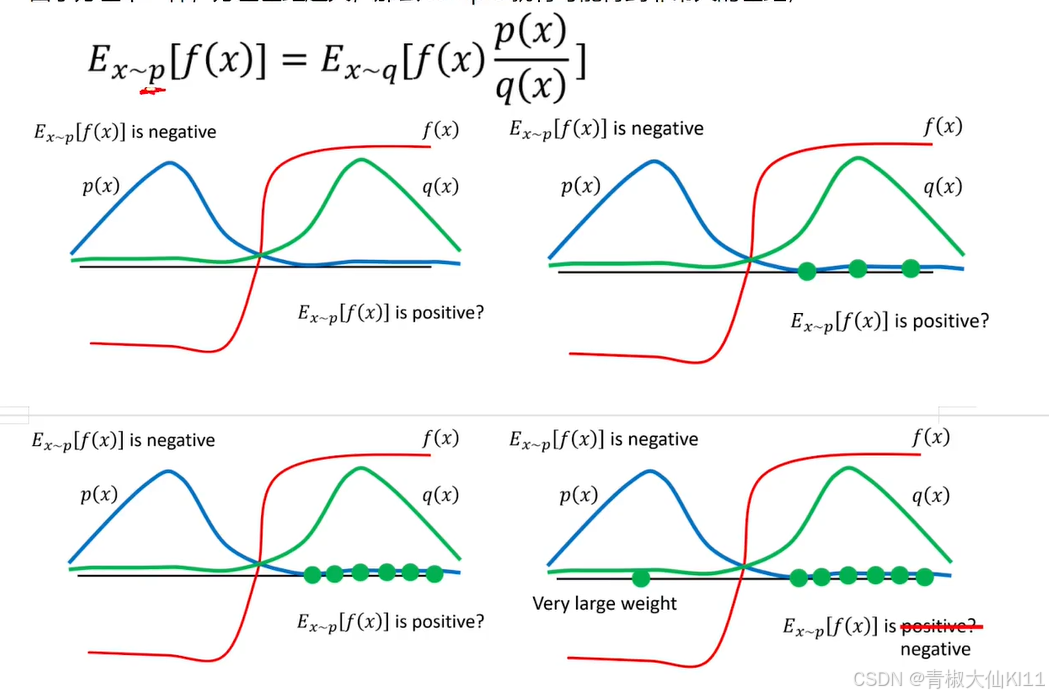
Add Constraint
当两个分布差距太大的时候,就会有问题,于是我们还得限制两个分布差距不能太大

在PPO1里面,用了是KL散度(相对熵)来衡量两个分布的差距,作为一个惩罚项来出现,KL散度是一种衡量两个概率分布的匹配程度的指标,两个分布差异越大,KL散度越大。
注意的是,这里KL计算的还真不是参数上面的距离,而是参数使得行为action表现上面的距离,也就是策略的距离。策略就是action上面的几率分布。
是可以动态调整的:

TRPO
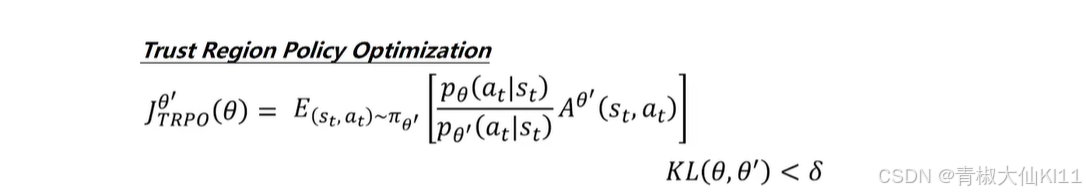
将KL散度当成一个约束条件。
PPO2
PPO2简单粗暴,直接裁剪了更新范围,但是这种方法却出乎意料地好
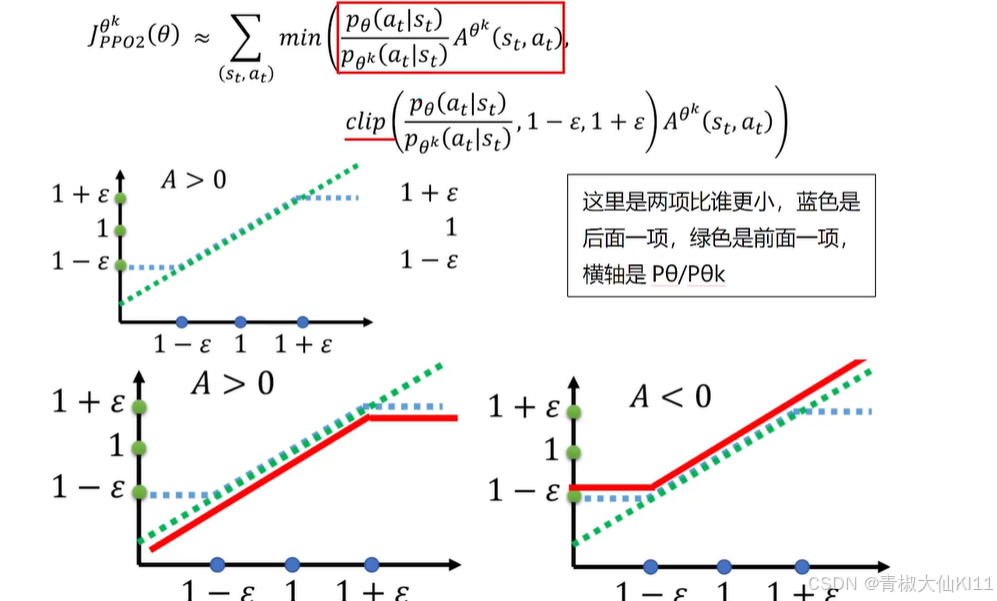
为什么这样限制就ok了呢?因为当A>0时,一定是(st,at)是好的,那么我们就希望P(st,st)变大,回头训练调参就会使得P
/ P
K变大,但是如果不断训练变得太大,他们就不相似了,那么constraint限制住它们的比例不能超过1-
,反而亦然。
代码实现以及核心
动作采样(PPO类的get_action方法)
def get_action(self, state):state = torch.from_numpy(state).float().unsqueeze(0)dist = self.policy(state)action = dist.sample()return action.item(), dist.log_prob(action)将处理后的状态输入到策略网络(self.policy,即 PolicyNetwork 类的实例)中,策略网络输出一个动作的概率分布,然后从这个概率分布中采样出一个动作,同时返回这个动作以及对应的对数概率。对数概率在后续计算策略更新时会用到,它用于衡量当前策略产生这个动作的可能性大小。
优势函数估计(PPO类的update方法中相关部分)
# 计算优势函数估计
returns = []
Gt = 0
for r, d in zip(reversed(rewards), reversed(dones)):Gt = r + self.gamma * Gt * (1 - d)returns.insert(0, Gt)
returns = torch.stack(returns)values = self.value(states)
advantages = returns - values.detach()- 回报(
returns)计算:按照时间步从后往前遍历每一步的即时奖励(rewards)和是否结束(dones)标志。通过动态规划的思想,利用折扣因子(gamma)来累计计算从当前时间步到最终时间步的折扣奖励总和,也就是回报Gt。例如,最后一步的回报就是最后一步的即时奖励,如果不是最后一步,则回报等于当前即时奖励加上下一个时间步回报乘以折扣因子(如果下一个时间步未结束)。最后将计算好的每一步回报组成一个张量returns。
- 优势函数计算:使用价值网络(
self.value,即ValueNetwork类的实例)对每个状态估计其价值(values = self.value(states)),这个估计的价值可以理解为从该状态开始按照当前策略后续能获得的期望奖励。然后用计算得到的回报returns减去价值网络估计的价值(这里要使用detach分离梯度,因为在计算优势函数时不希望价值网络的梯度传播影响到后续对回报的计算等),得到的差值advantages就是优势函数,它反映了在某个状态下采取某个动作相较于平均水平的好坏程度,是后续策略更新的关键依据。
策略更新(PPO类的update方法中相关部分)
dist = self.policy(states)
log_probs = dist.log_prob(actions.squeeze())
ratio = torch.exp(log_probs - old_log_probs.squeeze())
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1 - self.clip_eps, 1 + self.clip_eps) * advantages
actor_loss = -torch.min(surr1, surr2).mean()
self.optimizer_actor.zero_grad()
actor_loss.backward()
self.optimizer_actor.step() 首先将当前收集到的一系列状态(states)再次输入策略网络得到新的动作概率分布(dist),并计算出当前策略下对应之前所采取动作(actions)的对数概率(log_probs),然后和之前记录的旧策略下这些动作的对数概率(old_log_probs)相比较,计算出概率比率 ratio(通过指数运算得到新旧概率的比率)。接着,根据这个比率和优势函数计算出两个替代目标函数 surr1 和 surr2,其中 surr2 是对 ratio 进行了裁剪(clip)操作后的结果,限制策略更新的幅度,避免过大的策略更新导致性能变差,这是 PPO 算法的关键技巧之一。
取 surr1 和 surr2 中的较小值作为最终的策略损失(actor_loss),这样可以保证策略更新朝着让策略更好的方向进行,同时又有一定的约束。然后通过清空梯度(zero_grad)、反向传播(backward)和执行一步优化器更新(step)来更新策略网络的参数,使得策略网络朝着更优的方向调整。
DPPO
DPPO 是在深度确定性策略梯度(DDPG)算法基础上结合 PPO 的一些思想发展而来的。DDPG 主要用于处理连续动作空间的问题,它使用深度神经网络来逼近策略函数和价值函数。
和A3C一样,DPPO是希望多个智能体同时和环境互动,并对全局的PPO网络更新。
在A3C,我们需要跑数据并且计算好梯度,再更新全局网络。这是因为AC是一个在线的算法,所以在更新的时候,产生的数据和更新的策略需要同一个网络,所以我们不能把worker阐述的数据,直接给全局网络计算梯度使用。
但PPO解决了离线更新的问题,所以DPPO的worker只需要提供数据给全局网络,由全局网络从数据中直接学习。
但是这两项工作是不能同时的,当全局网络在学习的时候,workers需要等待全局网络学习完,才能干活,workers在干活的时候,全局网络就需要等待worker提供数据。
关键代码
select_action 方法
def select_action(self, state):state = torch.FloatTensor(state).unsqueeze(0)action = self.actor(state).detach().numpy()[0]return action该方法用于根据当前策略网络(Actor),给定一个状态来选择相应的动作,是智能体与环境交互过程中每次选择动作的关键操作,它将状态转换为网络输入的张量格式,经过策略网络计算后得到动作并转换为 numpy 数组返回,以便能在环境中执行该动作。
update 方法
def update(self):if len(self.memory) < self.batch_size:returnsamples = random.sample(self.memory, self.batch_size)states, actions, rewards, next_states, dones = zip(*samples)states = torch.FloatTensor(states)actions = torch.FloatTensor(actions).unsqueeze(1)rewards = torch.FloatTensor(rewards).unsqueeze(1)next_states = torch.FloatTensor(next_states)dones = torch.FloatTensor(dones).unsqueeze(1)# 计算目标价值target_values = rewards + (1 - dones) * self.gamma * self.critic(next_states)# 更新价值网络values = self.critic(states)critic_loss = nn.MSELoss()(values, target_values.detach())self.critic_optimizer.zero_grad()critic_loss.backward()self.critic_optimizer.step()# 计算优势函数估计值advantages = target_values - values.detach()# 计算旧策略的动作概率old_action_probs = self.actor(states).gather(1, actions.long())# 计算新策略的动作概率new_action_probs = self.actor(states)ratio = (new_action_probs / (old_action_probs + 1e-10)).gather(1, actions.long())# 计算PPO的裁剪损失surr1 = ratio * advantagessurr2 = torch.clamp(ratio, 1 - self.eps_clip, 1 + self.eps_clip) * advantagesactor_loss = -torch.min(surr1, surr2).mean()# 更新策略网络self.actor_optimizer.zero_grad()actor_loss.backward()self.actor_optimizer.step()update方法是整个DPPO算法的核心训练逻辑所在。它从经验回放缓冲区(memory)中采样一批数据,先基于这批数据计算目标价值来更新价值网络(Critic),然后通过计算优势函数估计值、新旧策略的动作概率等,进而计算策略网络(Actor)的裁剪损失,最终实现对策略网络和价值网络的更新优化,使得智能体能够不断改进其策略以获得更多奖励。
DDPO和PPO的区别
基本区别
PPO: 它主要是为了解决传统策略梯度方法(如 A2C、A3C)在更新策略时样本效率较低和训练不稳定的问题,通过限制新策略和旧策略之间的差异来提高训练效率。
DPPO: 它更像是深度确定性策略梯度(DDPG)算法与 PPO 思想的结合。DPPO 主要用于连续动作空间的强化学习问题,而 PPO 可以用于离散和连续动作空间。
动作空间适用性差异
PPO: 通用性较强,能够很好地处理离散动作空间问题。
DPPO: 主要是为连续动作空间设计的。
策略更新方式差异
PPO: 最常见的是PPO-clip。它通过裁剪目标函数中的概率比(新旧策略下动作概率的比值)来限制新策略和旧策略的差异。具体来说,定义一个裁剪参数,计算新旧策略的概率比
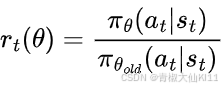 ,然后通过
,然后通过
来更新策略,其中![]() 是优势函数估计值。
是优势函数估计值。
DPPO: 策略更新结合了 DDPG 的一些特点。在 DDPG 中,策略网络(Actor)的更新是基于策略梯度定理,通过最大化累计奖励的期望来更新。DPPO 在这个基础上,类似于 PPO,会采取措施保证策略更新的稳定性。例如,它会利用经验回放等机制,在更新 Actor 网络时,考虑 Critic 网络评估的状态价值变化以及策略网络输出动作的变化,同时限制策略变化的幅度。
网络架构差异
PPO采用A-C架构
DPPO继承了DPPG的网络架构特点,有一个Actor网络用于输出连续动作,一个Critic网络用于评估状态价值。
相关文章:

24/12/9 算法笔记<强化学习> PPO,DPPO
PPO是目前非常流行的增强学习算法,OpenAI把PPO作为目前baseline算法,首选PPO,可想而知,PPO可能不是最强的,但是是最广泛的。 PPO是基于AC架构,因为AC架构有一个好处,就是解决了连续动作空间的问…...
Linux下编译安装METIS
本文记录Linux下编译安装METIS的流程。 零、环境 操作系统Ubuntu 22.04.4 LTSVS Code1.92.1Git2.34.1GCC11.4.0CMake3.22.1 一、安装依赖 1.1 下载GKlib sudo apt-get install build-essential sudo apt-get install cmake 2.2 编译安装GKlib 下载GKlib代码, …...

【数据库】关系代数和SQL语句
一 对于教学数据库的三个基本表 学生S(S#,SNAME,AGE,SEX) 学习SC(S#,C#,GRADE) 课程(C#,CNAME,TEACHER) (1)试用关系代数表达式和SQL语句表示:检索WANG同学不学的课程号 select C# from C where C# not in(select C# from SCwhere S# in…...

amazon亚马逊滑动识别验证码
注意,本文只提供学习的思路,严禁违反法律以及破坏信息系统等行为,本文只提供思路 如有侵犯,请联系作者下架 本文识别已同步上线至OCR识别网站: http://yxlocr.nat300.top/ocr/other/15 亚马逊的滑动还原验证码数据集如下: 和某顶象的差不多,图片分割高度是中间固定的,…...

Android Studio 创建虚拟设备的详细图文操作教程
本篇文章主要讲解 Android Studio 创建模拟器详细图文操作,包含了每一步的详细操作,便于理解和掌握对模拟的创建。 日期:2024年12月9日 作者:任聪聪 运行效果: 说明:创建运行后,点击右侧如下图…...

网络安全法-附则
第七章 附 则 第七十六条 本法下列用语的含义: (一)网络,是指由计算机或者其他信息终端及相关设备组成的按照一定的规则和程序对信息进行收集、存储、传输、交换、处理的系统。 (二)网络安全ÿ…...
)
CSS核心(上)
CSS 介绍 层叠样式表(英语:Cascading Style Sheets, 缩写:CSS; 又叫串样式列表,级联样式表,串接样式表,阶层式样式表)是一种用来为结构化文档(HTML或XML应用)添加样式(…...

深度学习常用损失函数介绍
均方差损失(Mean Square Error,MSE) 均方误差损失又称为二次损失、L2损失,常用于回归预测任务中。均方误差函数通过计算预测值和实际值之间距离(即误差)的平方来衡量模型优劣。即预测值和真实值越接近&…...

HarmonyOS-中级(四)
文章目录 Native适配开发三方库的基本使用 🏡作者主页:点击! 🤖HarmonyOS专栏:点击! ⏰️创作时间:2024年12月09日11点12分 Native适配开发 Node-API HarmonyOS Node-API 是 HarmonyOS 提供的…...

React v19稳定版发布12.5
🤖 作者简介:水煮白菜王 ,一位资深前端劝退师 👻 👀 文章专栏: 前端专栏 ,记录一下平时在博客写作中,总结出的一些开发技巧✍。 感谢支持💕💕💕 目…...

【毕业设计选题】深度学习类毕业设计选题参考 开题指导
目录 前言 毕设选题 开题指导建议 更多精选选题 选题帮助 最后 前言 大家好,这里是海浪学长毕设专题! 大四是整个大学期间最忙碌的时光,一边要忙着准备考研、考公、考教资或者实习为毕业后面临的升学就业做准备,一边要为毕业设计耗费大量精力。学长给大家整…...

NanoLog起步笔记-4-Server端的两个线程
nonolog起步笔记-4-Server端的两个线程 Server端的两个线程两个线程的角色与各自的职责RuntimeLogger::compressionThreadMain线程 详细学习一下相关的代码第三个线程第一次出现原位置swip buffer Server端的两个线程 如前所述,nanolog的server端,相对而…...

linux zookeeper安装并服务化
1.版本信息 系统:centos7.6 java版本:java 8(已经安装好) zookeeper版本:3.6.3 2.zookeeper安装并测试 1.上传文件至指定目录并解压 切换至cd downloads 目录下, rz上传文件 解压:tar -zxvf apache-zookeeper-3.…...

很简单,但是很实用。把docker run改写成docker compose。
很简单,但是很实用。把docker run改写成docker compose。 在Docker的世界里,docker run命令是启动容器最直接的方式之一。然而,当项目复杂度增加,涉及多个服务时,管理这些容器和服务之间的依赖关系就会变得繁琐。这时,使用Docker Compose来定义和运行多容器Docker应用就…...

DAMODEL丹摩|丹摩平台:AI时代的开发者福音
本文仅对丹摩平台进行介绍,非广告。 文章目录 1. 丹摩平台简介2. 平台特性2. 1 超友好的用户体验2. 2 资源丰富的GPU覆盖2. 3 强大的性能2. 4 超实惠的价格2. 5 不同目的推荐的配置2. 6 启动环境 3. 快速上手丹摩平台3. 1 创建项目与资源实例3. 2 储存选项3. 3 数据…...

全面解析租赁小程序的功能与优势
内容概要 租赁小程序正在逐渐改变人与物之间的互动方式。通过这些小程序,用户不仅可以轻松找到所需的租赁商品,还能够享受无缝的操作体验。为了给大家一个清晰的了解,下面我们将重点介绍几个核心功能。 建议:在选择租赁小程序时&…...

VRRP的知识点总结及实验
1、VRRP VRRP(Virtual Router Redundancy Protocol,虚拟路由器冗余协议)既能够实现网关的备份,又能解决多个网关之间互相冲突的问题,从而提高网络可靠性。 2、VRRP技术概述: 通过把几台路由设备联合组成一台虚拟的“路由设备”…...

商业银行基于容器云的分布式数据库架构设计与创新实践
导读 本文介绍了某商业银行基于 TiDB 和 Kubernetes(简称 K8s) 构建的云化分布式数据库平台,重点解决了传统私有部署模式下的高成本、低资源利用率及运维复杂等问题。 通过引入 TiDB Operator 自动化管理与容器化技术,银行能够实现多个业务系统的高可用…...

2025计算机毕设选题推荐【30条选题】【基础功能+创新点设计】
✅博主介绍:CSDN毕设辅导博主、CSDN认证 Java领域优质创作者 ✅技术范围:主要包括Java、Vue、Python、爬虫、小程序、安卓app、大数据、机器学习等设计与开发。 ✅主要内容:免费功能设计、开题报告、任务书、功能实现、代码编写、论文编写和…...

SpringBoot+OSS文件(图片))上传
SpringBoot整合OSS实现文件上传 以前,文件上传到本地(服务器,磁盘),文件多,大,会影响服务器性能 如何解决? 使用文件服务器单独存储这些文件,例如商业版–>七牛云存储,阿里云OSS,腾讯云cos等等 也可以自己搭建文件服务器(FastDFS,minio) 0 过程中需要实名认证 … 1 开…...

掌握BepInEx:Unity游戏扩展全家桶的零门槛实践指南
掌握BepInEx:Unity游戏扩展全家桶的零门槛实践指南 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx 🔍 游戏模组管理的行业痛点与解决方案 在Unity游戏生态…...
免费搭建个人AI助手网站(附Docker部署))
手把手教你用ChatGPT-Next-Web(NextChat)免费搭建个人AI助手网站(附Docker部署)
零代码实战:用ChatGPT-Next-Web快速搭建专属AI对话平台 在AI技术平民化的浪潮中,拥有一个私人定制的智能对话平台不再是大公司的专利。ChatGPT-Next-Web(原名NextChat)作为GitHub上最受欢迎的AI界面开源项目之一,让普…...

解锁RePKG的7个实战维度:从资源提取到合规创作的完整指南
解锁RePKG的7个实战维度:从资源提取到合规创作的完整指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 一、问题象限:资源处理的真实困境叙事 1.1 独立游…...

【紧急通知】Python 3.14 JIT默认profile已触发AWS Lambda冷启动恶化阈值!立即执行这4项低成本开关校准
第一章:Python 3.14 JIT编译器冷启动恶化现象的紧急定性Python 3.14 引入的实验性 JIT 编译器(基于 pyjion 改进的 cpython-jit 后端)在首次执行高密度计算函数时,观测到显著的冷启动延迟激增——部分基准测试中延迟较 Python 3.1…...

中关村论坛重磅发布十五项脑机接口成果
当前,脑机接口技术正处于从实验室走向临床应用、从技术突破迈向产业转化的关键时期。中关村论坛重磅发布十五项脑机接口创新成果,聚焦学术创新性、产品合规性、临床突破性与生态共建性四大核心维度,集中呈现我国在该领域的前沿进展。本次发布…...

uConfigLib:嵌入式轻量级类型安全配置注册表
1. uConfigLib 库深度解析:面向嵌入式系统的轻量级配置注册表实现1.1 设计目标与工程定位uConfigLib 是一个专为资源受限嵌入式平台设计的纯 C 语言配置管理库,其核心目标并非提供通用键值存储,而是构建一种类 Windows 注册表(Reg…...
)
手把手教你用SecureCRT录制和修改VBS脚本(解决无限循环执行问题)
SecureCRT自动化实战:从脚本录制到循环执行VBS的完整指南 在IT运维和网络设备管理的日常工作中,重复性命令的执行往往占据了大量时间。SecureCRT作为一款功能强大的终端仿真软件,其脚本录制和VBS脚本执行功能能够显著提升工作效率。本文将深入…...

BlueDot BME280库深度解析:嵌入式多传感器驱动实践
1. BlueDot BME280 库技术解析:面向嵌入式工程师的多传感器驱动实践指南BME280 是博世(Bosch)推出的高精度环境传感器,集成温度、相对湿度与气压三参数测量能力,广泛应用于气象站、IoT终端、无人机姿态补偿及室内环境监…...

【Unity实战】利用Preserve特性解决代码裁剪导致的反射调用失效问题
1. 代码裁剪与反射调用的相爱相杀 第一次遇到这个问题是在去年做手游项目的时候。那天测试同事急匆匆跑过来说:"哥,安卓包加载存档直接闪退!"我心想编辑器里明明好好的,怎么打包就出问题?打开日志一看&#…...
验证服务**在Web3.0时代,用户不再依赖中心化的身份提供商()
**发散创新:用Rust构建Web3.0去中心化身份(DID)验证服务**在Web3.0时代,用户不再依赖中心化的身份提供商(
发散创新:用Rust构建Web3.0去中心化身份(DID)验证服务 在Web3.0时代,用户不再依赖中心化的身份提供商(如Google、微信登录),而是通过去中心化身份(Decentralized Identity, DID&…...