scrapy对接rabbitmq的时候使用post请求
之前做分布式爬虫的时候,都是从push url来拿到爬虫消费的链接,这里提出一个问题,假如这个请求是post请求的呢,我观察了scrapy-redis的源码,其中spider.py的代码是这样写的
1.scrapy-redis源码分析
def make_request_from_data(self, data):"""Returns a `Request` instance for data coming from Redis.Overriding this function to support the `json` requested `data` that contains`url` ,`meta` and other optional parameters. `meta` is a nested json which contains sub-data.Along with:After accessing the data, sending the FormRequest with `url`, `meta` and addition `formdata`, `method`For example:.. code:: json{"url": "https://example.com","meta": {"job-id":"123xsd","start-date":"dd/mm/yy",},"url_cookie_key":"fertxsas","method":"POST",}If `url` is empty, return `[]`. So you should verify the `url` in the data.If `method` is empty, the request object will set method to 'GET', optional.If `meta` is empty, the request object will set `meta` to an empty dictionary, optional.This json supported data can be accessed from 'scrapy.spider' through response.'request.url', 'request.meta', 'request.cookies', 'request.method'Parameters----------data : bytesMessage from redis."""formatted_data = bytes_to_str(data, self.redis_encoding)if is_dict(formatted_data):parameter = json.loads(formatted_data)else:self.logger.warning(f"{TextColor.WARNING}WARNING: String request is deprecated, please use JSON data format. "f"Detail information, please check https://github.com/rmax/scrapy-redis#features{TextColor.ENDC}")return FormRequest(formatted_data, dont_filter=True)if parameter.get("url", None) is None:self.logger.warning(f"{TextColor.WARNING}The data from Redis has no url key in push data{TextColor.ENDC}")return []url = parameter.pop("url")method = parameter.pop("method").upper() if "method" in parameter else "GET"metadata = parameter.pop("meta") if "meta" in parameter else {}return FormRequest(url, dont_filter=True, method=method, formdata=parameter, meta=metadata)源码地址:https://github.com/rmax/scrapy-redis
可以看到这里是可以处理post请求的
2.scrapy-rabbitmq-schrduler源码分析
地址:
https://github.com/aox-lei/scrapy-rabbitmq-scheduler
class RabbitSpider(scrapy.Spider):def _make_request(self, mframe, hframe, body):try:request = request_from_dict(pickle.loads(body), self)except Exception as e:body = body.decode()request = scrapy.Request(body, callback=self.parse, dont_filter=True)return request可以看到RabbitSpider继承了spider的嘞,改写了request,当我们发我post请求的时候 request_from_dict(pickle.loads(body), self)会报错
builtins.UnicodeDecodeError: 'utf-8' codec can't decode byte 0x80 in position 0: invalid start bytepick.loads 在尝试反序列化字节数据时遇到无法解码的字节序列造成的。具体来说,UnicodeDecodeError: 'utf-8' codec can't decode byte 0x80 in position 0: invalid start byte 说明传入的数据包含非 UTF-8 编码的字节,可能是二进制数据或其他编码格式的数据。
def _make_request(self, mframe, hframe, body):try:# 反序列化 body 数据data = pickle.loads(body)# 获取请求的 URL 和其他参数url = data.get('url')method = data.get('method', 'GET').upper() # 默认 GET,如果是 POST 需要设置为 'POST'headers = data.get('headers', {})cookies = data.get('cookies', {})body_data = data.get('body') # 可能是 POST 请求的表单数据callback_str = data.get('callback') # 回调函数名称(字符串)errback_str = data.get('errback') # 错误回调函数名称(字符串)meta = data.get('meta', {})# 尝试从全局字典中获取回调函数# 使用爬虫实例的 `getattr` 方法获取回调函数callback = getattr(self, callback_str, None) if callback_str else Noneerrback = getattr(self, errback_str, None) if errback_str else None# # 确保回调函数存在# if callback is None:# self.logger.error(f"Callback function '{callback_str}' not found.")# if errback is None:# self.logger.error(f"Errback function '{errback_str}' not found.")# 判断请求方法,如果是 POST,则使用 FormRequestif callback:if method == 'POST':# FormRequest 适用于带有表单数据的 POST 请求request = scrapy.FormRequest(url=url,method='POST',headers=headers,cookies=cookies,body=body_data, # 请求的主体callback=callback,errback=errback,meta=meta,dont_filter=True)else:# 默认处理 GET 请求request = scrapy.Request(url=url,headers=headers,cookies=cookies,callback=callback,errback=errback,meta=meta,dont_filter=True)else: passexcept Exception as e:body = body.decode()request = scrapy.Request(body, callback=self.parse, dont_filter=True)return request直接获取callback是个字符串而不是函数,要在spider中获取到对应的函数
注:由于scrapy-rabbitmq-scheduler无人更新维护,目前新的scrapy已经不支持,上述最新的代码已推github:https://github.com/tieyongjie/scrapy-rabbitmq-task
安装直接安装
pip install scrapy-rabbitmq-task
相关文章:

scrapy对接rabbitmq的时候使用post请求
之前做分布式爬虫的时候,都是从push url来拿到爬虫消费的链接,这里提出一个问题,假如这个请求是post请求的呢,我观察了scrapy-redis的源码,其中spider.py的代码是这样写的 1.scrapy-redis源码分析 def make_request_from_data(self, data):"""Returns a Reques…...
vue+elementUI+transition实现鼠标滑过div展开内容,鼠标划出收起内容,加防抖功能
文章目录 一、场景二、实现代码1.子组件代码结构2.父组件 一、场景 这两天做项目,此产品提出需求 要求详情页的顶部区域要在鼠标划入后展开里面的内容,鼠标划出要收起部分内容,详情底部的内容高度要自适应,我这里运用了鼠标事件t…...

大模型语料库的构建过程 包括知识图谱构建 垂直知识图谱构建 输入到sql构建 输入到cypher构建 通过智能体管理数据生产组件
以下是大模型语料库的构建过程: 一、文档切分语料库构建 数据来源确定: 首先,需要确定语料库的数据来源。这些来源可以是多种多样的,包括但不限于: 网络资源:利用网络爬虫技术从各种网站(如新闻…...

阿里云ECS服务器域名解析
阿里云ECS服务器域名解析,以前添加两条A记录类型,主机记录分别为www和,这2条记录都解析到服务器IP地址。 1.进入阿里云域名控制台,找到域名 ->“解析设置”->“添加记录” 2.添加一条记录类型为A,主机记录为www,…...

牛客周赛71:A:JAVA
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 题目描述 \hspace{15pt}对于给定的两个正整数 nnn 和 kkk ,是否能构造出 kkk 对不同的正整数 (x,y)(x,y)(x,y) ,使得 xynxynxyn 。 \hspace{15pt}我们认为两对正整数 (…...
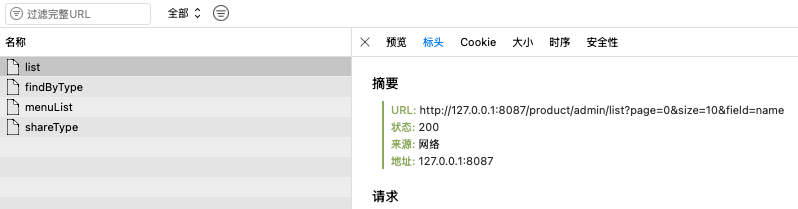
查询产品所涉及的表有(product、product_admin_mapping)
文章目录 1、ProductController2、AdminCommonService3、ProductApiService4、ProductCommonService5、ProductSqlService1. 完整SQL分析可选部分(条件筛选): 2. 涉及的表3. 总结4. 功能概述 查询指定管理员下所有产品所涉及的表?…...
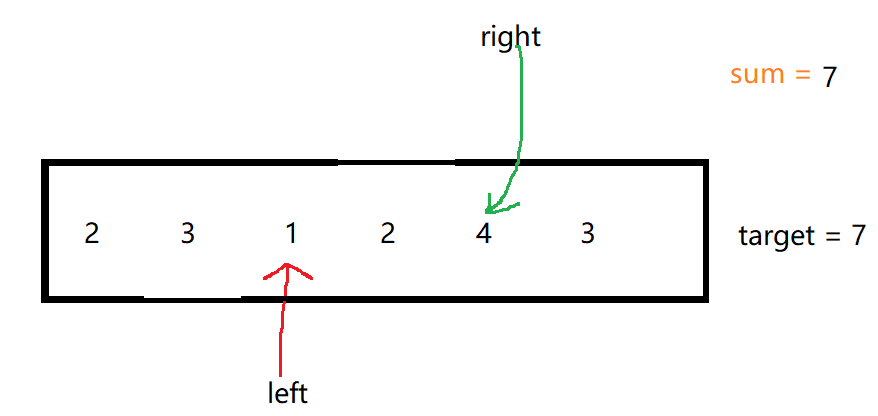
算法基础学习Day5(双指针、动态窗口)
文章目录 1.题目2.题目解答1.四数之和题目及题目解析算法学习代码提交 2.长度最小的子数组题目及题目解析滑动窗口的算法学习方法一:单向双指针(暴力解法)方法二:同向双指针(滑动窗口) 代码提交 1.题目 18. 四数之和 - 力扣(LeetCode&#x…...
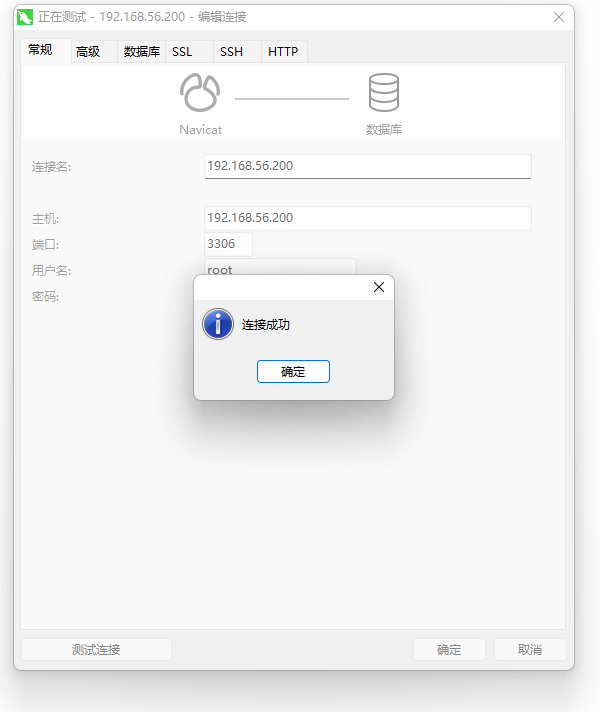
docker 部署 mysql 9.0.1
docker 如何部署 mysql 9 ,请看下面步骤: 1. 先看 mysql 官网 先点进去 8 版本的 Reference Manual 。 选择 9.0 版本的。 点到这里来看, 这里有一些基础的安装步骤,可以看一下。 - Basic Steps for MySQL Server Deployment wit…...

关于小标join大表,操作不当会导致笛卡尔积,数据倾斜
以前总是说笛卡尔积,笛卡尔积,没碰到过,今天在跑流程调度时,就碰到笛卡尔积了,本来,就是查询几个编码的信息,然后由于使用的是with tmp as,没使用where in ,所以跑的很慢 现象&#…...

SpringMVC全局异常处理
一、Java中的异常 定义:异常是程序在运行过程中出现的一些错误,使用面向对象思想把这些错误用类来描述,那么一旦产生一个错误,即创建某一个错误的对象,这个对象就是异常对象。 类型: 声明异常࿱…...

出海服务器可以用国内云防护吗
随着企业国际化进程的加速,越来越多的企业选择将业务部署到海外服务器上,以便更贴近国际市场。然而,海外服务器也面临着来自全球各地的安全威胁和网络攻击。当出海服务器遭受攻击时,是否可以借助国内的云服务器来进行有效的防护呢…...

从零开始的使用SpringBoot和WebSocket打造实时共享文档应用
在现代应用中,实时协作已经成为了非常重要的功能,尤其是在文档编辑、聊天系统和在线编程等场景中。通过实时共享文档,多个用户可以同时对同一份文档进行编辑,并能看到其他人的编辑内容。这种功能广泛应用于 Google Docs、Notion 等…...

Ant Design Pro实战--day01
下载nvm https://nvm.uihtm.com/nvm-1.1.12-setup.zip 下载node.js 16.16.0 //非此版本会报错 nvm install 16.16.0 安装Ant Design pro //安装脚手架 npm i ant-design/pro-cli -g //下载项目 pro create myapp //选择版本 simple 安装依赖 npm install 启动umi yarn add u…...

pcl点云库离线版本构建
某天在摸鱼的小邓接到任务需要进行点云数据的去噪,在万能的github中发现如下pcl库非常好使,so有了此, 1.下载vs2017连接如下: ed2k://|file|mu_visual_studio_community_2017_version_15.1_x86_x64_10254689.exe|1037144|12F5C1…...

字节高频算法面试题:小于 n 的最大数
问题描述(感觉n的位数需要大于等于2,因为n的位数1的话会有点问题,“且无重复”是指nums中存在重复,但是最后返回的小于n最大数是可以重复使用nums中的元素的): 思路: 先对nums倒序排序 暴力回…...

ElasticSearch常见面试题汇总
一、ElasticSearch基础: 1、什么是Elasticsearch: Elasticsearch 是基于 Lucene 的 Restful 的分布式实时全文搜索引擎,每个字段都被索引并可被搜索,可以快速存储、搜索、分析海量的数据。 全文检索是指对每一个词建立一个索引…...

Spring Boot如何实现防盗链
一、什么是盗链 盗链是个什么操作,看一下百度给出的解释:盗链是指服务提供商自己不提供服务的内容,通过技术手段绕过其它有利益的最终用户界面(如广告),直接在自己的网站上向最终用户提供其它服务提供商的…...

工作中常用springboot启动后执行的方法
前言: 工作中难免会遇到一些,程序启动之后需要提前执行的需求。 例如: 初始化缓存:在启动时加载必要的缓存数据。定时任务创建或启动:程序启动后创建或启动定时任务。程序启动完成通知:程序启动完成后通…...

力扣-图论-3【算法学习day.53】
前言 ###我做这类文章一个重要的目的还是给正在学习的大家提供方向和记录学习过程(例如想要掌握基础用法,该刷哪些题?)我的解析也不会做的非常详细,只会提供思路和一些关键点,力扣上的大佬们的题解质量是非…...

Linux上的C语言编程实践
说明: 这是个人对该在Linux平台上的C语言学习网站笨办法学C上的每一个练习章节附加题的解析和回答 ex1: 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后运行它看看发生了什么。 vim ex1.c打开 ex1.c 文件。假如我们删除 return 0…...
)
Simulink仿真避坑指南:PWM控制48V直流电机时,轻载和重载下的参数设置与波形分析(附2018a源文件)
Simulink仿真避坑指南:PWM控制48V直流电机时,轻载和重载下的参数设置与波形分析 在工程实践中,直流电机的仿真建模是验证控制算法和预测系统性能的关键环节。特别是当面对不同负载条件时,如何准确设置电机参数并解读仿真波形&…...

B站命令行工具bilibili-cli:极客的终端视频浏览与自动化方案
1. 项目概述:在终端里逛B站,是一种什么体验? 如果你和我一样,是个重度命令行爱好者,或者单纯觉得在浏览器里点来点去效率太低,那么今天聊的这个工具可能会让你眼前一亮。 bilibili-cli ,顾名思…...

如何在5分钟内免费掌握Windows风扇控制终极技巧
如何在5分钟内免费掌握Windows风扇控制终极技巧 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/FanControl.Relea…...

论文降AI率通关指南:7个实用技巧+高效工具一次讲清
为什么你的论文总被判定为AIGC疑似? 随着AI写作工具的广泛普及,不少科研人员和学生都碰到了同一个头疼的问题:论文AIGC疑似率超标。现在大多数高校都出台了明确规定,AIGC率超过30%就可能被判定为AI代写,直接取消答辩资…...

在多模型AI客服场景下利用Taotoken实现成本与效果的平衡
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多模型AI客服场景下利用Taotoken实现成本与效果的平衡 应用场景类,设想一个在线客服系统需要集成对话AI的场景&#…...

TEdit地图编辑器:从新手到专家的泰拉瑞亚世界创作指南
TEdit地图编辑器:从新手到专家的泰拉瑞亚世界创作指南 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you ch…...
)
别再只调分辨率了!手把手教你用VESA时序搞定1080P显示器驱动(附Verilog代码)
从VESA标准到FPGA实战:构建1080P显示驱动的完整逻辑链 在数字显示技术领域,驱动一块19201080分辨率的屏幕远不止是配置几个参数那么简单。当我第一次尝试用FPGA驱动高清显示器时,发现大多数教程都停留在"设置分辨率"的层面…...

Ask your GIT:AI驱动的代码仓库智能助手,一键解析与安装
1. 项目概述:一个为开发者“减负”的智能代码助手在GitHub、GitLab或者Bitbucket上发现一个看起来很有潜力的开源项目,是每个开发者的日常。但随之而来的,往往是长达十几甚至几十分钟的“阅读理解”时间:你得先通读冗长的README&a…...

3分钟解锁百度网盘极速下载:BaiduPCS-Web高效解决方案全攻略
3分钟解锁百度网盘极速下载:BaiduPCS-Web高效解决方案全攻略 【免费下载链接】baidupcs-web 项目地址: https://gitcode.com/gh_mirrors/ba/baidupcs-web 还在为百度网盘的龟速下载而烦恼吗?今天我要为你介绍一个能够彻底改变下载体验的神器——…...

gqty:零配置强类型GraphQL客户端,颠覆传统开发体验
1. 项目概述:一个颠覆性的GraphQL客户端方案如果你在过去几年里深度参与过前端开发,尤其是与GraphQL API打交道,那么你一定体会过那种“甜蜜的负担”。GraphQL带来的数据查询自由度和类型安全让人着迷,但随之而来的客户端状态管理…...